 電子發(fā)燒友App
電子發(fā)燒友App


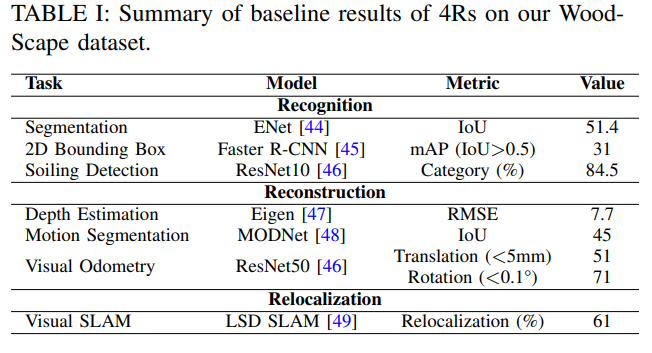
Camera是自動(dòng)駕駛系統(tǒng)中的主要傳感器,它們提供高信息密度,最適合檢測(cè)為人類視覺(jué)而設(shè)置的道路基礎(chǔ)設(shè)施。全景相機(jī)系統(tǒng)通常包括四個(gè)魚(yú)眼攝像頭,190°+視野覆蓋車輛周圍的整個(gè)360°,聚焦于近場(chǎng)感知。它們是低速、高精度和近距離傳感應(yīng)用的主要傳感器,如自動(dòng)泊車、交通堵塞輔助和低速緊急制動(dòng)。
在這項(xiàng)工作中,論文對(duì)此類視覺(jué)系統(tǒng)進(jìn)行了詳細(xì)的調(diào)查,并在可分解為四個(gè)模塊組件(即識(shí)別、重建、重新定位和重組)的架構(gòu)背景下進(jìn)行了調(diào)查,共同稱之為4R架構(gòu)。論文討論了每個(gè)組件如何完成一個(gè)特定方面,并提供了一個(gè)位置論證(即它們可以協(xié)同作用),形成一個(gè)完整的低速自動(dòng)化感知系統(tǒng)。
本文的工作部分受到了Malik等人在[5]中的工作的啟發(fā)。這項(xiàng)工作的作者提出,計(jì)算機(jī)視覺(jué)的核心問(wèn)題是重建、識(shí)別和重組,他們稱之為計(jì)算機(jī)視覺(jué)的3R。在此,論文建議將計(jì)算機(jī)視覺(jué)的3R擴(kuò)展并專門(mén)化為自動(dòng)駕駛計(jì)算機(jī)視覺(jué)的4R:重建、識(shí)別、重組和重新定位。
重建意味著從視頻序列推斷場(chǎng)景幾何體,包括車輛在場(chǎng)景中的位置。這一點(diǎn)的重要性應(yīng)該是顯而易見(jiàn)的,因?yàn)樗鼘?duì)于場(chǎng)景繪制、障礙物避免、機(jī)動(dòng)和車輛控制等問(wèn)題至關(guān)重要。Malik等人將此擴(kuò)展到幾何推斷之外,以包括反射和照明等特性。然而,這些附加屬性(至少目前)在自動(dòng)駕駛計(jì)算機(jī)視覺(jué)環(huán)境中并不重要,因此論文將重建定義為更傳統(tǒng)意義上的三維幾何恢復(fù)。
識(shí)別是一個(gè)術(shù)語(yǔ),用于將語(yǔ)義標(biāo)簽附加到視頻圖像或場(chǎng)景的各個(gè)方面,識(shí)別中包括層次結(jié)構(gòu)。例如,自行車手有一個(gè)空間層次結(jié)構(gòu),因?yàn)樗梢苑譃樽孕熊嚭万T手的子集,而車輛類別可以有汽車、卡車、自行車等分類子類別。只要對(duì)自動(dòng)駕駛系統(tǒng)有用,這種情況就可以繼續(xù)下去。燈可以按類型(車燈、路燈、剎車燈等)、顏色(紅、黃、綠)以及它們對(duì)自動(dòng)駕駛車輛的重要性(需要響應(yīng),可以忽略)進(jìn)行分類,從而完成系統(tǒng)的高級(jí)推理。
