 電子發燒友App
電子發燒友App


與傳統ASIC相比,FPGA和結構化ASIC的優勢在于重用靈活性高、上市時間快、性能佳而成本低。FPGA和專用的IP模塊可用于現有的商用AdvancedTCA平臺,可用來開發可擴展的交換接口控制器(FIC),以加快產品開發的設計并使線卡方案具有魯棒性和成本效益。
當今通信和計算系統制造商正在基于模塊化系統架構設計下一代平臺,以縮短開發周期、降低新設備的資本開支,并在增加新功能和服務時最大限度地減少運營費用。模塊化平臺使設備制造商能夠在一套通用的構建模塊上設計多種類型的系統,從而通過實現一定的規模經濟效應保持競爭力。

圖1:一個SPI4.2到ASI交換接口控制器的功能圖。左邊是SPI4.2到NPU的接口,右邊是ASI到交換結構的連接。
實現模塊化的必不可少的一步是使設備制造商共同創建一組用于電路板和機架的通用物理互連標準。AdvancedTCA就是由PCI工業計算機制造商組織(PICMG)定義的一種系統構造參數,它為諸如機架尺寸、線卡、I/O模塊、交換接口(星狀和網狀結構拓撲)、額定功率等等平臺單元提供了標準規范。AdvancedTCA標準的主要目標是提供一個基于標準的硬件平臺,這個硬件平臺由機架和存儲刀片、網絡處理器卡、控制平面刀片,以及管理模塊的組合來構建模塊化運營級產品,這些產品針對電信接入匯聚平臺和邊緣平臺應用。
AdvancedTCA背板接口的工業標準集的定義,使系統集成商在他們的交換接口卡和線卡之間互連具有更大的靈活性和互操作性。AdvancedTCA網絡接口采用開放的接口協議,并采用子規范PICMG 3.1-3.5提供可互操作的電路板。這些子規范支持以太網、光纖通道、Infiniband、PCI Express、StarFabric、高級交換互連(ASI)和串行RapidIO。一些大型OEM向AdvancedTCA規范的轉移標志著從定制、專有的和基于互連的平臺向基于開放標準的COTS平臺轉移。
PCI Express和ASI
系統可擴展性和模塊化需要通用互連以支持多種應用中芯片和/或子系統的無縫集成。隨著背板性能從40Gbps提升到160甚至320Gbps,必須仔細設計以確保交換結構和數據流源頭之間的接口不會出現傳輸瓶頸。交換接口必須在支持關鍵的結構需求,諸如數據吞吐、流控制和按流排隊的同時,以良好的信號完整性高效地傳輸2.5Gbps到超過10Gbps的數據流。

圖2:包含ASI報頭、可選的PI0和PI1報頭及一個PI2報頭的TLP。
PCI Express和ASI是兩種標準的交換結構技術,它們有潛力使標準、最新的交換設備和交換接口器件的市場急劇增長。PCI Express具有跨越從計算到通信生態系統的制造、技術支持和產品開發的經濟規模。把PCI Express移植到串行互連的好處在于:具有物理和性能上的可擴展性;改善了可靠性;實現了全雙工傳輸;布線和電纜連接更簡單、成本更低。
ASI通過定義兼容的擴展來增強PCI Express,從而解決諸如對等通信的支持、QoS、多播和支持多協議封裝的要求。PCI Express和ASI是互補協議,許多系統兩者都采用以滿足目前尚無法實現的設計要求。隨著新型組幀器、網絡處理單元(NPU)和交換結構采用ASI,有必要將ASI與其它接口規范橋接起來,例如與SPI3、SPI4.2和CSIX橋接。這種橋接功能可以方便地與交換接口控制器集成在一起。
