 電子發(fā)燒友App
電子發(fā)燒友App


摘要:自三十多年前問世以來,現(xiàn)場可編程門陣列(FPGAs)已被廣泛用于實(shí)現(xiàn)來自不同領(lǐng)域的無數(shù)應(yīng)用。由于其底層的硬件可重新配置性,與定制設(shè)計的芯片相比,F(xiàn)PGAs具有更快的設(shè)計周期和更低的開發(fā)成本。FPGA架構(gòu)的設(shè)計涉及許多不同的設(shè)計選擇,從高級架構(gòu)參數(shù)到晶體管級實(shí)現(xiàn)細(xì)節(jié),目標(biāo)是制造高度可編程的器件,同時最小化可重新配置的面積和性能成本。隨著應(yīng)用需求和工藝技術(shù)能力的不斷發(fā)展,F(xiàn)PGA架構(gòu)也必須適應(yīng)。在這篇文章中,我們回顧了現(xiàn)代商用FPGA架構(gòu)的不同關(guān)鍵組件的演變,并闡明了它們的主要設(shè)計原則和實(shí)現(xiàn)挑戰(zhàn)。
01簡介
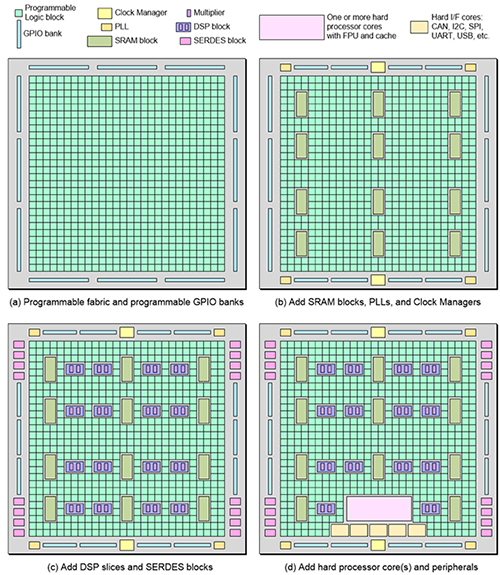
現(xiàn)場可編程門陣列(FPGAs)是可重構(gòu)的計算機(jī)芯片,可以通過編程實(shí)現(xiàn)任何數(shù)字硬件電路。如圖1所述,F(xiàn)PGAs由不同類型的可編程塊(邏輯、輸入輸出和其他)組成的陣列,這些可編程塊可以使用預(yù)制的布線通道與它們之間的可編程開關(guān)靈活地互連。所有FPGA塊的功能和布線開關(guān)的配置使用數(shù)百萬個靜態(tài)隨機(jī)存取存儲器(SRAM)單元來控制,這些SRAM在工作時被編程(即寫入)以實(shí)現(xiàn)特定功能。用戶用硬件描述語言(HDL)如Verilog或VHDL描述所需的功能,或者可能使用高級綜合將C或OpenCL翻譯成HDL。然后,使用復(fù)雜的計算機(jī)輔助設(shè)計(CAD)流程將HDL設(shè)計編譯成比特流文件,用于對FPGA的所有配置SRAM單元進(jìn)行編程。
與構(gòu)建定制專用集成電路(ASIC)相比,F(xiàn)PGAs的非重復(fù)性工程成本低得多,上市時間也短得多。預(yù)制的現(xiàn)成的FPGA可以用來在幾周內(nèi)實(shí)現(xiàn)一個完整的系統(tǒng),跳過了定制ASIC通常要經(jīng)歷的物理設(shè)計、布局、制造和驗(yàn)證階段。它們還允許持續(xù)的硬件升級,以支持新功能或通過在現(xiàn)場部署后簡單地加載新比特流來修復(fù)錯誤,因此稱為現(xiàn)場可編程。這使得FPGAs成為中小型設(shè)計的引人注目的解決方案,特別是在當(dāng)今市場產(chǎn)品周期快的情況下。FPGAs的比特級可重新配置性使得能夠?qū)崿F(xiàn)每個應(yīng)用所需的精確硬件(例如:數(shù)據(jù)路徑位寬、流水線級、并行計算單元的數(shù)量、存儲子系統(tǒng)等。)而不是通用處理器(CPUs)或圖形處理單元(GPUs)的固定的單一尺寸結(jié)構(gòu)。因此,通過實(shí)現(xiàn)無指令流硬件[1]或覆蓋有應(yīng)用定制流水線和指令集的處理器[2],它們可以實(shí)現(xiàn)比CPU或GPU更高的效率。
這些優(yōu)勢促使FPGAs在許多應(yīng)用領(lǐng)域采用,包括無線通信、嵌入式信號處理、網(wǎng)絡(luò)、ASIC原型、高頻交易等[3]–[7]。它們最近也被大規(guī)模部署在數(shù)據(jù)中心,以加速搜索引擎、數(shù)據(jù)包處理[9]和機(jī)器學(xué)習(xí)[10]等工作負(fù)載。然而,與ASIC相比,F(xiàn)PGA硬件的靈活性帶來了效率成本。庫恩和羅斯[11]表明,僅使用FPGA的電路比相應(yīng)的ASIC實(shí)現(xiàn)平均大35倍,慢4倍。最近的一項研究[12]表明,對于大量使用其他FPGA(如隨機(jī)存取存儲器和數(shù)字信號處理器)的全功能設(shè)計,這一面積差距有所縮小,但仍為9倍。FPGA設(shè)計師試圖盡可能地縮小這種效率差距,同時保持可編程性,使FPGA在廣泛的應(yīng)用中非常有用。
在這篇文章中,我們介紹了FPGA的關(guān)鍵原理,并強(qiáng)調(diào)了這些器件在過去30年的發(fā)展。圖1顯示了FPGAs如何從簡單的可編程邏輯陣列和輸入輸出模塊發(fā)展到復(fù)雜的異構(gòu)多芯片系統(tǒng),包括嵌入式模塊存儲、數(shù)字信號處理(DSP)模塊、處理器子系統(tǒng)、各種高性能外部接口、系統(tǒng)級互連等。首先,我們簡要概述了用于評估新的FPGA架構(gòu)思想的CAD流程和方法。然后,我們詳細(xì)介紹了一個FPGA的每個關(guān)鍵組件的架構(gòu)挑戰(zhàn)和設(shè)計原則。我們重點(diǎn)介紹了過去三十年來在這些組件的設(shè)計和實(shí)施方面的關(guān)鍵創(chuàng)新,以及正在進(jìn)行的研究領(lǐng)域。
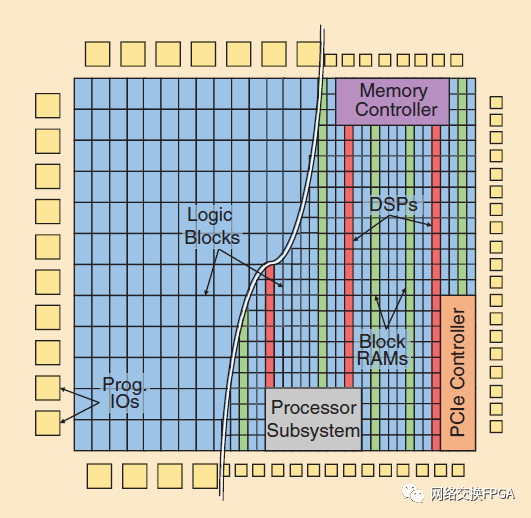
圖1:早期具有可編程邏輯和IOs的FPGA架構(gòu)與現(xiàn)代具有RAMs、DSPs和其他硬模塊的異構(gòu)FPGA架構(gòu)相比。所有模塊都使用比特級可編程布線進(jìn)行互連
02FPGA架構(gòu)評估
如圖2所示,F(xiàn)PGA架構(gòu)評估流程由三個主要組件組成:一套基準(zhǔn)應(yīng)用、一個架構(gòu)模型和一個CAD系統(tǒng)。與為特定功能構(gòu)建的ASIC不同,F(xiàn)PGA是為許多用例設(shè)計的通用平臺,其中一些用例甚至可能在FPGA構(gòu)建時不存在。因此,在實(shí)現(xiàn)代表關(guān)鍵FPGA市場和應(yīng)用領(lǐng)域的各種基準(zhǔn)設(shè)計時,將根據(jù)效率來評估FPGA架構(gòu)。通常,每個FPGA供應(yīng)商都有一套精心選擇的基準(zhǔn)設(shè)計,這些設(shè)計是從專有系統(tǒng)實(shí)現(xiàn)和各種客戶應(yīng)用中收集的。還有幾個開源基準(zhǔn)套件,如經(jīng)典的MCNC20[13]、VTR[14]和Titan23[15]套件,這些在學(xué)術(shù)FPGA架構(gòu)和CAD研究中是常用的。雖然早期的學(xué)術(shù)FPGA研究使用了MCNC設(shè)計套件,但這些電路現(xiàn)在太小(數(shù)千個邏輯原語)和太簡單(只有輸入輸出和邏輯),無法代表現(xiàn)代FPGA用例。VTR,尤其是Titan套件更大、更復(fù)雜,使它們更具代表性,但隨著FPGA容量和應(yīng)用復(fù)雜性的不斷增長,通常需要新的基準(zhǔn)套件。
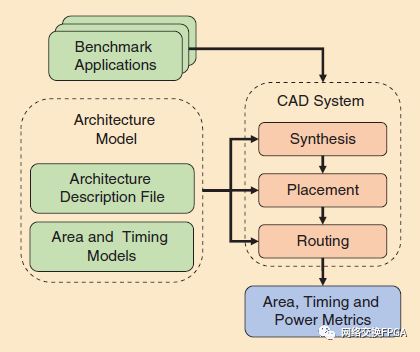
圖2:FPGA架構(gòu)評估流程
評估流程的第二部分是FPGA架構(gòu)模型。FPGA的設(shè)計涉及來自架構(gòu)級組織的許多不同決策(例如塊的數(shù)量和類型、線段長度的分布、邏輯簇和邏輯元件的大小)到晶體管級電路實(shí)現(xiàn)(例如可編程開關(guān)類型、布線緩沖器晶體管大小、寄存器實(shí)現(xiàn))。還涉及到不同的實(shí)現(xiàn)風(fēng)格;邏輯塊和可編程布線被設(shè)計和布局為全定制的電路,而大多數(shù)硬化的塊(例如DSP)分別為模塊內(nèi)核和外設(shè)混合了標(biāo)準(zhǔn)單元和全定制設(shè)計。一些模塊(存儲、輸入輸出)甚至包括重要的模擬電路。所有這些不同的組件都需要仔細(xì)建模,以評估整個FPGA架構(gòu)。除
了從每個組件的電路級實(shí)現(xiàn)中獲得的面積、時序和功率模型之外,這通常使用架構(gòu)描述文件來獲取,架構(gòu)描述文件指定不同的FPGA塊和布線架構(gòu)的組織和類型。
最后,使用可重定位的CAD系統(tǒng),如VTR [14],將選定的基準(zhǔn)應(yīng)用映射到指定的FPGA架構(gòu)上。這種CAD系統(tǒng)由一系列復(fù)雜的優(yōu)化算法組成,這些算法將寫在HDL中的基準(zhǔn)綜合為電路網(wǎng)表,將其映射到不同的FPGA塊,將映射的塊放置在FPGA上的特定位置,并使用指定的可編程布線架構(gòu)在它們之間布線連接。然后,我們用由CAD系統(tǒng)產(chǎn)生的實(shí)現(xiàn)來評估幾個關(guān)鍵指標(biāo)。總面積是應(yīng)用使用的FPGA塊的總面積,以及其中包含的可編程布線。時序分析器找到通過塊和布線的關(guān)鍵路徑,以確定應(yīng)用時鐘的最大頻率。功耗是根據(jù)使用的資源和信號切換速率來估計的。FPGAs從來不是為一個應(yīng)用設(shè)計的,所以這些指標(biāo)在所有基準(zhǔn)中是平均的。最后,根據(jù)架構(gòu)目標(biāo)(例如高性能或低功率)。其他指標(biāo),如CAD工具運(yùn)行時間以及CAD工具未能在一個架構(gòu)上布線一些基準(zhǔn)也經(jīng)常被考慮。
例如,F(xiàn)PGA架構(gòu)中的一組關(guān)鍵問題是: 在FPGA架構(gòu)中應(yīng)該硬化什么功能(即作為新的ASIC風(fēng)格的塊實(shí)現(xiàn))?這個塊應(yīng)該有多靈活?FPGA芯片面積應(yīng)該有多少專用于它?理想情況下,F(xiàn)PGA架構(gòu)師希望以盡可能低的硅成本為盡可能多的應(yīng)用提供硬化功能。與僅在可編程結(jié)構(gòu)中實(shí)現(xiàn)相比,能夠利用硬模塊的應(yīng)用將受益于更小、更快和更節(jié)能。這促使在硬模塊中有更多的可編程性來捕獲更多的用例;然而,更高的靈活性通常以更大的面積和降低的硬模塊效率為代價。另一方面,如果應(yīng)用電路不能使用硬模塊,則浪費(fèi)其硅面積;FPGA用戶寧愿在未使用的硬模塊區(qū)域有更多可用的通用邏輯塊。還必須考慮這種新的硬模塊對可編程布線的影響——它需要更多的互連還是會導(dǎo)致進(jìn)出該塊的布線路徑變慢?為了評估一個特定的功能是否應(yīng)該被硬化,硬化的成本和收益必須使用本節(jié)描述的流程根據(jù)經(jīng)驗(yàn)進(jìn)行量化。FPGA架構(gòu)師在找到正確的設(shè)計選擇組合之前,可能會嘗試許多想法,這些設(shè)計選擇在正確的位置添加了正確的可編程性,使這種新的硬模塊取得了最終的勝利。
在下一節(jié)中,我們將詳細(xì)介紹FPGAs的許多不同組件以及每個組件的關(guān)鍵架構(gòu)問題。雖然我們描述了關(guān)鍵結(jié)果,但沒有詳細(xì)說明用于發(fā)現(xiàn)它們的實(shí)驗(yàn)方法,一般來說,它們來自類似于圖2中的整體架構(gòu)評估流程。
