 電子發燒友App
電子發燒友App


據麥姆斯咨詢報道,隨著自動駕駛汽車市場的成熟,傳感器和感知工程師評估系統效率、可靠性和性能等工作變得越來越復雜。許多行業領導者已經認識到,用于激光雷達(LiDAR)數據收集的常規指標,例如幀率(frame rate)、全幀分辨率(full frame resolution)和探測距離(detection range)已不再能充分衡量激光雷達解決自動駕駛實際用例的有效性。
第一代激光雷達被動地搜索場景并使用背景圖案來探測物體,而背景圖案在時間(無法通過快速重新訪問進行增強)和空間(無法在諸如路面或行人之類的高度感興趣區域額外增加分辨率)兩個維度都是固定的。新型先進固態激光雷達可實現智能信息捕獲,從而將其功能從“被動搜索”或目標探測擴展到“主動搜索”,在許多情況下,還可以實時獲取目標的分類屬性。
由于早期的激光雷達使用固定光柵掃描,因此行業采用的是非常簡單的性能指標,無法表達出自動駕駛對所需傳感器的細微要求差別。因此,以AEye在內的許多激光雷達行業領導廠商正提議采用三項新指標來擴展對激光雷達性能的評估。具體而言:對“幀率(Rate)”指標進行擴展,以包括“目標重訪速度”;對“分辨率(Resolution)”指標進行擴展,以獲得“瞬時分辨率”;對“探測距離(Range)”指標進行擴展,以反映更重要的“目標分類距離”。
我們建議將這些新指標與攝像頭、雷達和被動激光雷達性能的現有指標結合使用。這些擴展的指標可衡量傳感器智能增強感知能力,并對傳感器系統在現實環境中改善自動駕駛汽車安全性和性能進行更全面的評估。
自動駕駛行業利用了經先進機器視覺研究驗證后的架構,并將其應用于特定激光雷達產品。事實證明,相比于目標識別,“搜索、采集(或分類)和采取行動”的架構具有通用性和指導性。
搜索是探測到所有目標而不會丟失任何目標的能力。
采集被定義為能夠進行搜索探測并增強對目標屬性的理解,以加速分類并確定意圖的能力(可通過對目標類型進行分類或計算來實現)。
采取行動指由車輛感知系統或域控制器經過訓練或建議對傳感器定義的響應。響應大致可分為四類:(1)繼續對新目標進行掃描,不需要增強信息;(2)對目標繼續掃描并進一步詢問,收集有關目標屬性的更多信息以進行分類;(3)對目標繼續掃描并跟蹤分類為非威脅性目標;(4)對目標繼續掃描并命令控制系統采取規避措施。
此架構的最終目標就是車輛完全安全運行所要求的性能指標和系統有效性。但是,由于目前大多數激光雷達系統都是被動的,只能進行基本搜索。因此,用于評估這些系統性能的常規指標與基本的目標探測功能有關:幀率(Rate)、分辨率(Resolution)和探測距離(Range)。如果以安全性為最終目標,則“搜索”需要更加智能,“采集(或分類)”操作必須更快速準確地進行,以便傳感器或車輛確定如何立即“采取行動”。
汽車激光雷達系統的制造商經常被問及產品幀率,以及技術是否有能力在一定距離內(通常為230米)探測到反射率為10%的物體。我們認為這些是必須的基本指標,但無法證明其捕捉關鍵細節(例如目標尺寸,被探測和識別所需的速度,或收集信息的成本),因而無法滿足要求。我們認為,在評估汽車激光雷達系統時,采用更全面的方法將對該行業產生積極影響。我們必須從整體審視與感知系統相關的指標,而不是將其作為單一的傳感器,然后問自己:“哪些信息將使感知系統做出更好、更快的決策?”
