從Transformer問世至2023年ChatGPT爆火到2024年Sora吸睛,人們逐漸意識到隨著模型參數規模增加,模型的效果越來越好,且兩者之間符合Scalinglaw規律,且當模型的參數規模超過數百億后
2024-03-22 16:40:28 135
135 章節,提供大語言模型微調的詳細指導,逐步引領讀者掌握關鍵技能。這不僅有助于初學者迅速上手,也為有經驗的開發者提供了深入學習的機會。作為真正的大語言模型實踐者,我們擁有十億、百億、千億等不同參數規模大語言
2024-03-18 15:49:46
首先看吞吐量,看起來沒有什么違和的,在單卡能放下模型的情況下,確實是 H100 的吞吐量最高,達到 4090 的兩倍。
2024-03-13 12:27:28353 學習展開,詳細介紹各階段使用的算法、數據、難點及實踐經驗。
預訓練階段需要利用包含數千億甚至數萬億單詞的訓練數據,并借助由數千塊高性能GPU 和高速網絡組成的超級計算機,花費數十天完成深度神經網絡參數
2024-03-11 15:16:39
谷歌在模型訓練方面提供了一些強大的軟件工具和平臺。以下是幾個常用的谷歌模型訓練軟件及其特點。
2024-03-01 16:24:01183 谷歌模型訓練軟件主要是指ELECTRA,這是一種新的預訓練方法,源自谷歌AI。ELECTRA不僅擁有BERT的優勢,而且在效率上更勝一籌。
2024-02-29 17:37:39336 2022 年開始,我們發現 Multilingual BERT 是一個經過大規模跨語言訓練驗證的模型實例,其展示出了優異的跨語言遷移能力。具
2024-02-20 14:51:35221 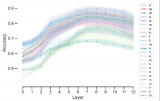
): 與稠密模型相比,預訓練速度更快 與具有相同參數數量的模型相比,具有更快的推理速度 需要大量顯存,因為所有專家系統都需要加載到內存中 在微調方面
2024-01-13 09:37:33315 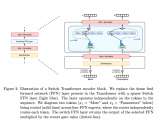
近日,百度地圖宣布其城市車道級導航取得里程碑突破,已率先覆蓋全國超100城普通道路。
2024-01-09 17:28:51627 
成都辰顯光電有限公司(以下簡稱“辰顯光電”)近日完成了數億元A輪融資,這是其發展歷程中的又一重要里程碑。
2024-01-03 14:44:02462 全微調(Full Fine-tuning):全微調是指對整個預訓練模型進行微調,包括所有的模型參數。在這種方法中,預訓練模型的所有層和參數都會被更新和優化,以適應目標任務的需求。
2024-01-03 10:57:212273 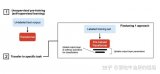
12月28日,國儀量子向上海大學理學院正式交付X波段連續波電子順磁共振波譜儀EPR200-Plus,標志著國儀量子自主研制的電子順磁共振波譜儀實現了全球交付100臺的重要里程碑。上海大學理學院常務副
2023-12-30 08:25:02172 
大模型時代,根據大模型縮放定律,大家通常都在追求模型的參數規模更大、訓練的數據更多,從而使得大模型涌現出更多的智能。但是,模型參數越大部署壓力就越大。即使有gptq、fastllm、vllm等推理加速方法,但如果GPU資源不夠也很難保證高并發。
2023-12-28 11:47:14432 
2023年12月25日,領先的汽車電子芯片整體解決方案提供商湖北芯擎科技有限公司(以下簡稱:芯擎科技)正式公布其商業業績的重要里程碑 –?首款國產7納米高算力車規級芯片“龍鷹一號”自年內開始量產交付
2023-12-26 10:37:10313 Hello大家好,今天給大家分享一下如何基于YOLOv8姿態評估模型,實現在自定義數據集上,完成自定義姿態評估模型的訓練與推理。
2023-12-25 11:29:01968 
