 電子發(fā)燒友App
電子發(fā)燒友App


該項目基于AMD Xilinx Varium C1100 FPGA加速卡,為 Filecoin 區(qū)塊鏈應用中的Poseidon哈希算法提供了一套完整的硬件加速方案。在硬件方面,使用SpinalHDL 設計了Poseidon加速器模塊并基于Vivado Block Design 工具搭建完整的FPGA硬件系統(tǒng)。在軟件方面,該項目為 Filecoin 軟件實現(xiàn) Lotus 提供了訪問 FPGA 硬件加速器的接口。最終,整個項目能為Filecoin中Poseidon哈希函數(shù)的計算帶來兩倍于AMD Ryzen 5900X處理器的性能提升。
1
項目背景1.1 零知識證明與Poseidon
Poseidon是一種全新的面向零知識證明(ZKP: Zero-Knowledge Proof)密碼學協(xié)議設計的哈希算法。相比同類算法,包括經典的SHA-256、SHA-3以及Pedersen哈希函數(shù),Poseidon最大的特點和優(yōu)勢在于其針對零知識證明協(xié)議做了特定優(yōu)化,夠顯著降低證明生成的計算復雜度。
零知識證明是一類用于驗證計算完整性(Computational Integrity)的密碼學協(xié)議。其基本的思想是: 使證明者(Prover)能夠在不泄露任何有效信息的情況下向驗證者(Verifier)證明某個計算等式的成立。由于能夠兼顧隱私保護和計算完整性證明,零知識證明具備廣泛的應用場景,也是目前密碼學、區(qū)塊鏈以及可信計算方向上的研究熱點之一。其具體的應用場景包括: 匿名線上拍賣、云數(shù)據庫SQL查詢驗證、去中心化數(shù)據存儲系統(tǒng)等。尤其是在區(qū)塊鏈和加密貨幣領域,零知識證明憑借其出色的隱私保護特性, 近年來獲得了大量開發(fā)者和設計者的青睞, 包括加密貨幣Zcash和Pinocchio以及分布式存儲系統(tǒng)Filecoin等在其設計中都采用了ZK-SNARK零知識證明算法。
雖然零知識證明能在提供計算完整性驗證的同時兼顧隱私的保護, 但其代價是提高了證明生成和驗證的計算復雜度,這在一定程度上阻礙了其在實際項目中獲得更加廣泛的應用。目前,加速零知識證明的途徑主要有兩種,一方面是通過設計專用的硬件電路或者GPU來加速證明算法中的計算瓶頸;另一方面,可以通過優(yōu)化證明對象,使待證函數(shù)更加適配于證明算法進而減少證明生成過程的計算復雜度。例如,當Poseidon哈希算法和SHA-256算法同時作為ZK-SNARK的證明對象時,Poseidon所需的證明生成的計算量要顯著小于SHA-256。
1.2 Filecoin分布式存儲網絡
