 電子發燒友App
電子發燒友App


本文來自“FPGA專題:萬能芯片點燃新動力,國產替代未來可期(2023)”,FPGA又稱現場可編程門陣列,是在硅片上預先設計實現的具有可編程特性的集成電路,用戶在使用過程中可以通過軟件重新配置芯片內部的資源實現不同功能。通俗意義上講,FPGA 芯片類似于集成電路中的積木,用戶可根據各自的需求和想法,將其拼搭成不同的功能、特性的電路結構,以滿足不同場景的應用需求。鑒于上述特性,FPGA 芯片又被稱作“萬能”芯片。

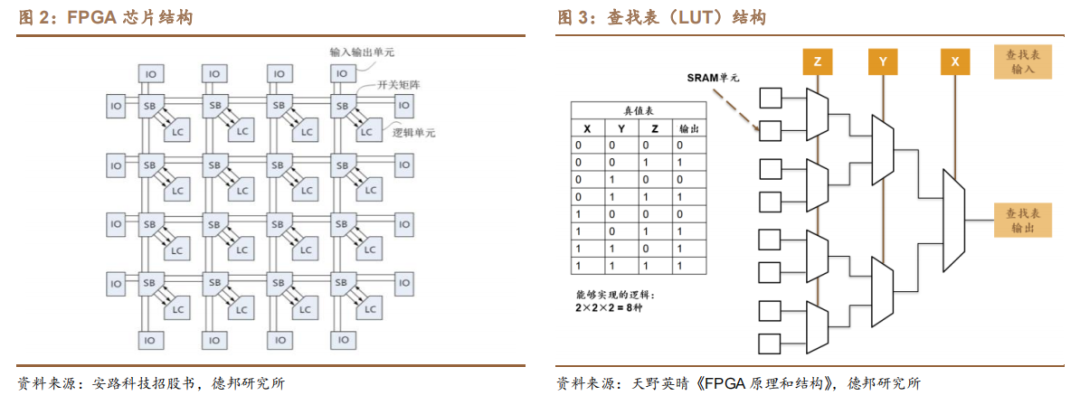
FPGA 芯片由可編程的邏輯單元(Logic Cell,LC)、輸入輸出單元(Input Output Block,IO)和開關連線陣列(Switch Box,SB)三個部分構成:
(1)邏輯單元:通過數據查找表(Look-up Table,LUT)中存放的二進制數據來實現不同的電路功能。LUT 的本質是一種靜態隨機存取存儲器(Static Random Access Memory,SRAM),其大小是由輸入端的信號數量決定的,常用的查找表電路是四輸入查找表(4-input LUT,LUT4)、五輸入查找表(5-input LUT,LUT5)和六輸入查找表(6-input LUT,LUT6)。查找表輸入端越多,可以實現的邏輯電路越復雜,因此邏輯容量越大,但是查找表的面積和輸入端數量成指數關系,輸入端數量增加一個,查找表使用的 SRAM 存儲電路面積增加約一倍。不同的邏輯單元結構可以使用不同大小的查找表,或者是不同查找表類型的組合。此外,邏輯單元內部還包含選擇器、進位鏈和觸發器等其他組件。為了提高芯片架構效率,若干邏輯單元可以進一步組成邏輯塊(Logic Block),邏輯塊內部提供快速局部資源,從而形成層次化芯片架構。
