 電子發燒友App
電子發燒友App


01
數字圖像基本概念
數字圖像(Digital Image),是計算機視覺與圖像處理的基礎,區別于模擬圖像。通常直接觀測到的圖像可以理解成連續的模擬量,模擬量在處理時涉及運算相對復雜,內部相關性較高,難以形成統一定量的標準。隨著計算機的發展,為便于計算機的運算與定量處理,同大多數模擬量一樣,模擬圖像需要通過采樣量化轉化為離散的數字量,即數字圖像。
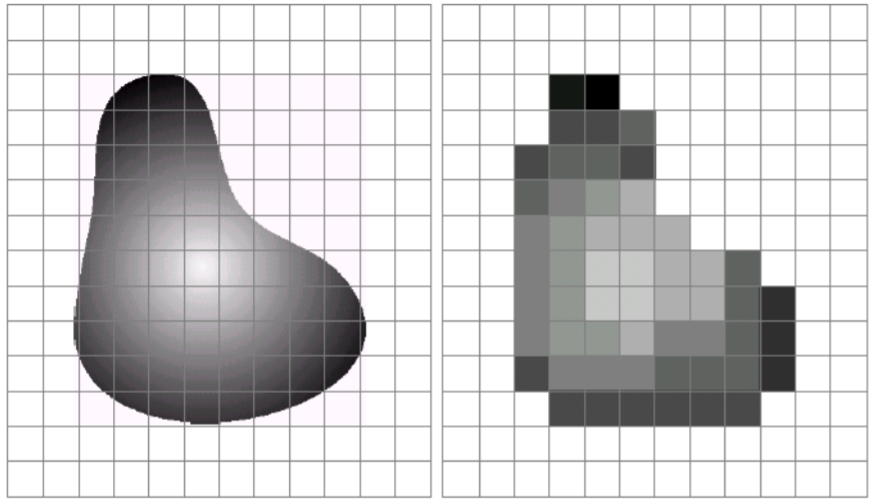
1.1 數字圖像提取
數字圖像通過對模擬圖像采樣和量化得到,該過程通常由圖像傳感器(例如CMOS圖像傳感器)實現,圖像傳感器通常為感光元件陣列。圖像傳感器的性能決定了采集到的數字圖像的質量。

1.1.1 采樣處理
采樣(Sampling)處理即對圖像所在空間坐標進行數字化,將空間上連續的圖像轉變為離散的采樣點。采樣處理的評估指標為圖像的空間分辨率。
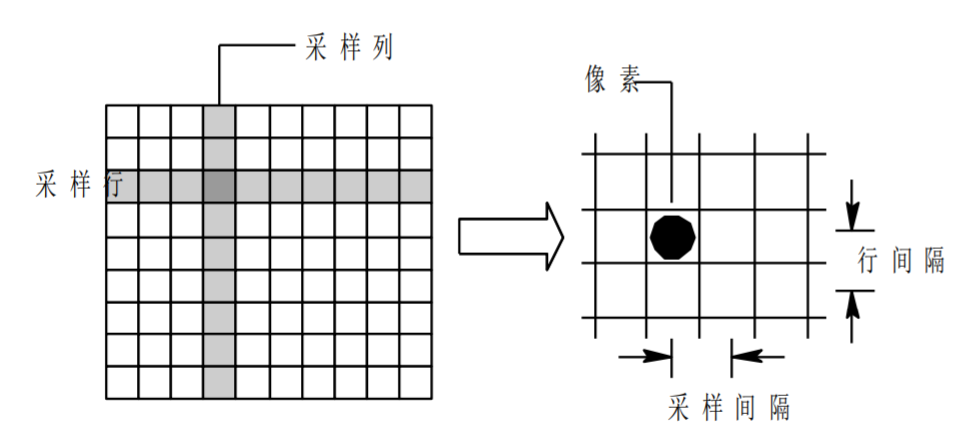
1.1.2 量化處理
量化(Quantifying)處理即對采樣信號按一定規則賦值,對采樣點幅度進行離散化。量化處理的評估指標為圖像的幅度分辨率,也稱為灰度級分辨率。量化通常以圖像的明暗信息為標準,考慮人眼識別能力,采用8bit 0~255來描述黑~白。
量化通常可分為均勻量化和非均勻量化:
均勻量化對連續灰度值等間隔分層,層數越多,產生的量化誤差越小;
非均勻量化通常基于不同的特性設置不同的采樣間距,例如,基于視覺特征的非均勻量化通常縮小細節豐富地方的采樣間距,基于統計特征的非均勻量化通常縮小灰度值出現頻繁的采樣間距。

通過采樣與量化處理后提取的數字圖像可以由一個矩陣進行表示,矩陣的大小為圖像的空間分辨率,矩陣每個元素的值為對應像素的幅度分辨率。
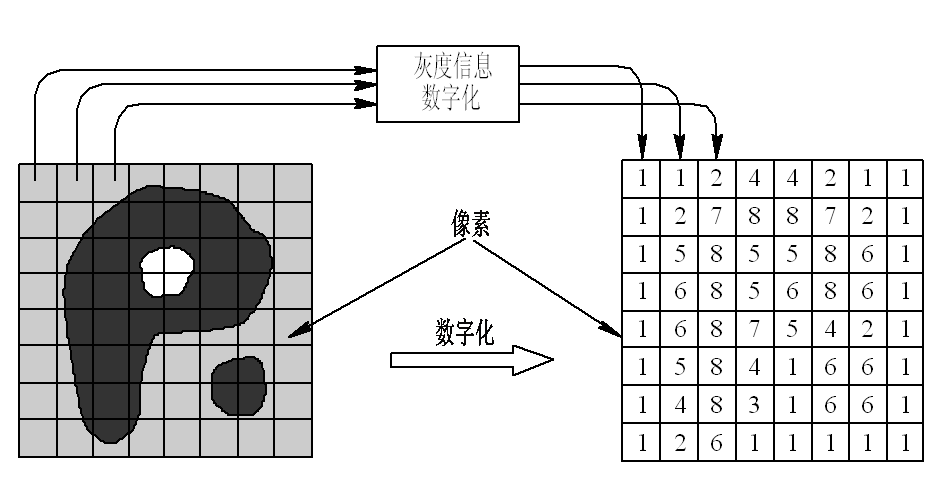
1.2 數字圖像概念
數字圖像處理過程中常見概念:
1.2.1 數字圖像基本單位——像素
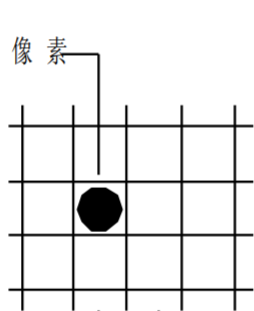
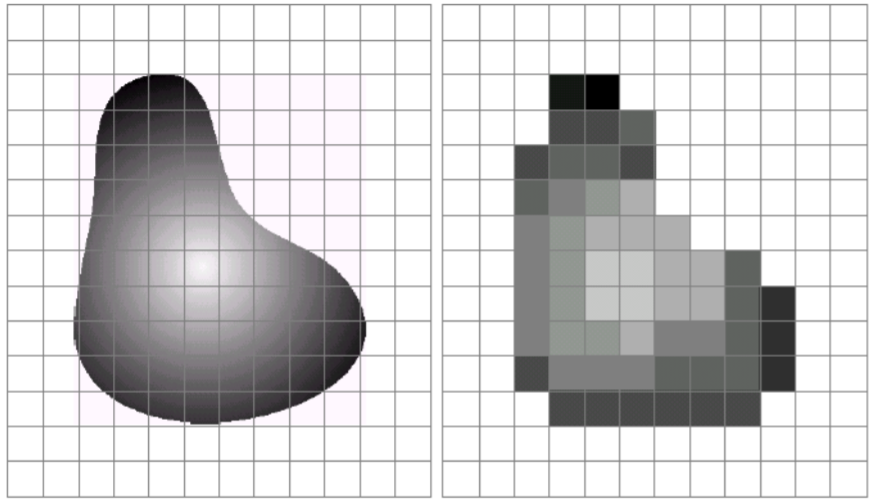