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現工件切割點位置預測,主要是通過對YOLOv8姿態評估模型在自定義的數據集上訓練,生成一個工件切割分離點預測模型
2023-12-22 11:07:46258 
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現圓檢測與圓心位置預測,主要是通過對YOLOv8姿態評估模型在自定義的數據集上訓練,生成一個自定義的圓檢測與圓心定位預測模型
2023-12-21 10:50:05513 
抓取圖像,手動標注并完成自定義目標檢測模型訓練和測試
在第二章中,我介紹了模型訓練的一般過程,其中關鍵的過程是帶有標注信息的數據集獲取。訓練過程中可以已有的數據集合不能滿足自己的要求,這時候就需要
2023-12-16 10:05:19
本章記錄了如何從網上抓取素材并進行標注,然后訓練,導出測試自己的模型。
2023-12-16 09:55:18266 
的,只不過主角這次換成了pulsar2:
1、先在服務器上訓練好網絡模型,并以一個通用的中間形式導出(通常是onnx)
2、根據你要使用的推理引擎進行離線轉換,把onnx轉換成你的推理引擎能部署的模型
2023-12-10 16:34:43
和足夠的計算資源,還需要根據任務和數據的特點進行合理的超參數調整、數據增強和模型微調。在本文中,我們將會詳細介紹深度學習模型的訓練流程,探討超參數設置、數據增強技
2023-12-07 12:38:24543 
近日,武漢芯源半導體正式發布首款基于Cortex?-M0+內核的CW32A030C8T7車規級MCU,這是武漢芯源半導體首款通過AEC-Q100 (Grade 2)車規標準的主流通用型車規MCU產品
2023-11-30 15:47:01
基于英偉達混合資源及天數智芯混合資源完成訓練的大模型, 也是智源研究院與天數智芯合作取得的最新成果,再次證明了天數智芯通用 GPU 產品支持大模型訓練的能力,以及與主流產品的兼容能力。 據林詠華副院長介紹,為了解決異構算力混合訓練難題,智源研究院開發了高效并行訓練框
2023-11-30 13:10:02727 
和 50% - 75% 的通信成本,而且英偉達最新一代卡皇 H100 自帶良好的 FP8 硬件支持。但目前業界大模型訓練框架對 FP8 訓練的支持還非常有限。最近,微軟提出了
2023-11-03 19:15:01848 
的博文,對 Pytorch的AMP ( autocast與Gradscaler 進行對比) 自動混合精度對模型訓練加速 。 注意Pytorch1.6+,已經內置torch.cuda.amp,因此便不需要加載
2023-11-03 10:00:191054 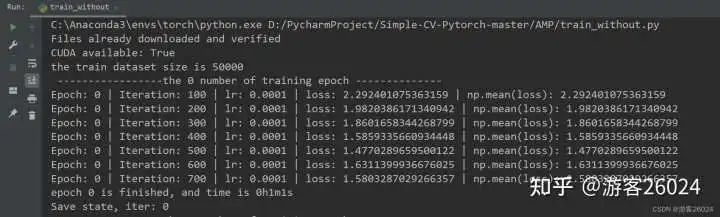
昂貴 H100 的一時洛陽紙貴,供不應求,大模型訓練究竟需要多少張卡呢?GPT-4 很有可能是在 10000 到 20000 張 A100 的基礎上訓練完成的[8]。按照 Elon Musk 的說法
2023-10-29 09:48:134184 
【Vitis AI】 Vitis AI 通過遷移學習訓練自定義模型
測評計劃:
一、開箱報告,KV260通過網線共享PC網絡
二、Zynq超強輔助-PYNQ配置,并使用XVC(Xilinx
2023-10-16 15:03:16
非常高興地向各位宣布,賽昉VisionFive 2上已成功集成了Android開源項目(AOSP),為用戶帶來了更多的軟件解決方案以及與Android軟件生態系統的無縫集成。這一里程碑源于與開源社區
2023-10-16 13:11:45
深度學習、機器學習、生成式AI、深度神經網絡、抽象學習、Seq2Seq、VAE、GAN、GPT、BERT、預訓練語言模型、Transformer、ChatGPT、GenAI、多模態大模型、視覺大模型
2023-09-22 14:13:09605 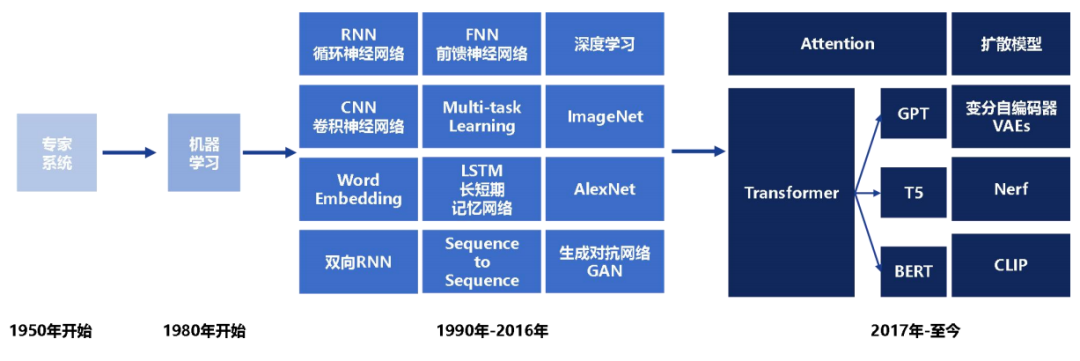
