 電子發燒友App
電子發燒友App


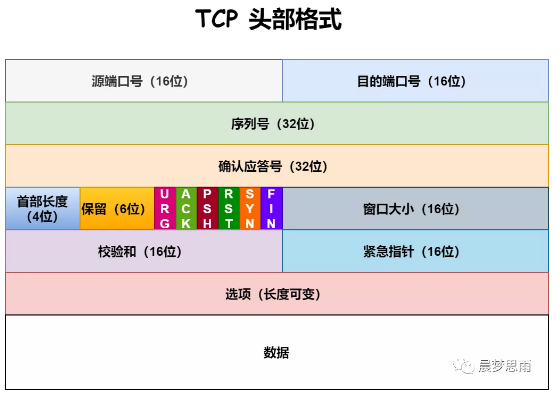
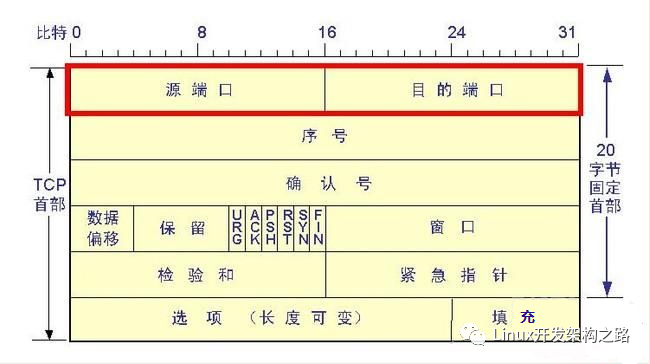
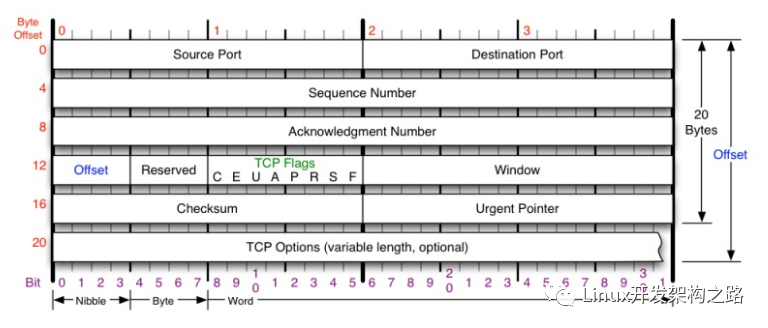
TCP常用命令
了解TCP之前,先了解幾個命令:
linux查看tcp的狀態命令:
1)、netstat -nat 查看TCP各個狀態的數量
2)、lsof -i:port 可以檢測到打開套接字的狀況
3)、 sar -n SOCK 查看tcp創建的連接數
4)、tcpdump -iany tcp port 9000 對tcp端口為9000的進行抓包
網絡測試常用命令;
1)ping:檢測網絡連接的正常與否,主要是測試延時、抖動、丟包率。
但是很多服務器為了防止攻擊,一般會關閉對ping的響應。所以ping一般作為測試連通性使用。ping命令后,會接收到對方發送的回饋信息,其中記錄著對方的IP地址和TTL。TTL是該字段指定IP包被路由器丟棄之前允許通過的最大網段數量。TTL是IPv4包頭的一個8 bit字段。例如IP包在服務器中發送前設置的TTL是64,你使用ping命令后,得到服務器反饋的信息,其中的TTL為56,說明途中一共經過了8道路由器的轉發,每經過一個路由,TTL減1。
2)traceroute:raceroute 跟蹤數據包到達網絡主機所經過的路由工具
traceroute hostname
3)pathping:是一個路由跟蹤工具,它將 ping 和 tracert 命令的功能與這兩個工具所不提供的其他信息結合起來,綜合了二者的功能
pathping www.baidu.com
4)mtr:以結合ping nslookup tracert 來判斷網絡的相關特性
5) nslookup:用于解析域名,一般用來檢測本機的DNS設置是否配置正確。
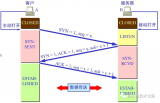
? ? ?TCP狀態分析
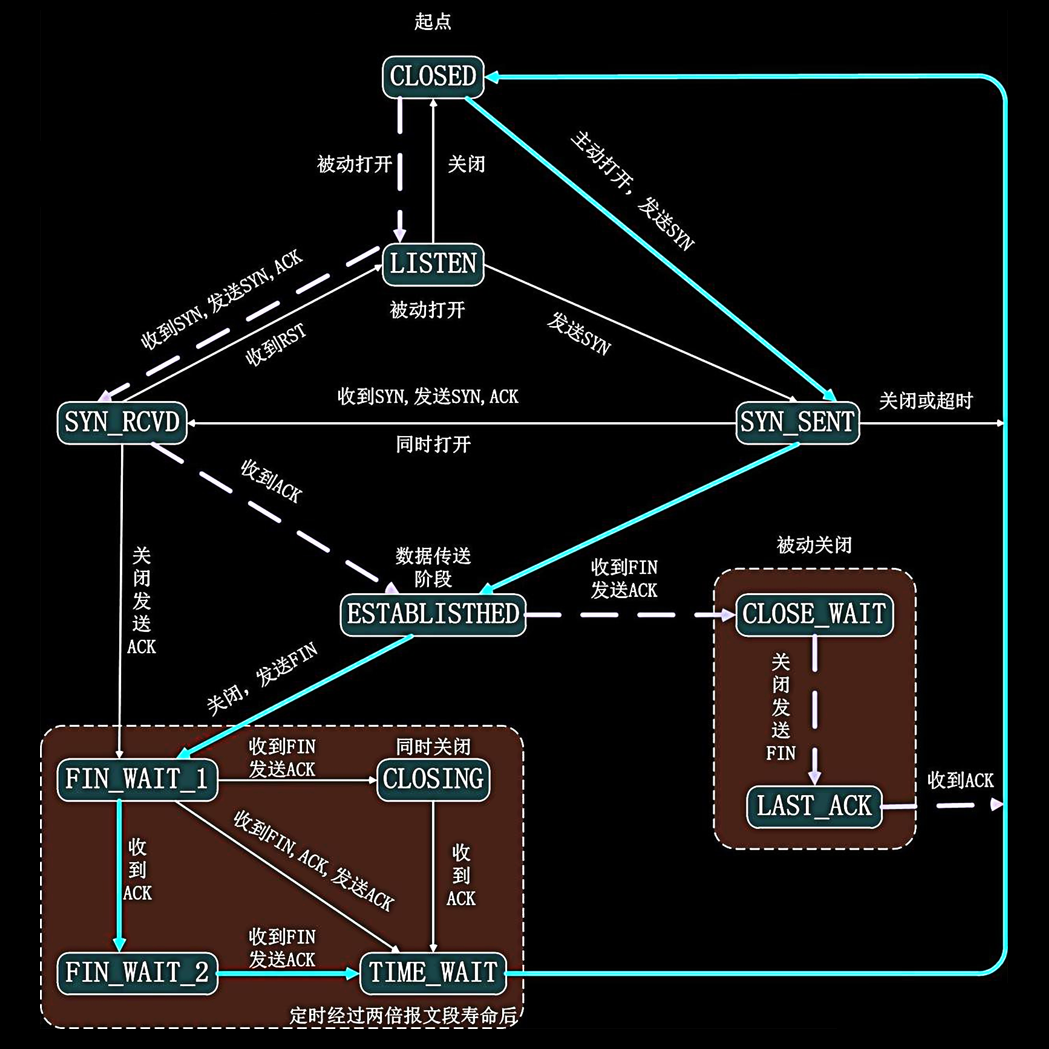
LISTENING:偵聽來自遠方的TCP端口的連接請求。
首先服務端需要打開一個socket進行監聽,狀態為LISTEN。
有提供某種服務才會處于LISTENING狀態,TCP狀態變化就是某個端口的狀態變化,提供一個服務就打開一個端口,例如:提供www服務默認開的是80端口,提供ftp服務默認的端口為21,當提供的服務沒有被連接時就處于LISTENING狀態。FTP服務啟動后首先處于偵聽(LISTENING)狀態。處于偵聽LISTENING狀態時,該端口是開放的,等待連接,但還沒有被連接。就像你房子的門已經敞開的,但還沒有人進來。
看LISTENING狀態最主要的是看本機開了哪些端口,這些端口都是哪個程序開的,關閉不必要的端口是保證安全的一個非常重要的方面,服務端口都對應一個服務(應用程序),停止該服務就關閉了該端口,例如要關閉21端口只要停止IIS服務中的FTP服務即可。關于這方面的知識請參閱其它文章。
