 電子發燒友App
電子發燒友App


憑借出色的性能和功耗指標,賽靈思 FPGA 成為設計人員構建卷積神經網絡的首選。新的軟件工具可簡化實現工作。
人工智能正在經歷一場變革,這要得益于機器學習的快速進步。在機器學習領域,人們正對一類名為“深度學習”算法產生濃厚的興趣,因為這類算法具有出色的大數據集性能。在深度學習中,機器可以在監督或不受監督的方式下從大量數據中學習一項任務。大規模監督式學習已經在圖像識別和語音識別等任務中取得巨大成功。
深度學習技術使用大量已知數據找到一組權重和偏差值,以匹配預期結果。這個過程被稱為訓練,并會產生大型模式。這激勵工程師傾向于利用專用硬件(例如 GPU)進行訓練和分類。
隨著數據量的進一步增加,機器學習將轉移到云。大型機器學習模式實現在云端的 CPU 上。盡管 GPU 對深度學習算法而言在性能方面是一種更好的選擇,但功耗要求之高使其只能用于高性能計算集群。因此,亟需一種能夠加速算法又不會顯著增加功耗的處理平臺。在這樣的背景下,FPGA 似乎是一種理想的選擇,其固有特性有助于在低功耗條件下輕松啟動眾多并行過程。
讓我們來詳細了解一下如何在賽靈思 FPGA 上實現卷積神經網絡 (CNN)。CNN 是一類深度神經網絡,在處理大規模圖像識別任務以及與機器學習類似的其他問題方面已大獲成功。在當前案例中,針對在 FPGA 上實現 CNN 做一個可行性研究,看一下 FPGA 是否適用于解決大規模機器學習問題。
卷積神經網絡是一種深度神經網絡 (DNN),工程師最近開始將該技術用于各種識別任務。圖像識別、語音識別和自然語言處理是 CNN 比較常見的幾大應用。
什么是卷積神經網絡??
卷積神經網絡是一種深度神經網絡 (DNN),工程師最近開始將該技術用于各種識別任務。圖像識別、語音識別和自然語言處理是 CNN 比較常見的幾大應用。
2012 年,Alex Krishevsky 與來自多倫多大學 (University of Toronto) 的其他研究人員 [1] 提出了一種基于 CNN 的深度架構,贏得了當年的“Imagenet 大規模視覺識別挑戰”獎。他們的模型與競爭對手以及之前幾年的模型相比在識別性能方面取得了實質性的提升。自此,AlexNet 成為了所有圖像識別任務中的對比基準。