邁步機器人BEAR-H系列是用于輔助腦卒中患者步態康復訓練的新型可穿戴式下肢外骨骼機器人。機器人擁有主動被動訓練模式,通過對患者髖、膝、踝關節提供助力完成行走訓練,可以節省人力,并提高康復效果
2023-09-20 17:25:48
model 訓練完成后,使用 instruction 以及其他高質量的私域數據集來提升 LLM 在特定領域的性能;而 rlhf 是 openAI 用來讓model 對齊人類價值觀的一種強大技術;pre-training dataset 是大模型在訓練時真正喂給 model 的數據,從很多 paper 能看到一些觀
2023-09-19 10:00:06505 
,608,609]\"
–model參數到模型所在文件夾那一級;paddle模型有2種:組合式(combined model)和非復合式(uncombined model);組合式就是__model__
2023-09-19 07:05:28
為什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 幾種并行方式,分別在模型的層內、模型的層間、訓練數據三個維度上對 GPU 進行劃分。三個并行度乘起來,就是這個訓練任務總的 GPU 數量。
2023-09-15 11:16:2112059 
目前官方的線上模型訓練只支持K210,請問K510什么時候可以支持
2023-09-13 06:12:13
近期,一支來自中國的研究團隊正是針對這些問題提出了解決方案,他們推出了FLM-101B模型及其配套的訓練策略。FLM-101B不僅大幅降低了訓練成本,而且其性能表現仍然非常出色,它是目前訓練成本最低的100B+ LLM。
2023-09-12 16:30:30921 
摘要:本文主要介紹大模型的內部運行原理、我國算力發展現狀。大模型指具有巨大參數量的深度學習模型,如GPT-4。其通過在大規模數據集上進行訓練,能夠產生更加準確和有創造性的結果。大模型的內部運行
2023-09-09 11:15:561261 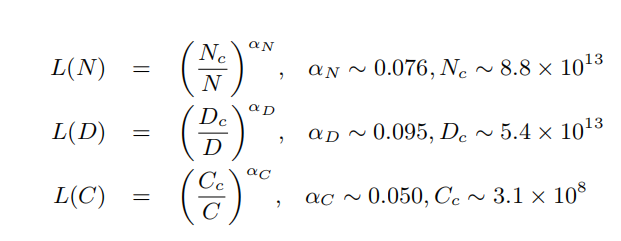
大模型落地實踐》的主題演講,深入介紹了天數智芯通用GPU產品以及自主算力解決方案,為大模型創新發展打造堅實算力底座。 天數智芯副總裁郭為 郭為指出,大模型的飛速發展產生超預期效果,為人工智能發展帶來了新的機遇。順應發展需求
2023-09-07 17:15:05574 
華為盤古大模型以Transformer模型架構為基礎,利用深層學習技術進行訓練。模型的每個數量達到2.6億個,是目前世界上最大的漢語預備訓練模型之一。這些模型包含許多小模型,其中最大的模型包含1億4千萬個參數。
2023-09-05 09:55:561228 生成式AI和大語言模型(LLM)正在以難以置信的方式吸引全世界的目光,本文簡要介紹了大語言模型,訓練這些模型帶來的硬件挑戰,以及GPU和網絡行業如何針對訓練的工作負載不斷優化硬件。
2023-09-01 17:14:561046 
基礎設施和通信基礎設施等領域開展緊密合作,全面提升自主算力供給能力和服務水平,助力我國數字經濟高質量發展。 天數算力是上海天數智芯半導體有限公司(以下簡稱“天數智芯”)的全資子公司。作為國內率先開展通用GPU設計的初創
2023-08-30 11:47:18848 同類產品有記錄以來首次達到的成就,也是整個行業的一個重要里程碑,證明 Transphorm 的氮化鎵器件能夠滿足伺服
2023-08-28 13:44:35154 
在《英特爾銳炫 顯卡+ oneAPI 和 OpenVINO 實現英特爾 視頻 AI 計算盒訓推一體-上篇》一文中,我們詳細介紹基于英特爾 獨立顯卡搭建 YOLOv7 模型的訓練環境,并完成了 YOLOv7 模型訓練,獲得了最佳精度的模型權重。
2023-08-25 11:08:58817 
數據并行是最常見的并行形式,因為它很簡單。在數據并行訓練中,數據集被分割成幾個碎片,每個碎片被分配到一個設備上。這相當于沿批次(Batch)維度對訓練過程進行并行化。每個設備將持有一個完整的模型副本,并在分配的數據集碎片上進行訓練。