重新定位是指車輛相對(duì)于其周圍環(huán)境的位置識(shí)別和度量定位。可以針對(duì)宿主車輛中預(yù)先記錄的軌跡進(jìn)行,例如,經(jīng)過(guò)訓(xùn)練的停車場(chǎng),也可以針對(duì)從基礎(chǔ)設(shè)施傳輸?shù)牡貓D進(jìn)行,例如HD Maps。它與SLAM中的環(huán)路閉合高度相關(guān),盡管不只是考慮環(huán)路閉合問(wèn)題,而是考慮根據(jù)一個(gè)或多個(gè)預(yù)定義地圖定位車輛的更廣泛?jiǎn)栴}。
重組是將計(jì)算機(jī)視覺(jué)前三個(gè)組成部分的信息組合成統(tǒng)一表示的方法。在本文中,使用這個(gè)術(shù)語(yǔ)來(lái)等同于“后期融合”,這是自動(dòng)駕駛的重要步驟,因?yàn)檐囕v控制需要傳感器輸出的統(tǒng)一表示,這也允許在后期融合多個(gè)攝像頭的輸出。
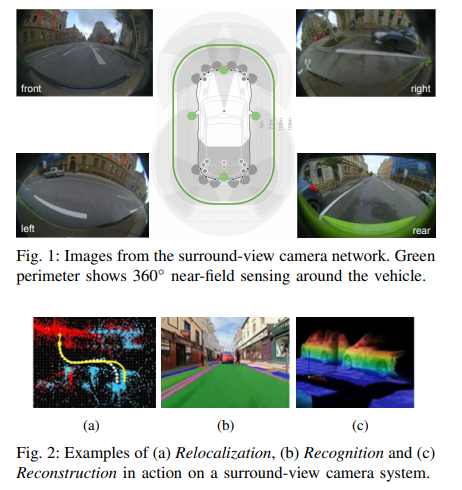
近域感知系統(tǒng)介紹
自動(dòng)停車系統(tǒng)
自動(dòng)停車系統(tǒng)是短距離傳感的主要用例之一,圖4描述了一些典型的停車用例。早期商業(yè)半自動(dòng)泊車系統(tǒng)采用超聲波傳感器或radar,然而,最近,全景攝像頭正成為自動(dòng)停車的主要傳感器之一。超聲波和毫米波雷達(dá)傳感器用于自動(dòng)停車的一個(gè)主要限制是,只能根據(jù)存在的其他障礙物來(lái)識(shí)別停車位(圖5)。此外,環(huán)視相機(jī)系統(tǒng)允許在存在可視停車標(biāo)記(如涂漆線標(biāo)記)的情況下停車,同時(shí)也被視為實(shí)現(xiàn)代客泊車系統(tǒng)的關(guān)鍵技術(shù)。
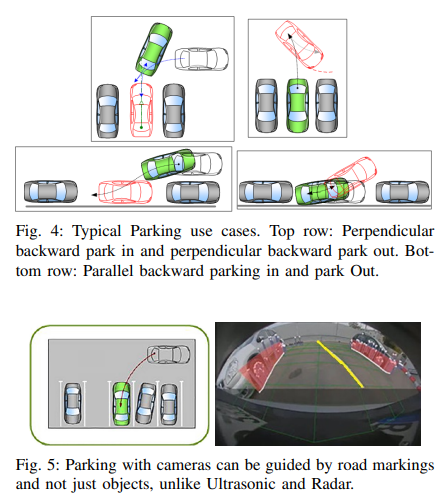
交通擁堵輔助系統(tǒng)
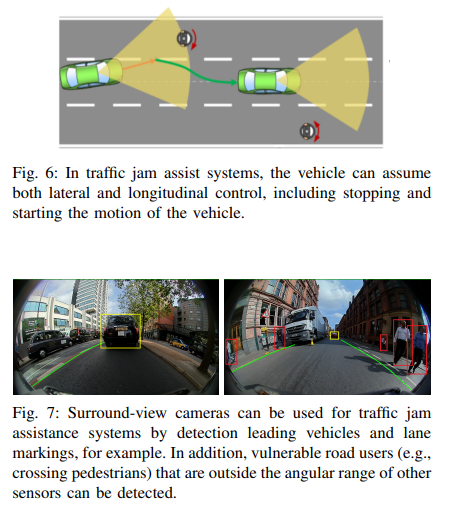
由于大部分事故都是低速追尾碰撞,交通擁堵情況被認(rèn)為是短期內(nèi)可以帶來(lái)好處的駕駛領(lǐng)域之一,盡管目前的系統(tǒng)可能缺乏魯棒性。在自動(dòng)交通擁堵輔助系統(tǒng)中,車輛在交通擁堵情況下控制縱向和橫向位置(圖6)。此功能通常用于低速環(huán)境,最高速度為~60kph,但建議更低的最高速度為40kph。
