 電子發(fā)燒友App
電子發(fā)燒友App


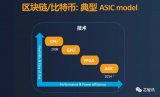
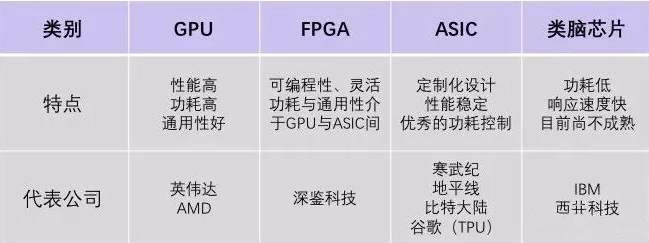
? GPU的并行算力能力很強(qiáng),但是它也有缺點(diǎn),就是功耗高,體積大,價(jià)格貴。 ? 進(jìn)入21世紀(jì)后,算力需求呈現(xiàn)兩個(gè)顯著趨勢(shì):一,算力的使用場(chǎng)景,開始細(xì)分;二,用戶對(duì)算力性能的要求,越來越高。通用的算力芯片,已經(jīng)無法滿足用戶的需求。 ? 于是,越來越多的企業(yè),開始加強(qiáng)對(duì)專用計(jì)算芯片的研究和投資力度。而ASIC(Application Specific Integrated Circuit,專用集成電路),就是一種專用于特定任務(wù)的芯片。 ? ? ?
? ASIC的官方定義,是指:應(yīng)特定用戶的要求,或特定電子系統(tǒng)的需要,專門設(shè)計(jì)、制造的集成電路。 ? ASIC起步于上世紀(jì)70-80年代。早期的時(shí)候,曾用于計(jì)算機(jī)。后來,主要用于嵌入式控制。這幾年,如前面所說,開始崛起,用于AI推理、高速搜索以及視覺和圖像處理等。 ? ? 說到ASIC,我們就不得不提到Google公司大名鼎鼎的TPU。 ? ?
? TPU,全稱Tensor Processing Unit,張量處理單元。所謂“張量(tensor)”,是一個(gè)包含多個(gè)數(shù)字(多維數(shù)組)的數(shù)學(xué)實(shí)體。
? 目前,幾乎所有的機(jī)器學(xué)習(xí)系統(tǒng),都使用張量作為基本數(shù)據(jù)結(jié)構(gòu)。所以,張量處理單元,我們可以簡(jiǎn)單理解為“AI處理單元”。 ? 2015年,為了更好地完成自己的深度學(xué)習(xí)任務(wù),提升AI算力,Google推出了一款專門用于神經(jīng)網(wǎng)絡(luò)訓(xùn)練的芯片,也就是TPU v1。
相比傳統(tǒng)的CPU和GPU,在神經(jīng)網(wǎng)絡(luò)計(jì)算方面,TPU v1可以獲得15~30倍的性能提升,能效提升更是達(dá)到30~80倍,給行業(yè)帶來了很大震動(dòng)。
2017年和2018年,Google又再接再厲,推出了能力更強(qiáng)的TPU v2和TPU v3,用于AI訓(xùn)練和推理。2021年,他們推出了TPU v4,采用7nm工藝,晶體管數(shù)達(dá)到220億,性能相較上代提升了10倍,比英偉達(dá)的A100還強(qiáng)1.7倍。
除了Google之外,還有很多大廠這幾年也在搗鼓ASIC。 ? 英特爾公司在2019年底收購了以色列AI芯片公司Habana Labs,2022年,發(fā)布了Gaudi 2 ASIC芯片。IBM研究院,則于2022年底,發(fā)布了AI ASIC芯片AIU。 ? ?
三星早幾年也搞過ASIC,當(dāng)時(shí)做的是礦機(jī)專用芯片。沒錯(cuò),很多人認(rèn)識(shí)ASIC,就是從比特幣挖礦開始的。相比GPU和CPU挖礦,ASIC礦機(jī)的效率更高,能耗更低。 ? ?