2023-08-24 15:17:28537 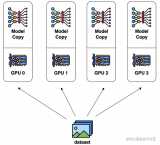
近日,沐曦集成電路(上海)有限公司(下稱“沐曦”)曦云C500千億參數AI大模型訓練及通用計算GPU與北京智譜華章科技有限公司(下稱“智譜AI”)開源的中英雙語對話語言模型ChatGLM2-6B完成
2023-08-23 10:38:473028 模型訓練是將模型結構和模型參數相結合,通過樣本數據的學習訓練模型,使得模型可以對新的樣本數據進行準確的預測和分類。本文將詳細介紹 CNN 模型訓練的步驟。 CNN 模型結構 卷積神經網絡的輸入
2023-08-21 16:42:00884 生態共創計劃,天數智芯作為重要合作伙伴參與此次發布儀式。 飛槳+ 文心大模型硬件生態共創計劃發布儀式 天數智芯是國內首家實現通用GPU量產的硬科技企業,公司天垓、智鎧兩大系列通用GPU產品具有全自主、高性能、廣通用等特點,廣泛適用互聯網、智能安防、生物
2023-08-17 22:15:01836 
模型,以便將來能夠進行準確的預測。推理是指在訓練完成后,使用已經訓練好的模型進行新的預測。然而,深度學習框架是否區分訓練和推理呢? 大多數深度學習框架是區分訓練和推理的。這是因為,在訓練和推理過程中,使用的是
2023-08-17 16:03:11905 盤古大模型參數量有多少 盤古大模型(PanGu-α)是由中國科學院計算技術研究所提供的一種語言生成預訓練模型。該模型基于Transformer網絡架構,并通過在超過1.1TB的文本數據上進行訓練
2023-08-17 11:28:181769 近日,上海天數智芯半導體有限公司(簡稱 “天數智芯”)與 上海愛可生信息技術股份有限公司(以下簡稱 “愛可生”) 完成產品兼容性 互 認證。 結論顯示: 天數智芯通用 GPU產品智鎧MR-V50
2023-08-12 14:30:031109 
新佳績 繼聯合電子新一代X-Pin電機正式批產后,公司又迎來了一個重要里程碑。截至2023年6月底,聯合電子電機產品累計銷售量突破200萬!從2013年首個電機項目IMG290批產,到2022年年
2023-08-06 08:35:01880 訓練好的ai模型導入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
2023-08-04 09:16:28
有很多方法可以將經過訓練的神經網絡模型部署到移動或嵌入式設備上。不同的框架在各種平臺上支持Arm,包括TensorFlow、PyTorch、Caffe2、MxNet和CNTK,如Android
2023-08-02 06:43:57
訓練和微調大型語言模型對于硬件資源的要求非常高。目前,主流的大模型訓練硬件通常采用英特爾的CPU和英偉達的GPU。然而,最近蘋果的M2 Ultra芯片和AMD的顯卡進展給我們帶來了一些新的希望。
2023-07-28 16:11:012123 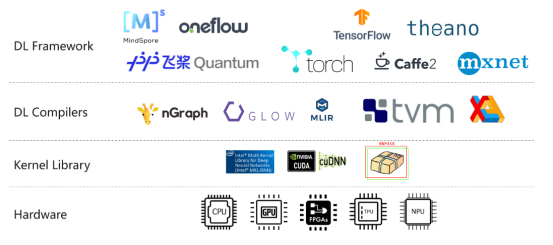
電子發燒友網報道(文/李彎彎)日前,在2023世界半導體大會暨南京國際半導體博覽會上,高通全球副總裁孫剛發表演講時談到,目前高通能夠支持參數超過10億的模型在終端上運行,未來幾個月內超過100億參數
2023-07-26 00:15:001058 《 國產 GPU的大模型實踐 》 的主題演講 , 全面介紹了天數智芯 通用 GPU產品特色 以及 在大模型上的 應用 情況 。 天數智芯副總裁郭為 郭為指出,算力關乎大模型產品的成敗。作為中國領先的通用GPU 高端芯片及超級算力系統提供商,天數智芯先后發布了訓練產品天垓100、推理產品智鎧100,
2023-07-17 22:25:02397 