雖然交通擁堵援助通常考慮高速公路場(chǎng)景,但已經(jīng)對(duì)城市交通擁堵救援系統(tǒng)進(jìn)行了調(diào)查。鑒于此應(yīng)用的低速特性,全景攝像頭是理想的傳感器,尤其是在城市環(huán)境中,例如,行人可以嘗試從傳統(tǒng)前向攝像頭或radar系統(tǒng)視野之外的區(qū)域穿過(guò)。圖7顯示了使用全景相機(jī)進(jìn)行交通堵塞輔助的示例。除了檢測(cè)其他道路使用者和標(biāo)記外,深度估計(jì)和SLAM等特征對(duì)于推斷到物體的距離和控制車輛位置也很重要。
低速制動(dòng)
一項(xiàng)研究表明,自動(dòng)后向制動(dòng)顯著降低了碰撞索賠率,配備后攝像頭、駐車輔助和自動(dòng)制動(dòng)的車輛報(bào)告碰撞減少了78%。全景相機(jī)系統(tǒng)對(duì)于低速制動(dòng)非常有用,因?yàn)樯疃裙烙?jì)和目標(biāo)檢測(cè)的組合是實(shí)現(xiàn)此功能的基礎(chǔ)。
魚(yú)眼相機(jī)
魚(yú)眼相機(jī)為自動(dòng)駕駛應(yīng)用提供了明顯的優(yōu)勢(shì),由于視野極廣,可以用最少的傳感器觀察車輛的整個(gè)周圍。通常,360°范圍只需要四個(gè)攝像頭覆蓋。然而,考慮到更為復(fù)雜的投影幾何體,這一優(yōu)勢(shì)帶來(lái)了成本。過(guò)去的幾篇論文綜述了如何建模魚(yú)眼幾何形狀,例如[34]。論文不打算在此重復(fù)這一點(diǎn),而是關(guān)注魚(yú)眼相機(jī)技術(shù)的使用給自動(dòng)駕駛視覺(jué)帶來(lái)的問(wèn)題。
在標(biāo)準(zhǔn)視場(chǎng)相機(jī)中,直線投影和透視的原理非常接近,具有常見(jiàn)的透視特性,即現(xiàn)實(shí)世界中的直線在圖像平面上投影為直線。平行的直線組被投影為一組直線,這些直線在圖像平面上的一個(gè)消失點(diǎn)上會(huì)聚。通過(guò)光學(xué)畸變的偏離很容易糾正。許多汽車數(shù)據(jù)集提供的圖像數(shù)據(jù)消除了光學(xué)畸變,具有簡(jiǎn)單的校正方法,或幾乎不可察覺(jué)的光學(xué)畸變。
因此,大多數(shù)汽車視覺(jué)研究都隱含了直線投影的假設(shè),魚(yú)眼透視圖與直線透視圖有很大不同。相機(jī)場(chǎng)景中的一條直線被投影為魚(yú)眼圖像平面上的一條曲線,平行線集被投影為一組在兩個(gè)消失點(diǎn)處會(huì)聚的曲線[38]。然而,失真并不是唯一的影響,圖8顯示了環(huán)視系統(tǒng)中安裝在鏡子上的典型攝像頭的圖像。在
魚(yú)眼相機(jī)中,物體圖像中的方向取決于它們?cè)趫D像中的位置。在本例中,左側(cè)的車輛旋轉(zhuǎn)了近90? 與右側(cè)車輛相比,這對(duì)目標(biāo)檢測(cè)卷積方法中假定的平移不變性有影響。在標(biāo)準(zhǔn)相機(jī)中,平移不變性是可以接受的假設(shè)。然而,如圖8所示,魚(yú)眼圖像并非如此,在任何計(jì)算機(jī)視覺(jué)算法設(shè)計(jì)中,必須仔細(xì)考慮如何處理這一點(diǎn)。

