 機器學習的特征工程是將原始的輸入數據轉換成特征
機器學習的特征工程是將原始的輸入數據轉換成特征
一、簡介
機器學習的特征工程是將原始的輸入數據轉換成特征,以便于更好的表示潛在的問題,并有助于提高預測模型準確性的過程。
找出合適的特征是很困難且耗時的工作,它需要專家知識,而應用機器學習基本也可以理解成特征工程。但是,特征工程對機器學習模型的應用有很大影響,有句俗話叫做“數據和特征決定了機器學習模型的性能上限”。
二、錯誤數據和缺失值
特征工程之前需要對缺失數據和錯誤數據進行處理。錯誤數據可以矯正,有的錯誤是格式錯誤,如日期的格式可能是“2018-09-19”和“20180920”這種混合的,要統一。
缺失數據的處理:
去掉所在行/列
取均值
中位數
眾數
使用算法預測
三、特征的種類
機器學習的輸入特征包括幾種:
數值特征:包括整形、浮點型等,可以有順序意義,或者無序數據。
分類特征:如ID、性別等。
時間特征:時間序列如月份、年份、季度、日期、小時等。
空間特征:經緯度等,可以轉換成郵編,城市等。
文本特征:文檔,自然語言,語句等,這里暫時不介紹處理。
四、特征工程技巧
4.1、分箱(Binning)
數據分箱(Binning)是一種數據預處理技術,用于減少輕微觀察錯誤的影響。落入給定小間隔bin的原始數據值由代表該間隔的值(通常是中心值)代替。這是一種量化形式。 統計數據分箱是一種將多個或多或少連續值分組為較少數量的“分箱”的方法。例如,如果您有關于一組人的數據,您可能希望將他們的年齡安排到較小的年齡間隔。對于一些時間數據可以進行分箱操作,例如一天24小時可以分成早晨[5,8),上午[8,11),中午[11,14),下午[14,19),夜晚[10,22),深夜[19,24)和[24,5)。因為比如中午11點和12點其實沒有很大區別,可以使用分箱技巧處理之后可以減少這些“誤差”。
4.2、獨熱編碼(One-Hot Encoding)
獨熱編碼(One-Hot Encoding)是一種數據預處理技巧,它可以把類別數據變成長度相同的特征。例如,人的性別分成男女,每一個人的記錄只有男或者女,那么我們可以創建一個維度為2的特征,如果是男,則用(1,0)表示,如果是女,則用(0,1)。即創建一個維度為類別總數的向量,把某個記錄的值對應的維度記為1,其他記為0即可。對于類別不多的分類變量,可以采用獨熱編碼。
4.3、特征哈希(Hashing Trick)
對于類別數量很多的分類變量可以采用特征哈希(Hashing Trick),特征哈希的目標就是將一個數據點轉換成一個向量。利用的是哈希函數將原始數據轉換成指定范圍內的散列值,相比較獨熱模型具有很多優點,如支持在線學習,維度減小很多燈。具體參考數據特征處理之特征哈希(Feature Hashing)。
4.4、嵌套法(Embedding)
嵌套法(Embedding)是使用神經網絡的方法來將原始輸入數據轉換成新特征,嵌入實際上是根據您想要實現的任務將您的特征投影到更高維度的空間,因此在嵌入空間中,或多或少相似的特征在它們之間具有小的距離。 這允許分類器更好地以更全面的方式學習表示。例如,word embedding就是將單個單詞映射成維度是幾百維甚至幾千維的向量,在進行文檔分類等,原本具有語義相似性的單詞映射之后的向量之間的距離也比較小,進而可以幫助我們進一步進行機器學習的應用,這一點比獨熱模型好很多。
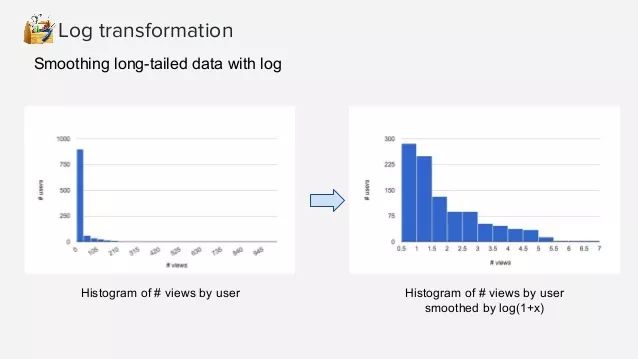
4.5、取對數(Log Transformation)