準備時間長,數據來源分散,歸集慢,預處理百TB數據需10天左右; ● 其次,多模態大模型以海量文本、圖片為訓練集,當前海量小文件的加載速度不足100MB/s,訓練集加載效率低; ● 第三,大模型參數頻繁調優,訓練平臺不穩定,平均約2天出現一次訓
2023-07-14 15:20:02475 
7月6日-8日,為期三天的2023世界人工智能大會(WAIC)圓滿落幕!作為國內率先實現通用GPU量產應用的硬科技企業,天數智芯重磅展示了天垓、智鎧系列通用GPU產品在大模型方面的最新應用成果以及
2023-07-11 23:05:01835 
而言,核心三要素是算法、數據和算力,其中算力是底座。 ?對于算力而言,目前行業基本的共識是基于通用GPU來構建AI大模型的算力集群,上海天數智芯半導體有限公司(以下簡稱:天數智芯)是目前國內第一家實現通用GPU量產并落地的公司。在WAIC上,天數
2023-07-11 01:07:002454 
參數規模大,訓練數據規模大。以GPT3為例,GPT3的參數量為1750億,訓練數據量達到了570GB。進而,訓練大規模語言模型面臨兩個主要挑戰:顯存效率和計算效率。 現在業界的大語言模型都是
2023-07-10 09:13:575726 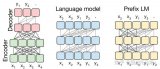
Corporation頒發的2022年度里程碑獎。貿澤長期備貨Amphenol旗下40多個產品部門的全線產品,客戶可前往貿澤官網mouser.cn進行購買。 ? 該獎項頒發給貿澤團隊,包括供應商經理
2023-07-07 16:58:28293 又一里程碑。 在活動現場,墨芯展臺成為全場熱點:1760億參數的大語言模型Bloom在墨芯AI計算平臺的推理引擎支持下,能夠快速、流暢地回答各類問題,并完成詩歌創作、文案撰寫等多項語言生成任務,贏得現場觀眾的關注與贊嘆。 墨芯在千億參
2023-07-07 14:41:17531 7月6日,2023世界人工智能大會在上海世博中心正式開幕。上海天數智芯半導體有限公司(以下簡稱“天數智芯”)攜大模型訓練、推理以及20+行業應用案例亮相WAIC,以視頻、互動等多方式呈現,吸引眾多
2023-07-07 08:20:02424 
近日,上海天數智芯半導體有限公司(簡稱“天數智芯”)與上海云脈芯聯科技有限公司(簡稱“云脈芯聯”)完成產品兼容性認證。在AI大模型智算中心場景下,雙方共同對天數智芯通用GPU產品天垓100系列產品
2023-06-30 17:50:03865 
天數智芯在 湘江新區的布局合作 事宜 。 天數智芯首席運營官劉崢等人陪同參加。 蔡全根副董事長首先對譚勇書記的熱情接待表示衷心的感謝。蔡全根表示,天數智芯率先實現國內通用GPU從0到1的重點突破,發布的兩款通用GPU產品天垓100、智鎧
2023-06-29 22:30:01776 
英偉達前段時間發布GH 200包含 36 個 NVLink 開關,將 256 個 GH200 Grace Hopper 芯片和 144TB 的共享內存連接成一個單元。除此之外,英偉達A100、A800、H100、V100也在大模型訓練中廣受歡迎。
2023-06-29 11:23:5825390 
? ? 在這篇文章中,我們將盡可能詳細地梳理一個完整的 LLM 訓練流程。包括模型預訓練(Pretrain)、Tokenizer 訓練、指令微調(Instruction Tuning)等環節。 文末
2023-06-29 10:08:591200 
SAM被認為是里程碑式的視覺基礎模型,它可以通過各種用戶交互提示來引導圖像中的任何對象的分割。SAM利用在廣泛的SA-1B數據集上訓練的Transformer模型,使其能夠熟練處理各種場景和對象。
2023-06-28 15:08:332574 
1. 大模型訓練的套路 昨天寫了一篇關于生成式模型的訓練之道,覺得很多話還沒有說完,一些關鍵點還沒有點透,決定在上文的基礎上,再深入探討一下大模型訓練這個話題。 任何一個大模型的訓練,萬變不離其宗
2023-06-21 19:55:02312 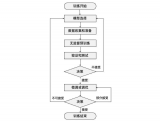