03FPGA架構(gòu)演進(jìn)
3.1 可編程序邏輯
最早的可重構(gòu)計算器件是可編程邏輯(PAL)架構(gòu)。如圖3所示,PALs由一個“與”門陣列和另一個“或”門陣列組成,并且可以將布爾邏輯表達(dá)式實(shí)現(xiàn)為兩級積和函數(shù)。PALs通過可編程開關(guān)實(shí)現(xiàn)可配置性,可編程開關(guān)選擇每個與/或門的輸入來實(shí)現(xiàn)不同的布爾表達(dá)式。因?yàn)闊o論實(shí)現(xiàn)什么邏輯功能,通過器件的延遲都是不變的,所以用于器件的設(shè)計工具非常簡單。但是,PALs的擴(kuò)展性不好;隨著器件邏輯容量的增加,形成與/或陣列的導(dǎo)線變得越來越長、越來越慢,所需的可編程開關(guān)數(shù)量也呈二次增長。
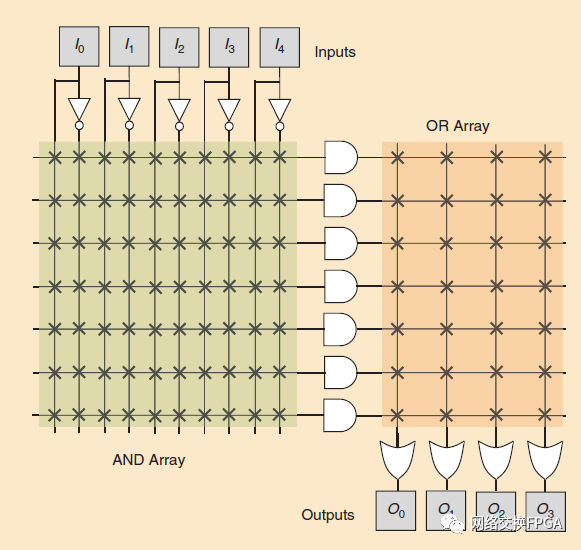
圖3:可編程陣列邏輯(PAL)架構(gòu),帶有一個“與”陣列,饋入到“或”陣列。叉是可重新配置的開關(guān),用于將任何布爾表達(dá)式編程為兩級的積和函數(shù)
隨后,復(fù)雜可編程邏輯器件(CPLDs)保留了與/或陣列作為基本邏輯元件,但試圖以更復(fù)雜的設(shè)計工具為代價,通過在同一芯片上集成多個具有交叉互連的PALs來解決可擴(kuò)展性挑戰(zhàn)。不久之后,Xilinx在1984年首創(chuàng)了第一個基于查找表的(基于LUT的)FPGA,它由一系列基于SRAM的LUTs組成,它們之間有可編程的互連。這種類型的可重構(gòu)器件顯示出很好的可擴(kuò)展性,與PALs和CPLDs中的與/或邏輯相比,LUTs實(shí)現(xiàn)了更高的面積效率。因此,基于LUT的架構(gòu)變得越來越占優(yōu)勢,今天LUTs構(gòu)成了所有商用FPGAs的基本邏輯元件。幾項研究[16]–[18]嘗試研究了用不同形式的可配置與門來替換LUTs:一種具有可編程輸出/輸入反轉(zhuǎn)的與門的完整二進(jìn)制樹,稱為與-反相器錐(AIC)。然而,當(dāng)在[19]中進(jìn)行全面評估時,基于AIC的FPGA架構(gòu)比基于LUT架構(gòu)面積大得多,延遲增益僅在關(guān)鍵路徑較短小的基準(zhǔn)上。
K-LUT可以通過在配置SRAM單元中存儲真值表來實(shí)現(xiàn)任何K輸入布爾函數(shù)。K個輸入信號被用作多路復(fù)用器選擇線,從真值表的個值中選擇一個輸出。圖4(a)展示出了使用傳輸晶體管邏輯的4-LUT的晶體管級電路實(shí)現(xiàn)。除了輸出緩沖器之外,還有一個內(nèi)部緩沖級(如圖4(a)中LUT的第二級和第三級之間所示),通常是為了減小當(dāng)通過一串傳輸晶體管時的二次增加延遲而實(shí)現(xiàn)的。LUT的傳輸晶體管和內(nèi)部/輸出緩沖器的尺寸經(jīng)過精心調(diào)整,以實(shí)現(xiàn)最佳的面積延遲積。經(jīng)典的FPGA文獻(xiàn)[20]將基本邏輯元件(BLE)定義為與輸出寄存器耦合并旁路2:1多路復(fù)用器的K-LUT,如圖4(c)所示。因此,一個BLE既可以實(shí)現(xiàn)一個觸發(fā)器(FF),也可以實(shí)現(xiàn)一個帶有寄存或未寄存輸出的LUT觸發(fā)器.如圖4(d)所示,BLEs通常在邏輯塊(LBs)中聚合,使得LBs包含N個BLEs以及局部互連。邏輯塊中的局部互連由信號源(BLE輸出和邏輯塊輸入)和目的地(BLE輸入)之間的多路復(fù)用器組成。這些多路復(fù)用器通常被安排成形成局部完全交叉開關(guān)[21]或部分交叉開關(guān)[22]。在電路級,這些多路復(fù)用器通常由兩級傳輸晶體管構(gòu)成,后面是一個兩級緩沖器,如圖4(b)所示;在大多數(shù)情況下,這是FPGA多路復(fù)用器最有效的電路設(shè)計[23]。圖4(d)還示出了形成可編程布線的開關(guān)和連接塊多路復(fù)用器,其允許邏輯塊相互連接;第三章第二節(jié)詳細(xì)討論了這種布線。
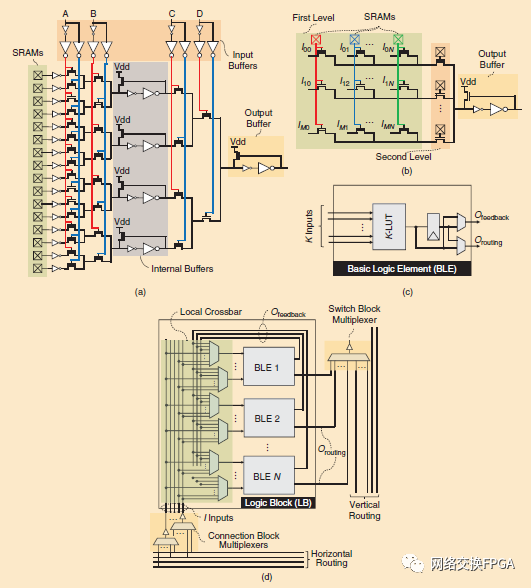
圖4:(a) 在第二和第三LUT級之間具有內(nèi)部緩沖器的4-LUT晶體管級實(shí)現(xiàn)(b) 兩級多路復(fù)用器電路(c)基本邏輯單元(BLE)和(d)邏輯塊內(nèi)部結(jié)構(gòu)
多年來,隨著器件邏輯容量的增長,LUTs(K)和LBs (N)的大小逐漸增加。隨著K的增加,更多的功能可以封裝到單個LUT中,不僅減少了所需的LUTs數(shù)量,而且減少了關(guān)鍵路徑上的邏輯級數(shù)量,從而提高了性能。此外,隨著越來越多的連接通過增加N而被捕獲到快速局部互連中,對LB間布線的需求減少。另一方面,LUT的面積隨K成指數(shù)增長(由于2的k次方SRAM單元),其速度線性下降(因?yàn)槎嗦窂?fù)用器構(gòu)成了具有周期性緩沖的K個傳輸晶體管的鏈)。如果LB局部互連實(shí)現(xiàn)為交叉開關(guān),其大小會呈四次方增長,速度會隨著LB中的BLEs數(shù)量呈線性下降。Ahmed和Rose[24]根據(jù)經(jīng)驗(yàn)評估了這些權(quán)衡,并得出結(jié)論,4-6尺寸的LUT和3-10尺寸的BLEs為FPGA架構(gòu)提供了最佳的面積延遲積,4-LUTs導(dǎo)致更好的面積,但6-LUTs產(chǎn)生更高的速度。歷史上,Xilinx的第一個基于LUT的FPGA,1984年的XC2000系列,有一個只包含兩個3-LUTs的LB(即N = 2,K = 3)。LB尺寸隨著時間的推移逐漸增加,到1999年,Xilinx的Virtex系列包括四個4-LUTs,Altera的Apex 20K系列包括每個LB中的十個4-LUTs。
架構(gòu)的下一個重大變化來自2003年的Altera,在他們的Stratix II架構(gòu)中引入了可分割的LUT[25]。Ahmed和Rose在[24]中表明,10個6-LUTs的LB比10個4-LUTs的LB性能高14%,但面積高17%。可分割LUTs試圖結(jié)合兩者的優(yōu)點(diǎn),實(shí)現(xiàn)更大LUTs的性能和更小LUTs的面積效率。傳統(tǒng)6-LUTs面積增加的一個主要因素是利用率低。Lewis et al.發(fā)現(xiàn)64%的嵌入式應(yīng)用中的LUTs使用少于6個輸入,浪費(fèi)了一些6-LUT的功能[26]。一個可分割的{K,M}-LUT可以配置為一個大小為K的單個LUT,也可以分割為兩個大小不超過K–1的LUTs,這些LUTs共同使用不超過K + M個不同的輸入。圖5(a)顯示6-LUT內(nèi)部由兩個5-LUTs和一個2:1多路復(fù)用器組成。因此,幾乎不需要任何電路(只有紅色的附加輸出)來允許6-LUTs作為共享相同輸入的兩個5-LUTs工作。然而,要求兩個5-LUTs共享它們的所有輸入將限制兩者同時使用的頻率。添加額外的布線端口,如圖5(b),增加了可分割的6-LUT的面積,但更容易找到兩個可以組合在一起的邏輯功能。Stratix II架構(gòu)中的自適應(yīng)邏輯模塊(ALM)實(shí)現(xiàn)了一個{6,2}-LUT,它有8個輸入和2個輸出端口。因此,一個ALM可以實(shí)現(xiàn)y一個6-LUT或兩個5-LUTs共享2個輸入(因此總共有8個不同的輸入)。成對的較小LUTs也可以在沒有任何共享輸入的情況下實(shí)現(xiàn),例如兩個4LUTs或一個5-LUT和一個3-LUT。利用可分割的6-LUT,在6-LUTs中實(shí)現(xiàn)了更大的邏輯功能,降低了關(guān)鍵路徑上的邏輯級,實(shí)現(xiàn)了性能改進(jìn)。另一方面,較小的邏輯功能可以打包在一起(每個只使用半個ALM),提高了面積效率。與基準(zhǔn)的基于4 LUT的LB相比,LBin Stratix II不僅性能提高了15%,而且邏輯和布線面積也減少了2.6%。
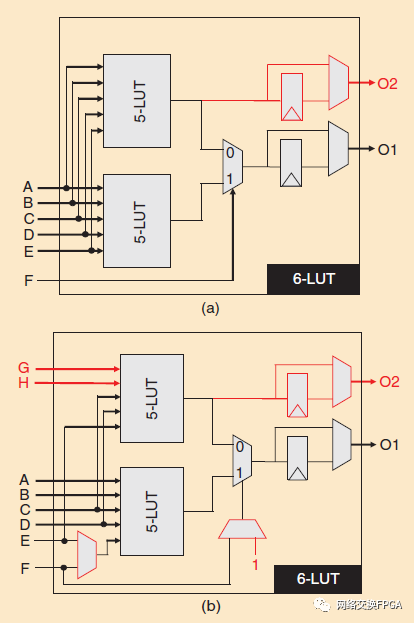
圖5: 6-LUT可分為兩個5-查找表,其中(a)沒有額外的輸入端口,導(dǎo)致5個共享輸入(A-E)或(b)兩個額外的輸入端口和轉(zhuǎn)向多路復(fù)用器,導(dǎo)致只有2個共享輸入(C,D)
Xilinx后來在其Virtex-5架構(gòu)中采用了相關(guān)的可分割LUT方法。像Stratix II一樣,Virtex-5 6-LUT可以分解成兩個5-LUT。然而,Xilinx選擇最小化增加的額外電路,以提高分割性,如圖5(a)所示。——不添加額外的輸入布線端口或轉(zhuǎn)向多路復(fù)用器。這導(dǎo)致每個可分割LUT的面積更小,但是由于它們必須使用不超過5個不同的輸入,所以將兩個更小的LUTs打包在一起更加困難[27]。雖然Altera/Intel和Xilinx的后續(xù)架構(gòu)也是基于可分割的6-LUTs,但最近的一項Microsemi研究[28]重新審視了4-LUT與6-LUT之間的效率權(quán)衡,該權(quán)衡針對的是比之前使用的更新的工藝技術(shù)、計算機(jī)輔助設(shè)計工具和設(shè)計。它表明,一個具有兩個緊密耦合的4路LUTs的LUTs結(jié)構(gòu),一個饋送另一個,可以獲得接近普通6-LUTs的性能,同時具有4路LUTs的面積和功率優(yōu)勢。就LB尺寸而言,Altera/Intel和Xilinx的FPGA架構(gòu)在幾代的時間里分別使用了10個和8個BLEs的相對較大的LB。然而,Xilinx最近宣布的Versal架構(gòu)進(jìn)一步將每個LB中的BLEs的數(shù)量增加到32[29]。這種大幅增長的原因有兩個方面。首先,LB之間的線路延遲隨著工藝的縮小而縮小,因此在LB的局部布線中捕獲更多的連接越來越有利。其次,越來越大的FPGA設(shè)計往往會增加CAD工具的運(yùn)行時間,但更大的LBs可以通過簡化布局和LB間布線來幫助緩解這一趨勢。