如果你不幸中了服務端口的木馬,木馬也開個端口處于LISTENING狀態。
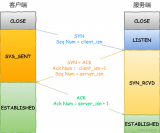
SYN-SENT:客戶端SYN_SENT狀態:
再發送連接請求后等待匹配的連接請求:客戶端通過應用程序調用connect進行active open.于是客戶端tcp發送一個SYN以請求建立一個連接。之后狀態置為SYN_SENT. /*The socket is actively attempting to establish a connection. 在發送連接請求后等待匹配的連接請求 */
當請求連接時客戶端首先要發送同步信號給要訪問的機器,此時狀態為SYN_SENT,如果連接成功了就變為ESTABLISHED,正常情況下SYN_SENT狀態非常短暫。例如要訪問網站http://www.baidu.com,如果是正常連接的話,用TCPView觀察IEXPLORE.EXE(IE)建立的連接會發現很快從SYN_SENT變為ESTABLISHED,表示連接成功。SYN_SENT狀態快的也許看不到。
如果發現有很多SYN_SENT出現,那一般有這么幾種情況,一是你要訪問的網站不存在或線路不好,二是用掃描軟件掃描一個網段的機器,也會出出現很多SYN_SENT,另外就是可能中了病毒了,例如中了“沖擊波”,病毒發作時會掃描其它機器,這樣會有很多SYN_SENT出現。
SYN-RECEIVED:服務器端狀態SYN_RCVD
再收到和發送一個連接請求后等待對方對連接請求的確認
當服務器收到客戶端發送的同步信號時,將標志位ACK和SYN置1發送給客戶端,此時服務器端處于SYN_RCVD狀態,如果連接成功了就變為ESTABLISHED,正常情況下SYN_RCVD狀態非常短暫。
如果發現有很多SYN_RCVD狀態,那你的機器有可能被SYN Flood的DoS(拒絕服務攻擊)攻擊了。
SYN Flood的攻擊原理是:
在進行三次握手時,攻擊軟件向被攻擊的服務器發送SYN連接請求(握手的第一步),但是這個地址是偽造的,如攻擊軟件隨機偽造了51.133.163.104、65.158.99.152等等地址。服務器在收到連接請求時將標志位ACK和SYN置1發送給客戶端(握手的第二步),但是這些客戶端的IP地址都是偽造的,服務器根本找不到客戶機,也就是說握手的第三步不可能完成。
這種情況下服務器端一般會重試(再次發送SYN+ACK給客戶端)并等待一段時間后丟棄這個未完成的連接,這段時間的長度我們稱為SYN Timeout,一般來說這個時間是分鐘的數量級(大約為30秒-2分鐘);一個用戶出現異常導致服務器的一個線程等待1分鐘并不是什么很大的問題,但如果有一個惡意的攻擊者大量模擬這種情況,服務器端將為了維護一個非常大的半連接列表而消耗非常多的資源----數以萬計的半連接,即使是簡單的保存并遍歷也會消耗非常多的CPU時間和內存,何況還要不斷對這個列表中的IP進行SYN+ACK的重試。此時從正常客戶的角度看來,服務器失去響應,這種情況我們稱做:服務器端受到了SYN Flood攻擊(SYN洪水攻擊)
ESTABLISHED:代表一個打開的連接。
