 電子發燒友App
電子發燒友App


作者:李博杰 ?
這是一個好問題。先說結論,大模型的訓練用 4090 是不行的,但推理(inference/serving)用 4090 不僅可行,在性價比上還能跟 H100 打個平手。
事實上,H100/A100 和 4090 最大的區別就在通信和內存上,算力差距不大。
| ? | H100 | A100 | 4090 |
|---|---|---|---|
| Tensor FP16 算力 | 1979 Tflops | 312 Tflops | 330 Tflops |
| Tensor FP32 算力 | 989 Tflops | 156 Tflops | 83 Tflops |
| 內存容量 | 80 GB | 80 GB | 24 GB |
| 內存帶寬 | 3.35 TB/s | 2 TB/s | 1 TB/s |
| 通信帶寬 | 900 GB/s | 900 GB/s | 64 GB/s |
| 通信時延 | ~1 us | ~1 us | ~10 us |
| 售價 | $30000~$40000 | $15000 | $1600 |
H100 這個售價其實是有 10 倍以上油水的。2016 年我在 MSRA 的時候,見證了微軟給每塊服務器部署了 FPGA,把 FPGA 打到了沙子的價格,甚至成為了供應商 Altera 被 Intel 收購的重要推手。2017 年我還自己挖過礦,知道什么顯卡最劃算。后來在華為,我也是鯤鵬、昇騰生態軟件研發的核心參與者。因此,一個芯片成本多少,我心里大概是有數的。
鯤鵬的首席架構師夏 Core 有一篇知名文章《談一下英偉達帝國的破腚》,很好的分析了 H100 的成本:
把他的成本打開,SXM 的成本不會高于 300$,封裝的 Substrate 及 CoWoS 大約也需要 $300,中間的 Logic Die 最大顆,看上去最高貴 :) 那是 4nm 的一顆 814mm2 的 Die,TSMC 一張 12 英寸 Wafer 大致上可以制造大約 60 顆這個尺寸的 Die,Nvidia 在 Partial Good 上一向做得很好(他幾乎不賣 Full Good),所以這 60 顆大致能有 50 顆可用,Nvidia 是大客戶,從 TSMC 手上拿到的價格大約是 $15000,所以這個高貴的 Die 大約只需要 $300。哦,只剩下 HBM 了,當前 DRAM 市場疲軟得都快要死掉一家的鬼樣了,即使是 HBM3 大抵都是虧本在賣,差不多只需要 $15/GB,嗯,80GB 的容量成本是 $1200。TSMC 曾經講過一個故事。臺灣同胞辛辛苦苦攢錢建廠,一張 4nm 那么先進的工藝哦,才能賣到 $15000,但是那某個客戶拿去噢,能賣出 $1500000($30000*50)的貨啦,機車,那樣很討厭耶。你懂我意思嗎?就如最開始說的,在這個世界的商業規則下,$2000 成本的東西賣 $30000,只有一家,銷售量還很大,這是不符合邏輯的,這種金母雞得有航母才守得住。
據說微軟和 OpenAI 包下了 H100 2024 年產能的一半,猜猜他們會不會發揮當年跟 Altera 砍價的傳統藝能?會真的花 $40,000 * 500,000 = 200 億美金去買卡?
咱們再分析下 4090 的成本,5nm 的 609mm2 Die,大約成本是 $250。GDDR6X,24 GB,按照 1 GB $10 算,$240。PCIe Gen4 這種便宜東西就算 $100 吧。封裝和風扇這些東西,算它 $300。總成本最多 $900,這樣的東西賣 $1600,算是良心價了,因為研發成本也是錢啊,更何況 NVIDIA 的大部分研發人員可是在世界上程序員平均薪酬最高的硅谷。
可以說,H100 就像是中國一線城市的房子,本身鋼筋水泥不值多少錢,房價完全是被供求關系吹起來的。我在 LA 已經住了兩周,公司租的房子使用面積是我北京房子的 4 倍,但售價只貴了 30%,還帶個小院,相當于單位面積的房價是北京的 1/3。我跟本地的老外聊天,他們都很吃驚,你們的平均收入水平比 LA 低這么多,怎么買得起北京的房子的?
問題來了,如果 4090 這么香的話,為啥大家還要爭著買 H100,搞得 H100 都斷貨了?甚至 H100 都要對華禁售,搞出個 H800 的閹割版?
大模型訓練為什么不能用 4090
GPU 訓練性能和成本對比
LambdaLabs 有個很好的 GPU 單機訓練性能和成本對比,在此摘錄如下。
首先看吞吐量,看起來沒有什么違和的,在單卡能放下模型的情況下,確實是 H100 的吞吐量最高,達到 4090 的兩倍。看算力和內存也能看出來,H100 的 FP16 算力大約是 4090 的 6 倍,內存帶寬是 3.35 倍,訓練過程中由于 batch size 比較大,大多數算子是 compute bound(計算密集型),少數算子是 memory bound(內存密集型),這個結果是不意外的。
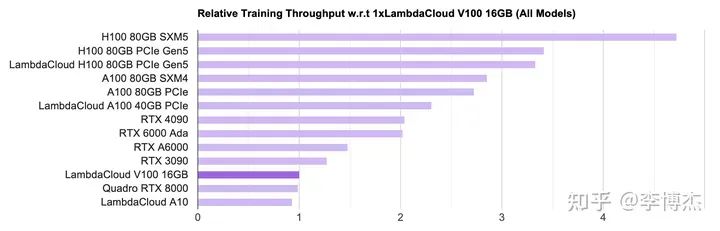
LambdaLabs PyTorch 單卡訓練吞吐量對比圖
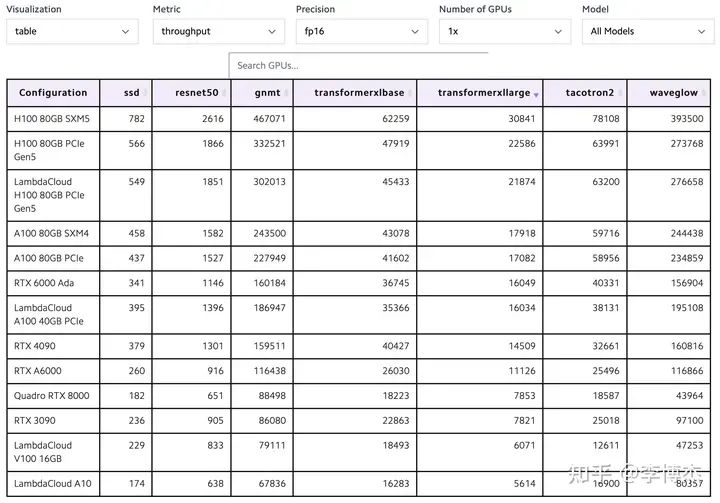
LambdaLabs PyTorch 單卡訓練吞吐量對比表
然后看性價比,就有意思了,原來排在榜首的 H100 現在幾乎墊底了,而且 4090 和 H100 的差距高達接近 10 倍。這就是因為 H100 比 4090 貴太多了。
由于 H100 貨源緊張,云廠商的 H100 租用價格就更黑了,按照標價大約 7 個月就可以回本。就算大客戶價能便宜一半,一年半也足夠回本了。
在價格戰中過慣了苦日子的 IaaS 云服務商看到這樣的 H100 回本速度,估計要感嘆,這真是比區塊鏈挖礦回本還快吶。
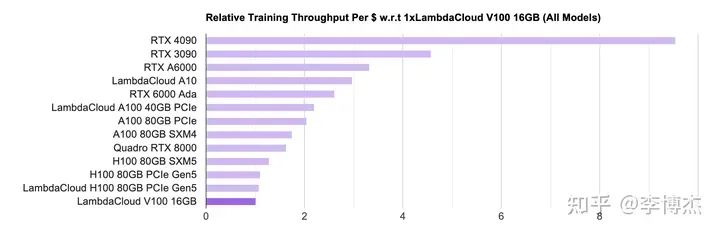
LambdaLabs PyTorch 單卡訓練單位成本吞吐量對比圖
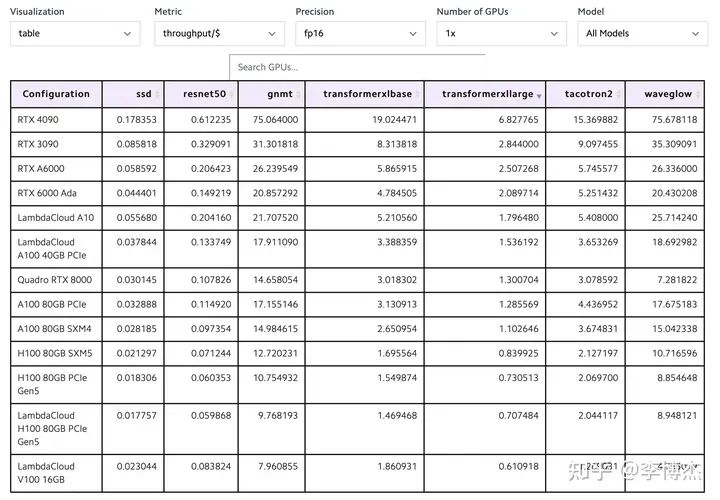
LambdaLabs PyTorch 單卡訓練單位成本吞吐量對比表
大模型訓練的算力需求
既然 4090 單卡訓練的性價比這么高,為啥不能用來做大模型訓練呢?拋開不允許游戲顯卡用于數據中心這樣的許可證約束不談,從技術上講,根本原因是大模型訓練需要高性能的通信,但 4090 的通信效率太低。
大模型訓練需要多少算力?訓練總算力(Flops)= 6 * 模型的參數量 * 訓練數據的 token 數。
我今年初第一次看到有人煞有介事地講這個公式的時候,覺得這不是顯然的嗎?又看到 OpenAI 的高級工程師能拿 90 多萬美金的年薪,頓時整個人都不好了,還是 AI 香呀。之前我也面試過一些做 AI 的工程師,包括一些做 AI 系統優化的專家,連 Q、K、V 是啥都說不清楚,LLaMA 每個 tensor 的大小也算不出來,就這樣還能拿到 offer。
APNet 2023 panel 的主題是 Network, AI, and Foundational Models: Opportunties and Challenges。前面幾個問題都中規中矩的,panelists 有點放不開,我就提了一個問題,網絡歷史上的重要成就基本上都基于對應用場景深刻的理解,但我們現在做網絡的很多都不了解 AI,甚至連每個 tensor 的大小和每個 step 傳輸的數據量都不知道,如何讓 network community 更了解 AI 呢?