另一個重要的架構(gòu)選擇是每個BLE的FFs數(shù)量。早期的FPGA將一個(不可分割的)LUT與一個FPGA連接起來,如圖4(c)所示。當(dāng)他們轉(zhuǎn)移到可分割的LUTs時,Altera/Intel和Xilinx架構(gòu)都給每個BLE增加了第二個LUTs,這樣就可以將分割后的LUT的兩個輸出都寄存,如圖5(a)和5(b)所示。在Stratix V架構(gòu)中,隨著設(shè)計變得更加深入流水線化以實(shí)現(xiàn)更高的性能,每個BLE的FFs數(shù)量進(jìn)一步從2個增加到4個,以適應(yīng)對FFs不斷增長的需求[30]。低成本多路復(fù)用電路允許在LUTs和FFs之間共享現(xiàn)有的輸入,以避免增加更昂貴的布線端口。Stratix V將FFs實(shí)現(xiàn)為脈沖鎖存器,而不是邊沿觸發(fā)的FFs。如圖6(b)所示,這移除了主從鎖存中的兩個鎖存器中的一個(圖6(a)),減少寄存器延遲和面積。一個脈沖鎖存器充當(dāng)一個更便宜的FF,它的保持時間更長,因?yàn)樗诜浅6痰拿}沖期間而不是像傳統(tǒng)的FF那樣在時鐘沿鎖存數(shù)據(jù)輸入。如果為每個FF建造一個脈沖發(fā)生器,每個FF的總面積將增加而不是減少。相反,Stratix V每個LB只包含兩個可配置的脈沖發(fā)生器;LB中的40個脈沖鎖存器中的每一個都選擇哪個發(fā)生器提供它的脈沖輸入。FPGA的CAD工具還可以對這些發(fā)生器的脈沖寬度進(jìn)行編程,允許在源寄存器和目的寄存器之間借用有限的時間。更長的脈沖會進(jìn)一步降低保持時間,但通常任何違反保持時間的情況都可以通過使用更長的布線路徑來延遲信號的FPGA布線算法來解決。在Ultrascale+架構(gòu)中,Xilinx還使用脈沖鎖存器作為其FFs[31]。
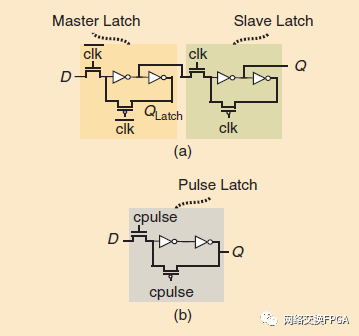
圖6:用于(a)主從正邊沿觸發(fā)觸發(fā)器和(b)脈沖鎖存器的電路
算術(shù)運(yùn)算(加法和減法)在FPGA設(shè)計中非常常見: Murray等人.發(fā)現(xiàn)在一套FPGA設(shè)計中,22%的邏輯元件都在實(shí)現(xiàn)算法[32]。雖然這些操作可以用LUTs來實(shí)現(xiàn),但行波進(jìn)位加法器中的每個算術(shù)位都需要兩個LUTs(一個用于求和輸出,一個用于進(jìn)位)。這導(dǎo)致了高邏輯利用率和緩慢的關(guān)鍵路徑,因?yàn)榇?lián)的任何LUTs都要計算多位加法的進(jìn)位.因此,所有現(xiàn)代的FPGA架構(gòu)都在其邏輯塊中包含了硬件算術(shù)電路。變體很多,但都有幾個共同點(diǎn)。首先,為了避免增加昂貴的布線端口,算術(shù)電路重復(fù)使用LUT布線端口或由LUT輸出饋送。其次,進(jìn)位位在特殊的專用互連上傳播,幾乎沒有或根本沒有可編程性,因此關(guān)鍵的進(jìn)位路徑是快速的。最低成本的算術(shù)電路硬化了行波進(jìn)位結(jié)構(gòu),并在LUTs上實(shí)現(xiàn)了較大的速度增益(在[32]中,32位加法器的速度增益為3.4)。硬化更復(fù)雜的結(jié)構(gòu),如進(jìn)位跳躍加法器,進(jìn)一步提高了速度(在[33]中,32位時速度增加了20%)。Xilinx的最新Versal架構(gòu)硬化了8位超前進(jìn)位加法器的進(jìn)位邏輯(即加法只能從每八個BLE開始),而求和、傳播和產(chǎn)生邏輯都是在可分割的6-LUTs中實(shí)現(xiàn)的,這些LUTs提供進(jìn)位邏輯,如圖7(a)所示[29]。這種組織允許每個邏輯元件實(shí)現(xiàn)1位算術(shù)。另一方面,最新的Intel Agilex架構(gòu)可以為每個邏輯元件實(shí)現(xiàn)2位算術(shù),邏輯元件之間的進(jìn)位具有專用的互連,如圖所示7(b)。它通過硬化2位進(jìn)位跳躍加法器來實(shí)現(xiàn)這一點(diǎn),該加法器由包含在6-LUT[34]中的4個4位LUTs饋送。Murray等人的研究[32]表明,與不可分割LUTs或每個邏輯元件一位算術(shù)的架構(gòu)相比,可分割LUTs和兩位算術(shù)的組合(類似于Altera/Intel FPGAs中采用的)特別有效。它還得出結(jié)論,在FPGA邏輯元件中專用的算術(shù)電路(即硬化加法器和進(jìn)位鏈)分別將算術(shù)微基準(zhǔn)電路和通用基準(zhǔn)電路的平均性能提高了75%和15%。
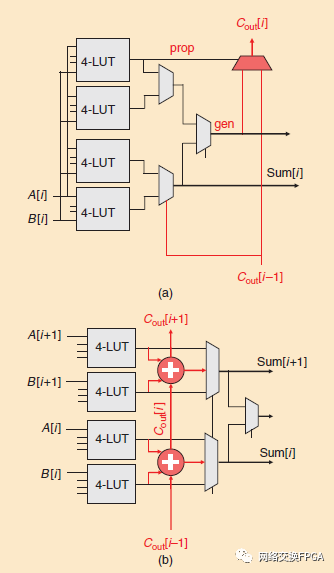
圖7:(a) Xilinx和(b) Altera/Intel FPGAs邏輯元件中的硬算術(shù)電路概述(紅色)。A[i]和B[i]是兩個加法操作數(shù)A和B的第i位。Xilinx LEs在查找表中計算進(jìn)位傳播和產(chǎn)生,而Altera/Intel使用查找表將輸入傳遞給硬加法器。實(shí)現(xiàn)加法器時,未標(biāo)記的輸入未被使用
最近,深度學(xué)習(xí)(DL)已經(jīng)成為許多終端用戶應(yīng)用的關(guān)鍵工作負(fù)載,其核心操作是乘加(MAC)。一般來說,MAC可以在數(shù)字信號處理器模塊中實(shí)現(xiàn),這將在第三章第五節(jié)中描述;然而,具有8位或更窄操作數(shù)的低精度MAC(在數(shù)字邏輯工作負(fù)載中變得越來越普遍)也可以在可編程邏輯中有效地實(shí)現(xiàn)[9]。LUTs用于生成乘法器陣列的部分積,然后是加法器樹,以減少部分積并執(zhí)行累加。因此,最近的多項研究[35]–[37]研究了如何增加FPGA邏輯結(jié)構(gòu)中硬化加法器的密度,以提高其在實(shí)現(xiàn)算術(shù)繁重的應(yīng)用(如DL加速)時的性能。[36]和[37]中的工作提出了多種不同的邏輯塊架構(gòu),每個邏輯單元包含4位算術(shù)運(yùn)算,排列在一個或兩個具有不同配置的進(jìn)位鏈中,而不是在類似Intel Stratix ALM中只有的2位算術(shù)運(yùn)算。由于乘法器陣列中的高度輸入共享,這些方案在實(shí)現(xiàn)乘法時不需要增加邏輯簇中的(相對昂貴的)布線端口的數(shù)量(即,對于N位乘法器,僅需要2N個輸入來生成N平方部分積)。這些提議中最有希望的一個將MAC操作的密度提高了1.7倍,同時提高了速度。它還將一般基準(zhǔn)測試所需的邏輯和布線面積減少了8%,突出了更多的算法密度對除了DL以外的應(yīng)用是有益的。
3.2 可編程布線
可編程布線通常占應(yīng)用的結(jié)構(gòu)面積和關(guān)鍵路徑延遲的50%以上[38],因此其效率至關(guān)重要。可編程布線由預(yù)制接線段和可編程開關(guān)組成。通過將適當(dāng)?shù)拈_關(guān)序列編程為接通,任何功能塊輸出都可以連接到任何輸入。FPGA布線架構(gòu)主要有兩類。分層次的FPGAs的靈感來源于這樣一個事實(shí),即設(shè)計本質(zhì)上是分層的:高級模塊實(shí)例化低級模塊,并在它們之間連接信號。在設(shè)計層次中,相互靠近的模塊之間的通信更加頻繁,層次化的FPGA可以通過連接芯片小區(qū)域的短線來實(shí)現(xiàn)這些連接。如圖8所示,為了與層次化的FPGA的更遠(yuǎn)的區(qū)域進(jìn)行通信,一個連接(用紅色突出顯示)在穿過互連層次的不同級時通過多條線路和開關(guān)。這種風(fēng)格的架構(gòu)在許多早期的FPGAs中很受歡迎,如Altera的7K和Apex20K系列,但它會導(dǎo)致互連層次結(jié)構(gòu)上層的線路非常長,隨著工藝長度的縮減,這種導(dǎo)線的電阻越來越大,這就成了問題。嚴(yán)格的分層布線架構(gòu)還會導(dǎo)致一些塊在物理上靠得很近(例如圖8中的藍(lán)色塊)仍然需要幾根線和開關(guān)來連接。因此,它現(xiàn)在主要用于較小的FPGA,例如可以嵌入大型SoC設(shè)計中的FlexLogix FPGA IP核[39]。
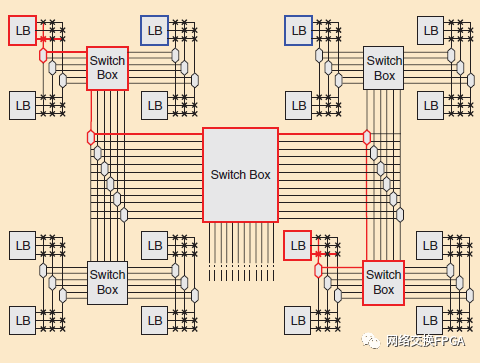
圖8:在層次化FPGAs中的布線架構(gòu)
另一種類型的FPGA互連是島式的,如圖9所示。該架構(gòu)由Xilinx首創(chuàng),其靈感來源于這樣一個事實(shí),即水平和垂直定向線段的規(guī)則二維布局可以有效地布局。如圖9所示,島式布線包括三個部分:布線線段、將功能塊輸入連接到布線的連接塊(多路復(fù)用器)和將布線連接在一起以實(shí)現(xiàn)更長布線的開關(guān)塊(可編程開關(guān)).FPGA CAD工具中的布局引擎選擇哪個功能塊實(shí)現(xiàn)設(shè)計的每個元件,以最小化所需的布線。因此,大多數(shù)功能塊之間的連接跨越很小的距離,并且可以用一些布線來實(shí)現(xiàn),如圖9中的紅色連接所示。
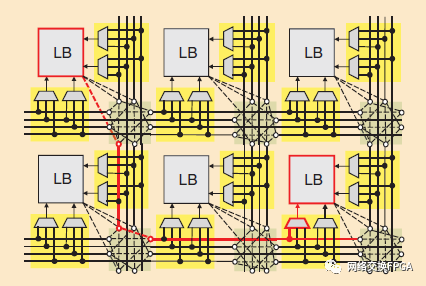
圖9:島式布線架構(gòu)。粗實(shí)線是走線,而虛線是可編程開關(guān)。連接塊和開關(guān)塊分別用黃色和綠色陰影表示
創(chuàng)建一個好的布線架構(gòu)需要管理復(fù)雜的權(quán)衡。它應(yīng)該包含足夠多的可編程開關(guān)和線段,以使絕大多數(shù)電路都能實(shí)現(xiàn);然而,過多的電線和開關(guān)浪費(fèi)了面積。布線架構(gòu)也應(yīng)符合應(yīng)用的需要:理想情況下,短連接將使用短導(dǎo)線,以最小化電容和版圖面積,而長連接可以使用較長的布線段,以避免通過許多布線開關(guān)的額外延遲。一些布線架構(gòu)參數(shù)包括:每個邏輯塊輸入或輸出可以連接多少條布線線(Fc),每條布線線可以連接多少條其他布線線(Fs),布線線段的長度,布線開關(guān)模式,線路和開關(guān)本身的電氣設(shè)計,以及每個通道的布線線數(shù)量[20]。例如在圖9,F(xiàn)c = 3,F(xiàn)s = 3,通道寬度為4條導(dǎo)線,一些布線長度為1,而其他布線長度為2.針對目標(biāo)應(yīng)用和特定流程節(jié)點(diǎn),全面評估這些權(quán)衡需要使用完整的CAD流程進(jìn)行實(shí)驗(yàn),詳見第二節(jié)。
早期的島式架構(gòu)只包含了可編程開關(guān)之間穿過單個邏輯塊的短線。后來的研究表明,這導(dǎo)致可編程開關(guān)比需要的多,并且在終止前使所有布線段跨越四個邏輯塊將應(yīng)用延遲減少40%,布線面積減少25% [40]。現(xiàn)代架構(gòu)包括多種長度的接線段,以更好地滿足短連接和長連接的需要,但最豐富的接線段仍然是中等長度,四個邏輯塊是一種流行的選擇。較長距離的連接可以使用較長的電線段來實(shí)現(xiàn)較低的延遲,但是在最近的工藝節(jié)點(diǎn),跨越許多(例如16)邏輯模塊必須在上部金屬層上使用寬而厚的金屬走線,以獲得可接受的電阻[41]。這種長距離布線可以包含在金屬疊層中的數(shù)量是有限的。為了更好地利用這種稀缺的布線,Intel的Stratix FPGAs允許長線段僅連接到短線段,而不是功能塊輸入或輸出[42]。這在島式的FPGA中創(chuàng)建了一種布線層次結(jié)構(gòu),其中短連接只使用較短的導(dǎo)線,而較長的連接通過短導(dǎo)線到達(dá)長導(dǎo)線網(wǎng)絡(luò)。在島式FPGA中使用層次化FPGA概念的另一個領(lǐng)域是邏輯塊。如圖4(d)所示,大多數(shù)邏輯塊現(xiàn)在將多個BLEs與局部布線組合在一起。這意味著每個邏輯塊都是層次化FPGA中的一個小簇;島式布線連接成千上萬個邏輯簇。
