 電子發(fā)燒友App
電子發(fā)燒友App


作者:李士昱、孫冬凱、梁程遠
雪球期權(quán)是一種新興的結(jié)構(gòu)較為復(fù)雜的期權(quán)產(chǎn)品,雪球期權(quán)的定價的準(zhǔn)確性和速度直接影響交易雙方的收益和風(fēng)險水平。目前我司雪球期權(quán)定價采用的是基于C++程序?qū)崿F(xiàn)蒙特卡羅模擬的方法。本文為解決基于C++的傳統(tǒng)定價程序帶來的處理時間長、延遲高、處理速率低的問題,提出并實現(xiàn)了一種基于FPGA的并行流水線計算處理設(shè)計,能夠完成對雪球期權(quán)的定價功能,并使用HLS開發(fā)模式對設(shè)計進行了實現(xiàn)。通過對比測試,相對于通用處理器與C++軟件實現(xiàn)的定價方式可獲得約17.83倍的性能提升。
引 言
普通歐式期權(quán)通常可以使用Black-Scholes模型進行定價,雪球期權(quán)在歐式期權(quán)的基礎(chǔ)上引入的觀察日和敲入敲出的概念,使得其定價無法運用類似模型獲得一個確定的期望價格,因此需要使用蒙特卡羅方法進行模擬。蒙特卡羅方法是一種對過程隨機抽樣的程序,我們可以通過隨機采樣得到近似的結(jié)果,其擁有采樣越多,越近似最優(yōu)解的特點。蒙特卡羅方法廣泛應(yīng)用于科學(xué)計算的各種領(lǐng)域。傳統(tǒng)思路是使用通用微處理器(CPU)進行蒙特卡羅模擬,在這種情況下通常需要通過提高處理器單核性能或者多線程方式提高模擬速度,也有使用GPU等專用計算處理器的嘗試。然而近年來,隨著摩爾定律漸漸失效,處理器單核性能提升逐漸放緩,而人們對計算量的需求隨著大數(shù)據(jù)、人工智能等技術(shù)的發(fā)展卻越來越大,因此對傳統(tǒng)體系結(jié)構(gòu)的變革需求變得越來越迫切。
隨著FPGA技術(shù)的不斷發(fā)展,利用FPGA進行硬件加速已經(jīng)逐步成為一個新的趨勢。一方面相比通用架構(gòu),F(xiàn)PGA能夠根據(jù)功能需求進行定制,獲得更好的性能和功耗;另一方面相比開發(fā)專用硬件,F(xiàn)PGA的開發(fā)周期更短,成本更低,其可重構(gòu)特性使得能夠根據(jù)算法變化快速進行更新迭代。此外,Xilinx公司推出的HLS和蘋果等公司推出的OpenCL等開發(fā)標(biāo)準(zhǔn)使得開發(fā)者能夠使用高級語言如C或C++進行硬件開發(fā)工作,進一步降低了開發(fā)門檻,提升了開發(fā)效率[1]。