像素(Pixel),也稱為像元,是數字圖像的基本元素。像素在模擬圖像離散化過程中生成,即采樣過程提取到的每一個采樣點就是一個像素。每個像素都具有位置坐標與灰度值(或顏色值)。在其他條件相同的情況下,包含像素越多的圖像,清晰度越高。
1.2.2 數字圖像的灰度與深度
數字圖像的灰度與深度通常用來衡量量化程度。灰度指每個像素取值大小,灰度范圍即每個像素取值的范圍,通常在其他條件相同的情況下,灰度值范圍越大的圖像越清晰;深度指每個像素存儲所需要的容量,通常也稱為灰度級,灰度范圍越大,所需要的深度越大。通常用8bit表示256個灰度級,灰度為0~255中某個整數,深度為8。
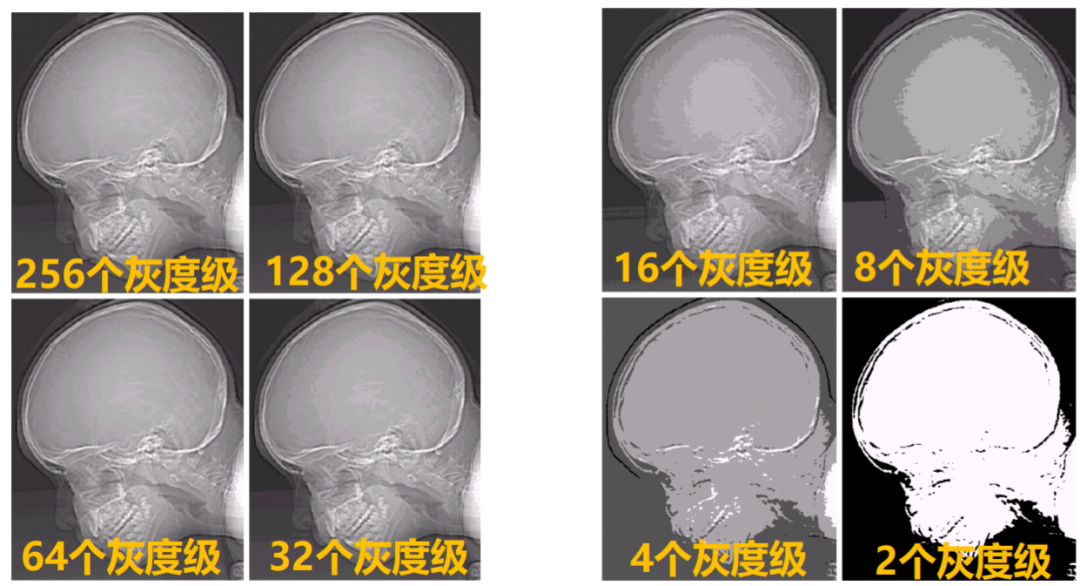
1.2.3 數字圖像的分辨率
數字圖像的分辨率包括空間分辨率和幅度(灰度)分辨率。空間分辨率指數字圖像所包含的像素個數,用于衡量圖像大小(通常利用分辨率描述圖像大小不能離開空間單位,例如印刷行業采用dpi表示每英寸像素數);幅度(灰度)分辨率指數字圖像量化灰度的位數,與深度的含義相同。

1.2.4 數字圖像的常見種類
二值圖像:圖像像素亮度值僅由0和1構成;
灰度圖像:圖像像素亮度值由0~255表示黑~白;
彩色圖像:由RGB三幅不同顏色的灰度圖像組成;
立體圖像:某物體從不同角度拍攝的一對圖像,可以計算出圖像深度信息;
三維圖像:由一組堆棧的二維圖像組成,每幅圖像表示物體的一個橫截面;
1.2.5 數字圖像的常見格式
JPG格式:全稱為JPEG,以24為顏色存儲單個光柵圖像,支持最高級別的有損壓縮,壓縮比率可達100:1,但會犧牲大量圖像質量,通常在10:1到20:1的壓縮比下保證圖像質量。JPEG壓縮可以很好得處理類似色調,但不能很好得處理亮度差異大和純色區域。JPEG支持隔行漸進顯示,但不支持透明性和動畫,對JPEG圖像進行除旋轉裁剪外得編輯操作通常會導致圖像質量損失,因此在編輯過程通常以PNG作為過渡格式;