關(guān)于開關(guān)的最佳數(shù)量以及如何最好地安排開關(guān),已經(jīng)有了大量的研究。雖然有許多詳細(xì)的選擇,但還是出現(xiàn)了一些原則。首先,功能塊引腳和導(dǎo)線(Fc)之間的連接性可能相對較低:通常只有10%或更少的導(dǎo)線經(jīng)過引腳時會有開關(guān)與之連接。類似地,布線線路在其末端(Fs)可以連接的其他線路的數(shù)量也可以很少,但是它應(yīng)該至少為3,以便信號可以在線路端點(diǎn)向左、向右或向右轉(zhuǎn)向。邏輯簇中的局部布線(在第三章中第一節(jié)描述)允許在布線過程中交換一些塊輸入和一些塊輸出。通過利用這種額外的靈活性,并考慮多級可編程布線網(wǎng)絡(luò)提供的所有選項,布線CAD工具即使在Fc和Fs值較低的情況下也可以實(shí)現(xiàn)較高的完成率。為CAD工具提供更多選項的開關(guān)模式也有助于布線;例如,Wilton開關(guān)模式確保遵循不同的通道序列,讓布線器到達(dá)目的塊附近的不同線段[43]。
可編程開關(guān)的電氣設(shè)計也有多種選擇,如圖10。早期的FPGA使用由SRAM單元控制的傳輸門晶體管來連接導(dǎo)線。雖然這是傳統(tǒng)CMOS工藝中可能的最小開關(guān),但通過晶體管串聯(lián)的走線延遲呈二次方增長,這使得它們對于大面積FPGA來說非常慢。添加一些三態(tài)緩沖開關(guān)會增加面積,但會提高速度[40]。如圖4(b)所示,最近的FPGAs主要使用由傳輸門構(gòu)建的多路復(fù)用器,其后是不能三態(tài)化的緩沖器。這種直接驅(qū)動開關(guān)中的傳輸晶體管可以很小,因?yàn)樗鼈兊呢?fù)載很輕,而緩沖器可以更大,以驅(qū)動布線線段周圍的大電容。這種直接驅(qū)動開關(guān)對開關(guān)模式產(chǎn)生了一個主要的限制:一根導(dǎo)線只能在一個點(diǎn)上被驅(qū)動,因此只有功能塊輸出和該點(diǎn)附近的布線導(dǎo)線才能饋送到布線多路復(fù)用器的輸入,因此可能是信號源。盡管有這種限制,學(xué)術(shù)界和工業(yè)界都認(rèn)為直接驅(qū)動開關(guān)由于其優(yōu)越的電氣特性而提高了面積和速度[42],[44]。例外情況是昂貴或稀有的導(dǎo)線,如在上層金屬層的寬金屬跡線上實(shí)現(xiàn)的長導(dǎo)線或第三章第七節(jié)中討論的跨中介層導(dǎo)線。這些線路通常有多個三態(tài)緩沖器來驅(qū)動它們,因?yàn)檫@些較大的可編程開關(guān)的成本值得允許更靈活地使用這些昂貴的線路。
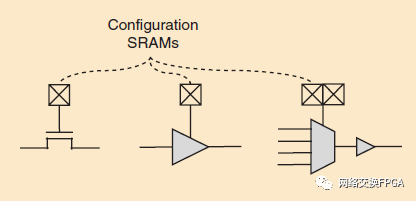
圖10: SRAM控制的可編程開關(guān)的不同實(shí)現(xiàn),使用傳輸晶體管(左)、三態(tài)緩沖器(中)或緩沖多路復(fù)用器(右)。
FPGA布線的一個主要挑戰(zhàn)是,長導(dǎo)線的延遲沒有隨著工藝尺寸的縮小而改善,這意味著即使時鐘頻率上升,穿過芯片的延遲也會停滯或增加。這使得FPGA應(yīng)用開發(fā)人員增加了他們設(shè)計中的流水線數(shù)量,從而允許長布線有多個時鐘周期。為了使這種策略更加有效,一些FPGA制造商已經(jīng)將寄存器集成到布線網(wǎng)絡(luò)本身中。Intel的Stratix10器件允許每個布線驅(qū)動器(即多路復(fù)用器后接一個緩沖器)被配置為脈沖鎖存器,如6(b)所示,從而充當(dāng)延遲低但保持時間相對較差的寄存器。這允許在不使用昂貴的邏輯資源的情況下進(jìn)行互連的深度管道化,代價是適度的面積和布線驅(qū)動器的延遲增加[45]。保持時間問題意味著在直接連續(xù)的Stratix布線開關(guān)中使用脈沖鎖存器是不可能的,因此Intel在其下一代Agilex器件中改進(jìn)了這種方法,只在三分之一的互連驅(qū)動器(以降低面積成本)上集成了當(dāng)前的寄存器(保持時間更短)[34]。Xilinx的Versal器件不是通過互連集成寄存器,而是只在功能塊的輸入端添加旁路寄存器。與Intel的互連寄存器不同,這些輸入寄存器功能齊全,具有時鐘使能和清除信號[46]。
3.3 可編程輸入輸出
FPGA包括獨(dú)特的可編程IO結(jié)構(gòu),使它們能夠與各種各樣的其他器件通信,使FPGA成為許多系統(tǒng)的通信基礎(chǔ)。對于一組物理接口來說,有計劃地支持許多不同的IO接口和標(biāo)準(zhǔn)是一項挑戰(zhàn),因?yàn)樗枰m應(yīng)不同的電平、電氣特性、時序規(guī)范和命令協(xié)議。可編程IO的價值和挑戰(zhàn)都因FPGAs上用于IO的大面積空間而凸顯出來。例如,Altera的Stratix II (90納米)器件支持28種不同的IO標(biāo)準(zhǔn),并將其20%(最大器件)至48%(最小器件)的芯片面積用于與IO相關(guān)的結(jié)構(gòu)。
如圖11所示,F(xiàn)PGAs采用多種方法[47]–[49]來應(yīng)對這一挑戰(zhàn)。首先,F(xiàn)PGA使用可以在一定電壓范圍內(nèi)工作的IO緩沖器。這些IO被分組到組(bank)中(通常每個組大約50個IO),其中每個組都有一個單獨(dú)的IO緩沖器線路。這允許不同的組工作不同的電壓電平;例如一組的IO可以在1.8 V下工作,而另一組的IO可以在1.2 V下工作。第二,每個IO可以單獨(dú)用于單端標(biāo)準(zhǔn),或者成對的IO可以編程形成差分IO標(biāo)準(zhǔn)的正負(fù)線。第三,IO緩沖器由多個并行的上拉和下拉晶體管實(shí)現(xiàn),因此它們的驅(qū)動強(qiáng)度可以通過啟用或禁用不同數(shù)量的上拉/下拉晶體管來進(jìn)行編程調(diào)整。通過將一些上拉或下拉晶體管編程為使能,即使沒有輸出被驅(qū)動,也可以將FPGA IOs編程為實(shí)現(xiàn)不同的片內(nèi)端接電阻,以最小化信號反射。可編程延遲鏈提供了第四級可配置性,允許對進(jìn)出IO緩沖器的信號時序進(jìn)行精細(xì)的延遲調(diào)整。
除了電氣和時序可編程性之外,F(xiàn)PGA IO模塊還包含額外的硬化數(shù)字電路,以簡化IO數(shù)據(jù)的捕獲和傳輸。一般來說,SRAM控制的多路復(fù)用器可以旁路部分或全部這種硬化電路,允許FPGA用戶選擇給定設(shè)計和IO協(xié)議所需的硬化功能。圖11第5部分顯示了IO路徑上的一些常見數(shù)字邏輯選項:捕獲寄存器、雙數(shù)據(jù)速率至單數(shù)據(jù)速率轉(zhuǎn)換寄存器(與DDR存儲器一起使用)和串行至并行轉(zhuǎn)換器,允許以較低頻率傳輸?shù)浇Y(jié)構(gòu)。大多數(shù)FPGA現(xiàn)在還包含可旁路的高級塊,這些塊連接到一組IOs,并實(shí)現(xiàn)更高級別的協(xié)議,如DDR存儲控制器。這些方法結(jié)合在一起,使通用FPGA的IO能夠以高達(dá)3.2Gb/s的速度服務(wù)于許多不同的協(xié)議。
最高速度的IOs實(shí)現(xiàn)串行協(xié)議,如PCIe和以太網(wǎng),將時鐘嵌入數(shù)據(jù)轉(zhuǎn)換,可以28 Gb/s或更高的速度工作。為了實(shí)現(xiàn)這些速度,F(xiàn)PGAs包括一組單獨(dú)的差分IO,具有更低的電壓和電氣可編程性;它們只能用作串行收發(fā)器[50]。就像通用IOs一樣,這些串行IOs在它們和結(jié)構(gòu)之間有一系列高速硬化電路,其中一些可以選擇旁路,以允許最終用戶定制確切的接口協(xié)議。
總的來說,F(xiàn)PGA的IO設(shè)計非常具有挑戰(zhàn)性,因?yàn)槿藗儾粌H需要快速IO,還需要可編程IO。此外,從IO接口分配非常高的數(shù)據(jù)帶寬需要在結(jié)構(gòu)中使用寬的軟總線,這帶來了額外的挑戰(zhàn),如第三章第六節(jié)所述。
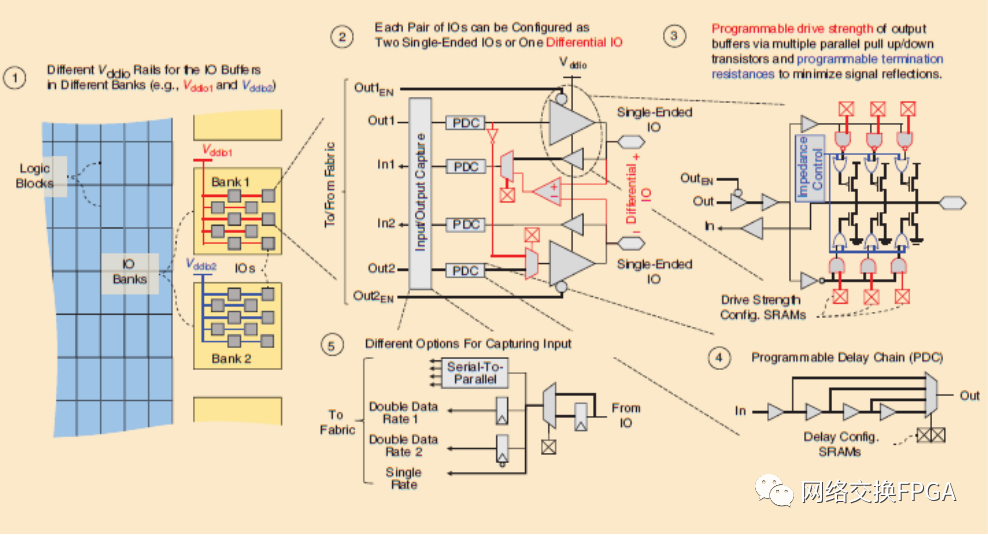
圖11:在FPGAs上實(shí)現(xiàn)可編程IOs的不同技術(shù)概述
3.4 片上存儲器
FPGA架構(gòu)中第一種形式的片上存儲元件是集成在FPGA邏輯塊中的FFs,如第三章第一節(jié)所述。然而,隨著FPGA邏輯容量的增長,它們被用來實(shí)現(xiàn)更大的系統(tǒng),這些系統(tǒng)幾乎總是需要存儲來緩沖和重用芯片上的數(shù)據(jù),因此非常需要更密集的片上存儲,因?yàn)橛眉拇嫫骱蚅UTs構(gòu)建大RAM比(ASIC的)SRAM塊密度低100多倍。與此同時,在FPGA上實(shí)現(xiàn)的應(yīng)用的存儲需求非常多樣,包括(但不限于)用于FIR濾波器的小系數(shù)存儲RAM、用于網(wǎng)絡(luò)數(shù)據(jù)包的大緩沖區(qū)、用于類似處理器的模塊的緩存和寄存器文件、用于指令的只讀存儲以及用于解耦計算模塊的數(shù)百萬個FIFO。這意味著在FPGA設(shè)計中沒有普遍使用的單一RAM配置(容量、字寬、端口數(shù)量),這使得決定哪(些)種RAM塊應(yīng)該添加到FPGA中以使它們在廣泛的應(yīng)用中高效變得具有挑戰(zhàn)性。第一個包含存儲硬功能塊的FPGA(塊RAMs或BRAMs)是1995年的Altera Flex 10k[51]。它包括通過可編程布線連接到結(jié)構(gòu)其余部分的小型(2kb)BRAM列。FPGA已經(jīng)逐漸集成了更大、更多樣的BRAM,典型的情況是,現(xiàn)代FPGA的大約25%的面積專用于BRAM[52]。
一個FPGA BRAM由一個基于SRAM的存儲器組成,帶有額外的外圍電路,使它們更容易配置為多種用途,并將其連接到可編程布線。一個基于SRAM的BRAM通常是如圖12所示。它由存儲位的SRAM單元的二維陣列和大量外圍電路組成,這些外圍電路協(xié)調(diào)對這些單元的訪問以進(jìn)行讀/寫操作。為了簡化讀和寫操作的時序,所有現(xiàn)代的FPGA BRAM都寄存了它們的所有輸入。在寫操作期間,列譯碼器激活寫驅(qū)動器,寫驅(qū)動器又根據(jù)要寫入存儲單元的輸入數(shù)據(jù)對位線(BL和)充電。同時,行譯碼器激活由輸入寫地址指定的行的字線,將一行單元連接到它們的位線,以便它們被新數(shù)據(jù)覆蓋。在讀操作期間,BL和都被預(yù)充電到高電平,然后行譯碼器激活由輸入讀地址指定的行的字線。激活單元的內(nèi)容導(dǎo)致BL和之間的電壓略有差異,這種差異被感知放大器電路感知和放大,以產(chǎn)生輸出數(shù)據(jù)[52]。
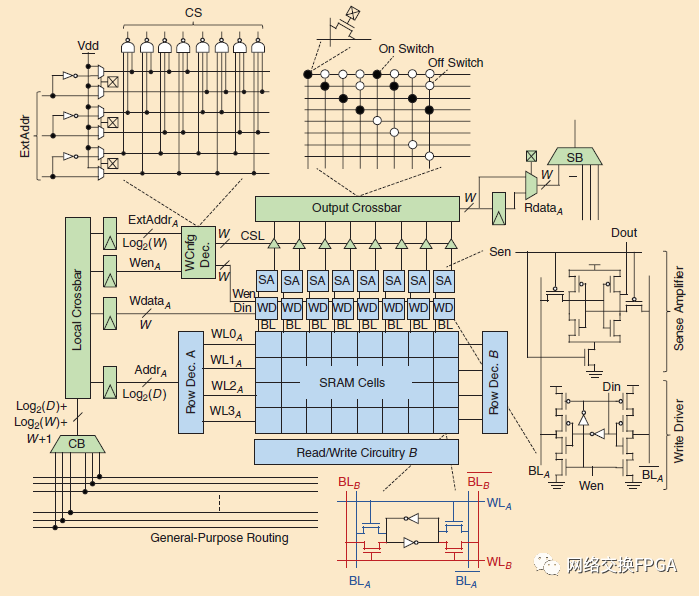