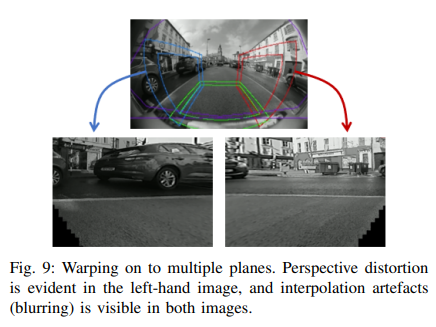
解決這些問(wèn)題的自然方法是以某種方式糾正圖像。可以立即放棄對(duì)單個(gè)平面圖像的校正,因?yàn)槭紫龋^(guò)多的視野必然會(huì)丟失,從而抵消魚(yú)眼圖像的優(yōu)勢(shì),其次,插值和透視偽影將很快占據(jù)校正輸出的主導(dǎo)地位。一種常見(jiàn)的方法是使用多平面校正,即魚(yú)眼圖像的不同部分被扭曲成不同的平面圖像。例如可以定義一個(gè)立方體,并將圖像扭曲到立方體的曲面上。圖9顯示了兩個(gè)此類表面上的翹曲。即使在這里,插值和透視效果也是可見(jiàn)的,必須處理曲面過(guò)渡的復(fù)雜性。
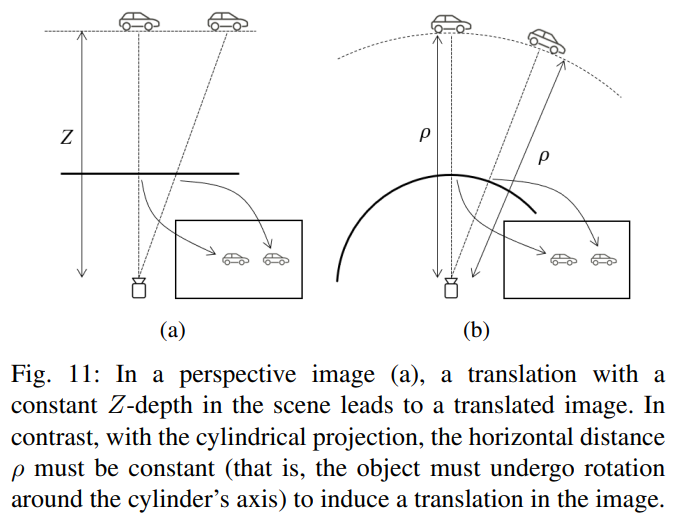
另一種校正方法是考慮圓柱表面的warping ,如圖10所示,在這種warping 中,圓柱軸線的配置使其垂直于地面。觀察結(jié)果表明,汽車場(chǎng)景中的大多數(shù)感興趣對(duì)象都位于近似水平的平面上,即路面上。因此希望保留水平視野,同時(shí)允許犧牲一些垂直視野,這帶來(lái)了有趣的幾何組合。

垂直是通過(guò)線性透視投影,因此場(chǎng)景中的垂直線在圖像中投影為垂直線。圖像中較遠(yuǎn)或較小的對(duì)象在視覺(jué)上類似于透視相機(jī),甚至有人建議,通過(guò)這種變形,可以使用標(biāo)準(zhǔn)透視相機(jī)訓(xùn)練網(wǎng)絡(luò),并在魚(yú)眼圖像上直接使用它們,而無(wú)需訓(xùn)練[39]。然而,在水平方向上,新圖像中存在失真,大型近景物體表現(xiàn)出強(qiáng)烈的失真,有時(shí)甚至比原始魚(yú)眼圖像中的失真還要大。
如圖11所示,當(dāng)我們處理透視相機(jī)時(shí),當(dāng)物體與相機(jī)以恒定的Z距離移動(dòng)時(shí),就會(huì)產(chǎn)生平移,也就是說(shuō),在與圖像平面平行的平面上。然而,在圓柱形圖像中,水平面上的距離必須保持不變,才能進(jìn)行圖像平移(對(duì)象必須繞圓柱體軸旋轉(zhuǎn))。相比之下,在原始魚(yú)眼圖像中,不清楚什么對(duì)象運(yùn)動(dòng)會(huì)導(dǎo)致圖像平移。
WoodScape dataset