FIC架構:
一個SPI4.2到ASI控制器的功能(圖1)包括:
1. ASI到SPI4.2的雙向橋接,可從2.5Gbps擴展到20Gbps(x1、x4或x8路);
2. 為端點和橋接組裝和分拆ASI事務層數據包(TLP);
3. 支持1到64,000個連接隊列(CQ);
4. 在SPI4.2上支持多達16個通道;
5. 可編程通道映射到SPI4.2;
6. 支持一個可旁路的、三個有序的和一個多播虛擬通道(VC);
7. 可編程最大數據包長度為64到80字節;
8. 鏈路層基于信用量的流控制;


圖3:PI2封裝示例。通過去除SPI4.2協議控制字(PCW)并增加ASI報頭、可選PI0和PI1報頭以及PI2報頭,初始SPI4.2突發數據流被轉換到ASI TLP之中。
9. CRC生成和誤碼校驗;
10. 處理連續的背靠背數據包結束符(EOP);
11. DIP4奇偶位生成和校驗;
12. 狀態通道組幀、DIP2生成和校驗;
13. 狀態同步生成丟失和檢測;
14. 訓練序列生成和檢測;
15. 全同步設計(800Mbps);
16. 與OIF兼容的SPI4階段2;
17. 與ASI-SIG兼容,ASI核心架構規范修訂版1.0。
在SPI4.2到ASI方向,必要時對進入的SPI4.2數據包進行分段,并根據流量類型(單播或多播)和等級映射到VC FIFO緩沖器。用戶在SPI4到VC映射表中對緩沖到SPI4.2接口的通道映射信息進行編程,接口上的數據包按照表中所示傳輸到相應的緩沖器。ASI調度器讀取隊列并將TLP發送到交換結構。
每一個SPI4.2通道FIFO緩沖器的填充水平被轉換為“空虛-未滿-飽滿”狀態,并通過接收狀態通道(RSTAT)發送到對等的SPI4.2發送器。當有空間時,在SPI4.2接口上接收的數據包被傳輸到相應的VC FIFO緩沖器。
SPI4.2和每一個VC支持最多16個通道(通道0到15)。下面是從SPI4.2到VC的示范通道分配:
1. SPI4.2通道0到7被映射為8個可旁路虛擬通道(BVC);
2. SPI4.2通道8到11被映射為4個有序虛擬通道(OVC);
3. SPI4.2通道12到15被映射為4個多播虛擬通道(MVC)。
ASI到SPI4.2的輸出數據包流
在ASI到SPI4.2方向,采用可編程地址映射表(圖2),從指定VC的交換結構輸出的ASI TLP和流量等級被映射到16個SPI4.2通道中的一個。用戶在VC到SPI4表中對VC到SPI4.2接口的通道映射信息進行編程。數據復用(MUX)記錄表RAM(VCS4記錄表RAM)包含從VC接口FIFO緩沖器讀數據到把數據傳送至SPI4.2接口的調度。VCS4記錄表RAM有16個位置。
VCS4數據MUX和地址映射模塊根據VCS4記錄表RAM規定的順序從VC FIFO通道讀數據。SPI4.2源模塊在必要時分拆隊列并重組數據包,增加SPI4.2有效載荷控制操作,并通過SPI4.2接口將它們發往NPU。SPI4.2源模塊也執行信用量管理,并根據從對等的SPI4.2接收器收到的流控制信息進行調度。
ASI提供若干協議接口(PI),它們提供可選功能或使各種協議適配到ASI基礎架構。
協議接口描述
PI0封裝被用于多播路由。為0的第二個PI表示生成樹數據包,非0的第二個PI表示多播路由,多播組尋址通過多播組索引字段實現。