圖12:一個傳統(tǒng)的基于雙端口SRAM的FPGA BRAM的組織和電路。以藍(lán)色突出顯示的組件在任何基于SRAM的存儲模塊中都很常見,而以綠色突出顯示的組件是特定于FPGA的。該BRAM最大數(shù)據(jù)寬度為8位,但輸出交叉開關(guān)配置為4位輸出模式
設(shè)計FPGA BRAMs的主要架構(gòu)決策是選擇它們的容量、數(shù)據(jù)字寬度和讀/寫端口數(shù)量。更強(qiáng)大的BRAMs需要更多的硅面積,因此架構(gòu)師必須仔細(xì)平衡BRAM設(shè)計選擇,同時考慮應(yīng)用電路中最常見的用例。SRAM單元占據(jù)的面積隨BRAM電容線性增長,但外圍電路的面積和布線端口的數(shù)量呈次線性增長。這意味著更大的BRAM具有更低的每比特面積,使得更大的片上緩沖更有效。另一方面,如果一個應(yīng)用只需要很小的RAM,那么一個更大的BRAM的大部分容量可能會被浪費(fèi)掉。同樣,具有較大數(shù)據(jù)寬度的BRAM可以為下游邏輯提供更高的數(shù)據(jù)帶寬。然而,它比同樣容量但字寬更小的BRAM占用更多的面積,因?yàn)楦蟮臄?shù)據(jù)字寬需要更多的靈敏放大器、寫驅(qū)動器和可編程布線端口。最后,增加一個BRAM的讀/寫端口的數(shù)量會增加SRAM單元和外圍電路的面積,但也會增加BRAM能夠提供的數(shù)據(jù)帶寬,并允許更多樣的用途。例如,F(xiàn)IFO(在FPGA設(shè)計中普遍存在)需要一個讀端口和一個寫端口。雙端口SRAM單元的實(shí)現(xiàn)細(xì)節(jié)顯示在圖12的底部。為SRAM單元實(shí)現(xiàn)第二個端口(端口B用紅色突出顯示)增加了兩個晶體管,使SRAM單元的面積增加了33%。此外,第二個端口還需要一個額外的靈敏放大器、寫驅(qū)動器和行譯碼器的復(fù)制(圖12中的“讀/寫電路B”和“行譯碼器B”塊)。如果兩個端口都是讀/寫(r/w),我們還必須將可編程布線的端口數(shù)量增加一倍。
因?yàn)镕PGA片上存儲器必須滿足在該FPGA上實(shí)現(xiàn)的每個應(yīng)用的需求,所以向BRAM添加額外的可配置性以允許它們適應(yīng)應(yīng)用需求也是常見的[53],[54]。通過在存儲器陣列的外圍增加低成本多路復(fù)用電路,F(xiàn)PGA BRAMs被設(shè)計成具有可配置的寬度和深度。例如,在圖12中,實(shí)際的SRAM陣列被實(shí)現(xiàn)為4×8位陣列,這意味著它自然存儲8位數(shù)據(jù)字。通過在輸出交叉開關(guān)上添加由3個地址位控制的多路復(fù)用器,并在其上的讀/寫電路上添加額外的解碼和使能邏輯,該RAM還可以在8×4位、16×2位或32×1位模式下工作。寬度可配置譯碼器(WCnfg Dec.)在Vdd和地址位之間選擇,如圖12左上角所示,表示最大8位字節(jié)大小。多路復(fù)用器使用配置SRAM單元進(jìn)行編程,并用于產(chǎn)生列選擇(CS)和寫使能(Wen)信號,分別控制靈敏放大器和寫驅(qū)動器進(jìn)行局部讀和寫操作。對于典型的BRAM大小(幾kb或更多),這種額外寬度可配置電路的成本與傳統(tǒng)SRAM陣列的成本相比很小,并且不需要任何額外的布線端口。
與傳統(tǒng)存儲塊相比,F(xiàn)PGA的另一個獨(dú)特組件是它們與可編程布線結(jié)構(gòu)的接口。該接口一般被設(shè)計成類似于第三章第一節(jié)中描述的邏輯塊;如果所有塊類型都以類似的方式連接,那么創(chuàng)建一個平衡靈活性和成本的布線架構(gòu)會更容易。連接塊多路復(fù)用器,隨后是某些FPGA中的局部交叉開關(guān),形成BRAM輸入布線端口,而其讀輸出驅(qū)動開關(guān)塊多路復(fù)用器形成輸出布線端口。這些布線接口的成本很高,尤其是對于小型BRAMs;它們分別占256Kb至8Kb的BRAM面積的5%至35%[55]。這促使盡可能減少通往BRAM的布線端口數(shù)量,同時又不影響其功能。表1總結(jié)了不同數(shù)量和類型的BRAM讀寫端口所需的布線端口數(shù)。例如,一個單端口BRAM (1r/w)需要W+log2(D)個輸入端口用于寫入數(shù)據(jù)和讀/寫地址,以及W個輸出端口用于讀取數(shù)據(jù),其中W和D分別是最大的字寬和BRAM深度。該表顯示,與簡單的雙端口(1r+1w)BRAM相比,真雙端口(2r/w) BRAM多需要2W的端口,這顯著增加了布線接口的成本。雖然真雙端口存儲適用于寄存器文件、緩存和共享存儲開關(guān),但FPGA上多端口RAM最常見的用途是用于FIFOs,它只需要一個讀端口和一個寫端口(1r+1w,而不是2r/w端口)。因此,F(xiàn)PGA BRAMs通常具有真雙端口SRAM核,但在SRAM核(W)支持的全寬度下,只有足夠的布線接口用于簡單雙端口模式,并將真正雙端口模式的寬度限制為最大寬度的一半(W/2)。
表1:不同數(shù)量和類型的BRAM讀/寫端口所需的布線端口數(shù)(W:數(shù)據(jù)寬度,D:BRAM深度)

另一種降低額外BRAM成本的方法是多泵(multi-pump)存儲塊(即以設(shè)計邏輯其余部分所用頻率的倍數(shù)運(yùn)行BRAM)。通過這樣做,物理上的單端口SRAM陣列可以實(shí)現(xiàn)邏輯上的多端口BRAM,而不需要增加額外的端口,正如在Tabula的時空架構(gòu)中那樣[56]。通過在軟結(jié)構(gòu)中建立時分多路復(fù)用邏輯,多泵也可以與傳統(tǒng)的FPGA BRAM一起使用;然而,這導(dǎo)致了對時分多路復(fù)用邏輯的激進(jìn)的時序約束,這可能使時序更加困難并增加編譯時間。Altera在2000年代早期在其Mercury器件中引入了四端口BRAMs,以提高共享存儲開關(guān)(用于數(shù)據(jù)包處理)和寄存器文件的效率[57]。然而,這一特性增加了BRAM的尺寸,并沒有在后續(xù)的FPGA代中充分地用于證明它的內(nèi)容。相反,設(shè)計人員使用各種技術(shù)將雙端口FPGA BRAM和軟件邏輯結(jié)合起來,在需要時制造高度移植的結(jié)構(gòu),盡管效率較低[58],[59]。我們請感興趣的讀者參考[52]和[55],了解BRAM核和外圍電路設(shè)計的更多細(xì)節(jié)。
除了構(gòu)建存儲之外,F(xiàn)PGA供應(yīng)商還可以添加電路,使設(shè)計人員能夠?qū)?gòu)成邏輯結(jié)構(gòu)的LUTs重新調(diào)整為額外的存儲塊。邏輯塊K-LUT中的真值表是2的k次方×1位只讀存儲器;當(dāng)設(shè)計比特流被加載時,它們由配置電路寫入一次。由于LUTs已經(jīng)有了讀電路(根據(jù)一個K位輸入/地址讀出一個存儲值),只要增加設(shè)計者控制的寫電路,它們就可以用作小型分布式基于LUT的RAM(LUT-RAMs)。然而,一個主要的問題是實(shí)現(xiàn)寫功能所需的額外布線端口的數(shù)量,以便將LUT更改為LUT-RAM。例如,在最近的Altera/Intel架構(gòu)中,ALM是一個6-LUT,它可以分為兩個5-LUTs,有8個輸入布線端口,如第三章第一節(jié)所述。這意味著它可以運(yùn)行一個64×1位或32×2位的存儲器,分別有6位或5位的讀地址。這僅留下2或3個未使用的布線端口,如果我們想要在每個周期中讀寫(簡單雙端口模式),這對于寫地址、數(shù)據(jù)和寫使能(總共8個信號)是不夠的,這是FPGA設(shè)計中最常用的RAM模式。為了克服這個問題,一個10ALM的完整邏輯塊被配置為一個LUT-RAM,以緩沖控制電路和10ALM的地址位。寫地址和寫使能是通過從每個ALM中一個未使用的布線端口帶來一個信號,并將結(jié)果地址和使能廣播給所有ALM來組裝的[60]。因此,一個邏輯塊可以實(shí)現(xiàn)64×10位或32×20位的簡單雙端口RAM,但有一個限制,即單個邏輯塊不能混合邏輯和LUT-RAM。Xilinx Ultrascale類似地將整個邏輯塊轉(zhuǎn)換為LUT-RAM,但是邏輯塊中八個LUTs中的一個的所有布線端口都被重新用于驅(qū)動(廣播)寫地址和使能信號。因此,Xilinx邏輯塊可以實(shí)現(xiàn)64×7位或32×14位簡單雙端口RAM,或稍寬的單端口存儲(64×8位或32 ×16位)。避免額外的布線端口可以降低LUT-RAM的成本,但仍會增加一些面積。由于將50%以上的邏輯結(jié)構(gòu)轉(zhuǎn)換為LUT-RAM的設(shè)計非常罕見,Altera/Intel和Xilinx都選擇在其最新的架構(gòu)中僅使用一半的邏輯塊LUT-RAM,從而進(jìn)一步降低了面積成本。
在一個典型的設(shè)計中,設(shè)計者需要許多不同的RAM,所有這些都必須由芯片上的固定BRAM和LUT-RAM資源來實(shí)現(xiàn)。迫使設(shè)計人員為他們需要的每種存儲配置確定組合BRAM和LUT-RAM的最佳方式,并編寫verilog來實(shí)現(xiàn)它們將是非常困難的,而且還會將設(shè)計與特定的FPGA架構(gòu)聯(lián)系起來。相反,供應(yīng)商的CAD工具包括一個RAM映射階段,該階段使用物理BRAM和芯片上的LUT-RAM在用戶的設(shè)計中實(shí)現(xiàn)邏輯存儲。存儲映射器選擇物理存儲實(shí)現(xiàn)(即存儲類型及其端口的寬度/數(shù)量/類型),并生成組合多個BRAM或LUT-RAM以實(shí)現(xiàn)每個邏輯存儲所需的任何額外邏輯。圖13給出了一個將具有2個讀端口和1個寫端口的邏輯2048×32位RAM映射到具有物理1024×8位雙端口RAM的FPGA的示例。首先,四個物理存儲并行組合在一起,形成更寬的存儲,沒有額外的邏輯。然后,使用軟邏輯資源來執(zhí)行兩組四個物理BRAM的深度匹配,使得寫和讀地址的最高有效位分別用作寫使能和讀輸出多路復(fù)用選擇信號。最后,在這種情況下,我們需要兩個讀端口和一個寫端口,而物理磁盤最多只能支持2個讀/寫端口。為了實(shí)現(xiàn)第二個讀端口,整個結(jié)構(gòu)被復(fù)制(見圖13)或雙泵,如前所述。[61],[62]描述了幾種優(yōu)化RAM映射的算法。
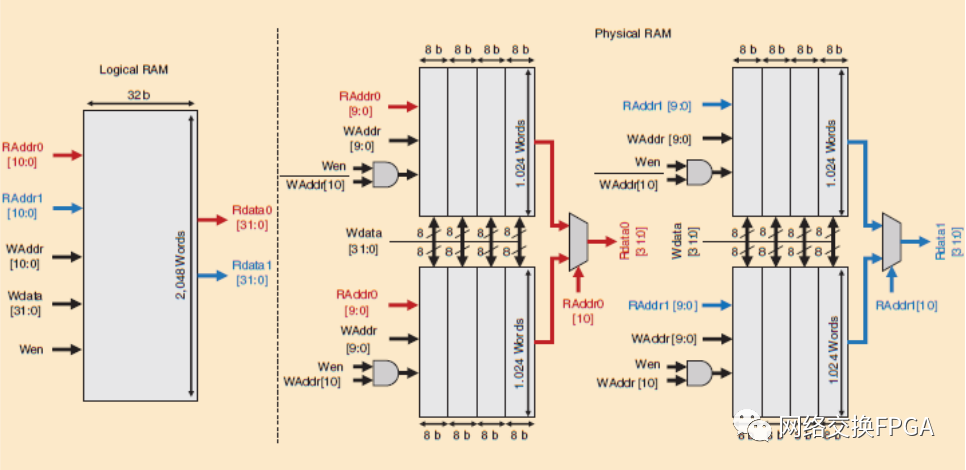
圖13:將2048×32位2r+1w邏輯內(nèi)存映射到具有1024×8位1r+1w物理內(nèi)存的FPGA