傳統指標一:10Hz~20Hz的幀率
擴展:目標重訪速度(Object Revisit Rate),對某一點或多點兩次拍攝的時間差
僅定義單點探測距離是不夠的,因為單個詢問點(單次拍攝)很難提供足夠的置信度——僅具有參考價值。因此,被動激光雷達系統需要對同一位置進行多次詢問/探測,或者在同一目標上進行多次詢問/探測以驗證目標或場景。在探測系統中,探測目標所需的時間取決于許多變量,例如距離、詢問模式、分辨率、反射率、物體的形狀和掃描速率。
傳統度量標準缺少的一個關鍵因素是對時間更精細的定義。因此,我們建議將目標重新訪問速度作為汽車激光雷達的一項新指標,諸如AEye推出的高靈敏度激光雷達iDAR能夠重新訪問同一幀內的目標。對目標的第一次測量與第二次測量之間的時間差非常關鍵,因為較短的目標重訪時間可以縮短關聯場景中多個運動目標先進算法的處理時間。當樣本的時間差過長時,關聯/相關多個運動目標的最佳算法可能會出現混亂。冗長的合并處理時間或延遲是該行業面臨的主要問題。
高靈敏度iDAR平臺通過允許在一幀內進行智能拍攝調度來加快重訪速度。iDAR不僅可以在傳統架構內多次詢問位置或目標,而且還可以維持背景搜索模式,同時覆蓋其它智能拍攝結果。例如,iDAR傳感器可以快速連續(30微秒)安排對目標進行兩次重復拍攝。這些多重詢問可以與用戶(人類或計算機)的需求進行情景集成,從而提高置信度,減少延時,增加探測距離。
這些額外的詢問與數據相關。例如,出現低置信度時重新探測目標,并且期望快速驗證或拒絕,啟動次級數據和測量。在圖1中,傳統被動激光雷達典型幀率為10Hz。對于傳統被動激光雷達,這就是目標的重訪速度。現在,借助AEye的iDAR技術,目標重訪速度與幀率有所不同,并且對關鍵點/目標的重訪時間差可以低至數十微秒,輕松實現比傳統被動激光雷達快100倍到1000倍的性能。
這意味著使用動態對象重新訪問功能的感知工程團隊可以創建一種感知系統,該系統至少比傳統被動激光雷達快一個數量級,且不會破壞背景掃描模式。我們認為,此功能對于實現Level 4和Level 5自動駕駛汽車來講是非常重要的,因為車輛將需要處理復雜的邊緣計算情況,例如識別朝著車輛前燈迎面駛來的行人或橫穿車輛行駛路徑的平板式半掛車。
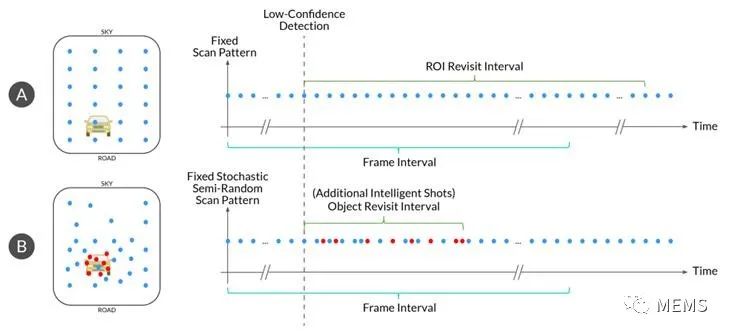
圖1:先進的高靈敏度激光雷達利用智能掃描模式來實現目標重訪間隔(Object Revisit Interval),如圖(B)所示AEye iDAR的隨機掃描模式,與典型固定模式激光雷達(A)的“重訪間隔”進行比較。可以看出,iDAR(B)能夠在一幀內對車輛進行八次目標重訪/探測,而典型的固定模式激光雷達(A)只能實現一次。
因此,在“搜索、采集和采取行動”的架構中,加快目標重訪速度可以加快采集速度,因為這可以識別并自動重訪目標,從而在場景中描繪出更完整的畫面。最終允許傳感器進行目標屬性分類,并高效地詢問和跟蹤潛在威脅。
實際用例1:正面探測
當您駕駛車輛時,眼前的世界會在十分之一秒之內發生巨大變化。實際上,兩輛車以每小時100公里速度相向而行時,0.1秒后距離就減少5.5米。通過提高目標重訪速度,由于在兩次拍攝之間目標明顯移動的可能性降低,增加了下一次拍攝到相同目標的可能性。這有助于用戶解決“目標對應問題”,確定動態場景的一個快照的哪些部分對應于同一場景另一快照的哪些部分。做到這一點的同時,使用戶能夠快速建立置信度更高的統計數據,并生成下游處理器可能需要的聚合信息,例如目標的速度和加速度。有選擇地提高目標重訪速度,同時降低對稀疏區域(如天空)的重訪率,顯著幫助實現更高層次的推測算法,從而使感知和路徑規劃系統能夠更快地確定最佳的自動決策。
實際用例2:橫向探測
