 電子發(fā)燒友App
電子發(fā)燒友App


以前發(fā)布過HanLP的Lucene插件,后來很多人跟我說其實(shí)Solr更流行(反正我是覺得既然Solr是Lucene的子項(xiàng)目,那么稍微改改配置就能支持Solr),于是就抽空做了個Solr插件出來,開源在Github上,歡迎改進(jìn)。
HanLP中文分詞solr插件支持Solr5.x,兼容Lucene5.x。
圖1
快速上手
1、將和hanlp-solr-plugin.jar共兩個jar放入${webapp}/WEB-INF/lib下
2、修改solr?core的配置文件${core}/conf/schema.xml:
??
??????
??????????
??????
??????
??????????
??????????
??????
??
??
??
??
Solr5中文分詞器詳細(xì)配置
對于新手來說,上面的兩步可能太簡略了,不如看看下面的step?by?step。本教程使用Solr5.2.1,理論上兼容solr5.x。
放置jar
將上述兩個jar放到solr-5.2.1/server/solr-webapp/webapp/WEB-INF/lib目錄下。如果你想自定義詞典等數(shù)據(jù),將hanlp.properties放到solr-5.2.1/server/resources,該目錄也是log4j.properties等配置文件的放置位置。HanLP文檔一直在說“將配置文件放到resources目錄下”,指的就是這個意思。作為Java程序員,這是基本常識。
啟動solr
首先在solr-5.2.1\bin目錄下啟動solr:
1.solr?start?-f
用瀏覽器打開http://localhost:8983/solr/#/,看到如下頁面說明一切正常:
圖2
創(chuàng)建core
在solr-5.2.1\server\solr下新建一個目錄,取個名字比如叫one,將示例配置文件solr-5.2.1\server\solr\configsets\sample_techproducts_configs\conf拷貝過來,接著修改schema.xml中的默認(rèn)域type,搜索
1.???
2.?...
3.?
?
替換為
1.?
4.?
5.?
6.?
7.?
8.?
11.?
12.?
13.?
14.?
15.?
16.?
17.?
18.?
19.?
?
意思是默認(rèn)文本字段類型啟用HanLP分詞器,text_general還開啟了solr默認(rèn)的各種filter。
solr允許為不同的字段指定不同的分詞器,由于絕大部分字段都是text_general類型的,可以說這種做法比較適合新手。如果你是solr老手的話,你可能會更喜歡單獨(dú)為不同的字段指定不同的分詞器及其他配置。如果你的業(yè)務(wù)系統(tǒng)中有其他字段,比如location,summary之類,也需要一一指定其type="text_general"。切記,否則這些字段仍舊是solr默認(rèn)分詞器,會造成這些字段“搜索不到”。
另外,切記不要在query中開啟indexMode,否則會影響PhaseQuery。indexMode只需在index中開啟一遍即可,要不然它怎么叫indexMode呢。
如果你不需要solr提供的停用詞、同義詞等filter,如下配置可能更適合你:
1.?
2.??????
3.??????????
4.??????
5.??????
6.??????????
7.??????????
8.??????
9.??
10.??
11.??
12.??
完成了之后在solr的管理界面導(dǎo)入這個core?one:
?
圖3
接著就能在下拉列表中看到這個core了:
擊查看原圖")
?
圖4
上傳測試文檔
修改好了,就可以拿一些測試文檔來試試效果了。hanlp-solr-plugin代碼庫中的src/test/resources下有個測試文檔集合documents.csv,其內(nèi)容如下:
1.?id,title
2.?1,你好世界
3.?2,商品和服務(wù)
4.?3,和服的價格是每鎊15便士
5.?4,服務(wù)大眾
6.?5,hanlp工作正常
?
代表著id從1到5共五個文檔,接下來復(fù)制solr-5.2.1\example\exampledocs下的上傳工具post.jar到resources目錄,利用如下命令行將數(shù)據(jù)導(dǎo)入:
1.?java?-Dc=one?-Dtype=application/csv?-jar?post.jar?*.csv
Windows用戶的話直接雙擊該目錄下的upload.cmd即可,Linux用戶運(yùn)行upload.sh。
正常情況下輸出如下結(jié)果:
1.?SimplePostTool?version?5.0.0
2.?Posting?files?to?[base]?url?http://localhost:8983/solr/one/update?using?content-
3.?type?application/csv...
4.?POSTing?file?documents.csv?to?[base]
5.?1?files?indexed.
6.?COMMITting?Solr?index?changes?to?http://localhost:8983/solr/one/update...