ESTABLISHED狀態是表示兩臺機器正在傳輸數據,觀察這個狀態最主要的就是看哪個程序正在處于ESTABLISHED狀態。
服務器出現很多ESTABLISHED狀態: netstat -nat |grep 9502或者使用lsof -i:9502可以檢測到。
當客戶端未主動close的時候就斷開連接:即客戶端發送的FIN丟失或未發送。
這時候若客戶端斷開的時候發送了FIN包,則服務端將會處于CLOSE_WAIT狀態;
這時候若客戶端斷開的時候未發送FIN包,則服務端處還是顯示ESTABLISHED狀態;
結果客戶端重新連接服務器。
而新連接上來的客戶端(也就是剛才斷掉的重新連上來了)在服務端肯定是ESTABLISHED; 如果客戶端重復的上演這種情況,那么服務端將會出現大量的假的ESTABLISHED連接和CLOSE_WAIT連接。
最終結果就是新的其他客戶端無法連接上來,但是利用netstat還是能看到一條連接已經建立,并顯示ESTABLISHED,但始終無法進入程序代碼。
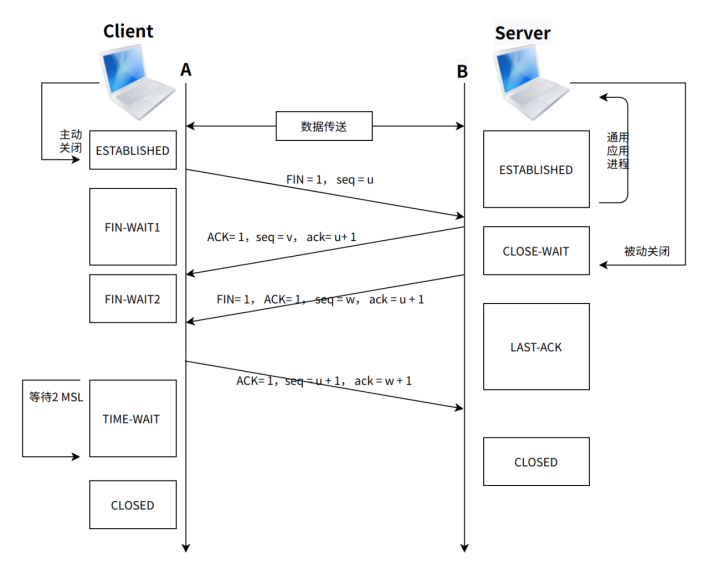
FIN-WAIT-1:等待遠程TCP連接中斷請求,或先前的連接中斷請求的確認
主動關閉(active close)端應用程序調用close,于是其TCP發出FIN請求主動關閉連接,之后進入FIN_WAIT1狀態。/* The socket is closed, and the connection is shutting down. 等待遠程TCP的連接中斷請求,或先前的連接中斷請求的確認 */
如果服務器出現shutdown再重啟,使用netstat -nat查看,就會看到很多FIN-WAIT-1的狀態。就是因為服務器當前有很多客戶端連接,直接關閉服務器后,無法接收到客戶端的ACK。
FIN-WAIT-2:從遠程TCP等待連接中斷請求
主動關閉端接到ACK后,就進入了FIN-WAIT-2 。/* Connection is closed, and the socket is waiting for a shutdown from the remote end. 從遠程TCP等待連接中斷請求 */
這就是著名的半關閉的狀態了,這是在關閉連接時,客戶端和服務器兩次握手之后的狀態。在這個狀態下,應用程序還有接受數據的能力,但是已經無法發送數據,但是也有一種可能是,客戶端一直處于FIN_WAIT_2狀態,而服務器則一直處于WAIT_CLOSE狀態,而直到應用層來決定關閉這個狀態。
CLOSE-WAIT:等待從本地用戶發來的連接中斷請求
被動關閉(passive close)端TCP接到FIN后,就發出ACK以回應FIN請求(它的接收也作為文件結束符傳遞給上層應用程序),并進入CLOSE_WAIT. /* The remote end has shut down, waiting for the socket to close. 等待從本地用戶發來的連接中斷請求 */
CLOSING:等待遠程TCP對連接中斷的確認
比較少見。/* Both sockets are shut down but we still don‘t have all our data sent. 等待遠程TCP對連接中斷的確認 */