在過去的25年里,F(xiàn)PGA的存儲結(jié)構(gòu)發(fā)生了很大的變化,并且變得越來越重要,因?yàn)镕PGA上存儲與邏輯的比例顯著增加。圖14顯示了從350納米Flex 10 K器件(1995年)到10納米Aeilex器件(2019年)的Altera/Intel器件中存儲位/邏輯元件(包括LUT-RAM)與邏輯元件數(shù)量的關(guān)系。隨著時間的推移,F(xiàn)PGA的存儲豐富程度逐漸增加,為了滿足對更多位的需求,現(xiàn)代BRAM比最初的存儲(2 kb)具有更大的容量(20 kb)。一些FPGA具有高度異構(gòu)的RAM,以便提供一些對小型或?qū)掃壿婻AM有效的物理RAM,以及對大型和相對窄的邏輯RAM有效的其他RAM。例如,Stratix (130 nm)有3種類型的BRAM,容量分別為512b、4kb和512kb。Stratix III中LUT-RAM (65納米)的引入減少了對小型BRAM的需求,因此轉(zhuǎn)移到了9 kb和144 kb BRAM的存儲架構(gòu)。Stratix V (28納米)和更高版本的Intel器件已經(jīng)轉(zhuǎn)向LUT-RAM和單個中型BRAM(20kb)的組合,以簡化FPGA版圖以及RAM映射和放置。Tatsumura等人[52] 也呈現(xiàn)了Xilinx器件的片上存儲器密度的類似趨勢。與Intel相似,Xilinx的存儲架構(gòu)結(jié)合了LUT-RAM和一個中等大小的18 kbRAM,但也包括一個將兩個BRAM結(jié)合到一個36kb塊中的硬件電路。然而,Xilinx的最新器件還包括一個大的288 kb BRAM (UltraRAM),以更有效地處理非常大的緩沖區(qū),這表明在最佳BRAM架構(gòu)上仍然有廣泛的共識。
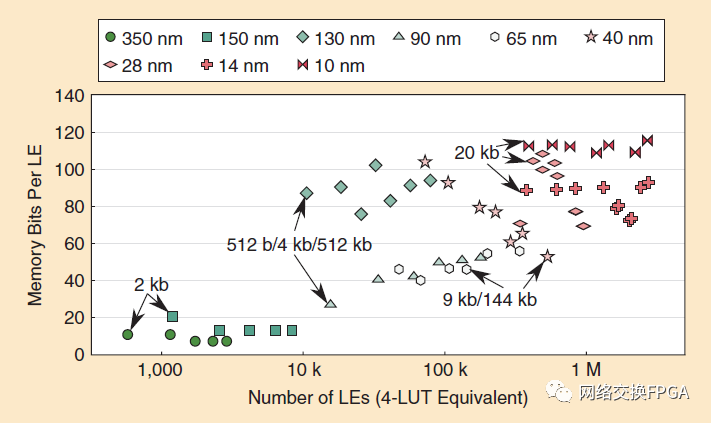
圖14:從350納米Flex 10k(1995年)到10納米Agilex(2019年)架構(gòu),Altera/Intel FPGAs每LE內(nèi)存位的趨勢。這些標(biāo)簽顯示了每種架構(gòu)中BRAM的大小
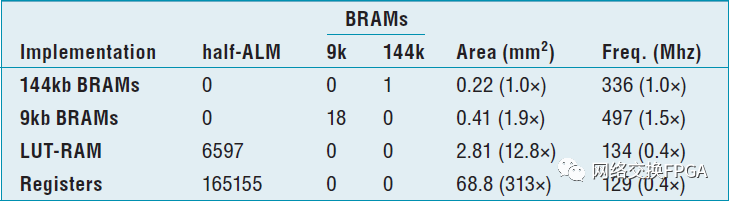
為了深入了解不同RAM塊的相對面積和效率,表2顯示了2048×72位邏輯RAM的資源使用、硅面積和頻率,當(dāng)它由Quartus(Altera/Intel FPGA的CAD流程)以多種方式在Stratix IV器件上實(shí)現(xiàn)時。硅面積的計算使用了已公布的Stratix III塊面積[63],并將其從65納米縮小至40納米,因?yàn)镾tratix III和IV具有相同的架構(gòu),但使用不同的工藝節(jié)點(diǎn)。由于這種邏輯RAM在Stratix IV上非常適合144kb的BRAM存儲,所以當(dāng)映射到一個144kb的BRAM時,它可以獲得最佳的面積。有趣的是,映射到18個9 kb的BRAMs在硅面積上只有1.9 倍大(注意,輸出寬度限制導(dǎo)致18個BRAMs,而不是可能預(yù)期的16個)。9 kb的BRAM實(shí)現(xiàn)實(shí)際上比144 kb的BRAM實(shí)現(xiàn)更快,因?yàn)檩^小的BRAM具有更高的最大工作頻率。將如此大的邏輯存儲映射到LUT-RAM是低效的,需要12.7倍更多的面積,并以40%的頻率工作。最后,只映射到邏輯和布線源顯示了片上存儲的重要性:面積比144kb的BRAM大300倍多。雖然144 kb的BRAM對于這個單一的測試用例來說是最有效的,但是真正的設(shè)計有不同的邏輯RAM,對于小的或淺的存儲來說,9 kb和LUT-RAM的選項將優(yōu)于144 kb的BRAM,這激發(fā)了片上RAM資源的多樣性。為了選擇BRAM大小和最大字寬的最佳組合,需要一個RAM映射工具和工具來估計每個BRAM的面積、速度和功率[55]。已發(fā)表的對FPGA BRAM架構(gòu)權(quán)衡的研究包括[30],[55],[64]。
表2:Stratix IV上使用BRAMs、LUT-RAMs和寄存器的2048×72位1r+1w RAM的實(shí)現(xiàn)結(jié)果
到目前為止,所有的商用FPGA在它們的BRAM中只使用基于SRAM的存儲單元。由于工藝的變化,對更高密度的BRAM的需求使得存儲更豐富的FPGA和SRAM的縮小變得越來越困難。一些學(xué)術(shù)研究(例如如[52],[65])已經(jīng)探索了使用其他新興的存儲技術(shù),如磁隧道結(jié)(MTJs)來構(gòu)建FPGA存儲塊。根據(jù)[52],在相同的管芯尺寸下,基于MTJ的BRAMs可以將FPGA存儲容量提高高達(dá)2.95倍;然而,它們會增加工藝復(fù)雜度。
3.5 數(shù)字信號處理器模塊
最初,商用FPGA架構(gòu)中唯一的專用算法電路是進(jìn)位鏈,以實(shí)現(xiàn)高效的加法器,如第三章第一節(jié)所述。因此,乘法器必須使用LUTs和進(jìn)位鏈在軟邏輯中實(shí)現(xiàn),這導(dǎo)致了很大的面積和延遲損失。由于高乘法器密度的信號處理和通信應(yīng)用構(gòu)成了一個主要的FPGA市場,設(shè)計人員提出了新的實(shí)現(xiàn)方法來減輕軟邏輯中乘法器實(shí)現(xiàn)的低效率。例如,無乘法器的分布式算術(shù)技術(shù)被用來在基于LUT的FPGAs上實(shí)現(xiàn)高效的有限脈沖響應(yīng)濾波器(FIR)結(jié)構(gòu)[66],[67]。
隨著乘法器在關(guān)鍵應(yīng)用領(lǐng)域的FPGA設(shè)計中的流行,以及它們在軟邏輯中實(shí)現(xiàn)時較低的面積/延遲/功率效率,它們很快成為FPGA架構(gòu)中專用電路硬化的候選對象。一個N位乘法器陣列由N平方個邏輯元件組成,只有2 N個輸入和輸出。因此,硬化乘法器邏輯的增益和可編程接口到FPGA布線結(jié)構(gòu)的成本導(dǎo)致了凈效率增益,并強(qiáng)烈主張在后續(xù)的FPGA架構(gòu)中采用硬乘法器。如圖15左上角所示,Xilinx推出了其Virtex-II架構(gòu),該架構(gòu)采用了業(yè)界首款18×18位硬乘法器塊[68]。為了簡化與完全定制的FPGA結(jié)構(gòu)的版圖集成,這些乘法器在BRAM列旁邊被排成列。為了進(jìn)一步降低互連成本,乘法器塊及其相鄰的BRAM共享一些互連資源,限制了BRAM塊的最大可用數(shù)據(jù)寬度。使用軟邏輯資源,可以將多個硬18位乘法器組合成更大的乘法器或FIR濾波器。
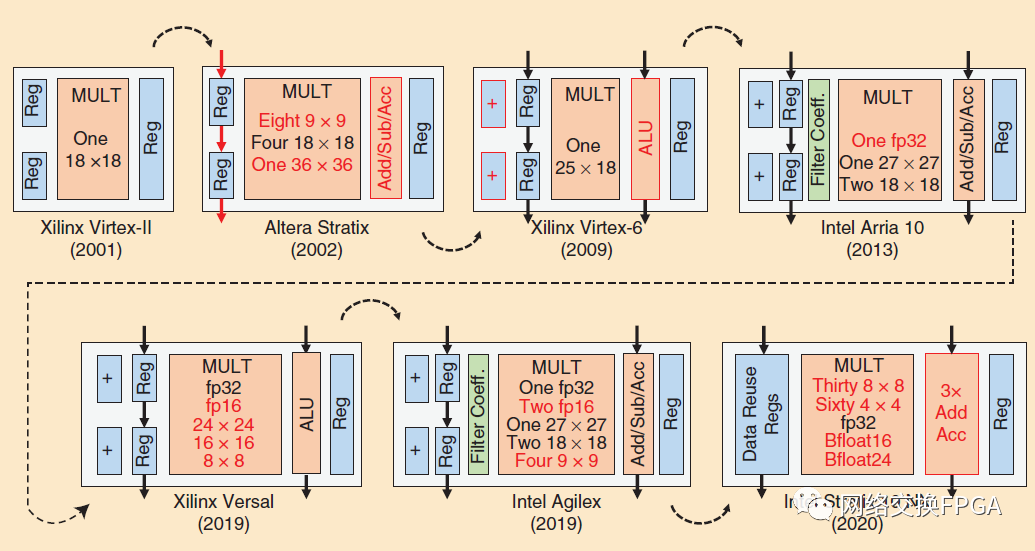
圖15:Altera/Intel和Xilinx FPGAs中的DSP塊演進(jìn)。增量添加的特征以紅色突出顯示
2002年,Altera采用了一種不同的方法,在其Stratix架構(gòu)中引入了針對通信和信號處理領(lǐng)域的全功能DSP模塊[42](參見圖15中的第二個模塊)。該DSP模塊的主要設(shè)計理念是通過硬化DSP模塊內(nèi)部的更多功能,并增強(qiáng)其靈活性以允許更多應(yīng)用使用它,從而最大限度地減少用于實(shí)現(xiàn)常見DSP算法的軟邏輯資源的數(shù)量。與Virtex-II架構(gòu)中的固定功能硬18位乘法器不同,Stratix DSP模塊可高度配置,支持不同的操作模式和乘法精度。每個Stratix可變精度DSP模塊跨越8行,可以實(shí)現(xiàn)8個9×9位乘法器、4個18×18位乘法器或1個36×36乘法器。
Altera選擇的這些操作模式突出了設(shè)計FPGA硬模塊的一個重要主題:通過添加低成本電路來增加這些模塊的可配置性和實(shí)用性。例如,一個18×18乘法數(shù)組可以分解成兩個9×9數(shù)組,它們一起使用相同數(shù)量的輸入和輸出(以及布線端口)。類似地,四個18×18乘法器可以使用廉價邏輯組合成一個36×36數(shù)組。圖16顯示了如何將一個18×18乘法器陣列分割成多個9×9陣列。通過將輸入和輸出引腳的數(shù)量增加一倍,它可以分成四個9×9陣列。然而,為了避免增加這些昂貴的布線接口,18×18陣列被分成兩個9×9陣列(圖中16的藍(lán)色)。這是通過在由紅色虛線指示的位置拆分部分積壓縮器樹,并將轉(zhuǎn)換功能添加到右上角數(shù)組的邊界單元格中來實(shí)現(xiàn)的,在圖16中用十字標(biāo)記。使用Baugh-Wooley算法[69]實(shí)現(xiàn)二進(jìn)制有符號乘法(左下角的數(shù)組已經(jīng)具有18×18數(shù)組的轉(zhuǎn)換能力)。
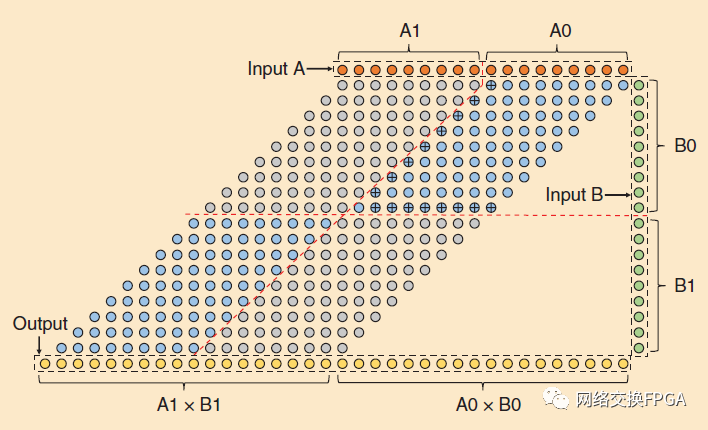
圖16:將一個18×18乘法器陣列分成兩個具有相同數(shù)量輸入/輸出端口的9×9陣列
除了可分割的乘法器陣列之外,Stratix DSP還集成了一個加法器/輸出塊來執(zhí)行求和和累加操作,以及可以配置為移位寄存器的硬化輸入寄存器,移位寄存器之間具有專用的級聯(lián)互連,以實(shí)現(xiàn)高效的FIR濾波器結(jié)構(gòu)[70]。晶格最新的28納米架構(gòu)也有一個可變精度的DSP模塊,可以實(shí)現(xiàn)相同的精度范圍,此外,還分別為濾波器結(jié)構(gòu)和視頻處理應(yīng)用提供特殊的一維和二維對稱模式。Xilinx還采用了一種全功能的DSP塊方法,在Virtex-4架構(gòu)中引入了DSP48芯片[71]。每個DSP都有兩個固定精度的18×18位乘法器,其功能與StratixDSP模塊相似(例如輸入級聯(lián)、加法器/減法器/累加器)。Virtex-4還引入了級聯(lián)加法器/累加器的能力,使用專用互連來實(shí)現(xiàn)具有硬化簡化鏈的高速系統(tǒng)FIR濾波器。 N抽頭FIR濾波器在信號樣本X = {x0,x1,…,xT}和某些系數(shù)C = {c0,c1,…,c(n-1)}之間執(zhí)行離散的一維卷積,這些系數(shù)表示所需濾波器的脈沖響應(yīng),如等式1所示。
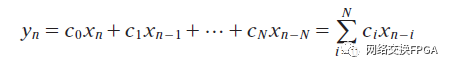
實(shí)踐中使用的許多FIR濾波器都是對稱的,ci =c(n-i) ,i = 0至N/2。由于這種對稱性,濾波器的計算可以重構(gòu)為等式2所示。
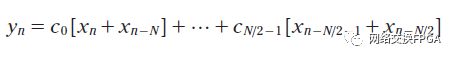
圖17顯示脈動對稱FIR濾波器電路的結(jié)構(gòu),這是無線基站中FPGAs的一個關(guān)鍵用例。Stratix和Virtex-4DSP模塊都可以實(shí)現(xiàn)虛線框突出顯示的部分,與在FPGA的軟邏輯中實(shí)現(xiàn)它們相比,這導(dǎo)致了顯著的效率增益。有趣的是,雖然FPGA CAD工具會自動在DSP塊中實(shí)現(xiàn)乘法(*)運(yùn)算,但它們通常不會利用任何高級DSP塊功能(例如累加,用于FIR濾波器的脈動寄存器),除非設(shè)計者以適當(dāng)?shù)哪J绞謩訉?shí)例化DSP塊。因此,使用更強(qiáng)大的DSP模塊功能使設(shè)計更加輕便。
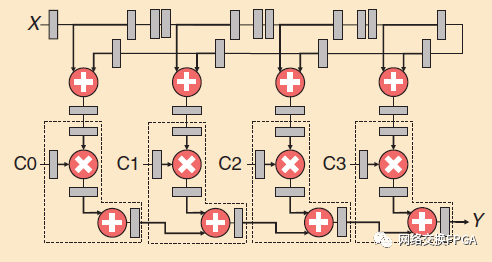