ASIC礦機(jī) ? 除了TPU和礦機(jī)之外,另外兩類很有名的ASIC芯片,是DPU和NPU。 ? DPU是數(shù)據(jù)處理單元(Data Processing Unit),主要用于數(shù)據(jù)中心。 ? NPU的話,叫做神經(jīng)網(wǎng)絡(luò)處理單元(Neural Processing Unit),在電路層模擬人類神經(jīng)元和突觸,并用深度學(xué)習(xí)指令集處理數(shù)據(jù)。 ? NPU專門用于神經(jīng)網(wǎng)絡(luò)推理,能夠?qū)崿F(xiàn)高效的卷積、池化等操作。一些手機(jī)芯片里,經(jīng)常集成這玩意。 ? 說到手機(jī)芯片,值得一提的是,我們手機(jī)現(xiàn)在的主芯片,也就是常說的SoC芯片,其實(shí)也是一種ASIC芯片。 ? ?
? ASIC作為專門的定制芯片,優(yōu)點(diǎn)體現(xiàn)在哪里?只是企業(yè)獨(dú)享,專用logo和命名? ? 不是的。 ? 定制就是量體裁衣。基于芯片所面向的專項(xiàng)任務(wù),芯片的計(jì)算能力和計(jì)算效率都是嚴(yán)格匹配于任務(wù)算法的。芯片的核心數(shù)量,邏輯計(jì)算單元和控制單元比例,以及緩存等,整個(gè)芯片架構(gòu),也是精確定制的。 ? 所以,定制專用芯片,可以實(shí)現(xiàn)極致的體積、功耗。這類芯片的可靠性、保密性、算力、能效,都會(huì)比通用芯片(CPU、GPU)更強(qiáng)。 ? 大家會(huì)發(fā)現(xiàn),前面我們提到的幾家ASIC公司,都是谷歌、英特爾、IBM、三星這樣的大廠。
這是因?yàn)椋瑢?duì)芯片進(jìn)行定制設(shè)計(jì),對(duì)一家企業(yè)的研發(fā)技術(shù)水平要求極高,且耗資極為巨大。
做一款A(yù)SIC芯片,首先要經(jīng)過代碼設(shè)計(jì)、綜合、后端等復(fù)雜的設(shè)計(jì)流程,再經(jīng)過幾個(gè)月的生產(chǎn)加工以及封裝測(cè)試,才能拿到芯片來搭建系統(tǒng)。 ? 大家都聽說過“流片(Tape-out)”。像流水線一樣,通過一系列工藝步驟制造芯片,就是流片。簡(jiǎn)單來說,就是試生產(chǎn)。 ? ? ? ? ASIC的研發(fā)過程是需要流片的。14nm工藝,流片一次需要300萬美元左右。5nm工藝,更是高達(dá)4725萬美元。 ? 流片一旦失敗,錢全部打水漂,還耽誤了大量的時(shí)間和精力。一般的小公司,根本玩不起。 ? 那么,是不是小公司就無法進(jìn)行芯片定制了呢? ? 當(dāng)然不是。接下來,就輪到另一個(gè)神器出場(chǎng)了,那就是——FPGA。 ?