本文基于DeepSpeedExamples倉庫中給出的Megatron相關例子探索一下訓練GPT2模型的流程。主要包含3個部分,第一個部分是基于原始的Megatron如何訓練GPT2模型,第二個部分
2023-06-19 14:45:131717 
在一些非自然圖像中要比傳統模型表現更好 CoOp 增加一些 prompt 會讓模型能力進一步提升 怎么讓能力更好?可以引入其他知識,即其他的預訓練模型,包括大語言模型、多模態模型 也包括
2023-06-15 16:36:11276 
遷移學習徹底改變了自然語言處理(NLP)領域,允許從業者利用預先訓練的模型來完成自己的任務,從而大大減少了訓練時間和計算資源。在本文中,我們將討論遷移學習的概念,探索一些流行的預訓練模型,并通過實際示例演示如何使用這些模型進行文本分類。我們將使用擁抱面轉換器庫來實現。
2023-06-14 09:30:14293 上海天數智芯半導體有限公司 天垓100訓練卡(BI-V100) 天垓100聚焦高性能、通用性和靈活性,支持200余種人工智能模型,支持通用計算、科學計算、大模型、支持業界前沿新算法模型。模型適配速度快,從容面對未來的算法變遷,為人工智能及通用計
2023-06-12 16:15:02515 
的Aquila語言基礎模型,使用代碼數據進行繼續訓練,穩定運行19天,模型收斂效果符合預期,證明天數智芯有支持百億級參數大模型訓練的能力。 在北京市海淀區的大力支持下,智源研究院、天數智芯與愛特云翔共同合作,聯手開展基于自主通用GPU的
2023-06-12 15:23:17550 
? 6月,智源研究院在北京智源大會上重磅發布了全面開源的“悟道3.0”系列大模型,包括“悟道·天鷹”(Aquila)語言大模型等領先成果。目前,摩爾線程已率先完成對“悟道·天鷹”(Aquila
2023-06-12 14:30:221182 ,全面介紹了天數智芯基于自研通用GPU的全棧式集群解決方案及其在支持大模型上的具體實踐。 天數智芯產品線總裁鄒翾 鄒翾指出,順應大模型的發展潮流,天數智芯依托通用GPU架構,從訓練和推理兩個角度為客戶提供支撐,全力打造高性
2023-06-08 22:55:02951 
前文說過,用Megatron做分布式訓練的開源大模型有很多,我們選用的是THUDM開源的CodeGeeX(代碼生成式大模型,類比于openAI Codex)。選用它的原因是“完全開源”與“清晰的模型架構和預訓練配置圖”,能幫助我們高效閱讀源碼。我們再來回顧下這兩張圖。
2023-06-07 15:08:242186 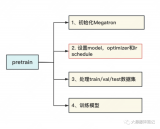
本文章將依次介紹如何將Pytorch自訓練模型經過一系列變換變成OpenVINO IR模型形式,而后使用OpenVINO Python API 對IR模型進行推理,并將推理結果通過OpenCV API顯示在實時畫面上。
2023-06-07 09:31:421057 
因為該模型的訓練時間明顯更長,訓練了1.4 萬億標記而不是 3000 億標記。所以你不應該僅僅通過模型包含的參數數量來判斷模型的能力。
2023-05-30 14:34:56642 
5月,上海市委網信辦楊海軍總工程師一行就大模型發展及應用情況赴上海天數智芯半導體有限公司(以下簡稱“天數智芯”)調研考察,天數智芯副董事長蔡全根等陪同調研。
2023-05-26 11:33:19861 本文章將依次介紹如何將 Pytorch 自訓練模型經過一系列變換變成 OpenVINO IR 模型形式,而后使用 OpenVINO Python API 對 IR 模型進行推理,并將推理結果通過 OpenCV API 顯示在實時畫面上。
2023-05-26 10:23:09548 
vivo AI 團隊與 NVIDIA 團隊合作,通過算子優化,提升 vivo 文本預訓練大模型的訓練速度。在實際應用中, 訓練提速 60% ,滿足了下游業務應用對模型訓練速度的要求。通過