該項目實現(xiàn)的Poseidon加速器主要針對的是應用在Filecoin分布式存儲網絡中的Poseidon哈希計算實例。Filecoin是基于區(qū)塊鏈技術建立的一種去中心化、分布式、開源的云存儲網絡。其在提供存儲服務的過程中需要對數(shù)據進行Poseidon哈希運算,這一計算過程需要消耗大量的算力,是整個Filecoin系統(tǒng)運行的性能瓶頸之一。
目前,應用最為廣泛的Filecoin軟件實現(xiàn)是由Protocol Labs基于Go語言編寫的Lotus。可以將Lotus理解為用戶與整個Filecoin存儲網絡進行交互的接口。該項目在Poseidon加速電路的基礎上,為Lotus提供了訪問底層FPGA硬件加速器的軟件接口,同時通過Lotus-Bench對FPGA的加速性能進行了測試和比較。
2
Poseidon哈希算法概述Poseidon哈希函數(shù)的計算流程大致如下圖所示,從輸入和輸出的角度看,Poseidon哈希函數(shù)將輸入的t個有限域元素組成的向量映射到一個輸出有限域元素。對于本次課題加速的Filecoin Poseidon實例,t的取值可以是3、5、9或12,同時每個元素的位寬為255 Bit。具體的計算過程由RF次Full Round循環(huán)和RP 次Partial Round循環(huán)組成。每次循環(huán)迭代都需要依次完成Add Round Constants常數(shù)模加、S-Box五次方模冪和MDS Mixing向量-矩陣模乘三個階段的計算。
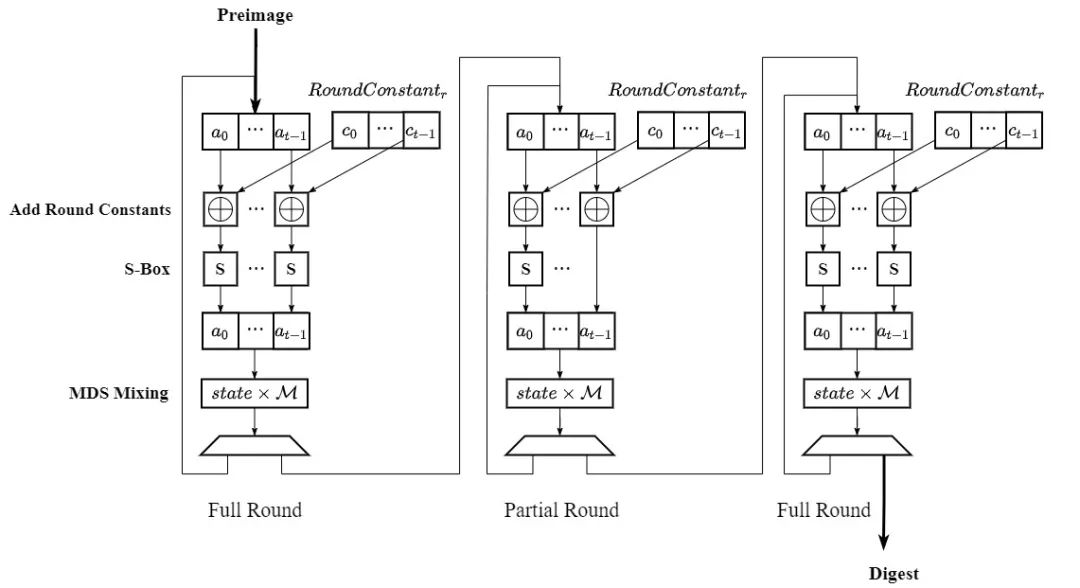
基于上述算法流程的介紹,Poseidon哈希函數(shù)硬件加速的難點主要分為三個層面:
a.基本運算單元: Poseidon哈希函數(shù)的基本運算單元包括模加和模乘。電路實現(xiàn)上模運算中的取余操作需要更加復雜的結構,同時操作數(shù)高位寬的特點也給電路設計提出了很大的挑戰(zhàn);
b.向量-矩陣乘法模塊: Poseidon中需要完成最高寬度為12的向量-矩陣乘法,其中涉及大量的乘加運算,是整個函數(shù)計算的性能瓶頸之一;
c.整體電路架構: Poseidon哈希函數(shù)的計算需要完成(RF+RP)次的循環(huán)迭代,而由于FPGA硬件資源的限制,無法將所有的循環(huán)在電路上展開得到一個全流水線的架構,需要設計額外的電路結構實現(xiàn)計算資源的復用。
3
基于SpinalHDL和Cocotb的電路設計與驗證本次項目中采用了基于Scala的硬件生成器語言 SpinaHDL和基于Python的驗證框架Cocotb完成Poseidon 加速器IP的設計與驗證。這兩種新興的設計和驗證工具極大提升了硬件開發(fā)的效率和質量。
3.1 SpinalHDL硬件描述語言
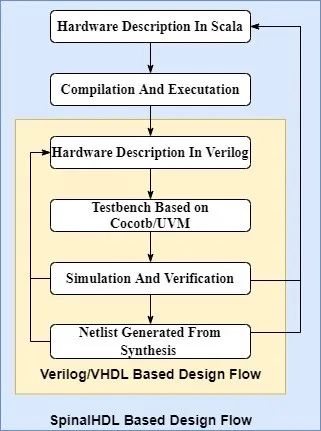