PNG格式:流式網絡圖形格式(Portable Network Graphic Format,PNG)是20世紀90年代中期開始開發的圖像文件存儲格式,其目的是企圖替代GIF和TIFF文件格式,同時增加一些GIF文件格式所不具備的特性PNG采用從LZ77派生的無損數據壓縮算法,用來存儲灰度圖像時,灰度圖像的深度可多到16位,存儲彩色圖像時,彩色圖像的深度可多到48位,并且還可存儲多到16位的α通道數據。PNG格式包括許多類,實踐中大致可分為256色和全色,其中256色PNG可以代替GIF格式,全色PNG可以代替JPEG格式。PNG支持alpha透明,即支持透明、不透明和半透明,圖像顏色較少且主要以純色或平滑漸變色填充和亮度差異大的圖像適合以PNG8格式存儲;
GIF格式:GIF(GraphicsInterchange Format)圖像互換格式是CompuServe公司在1987年開發的圖像文件格式。GIF文件的數據采用了可變長度等壓縮算法,是一種基于LZW算法的連續色調的無損壓縮格式,壓縮率一般在50%左右。它不屬于任何應用程序,目前幾乎所有相關軟件都支持。GIF的圖像深度從1bit到8bit,最多支持 256 種色彩圖像。在一個 GIF文件中可以存多幅彩色圖像,如果把存于一個文件中的多幅圖像數據逐幅讀出并顯示到屏幕上,就可構成一種最簡單的動畫。GIF支持動畫和布爾透明,即不支持半透明(alpha透明),GIF支持可選擇性的間隔漸進顯示,同時LZW水平掃描壓縮使得同一圖片橫向GIF比豎向GIF占用空間更小;
BMP格式:BMP是一種與硬件設備無關的圖像文件格式,采用位映射存儲格式,除了圖像深度可選可選1bit、4bit、8bit及24bit以外,不采用其他任何壓縮,因此BMP 文件所占用的空間很大。BMP支持索引色和直接色,存儲數據時,圖像按從左到右、從下到上的順序進行掃描;
SVG格式:可縮放矢量圖形 (Scalable Vector Graphics)是由萬維網聯盟制定的一個基于可擴展標記語言(標準通用標記語言的子集)的開放標準,用于描述二維矢量圖形的一種圖形格式,因此在放大時不會失真,線不會變為像素點。SVG使用XML格式定義圖形,與DOM和XSL等W3C標準是一個整體;
02
數字圖像處理算法
數字圖像處理算法通常包括圖像增強、圖像拼接、圖像分割、圖像壓縮、圖像識別、圖像變換、圖像復原、圖像重建等研究領域。
2.1 圖像增強