(2)輸入輸出單元:是芯片與外界電路的接口部分,用于實現不同條件下對輸入/輸出信號的驅動與匹配要求。
(3)開關陣列:能夠通過內部 MOS 管的開關控制信號連線的走向。
FPGA 從 Xilinx 公司 1985 年推出世界首款 FPGA 芯片“XC2064”經歷過數十年發展,在硬件架構上大致經歷了四個階段:從 PROM 階段(簡單的數字邏輯)到 PAL/GAL 階段(“與”&“或”陣列)再到 CPLD/FPGA 階段(超大規模電路),到如今 FPGA 與 ASIC 技術融合、向系統級發展的 SoC FPGA/eFPGA 階段。硬件水平整體趨向更大規模、更高靈活性、更優性能。

FPGA 芯片屬于邏輯芯片大類。邏輯芯片按功能可分為四大類芯片:通用處理器芯片(包含中央處理芯片 CPU、圖形處理芯片 GPU,數字信號處理芯片 DSP等)、存儲器芯片(Memory)、專用集成電路芯片(ASIC)和現場可編程邏輯陣列芯片(FPGA)。
FPGA 兼具靈活性和并行性兩大特點。
(1)靈活性:FPGA芯片擁有更高的靈活性和更豐富的選擇性,通過對 FPGA 編程,用戶可隨時改變芯片內部的連接結構,實現任何邏輯功能。尤其是在技術標準尚未成熟或發展更迭速度快的行業領域,FPGA 能有效幫助企業降低投資風險及沉沒成本,是一種兼具功能性和經濟效益的選擇。