本文設(shè)計并使用Xilinx公司提供的HLS開發(fā)方式,利用C++語言實現(xiàn)了定價實現(xiàn)了基于FPGA的雪球期權(quán)定價程序,并作為動態(tài)鏈接庫,通過Java本地接口JNI提供調(diào)用,作為dubbo服務(wù)整合到了場外衍生品OMS訂單管理系統(tǒng)中。
1 雪球期權(quán)的定價方法
雪球期權(quán)的本質(zhì)是一種賣出帶觸發(fā)條件的看跌期權(quán)。雪球期權(quán)屬于奇異期權(quán),因此帶有奇異期權(quán)的障礙概念,“障礙”是指當(dāng)標(biāo)的資產(chǎn)價格在特定時間內(nèi)穿越某一水平該期權(quán)才會生效或者失效。“障礙”一般分為敲出和敲入兩類。敲出即當(dāng)標(biāo)的資產(chǎn)價格達到一個特定的障礙水平時,該期權(quán)了結(jié)并兌現(xiàn)賠付,若規(guī)定時間內(nèi)標(biāo)的資產(chǎn)價格沒有觸及障礙水平,則為一個普通期權(quán)。敲入與敲出期權(quán)相反,當(dāng)標(biāo)的資產(chǎn)價格達到一個特定障礙水平時,該期權(quán)才能觸發(fā)約定賠付機制,若規(guī)定時間內(nèi)標(biāo)的資產(chǎn)價格沒有觸及障礙水平,則不觸發(fā)約定賠付機制。
一個雪球期權(quán)的要素表示如下:
雪球期權(quán)存續(xù)或結(jié)束時可能出現(xiàn)三種情形:
(1)產(chǎn)品發(fā)出敲出事件,此時無論是否發(fā)生敲入事件,產(chǎn)品將提前結(jié)束,客戶可獲得票息收益,按照產(chǎn)品實際存續(xù)期計算。
(2)產(chǎn)品存續(xù)期未發(fā)生敲出或敲入事件,客戶可在產(chǎn)品到期時獲得票息收益,按產(chǎn)品期限計算。
(3)產(chǎn)品存續(xù)期發(fā)生了敲入事件但未發(fā)生敲出事件,則客戶無票息收益,且可能承擔(dān)虧損,,如無跌幅則無虧損。
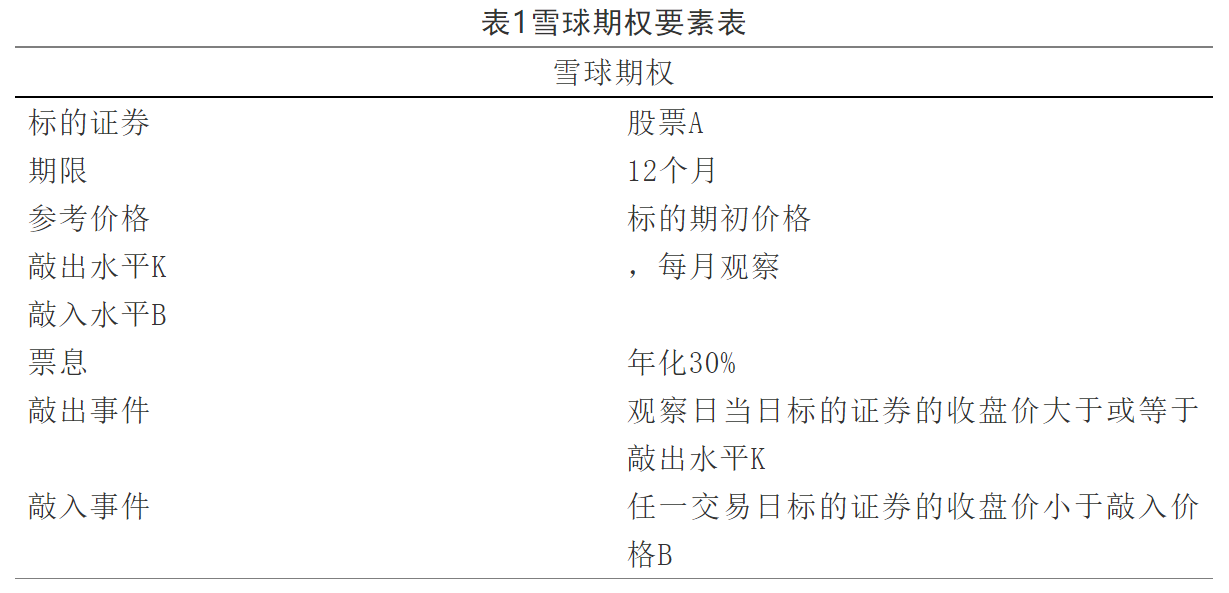
由上述條件可得到雪球期權(quán)收益率如圖1所示:
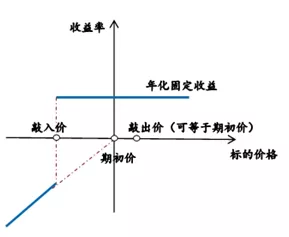
圖 1雪球期權(quán)收益
由于雪球期權(quán)障礙的存在,我們難以直接給出雪球期權(quán)的價格模型,因此考慮采用蒙特卡羅方法對作為標(biāo)的的股票價格進行抽樣,根據(jù)股票價格和障礙條件確定雪球期權(quán)最終收益,將收益折現(xiàn)后得到雪球期權(quán)的當(dāng)前價格。
2 雪球期權(quán)定價程序設(shè)計
2.1 雪球期權(quán)蒙特卡羅定價程序設(shè)計
我們以幾何布朗運動模型描述風(fēng)險中性情況下股票價格隨時間變化的離散形式如下[2]:
其中為無風(fēng)險利率 ,為股票波動率,服從標(biāo)準(zhǔn)正態(tài)分布。我們需要對該隨機過程進行蒙特卡羅模擬,獲得標(biāo)的股票期權(quán)存續(xù)期內(nèi)的價格路徑。蒙特卡羅模擬程序主要有兩個模塊,一是生成服從標(biāo)準(zhǔn)正態(tài)分布的隨機數(shù),二是完成價格計算,進行股票價格路徑模擬,并根據(jù)模擬結(jié)果計算雪球期權(quán)價格,由此可得到定價程序流程圖如圖2所示:

圖 2雪球期權(quán)定價程序流程圖
在通用處理器上程序都是串行順序執(zhí)行,執(zhí)行效率不高。本文提出了基于FPGA的解決方案。在處理方式上采用流水線執(zhí)行,并在路徑模擬部分根據(jù)硬件資源使用進行一定程度的并發(fā),進一步提高了路徑模擬的吞吐量。

圖3雪球期權(quán)定價在FPGA多并發(fā)流水線的執(zhí)行流程示例
2.2 定價程序開發(fā)模式
傳統(tǒng)FPGA開發(fā)方式通常采用RTL級描述,如使用Verilog或VHDL語言。RTL級開發(fā)雖然直接描述硬件的行為,能夠獲得更加準(zhǔn)確、性能更好的電路設(shè)計,但是對于軟件工程師來說門檻較高,調(diào)試優(yōu)化時間也更長,就好像在用匯編語言進行軟件開發(fā)一樣。為了解決這些問題,Xilinx公司推出了支持高層次綜合(High-Level Synthesis)的編譯工具,使開發(fā)人員能夠使用C/C++語言進行FPGA開發(fā),把精力更多集中在算法實現(xiàn)上面,不需要親自動手進行底層細節(jié)的實現(xiàn),極大提升了開發(fā)效率。圖4展示了使用RTL設(shè)計方法的傳統(tǒng)FPGA開發(fā)方式、HLS開發(fā)方式與其他平臺主流設(shè)計開發(fā)方法的開發(fā)時間和理想性能對比。
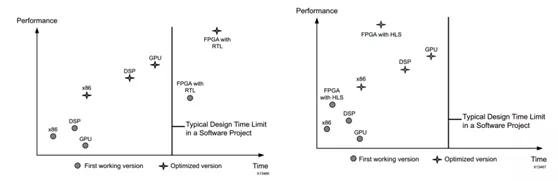
圖4不同平臺開發(fā)方式時間和理想性能對比[3]
總體來說,HLS可以自動完成以下曾經(jīng)需要手動完成的工作,包括[4]:
(1)HLS自動分析并利用一個算法中潛在的并發(fā)性;
(2)HLS自動在需要的路徑上插入寄存器,并自動選擇最理想的時鐘;
(3)HLS自動產(chǎn)生控制數(shù)據(jù)在一個路徑上出入方向的邏輯;
(4)HLS自動完成設(shè)計的部分與系統(tǒng)中其他部分的接口;
(5)HLS自動映射數(shù)據(jù)到儲存單位以平衡資源使用與帶寬;
(6)HLS自動將程序中計算的部分對應(yīng)到邏輯單位,在實現(xiàn)等效計算的前提下自動選取最有效的實施方式。
