 電子發(fā)燒友App
電子發(fā)燒友App


隨著阿里大數(shù)據(jù)產(chǎn)品業(yè)務(wù)的增長,服務(wù)器數(shù)量不斷增多,IT運維壓力也成比例增大。各種軟、硬件故障而造成的業(yè)務(wù)中斷,成為穩(wěn)定性影響的重要因素之一。本文詳細解讀阿里如何實現(xiàn)硬件故障預(yù)測、服務(wù)器自動下線、服務(wù)自愈以及集群的自平衡重建,真正在影響業(yè)務(wù)之前實現(xiàn)硬件故障自動閉環(huán)策略,對于常見的硬件故障無需人工干預(yù)即可自動閉環(huán)解決。
1.背景
1.1.面臨挑戰(zhàn)
對于承載阿里巴巴集團95%數(shù)據(jù)存儲及計算的離線計算平臺MaxCompute,隨著業(yè)務(wù)增長,服務(wù)器規(guī)模已達到數(shù)十萬臺,而離線作業(yè)的特性導(dǎo)致硬件故障不容易在軟件層面被發(fā)現(xiàn),同時集團統(tǒng)一的硬件報障閾值常常會遺漏一些對應(yīng)用有影響的硬件故障,對于每一起漏報,都對集群的穩(wěn)定性構(gòu)成極大的挑戰(zhàn)。
針對挑戰(zhàn),我們面對兩個問題:硬件故障的及時發(fā)現(xiàn)與故障機的業(yè)務(wù)遷移。下面我們會圍繞這兩個問題進行分析,并詳細介紹落地的自動化硬件自愈平臺——DAM。在介紹之前我們先了解下飛天操作系統(tǒng)的應(yīng)用管理體系——天基(Tianji)。
1.2.天基應(yīng)用管理
MaxCompute是構(gòu)建在阿里數(shù)據(jù)中心操作系統(tǒng)——飛天(Apsara)之上,飛天的所有應(yīng)用均由天基管理。天基是一套自動化數(shù)據(jù)中心管理系統(tǒng),管理數(shù)據(jù)中心中的硬件生命周期與各類靜態(tài)資源(程序、配置、操作系統(tǒng)鏡像、數(shù)據(jù)等)。而我們的硬件自愈體系正是與天基緊密結(jié)合,利用天基的Healing機制構(gòu)建面向復(fù)雜業(yè)務(wù)的硬件故障發(fā)現(xiàn)、自愈維修閉環(huán)體系。
透過天基,我們可以將各種物理機的指令(重啟、重裝、維修)下發(fā),天基會將其翻譯給這臺物理機上每個應(yīng)用,由應(yīng)用根據(jù)自身業(yè)務(wù)特性及自愈場景決策如何響應(yīng)指令。
2.硬件故障發(fā)現(xiàn)
2.1.如何發(fā)現(xiàn)
我們所關(guān)注的硬件問題主要包含:硬盤、內(nèi)存、CPU、網(wǎng)卡電源等,下面列舉對于常見硬件問題發(fā)現(xiàn)的一些手段和主要工具:
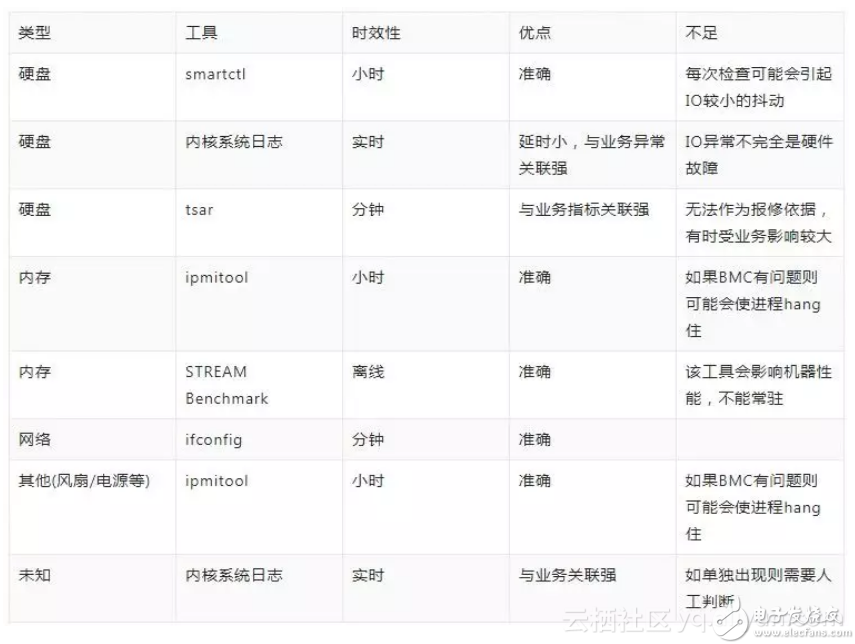