(2)并行性:CPU、GPU 在執行任務時,執行單元需按順序通過取指、譯碼、執行、訪存以及寫回等一系列流程完成數據處理,且多方共享內存導致部分任務需經訪問仲裁,從而產生任務延時。而 FPGA 每個邏輯單元與周圍邏輯單元的連接構造在重編程(燒寫)時就已經確定,寄存器和片上內存屬于各自的控制邏輯,無需通過指令譯碼、共享內存來通信,各硬件邏輯可同時并行工作,大幅提升數據處理效率。尤其是在執行重復率較高的大數據量處理任務時,FPGA 相比 CPU 等優勢明顯。

相較于其他邏輯芯片而言,FPGA 在靈活性、性能、功耗、成本之間具有較好的平衡:
(1)相較于 GPU,FPGA 在功耗和靈活性等方面具備優勢。一方面,由于GPU 采用大量的處理單元并且大量訪問片外存儲 SDRAM,其計算峰值更高,同時功耗也較高,FPGA 的平均功耗(10W)遠低于 GPU 的平均功耗(200W),可有效改善散熱問題;另一方面,GPU 在設計完成后無法改動硬件資源,而 FPGA根據特定應用對硬件進行編程,更具靈活性。機器學習使用多條指令平行處理單一數據,FPGA 的定制化能力更能滿足精確度較低、分散、非常規深度神經網絡計算需求。
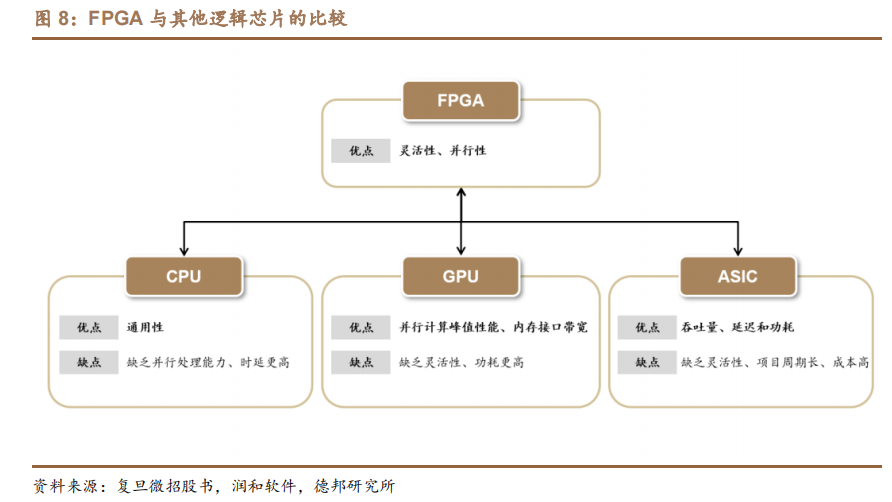
(2)相較于 ASIC 芯片,FPGA 在項目初期具備短周期、高性價比的優勢。ASIC 需從標準單元進行設計,當芯片的功能及性能需求發生變化時或者工藝進步時,ASIC 需重新投片,由此帶來較高的沉沒成本以及較長的開發周期;而 FPGA具有編程、除錯、再編程和重復操作等優點,可實現芯片功能重新配置,因此早期 FPGA 常作為定制化 ASIC 領域的半定制電路出現,被業內認為是構建原型和開發設計的較快推進的路徑之一。
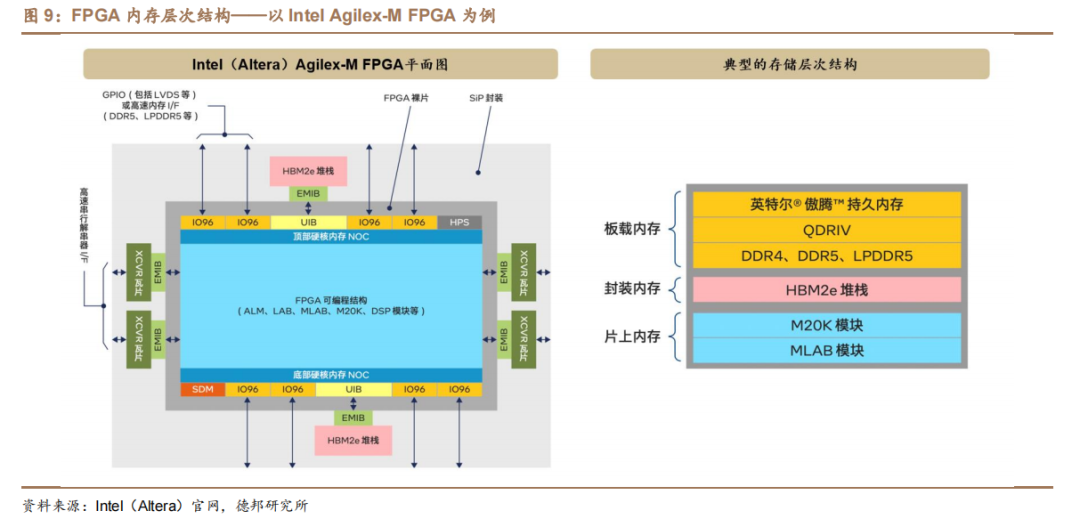