這下熱鬧了,臺下的譚博首先發言,說我在華為肯定能知道所有這些東西;然后傳雄老師也跟了一句,要是做網絡的懂了太多 AI,那可能他就變成一個 AI guy 了。接著主持人陳凱教授問,你們有誰真的訓練過大模型?沉默了一會兒,阿里的兄弟先說,我算是半個訓練過大模型的,我們做的東西是支撐阿里大模型 infra 的。后面又有 panelist 說,做 AI 系統的網絡優化是否有必要自己懂 AI 呢,是不是只要會做 profiling 就行了?
我個人觀點仍然是,AI 并不難學,要想做好 AI 系統優化,可以不懂 attention 的 softmax 里面為什么要除以 sqrt(d_k),但不能不會計算模型所需的算力、內存帶寬、內存容量和通信數據量。Jeff Dean 就有個很有名的 Numbers Every Programmer Should Know,數量級的估算對任何系統優化來說都很關鍵,不然根本不知道瓶頸在哪里。
回到大模型訓練所需的總算力,其實很簡單,6 * 模型的參數量 * 訓練數據的 token 數就是所有訓練數據過一遍所需的算力。這里的 6 就是每個 token 在模型正向傳播和反向傳播的時候所需的乘法、加法計算次數。
一堆矩陣相乘,簡單來想就是左邊若干個神經元,右邊若干個神經元,組成一個完全二分圖。選出其中任意一個左邊的神經元 l 和右邊的神經元 r。
正向傳播的時候:
l 把它的輸出乘上 l 和 r 之間的權重 w,發給 r;
r 不可能只連一個神經元吧,總要把多個 l 的加到一起,這就是 reduce,需要一次加法。
反向傳播的時候:
r 把它收到的梯度乘上 l 和 r 之間的權重 w,發給 l;
l 也不可能只連一個 r,需要把梯度 reduce 一下,做個加法;
別忘了權重 w 需要更新,那就要計算 w 的梯度,把 r 收到的梯度乘上 l 正向傳播的輸出(activation);
一個 batch 一般有多個 sample,權重 w 的更新需要把這些 sample 的梯度加到一起。
一共 3 次乘法,3 次加法,不管 Transformer 多復雜,矩陣計算就是這么簡單,其他的向量計算、softmax 之類的都不是占算力的主要因素,估算的時候可以忽略。
想起來我 2019 年剛加入 MindSpore 團隊的時候,領導讓我開發一個正向算子的反向版本,我求導給求錯了,搞得算子的計算結果總是不對,還以為是我們的編譯器出 bug 了。當發現求導求錯的時候,領導像以為我沒學過微積分一樣看著我,確實我的微積分學的不好,這也是我從數學專業轉到計算機專業的原因之一。
在 MindSpore 的時候,自動微分一共就不到 1000 行代碼,按照微分公式遞歸計算下去就行了,但自動微分作為一個重要特性被吹了半天,我都感覺不好意思了。
模型的參數量和訓練數據的 token 數之間也有個比例關系,這也很容易理解,只要把模型想象成數據的壓縮版本就行了,壓縮比總是有極限的。模型的參數量太小,就吃不下訓練數據里面所有的知識;模型的參數量如果大于訓練數據的 token 數,那又浪費,還容易導致 over-fitting。
訓練 LLaMA-2 70B 需要多少張卡
有了模型訓練所需的總算力,除以每個 GPU 的理論算力,再除以 GPU 的有效算力利用比例,就得到了所需的 GPU-hours,這塊已經有很多開源數據。LLaMA 2 70B 訓練需要 1.7M GPU hours(A100),要是用 1 個 GPU,那得算 200 年。要在一個月這種比較能接受的時間周期內訓練出來,就得至少有 2400 塊 A100。
如果用 4090,單卡 FP16 算力是跟 A100 差不多(330 vs 312 Tflops),但是內存帶寬比 A100 低一半(1 vs 2 TB/s),內存容量更是差好幾倍(24 vs 80 GB),計算梯度時需要使用的 TF32 算力也低一半(83 vs 156 Tflops),綜合起來 4090 單卡的訓練速度還比 A100 稍低(參考前面 LambdaLabs 的評測)。
就按照 2048 塊 4090 算吧,這 2048 塊 4090 之間的通信就成了最大的問題。
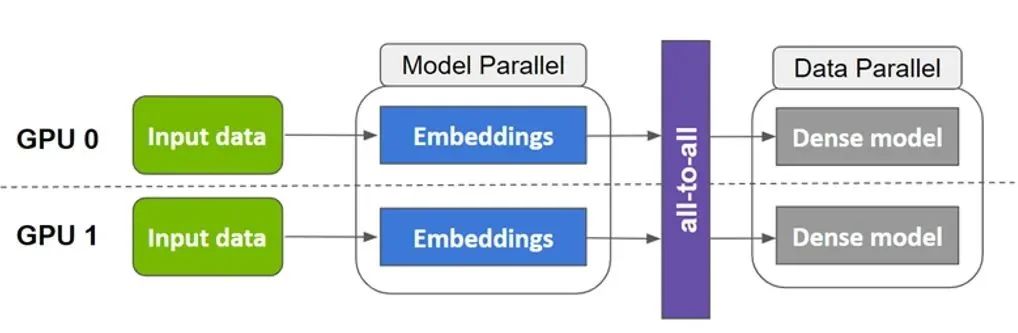
為什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 幾種并行方式,分別在模型的層內、模型的層間、訓練數據三個維度上對 GPU 進行劃分。三個并行度乘起來,就是這個訓練任務總的 GPU 數量。
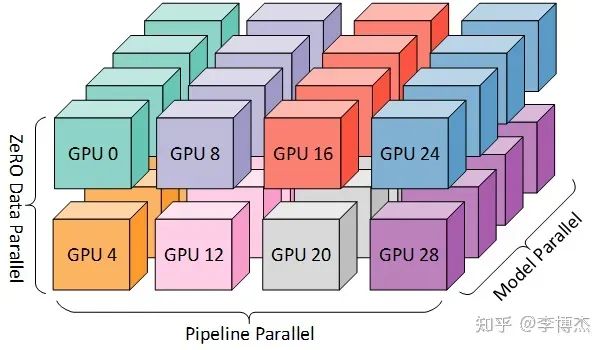
三種并行方式從三個維度劃分計算空間的示意圖,來源:DeepSpeed
Data parallelism(數據并行)
數據并行是最容易想到的并行方式。每個 GPU 分別計算不同的輸入數據,計算各自的梯度(也就是模型參數的改變量),再把梯度匯總起來,取個平均值,廣播給各個 GPU 分別更新。
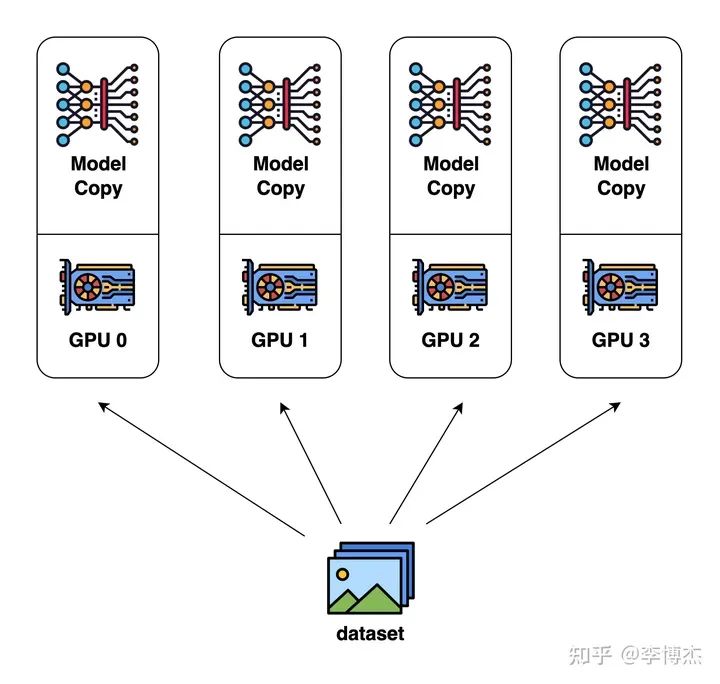
Data Parallelism 示意圖,來源:Colossal AI
但只用數據并行是肯定不行的,因為一塊 GPU 放不下整個 LLaMA 70B 模型。
就模型訓練需要多少 GPU 內存,我發現能算清楚的人就不多。有的人甚至以為只需要把模型的參數和反向傳播的梯度存下來就夠了。事實上,訓練需要的內存包括模型參數、反向傳播的梯度、優化器所用的內存、正向傳播的中間狀態(activation)。
優化器所用的內存其實也很簡單,如果用最經典的 Adam 優化器,它需要用 32 位浮點來計算,否則單純使用 16 位浮點來計算的誤差太大,模型容易不收斂。因此,每個參數需要存 4 字節的 32 位版本(正向傳播時用 16 位版本,優化時用 32 位版本,這叫做 mixed-precision),還需要存 4 字節的 momentum 和 4 字節的 variance,一共 12 字節。如果是用類似 SGD 的優化器,可以不存 variance,只需要 8 字節。