在所有硬件故障中,硬盤故障占比50%以上,下面分析一下最常見的一類故障:硬盤媒介故障。通常這個問題表象就是文件讀寫失敗/卡住/慢。但讀寫問題卻不一定是媒介故障產(chǎn)生,所以我們有必要說明一下媒介故障的在各層的表象。
a. 系統(tǒng)日志報錯是指在/var/log/messages中能夠找到類似下面這樣的報錯
Sep 3 13:43:22 host1.a1 kernel: : [14809594.557970] sd 6:0:11:0: [sdl] Sense Key : Medium Error [current]
Sep 3 20:39:56 host1.a1 kernel: : [61959097.553029] Buffer I/O error on device sdi1, logical block 796203507
b. tsar io指標(biāo)變化是指rs/ws/await/svctm/util等這些指標(biāo)的變化或突變,由于報錯期間會引起讀寫的停頓,所以通常會體現(xiàn)在iostat上,繼而被采集到tsar中。
?●??在tsar io指標(biāo)中,存在這樣一條規(guī)則讓我們區(qū)分硬盤工作是否正常 qps=ws+rs<100 & util>90,假如沒有大規(guī)模的kernel問題,這種情況一般都是硬盤故障引起的。
c. 系統(tǒng)指標(biāo)變化通常也由于io變化引起,比如D住引起load升高等。
d. smart值跳變具體是指197(Current_Pending_Sector)/5(Reallocated_Sector_Ct)的跳變。這兩個值和讀寫異常的關(guān)系是:
?●??媒介讀寫異常后,在smart上能觀察到197(pending) +1,表明有一個扇區(qū)待確認(rèn)。
?●??隨后在硬盤空閑的時候,他會對這個197(pending)中攢的各種待確認(rèn)扇區(qū)做確認(rèn),如果讀寫通過了,則197(pending) -1,如果讀寫不通過則 197(pending)-1 且 5(reallocate)+1。
總結(jié)下來,在整條報錯鏈路中,只觀察一個階段是不夠的,需要多個階段綜合分析來證明硬件問題。由于我們可以嚴(yán)格證明媒介故障,我們也可以反向推導(dǎo),當(dāng)存在未知問題的時候能迅速地區(qū)分出是軟件還是硬件問題。
上述的工具是結(jié)合運維經(jīng)驗和故障場景沉淀出來,同時我們也深知單純的一個發(fā)現(xiàn)源是遠遠不夠的,因此我們也引入了其他的硬件故障發(fā)現(xiàn)源,將多種檢查手段結(jié)合到一起來最終確診硬件故障。
2.2.如何收斂
上一章節(jié)提到的很多工具和路徑用來發(fā)現(xiàn)硬件故障,但并不是每次發(fā)現(xiàn)都一定報故障,我們進行硬件問題收斂的時候,保持了下面幾個原則:
?●??指標(biāo)盡可能與應(yīng)用/業(yè)務(wù)無關(guān):有些應(yīng)用指標(biāo)和硬件故障相關(guān)性大,但只上監(jiān)控,不作為硬件問題的發(fā)現(xiàn)來源。 舉一個例子,當(dāng)io util大于90%的時候硬盤特別繁忙,但不代表硬盤就存在問題,可能只是存在讀寫熱點。我們只認(rèn)為io util>90且iops<30 超過10分鐘的硬盤可能存在硬件問題。
?●??采集敏感,收斂謹(jǐn)慎:對于可能的硬件故障特征都進行采集,但最終自動收斂分析的時候,大多數(shù)采集項只做參考,不作為報修依據(jù)。 還是上一個硬盤io util的例子,如果單純出現(xiàn)io util>90且iops<30的情況,我們不會自動報修硬盤,因為kernel問題也可能會出現(xiàn)這個情況。只有當(dāng) smartctl超時/故障扇區(qū) 等明確故障項出現(xiàn)后,兩者關(guān)聯(lián)才確診硬盤故障,否則只是隔離觀察,不報修。
2.3.覆蓋率
以某生產(chǎn)集群,在20xx年x月的IDC工單為例,硬件故障及工單統(tǒng)計如下:
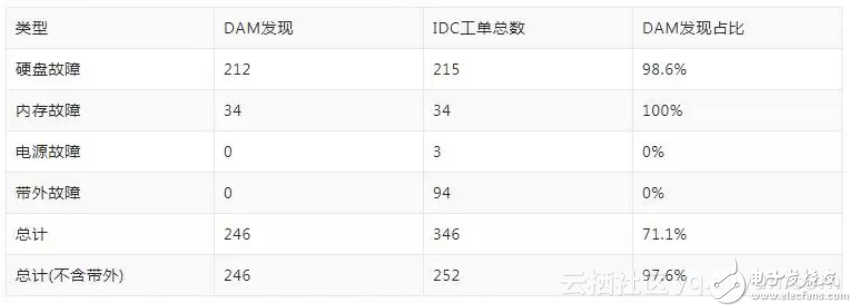
去除帶外故障的問題,我們的硬件故障發(fā)現(xiàn)占比為97.6%。
3.硬件故障自愈
3.1 自愈流程
針對每臺機器的硬件問題,我們會開一個自動輪轉(zhuǎn)工單來跟進,當(dāng)前存在兩套自愈流程:【帶應(yīng)用維修流程】和【無應(yīng)用維修流程】,前者針對的是可熱拔插的硬盤故障,后者是針對余下所有的整機維修硬件故障。
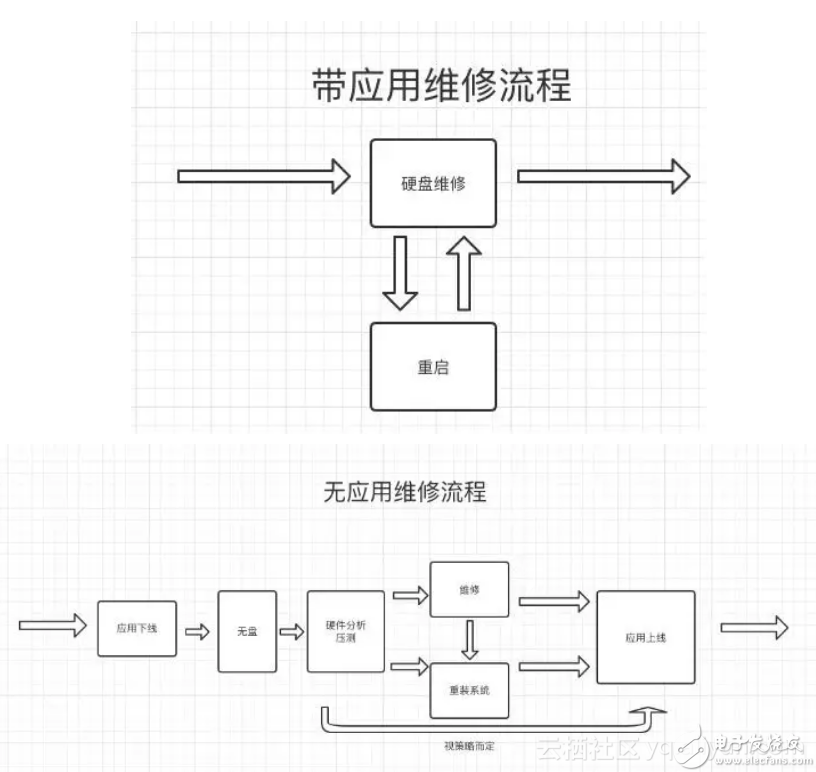
在我們的自動化流程中,有幾個比較巧妙的設(shè)計:
a. 無盤診斷
?●??對于宕機的機器而言,無法進無盤(ramos)才開【無故宕機】維修工單,這樣能夠大量地減少誤報,減少服務(wù)臺同學(xué)負擔(dān)。
?●??無盤中的壓測可以完全消除當(dāng)前版本的kernel或軟件的影響,真實地判斷出硬件是否存在性能問題。
b. 影響面判斷/影響升級
?●??對于帶應(yīng)用的維修,我們也會進行進程是否D住的判斷。如果存在進程D住時間超過10分鐘,我們認(rèn)為這個硬盤故障的影響面已擴大到了整機,需要進行重啟消除影響。
?●??在重啟的時候如果出現(xiàn)了無法啟動的情況,也無需進行人工干預(yù),直接進行影響升級,【帶應(yīng)用維修流程】直接升級成【無應(yīng)用維修流程】。
c. 未知問題自動化兜底
?●??在運行過程中,會出現(xiàn)一些機器宕機后可以進無盤,但壓測也無法發(fā)現(xiàn)任何硬件問題,這個時候就只能讓機器再進行一次裝機,有小部分的機器確實在裝機過程中,發(fā)現(xiàn)了硬件問題繼而被修復(fù)了。
d. 宕機分析