圖17:脈動對稱FIR濾波電路
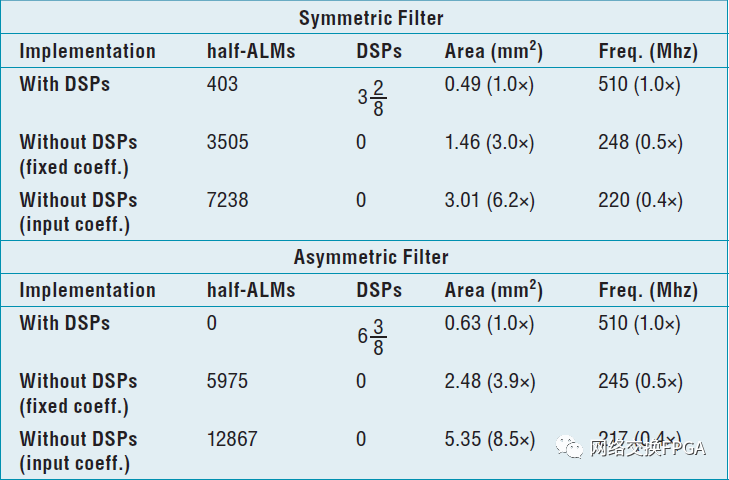
Stratix IIIDSP模塊類似于Stratix IIDSP模塊,但如果將結(jié)果相加以限制輸出布線接口的數(shù)量,則每半個DSP模塊(而不是兩個)可以實(shí)現(xiàn)四個18×18乘法器[72]。表3列出了對稱和不對稱的51抽頭FIR濾波器的實(shí)現(xiàn)結(jié)果,在Stratix器件上使用和不使用硬件DSP模塊。當(dāng)不使用DSP塊時,我們用兩種不同的情況進(jìn)行實(shí)驗(yàn):固定的濾波器系數(shù)和運(yùn)行時可以改變的濾波器系數(shù)。如果濾波器系數(shù)是固定的,則在軟邏輯中實(shí)現(xiàn)的乘法器陣列通過綜合部分積生成邏輯中對應(yīng)于系數(shù)值中的零比特的部分而被優(yōu)化。因此,與運(yùn)行時可能改變的輸入系數(shù)相比,它的資源利用率較低。對于對稱濾波器,即使使用DSP模塊,我們?nèi)匀恍枰褂靡恍┸涍壿嬞Y源來實(shí)現(xiàn)輸入級聯(lián)鏈和預(yù)加法器,如圖17所示。使用硬DSP模塊在系數(shù)固定的情況下導(dǎo)致比使用軟結(jié)構(gòu)的面積效率多3倍。對于運(yùn)行時可變的過濾器系數(shù),這一差距增長到6.2倍。對于不對稱濾波器,完整的FIR濾波器結(jié)構(gòu)可以在DSP模塊中實(shí)現(xiàn),無需任何軟邏輯資源。因此,對于固定系數(shù)和輸入系數(shù),面積效率差距分別增加到3.9倍和8.5倍。這些收益很大,但仍低于學(xué)術(shù)界通常引用的FPGA和ASIC[11]之間的35倍差距。這種差異部分是由于大多數(shù)應(yīng)用電路中保留了一些軟邏輯,但即使在FIR濾波器完全適合沒有軟邏輯的DSP塊的情況下,面積減少也達(dá)到最大值8.5倍。低于[11]的35倍增益的主要原因是可編程布線的接口以及必須在DSP模塊中實(shí)現(xiàn)的通用模塊間可編程布線和多路復(fù)用器。在所有情況下,如表3所示,使用硬DSP模塊導(dǎo)致大約2倍頻率改善。
表3:Stratix IV上51抽頭對稱FIR濾波器的實(shí)現(xiàn)結(jié)果,使用和不使用硬化的DSP塊
Altera和Xilinx的后續(xù)代FPGA架構(gòu)僅見證了DSP塊架構(gòu)的微小變化。兩家供應(yīng)商的主要關(guān)注點(diǎn)是在不增加昂貴的可編程布線接口的情況下,微調(diào)關(guān)鍵應(yīng)用領(lǐng)域的DSP模塊功能。在Stratix V中,DSP塊被極大地簡化為支持兩個18×18位乘法(無線基站信號處理中使用的關(guān)鍵精度)或一個27×27乘法(適用于單精度浮點(diǎn)尾數(shù))。因此,更簡單的Stratix V DSP塊跨越了一個單一的行,這對于Altera的行冗余方案更友好。此外,添加了輸入預(yù)加法器以及存儲只讀濾波器權(quán)重的嵌入式系數(shù)庫[73],這允許實(shí)現(xiàn)圖17中所示的整個對稱濾波器結(jié)構(gòu),不需要任何軟邏輯資源。另一方面,Xilinx在其Virtex-5 DSP48E芯片[74]中從18×18乘法器切換到25×18乘法器,之后他們合并了輸入預(yù)加法器,并增強(qiáng)了加法器/累加單元,以支持Virtex-6DSP48E1芯片[75]中的位邏輯運(yùn)算。然后,他們將乘法寬度再次增加到27×18位,并在Ultrascale系列DSP48E2芯片中的算術(shù)邏輯單元中增加了第四個輸入[76]。
如圖15所示,直到2009年,DSP模塊架構(gòu)的發(fā)展主要是由通信應(yīng)用的要求驅(qū)動的,尤其是在無線基站中,很少有學(xué)術(shù)研究探索[77],[78]。最近,F(xiàn)PGAs被廣泛應(yīng)用于數(shù)據(jù)中心,以加速各種類型的工作負(fù)載,如搜索引擎和網(wǎng)絡(luò)數(shù)據(jù)包處理[9]。此外,DL已經(jīng)成為數(shù)據(jù)中心和邊緣工作負(fù)載中許多應(yīng)用的關(guān)鍵組件,而MAC是其核心算術(shù)運(yùn)算。在這些新趨勢的推動下,DSP模塊架構(gòu)朝著兩個不同的方向發(fā)展。第一個方向針對高性能計算(HPC)領(lǐng)域,增加了對單精度浮點(diǎn)(fp32)乘法的本機(jī)支持。在此之前,F(xiàn)PGA供應(yīng)商將為設(shè)計者提供IP核,這些核可以從定點(diǎn)DSP和大量軟邏輯資源中實(shí)現(xiàn)浮點(diǎn)算法。這為FPGAs在高性能計算領(lǐng)域與CPU和GPU(有專用浮點(diǎn)單元)競爭創(chuàng)造了巨大的障礙。Intel的Arria10架構(gòu)首次引入了本機(jī)浮點(diǎn)功能,其主要設(shè)計目標(biāo)是避免DSP塊面積的大幅增加[79]。通過將相同的接口重新用于可編程布線,不支持不常見的功能,如次法距、標(biāo)志和多舍入方案,并最大限度地重用現(xiàn)有的定點(diǎn)硬件,塊面積的增加僅限于10%(即總芯片面積增加0.5%)。下一代Xilinx通用架構(gòu)的DSP58芯片也將支持浮點(diǎn)功能[80]。
第二個方向旨在增加低精度整數(shù)乘法的密度,特別是針對DL的推斷工作負(fù)載。先前的工作已經(jīng)證明了使用低精度定點(diǎn)算法(8位及以下)代替fp32,精度下降可以忽略不計或沒有,但大大降低了硬件成本[81]–[83]。然而,所需的精度取決于模型,甚至可以在同一模型的不同層之間變化。因此,F(xiàn)PGA已經(jīng)成為一種有吸引力的DL推斷解決方案,因?yàn)樗鼈兡軌驅(qū)崿F(xiàn)定制精細(xì)的數(shù)據(jù)路徑,與GPU相比具有更高的能效,與定制ASIC相比具有更低的開發(fā)成本。這導(dǎo)致學(xué)術(shù)研究人員和FPGA供應(yīng)商研究向DSP模塊添加對低精度乘法的本地支持。[84]的作者增強(qiáng)了類似Intel的DSP塊的可分割性,以支持更多的int9和int4乘法和MAC操作,同時保持相同的DSP塊布線接口并確保其向后兼容性。所提出的DSP塊可以實(shí)現(xiàn)4個int9和8個int4乘法/MAC運(yùn)算以及類似Arria-10的DSP塊功能,代價是DSP塊面積增加12%,這相當(dāng)于總芯片面積僅增加0.6%。與不支持這些操作模式的帶DSP的FPGA相比,該DSP塊將8位和4位DL加速器的性能分別提高了1.3倍和1.6倍,同時將已利用的FPGA資源分別減少了15%和30%。另一項學(xué)術(shù)工作[85]通過在DSP48E2塊中包含一個可分割的乘法器陣列來代替固定精度的乘法器,以支持int9、int4和int2精度,從而增強(qiáng)了類似Xilinx的DSP塊。它還添加了FIFO寄存器文件和DSP模塊之間的特殊專用互連,以實(shí)現(xiàn)更有效的標(biāo)準(zhǔn)、逐點(diǎn)和深度卷積層。此后不久,Intel宣布,下一代Agilex DSP塊將與半精度浮點(diǎn)(fp16)和浮點(diǎn)(bfloat16)精度一起添加相同的int9操作模式[86]。此外,下一代Xilinx Versal架構(gòu)將在其DSP58芯片中支持int8乘法[80]。
多年來,DSP塊架構(gòu)已經(jīng)發(fā)展到最適合FPGAs關(guān)鍵應(yīng)用領(lǐng)域的要求,并提供更高的靈活性,以便許多不同的應(yīng)用可以從其功能中受益。在這一演變的所有步驟中,共同的焦點(diǎn)是盡可能重用乘法器陣列和布線端口,以最好地利用這兩種昂貴的資源。然而,隨著高性能計算中的高精度浮點(diǎn)、通信中的中精度定點(diǎn)和DL中的低精度定點(diǎn)之間的關(guān)鍵FPGA應(yīng)用領(lǐng)域的DSP塊要求的最新進(jìn)展,這變得更加困難。因此,Intel最近宣布了一種人工智能優(yōu)化的FPGA,StATrix 10 NX,它用人工智能張量塊代替了傳統(tǒng)的DSP塊[87]。新的張量塊放棄了對傳統(tǒng)DSP模式和精度的支持,這些模式和精度針對通信領(lǐng)域,并采用了專門針對DL領(lǐng)域的新模式。在幾乎相同的芯片尺寸下,這種張量塊顯著地將每個塊的int8和int4 MACs的數(shù)量分別增加到30和60[88]。向所有乘法器提供輸入而不增加更多布線端口是一個關(guān)鍵問題。因此,NX張量塊引入了一個雙緩沖數(shù)據(jù)重用寄存器網(wǎng)絡(luò),可以從較少數(shù)量的布線端口順序加載,同時允許通用的DL計算模式來充分利用所有可用的乘法器[89]。Achronix的下一代Speedster7t FPGA還將包括一個機(jī)器學(xué)習(xí)處理(MLP)模塊[90]。除了fp24、fp16和bfloat16浮點(diǎn)格式之外,它還支持從int16到int3的各種精度。Speedster7t中的MLP模塊還將具有一個緊密耦合的BRAM和循環(huán)寄存器文件,允許重用輸入值和輸出結(jié)果。這些緊密集成的組中的每一個都有一個72位的外部輸入,但可以配置為具有高達(dá)144位的輸出,饋送到MLP乘法器陣列,從而將所需的布線端口數(shù)量減少2倍。
3.6 系統(tǒng)級互連:片上網(wǎng)絡(luò)
FPGA的外部IO接口(如DDR、PCIe和以太網(wǎng))的容量和帶寬不斷增加。在這些高速接口和越來越大的光纖之間分配數(shù)據(jù)流量是一項挑戰(zhàn)。這種系統(tǒng)級互連傳統(tǒng)上是通過配置部分FPGA邏輯和布線來實(shí)現(xiàn)軟總線,從而實(shí)現(xiàn)相關(guān)端點(diǎn)之間的多路復(fù)用、仲裁、流水線和布線。這些外部接口的工作頻率高于FPGA結(jié)構(gòu)所能實(shí)現(xiàn)的頻率,因此匹配其帶寬的唯一方法是使用更寬的(軟)總線。例如,一個單通道高帶寬存儲器(HBM)有一個128位雙數(shù)據(jù)速率接口,工作在1 GHz,因此在250 MHz工作的帶寬匹配軟總線必須是1024位寬。最近的FPGA集成了多達(dá)8個HBM通道[91]以及許多PCIe、以太網(wǎng)和其他接口,系統(tǒng)級互連可以快速使用FPGA邏輯和布線源的主要部分。此外,系統(tǒng)級互連往往會跨越很長的距離。非常寬的總線和物理上很長的總線的結(jié)合使得時序收斂具有挑戰(zhàn)性,并且通常需要軟總線的深度流水線操作,進(jìn)一步增加了它的資源使用。隨著FPGA外部接口的數(shù)量和速度的增加,以及金屬線寄生效應(yīng)(以及互連延遲)的不良擴(kuò)展,先進(jìn)工藝節(jié)點(diǎn)中的系統(tǒng)級互連挑戰(zhàn)變得更加困難[92]。