FPGA邏輯結構中的內存大致分為三個層次(以Intel Agilex-M FPGA為例),包括超本地化片上內存、以 HBM2e 堆棧形式提供的本地封裝內存,以及 DDR5和 LPDDR5 等外部內存架構和接口。
片上內存(MLAB 模塊和 M20K 模塊):最本地化的內存;
封裝內存(HBM):彌合內存層次結構中關鍵缺口的內存,其容量遠大于片上內存(兩個數量級以上),同時帶寬又遠大于片外內存(兩個數量級以上);
片外內存(DDR5、LPDDR5 等):對于超出 HBM2e 容量的應用,或對獨立內存的靈活性有要求時,需要 DDR5 和 LPDDR5 以及其他主流的內存架構。
HBM2e 與 FPGA 裸片集成在同一封裝中可以在小尺寸外形規格中實現更高帶寬、更低功耗、更低時延。
(1)內存容量方面:每個 HBM2e 堆棧可包含 4 層或 8 層,每層提供 2GB 內存,因此單個 Intel Agilex-M 系列 FPGA 可包含 16GB或 32 GB 的高帶寬內存;
(2)帶寬方面:HBM2e 可實現每堆棧高達 410Gbps 的內存帶寬,較 DDR5 組件的帶寬提升高達 18 倍,較 GDDR6 組件提升 7 倍。兩個 HBM2e 堆棧加起來可提供高達 820Gbps 的峰值內存帶寬;
(3)功耗和時延方面:由于 HBM2e 集成在封裝中,因此也不需要使用外部 I/O 引腳,從而節省了電路板空間,并消除了它們會帶來的功耗和互連時延。
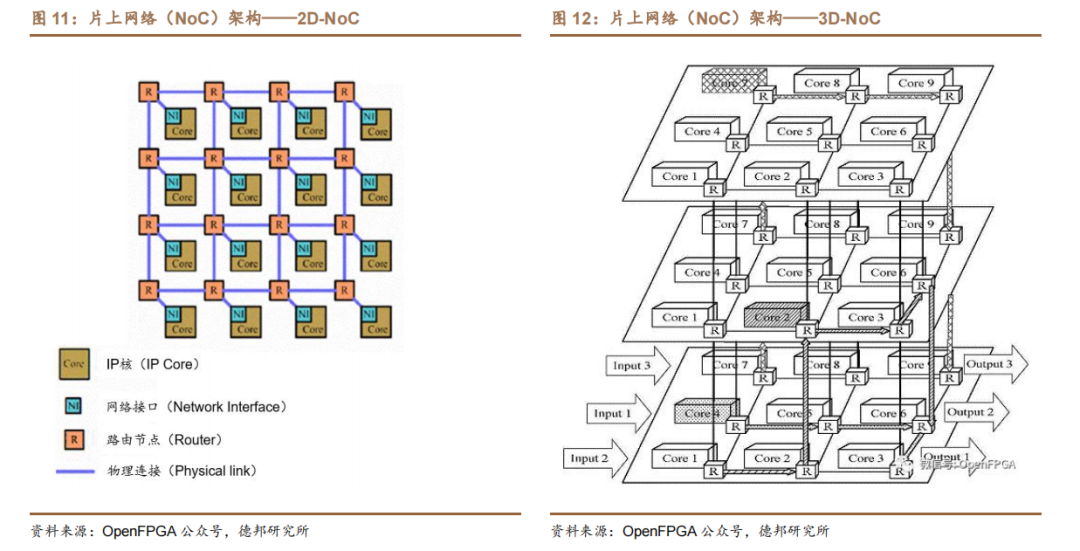
片上網絡(NoC,Network on Chip)是指在單芯片上集成大量的計算資源以及連接這些資源的片上通信網絡,用于在可編程邏輯(PL)、處理器系統(PS)和其它硬核塊中的 IP 端點之間共享數據。