LAST-ACK:等待原來的發向遠程TCP的連接中斷請求的確認
被動關閉端一段時間后,接收到文件結束符的應用程序將調用CLOSE關閉連接。這導致它的TCP也發送一個 FIN,等待對方的ACK.就進入了LAST-ACK 。 /* The remote end has shut down, and the socket is closed. Waiting for acknowledgement. 等待原來發向遠程TCP的連接中斷請求的確認 */
使用并發壓力測試的時候,突然斷開壓力測試客戶端,服務器會看到很多LAST-ACK。
TIME-WAIT:等待足夠的時間以確保遠程TCP接收到連接中斷請求的確認
在主動關閉端接收到FIN后,TCP就發送ACK包,并進入TIME-WAIT狀態。/* The socket is waiting after close to handle packets still in the network.等待足夠的時間以確保遠程TCP接收到連接中斷請求的確認 */
TIME_WAIT等待狀態,這個狀態又叫做2MSL狀態,說的是在TIME_WAIT2發送了最后一個ACK數據報以后,要進入TIME_WAIT狀態,這個狀態是防止最后一次握手的數據報沒有傳送到對方那里而準備的(注意這不是四次握手,這是第四次握手的保險狀態)。這個狀態在很大程度上保證了雙方都可以正常結束,但是,問題也來了。
由于插口的2MSL狀態(插口是IP和端口對的意思,socket),使得應用程序在2MSL時間內是無法再次使用同一個插口的,對于客戶程序還好一些,但是對于服務程序,例如httpd,它總是要使用同一個端口來進行服務,而在2MSL時間內,啟動httpd就會出現錯誤(插口被使用)。為了避免這個錯誤,服務器給出了一個平靜時間的概念,這是說在2MSL時間內,雖然可以重新啟動服務器,但是這個服務器還是要平靜的等待2MSL時間的過去才能進行下一次連接。
CLOSED:沒有任何連接狀態
被動關閉端在接受到ACK包后,就進入了closed的狀態。連接結束。/* The socket is not being used. 沒有任何連接狀態 */
TCP 連接斷鏈分析
在官方的正式文檔中,TCP/IP 協議簇也稱為國際互聯網協議簇。TCP/IP 協議簇是目前使用最為廣泛的全球互聯網技術,其分層結構如圖 1 所示:
圖 1. TCP/IP 協議簇分層結構
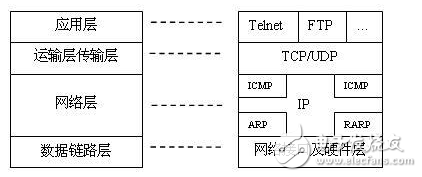
如圖 1 所示,數據鏈路層主要負責處理傳輸媒介等眾多的物理接口細節;網絡層負責處理數據分組在網絡中的活動,包括上層數據報文的分割、選路 phost2008-08-21T00:00:00 等;傳輸層則負責為兩臺主機提供端到端的通信;應用層將負責處理應用程序的特定細節。其中,IP 協議是網絡層的核心協議,用來提供不可靠、無連接的數據傳遞服務;而 TCP 協議則處于傳輸層,其基于不可靠無連接的 IP 協議能夠為兩臺主機提供面向連接的、可靠的通信。UDP?