本文采用HLS方式進行雪球期權(quán)定價程序的開發(fā),一方面可以降低開發(fā)難度,將冪計算、開方計算、浮點數(shù)處理等硬件開發(fā)難點交由編譯器進行處理,提升開發(fā)速度,另一方面能夠?qū)W⒂谒惴▽崿F(xiàn),從更高層級優(yōu)化程序的執(zhí)行效率,提升程序優(yōu)化效率,在更短時間內(nèi)獲得更高性能提升。
3定價程序?qū)崿F(xiàn)與優(yōu)化
3.1 總體設(shè)計與實現(xiàn)
雪球定價程序參照Xilinx推薦的層次結(jié)構(gòu),總體自下至上可以分為三個層次:最下層L1層提供了用于構(gòu)建內(nèi)核的低級原語,包括隨機數(shù)生成器、路徑模擬、累加器等模塊;中間層由L1層各模塊構(gòu)建,并輔以更高層次層次邏輯控制和計算模塊,并以FPGA內(nèi)核形式提供定價引擎的接口;L3層則將數(shù)據(jù)傳輸、與內(nèi)核相關(guān)的資源配置和任務(wù)調(diào)度的低層細節(jié)抽象化,提供了供高級語言或軟件可直接調(diào)用的接口,通過調(diào)用即可完成定價引擎內(nèi)核的部署和運行。
此外,我們將定價用JNI包裝后編譯成動態(tài)鏈接庫,使用Java微服務(wù)進行調(diào)用,從而將定價服務(wù)云化,進一步為交易人員提供使用便利。圖5展示了定價功能的整體架構(gòu)。
圖5FPGA雪球定價程序總體架構(gòu)設(shè)計
3.2 核心模塊設(shè)計實現(xiàn)與優(yōu)化
蒙特卡羅模擬主要功能在L1層實現(xiàn),L1層共分為隨機數(shù)生成、路徑模擬和累加器三個模塊。
3.2.1 隨機數(shù)生成
隨機數(shù)生成模塊要求能夠生成符合標(biāo)準(zhǔn)正態(tài)分布的隨機數(shù),這里我們復(fù)用了Xilinx提供的隨機數(shù)發(fā)生器。Xilinx共提供了三種正態(tài)分布隨機數(shù)發(fā)生器,分別為MT19937IcnRng、MT2003IcnRng和MT19937BoxMullerNomralRng。第一種使用MT19937隨機數(shù),通過逆累計函數(shù)變換獲得最終結(jié)果;第二種使用MT2203隨機數(shù),同樣為逆累計函數(shù)變換獲得結(jié)果,與第一種不同的是MT2203的周期略短,同時理論上多實例的相關(guān)性更弱,隨機性也更好一些;第三種是使用MT19937隨機數(shù),通過Box-Muller變換得到正態(tài)隨機數(shù),其優(yōu)點是性能和資源消耗略小。本文采用MT19937BoxMullerNomralRng隨機數(shù)發(fā)生器來生成隨機數(shù)。生成的隨機數(shù)會按序放入一個隊列中結(jié)構(gòu)中,供路徑模擬模塊取用,并通過這一隊列將兩個模塊銜接起來組成一個長流水線。在HLS中這種隊列使用hls命名空間的stream類型來表示。