正向傳播的中間狀態(activation)是反向傳播時計算梯度必需的,而且跟 batch size 成正比。Batch size 越大,每次讀取模型參數內存能做的計算就越多,這樣對 GPU 內存帶寬的壓力就越小。可是不要忘了,正向傳播的中間狀態數量是跟 batch size 成正比的,GPU 內存容量又會成為瓶頸。
大家也發現正向傳播中間狀態占的內存太多了,可以玩一個用算力換內存的把戲,就是不要存儲那么多梯度和每一層的正向傳播的中間狀態,而是在計算到某一層的時候再臨時從頭開始重算正向傳播的中間狀態,這樣這層的正向傳播中間狀態就不用保存了。如果每一層都這么干,那么就只要 2 個字節來存這一層的梯度。但是計算中間狀態的算力開銷會很大。因此實際中一般是把整個 Transformer 分成若干組,一組有若干層,只保存每組第一層的中間狀態,后面的層就從該組第一層開始重新計算,這樣就平衡了算力和內存的開銷。
如果還是算不清楚,可以讀讀這篇論文:Reducing Activation Recomputation in Large Transformer Models。
當然有人說,GPU 內存放不下可以換出到 CPU 內存,但是就目前的 PCIe 速度,換出到 CPU 內存的代價有時候還不如在 GPU 內存里重算。如果是像 Grace Hopper 那種極高帶寬的統一內存,那么換入換出倒是一個不錯的主意,不管訓練的正向傳播中間狀態還是 KV Cache,都有很多優化的空間。
Pipeline parallelism(流水線并行)
既然一塊 GPU 放不下,用多塊 GPU 總行了吧?這就是?model parallelism(模型并行),可以大致分為 pipeline parallelism 和 tensor parallelism。
大家最容易想到的并行方式就是?pipeline parallelism,模型不是有很多層嗎,那就分成幾組,每組算連續的幾層,穿成一條鏈。
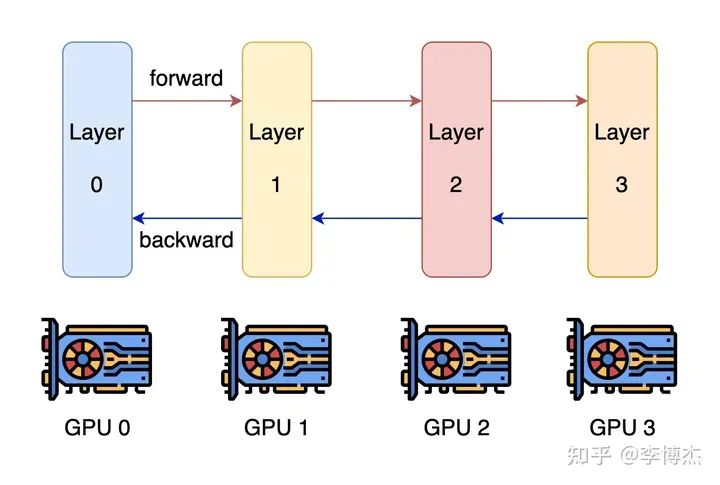
Pipeline Parallelism 示意圖,來源:Colossal AI
這樣就有個問題,一條鏈上只有一個 GPU 在干活,剩下的都在干等。當然聰明的你一定也想到了,既然叫 pipeline,那就可以流水線處理,可以把一個 batch 分為若干個 mini-batch,每個 mini-batch 分別計算。
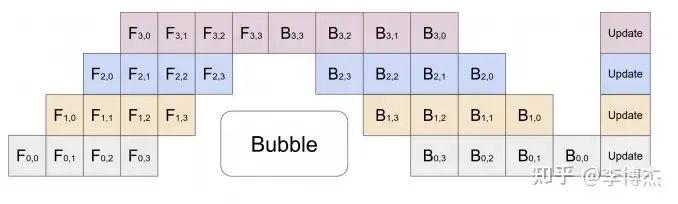
Pipeline Parallelism 示意圖,來源:GPipe
這可好,是不是把 pipeline 搞的越深越好,每個 GPU 只算一層?
首先,正向傳播中間狀態(activation)的存儲容量會成倍增加,加劇內存容量不足的問題。比如流水線的第一級算出了正向傳播的中間狀態,如果有 N 個流水級,那就要正向流過后面的 N - 1 個流水級,再等反向傳播 N - 1 個流水級,也就是 2N - 2 輪之后才能用到這個正向傳播的中間狀態。不要忘了每一輪都會產生這么多中間狀態,因此一共是保存了 2N - 1 個中間狀態。如果 N 比較大,這個存儲容量是非常恐怖的。
其次,pipeline 的相鄰流水級(pipeline stage)之間是要通信的,級數越多,通信的總數據量和總時延就越高。
最后,要讓這樣的 pipeline 流起來,batch size 需要等于 Transformer 里面的層數,一般是幾十,再乘以 data parallelism 的并行數,batch size 會很大,影響模型收斂的速度或模型收斂后的精度。
因此,在內存容量足夠的情況下,最好還是少劃分一些流水級。
對于 LLaMA-2 70B 模型,模型參數需要 140 GB,反向傳播的梯度需要 140 GB,優化器的狀態(如果用 Adam)需要 840 GB。
正向傳播的中間狀態跟 batch size 和選擇性重新計算的配置有關,我們在算力和內存之間取一個折中,那么正向傳播的中間狀態需要 token 長度 * batch size * hidden layer 的神經元數量 * 層數 * (10 + 24/張量并行度) 字節。假設 batch size = 8,不用張量并行,那么 LLaMA-2 70B 模型的正向傳播中間狀態需要 4096 * 8 * 8192 * 80 * (10 + 24) byte = 730 GB,是不是很大?
總共需要 140 + 140 + 840 + 730 = 1850 GB,這可比單放模型參數的 140 GB 大多了。一張 A100/H100 卡也只有 80 GB 內存,這就至少要 24 張卡;如果用 4090,一張卡 24 GB 內存,就至少需要 78 張卡。
LLaMA-2 模型一共就只有 80 層,一張卡放一層,是不是正好?這樣就有 80 個流水級,單是流水線并行就有 80 個并行的 batch 才能填滿流水線。
這樣,正向傳播的中間狀態存儲就會大到無法忍受,這可是 80 * 2 = 160 輪的中間狀態,翻了 160 倍。就算是使用選擇性重新計算,比如把 80 層分成 8 組,每組 10 層,中間狀態存儲仍然是翻了 16 倍。
除非是用最極端的完全重新計算,反向傳播到每一層都重新從頭開始計算正向傳播的中間結果,但這樣計算開銷可是隨模型層數平方級別的增長,第 1 層算 1 層,第 2 層算 2 層,一直到第 80 層算 80 層,一共算了 3240 層,計算開銷可是比正常算一次 80 層翻了 40 倍,這還能忍?