?●??整個流程巧妙的設(shè)計,使得我們在處理硬件故障的時候,同時具備了宕機分析的能力。
?●??不過整機流程還以解決問題為主導(dǎo)向,宕機分析只是副產(chǎn)品。
?●??同時,我們也自動引入了集團的宕機診斷結(jié)果進行分析,達到了1+1>2的效果。
3.2.流程統(tǒng)計分析
如果是同樣的硬件問題反復(fù)觸發(fā)自愈,那么在流程工單的統(tǒng)計,能夠發(fā)現(xiàn)問題。例如聯(lián)想RD640的虛擬串口問題,在還未定位出根因前,我們就通過統(tǒng)計發(fā)現(xiàn)了:同個機型的機器存在反復(fù)宕機自愈的情況,即使機器重裝之后,問題也還是會出現(xiàn)。接下來我們就隔離了這批機器,保障集群穩(wěn)定的同時,為調(diào)查爭取時間。
3.3.業(yè)務(wù)關(guān)聯(lián)誤區(qū)
事實上,有了上面這套完整的自愈體系之后,某些業(yè)務(wù)上/kernel上/軟件上需要處理的問題,也可以進入這個自愈體系,然后走未知問題這個分支。其實硬件自愈解決業(yè)務(wù)問題,有點飲鴆止渴,容易使越來越多還沒想清楚的問題,嘗試通過這種方式來解決兜底。
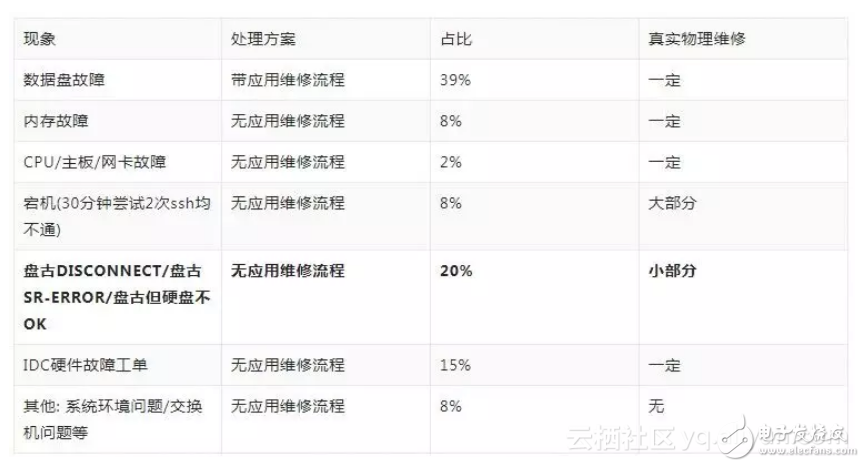
當(dāng)前我們逐步地移除對于非硬件問題的處理,回歸面向硬件自愈的場景(面向軟件的通用自愈也有系統(tǒng)在承載,這類場景與業(yè)務(wù)的耦合性較大,無法面向集團通用化),這樣也更利于軟硬件問題分類和未知問題發(fā)現(xiàn)。
4.架構(gòu)演進
4.1.云化
最初版本的自愈架構(gòu)是在每個集群的控制機上實現(xiàn),因為一開始時候運維同學(xué)也是在控制機上處理各種問題。但隨著自動化地不斷深入,發(fā)現(xiàn)這樣的架構(gòu)嚴(yán)重阻礙了數(shù)據(jù)的開放。于是我們采用中心化架構(gòu)進行了一次重構(gòu),但中心化架構(gòu)又會遇到海量數(shù)據(jù)的處理問題,單純幾個服務(wù)端根本處理不過來。
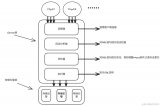
因此我們對系統(tǒng)進一步進行分布式服務(wù)化的重構(gòu),以支撐海量業(yè)務(wù)場景,將架構(gòu)中的各個模塊進行拆解,引入了 阿里云日志服務(wù)(sls)/阿里云流計算(blink)/阿里云分析數(shù)據(jù)庫(ads) 三大神器,將各個采集分析任務(wù)由云產(chǎn)品分擔(dān),服務(wù)端只留最核心的硬件故障分析和決策功能。
下面是DAM1與DAM3的架構(gòu)對比
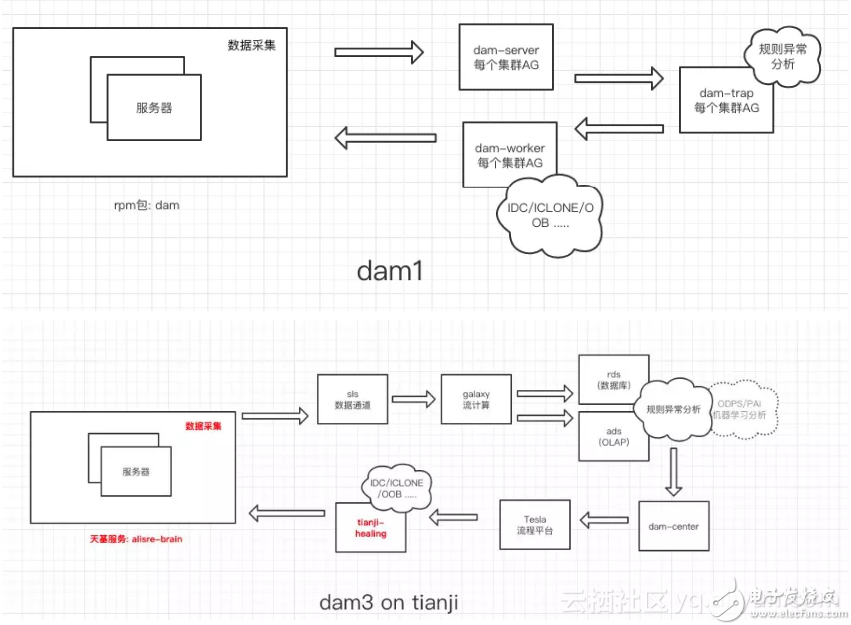
4.2.數(shù)據(jù)化