3.2.2 路徑模擬
路徑模擬是定價程序最重要的模塊,也是邏輯最復(fù)雜、對總體性能影響最大的模塊。在該模塊中需要對一條完整的隨機過程路徑進行模擬,也即模擬標(biāo)的股票在期權(quán)存續(xù)期內(nèi)的價格,并根據(jù)價格判斷是否觸發(fā)雪球期權(quán)的敲入敲出。
路徑中每節(jié)點開始首先判斷期權(quán)是否已經(jīng)敲出,如敲出則該路徑直接結(jié)束,如未敲出,則將上一節(jié)點價格和隨機數(shù)計算帶入定價公式,算出當(dāng)前節(jié)點股票價格,隨后判斷是否是觀察日和敲入敲出等障礙條件是否滿足,并根據(jù)結(jié)果調(diào)整敲入敲出標(biāo)志,最后判斷該路徑模擬是否已經(jīng)結(jié)束,如未結(jié)束則開始模擬路徑中下一個節(jié)點,處理流程如圖6所示。
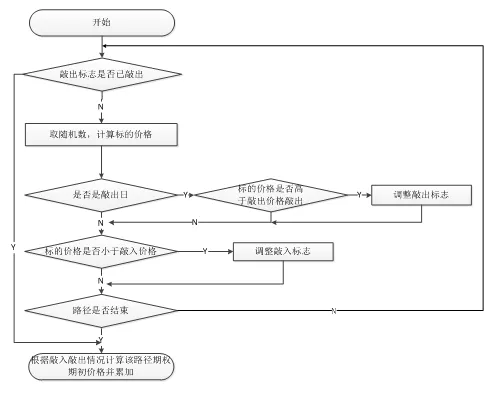
圖6路徑模擬模塊初始處理流程
FPGA的性能優(yōu)勢主要體現(xiàn)在流水線處理和并行兩個方面,在HLS開發(fā)過程中主要是通過對循環(huán)進行流水線處理和展開實現(xiàn),可以通過加入Pragma提示編譯器進行優(yōu)化工作,如:
for(int i = 0; i
#pragma HLS pipeline II = 1
…
}
其中#pragma HLS pipeline即告訴編譯器將該循環(huán)按照流水線展開,II為循環(huán)起始間隔,即本次循環(huán)到下一次循環(huán)開始的時鐘周期數(shù),本例II=1即告訴編譯器我們期望每周期能夠啟動新的循環(huán)迭代,相應(yīng)的即流水線填滿后每周期能夠產(chǎn)生一個結(jié)果,編譯器會根據(jù)期望結(jié)果進行嘗試,實際優(yōu)化效果未必能夠完全實現(xiàn)。
編譯器對于能夠流水線化循環(huán)的結(jié)構(gòu)也有兩點要求:一是循環(huán)盡量為單層循環(huán)且有固定邊界,二是如果無法滿足單層循環(huán),則盡量在兩層循環(huán)之間沒有邏輯操作且讓內(nèi)層循環(huán)擁有固定邊界[5]。