中間狀態存儲的問題就已經夠大了,再看這 2048 張卡之間的通信開銷。按照一張卡放一層,并且用不同的輸入數據讓它完全流水起來的做法,這 2048 張卡分別在計算自己的 mini-batch,可以認為是獨立參與到 data parallelism 里面了。前面講過,在數據并行中,每一輪需要傳輸的是它計算出的梯度和全局平均后的梯度,梯度的數據量就等于模型的參數數量。
把 70B 模型分成 80 層,每一層大約有 1B 參數,由于優化器用的是 32 bit 浮點數,這就需要傳輸 4 GB 數據。那么一輪計算需要多久呢?總的計算量 = batch size * token 數量 * 6 * 參數量 = 8 * 4096 * 6 * 1B = 196 Tflops,在 4090 上如果假定算力利用率 100%,只需要 0.6 秒。而通過 PCIe Gen4 傳輸這 4 GB 數據就已經至少需要 0.12 秒了,還需要傳兩遍,也就是先傳梯度,再把平均梯度傳過來,這 0.24 秒的時間相比 0.6 秒來說,是占了比較大的比例。
當然我們也可以做個優化,讓每個 GPU 在 pipeline parallelism 中處理的 80 組梯度數據首先在內部做個聚合,這樣理論上一個 training step 就需要 48 秒,通信占用的時間不到 1 秒,通信開銷就可以接受了。當然,通信占用時間不到 1 秒的前提是機器上插了足夠多的網卡,能夠把 PCIe Gen4 的帶寬都通過網絡吐出去,否則網卡就成了瓶頸。假如一臺機器上插了 8 塊 GPU,這基本上需要 8 塊 ConnectX-6 200 Gbps RDMA 網卡才能滿足我們的需求。
最后再看 batch size,整個 2048 張卡的集群跑起來,每個 GPU 的 mini-batch 我們剛才設置為 8,那可真是 batch size = 16384,已經是大規模訓練中比較大的 batch size 了,如果再大,可能就影響模型的收斂速度或收斂后的精度了。
因此,單純使用流水線并行和數據并行訓練大模型的最大問題在于流水線并行級數過多,導致正向傳播中間狀態(activation)存儲容量不足。
Tensor parallelism(張量并行)
那就沒辦法了嗎?我們還有最后一招,就是 Tensor parallelism(張量并行)。它也是模型并行的一種,但不像流水線并行那樣是在模型的層間劃分,而是在模型的層內劃分,也就是把一層內的 attention 計算和 Feed Forward Network 劃分到多個 GPU 上處理。
有了張量并行,就可以緩解 GPU 放不下模型導致的流水級太多的問題。分到 80 個 GPU 才能放下的模型,如果用單機 8 卡張量并行,就只需要劃分 10 個流水級。同時,張量并行還可以降低 batch size,因為張量并行的幾個 GPU 是在算同一個輸入數據。
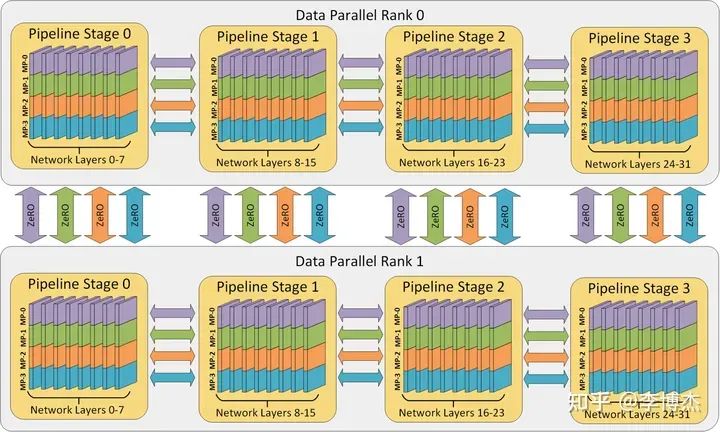
Tensor、Pipeline、Data 三種并行方式從模型層內、模型層間、訓練數據三個維度上劃分計算空間,來源:DeepSpeed
Attention 的計算過程是比較容易并行的,因為有多個 head,用來關注輸入序列中的不同位置的,那么把這些 head 分別拆開就行了。
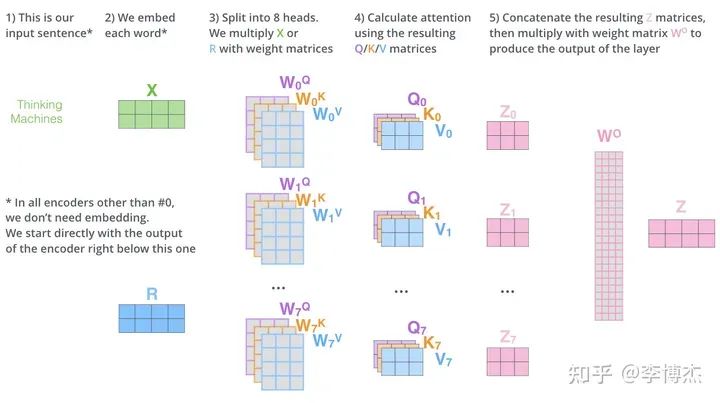
Attention 的計算過程,來源:The Illustrated Transformer
但是我們做任何并行計算的時候都不要忘記通信開銷。
每個 head 里面的 Q、K 兩個矩陣的大小是 batch size * token 長度 * key 的大小,V 矩陣的大小是 batch size * token 長度 * value 的大小。key/value 的大小一般等于 embedding size / heads 數量,例如在 LLaMA-2 70B 中就是 8192 / 64 = 128,矩陣大小是 batch size * 4096 * 8192 / 64(注意,這只是一個 head 的)。而 Q、K、V 參數矩陣在每個 head 上的大小是 embedding size * embedding size / heads num = 8192 * 8192 / 64。
我們前面推導過,正向的計算量基本上就是每個 token 過一遍所有參數的計算量,2 * 3 (Q, K, V) * batch size * token 長度 * 參數個數 = 2 * 3 * batch size * 4096 * 8192 * 8192 / 64。可以跟矩陣的大小對一下,看看有沒有算錯。
那么通信量是多少呢?輸出矩陣 Z 是由每個 head 拼起來的,每個 head 的大小是 batch size * token 長度 * embedding size / heads num = batch size * 4096 * 8192 / 64。輸入矩陣 X 的大小是 batch size * token 長度 * embedding size = batch size * 4096 * 8192。注意這里的 X 大小跟所有 heads 合并在一起后的 Z 大小是一致的,而我們在這里算的是每個 head 的 Z 大小。這里的單位是參數數量,如果按照字節算,還要乘以每個參數的大小。
如果我們采用最極端的方式,每個 head 交給一個 GPU 去算,那么計算量和通信量的比例是多少?大概是 2 * 3 * embedding size / heads num / bytes per param = 2 * 3 * 8192 / 64 / 2 = 384。代入 4090 的 330 Tflops,如果想讓通信不成為瓶頸,那么通信帶寬至少需要是 330T / 384 = 859 GB/s,發送接收雙向還得乘以 2,就是 1.7 TB/s。太大了,遠遠超過 PCIe Gen4 x16 的 64 GB/s,就算 NVLink 的 900 GB/s 都撐不住。
所以,tensor parallelism 不能切得太細,每個 GPU 需要多算幾個 heads。如果每個 GPU 多算幾個 attention heads,輸入矩陣 X 就是這些 heads 共享的了,因此輸入矩陣的通信開銷就被多個 heads 平攤了,計算量和通信量的比例就可以提高。
還是按照 4090 的算力 / 單向通信帶寬 = 330T / (64GB/s / 2) 來算,計算量和通信量的比例最少需要是 10000,也就是 2 * 3 * (embedding size / 張量并行 GPU 數量) / bytes per param = 2 * 3 * 8192 / 張量并行 GPU 數量 / 2 >= 10000,解得:張量并行 GPU 數量 <= 2.4。也就是告訴你,要是用了張量并行,最多用 2 個 GPU,如果用更多的 GPU,算力就肯定跑不滿理論值。這讓我怎么玩?