? █?FPGA(現(xiàn)場(chǎng)可編程門陣列)
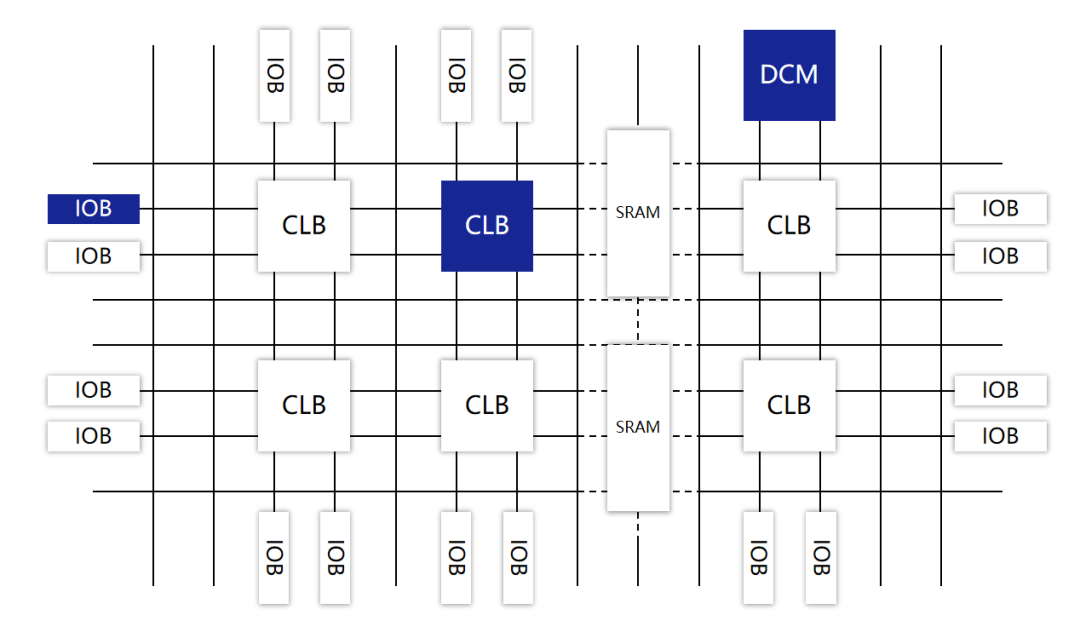
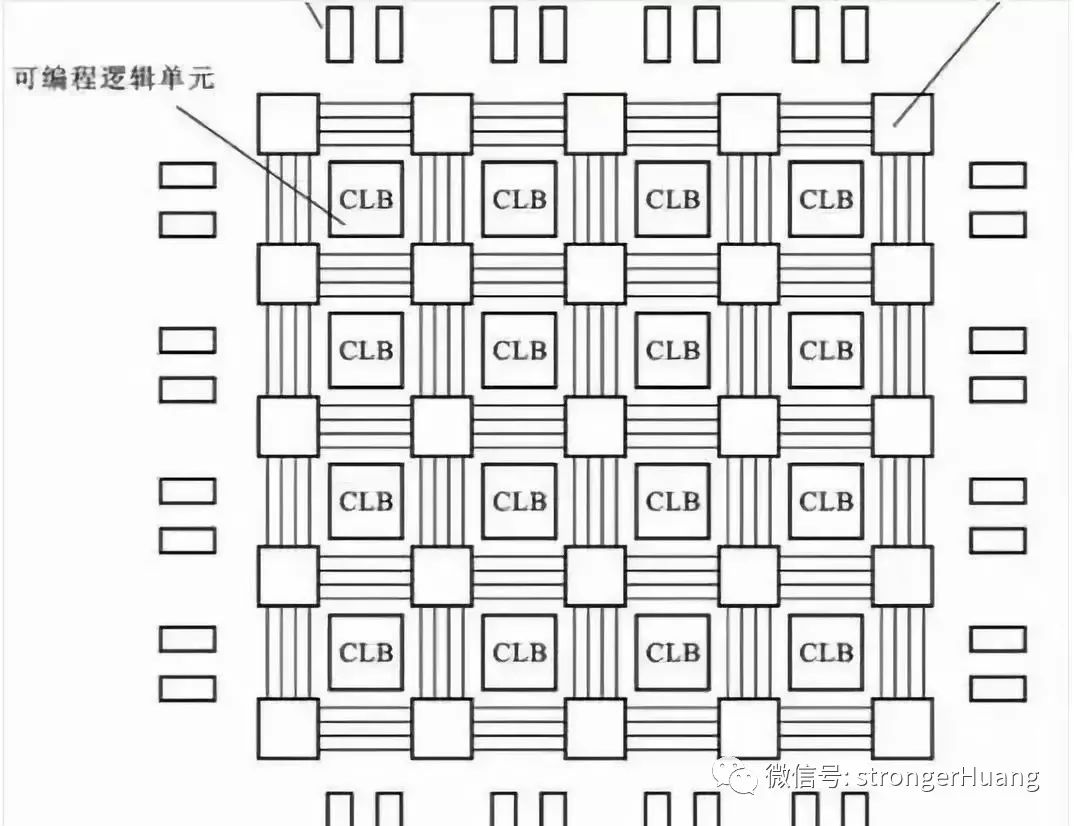
? FPGA,英文全稱Field Programmable Gate Array,現(xiàn)場(chǎng)可編程門陣列。 ? FPGA這些年在行業(yè)里很火,勢(shì)頭比ASIC還猛,甚至被人稱為“萬能芯片”。 ? 其實(shí),簡(jiǎn)單來說,F(xiàn)PGA就是可以重構(gòu)的芯片。它可以根據(jù)用戶的需要,在制造后,進(jìn)行無限次數(shù)的重復(fù)編程,以實(shí)現(xiàn)想要的數(shù)字邏輯功能。 ? 之所以FPGA可以實(shí)現(xiàn)DIY,是因?yàn)槠洫?dú)特的架構(gòu)。 ? FPGA由可編程邏輯塊(Configurable Logic Blocks,CLB)、輸入/輸出模塊(I/O Blocks,IOB)、可編程互連資源(Programmable Interconnect Resources,PIR)等三種可編程電路,以及靜態(tài)存儲(chǔ)器SRAM共同組成。 ?