WoodScape全景數(shù)據(jù)集在兩個(gè)不同的地理位置采集的:美國(guó)和歐洲。雖然大多數(shù)數(shù)據(jù)是從轎車中獲得的,但運(yùn)動(dòng)型多用途車中有很大一部分?jǐn)?shù)據(jù)可確保傳感器機(jī)械配置的強(qiáng)大組合,駕駛場(chǎng)景分為高速公路、城市駕駛和停車用例。數(shù)據(jù)集中為所有傳感器以及時(shí)間戳文件提供內(nèi)部和外部校準(zhǔn),以實(shí)現(xiàn)數(shù)據(jù)同步,包括相關(guān)車輛的機(jī)械數(shù)據(jù)(例如,車輪周長(zhǎng)、軸距)。為該數(shù)據(jù)集記錄的傳感器如下所示:
1)4x 1MPx RGB魚(yú)眼攝像頭(190? 水平視野)
2)1x激光雷達(dá),20Hz旋轉(zhuǎn)(Velodyne HDL-64E)
3)1x全球?qū)Ш叫l(wèi)星系統(tǒng)/慣性測(cè)量裝置(NovAtel Propak6和SPAN-IGM-A1)
4)1x帶SPS的GNSS定位(Garmin 18x)
5)來(lái)自車輛總線的里程表信號(hào)
系統(tǒng)架構(gòu)注意事項(xiàng)
在自動(dòng)駕駛計(jì)算機(jī)視覺(jué)設(shè)計(jì)中,尤其是pipelines設(shè)計(jì)中,一個(gè)重要的考慮因素是嵌入式系統(tǒng)的約束,其中多個(gè)攝像頭和多個(gè)計(jì)算機(jī)視覺(jué)算法必須并行運(yùn)行。由于計(jì)算機(jī)視覺(jué)算法是計(jì)算密集型的,汽車SoC有許多專用硬件加速器用于圖像信號(hào)處理、鏡頭畸變校正、密集光流、立體視差等。在計(jì)算機(jī)視覺(jué)中,深度學(xué)習(xí)在各種識(shí)別任務(wù)中發(fā)揮著主導(dǎo)作用,并逐漸用于幾何任務(wù),如深度和運(yùn)動(dòng)估計(jì)。
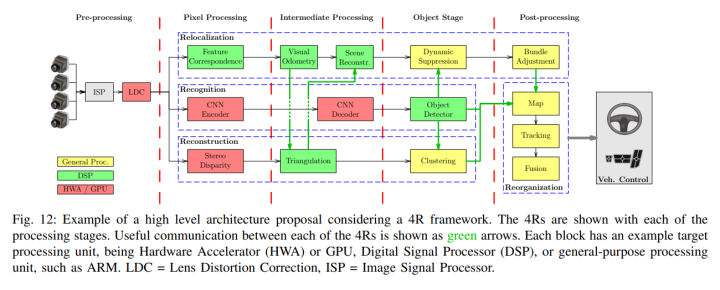
為了最大限度地提高處理硬件的性能,最好從處理階段的角度考慮嵌入式視覺(jué),并在每個(gè)處理階段考慮共享處理,pipelines如圖12所示。
1) 預(yù)處理:pipelines的預(yù)處理階段可以看作是為計(jì)算機(jī)視覺(jué)準(zhǔn)備數(shù)據(jù)的處理。這包括圖像信號(hào)處理(ISP)步驟,如白平衡、去噪、顏色校正和顏色空間轉(zhuǎn)換。關(guān)于ISP和ISP在汽車環(huán)境中用于計(jì)算機(jī)視覺(jué)任務(wù)的調(diào)整的詳細(xì)討論,請(qǐng)參考[52]。ISP通常由硬件引擎完成,例如作為主要SoC的一部分。很少在軟件中完成,因?yàn)樾枰瓿纱罅肯袼丶?jí)處理。正在提出一些方法來(lái)自動(dòng)將ISP管道的超參數(shù)調(diào)整為優(yōu)化計(jì)算機(jī)視覺(jué)算法的性能[52]、[53]。值得注意的是,目前正在提出簡(jiǎn)化ISP視覺(jué)感知pipelines的方法,可以參考[54]。