但是,如果把 H100 的參數代入進去,馬上就不一樣了。H100 的峰值算力是 1979 Tflops,NVLink 雙向帶寬是 900 GB/s,計算量和通信量的比例最少需要是 4400,也就是 2 * 3 * (embedding size / 張量并行 GPU 數量) / bytes per param = 2 * 3 * 8192 / 張量并行 GPU 數量 / 2 >= 4400,解得:張量并行 GPU 數量 <= 5.5,也就是單機 8 卡做張量并行,如果算力跑滿,網絡會成為瓶頸。可以看到,即使對于 900 GB/s 這么快的 NVLink,在巨大的算力面前,都容易出現茶壺里煮餃子倒不出來的情況。當然,采用更優的并行切分方式可以節約一些網絡通信開銷。
閹割版的 H800 相比 H100 卡的就是網絡帶寬,把網絡帶寬從 900 GB/s 降到 400 GB/s 了。我們再代入一次,計算量和通信量比例最少需要是 10000,那么張量并行 GPU 數量 <= 2.4,跟 4090 一個貨色了。這樣單機 8 卡做張量并行,就會導致網絡成為瓶頸。當然,計算量 1979 Tflops 是理論值,并行切分方式也可以優化,因此實際訓練 70B 的模型 8 卡 H800 網絡不一定真的是瓶頸。這就是 H800 精準打擊大模型訓練,讓張量并行過得不舒服。
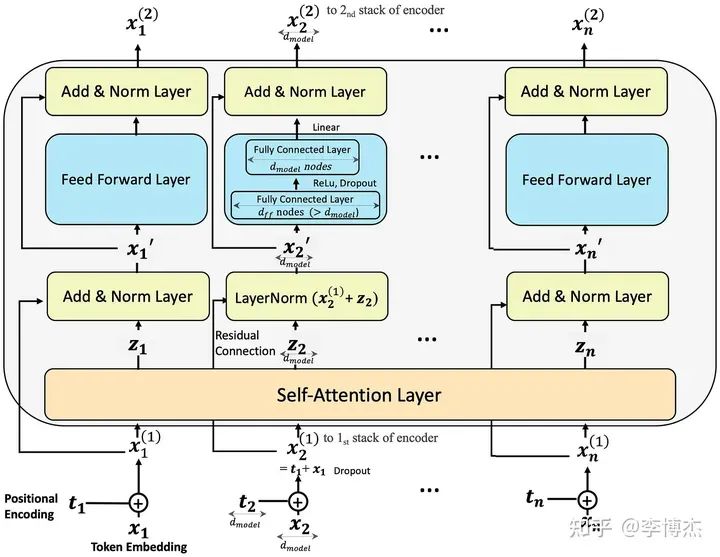
Feed Forward Network 的計算過程,雖然這是 encoder 的,但 decoder 也差不多,來源:Step-by-Step Illustrated Explanations of Transformer
如果在 Feed Forward Network 這里做張量并行,也是可以做類似的推導,在這里就不贅述了。大凡神經網絡里的矩陣乘法,M*N 的矩陣乘上 N*K 的矩陣,總的計算量是 M*N*K,輸入輸出的總大小是 (M*N + N*K),多摞幾個矩陣那也是常數(就像 Q、K、V),也就是計算和通信的比例跟矩陣的邊長(dimension)是一個量級的。
這么分析完了,如果你是要做大規模大模型訓練,你還會買 A100/H100/H800 的 PCIe 版嗎?PCIe Gen5 雖然比 Gen 4 快一倍,但對 H100 而言,計算量和通信量的比例仍然最少需要是 1979T / (128G / 2) = 30000,解出來張量并行 GPU 數量 <= 0.8,只要用了張量并行,就是損失算力的!
等到 H100 的下一代出來了,比如 GH200,算力又翻了一倍,NVLink 還是 900 GB/s,這時候 NVLink 就也開始有點吃力了。所以 GH200 不失時機的推出了統一大內存,號稱 144 TB,就是為了更好的做換入換出,用內存換網絡通信。如果禁令保持不變,國內版本還是卡住 400 GB/s 的通信,那性能差距會有多大?
上面的推導當然都是簡化的,實際上可能不會這么夸張,但數量級是差不多的。
訓練部分小結
4090 不容易做大模型訓練的原因除了前面分析的內存小,通信慢,license 不支持數據中心,還有很多其他問題。
比如,A100/H100 支持 ECC 顯存容錯,據說 4090 也支持 ECC,但是不知道故障率會不會比 A100/H100 更高。不要小看了容錯,2048 張卡的集群就算每張卡 1 個月出一次故障,平均 20 分鐘就會有一張卡出故障!要是沒有自動化的故障恢復方式,煉丹師就別想睡覺了。
就算是自動從上一個 checkpoint 恢復,這可是要時間的,如果不考慮丟棄故障 GPU 梯度這種比較暴力的方式,當前這個 step 就算是白算了,還要從上一個 checkpoint 加載梯度,一般需要 10 來分鐘的時間才能搞定。這樣,每 20 分鐘就浪費 10 分鐘,這 10 分鐘恢復過程中可能又有新的卡故障,總的算下來要浪費掉一半的有效算力。
因此,保持大規模訓練集群的低故障率是非常重要的,這些 GPU 卡都非常金貴,可不能像挖礦機房那樣,動不動就過熱死機了。
據說 3090 是支持 NVLink 的,但 4090 就把 NVLink 給砍掉了。更老的卡,甚至還有支持 PCIe P2P 的,現在也都被砍掉了。誰感興趣可以測一測 3090 的 NVLink 性能怎么樣,是不是真的能達到標稱的 600 GB/s,如果真的能達到的話,是否又可以用來做大模型訓練了呢。
我們年會的時候,海哥講了個段子,我們找老婆都希望又漂亮,又能掙錢,還一心一意愛自己。可同時滿足這三個條件的老婆就很難找到了。類似的,在分布式系統中,我們都希望性能又高,通用性又強,成本還低。這三個條件的交集也很小。海哥講到這里,譚博補充了一句,同時滿足這三個條件的分布式系統根本就不存在。
Tensor、Pipeline、Data Parallelism 就像是這樣的不可能三角,相互牽制,只要集群規模夠大,模型結構仍然是 Transformer,就很難逃出內存容量和網絡帶寬的魔爪。
大模型推理為什么 4090 很香
推理和訓練有什么區別?