?
CLB是FPGA中最重要的部分,是實(shí)現(xiàn)邏輯功能的基本單元,承載主要的電路功能。 ? 它們通常規(guī)則排列成一個(gè)陣列(邏輯單元陣列,LCA,Logic Cell Array),散布于整個(gè)芯片中。 ? IOB主要完成芯片上的邏輯與外部引腳的接口,通常排列在芯片的四周。 ? PIR提供了豐富的連線資源,包括縱橫網(wǎng)狀連線、可編程開關(guān)矩陣和可編程連接點(diǎn)等。它們實(shí)現(xiàn)連接的作用,構(gòu)成特定功能的電路。 ? 靜態(tài)存儲(chǔ)器SRAM,用于存放內(nèi)部IOB、CLB和PIR的編程數(shù)據(jù),并形成對(duì)它們的控制,從而完成系統(tǒng)邏輯功能。 ? CLB本身,又主要由查找表(Look-Up Table,LUT)、多路復(fù)用器(Multiplexer)和觸發(fā)器(Flip-Flop)構(gòu)成。它們用于承載電路中的一個(gè)個(gè)邏輯“門”,可以用來實(shí)現(xiàn)復(fù)雜的邏輯功能。 ? 簡(jiǎn)單來說,我們可以把LUT理解為存儲(chǔ)了計(jì)算結(jié)果的RAM。當(dāng)用戶描述了一個(gè)邏輯電路后,軟件會(huì)計(jì)算所有可能的結(jié)果,并寫入這個(gè)RAM。每一個(gè)信號(hào)進(jìn)行邏輯運(yùn)算,就等于輸入一個(gè)地址,進(jìn)行查表。LUT會(huì)找出地址對(duì)應(yīng)的內(nèi)容,返回結(jié)果。
這種“硬件化”的運(yùn)算方式,顯然具有更快的運(yùn)算速度。 ? 用戶使用FPGA時(shí),可以通過硬件描述語言(Verilog或VHDL),完成的電路設(shè)計(jì),然后對(duì)FPGA進(jìn)行“編程”(燒寫),將設(shè)計(jì)加載到FPGA上,實(shí)現(xiàn)對(duì)應(yīng)的功能。 ? 加電時(shí),F(xiàn)PGA將EPROM(可擦編程只讀存儲(chǔ)器)中的數(shù)據(jù)讀入SRAM中,配置完成后,F(xiàn)PGA進(jìn)入工作狀態(tài)。掉電后,F(xiàn)PGA恢復(fù)成白片,內(nèi)部邏輯關(guān)系消失。如此反復(fù),就實(shí)現(xiàn)了“現(xiàn)場(chǎng)”定制。 ? FPGA的功能非常強(qiáng)大。理論上,如果FPGA提供的門電路規(guī)模足夠大,通過編程,就能夠?qū)崿F(xiàn)任意ASIC的邏輯功能。 ? ?