2) 像素處理階段:像素處理可以被視為計(jì)算機(jī)視覺(jué)體系結(jié)構(gòu)中直接接觸圖像的部分。在經(jīng)典的計(jì)算機(jī)視覺(jué)中,這些算法包括邊緣檢測(cè)、特征檢測(cè)、描述符、形態(tài)運(yùn)算、圖像配準(zhǔn)、立體視差等。在神經(jīng)網(wǎng)絡(luò)中,這等同于CNN編碼器的早期層。這一階段的處理主要由相對(duì)簡(jiǎn)單的算法控制,這些算法必須每秒多次在數(shù)百萬(wàn)像素上運(yùn)行。也就是說(shuō),計(jì)算成本與這些算法每秒可能運(yùn)行數(shù)百萬(wàn)次的事實(shí)有關(guān),而不是與算法本身的復(fù)雜性有關(guān)。這一階段的處理硬件通常由硬件加速器和GPU主導(dǎo),盡管有些元素可能適合DSP。
3) 中間處理階段:顧名思義,中間處理階段是從像素到對(duì)象檢測(cè)階段之間的橋梁。在這里,要處理的數(shù)據(jù)量仍然很高,但大大低于像素處理階段。這可能包括通過(guò)視覺(jué)里程表估計(jì)車輛運(yùn)動(dòng)、視差圖的立體三角測(cè)量和場(chǎng)景的一般特征重建等步驟,在pipelines的這個(gè)階段包括CNN解碼器。這個(gè)階段的處理硬件通常是數(shù)字信號(hào)處理器。
4) 目標(biāo)處理階段:對(duì)象處理階段是整合更高層次推理的階段,在這里可以聚類點(diǎn)云來(lái)創(chuàng)建目標(biāo),對(duì)對(duì)象進(jìn)行分類,并且通過(guò)上述推理,可以應(yīng)用算法來(lái)抑制移動(dòng)目標(biāo)的重縮放。此階段的處理主要由更復(fù)雜的算法控制,但操作的數(shù)據(jù)點(diǎn)較少。就硬件而言,通常適合在ARM等通用處理單元上運(yùn)行這些處理器,盡管通常也會(huì)使用數(shù)字信號(hào)處理器。
5) 后處理:最后后處理階段,也可以稱為全局處理階段。在時(shí)間和空間上持久化數(shù)據(jù)。由于可以擁有長(zhǎng)時(shí)間持久性和大空間地圖,因此前幾個(gè)階段的總體目標(biāo)是最小化到達(dá)此階段的數(shù)據(jù)量,同時(shí)維護(hù)最終用于車輛控制的所有相關(guān)信息。在此階段,將包括 bundle adjustment、地圖構(gòu)建、高級(jí)目標(biāo)跟蹤和預(yù)測(cè)以及各種計(jì)算機(jī)視覺(jué)輸入的融合等步驟。由于處理的是系統(tǒng)中最高級(jí)別的推理,并且理想情況下處理的是最少的數(shù)據(jù)點(diǎn),因此這里通常需要通用處理單元。