AlexNet 有五個卷積層和三個致密層(圖 1)。每個卷積層將一組輸入特征圖與一組權值濾波器進行卷積,得到一組輸出特征圖。致密層是完全相連的一層,其中的每個輸出均為所有輸入的函數。
卷積層??
AlexNet 中的卷積層負責三大任務,如圖 2 所示:3D 卷積;使用校正線性單元 (ReLu) 實現激活函數;子采樣(最大池化)。3D 卷積可用以下公式表示:
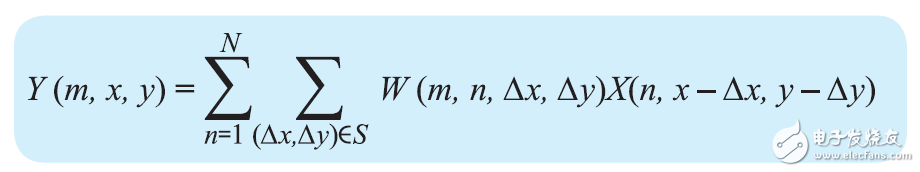
其中Y (m,x,y) 是輸出特征圖 m 位置 (x,y) 處的卷積輸出,S 是 (x,y) 周圍的局部鄰域,W 是卷積濾波器組,X(n,x,y)是從輸入特征圖 n 上的像素位置 (x,y) 獲得的卷積運算的輸入。
所用的激活函數是一個校正線性單元,可執行函數 Max(x,0)。激活函數會在網絡的傳遞函數中引入非線性。最大池化是 AlexNet 中使用的子采樣技術。使用該技術,只需選擇像素局部鄰域最大值傳播到下一層。
定義致密層?
AlexNet 中的致密層相當于完全連接的層,其中每個輸入節點與每個輸出節點相連。AlexNet 中的第一個致密層有 9,216 個輸入節點。將這個向量乘以權值矩陣,以在 4,096 個輸出節點中產生輸出。在下一個致密層中,將這個 4,096 節點向量與另一個權值矩陣相乘得到 4,096 個輸出。最后,使用 4,096 個輸出通過 softmax regression 為 1,000 個類創建概率。
在 FPGA 上實現 CNN?
隨著新型高級設計環境的推出,軟件開發人員可以更方便地將其設計移植到賽靈思 FPGA 中。軟件開發人員可通過從 C/C++ 代碼調用函數來充分利用 FPGA 與生俱來的架構優勢。Auviz Systems 的庫(例如 AuvizDNN)可為用戶提供最佳函數,以便其針對各種應用創建定制 CNN。可在賽靈思 SD-Accel? 這樣的設計環境中調用這些函數,以在 FPGA 上啟動內核。
最簡單的方法是以順序方式實現卷積和向量矩陣運算。考慮到所涉及計算量,因此順序計算會產生較大時延。
順序實現產生很大時遲的主要原因在于 CNN 所涉及的計算的絕對數量。圖 3 顯示了 AlexNet 中每層的計算量和數據傳輸情況,以說明其復雜性。
因此,很有必要采用并行計算。有很多方法可將實現過程并行化。圖 6 給出了其中一種。在這里,將 11x11 的權值矩陣與一個 11x11 的輸入特征圖并行求卷積,以產生一個輸出值。這個過程涉及 121 個并行的乘法-累加運算。根據 FPGA 的可用資源,我們可以并行對 512 抑或 768 個值求卷積。
為了進一步提升吞吐量,我們可以將實現過程進行流水線化。流水線能為需要一個周期以上才能完成的運算實現更高的吞吐量,例如浮點數乘法和加法。通過流水線處理,第一個輸出的時延略有增加,但每個周期我們都可獲得一個輸出。
使用 AuvizDNN 在 FPGA 上實現的完整 CNN 就像從 C/C++ 程序中調用一連串函數。在建立對象和數據容器后,首先通過函數調用來創建每個卷積層,然后創建致密層,最后是創建 softmax 層,如圖 4 所示。
AuvizDNN 是 Auviz Systems 公司提供的一種函數庫,用于在 FPGA 上實現 CNN。該函數庫提供輕松實現 CNN 所需的所有對象、類和函數。用戶只需要提供所需的參數來創建不同的層。例如,圖 5 中的代碼片段顯示了如何創建 AlexNet 中的第一層。
AuvizDNN 提供配置函數,用以創建 CNN 的任何類型和配置參數。AlexNet 僅用于演示說明。CNN 實現內容作為完整比特流載入 FPGA 并從 C/C++ 程序中調用,這使開發人員無需運行實現軟件即可使用 AuvizDNN。
FPGA 具有大量的查找表 (LUT)、DSP 模塊和片上存儲器,因此是實現深度 CNN 的最佳選擇。在數據中心,單位功耗性能比原始性能更為重要。數據中心需要高性能,但功耗要在數據中心服務器要求限值之內。?
像賽靈思 Kintex? UltraScale? 這樣的 FPGA 器件可提供高于 14 張圖像/秒/瓦特的性能,使其成為數據中心應用的理想選擇。圖 6 介紹了使用不同類型的 FPGA 所能實現的性能。
一切始于 c/c++
卷積神經網絡備受青睞,并大規模部署用于處理圖像識別、自然語言處理等眾多任務。隨著 CNN 從高性能計算應用 (HPC) 向數據中心遷移,需要采用高效方法來實現它們。
FPGA 可高效實現 CNN。FPGA 的具有出色的單位功耗性能,因此非常適用于數據中心。
AuvizDNN 函數庫可用來在 FPGA 上實現 CNN。AuvizDNN 能降低 FPGA 的使用復雜性,并提供用戶可從其 C/C++ 程序中調用的簡單函數,用以在 FPGA 上實現加速。使用 AuvizDNN 時,可在 AuvizDNN 庫中調用函數,因此實現 FPGA 加速與編寫 C/C++ 程序沒有太大區別。
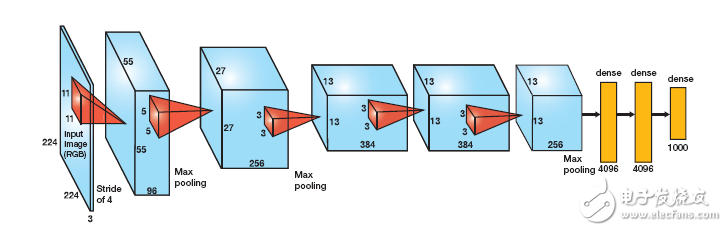
圖 1 –? AlexNet 是一種圖像識別基準,包含五個卷積層(藍框)和三個致密層(黃)。

圖 2 – AlexNet 中的卷積層執行 3D 卷積、激活和子采樣。

圖 3? – 圖表展示了 AlexNet 中涉及的計算復雜性和數據傳輸數量。

圖 4 - 實現 CNN 時的函數調用順序。

圖 5 – 使用 AuvizDNN 創建 AlexNet 的 L1 的代碼片段。

圖 6 – AlexNets 的性能因 FPGA 類型不同而不同。















 工商網監
工商網監
評論