PI1將連接隊列識別信息傳遞到下游對等交換單元或端點。當發生擁塞時,下游對等交換單元可以發送識別上游對等交換單元的違規連接隊列的PI5擁塞管理消息。
PI2提供分段和重組(SAR)服務及封裝。PI2報頭包含有利于數據包描述的包起始(SOP)和包結束(EOP)信息。此外,PI2封裝規定了可以在PI2容器內排列有效載荷數據的可選前置塊(PPD)和末塊(EPD)字節。
如果SPI4.2突發數據包長度與ASI TLP有效載荷長度相等的話(圖3),PI2封裝可以用于描述數據包并將數據流映射到關聯域(Context)。此時,所接收到的SPI4.2突發數據已經被分段為ASI接口支持的有效載荷長度。因此,以數據包描述的觀點來看,PI2僅僅需要表示SOP和EOP。
對于中間的突發數據,PI2 SAR代碼就是“居中的”。注意,由于非EOP SPI4.2突發數據必須是多個16字節,所以中間數據包SPI4.2有效載荷將始終是32位排列,與ASI有效載荷匹配。
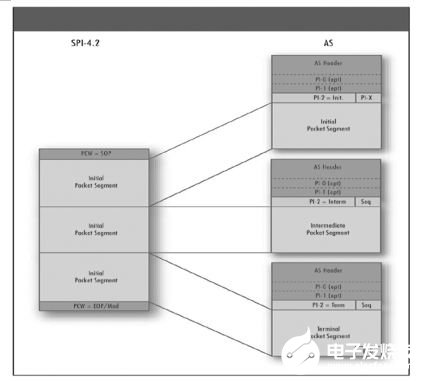
圖4:在PI2分段的例子中,SPI4.2數據包被分為三個ASI TLP,去掉了SPI4.2協議控制字,對于每一個TLP,ASI報頭要加上可選的PI0和PI1報頭及PI2報頭。
對于終端突發數據,如果在最后的TLP字中的所有字節都有效或與末塊終接(terminal with end pad),則PI2 SAR代碼就是“終端”,來表示最后的字中有效字節的數目。
如果SPI4.2突發數據包長度超過ASI TLP有效載荷長度的話,PI2 SAR被用于將SPI4.2數據包分段和重組。接收到的SPI4.2突發數據包在橋接中被分段為ASI接口支持的有效載荷的長度(圖4)。
至于封裝,三個TLP的PI2 SAR代碼被分別設置為代表“初始”、“中間”和“終止”或“末塊終接”。對于重組,來自每一個關聯域的AS片段被重組成完整的數據包。一旦獲得完整的數據包,它就被映射到一個SPI4.2通道并在突發數據包中輸出。來自SPI4.2不同通道的突發數據包可以交織在一起。
映射流量類型、等級和目的端口
交換接口必須與數據一起傳輸若干重要屬性。這些屬性包括流量類型(單播或多播)、等級、目的端口和擁塞管理。這些參數都在AS中得到支持。然而,在SPI4.2中,該信息被映射在SPI4.2通道編號中或SPI4.2有效載荷內的專有報頭。
SPI4.2利用三級擁塞指示(空虛、未滿、飽滿)進行基于信用量的流控制。通過預置與空虛和未滿狀態相對應的最大突發數據量(Maxburst1和Maxburst2),發送器會再次裝滿信用量。
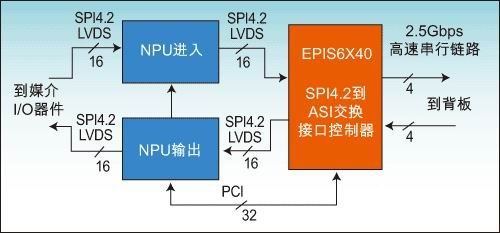
圖5:典型單10Gbps端口中的雙網絡處理器及配備專用FIC的全雙工線卡。
ASI具有多個流控制選項:VC,它是一個基于信用量的流控制;用于源速率控制的令牌桶;按照類或者流隊列的基于狀態的流控制。
橋接內的擁塞管理是橋接架構和緩沖機制的不可缺少的組成部分。橋接可以采用兩種基本架構,或者采用具有很少或沒有緩沖的直通(flow-through),或者每一個接口采用單級或兩級緩沖。
在直通架構中,流控制信息被生成并在外部作用于橋上。該方法簡化了橋的設計,但是,增加了源和流控制的目的端口之間的延遲時間,因此可能需要增加緩沖資源。