4R部件介紹
識(shí)別
識(shí)別任務(wù)通過(guò)模式識(shí)別識(shí)別場(chǎng)景的語(yǔ)義。在汽車領(lǐng)域,第一個(gè)成功的應(yīng)用是行人檢測(cè),它結(jié)合了手工設(shè)計(jì)的特征,如定向梯度直方圖和機(jī)器學(xué)習(xí)分類器,如支持向量機(jī)。最近CNN在目標(biāo)識(shí)別應(yīng)用程序中的各種計(jì)算機(jī)視覺(jué)任務(wù)中表現(xiàn)出顯著的性能飛躍,然而,這是有代價(jià)的。
首先,汽車場(chǎng)景非常多樣化,預(yù)計(jì)該系統(tǒng)將在不同國(guó)家以及不同的天氣和照明條件下工作,因此,主要挑戰(zhàn)之一是建立一個(gè)涵蓋不同方面的有效數(shù)據(jù)集。其次,CNN是計(jì)算密集型的,通常需要專用硬件加速器或GPU(與在通用計(jì)算核心上可行的經(jīng)典機(jī)器學(xué)習(xí)方法相比)。因此,有效的設(shè)計(jì)技術(shù)對(duì)于任何設(shè)計(jì)都至關(guān)重要,最后,雖然對(duì)正常圖像的CNN進(jìn)行了很好的研究,但如前所述,魚(yú)眼圖像的平移不變性假設(shè)被打破,這帶來(lái)了額外的挑戰(zhàn)。
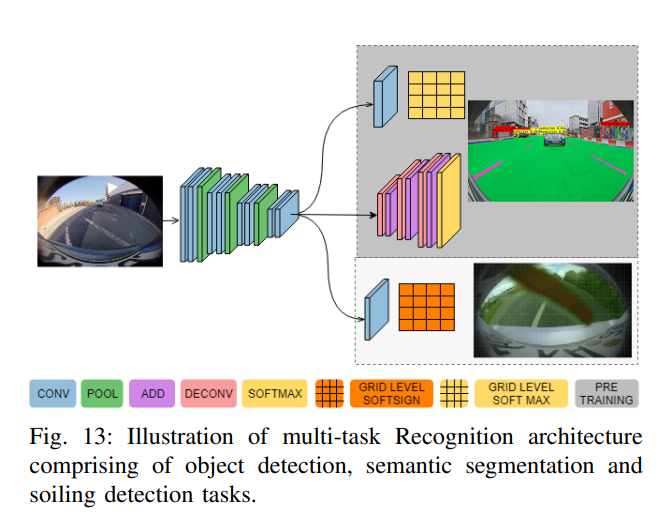
本文的識(shí)別pipelines中,提出了一種基于外觀模式識(shí)別對(duì)象的多任務(wù)深度學(xué)習(xí)網(wǎng)絡(luò)。它包括三個(gè)任務(wù),即目標(biāo)檢測(cè)(行人、車輛和騎車人)、語(yǔ)義分割(道路、路緣和道路標(biāo)記)和透鏡污染檢測(cè)(不透明、半透明、透明、透明)。目標(biāo)檢測(cè)和語(yǔ)義分割是標(biāo)準(zhǔn)任務(wù),有關(guān)更多實(shí)現(xiàn)細(xì)節(jié),請(qǐng)參閱FisheyeMultiNet論文。其中一個(gè)挑戰(zhàn)是在訓(xùn)練階段平衡三個(gè)任務(wù)的權(quán)重,因?yàn)橐粋€(gè)任務(wù)可能比其他任務(wù)收斂得更快。
魚(yú)眼攝像頭安裝在車輛上相對(duì)較低的位置(~地面以上0.5至1.2米),容易因其它車輛的道路噴霧或道路水而導(dǎo)致透鏡臟污。因此,檢測(cè)攝像頭上的污物至關(guān)重要 鏡頭提醒駕駛員清潔攝像頭或觸發(fā)清潔系統(tǒng)。SoilingNet中詳細(xì)討論了污垢檢測(cè)任務(wù)及其在清潔和算法降級(jí)中的使用,與此密切相關(guān)的一項(xiàng)任務(wù)是通過(guò)修補(bǔ)修復(fù)受污染區(qū)域的去污,但這些去污技術(shù)目前仍屬于可視化改進(jìn)領(lǐng)域,而不是用于感知。