首先,訓練不僅需要存儲模型參數,還需要存儲梯度、優化器狀態、正向傳播每一層的中間狀態(activation),后面幾個比參數更大,對模型內存的需求量也更大。
其次,訓練任務是一個整體,流水線并行的正向傳播中間結果是需要存下來給反向傳播用的。為了節約內存而使用流水線并行,流水級越多,要存儲的中間狀態也就更多,反而加劇內存的不足。而推理任務中的各個輸入數據之間并沒有關系,正向傳播每一層的中間狀態也不需要保存下來,因此流水線并行不需要存儲很多中間狀態。
首先我們需要計算一下推理需要多少算力。前面針對訓練算力的估算,為了簡單起見,忽略了兩個事情,首先是沒有考慮 KV Cache,其次是沒有考慮內存帶寬。
KV Cache
什么是 KV Cache?對于每個輸入的 prompt,在計算第一個 token 輸出的時候,每個 token 的 attention 肯定是都要從頭計算。但是在后續 token 的生成中,都需要計算 self-attention,也就是輸入 prompt 以及前面輸出的 token 的 attention。這是就需要用到前面每一個 token 的 K 和 V,由于每一層的參數矩陣是不變的,此時只有剛生成的那個 token 的 K 和 V 需要從頭計算,輸入 prompt 和之前生成的 token 的 K 和 V 其實是跟上一輪一樣的。
這時,我們就可以把每一層的 K、V 矩陣緩存起來,生成下一個 token 的時候不再需要重新計算,這就是所謂的 KV Cache。Q 矩陣每次都不一樣,沒有緩存的價值。前面講的訓練中的選擇性保存正向 activation 是個拿計算換內存的把戲,這里的 KV Cache 就是一個拿內存換計算的把戲。
KV Cache 需要多少存儲容量呢?每一層,每個 token 的 K、V 矩陣都是 embedding size 這么大,再乘上 token 數量和 batch size,就是這一層的 KV Cache 所需的存儲容量了。一定要記住 batch size,在正向和反向傳播的幾乎所有階段,都不會涉及到對 batch size 中各個 sample 的合并處理,因此它始終是存儲量和計算量計算中的一個系數。
例如,如果 batch size = 4,在 LLaMA 2 70B 中,假設輸入和輸出的 token 數量達到了模型的極限 4096,80 層的 KV Cache 一共需要 2 (K, V) * 80 * 8192 * 4096 * 8 * 2B = 80 GB。如果 batch size 更大,那么 KV Cache 占據的空間將超過參數本身占的 140 GB。
KV Cache 能省下來多少計算量?每一層計算 K、V 矩陣一共需要 2 (K, V) * 2 (mult, add) * embedding size * embedding size = 4 * 8192 * 8192 這么多計算量,乘以之前輸入過的 token 數量、層數和 batch size,就是 4096 * 80 * 8 * 4 * 8192 * 8192 = 640 Tflops。相當于每存儲 1 個字節,節約了 16K 次計算,還是很劃算的。
事實上,KV Cache 節約的遠遠不止這些。計算 K、V 矩陣的過程是個典型的內存密集型過程,它需要加載每一層的 K、V 參數矩陣。也就是如果不做任何緩存,假設 prompt 長度很短而輸出長度接近 token 的最大長度 4096,到了最后一個 token 的時候,單是重復計算前面每個 token 的 K、V 矩陣,就需要讀取內存 4096 * 80 * 2 * 8192 * 8192 = 40T 次,每次 2 個字節,要知道 H100 的內存帶寬只有 3.35 TB/s,4090 更是只有 1 TB/s,這單是最后一個 token 就得耗掉一張卡幾十秒的時間來做重復計算。這樣,token 的輸出就會越來越慢,整個輸出時間是輸出長度平方級別的,根本沒法用。
推理是計算密集還是存儲密集
接下來我們就可以計算推理所需的計算量了。總的算力很好算,前面講過,大概就是?2 * 輸出 token 數量 * 參數數量 flops。如果想看細節,可以看下面這張圖,來源是這里。
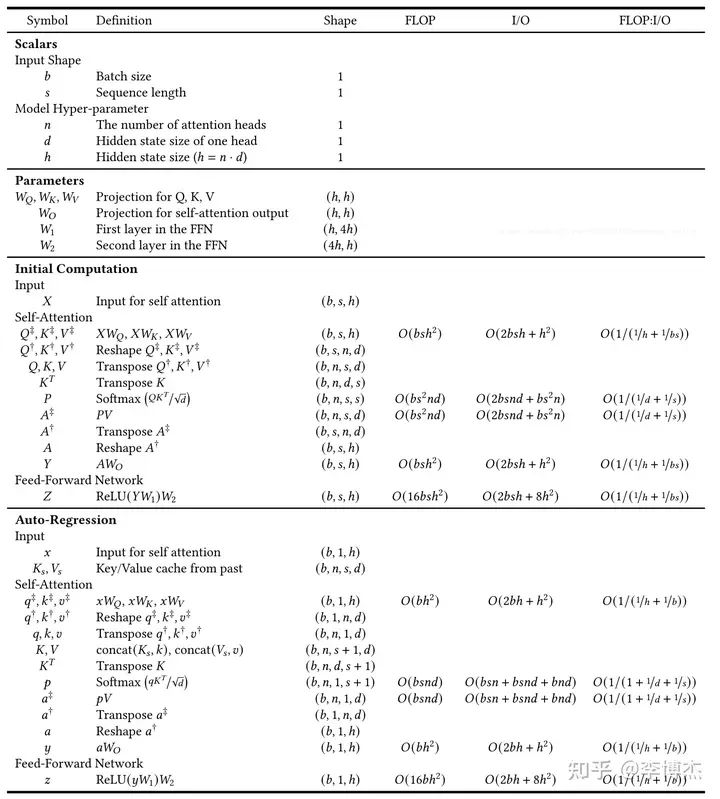
Transformer 推理過程中每一步的矩陣形狀、所需算力和內存訪問量,來源:Lequn Chen,Dissecting Batching Effects in GPT Inference
但算力并不能說明一切,模型還需要訪問 GPU 內存,內存帶寬也可能成為瓶頸。至少需要把參數從內存里面讀出來吧?事實上,內存帶寬的估算就這么簡單,內存訪問量 = 參數數量 * 2 bytes。中間結果有一部分是可以放在緩存里面的,緩存放不下的部分也需要占內存帶寬,我們先不算。
如果不做任何批量輸入,也就是模型專門服務一個 prompt,batch size = 1,整個 context 的長度很短(例如只有 128),那么整個推理過程中,每載入一個參數(2 字節),就只進行 128 次乘法和加法計算,那么計算 flops 和訪問內存 bytes 的比例就只有 128。基本上任何 GPU 在這種情況下都會變成 memory bound,時間都耗在加載內存上了。
對于 4090 來說,計算 flops 和內存帶寬之比是 330 / 1 = 330;對于 H100 來說,計算 flops 和內存帶寬之比是 1979 / 3.35 = 590。也就是說,如果 context 中的 token 數量小于 330 或者 590,那么內存訪問就會成為瓶頸。
雖然 LLaMA 2 的理論上限是 4096 個 token,但很多輸入 prompt 用不了這么多,因此內存訪問是有可能成為瓶頸的。此時,就需要靠 batch size 來補足了。推理中的批量處理,就是把幾乎同時到達后端服務的 prompt 放到一起處理。不用擔心,batch 里面的不同 prompt 的處理是完全獨立的,不用擔心會互相干擾。但這些 prompt 的輸出是步調整齊劃一的,每一輪整個 batch 中的每個 prompt 都會輸出一個 token,因此如果有的 prompt 先輸出完了,那就只能等其他的輸出結束,造成一定的算力浪費。
有的人問,批量處理所需的算力跟分別單獨處理所需的算力是一樣的呀,那推理時為什么需要批量處理?答案就在訪問內存的帶寬上。
如果同時到達服務器的 prompt 很多,是不是 batch size 越大越好?也不是,因為 KV Cache 的大小可是正比于 batch size 的,batch size 大了,KV Cache 占據的 GPU 內存容量就很可觀,比如在 LLaMA-2 70B 中,每個 prompt 都要占據 5 GB 的 KV Cache,如果 batch size 搞到 32,那么 KV Cache 就會占掉 160 GB 的 GPU 內存,比參數都大了。
70B 推理需要多少張卡?
總的存儲容量也很好算,推理的時候最主要占內存的就是參數、KV Cache 和當前層的中間結果。當 batch size = 8 時,中間結果所需的大小是 batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB,相對來說是很小的。
70B 模型的參數是 140 GB,不管 A100/H100 還是 4090 都是單卡放不下的。那么 2 張 H100 夠嗎?看起來 160 GB 是夠了,但是剩下的 20 GB 如果用來放 KV Cache,要么把 batch size 壓縮一半,要么把 token 最大長度壓縮一半,聽起來是不太明智。因此,至少需要 3 張 H100。
對于 4090,140 GB 參數 + 40 GB KV Cache = 180 GB,每張卡 24 GB,8 張卡剛好可以放下。
推理用流水線并行可以嗎?