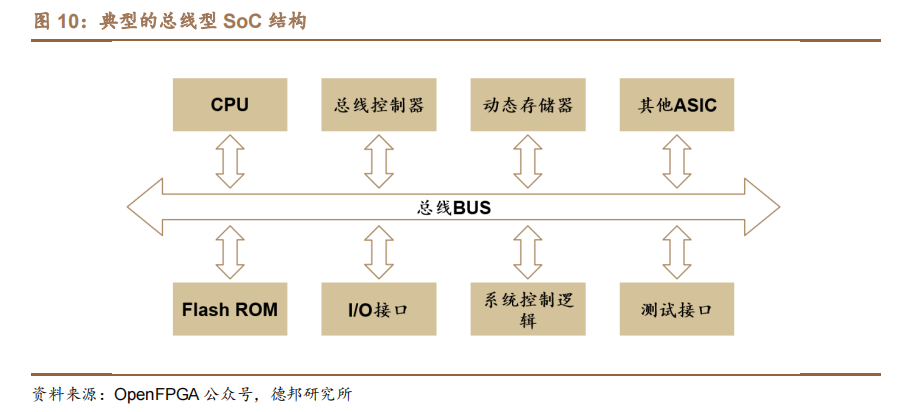
與之對應的概念——片上系統(SoC)則是包含一整套多樣化和互連單元的單芯片,旨在解決一定范圍的任務。傳統上,SoC 包括幾個計算內核、內存控制器、I/O 子系統以及它們之間的連接與切換方式(總線、交叉開關、NoC 元件)。
片上網絡 NoC 包括計算和通信兩個子系統。計算子系統(由 PE,Processing Element 構成的子系統)完成廣義的“計算”任務,PE 既可以是現有意義上的CPU、SoC,也可以是各種專用功能的 IP 核或存儲器陣列、可重構硬件等。通信子系統(由 Switch 組成的子系統)負責連接 PE,實現計算資源之間的高速通信。通信節點及其間的互連線所構成的網絡即為片上通信網絡。
類比城市高速公路網絡,NoC 架構簡化互連路徑,提高 FPGA 傳輸速率。Achronix 基于臺積電(TSMC)的 7nm FinFET 工藝的 Speedster7t FPGA 器件包含了 2D NoC 架構,為 FPGA 外部高速接口和內部可編程邏輯的數據傳輸提供了超高帶寬(~27Tbps)。NoC 使用一系列高速的行和列網絡通路(水平和垂直方式)在整個 FPGA 內部分發數據,每一行或每一列都有兩個 256 位的、單向的、行業標準的 AXI 通道,可以在每個方向上以 512Gbps(256bit x 2GHz)的傳輸速率運行。

NoC 為 FPGA 設計提供了幾項重要優勢,包括:(1)提高設計的性能;(2)減少邏輯資源閑置,在高資源占用設計中降低布局布線擁塞的風險;(3)減小功耗;(4)簡化邏輯設計,由 NoC 去替代傳統的邏輯去做高速接口和總線管理;(5)實現真正的模塊化設計。