隨著自愈體系的不斷深入,各階段的數(shù)據(jù)也有了穩(wěn)定的產(chǎn)出,針對這些數(shù)據(jù)的更高維分析,能讓我們發(fā)現(xiàn)更多有價值且明確的信息。同時,我們也將高維的分析結(jié)果進行降維,采用健康分給每臺機器打標(biāo)。通過健康分,運維的同學(xué)可以快速知曉單臺機器、某個機柜、某個集群的硬件情況。
4.3.服務(wù)化
基于對全鏈路數(shù)據(jù)的掌控,我們將整個故障自愈體系,作為一個硬件全生命周期標(biāo)準(zhǔn)化服務(wù),提供給不同的產(chǎn)品線。基于對決策的充分抽象,自愈體系提供各類感知閾值,支持不同產(chǎn)品線的定制,形成適合個性化的全生命周期服務(wù)。
5.故障自愈閉環(huán)體系
在AIOps的感知、決策、執(zhí)行閉環(huán)體系中,軟件/硬件的故障自愈是最常見的應(yīng)用場景,行業(yè)中大家也都選擇故障自愈作為首個AIOps落地點。在我們看來,提供一套通用的故障自愈閉環(huán)體系是實現(xiàn)AIOps、乃至NoOps(無人值守運維)的基石,應(yīng)對海量系統(tǒng)運維,智能自愈閉環(huán)體系尤為重要。
5.1.必要性
在一個復(fù)雜的分布式系統(tǒng)中,各種架構(gòu)間不可避免地會出現(xiàn)運行上的沖突,而這些沖突的本質(zhì)就在于信息不對稱。而信息不對稱的原因是,每種分布式軟件架構(gòu)在設(shè)計都是內(nèi)斂閉環(huán)的。現(xiàn)在,通過各種機制各種運維工具,可以抹平這些沖突,然而這種方式就像是在打補丁,伴隨著架構(gòu)的不斷升級,補丁似乎一直都打不完,而且越打越多。因此,我們有必要將這個行為抽象成自愈這樣一個行為,在架構(gòu)層面顯式地聲明這個行為,讓各軟件參與到自愈的整個流程中,將原本的沖突通過這種方式轉(zhuǎn)化為協(xié)同。
當(dāng)前我們圍繞運維場景中最大的沖突點:硬件與軟件沖突,進行架構(gòu)和產(chǎn)品設(shè)計,通過自愈的方式提升復(fù)雜的分布式系統(tǒng)的整體魯棒性。
5.2.普適性
透過大量機器的硬件自愈輪轉(zhuǎn),我們發(fā)現(xiàn):
?●??被納入自愈體系的運維工具的副作用逐漸降低(由于大量地使用運維工具,運維工具中的操作逐漸趨于精細化)。
?●??被納入自愈體系的人工運維行為也逐漸變成了自動化。
?●??每種運維動作都有了穩(wěn)定的SLA承諾時間,不再是隨時可能運行報錯的運維腳本。
因此,自愈實際上是在復(fù)雜的分布式系統(tǒng)上,將運維自動化進行充分抽象后,再構(gòu)筑一層閉環(huán)的架構(gòu),使得架構(gòu)生態(tài)形成更大的協(xié)調(diào)統(tǒng)一。




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論