推理使用流水線并行,最主要的問題是串行處理的推理延遲,網絡延遲倒是小問題。
首先是推理延遲。雖然流水線的不同階段可以塞進不同的 prompt,但同一個 prompt 的處理仍然永遠在單個 GPU 上輪轉,這樣相比 Tensor parallelism 而言,單個 prompt 的延遲就增大了。
對于很小的 batch size,GPU 內存帶寬是瓶頸,此時每張卡計算每個 token 的時延就是 2 byte * 參數量 / 卡的數量 / 內存帶寬,例如 8 卡 4090 跑 LLaMA-2 70B,就是 2 * 70G / 8 / 1 TB/s = 0.0175 秒。這里沒有考慮 KV Cache 帶來的節約。注意,8 張卡是串行處理的,因此每個 token 的時延還要乘以 8,也就是 0.14 秒。每秒只能輸出 7 個 token,對于 70B 這么小的模型來說是有點慢了。
對于很大的 batch size,GPU 算力是瓶頸,此時每張卡計算每個 token 的時延就是 batch size * 2 * 參數量 / 卡的數量 / 算力,例如 batch size = 1024,同樣的 8 卡例子,就是 1024 * 2 * 70G / 8 / 330 Tflops = 0.0543 秒。事實上,對于這么大的 batch size,KV Cache 和正向傳播的中間結果先把 GPU 內存給吃滿了。
那么要平衡利用 GPU 算力和內存帶寬,batch size 需要是多少呢?這就是 2 byte * 參數量 / 卡的數量 / 內存帶寬 = batch size * 2 * 參數量 / 卡的數量 / 算力,左右兩邊參數量和卡的數量互相抵消,得到 batch size = 算力 / 內存帶寬。對于 4090,就是 330 / 1 = 330;對于 H100,就是 1979 / 3.35 = 590。也就是說,對 4090 而言,batch size 小于 330 的時候 GPU 內存帶寬是瓶頸,大于 330 的時候 GPU 算力是瓶頸。當 batch size = 330 的時候,理想情況下,內存帶寬和算力恰好都打滿,每張卡處理每個 token 的時間就是 17.5 ms。
其次是網絡延遲。流水線并行相比張量并行的優點就是網絡傳輸量小,流水級之間只需要傳輸 batch size * embedding size 這么多數據。例如 batch size = 8,embedding size = 8192,只需要傳輸 128 KB 數據,在 32 GB/s 的 PCIe Gen4 x16 上,只需要 4 us 就可以傳輸完成。當然,還需要考慮到通信庫本身的開銷,加上 4090 不支持 GPU 之間 P2P 傳輸,需要通過 CPU 中轉,實際上需要幾十 us 的時間,相比計算部分動輒幾十 ms 的時延,可以忽略不計。
即使 batch size = 330,這 5.28 MB 數據在 PCIe 上也只需要傳輸 0.16 ms,相比計算部分的 17.5 ms 仍然可以忽略不計。
如果可以忍受流水線并行的推理延遲,甚至可以用多臺主機來做流水線并行。我們假設主機間只有 1 Gbps 的普通以太網絡,每臺主機只有一張 4090。對于 batch size = 1,16 KB 數據需要 0.25 ms 才能傳輸完成,再加上 0.25 ms 兩端網絡協議棧的處理時間,每個流水級就需要 0.5 ms 的時延,8 張卡花在通信上的時間只有 4 ms,相比整體計算時延 140 ms 來說可以忽略,不會顯著影響系統的推理延遲。
當 batch size 很小時,流水線推理中的網絡流量是突發性(bursty)的,每過 18 ms 只會進行 0.25 ms 數據傳輸,只有 1/72 的占空比,不用擔心流水線推理把局域網全部給占滿了,搞得沒法正常上網了。
如果為了充分利用算力,把 batch size 設置得很大,比如 330,那么 16 KB * 330 = 5.28 MB 數據需要傳輸 41 ms,8 張卡花在通信上的時間高達 0.33 秒,這樣就只有 3 token/s 的輸出速度了,難以忍受。因此,如果用主機間通信來做流水線并行,主機間又沒有很高的通信帶寬,就勢必需要犧牲一定的吞吐量。
例如,我們設置輸出速度不小于 5 token/s,這時留給通信的時間是 60 ms,每個流水級至多 7.5 ms,1 Gbps 網絡可以傳輸 960 KB 數據,這時 batch size 至多設置為 60,也就是這 8 張 4090 的總吞吐量是 2400 token/s。此時的有效算力利用率只有不到 20%。
最近有一個比較火的 Petals 開源項目,就是利用流水線并行,把 GPU 做成了一個類似 BitTorrent 的分布式網絡。雖然推理延遲確實比較高,但至少說明了分布式 GPU 推理的可行性。
推理用張量并行怎么樣?
前面講到,流水線并行的最大缺點是 GPU 串行處理,延遲較高,導致輸出 token 比較慢。而張量并行的最大缺點是傳輸數據量大,網絡帶寬低的設備不一定 hold 得住。
但是推理要傳輸的數據量跟訓練要傳輸的數據量可不是一回事啊!推理只需要傳輸正向傳播的中間結果(activation),而訓練還需要傳輸所有參數的梯度,梯度才是數據量的大頭。
在推理中,如果使用張量并行,Transformer 的每一層都需要傳輸把自己負責的結果向量(大小為 batch size * embedding size / num GPUs)廣播給其他所有 GPU,并接受來自所有其他 GPU 廣播來的數據。計算 attention 的時候需要傳輸一次,計算 feed-forward network 的時候又需要傳輸一次,也就是總共需要傳輸 2 * 層數這么多次。
每次發送就是 batch size * embedding size(發送和接收是不同的方向,不能算兩次),對于 batch size = 1, embedding size = 8192,只需要傳輸 16 KB 數據,在 32 GB/s 的 PCIe Gen4 上傳輸只需要 1 us。當然,考慮到前面討論的 CPU 中轉開銷,還是需要大約 30 us 的。一共 160 次傳輸,需要 4.8 ms。
我們再考慮計算的開銷。還是考慮 batch size = 1 的情形,GPU 內存帶寬是瓶頸,此時每張卡計算每個 token 的時延就是 2 byte * 參數量 / 卡的數量 / 內存帶寬,代入我們前面的數值,仍然是 17.5 ms。但是這里 8 張卡是并行處理的,因此總的處理時長就是計算時間 + 通信時間 = 17.5 ms + 4.8 ms = 22.3 ms。這就意味著每秒可以生成 45 個 token,這個 token 生成速度已經很不錯了,至少人類的閱讀速度是很難趕上生成的速度了。
如果 batch size 更大會怎樣?例如 batch size = 330,把 GPU 算力和內存帶寬都充分利用起來,每次需要傳輸的數據量是 330 * 8192 * 2 = 5.4 MB,在 32 GB/s 的 PCIe Gen4 上需要 0.17 ms。一共 160 次傳輸,就是 27 ms。這下網絡通信開銷成了延遲的大頭,總處理時長為 27 + 17.5 = 44.5 ms,每秒只能生成 22 個 token 了,但也不算慢。
注意,不管用多少個 GPU 做并行推理,只要用的是張量并行,網絡傳輸的總數據量是相同的,因此增加 GPU 的數量只能加速計算,不能加速通信。
因此,A100/H100 的 NVLink 在降低推理延遲方面還是有很大作用的。如果用 A100/H100,取 batch size = 590 達到算力和帶寬的平衡利用,這 9.44 MB 數據只需要 9.44 MB / 450 GB/s = 0.02 ms。一共 160 次傳輸,也只有 3.2 ms。由于內存帶寬大了,計算時間也可以大幅縮短,例如 H100 的計算時間為 2 * 70G / 8 / 3.35 TB/s = 5.2 ms。總處理時長只有 5.2 ms + 3.2 ms = 8.4 ms,每秒可以生成 119 個 token,非常棒!
可以說,如果論單個 prompt 的 token 生成速度,無論用多少塊 4090 也追不上 8 卡 H100。
用 4090 做推理的成本怎么樣?
對于推理,不管用流水線并行還是張量并行,batch size 不算高到太離譜的情況下內存帶寬都是瓶頸。
假如 batch size 能夠高到把算力 100% 利用起來,并且還能解決 KV Cache 不夠大的問題,能解決中間結果占用內存過多的問題,那么這 8 張 4090 可以達到多少吞吐量?
當然,這兩個問題都不好解決,因此推理優化才是一個熱門的研究領域,存在很多的 trade-off 和奇技淫巧。如果只是用標準的 PyTorch,那推理性能距離把算力 100% 利用起來還遠得很吶。
假設都解決了,在張量并行的通信過程中我們可以利用 double buffer 做另外一個 batch 的計算,也就是計算和通信并行,進一步提高吞吐量。通信和計算分別是 27 ms 和 17.5 ms,傳輸的 27 ms 是瓶頸,也就是每 27 ms 輸出一組 token,一個 batch 330 個 prompt,那這 8 張 4090 真是可以達到每秒 330 / 0.027 = 12.2K token 的吞吐量。
8 張 4090 的成本是 12800 美金,8 卡 PCIe Gen4 服務器本身要 2 萬美金,加上網絡設備,平均每臺 4 萬美金的設備成本。固定資產按照 3 年攤銷,每小時 1.52 美元。整機功耗大約 400W * 8 + 2 kW = 5 kW,按照 0.1 美元一度電算,每小時 0.5 美元。這 2 美元一小時的機器,滿打滿算能生成 12.2K * 3600 = 44M tokens,也就是說?1 美元能生成 22M tokens。
是不是比 GPT-3.5 Turbo 的 $0.002 / 1K tokens,也就是 1 美元 0.5M tokens?便宜 44 倍?當然,賬不能這么算。
首先,GPU 的算力利用率到不了 100%;
其次,如同所有 SaaS 服務一樣,用戶的請求數量有波峰有波谷,用戶是按量付費的,平臺提供方可是不管有沒有人用都在燒錢的;
此外,每個 batch 中不同 prompt 的長度和響應 token 數量都不同,消耗的算力是 batch 中最大的那個,但收的錢是用戶實際用的 token 數;
再次,GPT-3.5 是 175B 的模型,比 70B 的 LLaMA 很可能推理成本更高;
最后,OpenAI 開發 GPT-3.5 是燒了不知道多少錢的,人家至少要賺回訓練成本和研發人員的工資吧。
其實 GPT-3.5 Turbo 的 $0.002 / 1K tokens 真的挺良心的,有的賣 API 的,LLaMA-2 70B 都敢比 GPT-3.5 Turbo 賣得貴。
如果換成用 H100 做推理,重新算一下這筆賬。一張 H100 至少要 3 萬美金,一臺 8 卡 H100 高配服務器加上配套的 IB 網絡,起碼要 30 萬美金,同樣按照 3 年攤銷,每小時 11.4 美元。10 kW 功耗,電費每小時 1 美元。一共 12.4 美元一小時。
這其實已經是非常良心的價格了,你在任何云服務商都不可能租得到這么便宜的 8 卡 H100。所以說從云服務商租卡賣沒有護城河的 SaaS 服務,比如開源模型的推理 API,除非有一種提高推理性能的獨門絕技,很難賺得了什么大錢,二房東的生意不是這么好做的。
再算算這臺 8 卡 H100 機器的吞吐量,張量并行也采用傳輸和計算并行,H100 的通信比較快,因此計算是瓶頸,每 5.2 ms 可以輸出一組 token,一個 batch 590 個 prompt,滿打滿算可以達到每秒 590 / 0.0052 = 113K token 的吞吐量。理想情況下,一小時能生成 407M tokens,也就是 1 美元能生成 33M tokens,H100 這單位 token 的成本比 4090 還要低 30%。
為什么 8 卡 H100 機器是 4090 機器價格的 6 倍,性價比卻比 4090 高?因為一張 H100 的算力是 4090 的 6 倍,內存帶寬是 4090 的 3.35 倍,當 batch size 夠大,算力達到瓶頸的時候,單卡的性能就是 6 倍。而且,H100 比 4090 的網絡帶寬強太多了,導致 4090 在張量并行中網絡通信成了瓶頸,浪費了有效算力。因此,同樣的 8 卡機器吞吐量幾乎可以達到 4090 的 10 倍。雖然一張 H100 卡的價格是 4090 的 20 倍以上,但算上服務器本身的成本和電費,整機的成本只是 6 倍左右。
用最便宜的設備搞出最高的推理性能
我們發現在 8 卡 4090 機器中,3 萬美金的設備成本,GPU 卡只占了 1.28 萬美金,不像 H100 機器那樣 GPU 成本占了大頭。還有辦法進一步降低嗎?