回顧路徑模擬的處理流程圖我們可以發(fā)現(xiàn),循環(huán)初始對敲入敲出的判斷在CPU順序執(zhí)行的情況下能夠避免后續(xù)無用的循環(huán),但是在FPGA平臺則會導(dǎo)致循環(huán)無法順利流水化,因此需要對處理流程進行調(diào)整,將敲出結(jié)果保存下來留到循環(huán)結(jié)束再進行處理,從而固定循環(huán)邊界,使循環(huán)能夠順利展開并減少分支損耗。該優(yōu)化使得循環(huán)迭代周期從II=17降至II=5,優(yōu)化后的處理流程如圖7所示:
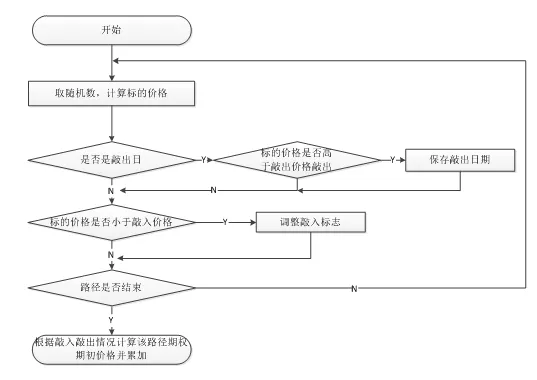
圖7優(yōu)化后的路徑模擬處理流程
3.2.3 累加器
累加器模塊一方面將各個路徑的結(jié)果累加并求平均得到最終結(jié)果,另一方面也負責(zé)隨機數(shù)生成和路徑模擬兩個模塊的銜接,以及路徑模擬的并行展開控制。
由于蒙特卡羅模擬路徑各路徑間的結(jié)果相互獨立,因此非常適合并行執(zhí)行,在HLS中的實現(xiàn)方式也非常簡單,如下所示:
for(int i = 0; i
#pragma HLS unroll factor = unrollNum
mcSimulation();//蒙特卡羅模擬函數(shù)
}
通過#pragma HLS unroll告知編譯器對該循環(huán)進行展開并行執(zhí)行,factor = unrollNum告知編譯器并行度,該部分可以省略,如省略則編譯器會將循環(huán)完全展開。
各路徑模擬結(jié)果將會暫存至與隨機數(shù)類似的隊列流中,該隊列在實例化為硬件后將會是一個RAM結(jié)構(gòu),其讀寫口數(shù)量和大小編譯器會根據(jù)代碼自動確定,通常為1讀口1寫口。使用同樣RAM結(jié)構(gòu)的C++數(shù)據(jù)結(jié)構(gòu)還有數(shù)組等。當(dāng)循環(huán)充分流水線化且并行展開后,對RAM的讀寫將會非常頻繁,自動生成的RAM讀寫口數(shù)量可能會無法滿足我們的需求,造成流水線阻塞。這時候就需要告知編譯器所需要的RAM大小和讀寫口數(shù)量,一種方式是直接告知采用的RAM規(guī)格,另一種方式是通過將數(shù)組或隊列拆分。以一個完全拆分即每一個數(shù)均采用寄存器存儲,深度為64的隊列為例,使用HLS的實現(xiàn)寫法為:
#pragma HLS stream variable = sumStrm depth =64
#pragma HLS array_partition variable =sunStrm dim = 0
4 測試與分析
4.1 測試環(huán)境