圖像增強技術針對光照不足、雨霧影響等噪聲較大的圖像,改善畫質,提高圖像清晰度。常用算法包括直方圖均衡化、Retinex理論、深度學習等。
2.1.1 直方圖均衡化
圖像直方圖和圖像像素之間存在直接映射關系,直方圖均衡化可以將這一映射表達出來。直方圖均衡化的基本思想是對圖像像素統計個數多的灰度級進行展寬,對像素統計個數少的灰度級進行縮減,改變圖像通道的直方圖分布以達到視覺上對比度增強的效果。
直方圖均衡化圖像增強通過利用直方圖可以進行層次差分表達的特性,增強圖像的對比度,并將相鄰像素間的灰度差放大,從而提高圖像對比度。

直方圖均衡化僅對圖像像素進行映射,計算像素強度而忽略其空間信息,導致圖像的局部亮度調節能力不夠好,從而影響到某些場景的整體亮度,同時可能會引入其他噪聲。
2.1.2 Retinex理論
Retinex的基本思想是,將待增強圖像S分解為圖像的反射成分R(x)與光照成分L(x)的積,即對象自身色彩與光照成分無關,取決于對象表面的反射特性,因而從輸入圖像中移除干擾圖像強度的成分可以獲得圖像的增強。
將固有先驗引入到分解模型中來增強對比度,在反射層和光照層分別引入約束條件(反射層通過顏色相似性對相鄰像素進行規范約束,光照層通過分段平滑進行約束)可以解決增強圖像出現過亮等問題。
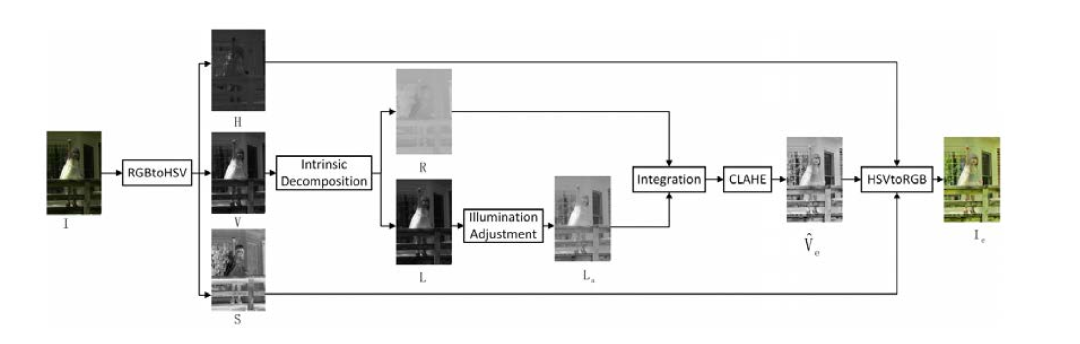
2.1.3 深度學習
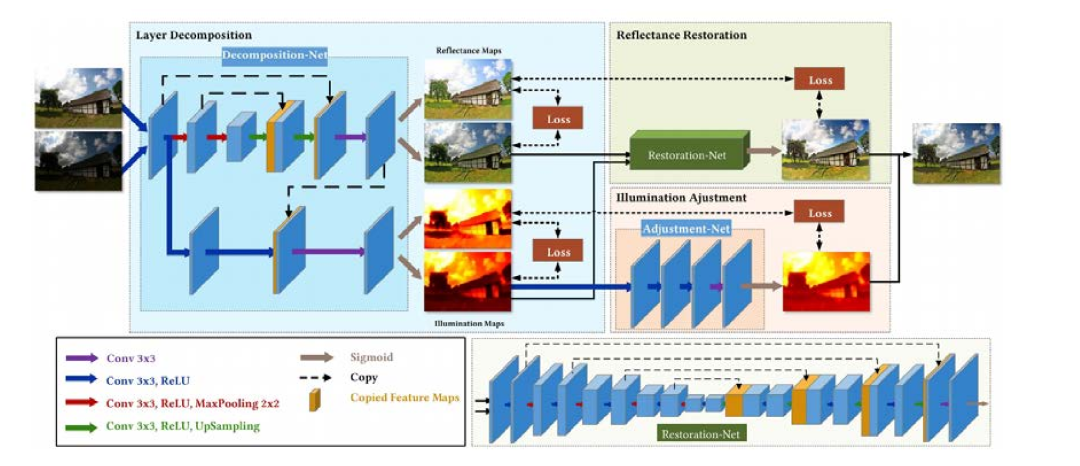
隨著深度學習的發展,基于卷積神經網絡(CNN)、對抗生成網絡(GAN)等圖像增強算法也相繼被提出。下圖是在Retinex原理啟發下提出的CNN網絡方法流程圖,將網絡分成用來調節光線和用來消除噪聲兩部分。
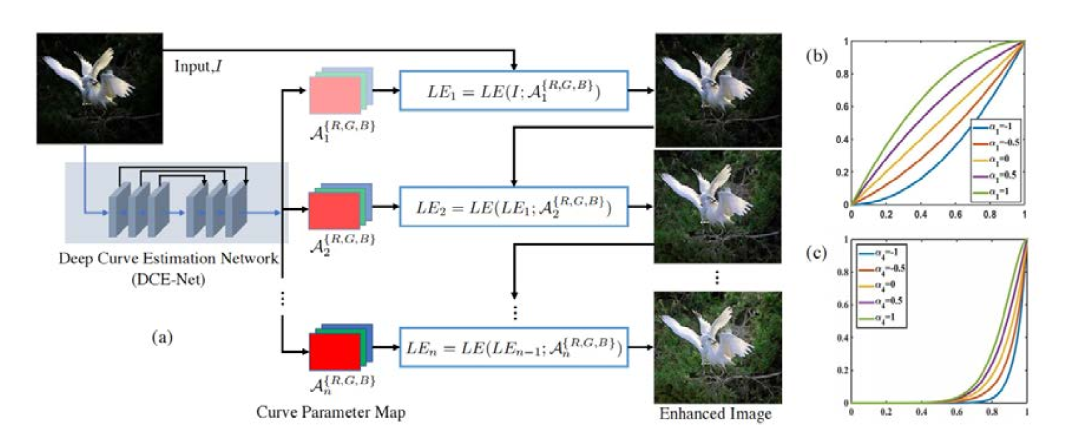
無監督深度網絡模型,零參考深度曲線估計網絡(Zero-DCE)方法利用深度網絡將增強作為圖像特定曲線估計的任務,該方法不要求有成對或不成對的數據,而是訓練一種用于估算像素水平和高次曲線的網絡以適應給定的圖像動態范圍。
2.2 圖像拼接