取對數就是指對數值做log轉換,可以將范圍很大的數值轉換成范圍較小的區間中。Log轉換對分布的形狀有很大的影響,它通常用于減少右偏度,使得最終的分布形狀更加對稱一些。它不能應用于零值或負值。對數刻度上的一個單位表示乘以所用對數的乘數。在某些機器學習的模型中,對特征做對數轉換可以將某些連乘變成求和,更加簡單,這不屬于這部分范圍了。
如前所述,log轉換可以將范圍很大的值縮小在一定范圍內,這對某些異常值的處理也很有效,例如用戶查看的網頁數量是一個長尾分布,一個用戶在短時間內查看了500個和1000個頁面都可能屬于異常值,其行為可能差別也沒那么大,那么使用log轉換也能體現這種結果。
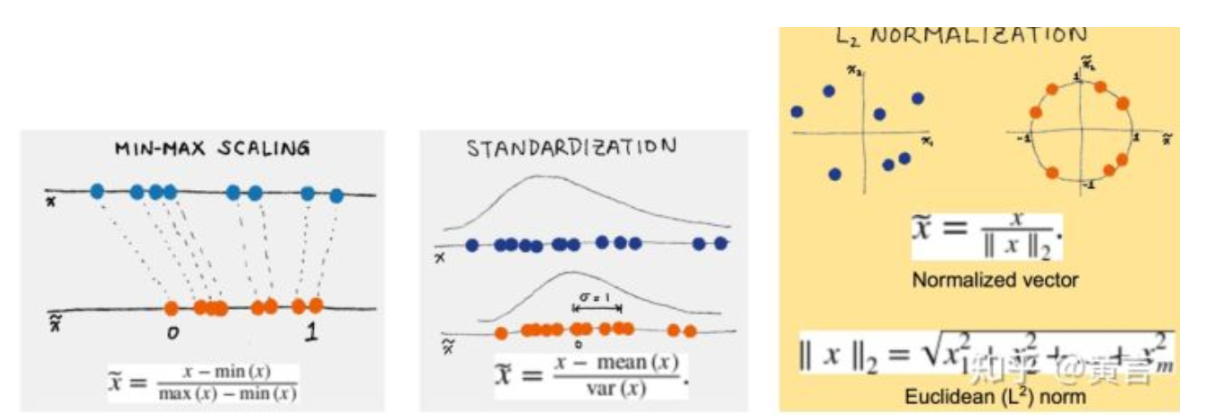
4.6、特征縮放(Scaling)
特征縮放是一種用于標準化獨立變量或數據特征范圍的方法。 在數據處理中,它也稱為數據標準化,并且通常在數據預處理步驟期間執行。特征縮放可以將很大范圍的數據限定在指定范圍內。由于原始數據的值范圍變化很大,在一些機器學習算法中,如果沒有標準化,目標函數將無法正常工作。例如,大多數分類器按歐幾里德距離計算兩點之間的距離。 如果其中一個要素具有寬范圍的值,則距離將受此特定要素的控制。因此,應對所有特征的范圍進行歸一化,以使每個特征大致與最終距離成比例。
應用特征縮放的另一個原因是梯度下降與特征縮放比沒有它時收斂得快得多。
特征縮放主要包括兩種:
最大最小縮放(Min-max Scaling)
標準化縮放(Standard(Z) Scaling)
4.7、標準化(Normalization)
在最簡單的情況下,標準化意味著將在不同尺度上測量的值調整到概念上的共同尺度。在更復雜的情況下,標準化可以指更復雜的調整,其中意圖是使調整值的整個概率分布對齊。在一般情況下,可能有意將分布與正態分布對齊。
在統計學的另一種用法中,標準化上將不同單位的數值轉換到可以互相比較的范圍內,避免總量大小的影響。標準化后的數據對于某些優化算法如梯度下降等也很重要。
在回歸模型中加入交互項是一種非常常見的處理方式。它可以極大的拓展回歸模型對變量之間的依賴的解釋。具體參見回歸模型中的交互項簡介(Interactions in Regression)。
五、時間特征處理
幾乎所有的時間特征都要處理,時間特征有序列性,其順序有意義。這里簡單列舉幾種處理方式。
5.1、分箱法
這是最常用的方法,如前面所述。有時候11點與12點之間差別并沒有意義,可以采用上述分箱法處理。
5.2、趨勢線(Treadlines)
多使用趨勢量而不是總量來編碼,例如使用上個星期花銷,上個月花銷,去年的花銷,而不是總花銷。兩個總花銷相同的客戶可能在消費行為上有很大差別。
5.3、事件貼近(Closeness to major events)
假日之前幾天,每個月第一個周六等。這種重要時間節點附近的值可能更有意義。
5.4、時間差(Time Difference)
上次用戶交互的時間到這次用戶交互時間間隔,這種時間差別意義也很大。
-
神經網絡
+關注
關注
42文章
4717瀏覽量
99990 -
機器學習
+關注
關注
66文章
8306瀏覽量
131838 -
數據預處理
+關注
關注
1文章
18瀏覽量
2728
原文標題:機器學習:特征工程相關技術簡介
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦









 工商網監
工商網監
評論