FPGA測試平臺:Xilinx公司的Alveo U200 FPGA加速卡,該FPGA加速卡被劃分為3個內(nèi)核,本次測試僅測試單核下的資源利用達到極限的性能,XRT運行環(huán)境版本為u200_201830_2,在Vitis 2019.2開發(fā)環(huán)境下完成的開發(fā)、綜合、驗證工作。
對比程序為使用QuantLib庫開發(fā)的基于蒙特卡羅模擬的雪球期權(quán)定價程序,開發(fā)語言為C++,運行環(huán)境處理器為Intel i7-8700,主頻3.2GHz,內(nèi)存16GB,操作系統(tǒng)為64位Windows 10。
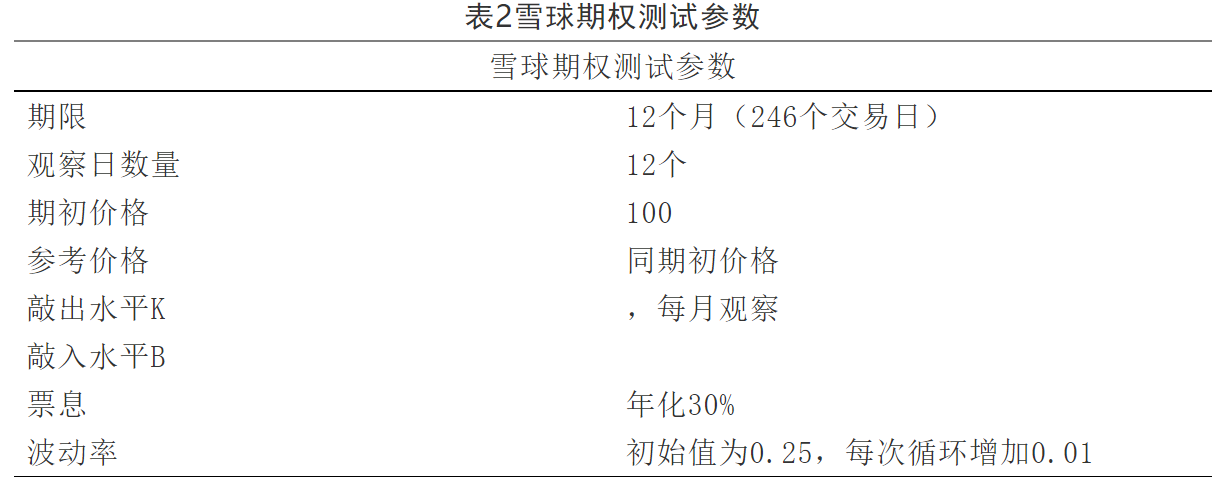
測試方法:在兩個平臺使用相同期權(quán)參數(shù)分別運行雪球期權(quán)的定價程序,蒙特卡羅路徑數(shù)為20萬條,路徑節(jié)點數(shù)為246個,對應(yīng)246個交易日。程序循環(huán)運行100次,每次對股票波動率進行調(diào)整,對比平均運行時間和定價結(jié)果誤差。期權(quán)主要參數(shù)如表2所示:
4.2 結(jié)果分析
FPGA與C++對比程序定價結(jié)果如圖8所示,F(xiàn)PGA定價結(jié)果相對C++定價結(jié)果誤差平均值為2.6%,方差為0.0245。與FPGA定價結(jié)果相比,C++程序的定價曲線更不平滑,考慮到兩邊隨機數(shù)的種子與隨機數(shù)生成方式均不相同,且蒙特卡羅為對隨機過程的抽樣近似,可以認為FPGA的定價結(jié)果準(zhǔn)確,能夠滿足定價使用要求。
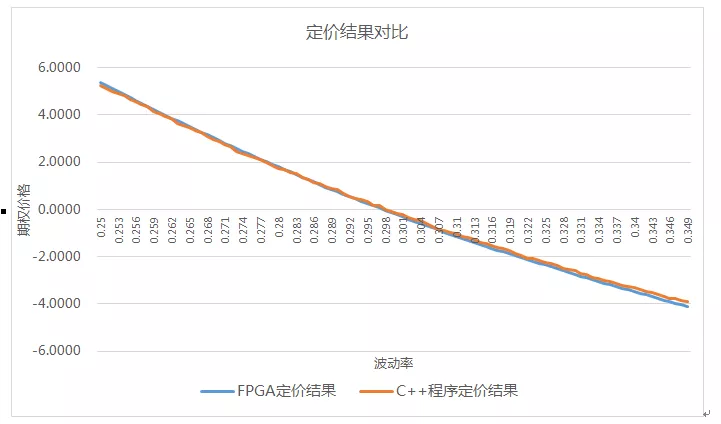
圖8雪球期權(quán)FPGA定價結(jié)果與C++程序定價結(jié)果對比
兩者執(zhí)行時間對比,C++程序平均每次定價時間為1153.48ms,F(xiàn)PGA程序平均定價時間為62.75ms,性能提升約為17.38倍。資源利用率如表3所示,其中最高的LUT查找表單核使用率為98%,基本達到單核性能極限。
5 結(jié)束語
本文采用流水線并行的設(shè)計結(jié)構(gòu)實現(xiàn)了對雪球期權(quán)的定價,相比于傳統(tǒng)軟件的處理方式,本設(shè)計在處理時間上顯著提高,其性能提升約為17.38倍左右。基于本設(shè)計在現(xiàn)有的Alveo U200 FPGA加速卡上使用HLS開發(fā)模式構(gòu)建了雪球期權(quán)定價功能,具有穩(wěn)定性好、延遲低、效率高、處理速率快等特點,取得了良好的測試效果,具有較高的工程實用價值。
審核編輯:郭婷













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論