圖像拼接技術針對單鏡頭拍攝圖像顯示范圍的局限性,將多幅圖像拼接為一幅以克服圖像視野的限制、擴大圖像范圍進而更好地展示細節。圖像拼接的主要方法有兩種:基于區域的圖像拼接方法和基于特征的圖像拼接方法。
2.2.1 基于區域的圖像拼接方法
基于區域的圖像拼接方法通過對兩張待拼接圖像在同一區域內的強度差進行計算得到拼接后圖像。基于區域的拼接方法有:像素點匹配法、基于互信息的方法和基于拉普拉斯金字塔的方法。此類方法的優點是最優地利用了圖像對齊信息,但是計算量大,配準精度低,對常見幾何變換沒有不變性。
2.2.2 基于特征的圖像拼接方法
基于特征的圖像拼接方法是通過像素得到圖像特征信息進而匹配和拼接圖像,步驟包括:圖像的特征提取與描述、特征匹配、重投影拼接和圖像融合。圖像特征提取與描述是描述一塊與其他區域高度可區分的區域,局部特征應準確、有效、區分性強。特征匹配要找同一場景的待拼接圖像間的匹配點。重投影拼接和圖像融合是指使用幾何變換將圖像對齊到一個統一的坐標系統中并消除由光照影響產生的拼接縫。此步中首先要描繪輸入圖像的幾何變換關系,一般的變換關系是8個自由度的單應性矩陣,然后進行重投影拼接,最后融合拼接縫處光照突變的像素。
基于特征的圖像拼接技術普適性好、在各領域使用頻率最高、范圍最廣,因此是實現圖像拼接最好的選擇。圖像配準常用算法包括Harris角點檢測、SIFT、PCA-SIFT、FAST、ORB、SURF等算法;圖像重投影拼接與融合常用算法為RANSAC算法。
2.3 圖像分割
圖像分割技術針對圖像中某些特定物體進行研究,將待研究物體分離以更清晰得研究物體變化特點。圖像分割技術主要應用于醫學和科研領域,醫學圖像中不同的人體器官、組織和病變區域所表現的復雜特點,以及醫學圖像自身的復雜性和多模態性,對適用于各種類型的醫學圖像分割任務的圖像分割算法提出了很高的要求。圖像分割技術根據圖像特征手工提取和自動學習方式可劃分為兩大類:傳統圖像分割方法和基于深度學習的圖像分割方法。
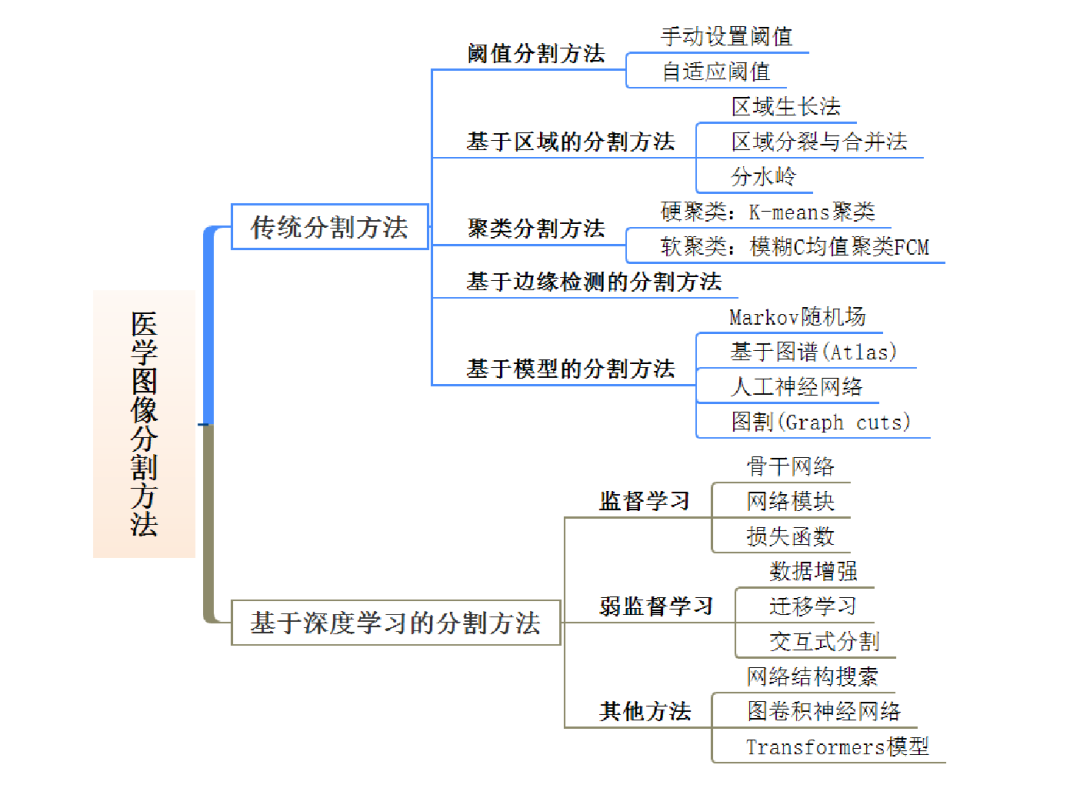
2.3.1 傳統圖像分割方法