橫向進入場景的車輛最難追蹤。即使是多普勒雷達,在這種情況下也很難應對。但是,當探測已成為采集過程的一部分時,有選擇地分配拍攝次數以提取速度和加速度,則會大大減少每幀所需的拍攝次數。iDAR增加二次探測,對每個目標探測建立速度估算,總拍攝次數僅增加1%。而使用固定掃描系統獲得速度,所需的拍攝次數增加一倍。速度和特征拍攝消除了歧義,允許更有效地利用資源,讓自動駕駛更安全。
傳統指標二:固定視場的固定分辨率
擴展:瞬時分辨率(Instantaneous Resolution),增加激光雷達同一幀內關鍵區域的分辨率
傳統的分辨率,假定以恒定的模式和均勻的功率對視場內目標進行掃描。這對于收集能力較差、智能級別較低的被動傳感器來說,非常有意義。另外,傳統的分辨率是假設場景內的顯著信息在空間和時間上是統一的,我們知道這并不正確,這對于行駛中的車輛來講更不正確。但是,正是由于這些假設,傳統激光雷達系統會不加選擇地從車輛周圍收集千兆字節的數據,并將這些輸入發送到CPU進行抽取和解釋。該數據中約70%~90%是無用或冗余,需要被過濾。此外,傳統激光雷達系統對任何區域都實施相同級別的功率,相當于對車輛的行進路徑的目標提供與對天空相同的功率。這樣的處理效率極低。
作為人類,我們不會平均地“吸收”周圍的一切。我們的視覺皮層會過濾無關信息,例如飛過頭頂的飛機,同時(而不是連續地)將我們的眼睛聚焦在特定的興趣點上。集中在一個興趣點,將其它次要目標放用余光察覺。這就是所謂的“Foveation視覺模型”,目標被分配了“更高濃度”的視錐細胞,因此可以更加生動地看到它。
iDAR應用仿生技術來擴展人類視覺皮層的人工感知能力。人眼通常只集中看一個區域,而iDAR可以同時(以多種方式)集中在多個區域,同時還可以進行背景掃描以確保不會遺漏任何新進入物體。我們將此功能描述為感興趣區域(ROI)。此外,由于人類完全依賴于來自太陽、月亮或人造照明發出的光,因此人類的“Foveation視覺模型”是“只能接收”的,即是被動的。相比之下,iDAR集中在發射端(激光選擇“繪畫”的區域)和接收端(處理被選擇的關注位置/時間)兩個方面。
圖2是一個示例。圖2顯示了兩種系統,即系統A和系統B。這兩種系統在同一場景中具有相似數量的拍攝次數(左)。系統A代表傳統激光雷達的典型掃描模式,固定的掃描模式會產生固定的幀率,而沒有ROI的概念。系統B顯示了調整后的靈敏掃描模式。系統B中的拍攝次數在正方形內的ROI(小方框)之內和周圍更加密集。此外,背景掃描繼續搜索以確保不會遺漏任何新目標,同時對固定區域增加額外的分辨率以幫助采集。從本質上講,這是利用智能來優化功率和拍攝次數。
查看系統A和B相關圖(右),我們發現系統B(靈敏掃描模式)可以在比系統A(固定掃描模式)短得多的時間間隔內重新訪問ROI。系統B不僅可以完成一次ROI重訪間隔,還能在單幀內實現多個ROI。而系統A無法重新訪問。iDAR實現傳統激光雷達無法完成的事情:實現動態感知,使系統能夠以前所未有的速度專注于特定ROI并收集更全面的數據。
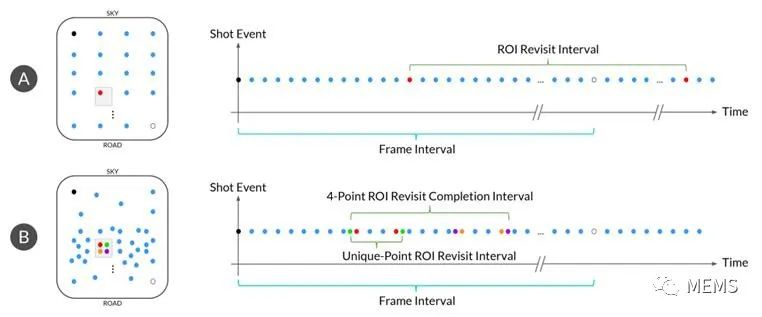
圖2:與傳統掃描模式(A)相比,iDAR(B)的感興趣區域(ROI)和Foveation視覺模型展示。
在“搜索、采集和采取行動”架構中,瞬時分辨率使iDAR系統可以搜索整個場景并獲取多個目標,并捕獲有關它們的更多信息。iDAR還允許在一個場景中創建多個同時的ROI,從而使系統能夠關注并收集特定目標更全面的數據,從而更完整地詢問并更有效地跟蹤目標。
實際用例:目標詢問