由于 TCP 是面向連接的協議,因此在兩臺主機通信之前,需要首先建立起一條連接。下面我們將簡要介紹 TCP 連接的建立以及通信雙方是如何保持已建立的 TCP 連接的。
TCP 連接的建立及保持
一個 TCP 連接的建立需要通過著名的“三次握手”來完成。下面的例子將直觀給出一個 TCP 連接的建立過程。
在本文的下述描述中,客戶端主機均為 testClient.cn.ibm.com(Linux),服務器主機均為 testServer.cn.ibm.com(AIX)。在 testClient 主機的一終端上執行 tcpdump –i eth0 host testServer 命令,啟動 tcpdump 監聽網絡數據(其中,eth0 是客戶主機與外部網絡進行通信所使用的網卡);與此同時,在客戶主機的另一個終端上執行下述命令: (root@testClient /)》telnet testServer。此時客戶主機上 tcpdump 的輸出如清單 1 所示。
清單 1. 創建一個 TCP 連接的三次握手
# tcpdump –S -i en0 host testServer
1 14:02:38.384918 IP testClient.cn.ibm.com.43370 》
testServer.cn.ibm.com.telnet: S 3392458353:3392458353(0) …
2 14:02:38.629578 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.43370: S 881279296:881279296(0) ack 3392458354 …
3 14:02:38.629592 IP testClient.cn.ibm.com.43370 》
testServer.cn.ibm.com.telnet: 。 ack 881279297 …
注意:我們刪除了 tcpdump 輸出結果中的部分無關信息。為了便于理解,我們將上述輸出轉換為實際序列圖 2。
圖 2. TCP 建立創建三次握手的實際序列
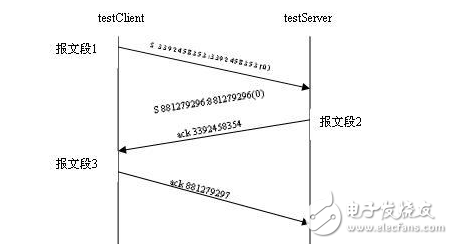
從圖 2 中我們可以清楚地看到,在 testClient 與 testServer 之間建立連接時,要經過以下三次握手過程:
testClient 向 testServer 主動發送握手協議,報文序列號為 3392458353,大小為 1 個字節。
testServer 向 testClient 主動發送握手協議,報文序列號為 881279296,大小為 1 個字節;同時返回 ACK 3392458354,作為對 testClient 發來的 3392458354 包的應答。
testClient 向 testServer 返回 ACK 881279297,作為對 testServer 發來的 881279296 包的應答。
一個 TCP 連接在完成上述的三次握手之后便建立完畢;此后,連接的兩端即可進行信息的相互傳遞。因此,TCP 連接可以認為是以兩端 IP 地址和端口進行標識的一個通信信道,而 TCP 連接的建立就是向通信雙方進行上述通信信道注冊的過程。TCP 連接一旦建立,只要通信雙方之間的中間結點(包括網關和交換機、路由器等網絡設備)工作正常,那么在通信雙方中的任何一方主動關閉連接之前,TCP 連接都將被一直保持下去。
TCP 連接的這種特性,使得一個長期不交換任何信息的空閑連接可以長期保持數小時、數天甚至數月。中間路由器可以崩潰、重啟,網線可以被掛斷再連通,只要兩端的主機沒有被重啟,TCP 連接就可以被一直保持下來。
導致 TCP 連接斷連的因素
理想狀態下,一個 TCP 連接可以被長期保持。然而,在實際應用中,客戶端或服務器端上維持的一個看似正常的 TCP 連接可能已經斷連。TCP 連接主要受到兩個方面的影響而導致斷連:網絡中間節點和客戶端 / 服務器節點參與通信的兩方節點?