傳統醫學圖像分割方法主要依賴于圖像中強度值的不連續性和相似性特征。例如基于邊緣檢測的方法根據圖像中強度級別或圖像灰度級別的瞬時變化,利用其不連續性實現圖像的分割,其主要關注孤立點的識別。閾值分割或區域分割等根據圖像分割的預設標準,基于一定范圍內的像素相似性來分割圖像。傳統的醫學圖像分割方法可大致分為閾值分割法、基于區域的分割方法、聚類分割法、基于邊緣檢測的分割方法、基于模型的分割方法。
2.3.2 基于深度學習的圖像分割方法
基于深度學習的分割方法克服了傳統手工特征分割的局限性,在特征自動學習方面凸顯優勢。其中,全卷積網絡(Fully Convolutional Network, FCN)在語義分割取得優異的效果,為語義分割提供了新的思路和方向,在醫學圖像語義分割任務中得到了廣泛的應用,并在該領域取得了大量的研究成果。從數據驅動技術的角度出發,深度學習在醫學圖像分割中的方法可大致劃分為監督學習、弱監督學習和其他方法。
2.4 圖像壓縮
圖像壓縮技術針對圖像數據冗余度較大的問題,將圖像中的冗余度壓縮以減小圖像數據量,從而加速圖像的傳輸于處理過程。圖像壓縮技術的研究方向主要包括兩個方面:傳統的圖像壓縮技術研究和基于深度學習的圖像壓縮技術研究。
2.4.1 傳統的圖像壓縮技術研究
傳統的圖像壓縮技術研究從信息恢復的角度主要分為無損壓縮和有損壓縮兩類:
無損壓縮編碼:壓縮過程不損失任何信息,重建后的圖像與原來的圖像完全相同,在數據壓縮過程中盡量降低冗余度,常用編碼包括Huffman編碼、算數編碼、行程編碼等;
有損壓縮編碼:壓縮過程通過損失一定的信息實現更高的壓縮率,重建后的圖像與原圖有差距,常用編碼包括JPEG,H.264等。
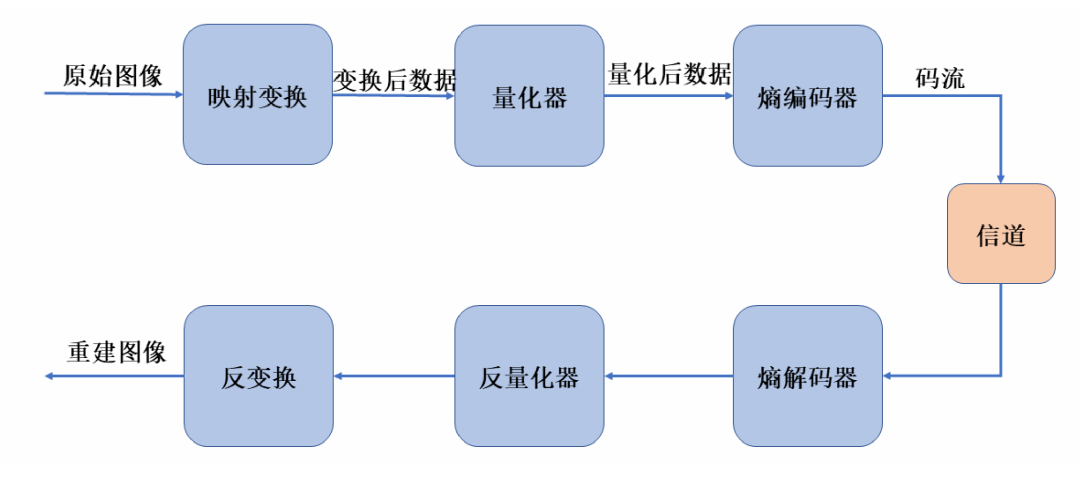
2.4.2 基于深度學習的圖像壓縮技術研究
傳統的編碼質量評估通常針對一些客觀的性能指標,對于比較主觀的質量指標和語義質量指標比較難以滿足其要求,也無法獲得圖像深層次的語義信息。因此,傳統的圖像壓縮編碼在這方面已經無法滿足現代的要求,深度學習和計算機視覺的發展進步帶來一種新的解決圖像壓縮編碼的問題方式:端到端的圖像壓縮能夠將圖像編碼中的各個模塊進行聯合優化,依靠數據自身進行評估。
2.5 圖像識別
圖像識別技術針對通過計算機視覺識別物體這一方向深入研究發展,在神經網絡等技術的發展下取得優異成就。圖像識別技術可劃分為兩類:傳統圖像識別算法和基于深度學習的圖像識別算法。