識別出感興趣目標后,iDAR可以實現Foveation視覺模型,掃描、收集更多有用信息并采取額外的分類屬性。例如,假設車輛在行進路徑中遇到了一位正在穿過人行橫道的行人。由于iDAR可以動態改變ROI內的時間和空間采樣密度(因此我們稱之為“瞬時分辨率”),該系統可以更多地關注到人行橫道,而較少地關注無關信息,如路邊停放的車輛。ROI使iDAR可以快速、有效和準確地識別有關人行橫道的關鍵信息,例如速度和方向。iDAR系統向域控制器提供最有用、最可執行的數據,以確定最及時的行動方案。
有三種利用瞬時分辨率來實現的用例:
固定ROI:如今,被動系統只能分配更多的水平掃描線,這是一種非常簡單的Foveation視覺技術,受其固定分辨率限制。具有瞬時分辨率的第二代智能激光雷達(如iDAR),可幫助整車廠或Tier 1廠商利用先進仿真程序來測試數百個(甚至數千個)拍攝模式(無論速度、功率和其他限制條件如何變化)以識別將固定ROI與更高瞬時分辨率集成在一起的最佳模式,獲得其所需的結果。
例如,固定ROI可用于優化不同傾斜度前窗玻璃后面的拍攝模式。此外,固定ROI還可以用于相對復雜的城市環境,威脅更可能來自路邊,例如車門打開,行人和其它交通工具橫穿馬路或車輛的前進路徑。增加覆蓋道路兩側和車輛前方路面固定區域的分辨率來定義ROI(請參考圖3B)。這樣可以為ROI提供出色的垂直分辨率和水平分辨率。模式一旦獲得批準,就可以固定以確保功能安全。
觸發式ROI:觸發式ROI需要軟件可定義的系統,該系統可進行編程以接受觸發。感知軟件團隊可以確定,當滿足某些條件時,將在現有掃描模式中生成ROI。例如,地圖或導航系統可能會發出信號通知您正在接近十字路口,在場景的關鍵區域上產生目標ROI更多細節(請參考圖3C)。
動態ROI:動態ROI需要最高智能水平,并利用戰斗機自動瞄準系統(ATS)的相同技術和方法,隨時間推移連續詢問關注目標。當這些目標移近或離開時,ROI的大小和密度會發生變化。例如,可以探測到場景中的行人、自行車騎行者、車輛或其它物體,并自動應用動態ROI來跟蹤其運動(請參考圖3D)。
圖3:圖A展示了車輛接近十字路口時的場景。圖B展示了固定ROI覆蓋道路兩側和緊鄰車輛前方區域的情況。圖C展示了觸發式ROI:導航系統在車輛接近十字路口時觸發特定的ROI。圖D展示了動態ROI:當多個目標在場景中移動時,它們會被探測到并被跟蹤。
傳統指標三:目標探測距離
擴展:目標分類距離(object classification range),擁有足夠的數據來以實現對目標分類的距離
在評估汽車激光雷達系統對周圍空間的感知水平時,制造商通常認為確定其探測距離很有價值。為了優化安全性,車載計算機系統應盡可能早地探測到障礙物。從理論上講,速度決定了控制系統是否可以計劃和執行及時的規避措施。AEye認為“探測距離”這個指標是必要的,但還不夠。感知系統應該能對目標進行分類并將準確及時的信息傳遞給控制系統。
最重要的不僅是有多快能探測到目標,而且有多快能識別出目標并進行分類,從而做出威脅級別決策并計算出適當的響應。單點探測無法與噪聲進行區分。因此,我們使用行業內對探測的通用定義,即每幀和/或多幀之間的相鄰拍攝的持久性。我們要求每幀(在相同探測距離內有五個點)和/或從多幀之間(連續五幀的一個相關點)對一個目標進行五次探測,以驗證探測到了有效的對象。在20Hz時,定義一次簡單的探測需要0.25秒。
當前,分類通常在感知堆棧中進行,對目標進行標記,并最終對其進行更清晰的識別。此數據被用于預測行為模式或軌跡。傳感器提供的分類屬性越多,感知系統確認和分類的速度就越快。AEye認為,評估這種關鍵汽車激光雷達能力的更好方法是影響“目標分類距離”的能力。該指標減少了早期感知堆棧的未知數,如與噪聲抑制相關的等待時間,從而確定了重要信息。