和RISC-V處理器開發(fā)中常用的Chisel類似,SpinalHDL是一種基于高級編程語言Scala的硬件生成器語言HCL(HCL: Hardware Construction Language)。基于SpinalHDL的硬件開發(fā)流程:首先需要使用Scala以及SpinalHDL中提供的電路單元描述整體的電路結構,然后編譯運行Scala代碼生成對應的Verilog程序,并在Verilog代碼的基礎上完成仿真、調試以及綜合等流程。
SpinalHDL提升硬件設計效率主要分成兩個方面:首先,Spinal建立在Scala高級編程語言的基礎上,因此能夠使用Scala中各種高級的編程特性提升電路描述的能力,具體包括:
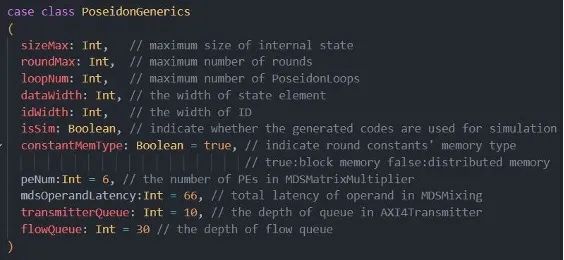
a.面向對象編程:Scala中面向對象的編程特性給硬件電路設計帶來了更強的參數(shù)化能力,極大提升代碼的復用性。例如,在本次項目中我們?yōu)镻oseidon加速器設計了一個配置類,這個配置類中包含了數(shù)據位寬、輸入向量寬度等,通過修改配置類的參數(shù),能夠高效地將本項目中實現(xiàn)的Filecoin Poseidon加速電路適配到其他的應用中。
b.遞歸:很大一部分電路的結構都具備遞歸的特點,如果使用遞歸的編程特性進行電路描述能夠極大地提升開發(fā)效率,同時提升代碼的復用性。
c.函數(shù)式編程:函數(shù)式編程是基于變量之間的映射關系來對系統(tǒng)進行建模,相比常用的面向過程的編程方式,函數(shù)式編程更加符合電路并行的特點。
在Scala的基礎上,SpinalHDL在硬件開發(fā)上的優(yōu)勢包括:
a.和Verilog相同的電路描述粒度:和同樣基于高級編程語言進行電路描述的高層次綜合工具HLS不同,Spinal仍然是在結構層面對電路進行建模,同時其具備和Verilog相同的電路描述粒度,如下表所示,所有Verilog可綜合的語法元素都能在SpinalHDL中找到相對應的部分:

b.豐富的電路元件抽象: SpinalHDL為硬件設計提供了豐富的電路元件抽象,例如狀態(tài)機、計數(shù)器以及總線控制器等,能夠使開發(fā)者避免重復實現(xiàn)底層的基礎模塊進而從更高的層次構建電路;
c.更加可靠的電路描述方式:首先,SpinalHDL為電路設計提供了更加準確的描述模型,例如,Verilog中只能使用wire描述信號,而Spinal提供了包括UInt(無符號整數(shù))、SInt(有符號整數(shù))、Bits(比特信號)等更加精確的描述模型。在此基礎上,SpinalHDL在編譯生成Verilog代碼的過程中會對電路描述進行相應的設計規(guī)則檢查,包括: Bits信號不能用于算術運算、信號連接時的位寬匹配、誤用鎖存器等問題。