2.5.1 傳統圖像識別算法
傳統的圖像識別算法包括微分算子邊緣檢測算法、Canny邊緣檢測算法、角點檢測算法等。
Canny邊緣檢測算法: 一般包含4個步驟:濾波、梯度幅值和梯度方向計算、非極大值抑制計算、邊緣檢測與連接。首先通過高斯濾波函數去除圖像的噪聲,并對圖像進行平滑處理,接著通過一階有限差分法分別對濾波后的圖像水平和垂直方向的像素點進行偏導求解,再使用非極大值抑制算法將局部最大值之外的正負梯度值設置為0,最后通過不相同的2個閾值對候選邊緣圖像中的像素進行處理,保留兩閾值范圍內的像素,最終檢測出物體。傳統的Canny邊緣檢測算法降噪能力較差,同時使用4個具有各向異性的5階差分模板檢測多個方向上的像素點,不僅能夠檢測上下左右4個領域的灰度加權值,同時還能夠檢測對角線方向的值。為了提高Canny算法的自適應能力,采用自適應中值濾波和形態學閉合運算來防止多方向梯度幅值計算時邊緣信息被弱化,同時利用目標與背景的最佳分離點是最優梯度下最大的類間方差與最小的類內方差這一概念,來計算Canny算法中的上下閾值,以此來提高其自適應能力。
角點檢測算法: 是通過一個固定像素窗口在圖像中進行任意方向的滑動,比較滑動前后窗口中的像素灰度值,如果存在較大的變化,則可判斷出該像素內存在角點。角點檢測算法分為3類:基于二值圖像的角點檢測、基于灰度圖像的角點檢測和基于邊緣輪廓的角點檢測。傳統的Harris角點檢測算法精度較低,抗噪性差,將Sobel算法和Harris算法結合可以有效提高算法性能(首先使用Sobel算法進行角點初選,將非極大值抑制算法中的矩形模板用圓周模板替代,以此來提高檢測精度,最后使用臨近點剔除法提高算法的抗噪性)。通過比較階梯邊緣、L型拐角、Y或T型拐角、X型拐角和星型拐角的強度變化特性后,利用多尺度各向異性高斯方向導數濾波器,從輸入圖像中提取灰度變化的新方法能夠連續地提取圖像中的邊緣點和角點特征。
2.5.2 基于神經網絡學習的圖像識別算法
基于神經網絡學習的圖像識別算法主要可以分為卷積神經網絡、注意力神經網絡、自編碼神經網絡、生成網絡和時空網絡。卷積神經網絡是所有其他復雜網絡的基礎,基于CNN卷積神經網絡提出了一系列典型的框架: Le Net、Alex Net、Goole Net、VGGNet、Res Net、Inception、DenseNet。