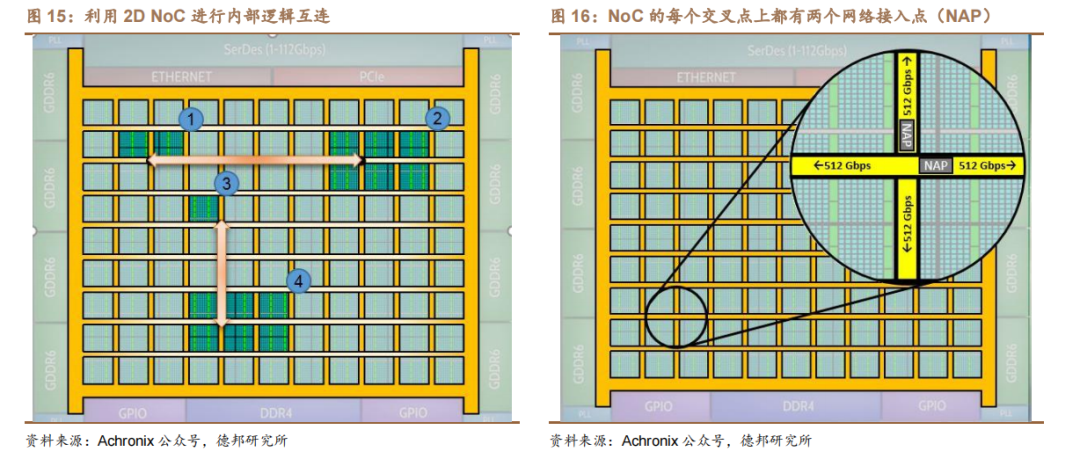
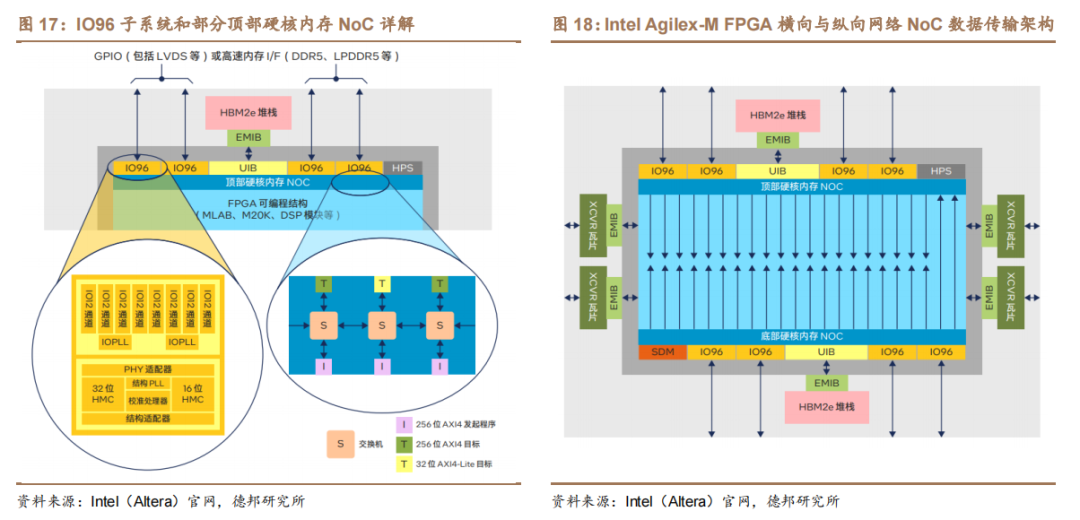
Intel(Altera)利用 NoC 架構實現內存和可編程邏輯結構之間的現高帶寬數據傳輸。如下圖所示,每個片上 HBM2e 堆棧通過 UIB 與其 NoC 通信。片外內存(DDR4、DDR5 等)則通過 IO96 子系統與 NoC 通信。NoC 通過一個由交換機(路由器)、互連鏈路(導線)、發起程序(I)和目標(T)組成的網絡,將數據從數據源傳輸到目的地。每個 NoC 都提供一個橫向網絡,通過 AXI4 發起程序將可編程邏輯結構中的邏輯連接到集成 NoC 的目標內存。此外,每個 NoC 也都提供一個縱向網絡,通過優化的路由將橫向網絡路徑讀取的內存數據分發到 FPGA的可編程邏輯結構深處(可編程邏輯結構和/或 M20K 模塊)。
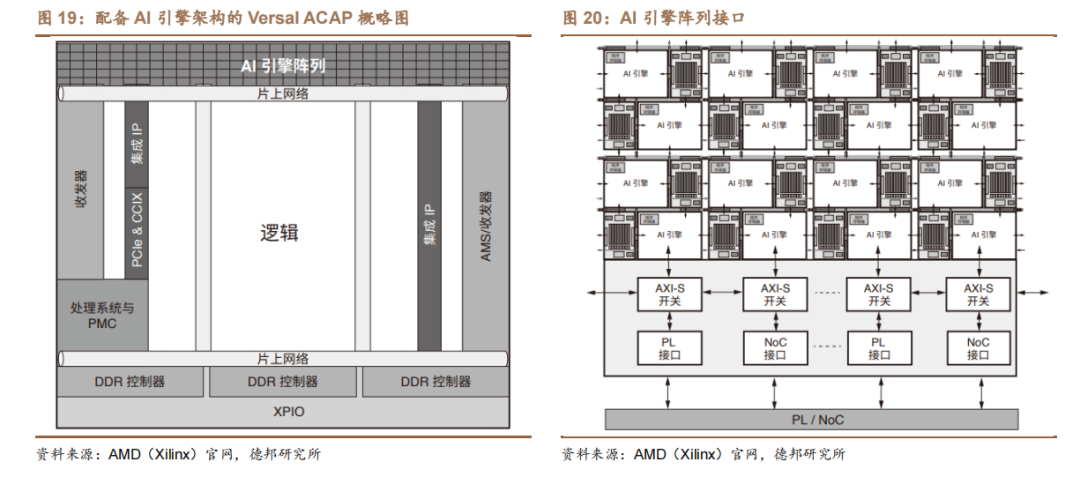
AMD(Xilinx)在 AI 引擎和可編程邏輯之間部署 NoC 架構,可大幅降低功耗。AMD Versal 產品最突出的優勢之一,是能夠在自適應引擎中將 AI 引擎陣列與可編程邏輯(PL)結合使用,由 AI 引擎陣列接口連接 AI 引擎陣列和可編程邏輯。這樣的資源結合為在最佳資源、AI 引擎、自適應引擎或標量引擎中實現功能提供了極大的靈活性。該方案與傳統可編程邏輯 DSP 和 ML 實現方案相比,可將芯片面積計算密度提高達 8 倍,從而在額定值情況下,可將功耗降低 40%。
審核編輯:湯梓紅









 工商網監
工商網監
評論