3.2 Cocotb驗證框架
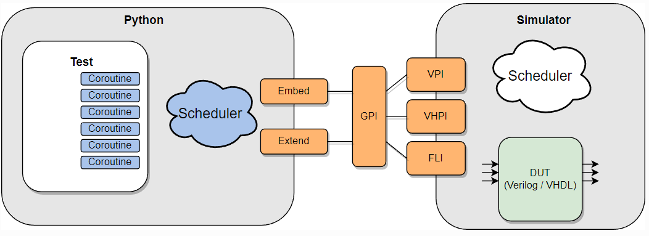
Cocotb是一種開源的基于Python的數(shù)字電路驗證框架,該驗證框架的具體工作模式如下圖所示。開發(fā)者可以完全在Python環(huán)境中完成測試功能的代碼實現(xiàn),而Cocotb框架通過VPI接口與仿真器中的待測模型進行交互。目前Cocotb已經可以支持大部分的仿真器包括:Verilator、Synopsis VCS和Modelsim等。
Cocotb在電路功能驗證上的優(yōu)勢主要包括:
a.Python高效簡潔的表達能力提升測試代碼的編寫效率;
b.復用Python豐富的生態(tài)搭建參考模型;
c.使用pytest、pytest-parallel、cocotb-test等軟件測試框架對代碼進行更加高效的管理。
4
總體方案設計加速系統(tǒng)的架構設計如下圖所示。整個系統(tǒng)主要分為CPU服務器和FPGA加速卡兩個主體。CPU服務器運行Filecoin的具體軟件實現(xiàn)Lotus提供數(shù)據存儲服務,當需要進行Poseidon哈希函數(shù)的計算時,服務器以DMA的方式將數(shù)據傳輸?shù)絇oseidon硬件加速器當中進行哈希計算。Poseidon加速器完成計算后以相同的方式將哈希結果傳回處理器內存中。
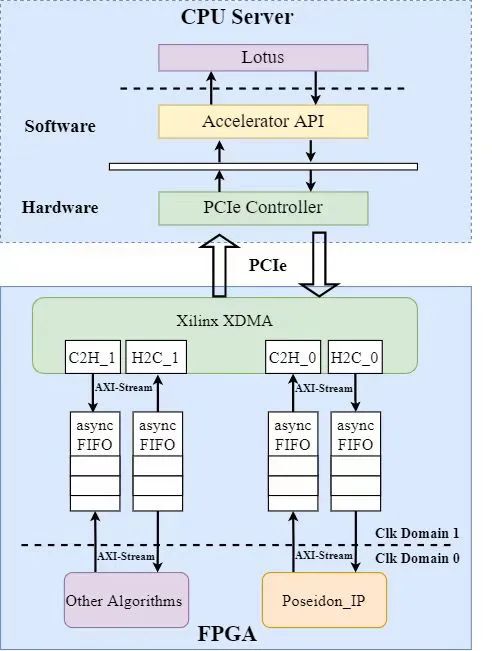
其中FPGA硬件系統(tǒng)主要由三個部分組成:
a.AMD Xilinx XDMA IP:實現(xiàn)數(shù)據從CPU內存到FPGA的搬運;同時負責PCIe外設總線到FPGA片內AXI-Stream總線的轉換;
b.異步FIFO:XDMA輸出總線的時鐘頻率固定為250MHz,而Poseidon加速器IP的工作頻率在100-200MHz左右,異步FIFO實現(xiàn)了這兩部分之間的跨時鐘域數(shù)據傳輸;
c.Poseidon加速器:整個FPGA加速卡的核心部分,負責Poseidon哈希函數(shù)的計算加速。
在上述系統(tǒng)架構設計的基礎上,本次課題研究中實際搭建的FPGA硬件系統(tǒng)如下。和上圖展示的硬件架構圖相比,實際的FPGA硬件系統(tǒng)中增加了Utility、Buffer、Utility Vector Logic和Clock Wizard等模塊來處理時鐘和復位信號。
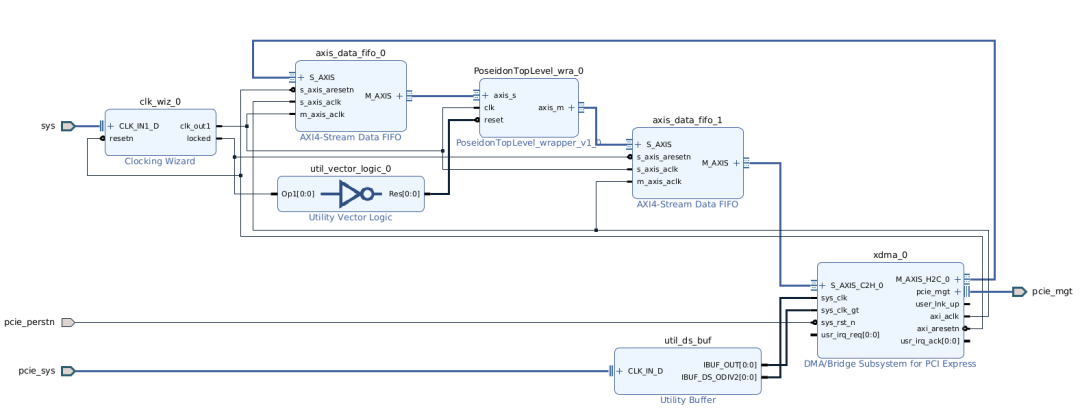
5