03
FPGA與數字圖像處理
數字圖像由大量的像素組成,數字圖像處理算法通常基于未壓縮的原圖,以1920*1080 RGB格式 256灰度圖像為例,單幅圖像的數據量為1920*1080*3*8bit=6.22MB。DSP、GPU、CPU通常以幀為單位對圖像的處理,需要將采集圖像從內存讀取后進行處理,處理一幀的圖像都將耗費大量的時間,使得視頻圖像的幀率難以提高。
FPGA數字圖像處理的優勢在于以行為單位實時流水線運算,從而達到最高的實時性。FPGA可以直接與圖像傳感器芯片連接獲得圖像數據流,RAW格式還可以進行插值以獲得RGB圖像數據。FPGA通過內部Block RAM緩存若干行圖像數據實現實時流水線處理,FPGA的Block RAM類似于CPU的Cache,但是Cache不能完全控制,Block RAM完全可控,因此可以用它實現各種靈活的運算處理。
由于Block RAM在FPGA中的有限性,通常也可采用外接DDR將圖像緩存后讀出,但是這種處理模式類似于CPU從內存中讀取處理,無法達到最高的實時性。因此,如何合理利用Block RAM這一稀缺資源是充分發揮FPGA圖像處理實時性的關鍵。
FPGA對圖像數據流處理通常采用順序讀取,可以快速高效實現以3x3到NxN算子進行的濾波、腐蝕、膨脹、邊緣提取等算法,以及卷積神經網絡的卷積層運算,FPGA的并行特性決定了處理這種類型算法相比于其他處理器速度最快,優勢最大。盡管這種算法運算較為簡單,但通過不同算子的配合可以實現例如邊緣提取,運動目標識別等不同功能,同時可以滿足實時性的要求。
因此,FPGA的并行特性使之在圖像處理和深度學習領域存在一定的優勢,由于FPGA開發相對于DSP等嵌入式需要一定的門檻,導致該領域的工程師數量相對較少,對于FPGA擅長的功能有待進一步發掘。
審核編輯:劉清








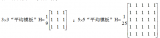
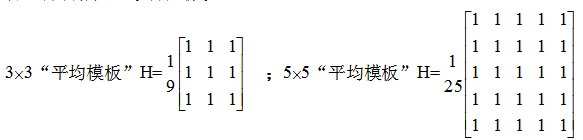





 工商網監
工商網監
評論