7.?Time?spent:?0:00:00.059
8.?請按任意鍵繼續(xù).?.?.
?
同時刷新一下core?one的Overview,的確看到了5篇文檔:
擊查看原圖")
?
圖5
搜索文檔
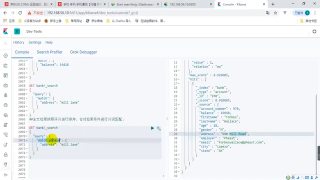
是時候看看HanLP分詞的效果了,點(diǎn)擊左側(cè)面板的Query,輸入“和服”試試:
?
圖6
發(fā)現(xiàn)精確地查到了“和服的價格是每鎊15便士”,而不是“商品和服務(wù)”這種錯誤文檔:
擊查看原圖")
?
圖7
這說明HanLP工作良好。
要知道,不少中文分詞器眉毛胡子一把抓地命中“商品和服務(wù)”這種錯誤文檔,降低了查準(zhǔn)率,拉低了用戶體驗(yàn),跟原始的MySQL?LIKE有何區(qū)別?
索引模式的功能
索引模式可以對長詞進(jìn)行全切分,得到其中蘊(yùn)含的所有詞匯。比如“中醫(yī)藥大學(xué)附屬醫(yī)院”在HanLP索引分詞模式下的切分結(jié)果為:
1.?中0?醫(yī)1?藥2?大3?學(xué)4?附5?屬6?醫(yī)7?院8?
2.?[0:3?1]?中醫(yī)藥/n
3.?[0:2?1]?中醫(yī)/n
4.?[1:3?1]?醫(yī)藥/n
5.?[3:5?1]?大學(xué)/n
6.?[5:9?1]?附屬醫(yī)院/nt
7.?[5:7?1]?附屬/vn
8.?[7:9?1]?醫(yī)院/n
開啟indexMode后,無論用戶搜索“中醫(yī)”“中醫(yī)藥”還是“醫(yī)藥”,都會搜索到“中醫(yī)藥大學(xué)附屬醫(yī)院”:
擊查看原圖")
?
圖8
高級配置
目前本插件支持如下基于schema.xml的配置:
擊查看原圖")
?
圖9
對于更高級的配置,HanLP分詞器主要通過class?path下的hanlp.properties進(jìn)行配置,請閱讀HanLP自然語言處理包文檔以了解更多相關(guān)配置,如:
1.停用詞
2.用戶詞典
3.詞性標(biāo)注
4.……
代碼調(diào)用
在Query改寫的時候,可以利用HanLPAnalyzer分詞結(jié)果中的詞性等屬性,如
1.?String?text?=?"中華人民共和國很遼闊";
2.?for?(int?i?=?0;?i?
3.?{
4.?????System.out.print(text.charAt(i)?+?""?+?i?+?"?");
5.?}
6.?System.out.println();
7.?Analyzer?analyzer?=?new?HanLPAnalyzer();
8.?TokenStream?tokenStream?=?analyzer.tokenStream("field",?text);
9.?tokenStream.reset();
10.?while?(tokenStream.incrementToken())
11.?{
12.?????CharTermAttribute?attribute?=?tokenStream.getAttribute(CharTermAttribute.class);
13.?????//?偏移量
14.?????OffsetAttribute?offsetAtt?=?tokenStream.getAttribute(OffsetAttribute.class);
15.?????//?距離
16.?????PositionIncrementAttribute?positionAttr?=?kenStream.getAttribute(PositionIncrementAttribute.class);
17.?????//?詞性
18.?????TypeAttribute?typeAttr?=?tokenStream.getAttribute(TypeAttribute.class);
19.?????System.out.printf("[%d:%d?%d]?%s/%s\n",?offsetAtt.startOffset(),?offsetAtt.endOffset(),?positionAttr.getPositionIncrement(),?attribute,?typeAttr.type());
20.?}
?
在另一些場景,支持以自定義的分詞器(比如開啟了命名實(shí)體識別的分詞器、繁體中文分詞器、CRF分詞器等)構(gòu)造HanLPTokenizer,比如:
1.?tokenizer?=?new?HanLPTokenizer(HanLP.newSegment()
2.?????????????????????.enableJapaneseNameRecognize(true)
3.?????????????????????.enableIndexMode(true),?null,?false);
4.?tokenizer.setReader(new?StringReader("林志玲亮相網(wǎng)友:確定不是波多野結(jié)衣?"));
5.?...
文章來源于網(wǎng)絡(luò)





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論