Poseidon加速器 IP 設計在上述FPGA系統(tǒng)架構設計的基礎上,這部分內容將介紹其中的核心模塊Poseidon加速器IP的設計與實現(xiàn)細節(jié)。對于任意算法的硬件加速器,其設計與實現(xiàn)大體上都可以分成單元運算電路和整體硬件架構兩部分。對于單元運算電路而言,諸如加法器、乘法器和模乘器等,其設計的主要目標是如何在更少的硬件開銷下達到更佳的計算性能。在單元運算電路的基礎上,硬件架構設計需要考慮的是如何提升每個運算單元的利用率,進而使加速器整體達到更高的數(shù)據吞吐率。本節(jié)將對Poseidon涉及的兩種模運算,包括模加和模乘的具體電路實現(xiàn)以及加速器硬件架構的設計做詳細地介紹。
5.1 模加電路的設計
任意模運算的實現(xiàn)都可以分成一次普通算術運算和取余運算兩部分。對于模加,需要先完成一次普通加法,然后將加法結果縮減到模數(shù)所規(guī)定的范圍內。最簡單的取余方式可以通過一次比較判斷和減法完成,具體如下公式所示:

該算法對應硬件電路結構如下圖(a)所示, 具體數(shù)據通路為:輸入操作數(shù)經過一個加法器后得到加法結果,將加法結果同時傳遞給減法器和比較器,分別得到減去模值和與模值比較的結果,將比較結果作為多路選擇器的選通信號對加法器和減法器的輸出進行仲裁后輸出。
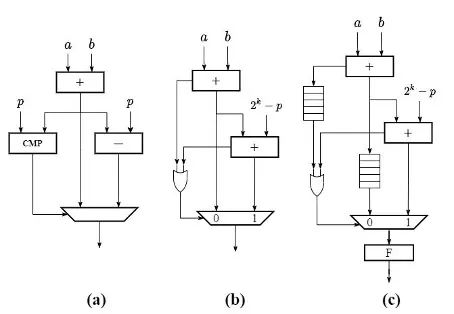
除了普通加法和減法操作相結合的方式外,還可以只通過兩次普通加法實現(xiàn)相同的模加功能,具體的算法定義如下:

其對應的硬件電路結構由兩個加法器和一個多路選擇器組成,如上圖(b)所示,具體數(shù)據通路為:輸入操作數(shù)經過第一個加法器,輸出兩數(shù)之和與進位;兩數(shù)之和繼續(xù)輸入第二個加法器,將兩次加法的進位進行或運算后,作為多路選擇器的選通信號對兩次加法結果進行仲裁后輸出。
上述兩種模加的實現(xiàn)方式均需要兩個加/減法器,分別完成加法和取余的計算步驟,然后經過一個多路選擇器仲裁后輸出,而第二種方法通過與門生成對應的選通信號,相比前一種方式能夠節(jié)約一個比較器的電路開銷。具體的實現(xiàn)中,由于Poseidon操作數(shù)位寬為255比特,在代碼中直接實現(xiàn)單周期加法器會對整體的時序產生較大的影響。為了提高電路的工作頻率,我們將圖(b)中兩個255比特加法器進行了全流水線化,每個加法器進行五級流水線的分割,并在多路選擇器的輸出端添加一級寄存器,使得整體模加電路總共包含11級流水延遲。流水線化后的模加電路結構如上圖 (c) 所示。
5.2 模乘電路的設計
和模加電路類似,模乘的實現(xiàn)也可以分解成一次普通的乘法運算和取余兩個步驟。這兩個步驟分別對應模乘實現(xiàn)過程中的兩個難點。
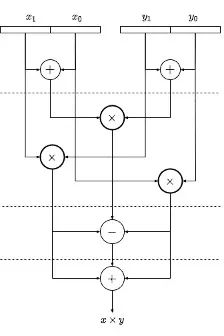
首先,從普通乘法的角度,Poseidon哈希函數(shù)操作數(shù)的位寬為255Bit。本項目中解決高位寬乘法的方式為: 將其分解成若干并行的小乘法器,而小乘法器通過調用FPGA中嵌入的DSP模塊實現(xiàn),具體的分解方式采用了Karatsuba-Offman算法,其算法定義如下公式所示:

上述算法對應的乘法器拆分結構如下圖,每次拆分后乘法器位寬減半,但數(shù)量上增加兩倍,同時需要引入額外的加/減法器。基于遞歸的思想,圖中的三個乘法器還可以不斷地進行拆分,直至位寬滿足需求。本次項目中對255比特的乘法器進行了三次拆分,最終分解為27個并行的34-Bit乘法器。而34比特乘法器則通過調用AMD Xilinx提供的乘法器IP實現(xiàn)。
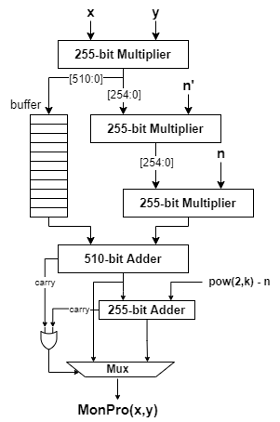
其次,從取余的角度,和模加中通過減/加法即可實現(xiàn)不同,模乘運算的取余通常需要在除法的基礎上完成,而除法器需要復雜的電路結構同時會消耗大量邏輯資源,對于硬件實現(xiàn)不夠友好。因此,大部分模乘電路的設計都采用了優(yōu)化的取余方式,將除法轉換成其他容易在硬件上實現(xiàn)的算術運算。本次項目基于Montgomery Reduction算法實現(xiàn)模乘器電路。Montgomery算法的基本思想是通過數(shù)域轉換的方式,將操作數(shù)和運算結果轉換到Montgomery域內,在該數(shù)域內取余計算中的除法可以簡化成移位實現(xiàn),具體的算法定義如下所示:

具體的電路實現(xiàn)結構如下圖所示,其數(shù)據通路主要由三個級聯(lián)的乘法器以及兩個加法器組成。
5.3 加速器架構設計
基于第二部分中算法流程的定義,項目中實現(xiàn)的Poseidon加速器的具體硬件架構如下圖所示。在Poseidon單次迭代的算法流程的基礎上, 加速器的實現(xiàn)針對具體的FPGA架構特點和硬件資源限制做了如下幾點優(yōu)化:
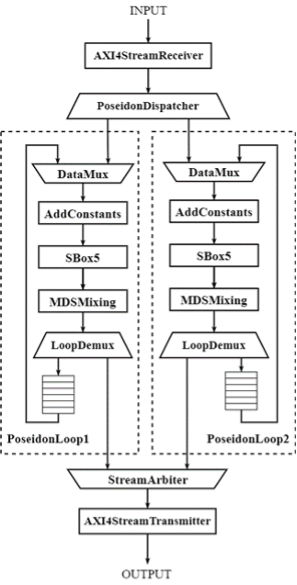
a.流水線處理:
為了提高加速器的工作頻率,對Poseidon加速器的數(shù)據通路進行了流水線化的處理。數(shù)據通路主要由模乘和模加單元組成,而每個模運算單元的組合邏輯路徑都進行了充分的切割,其中模加運算包含了11級流水,而Montgomery模乘器分割成了43級流水,整個計算通路總共由兩百級左右的流水組成。
b.折疊的設計思路:
Poseidon哈希算法總共由(RF+RP)次迭代組成,對于Filecoin Poseidon實例,根據中間狀態(tài)向量大小的不同,總共需要63 - 65次循環(huán)。由于FPGA硬件資源的限制,設計中不可能將所有循環(huán)都在電路上展開。因此需要基于折疊的思路,即時分復用的方式,在有限的循環(huán)單元上完成Poseidon哈希算法的所有迭代。具體的實現(xiàn)里,每個PoseidonLoop都可以完成一次Partial Round或Full Round的計算,而整個PoseidonLoop的數(shù)據通路呈環(huán)狀結構,輸入數(shù)據在環(huán)中不斷的流動,直至所有迭代完成后輸出。