Abdelfattah和Betz[93]–[95]提出在FPGA結(jié)構(gòu)中嵌入一個硬的分組交換片上網(wǎng)絡(luò)(NoC),以實(shí)現(xiàn)更高效、更易于使用的系統(tǒng)級互連。雖然全功能數(shù)據(jù)包交換的NoC可以使用FPGA的軟邏輯和布線來實(shí)現(xiàn),但與軟NoC相比,具有硬化的處理器和鏈路的NoC的面積效率高23倍,速度快6倍,功耗低11倍。為FPGA設(shè)計一個硬的NoC是一個挑戰(zhàn),因?yàn)镕PGA架構(gòu)師必須為芯片做出許多選擇(例如布線器數(shù)量、鏈路寬度、NoC拓?fù)浣Y(jié)構(gòu)),但仍然保持了FPGA的靈活性,可以使用許多不同的外部接口和通信端點(diǎn)來實(shí)現(xiàn)各種各樣的應(yīng)用。[95]中的工作提倡布線器數(shù)量適中的網(wǎng)狀拓?fù)?例如16)和相當(dāng)寬(128位)的鏈路;這些選擇使面積成本不到總面積的2%,同時確保NoC更容易布局,一條NoC鏈路可以承載整個數(shù)據(jù)通道的帶寬。硬NoC控制器還必須能夠靈活地連接到在FPGA結(jié)構(gòu)中實(shí)現(xiàn)的用戶邏輯;Abdelfattahet等人[96]通過執(zhí)行寬度適配、跨時鐘域和電壓轉(zhuǎn)換,引入了將硬NoC布線器連接到FPGA可編程結(jié)構(gòu)的結(jié)構(gòu)端口。這將NoC從NoC結(jié)構(gòu)中分離出來,這樣NoC就可以以固定(高)頻率工作,并且仍然可以與不同速度和帶寬要求的FPGA邏輯和IO接口連接,只需很少的粘合邏輯。硬NoC似乎也非常適合數(shù)據(jù)中心的FPGA。數(shù)據(jù)中心FPGA通常由兩部分組成:shell提供與外部接口的系統(tǒng)級互連,一個角色實(shí)現(xiàn)應(yīng)用加速功能[9]。shell的資源使用可能很重要:在微軟的第一代Catapult系統(tǒng)中,它需要23%的器件資源[8]。Yazdanshenaset等人[97]表明,在這種shell+role FPGA用例中,硬NoC顯著提高了資源利用率、工作頻率和布線開銷。其他研究提出了特定于FPGA的優(yōu)化,以提高軟NoC的面積效率和性能[98]–[100]。然而,[101]表明,即使是優(yōu)化的軟NoC,在大多數(shù)方面(可用帶寬、延遲、面積和布線擁塞)仍然落后于硬NoC。
最近的Xilinx (Versal)和Achronix (Speedster7t)FPGAs集成了一個硬NoC [102],[103],類似于上面討論的學(xué)術(shù)建議。Versal使用硬NoC在各種端點(diǎn)(千兆收發(fā)器、處理器、子系統(tǒng)、軟結(jié)構(gòu))之間進(jìn)行系統(tǒng)級通信,事實(shí)上,這是外部存儲器接口與器件其余部分通信的唯一方式。它使用工作在1 GHz的128位寬的鏈路,匹配DDR信道的帶寬。它的拓?fù)浣Y(jié)構(gòu)與網(wǎng)格有關(guān),但是所有的水平鏈接都被推到器件的頂部和底部,以便更容易在FPGA布局中顯示。Versal NoC包含多行(即鏈路鏈和布線器鏈),以及許多垂直的NoC列(類似于任何其他硬模塊列,如DSP),具體取決于圖18(a)中所示的器件大小。NoC具有可編程布線表,這些布線表在引導(dǎo)時配置,并提供標(biāo)準(zhǔn)AXI接口[104]作為其結(jié)構(gòu)端口。Speedster7tNoC拓?fù)溽槍ν獠拷涌诘綆瑐鬏斶M(jìn)行了優(yōu)化。它由圍繞結(jié)構(gòu)的外圍環(huán)組成,在FPGA結(jié)構(gòu)上有規(guī)則間隔的NoC控制器行和列,如圖18(b)所示。外環(huán)NoC可以獨(dú)立工作,而無需配置FPGA結(jié)構(gòu)來布線不同外部接口之間的流量。NoC的行和列之間沒有直接的聯(lián)系;來自連接到一個NoC行的主塊的數(shù)據(jù)包將通過外圍環(huán)到達(dá)連接到一個NoC列的從塊。
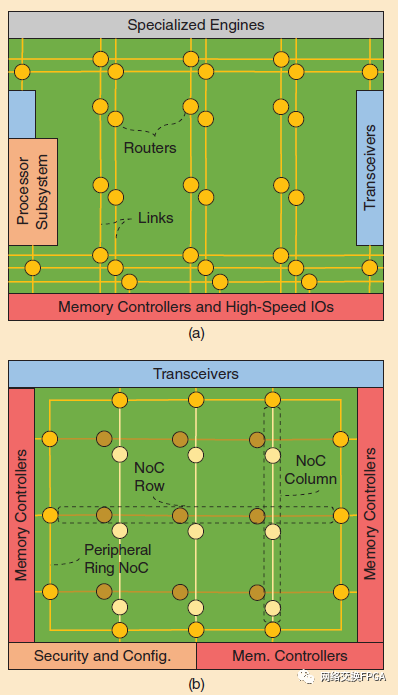
圖18:下一代(a) Xilinx Versal和(b) Achronix Speedster7t架構(gòu)中的片上網(wǎng)絡(luò)系統(tǒng)級互連
3.7 內(nèi)插器
FPGA是允許多個硅器件密集互連的內(nèi)插器技術(shù)的早期采用者。如圖19(a)所示,無源內(nèi)插器是一種硅器件(通常采用拖尾工藝技術(shù)以降低成本),其表面具有形成布線軌跡和數(shù)千個微凸點(diǎn)的傳統(tǒng)金屬層,這些金屬層連接到在其頂部翻轉(zhuǎn)的兩個或多個管芯。基于內(nèi)插器的FPGAs的一個動機(jī)是以合理的成本實(shí)現(xiàn)高邏輯容量。制造前驗(yàn)證ASIC設(shè)計的高端系統(tǒng)和仿真平臺都需要具有高邏輯容量的FPGAs。然而,大型單片(即單硅芯片)器件的成品率很低,尤其是在工藝技術(shù)的早期階段(正好是FPGA最先進(jìn)的時候)。將多個較小的芯片組合在一個硅互連上是一種具有更高集成度的替代方法。2.5維系統(tǒng)的第二個動機(jī)是將不同的專用小芯片(可能使用不同的處理技術(shù))集成到一個系統(tǒng)中。這種方法對FPGAs也很有吸引力,因?yàn)榻Y(jié)構(gòu)的可編程性可以橋接不同的小芯片功能和接口協(xié)議。
Xilinx最大的Virtex-7 (28納米)和Virtex Ultrascale(20納米)FPGAs使用無源硅內(nèi)插器將四個FPGA芯片集成在一起,每個芯片構(gòu)成FPGA的一部分行。最大的基于內(nèi)插器的器件在同一個工藝節(jié)點(diǎn)上提供了兩倍于最大單芯片F(xiàn)PGAs的邏輯元件。FPGA可編程布線需要大量的互連,這就提出了一個問題,即互連微凸點(diǎn)(比傳統(tǒng)的布線軌跡大得多,也慢得多)是否會限制系統(tǒng)的布線能力。例如,在Virtex-7基于內(nèi)插器的FPGAs中,只有23%的垂直布線軌跡通過內(nèi)插器在管芯之間交叉[105],估計附加延遲約為1 ns [106]。[105]中的研究表明,將FPGA邏輯設(shè)置為最小化內(nèi)插器邊界交叉的CAD工具,結(jié)合增加插入器交叉軌跡開關(guān)靈活性的結(jié)構(gòu)變化,可以大大減輕這種減少信號數(shù)量的影響。下一代Xilinx通用架構(gòu)(在第三章第六節(jié)中討論)中的NoC控制器的整個垂直和寬度在片之間交叉,有助于提供更多的互連帶寬。嵌入式NoC很好地利用了可以穿過中介層的有限數(shù)量的導(dǎo)線,因?yàn)樗愿哳l率運(yùn)行其鏈路,并且當(dāng)它們被分組交換時,它們可以被不同的通信流共享。
取而代之的是,Intel FPGA使用更小的內(nèi)插器,稱為嵌入式多芯片互連橋(EMIB),嵌入在封裝襯底上,如圖19(b)所示。IntelStratix 10器件使用EMIB將大型FPGA結(jié)構(gòu)芯片與較小的IO收發(fā)器或HBM小芯片集成在同一個封裝中,將FPGA的這兩個關(guān)鍵元件的設(shè)計和工藝技術(shù)選擇去耦。最近的一些研究[107]–[109]使用EMIB技術(shù)將FPGA結(jié)構(gòu)與用于DL應(yīng)用的專用ASIC加速芯片緊密耦合。這種方法卸載了計算的特定內(nèi)核(例如matrixmatrixor矩陣向量乘法)到更高效的專用小芯片,同時利用FPGA結(jié)構(gòu)與外部世界接口,并實(shí)現(xiàn)快速變化的DL模型組件。
3.8 其他FPGA組件
現(xiàn)代FPGA架構(gòu)包含其他重要組件,我們不會詳細(xì)討論。其中一個組件是配置電路,它將比特流加載到數(shù)百萬個SRAM單元中,這些單元控制LUTs、布線開關(guān)和硬模塊中的配置位。上電時,配置控制器從諸如板上FLASH或硬化PCIe接口的源串行加載該比特流。當(dāng)一組足夠的配置位被緩沖時,它們被并行寫入一組配置SRAM單元,類似于將一個(非常寬的)字寫入SRAM陣列。這種配置電路也可以由FPGA軟邏輯訪問,允許器件的一部分進(jìn)行部分重新配置,而另一部分繼續(xù)處理。一個完整的FPGA應(yīng)用是非常有價值的知識產(chǎn)權(quán),如果沒有安全措施,只需復(fù)制編程比特流就可以克隆它。為了避免這種情況,F(xiàn)PGA CAD工具可以選擇性地加密比特流,并且FPGA器件可以具有由制造商編程的私有解密密鑰,使得比特流只能由購買具有適當(dāng)密鑰的FPGA的單個客戶使用。
由于FPGA應(yīng)用通常以不同的速度與許多不同的器件通信,它們通常包括幾十個時鐘。這些時鐘大多由片內(nèi)可編程鎖相環(huán)(PLLs)、延遲鎖定環(huán)(DLL)和時鐘數(shù)據(jù)恢復(fù)(CDR)電路產(chǎn)生。對于不同的應(yīng)用,以不同的方式分配許多高頻時鐘是具有挑戰(zhàn)性的,并且導(dǎo)致了用于時鐘的特殊互連網(wǎng)絡(luò)。這些時鐘網(wǎng)絡(luò)在原理上類似于第三章第二節(jié)的可編程互連,但使用了允許構(gòu)建低偏斜網(wǎng)絡(luò)(如H樹)的布線和開關(guān)拓?fù)洌⑹褂酶鼘挼慕饘俸推帘螌?dǎo)體來減少串?dāng)_和抖動。
04結(jié)論和未來方向
FPGAs已經(jīng)從簡單的可編程邏輯塊陣列和通過可編程加速互連的IOs發(fā)展成為更復(fù)雜的多芯片系統(tǒng),具有許多不同的嵌入式組件,如BRAM、DSP、高速外部接口和系統(tǒng)級NoC控制器。最近在高性能計算和數(shù)據(jù)中心領(lǐng)域采用FPGA,以及深度學(xué)習(xí)等新的高需求應(yīng)用的出現(xiàn),正在引領(lǐng)FPGA架構(gòu)設(shè)計的新階段。這些新應(yīng)用和數(shù)據(jù)中心的多用戶模式為架構(gòu)創(chuàng)新創(chuàng)造了機(jī)會。與此同時,過程技術(shù)擴(kuò)展正在發(fā)生根本性的變化。線路延遲的伸縮性很差,這促使人們重新思考可編程的布線架構(gòu)。內(nèi)插和3D集成支持全新類型的異構(gòu)系統(tǒng)。控制功耗是一個壓倒一切的問題,并可能導(dǎo)致更多的電源門控和更多異構(gòu)硬件塊的FPGA。我們并不聲稱預(yù)測未來的FPGA架構(gòu),除了它將是有趣的和不同于今天!
審核編輯:湯梓紅














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論