? ? ? 我們?cè)倏纯碏PGA的發(fā)展歷程。 ? FPGA是在PAL(可編程陣列邏輯)、GAL(通用陣列邏輯)等可編程器件的基礎(chǔ)上發(fā)展起來的產(chǎn)物,屬于一種半定制電路。 ? 它誕生于1985年,發(fā)明者是Xilinx公司(賽靈思)。后來,Altera(阿爾特拉)、Lattice(萊迪思)、Microsemi(美高森美)等公司也參與到FPGA這個(gè)領(lǐng)域,并最終形成了四巨頭的格局。 ? 2015年5月,Intel(英特爾)以167億美元的天價(jià)收購了Altera,后來收編為PSG(可編程解決方案事業(yè)部)部門。 ? 2020年,Intel的競(jìng)爭(zhēng)對(duì)手AMD也不甘示弱,以350億美元收購了Xilinx。
于是,就變成了Xilinx(AMD旗下)、Intel、Lattice和Microsemi四巨頭(換湯不換藥)。 ? 2021年,這四家公司的市占率分別為51%、29%、7%和6%,加起來是全球總份額的93%。 ? 不久前,2023年10月,Intel宣布計(jì)劃拆分PSG部門,獨(dú)立業(yè)務(wù)運(yùn)營。 ? 國內(nèi)FPGA廠商的話,包括復(fù)旦微電、紫光國微、安路科技、東土科技、高云半導(dǎo)體、京微齊力、京微雅格、智多晶、遨格芯等。看上去數(shù)量不少,但實(shí)際上技術(shù)差距很大。
? █?ASIC和FPGA的區(qū)別
接下來,我們重點(diǎn)說說ASIC和FPGA的區(qū)別,還有它們和CPU、GPU之間的區(qū)別。 ? ASIC和FPGA,本質(zhì)上都是芯片。AISC是全定制芯片,功能寫死,沒辦法改。而FPGA是半定制芯片,功能靈活,可玩性強(qiáng)。 ? 我們還是可以通過一個(gè)例子,來說明兩者之間的區(qū)別。 ? ASIC就是用模具來做玩具。事先要進(jìn)行開模,比較費(fèi)事。而且,一旦開模之后,就沒辦法修改了。如果要做新玩具,就必須重新開模。 ? 而FPGA呢,就像用樂高積木來搭玩具。上手就能搭,花一點(diǎn)時(shí)間,就可以搭好。如果不滿意,或者想搭新玩具,可以拆開,重新搭。 ? ?