在有緩沖的架構中,橋接本身遵照流控制信息,因此需要內部緩沖。內部橋接緩沖可以由兩個接口共享(單級),或每一個接口配備自己的關聯緩沖器,稱為兩級緩沖處理。
入口網絡處理器接收端口被配置為物理器件接口的SPI4,而發送端口被配置為交換接口的SPI4.2,連接到專有的FIC(圖5)。FIC支持全雙工SPI4.2接口和多達24個速率為2.5Gbps的全雙工PCI Express SERDES(串行化/解串化)鏈路,一個10Gbps的全雙工鏈路端口需要4個SERDES鏈路。不用的SERDES鏈路可以通過器件配置寄存器的設置來關閉供電。在這個10Gbps的例子中,NPU通過PCI本地總線接口配置EP1SGX40內部的“配置和狀態”寄存器。
專有FIC參考設計
專有FIC參考設計平臺是采用英特爾的IXDP2401先進開發平臺設計和驗證的。AdvancedTCA機架把連接AdvancedTCA高速交換接口的兩個IXMB2401網絡處理器承載卡(carrier card)互連起來,承載卡是采用一塊IXP2400處理器設計的PICMG3.x兼容板。承載卡采用標準組件結構,包含4個子卡槽位和一個可選交換接口子卡槽位,以便連接到AdvancedTCA背板上區域2的交換接口引腳。
專有的、基于FPGA的交換接口子卡(mezzanine card)槽位的設計使其可插入承載卡,并提供一個可重配置的FIC和可選的流量管理開發板。FIC使處理器與AdvancedTCA交換結構相互連接。利用包含兼容PCI Express與XAUI的多通道收發器的可重復編程器件,可以提供可擴展的開發平臺,以便快速設計和驗證2.5Gbps到10Gbps的AdvancedTCA FIC設計(圖6)。
工作模式
參考設計的主要工作模式接收來自處理器入口端的32位SPI3或16位SPI4.2數據,通過FPGA集成收發器將數據流傳輸到AdvancedTCA背板,并將背板數據流通過32位SPI3或16位SPI4.2接口傳回處理器的出口端。
集成收發器經由處理器的SlowPort出口來配置。參考設計支持若干其它工作模式,包括SPI4.2接口環回、ASI接口環回、流量管理、交換結構數據包生成和監測。
FPGA和結構化ASIC FIC
采用專有的多FPGA和結構化ASIC技術,可以開發可擴展的PCI Express、ASI橋和端點。內建兼容PCI Express收發器的高密度、高性能的FPGA,可以提供:1. 具有可擴展的2.5鏈路的整體解決方案;2. 對每一個通道運行速率高達1Gbps的接口進行動態相位校正(DPA);3. 多種封裝選擇和高達40,000邏輯單元的密度選項。

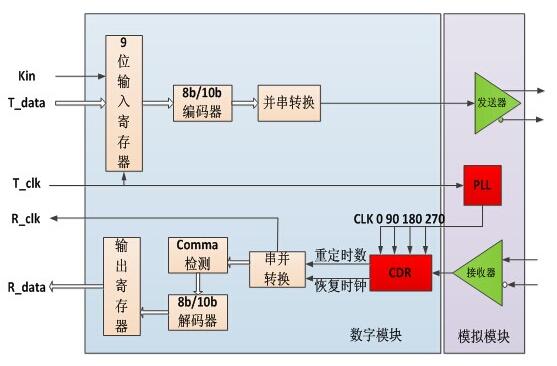
圖6:功能模塊框圖。
可選的FPGA結合獨立的兼容PCI Express的SERDES,如PMC-Sierra的PM8358 QuadPHY 10GX器件可用于對成本的關注超過對性能和擴展功能需求的應用,從而提供低成本的1x、2x和4x(路)靈活的解決方案。高密度、高性能FPGA與獨立的、兼容PCI Express的SERDES的結合,可被移植到專用的結構化ASIC,以提供所需要的最高密度、最快性能和最大數量的應用。
責任編輯:gt













 工商網監
工商網監
評論