在實際網絡應用中,兩個主機之間的通信往往需要穿越多個中間節點,例如路由器、網關、防火墻等。因此,兩個主機之間 TCP 連接的保持同樣會受到中間節點的影響,尤其是會受到防火墻(軟件或硬件防火墻)的限制。防火墻是一種裝置,有多種不同的實現方式(軟件實現、硬件設備實現 或是軟硬件相結合實現),它需要依據一系列規則對進出的信息流進行掃描,并允許安全(符合規則)的信息交互、阻止不安全(違反規則)的信息交互。防火墻的 工作特性決定了要維護一個網絡連接就需要耗費較多的資源,并且企業防火墻常常位于企業網絡的出入口,長時間維護非活躍的 TCP 連接必將導致網絡性能的下降。因此,大部分防火墻默認會關閉長時間處于非活躍狀態的連接而導致 TCP 連接斷連。類似的,如果中間節點異常導致來自客戶端關閉連接的請求無法傳遞到服務器端,也將導致服務器端的相應連接發生斷連。
另一方面,對于一個 TCP 連接兩端的主機而言,創建 TCP 連接需要耗費一定的系統資源。如果不再使用某個連接,那么我們總是希望進行通信的兩個主機能夠主動關閉相應的連接,以便釋放所占用的系統資源。然而,如果 由于客戶端出現異常 ( 例如崩潰或異常重啟 ) 而導致連接未能正常關閉,這將導致服務器端的連接斷連。
無論是客戶端節點或是服務器端節點,斷連的 TCP 連接已經不能傳遞任何信息,因此,維護大量斷連的 TCP 連接將導致系統資源的浪費。這種系統資源的浪費可能并不會對客戶端節點帶來太大問題;然而,對于服務器主機而言,這可能會導致系統資源(尤指內存資源和 socket 資源)被耗盡而拒絕為新的用戶請求提供服務。因此在實際應用中,服務器端需要采取相應的方法來探測 TCP 連接是否已經斷連。
探測 TCP 連接斷連的三種常用方法
探測 TCP 連接是否斷連或是工作正常的原理比較簡單:定期向連接的遠程通信節點發送一定格式的信息并等待遠程通信節點的反饋,如果在規定時間內收到來自遠程節點的正 確的反饋信息,那么該連接就是正常的,否則該連接已經斷連。依據該原理,目前常用的探測方法有以下三種。
應用程序的自我探測
應用程序本身附帶探測其自身建立的 TCP 連接的功能。這種方法具有極大的靈活性,可以依據應用本身的特點選擇相應的探測機制和功能實現。然而,實際應用中,大部分應用程序均沒有附帶自我探測的功能。
第三方應用程序的探測
此種方法就是在服務節點上安裝相應的第三方應用程序來探測該節點上所有的 TCP 連接是否正常或是已經斷連。該方法最大的不足就是需要所有支持探測的客戶端能夠識別來自該探測應用的數據報文,因此,實際應用中比較少見。
TCP 協議層的保活探測
最常用的探測方法就是采用 TCP 協議層提供的保活探測功能即 TCP 連接保活定時器。盡管該功能并不是 RFC 規范的一部分,但是幾乎所有的類 Unix 系統均實現了該功能,所以使得該探測方法被廣泛使用。
接下來的部分,我們將重點討論來自 TCP 協議層的保活探測方法。
類 Unix 系統上的 TCP 連接保活定時器
TCP 連接的保活定時器可以在應用層實現,也可以在 TCP 中提供。這個問題存在爭議,因此 TCP 連接的保活探測并不是 TCP 規范中的一部分。但為了方便,幾乎所有類 Unix 系統均在 TCP 中提供了相應的功能。
清單 2. 常見 Unix 系統上的保活定時器
操作系統 保活定時器
AIX# no -a | grep keep
tcp_keepcnt = 8
tcp_keepidle = 14400
tcp_keepintvl = 150
Linux# sysctl -A | grep keep
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 7200
FreeBSD#sysctl -A | grep net.inet.tcp
net.inet.tcp.keepidle=…
net.inet.tcp.keepintvl=…
不同系統上的各參數的時間單位不盡相同。在 AIX 上,tcp_keeidle/tcp_keepinit/tcp_keepintvl 的時間單位是 0.5 秒;而在 Linux 上,net.ipv4.tcp_keepalive_intvl 和 net.ipv4.tcp_keepalive_time 的時間單位則為秒。并且,上述參數僅對運行在其上的服務器應用連接有效。
注:在 Solaris 上可通過“ndd /dev/tcp \?”命令顯示上述類似參數信息,而在 HP Unix 上則可通過 nettune 或 ndd 命令進行查詢。
由于所有類 Unix 系統上均支持這種功能,因此,在接下來的部分中我們將基于 AIX 系統具體講述上述參數的意義和作用機制。
AIX 中的 TCP 連接保活探測機制及原理
正如清單 2 中列出的一樣,AIX 上的保活探測機制由 4 個參數來控制,其具體意義見清單 3:
清單 3. AIX 上的保活定時器控制參數
控制參數 參數說明
tcp_keepcnt關閉一個非活躍連接之前進行探測的最大次數,默認為 8 次
tcp_keepidle對一個連接進行有效性探測之前運行的最大非活躍時間間隔,默認值為 14400(即 2 個小時)
tcp_keepintvl兩個探測的時間間隔,默認值為 150 即 75 秒
我們來看一個具體的例子。在 testServer 端(AIX 主機)采用 tcp_keepidel=240(即 2 分鐘):tcp_keepcnt=8:tcp_keepintvl=150(即 75 秒)的參數值;啟動 testServer 上的 tcpdump 查看網絡包的交互情況;從 testClient 端發起請求建立和 testServer 之間的一個 telnet 連接。在連接建立完成之后,拔出 testClient 端的網線并觀察服務器端的數據輸出(見清單 4)。
清單 4. telnet 連接在服務器端的 tcpdump 輸出