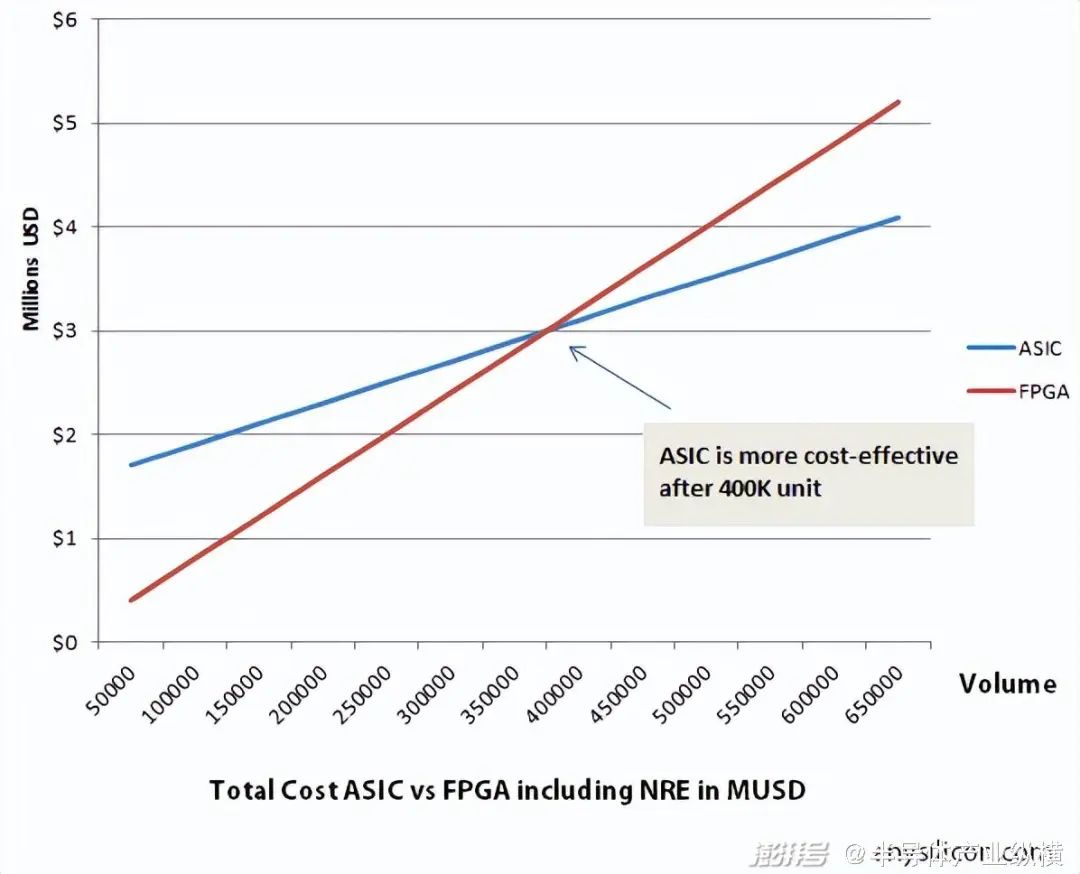
? ? ASIC與FPGA的很多設(shè)計(jì)工具是相同的。在設(shè)計(jì)流程上,F(xiàn)PGA沒有ASIC那么復(fù)雜,去掉了一些制造過程和額外的設(shè)計(jì)驗(yàn)證步驟,大概只有ASIC流程的50%-70%。最頭大的流片過程,F(xiàn)PGA是不需要的。 ? 這就意味著,開發(fā)ASIC,可能需要幾個(gè)月甚至一年以上的時(shí)間。而FPGA,只需要幾周或幾個(gè)月的時(shí)間。 ? 剛才說到FPGA不需要流片,那么,是不是意味著FPGA的成本就一定比ASIC低呢? ? 不一定。 ? FPGA可以在實(shí)驗(yàn)室或現(xiàn)場(chǎng)進(jìn)行預(yù)制和編程,不需要一次性工程費(fèi)用 (NRE)。但是,作為“通用玩具”,它的成本是ASIC(壓模玩具)的10倍。 ? 如果生產(chǎn)量比較低,那么,F(xiàn)PGA會(huì)更便宜。如果生產(chǎn)量高,ASIC的一次性工程費(fèi)用被平攤,那么,ASIC反而便宜。 ? 這就像開模費(fèi)用。開模很貴,但是,如果銷量大,開模就劃算了。 ? 如下圖所示,40W片,是ASIC和FPGA成本高低的一個(gè)分界線。產(chǎn)量少于40W,F(xiàn)PGA便宜。多于40W,ASIC便宜。 ?
? 從性能和功耗的角度來看,作為專用定制芯片,ASIC是比FPGA強(qiáng)的。 ? FPGA是通用可編輯的芯片,冗余功能比較多。不管你怎么設(shè)計(jì),都會(huì)多出來一些部件。 ? 前面小棗君也說了,ASIC是貼身定制,沒什么浪費(fèi),且采用硬連線。所以,性能更強(qiáng),功耗更低。 ? FPGA和ASIC,不是簡(jiǎn)單的競(jìng)爭(zhēng)和替代關(guān)系,而是各自的定位不同。 ? FPGA現(xiàn)在多用于產(chǎn)品原型的開發(fā)、設(shè)計(jì)迭代,以及一些低產(chǎn)量的特定應(yīng)用。它適合那些開發(fā)周期必須短的產(chǎn)品。FPGA還經(jīng)常用于ASIC的驗(yàn)證。 ?