c.并行計算:
Poseidon加速器IP中配置了兩個相同的PoseidonLoop核心模塊,并行地進行Poseidon哈希函數(shù)的計算。
基于上述架構設計,整個Poseidon加速器的工作流程主要可以分成三個階段:
a.輸入階段: AXIStreamReceiver模塊接收XDMA IP以AXI-Stream總線協(xié)議傳送來的輸入數(shù)據,并將其轉換成加速器內部的數(shù)據傳輸格式。PoseidonDispatcher負責將AXIStreamReceiver輸出的數(shù)據分發(fā)到兩個迭代單元中。
b.計算階段:輸入數(shù)據在兩個PoseidonLoop的環(huán)形數(shù)據通路中不斷流動,直至所有循環(huán)完成后輸出;
c.輸出階段:StreamArbiter對兩個迭代模塊PoseidonLoop的輸出進行仲裁后傳遞給AXIStreamTransmitter模塊,而AXIStreamTransmitter模塊負責將內部數(shù)據傳輸格式轉換成AXI4-Stream總線形式輸出。
6
性能測試在上文中介紹的FPGA硬件系統(tǒng)和其中Poseidon加速器IP的基礎上,我們通過Vivado集成開發(fā)環(huán)境將其實現(xiàn)在了Varium C1100 FPGA加速卡上,該板卡搭載了AMD Xilinx Virtex UltraScale+系列的FPGA芯片,具體芯片型號為具體型號為XCU55N-FSVH2892-2L-E。整個硬件系統(tǒng)實現(xiàn)(Implementation)后的報告以及性能測試結果如下:
6.1 Vivado Implementation 報告
整體硬件加速系統(tǒng)綜合實現(xiàn)后邏輯資源消耗情況如下表所示:
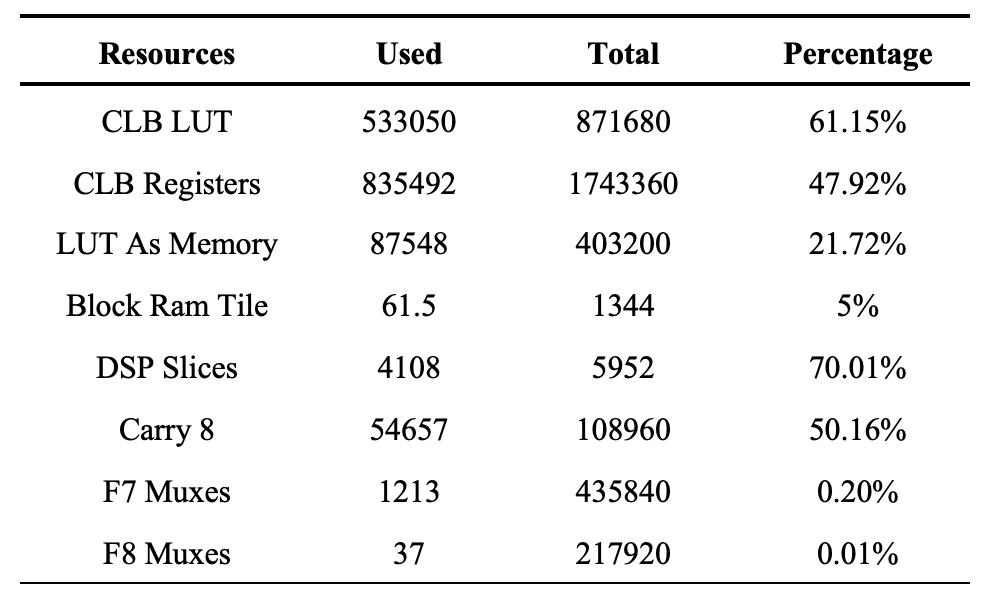
各項FPGA資源中DSP Slices(70.01%)和LUT(61.15%)的消耗最多, 主要用于255-Bit Montgomery模乘電路的實現(xiàn)上。這兩項資源的不足也限制了在加速器中配置更多模乘器來提升計算并行度和整體的加速性能。
在時序上,實現(xiàn)(Implementation)后Poseidon加速器剛好能夠滿足100MHz工作頻率的要求。關鍵路徑上,建立(set up)時間的余量為0.069ns,保持(hold)時間的余量為0.01ns。
除了資源和時序外,F(xiàn)PGA實現(xiàn)后的功耗信息如下圖所示。由下圖可見,在運行我們設計的加速器硬件時,F(xiàn)PGA芯片的整體功耗在24.7W左右。而我們在性能測試中使用的RTX 3070 GPU加速卡的運行功耗在120W左右。