2023-05-26 07:15:03422 
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。
2023-05-25 17:10:09593 OPPO 今日正式發布 Reno 十代里程碑之作 Reno10 系列新品。得益于 Reno 系列在輕薄美學和人像科技賽道的長期深耕,Reno10 系列創新地為用戶帶來一款兼具輕薄手感和大底潛望的人像輕旗艦。
2023-05-24 16:03:25931 
作為深度學習領域的 “github”,HuggingFace 已經共享了超過 100,000 個預訓練模型
2023-05-19 15:57:43494 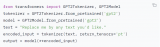
近日,上海天數智芯半導體有限公司(以下簡稱“天數智芯”)與中電云數智科技有限公司(以下簡稱“中國電子云”)完成產品兼容性認證。結論顯示:天數智芯的通用GPU天垓、智鎧系列加速卡在中國電子云專屬云平臺以及超融合產品上運行穩定,性能可靠,表現出良好的兼容性。
2023-05-17 14:50:491013 在推理時,將左右兩部分的結果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要將訓練完成的矩陣乘積BA跟原本的權重矩陣W加到一起作為新權重參數替換原始預訓練語言模型的W即可,不會增加額外的計算資源。
2023-05-17 14:24:201623 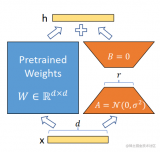
全球 50 多家車企共計部署了 800 多輛基于NVIDIA DRIVE Hyperion 自動駕駛汽車開發平臺和參考架構打造的自動駕駛測試車輛。近日,該架構于自動駕駛安全領域樹立了新的里程碑。
2023-05-10 14:55:01879 在合作伙伴的大力支持和共同努力下,天數智芯自主算力集群方案不僅能夠有效支持OPT、LLaMa、GPT-2、CPM、GLM等主流AIGC大模型的Pretrain和Finetune,還適配支持了清華、智源、復旦等在內的國內多個研究機構的開源大模型,取得了大模型適配支持階段性成果。
2023-04-23 14:19:39938 
我正在嘗試使用自己的數據集訓練人臉檢測模型。此錯誤發生在訓練開始期間。如何解決這一問題?
2023-04-17 08:04:49
,五年不到的時間,完成智艙、智駕、智控三大方向、四個系列產品的順利流片、安全及可靠性驗證和量產上車,目前已擁有260多家國內外優質客戶,完成超百萬片上車的里程碑,成為國內車規級核心芯片設計的引領者。芯
2023-04-14 14:01:22
DriveGPT 雪湖·海若的底層模型采用 GPT(Generative Pre-trained Transformer)生成式預訓練大模型,與 ChatGPT 使用自然語言進行輸入與輸出
2023-04-14 10:27:15871 全球累計出貨量已達1億顆,廣泛運用在如智能座艙、智能駕駛、智能網聯、新能源電動車大小三電系統等,這一重要里程碑凸顯了兆易創新與國內外主流車廠及Tier1供應商的密切合作關系。兆易創新致力于為汽車領域客戶
2023-04-13 15:18:46
我正在嘗試使用 eIQ 門戶訓練人臉檢測模型。我正在嘗試從 tensorflow 數據集 (tfds) 導入數據集,特別是 coco/2017 數據集。但是,我只想導入 wider_face。但是,當我嘗試這樣做時,會出現導入程序錯誤,如下圖所示。任何幫助都可以。
2023-04-06 08:45:14
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。 如果要教一個剛學會走路的孩子什么是獨角獸,那么我們首先應
2023-04-04 01:45:021024
 電子發燒友App
電子發燒友App













 工商網監
工商網監
評論