1 # tcpdump -i en1 host testServer.cn.ibm.com
2 04:51:51.379716 IP testClient.cn.ibm.com.telnet.40621 》
testServer.cn.ibm.com.telnet: S 4097149880:4097149880(0)
3 04:51:51.379755 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: S 2543529892:2543529892(0) ack 4097149881
4 04:51:51.380609 IP testClient.cn.ibm.com.telnet.40621 》
testServer.cn.ibm.com.telnet: 。 ack 1
5 。。。
6 04:51:54.924058 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: P 676:696(20) ack 87
7 04:51:54.924909 IP testClient.cn.ibm.com.telnet.40621 》
testServer.cn.ibm.com.telnet: 。 ack 696
8 04:53:54.550192 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
9 04:55:09.550997 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
10 04:56:24.552053 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
11 04:57:39.552615 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
12 04:58:54.553446 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
13 05:00:09.554287 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
14 05:01:24.555117 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
15 05:02:39.555958 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
16 05:03:54.557282 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: 。 695:696(1) ack 86
17 05:05:09.559795 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.40621: R 696:696(0) ack 87
從清單 4 中可以看出,第 6 行的報文是本連接發送的最后數據,而第 7 行則是對第 6 行數據的確認。其后,該連接上沒有任何數據交互,從而使得該連接一直處于非活躍狀態。經過 2 分鐘(第 8 行數據報時間 04:53:54 和第 7 行數據報時間 04:51:54 之差,即 tcp_keepidle 的值)的非活躍時間后,第 8 行是服務器端發起第一個保活探測數據報。由于服務器端沒有收到客戶端關于探測報文的相應,因此再經過 tcp_keepintvl 的時間間隔(75 秒)之后,第 9 行顯示服務器端再次發起保活探測數據報。服務器端持續發送了 tcp_keepcnt 個探測報文(上面結果顯示,在 AIX 上是持續發送 tcp_keepcnt+1 個探測報文)之后,仍然沒有收到來自客戶端的任何回應,所以服務器在第 17 行向客戶端發送復位報文同時在服務器端關閉了該連接。
需要注意的是,保活探測雖然通過發送 TCP 探測報文,但探測報文不會對正常的 TCP 連接產生任何影響。從清單 4 可以看出,第 8 行發送數據的 TCP 報文序號為 695 起始的 1Byte 數據,而該數據在第 6 行已經發送并被客戶端確認。對于正常狀態的連接,客戶端在收到探測報文之后將返回一個第 7 行所示的 ACK 報文并借此向服務器端表明連接工作正常。
接下來,我們將通過一個實際的 TCP 斷連的例子來分析上述機制對 TCP 連接保持的影響,并針對需要長時間保持 TCP 連接的應用提出兩種可選的解決方案。
AIX 上的 TCP 斷連及數據分析
圖 3. 出現 TCP 斷連的網絡拓撲結構示意圖
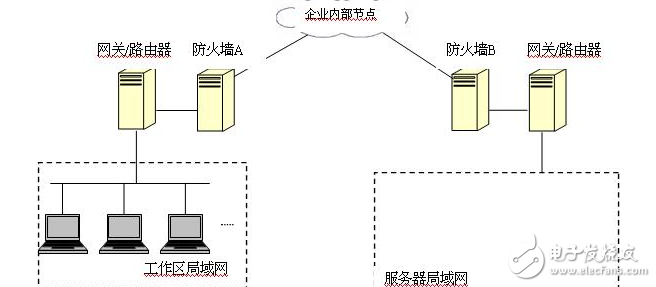
所有服務器主機均劃為一個局域網,并處于防火墻 B 之后。由于工作需要,來自工作區局域網的主機 testClient 需和服務器局域網內的 testServer 上的數據庫使用 TCP/IP 建立一個連接,testClient 上的上層應用將通過該連接對 testServer 上的數據庫進行相應操作。
在實際測試中,我們發現,在 testClient 和 testServer 均工作正常的情況下,testClient 上的客戶端在事先沒有收到任何異常信息的情況下,所持有的連接會出現非預期的斷連現象(在試圖通過連接進行數據庫操作時,會被告知 connection is reset by foreign host 的錯誤)。
由于該現象不斷出現,并且網絡內的中間節點(路由器和交換機等)均工作正常,因此可以排除物理因素(如掉電、宕機等)的可能。為了便于分析斷連原因,我們首先查看了 testServer 機器上的默認保活設置:
# no -a | grep keep
tcp_keepcnt = 8
tcp_keepidle = 14400