如果我們可以忍受 5 token/s 的輸出速度,甚至可以利用流水線并行,用家用臺式機和 4090 攢出個推理集群來。
遙想我當年在 MSRA 的時候,在一臺只用 1000 美金攢出來的機器上插了 10 塊 FPGA,做出個世界最快的 Key-Value Store。其實如果讓我去設計一個性價比最高的 4090 推理集群,有很多種方案可以嘗試:
用流水線并行,臺式機 + 10 Gbps 網卡,足夠在 5 ms 內傳輸 batch size = 330 的 5.28 MB 數據了,通信 40 ms,計算 140 ms,達到 5 token/s 的單 prompt 輸出速度,同時又能充分利用 4090 的算力。10 Gbps 的網卡和交換機都很便宜,Intel X710 網卡只要 150 美金,20 口交換機只要 1500 美金(每 8 個口 750 美金),一臺家用臺式機 700 美金,這只要 2 萬美金就可以搞定原本需要 4 萬美金的設備。
用張量并行,臺式機 + 200 Gbps ConnectX-6 網卡,上 RoCE,可以把 batch size = 330 的 5.28 MB 數據在 0.22 ms 內傳完,160 次傳輸是 35 ms,加上計算的 17.5 ms,一個 token 52.5 ms,可以達到 19 token/s 的單 prompt 輸出速度,這個速度已經不錯了。網卡 1000 美金,200G 交換機 2 萬美金 40 個端口,平均每 8 個端口 4000 美金,一臺家用臺式機 700 美金,這只要 3 萬美金就能搞定原本 4 萬美金的設備。
主機內用張量并行,主機間用流水線并行,4 卡 PCIe Gen4 服務器主板只要 1000 美金而且能跑滿 PCIe 帶寬(因為 8 卡就需要 PCIe switch 了,價格會貴很多),兩臺主機之間用 25 Gbps 網卡直連,主機內張量并行的時延是 27 ms,主機間流水線并行只需 2 次 8 ms 的傳輸(注意 25G 的網絡帶寬是 4 張 GPU 卡共享的),加上兩次流水線計算各 17.5 ms,總共 78 ms,可以達到 13 token/s 的單 prompt 輸出速度。網卡 300 美金 * 2,服務器 3000 美金 * 2,這只要 1.95 萬美金就可以搞定原本需要 4 萬美金的設備。
2 萬美金按照 3 年攤銷是每小時 0.76 美元。按照 0.1 美元/度的電價,每小時的電費都要 0.5 美元,接近設備成本了,這有點挖礦的味道了。這 1.26 美元一小時的機器如果跑滿了 44M tokens 的吞吐量,1 美元能生成 35M tokens,終于趕上 8 卡 H100 的 33M token per dollar 了。
為什么 H100 以 20 倍于 4090 的 GPU 價格,9 倍的性能,卻仍然能在系統性價比上打個平手,首先是因為能耗成本更低,8 卡 H100 的功耗是 10 kW,但 9 臺 8 卡 4090 的功耗是 45 kW;其次是因為主機和網絡設備成本更低,一臺 8 卡 H100 準系統雖然貴,但只占整機價格的 20% 左右;但 4090 因為卡多,除非像 GPU 礦機那樣壓成本,只要還是用數據中心級的設備,準系統價格就要占到 35% 以上。
其實,這個世界上不止有 A100/H100 和 4090,還有 A10 等計算卡和 3090 等游戲卡,還有 AMD 的 GPU 和很多其他廠商的 AI 芯片。H100 和 4090 大概率都不是性價比的最優解,例如 A10 和 AMD GPU 的性價比有可能就更高。
我都想搞一個推理性價比挑戰賽,看誰能用最便宜的設備搞出最強的推理吞吐量,同時延遲不能太高;或者用最便宜的設備搞出最低的推理延遲,同時吞吐量不能太低。
這一切都是在假設使用 LLaMA-2 70B 模型,沒有做量化壓縮的前提下。如果做了量化壓縮,那性能就更高,甚至在 Unified Memory 夠大的 MacBook Pro 上都能單機跑了。
License 問題怎么辦?
我把這個問題放到最后。NVIDIA Geforce driver 的 License 里寫道:
No Datacenter Deployment. The SOFTWARE is not licensed for datacenter deployment, except that blockchain processing in a datacenter is permitted.
既然機器都是用臺式機攢起來的,這能叫 data center 嗎?還是叫礦場比較合適吧。人家也說了,4090 用來做區塊鏈是允許的。
我有一個大膽的想法,如果未來的區塊鏈不再用挖礦來做 proof of work,而是用大模型推理來做 proof of work,這是不是很有意思?每個人買幾塊顯卡,接到礦池上,既可以自己用來玩游戲,閑時又可以貢獻算力。礦池直接就是個賣大模型推理 SaaS 服務的公司,提供前所未有的低價 API。甚至需要大模型推理服務的人可以在區塊鏈里自己 P2P 玩起來,誰要用大模型就付點 gas。
當然,目前的 proof of work 都是計算很復雜,驗證很簡單的。如果真用大模型推理做 proof of work,必須防止用戶隨意編造一個結果交上去。當然這也是有解決方案的,就像 BitTorrent 和其他一些去中心化網絡一樣,采用信用機制,新人只能做驗證別人計算結果的工作,積攢信用;老人每次算錯了,都有比較嚴厲的懲罰。
從另一個角度看,家庭局域網絡的速度也越來越快,比如我家就自己部署了 10 Gbps 的網絡。家中的智能設備越來越多,算力越來越強。光纖入戶也越來越普遍,小區和城市的運營商機房里部署了越來越多的邊緣計算節點。前面我們用 1 Gbps 的網絡就足以把多臺主機上的 GPU 組成流水線并行,那么在未來的家庭高速網絡中,流水線并行甚至張量并行都將成為可能。
大多數搞 AI 推理的都只關心數據中心,忽略了家中的分布式算力。只要解決了安全、隱私和經濟動機問題,我家的 Siri,也許就跑在鄰居家里的 GPU 上。
很多人都在說要 democratize AI。但現在大模型平民化的最大障礙就是成本,而成本最大的來源又是 GPU 市場上計算卡和游戲卡價格的剪刀差。這并不是指責某家公司,其他做 AI 芯片的公司,AI 芯片的算力也并不便宜。畢竟芯片、軟件和生態的研發都是白花花的銀子。
就像本文開頭提到的微軟給每臺服務器部署 FPGA 一樣,大規模量產的芯片價格就像沙子一樣。到時候,能限制大模型推理算力的就只有能源了,就像區塊鏈挖礦和通用 CPU 的云計算一樣,都在找最便宜的電力供應。我在之前的一個采訪中就表示,長期來看,能源和材料可能是制約大模型發展的關鍵。讓我們期待廉價的大模型走進千家萬戶,真正改變人們的生活。
編輯:黃飛
?























 工商網監
工商網監
評論