ASIC用于設(shè)計(jì)規(guī)模大、復(fù)雜度高的芯片,或者是成熟度高、產(chǎn)量比較大的產(chǎn)品。 ? ? FPGA還特別適合初學(xué)者學(xué)習(xí)和參加比賽。現(xiàn)在很多大學(xué)的電子類專業(yè),都在使用FPGA進(jìn)行教學(xué)。
? 從商業(yè)化的角度來看,F(xiàn)PGA的主要應(yīng)用領(lǐng)域是通信、國防、航空、數(shù)據(jù)中心、醫(yī)療、汽車及消費(fèi)電子。 ? FPGA在通信領(lǐng)域用得很早。很多基站的處理芯片(基帶處理、波束賦形、天線收發(fā)器等),都是用的FPGA。核心網(wǎng)的編碼和協(xié)議加速等,也用到它。數(shù)據(jù)中心之前在DPU等部件上,也用。
? 后來,很多技術(shù)成熟了、定型了,通信設(shè)備商們就開始用ASIC替代,以此減少成本。 ? 值得一提的是,最近這些年很熱門的Open RAN,其實(shí)很多都是采用通用處理器(Intel CPU)進(jìn)行計(jì)算。這種方案的能耗遠(yuǎn)遠(yuǎn)不如FPGA和ASIC。這也是包括華為等設(shè)備商不愿意跟進(jìn)Open RAN的主要原因之一。 ? 汽車和工業(yè)領(lǐng)域,主要是看中了FPGA的時(shí)延優(yōu)勢(shì),所以會(huì)用在ADAS(高級(jí)駕駛輔助系統(tǒng))和伺服電機(jī)驅(qū)動(dòng)上。 ? 消費(fèi)電子用FPGA,是因?yàn)楫a(chǎn)品迭代太快。ASIC的開發(fā)周期太長了,等做出東西來,黃花菜都涼了。 ?
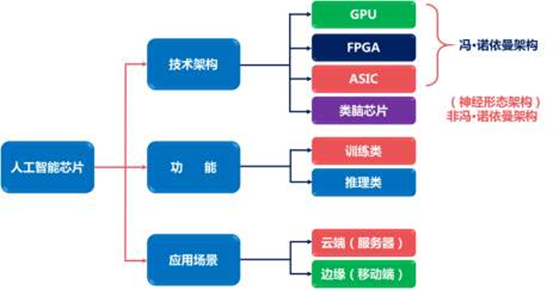
? █ FPGA、ASIC、GPU,誰是最合適的AI芯片?
首先,單純從理論和架構(gòu)的角度,ASIC和FPGA的性能和成本,肯定是優(yōu)于CPU和GPU的。 ?

? CPU、GPU遵循的是馮·諾依曼體系結(jié)構(gòu),指令要經(jīng)過存儲(chǔ)、譯碼、執(zhí)行等步驟,共享內(nèi)存在使用時(shí),要經(jīng)歷仲裁和緩存。 ? 而FPGA和ASIC并不是馮·諾依曼架構(gòu)(是哈佛架構(gòu))。以FPGA為例,它本質(zhì)上是無指令、無需共享內(nèi)存的體系結(jié)構(gòu)。
FPGA的邏輯單元功能在編程時(shí)已確定,屬于用硬件來實(shí)現(xiàn)軟件算法。對(duì)于保存狀態(tài)的需求,F(xiàn)PGA中的寄存器和片上內(nèi)存(BRAM)屬于各自的控制邏輯,不需要仲裁和緩存。 ? 從ALU運(yùn)算單元占比來看,GPU比CPU高,F(xiàn)PGA因?yàn)閹缀鯖]有控制模塊,所有模塊都是ALU運(yùn)算單元,比GPU更高。 ? 所以,綜合各個(gè)角度,F(xiàn)PGA的運(yùn)算速度會(huì)比GPU更快。 ? 再看看功耗方面。 ? GPU的功耗,是出了名的高,單片可以達(dá)到250W,甚至450W(RTX4090)。而FPGA呢,一般只有30~50W。
? 這主要是因?yàn)閮?nèi)存讀取。GPU的內(nèi)存接口(GDDR5、HBM、HBM2)帶寬極高,大約是FPGA傳統(tǒng)DDR接口的4-5倍。但就芯片本身來說,讀取DRAM所消耗的能量,是SRAM的100倍以上。GPU頻繁讀取DRAM的處理,產(chǎn)生了極高的功耗。 ? 另外,F(xiàn)PGA的工作主頻(500MHz以下)比CPU、GPU(1~3GHz)低,也會(huì)使得自身功耗更低。FPGA的工作主頻低,主要是受布線資源的限制。有些線要繞遠(yuǎn),時(shí)鐘頻率高了,就來不及。 ? 最后看看時(shí)延。 ? GPU時(shí)延高于FPGA。 ? GPU通常需要將不同的訓(xùn)練樣本,劃分成固定大小的“Batch(批次)”,為了最大化達(dá)到并行性,需要將數(shù)個(gè)Batch都集齊,再統(tǒng)一進(jìn)行處理。 ? FPGA的架構(gòu),是無批次(Batch-less)的。每處理完成一個(gè)數(shù)據(jù)包,就能馬上輸出,時(shí)延更有優(yōu)勢(shì)。 ? 那么,問題來了。GPU這里那里都不如FPGA和ASIC,為什么還會(huì)成為現(xiàn)在AI計(jì)算的大熱門呢?