tcp_keepintvl = 150
testServer 上的 tcp_keepidle 為 14400,即 2 個小時。既然中間節點工作正常,為什么保活機制沒有其作用呢?為了進行分析,我們采用 tcpdump 工具捕獲 testClient 和 testServer 上的報文信息,見清單 5 和清單 6 所示。
清單 5. 服務器端的 tcpdump 數據輸出
1 10:18:58.881950 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: S 1182666808:1182666808(0) 。。。
2 10:18:58.882001 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.59098: S 3333341833:3333341833(0) ack 1182666809 。。。
3 10:18:58.882845 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: 。 ack 1 。。。
4 。。。
5 10:19:03.165568 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.59098: P 1010:1032(22) ack 87 。。。
6 10:19:03.166457 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: 。 ack 1032 。。。
7 12:19:05.445336 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.59098: 。 1031:1032(1) ack 86 。。。
8 12:19:05.445464 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: R 86:87(1) ack 1031 。。。
清單 6. 客戶端的 tcpdump 數據輸出
1 # tcpdump -e -i eth0 host testServer.cn.ibm.com
2 10:18:55.800553 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: S 1182666808:1182666808(0) 。。。
3 10:18:55.801778 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.59098: S 3333341833:3333341833(0) ack 1182666809 。。。
4 10:18:55.801799 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: 。 ack 1 。。。
5 。。。
6 10:19:00.084662 IP testServer.cn.ibm.com.telnet 》
testClient.cn.ibm.com.59098: P 1010:1032(22) ack 87 。。。
7 10:19:00.084678 IP testClient.cn.ibm.com.59098 》
testServer.cn.ibm.com.telnet: 。 ack 1032 。。。
從清單 5 中可以看出,在該連接處于非活躍狀態的時間達到 tcp_keepidle 設定的 2 小時時,服務器主機發出了第一個連接保活的探測報文(清單 5 中的第 7 行)。緊接著,服務器主機就收到了來自 testClient 的連接復位報文(清單 5 中的第 8 行)。之后,服務器便關閉了該連接(可以通過 netstat –ni 來查看)。然而,從清單 6 的 tcpdump 數據可以看出, testClient 端并未發送任何報文。那么,是誰向 testServer 發送了復位報文呢?
為了查看上述復位報文的發送者,同樣采用上述 tcpdump 命令再次捕獲服務器端和防火墻 B 的報文信息(注意:通常需要捕獲防火墻主機上網絡數據的出口網卡和入口網卡數據),結果顯示,防火墻 B 在收到來自 testServer 的第一個探測報文之后就立刻向 testServer 發送了一個復位報文。
上述分析說明,在連接傳遞完最后一個交互數據之后到服務器端發送第一個保活探測之間,該連接已經被防火墻 B 終止;在此之后,基于該連接的任何報文傳遞在試圖穿過防火墻的時候均會被防火墻丟棄并發送復位報文。
兩種常用的解決方案
針對上述 TCP 斷連現象,有兩種常用的解決方案可供選擇:
方案 1、延長防火墻終止非活躍的 TCP 連接的時間。例如,針對上述案例,可以調節防火墻設置,將時間設置為大于服務器端設定的 2 小時。
方案 2、縮短服務器端的 TCP 連接保活時間。縮短該時間的目的是為了在連接被防火墻終止之前發送保活探測報文,既可以探測客戶端狀態,又可以使連接變為活躍狀態。
對于第一種方案而言,延長 TCP 連接的保持時間可能會導致防火墻性能的降低,尤其是在維持大量長時間處于非活躍狀態的連接的情況下更是如此;而對于第二種方案,如果縮短服務器端的 TCP 連接保活時間,意味著會增加網絡中的數據報文數而占用額外的網絡帶寬。因此,兩種方案各有利弊,需要依據不同的實際應用情況進行選擇。
總結
本文介紹了 TCP 連接的建立和保持的相關概念以及影響 TCP 連接保持的常見因素。給出了常見的類 Unix 系統上 TCP 連接保活探測的相關配置參數,并基于 AIX 借助 tcpdump 工具分析了一個實際的 TCP 斷連的案例。最后,針對 TCP 斷連的情況給出了兩種可行的解決方案。

















 工商網監
工商網監
評論