作為相對較新的領域,尚未確定汽車激光雷達分類所需數據量的定義。因此,我們建議使用視頻分類的感知標準作為參考定義。根據視頻標準,采用的分類是基于對象的3 x 3像素網格。在此定義下,可以通過汽車激光雷達系統以多快的速度生成高質量、高分辨率的3 x 3點云來進行評估,使感知堆棧能夠理解場景中的物體和人物。
對于傳統激光雷達系統而言,生成3 x 3點云是一項艱巨的任務。盡管許多系統都宣稱可以在一秒鐘內顯示100萬點甚至更多的點云,但這些圖像均勻性不佳。對于分類而言,這些固定采樣模式可能很難完成,因為域控制器必須每秒處理100萬個點,這在許多情況下與所涉及目標的關鍵采樣所需的分辨率無法平衡。如此廣泛的點樣本意味著它需要執行其它解釋,從而占用大量CPU資源。
圖4:在探測物周圍排列密集的3 x 3網格可以收集更多有用的數據,并大大加快分類速度。在左側的“掃描1”(scan 1)中,對車輛進行了一次探測。無需等待下一幀對該車輛進行重新采樣(如傳統激光雷達的典型操作),而是快速形成動態ROI,如“掃描2”(scan 2)所示。在初始單次探測之后和完成下一次掃描之前,將立即執行。
回到“搜索、采集和采取行動”的架構中,一旦我們獲得了目標并確定其是有效的潛在威脅,我們就可以分配更多拍攝進行分類,并在需要時采取行動。另外,如果我們確定目標不是立即威脅,我們可以更全面地詢問該目標以獲取其它分類數據,或者每次掃描拍攝幾次就可以對其進行簡單跟蹤。
實際用例:無保護左轉彎
對不同目標需要不同響應。在具有挑戰性的駕駛場景尤其如此,例如在高速行駛過程中的無保護左轉彎。想象一下,在四車道道路上的自動駕駛汽車,其時速限制為100公里/小時,在兩條行車道上進行無保護左轉彎。在迎面而來的交通中,一條車道有摩托車,另一條車道有小轎車。在這種情況下,目標分類距離至關重要,在足夠的距離內將一個目標分類為摩托車,高速行駛的自動駕駛汽車會更加謹慎,這是由于摩托車行駛速度較快且路徑不可預測。
實際用例:校車(特殊目標)
在特定距離對目標進行分類的意義比即時響應更為重要。一個很好的例子就是遇到一輛滿員的校車。該目標被歸類為校車的速度越快,自動駕駛車輛啟動適當協議的速度就越快——減慢車速并部署其它工具,如在校車周圍區域增加瞬時分辨率(觸發式ROI),以立即捕獲兒童朝車道移動的任何動作。此功能可用于警車、救護車、消防車或任何需要自動駕駛車輛改變詢問場景、改變速度或路徑的特殊車輛。
結論
在本文中,我們討論了減少同一幀內對目標探測時間差至關重要的原因。由于需要捕獲同一點/目標的多次探測才能完全理解該目標或場景,因此對于汽車激光雷達來講,目標重訪速度是比幀速率更為關鍵的指標。
另外,我們認為分辨率是不夠的。量化瞬時分辨率更加重要,因為智能、高靈敏度的分辨率更有效,并且可以通過更短的響應時間提供更高的安全性,尤其是在將ROI與卷積神經網絡配合時。
最后,我們證明了探測距離這個指標遠遠不夠,目標分類距離(即識別和分類目標的速度)更為重要。僅僅量化傳感器可以探測到潛在目標的距離還不夠。還必須量化從實際事件發生到被傳感器探測的延遲,并加上從傳感器探測到CPU決策的延遲。在此架構下,激光雷達系統可提供的屬性越多,感知系統的分類速度就越快。
傳統的激光雷達傳感器雖然具有開創性意義,但它用固定的掃描模式對空間被動地搜索。新一代智能傳感器從被動探測目標轉變為實時主動搜索目標并識別其分類屬性。隨著感知技術和傳感器系統的發展,用于衡量其性能的指標也必須隨之演進。
對自動駕駛車輛來講,安全性永遠排第一。這些擴展指標不僅應展示激光雷達能夠實現的功能,而且還應展示出這些功能如何使車輛在現實駕駛場景中更接近最佳安全條件。
文章來源:Aeye官網,由麥姆斯咨詢編譯。



















 工商網監
工商網監
評論