? 很簡(jiǎn)單,在對(duì)算力性能和規(guī)模的極致追求下,現(xiàn)在整個(gè)行業(yè)根本不在乎什么成本和功耗。 ? 在英偉達(dá)的長期努力下,GPU的核心數(shù)和工作頻率一直在提升,芯片面積也越來越大,屬于硬剛算力。功耗靠工藝制程,靠水冷等被動(dòng)散熱,反而不著火就行。
? 他們搗鼓出來的CUDA,是GPU的一個(gè)核心競(jìng)爭(zhēng)力。基于CUDA,初學(xué)者都可以很快上手,進(jìn)行GPU的開發(fā)。他們苦心經(jīng)營多年,也形成了群眾基礎(chǔ)。 ? 相比之下,F(xiàn)PGA和ASIC的開發(fā)還是太過復(fù)雜,不適合普及。 ? 在接口方面,雖然GPU的接口比較單一(主要是PCIe),沒有FPGA靈活(FPGA的可編程性,使其能輕松對(duì)接任何的標(biāo)準(zhǔn)和非標(biāo)準(zhǔn)接口),但對(duì)于服務(wù)器來說,足夠了,插上就能用。 ? 除了FPGA之外,ASIC之所以在AI上干不過GPU,和它的高昂成本、超長開發(fā)周期、巨大開發(fā)風(fēng)險(xiǎn)有很大關(guān)系。現(xiàn)在AI算法變化很快,ASIC這種開發(fā)周期,很要命。
? 綜合上述原因,GPU才有了現(xiàn)在的大好局面。 ? 在AI訓(xùn)練上,GPU的算力強(qiáng)勁,可以大幅提升效率。 ? 在AI推理上,輸入一般是單個(gè)對(duì)象(圖像),所以要求要低一點(diǎn),也不需要什么并行,所以GPU的算力優(yōu)勢(shì)沒那么明顯。很多企業(yè),就會(huì)開始采用更便宜、更省電的FPGA或ASIC,進(jìn)行計(jì)算。 ? 其它一些算力場(chǎng)景,也是如此。看重算力絕對(duì)性能的,首選GPU。算力性能要求不那么高的,可以考慮FPGA或ASIC,能省則省。 ?
? █ 最后的話
關(guān)于CPU、GPU、FPGA、ASIC的知識(shí),就介紹到這里了。 ? 它們是計(jì)算芯片的典型代表。人類目前所有的算力場(chǎng)景,基本上都是由它們?cè)谪?fù)責(zé)。 ? 隨著時(shí)代的發(fā)展,計(jì)算芯片也有了新的趨勢(shì)。例如,不同算力芯片進(jìn)行混搭,互相利用優(yōu)勢(shì)。我們管這種方式,叫做異構(gòu)計(jì)算。 ? 另外,還有IBM帶頭搞的類腦芯片,類似于大腦的神經(jīng)突觸,模擬人腦的處理過程,也獲得了突破,熱度攀升。以后有機(jī)會(huì),我再和大家專門介紹。
審核編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論