6.2 計算性能測試
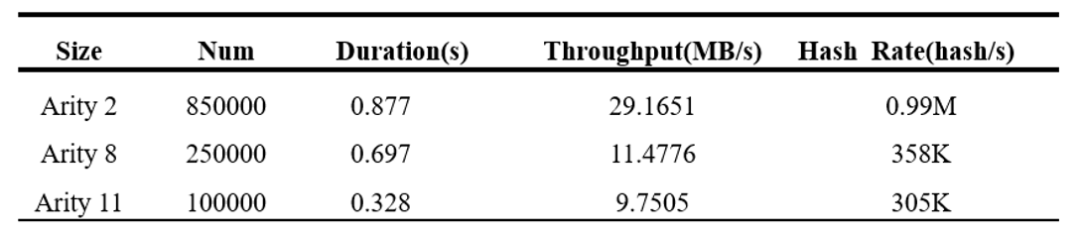
a.吞吐率測試:在 AMD Xilinx提供的XDMA驅動的基礎上項目中為加速器編寫了簡單的性能測試程序。該測試程序向FPGA加速器寫入一定數(shù)量的輸入數(shù)據,并記錄加速器完成所有數(shù)據哈希運算所需要的時間。基于該測試程序,我們分別測試了Poseidon加速器在三種長度輸入數(shù)據下的性能表現(xiàn)。當輸入數(shù)據的大小為 arity2,加速器在0.877秒內完成了850000次的哈希運算,數(shù)據吞吐率可達到29.1651MB/s, 即每秒大約能夠完成1M次哈希運算;
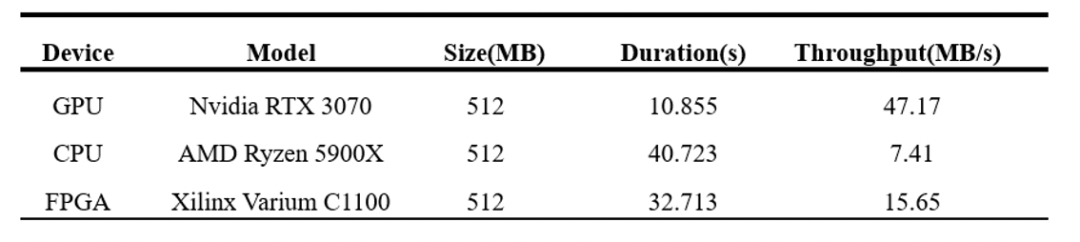
b.Lotus-Bench測試結果:Lotus中提供了計算機硬件在Filecoin計算負載下性能表現(xiàn)的基準測試程序Lotus-Bench;該測試更加接近實際的工作負載,能夠得到更加準確的測試結果。在Lotus-Bench的基礎上,我們分別測試了CPU, GPU和FPGA 在preCommit階段(該階段主要完成Poseidon哈希函數(shù)的計算)處理512MB數(shù)據所需要的時間。FPGA在 Lotus-Bench 測試下的算力可達到 15.65MB/s,大約是AMD Ryzen 5900X CPU實現(xiàn)的2倍,但和RTX 3070 GPU的加速性能相比仍有很大的提升空間。
總結
本項目為Filecoin區(qū)塊鏈應用中的Poseidon哈希函數(shù)提供了基于FPGA的加速方案。硬件上,我們基于AMD Xilinx Varium C1100 FPGA板卡搭建了一個完整的加速系統(tǒng),該系統(tǒng)主要由XDMA、FIFO以及Poseidon加速器IP三部分組成。其中,Poseidon加速器IP是整個系統(tǒng)的核心部分,其設計與實現(xiàn)主要可以分成單元運算電路和整體架構兩個部分。在單元運算電路的實現(xiàn)中,我們基于Karatsuba-Offman算法將高位寬乘法分解成若干并行的小乘法器實現(xiàn),同時采用Montgomery Reduction算法將取余過程中復雜的除法運算轉換成乘法實現(xiàn)。在加速器架構的設計上,我們針對具體的FPGA硬件資源限制,基于流水線和折疊技術設計了一個串行的Poseidon計算架構。最終,F(xiàn)PGA加速系統(tǒng)能夠工作在100MHz并為Filecoin提供兩倍于AMD Ryzen 5900X處理器的加速性能。






















 工商網監(jiān)
工商網監(jiān)
評論