這是一個(gè)定義不清的問(wèn)題,因?yàn)椴豢赡茴A(yù)測(cè)遮擋的背后(盡管這可以通過(guò)利用時(shí)間信息來(lái)改善)。由于低功耗汽車ECU的CNN處理能力有限,本文使用多任務(wù)架構(gòu),其中大部分計(jì)算在編碼器中共享,如圖13所示。
重建
如前所述,重建意味著從視頻序列推斷場(chǎng)景幾何體。例如,這通常意味著估算場(chǎng)景的點(diǎn)云或體素化表示。靜態(tài)對(duì)象的重建,傳統(tǒng)上是使用諸如運(yùn)動(dòng)立體[56]或多視圖幾何中的三角剖分[73]等方法來(lái)完成的。在設(shè)計(jì)深度估計(jì)算法的背景下,[74]中簡(jiǎn)要概述了人類如何推斷深度,并提供了有用的進(jìn)一步參考。推斷深度有四種基本方法:?jiǎn)文恳曈X(jué)線索、運(yùn)動(dòng)視差、立體視覺(jué)和focus深度。
每種方法在計(jì)算機(jī)視覺(jué)方面都有其等效性,根據(jù)Marr&Poggio早期的理論工作[75],Grimson在20世紀(jì)80年代早期提供了立體視覺(jué)的計(jì)算實(shí)現(xiàn)[76],自那時(shí)以來(lái)立體視覺(jué)方面的工作一直在繼續(xù)。然而,立體視覺(jué)系統(tǒng)并沒(méi)有普遍在車輛上實(shí)現(xiàn)部署,因此,單目運(yùn)動(dòng)視差方法在汽車研究中仍然很流行。從計(jì)算上看,運(yùn)動(dòng)視差的深度傳統(tǒng)上是通過(guò)特征三角剖分完成的[78],但運(yùn)動(dòng)立體也被證明很流行[79]。
考慮魚(yú)眼圖像會(huì)增加重建任務(wù)的復(fù)雜性,多視圖幾何、立體視覺(jué)和深度估計(jì)中的大多數(shù)工作通常假設(shè)場(chǎng)景的平面透視圖像。傳統(tǒng)的立體方法進(jìn)一步限制了圖像中的極線必須是水平的,然而,真實(shí)相機(jī)很少出現(xiàn)這種情況,因?yàn)榇嬖阽R頭畸變,從而破壞了平面投影模型。它通常通過(guò)圖像的校準(zhǔn)和校正來(lái)解決。然而,對(duì)于鏡頭畸變非常嚴(yán)重的魚(yú)眼圖像,在校正過(guò)程中保持寬視場(chǎng)是不可行的。領(lǐng)域已經(jīng)提出了幾種魚(yú)眼立體深度估計(jì)方法,常見(jiàn)的方法是多平面校正,其中魚(yú)眼圖像映射到多個(gè)透視平面[82]。
然而,如前所述,任何平面校正(即使有多個(gè)平面)都會(huì)遭受嚴(yán)重的重采樣失真。要最小化此重采樣提出了對(duì)非平面圖像進(jìn)行畸變、校正的方法,有些方法會(huì)扭曲不同的圖像幾何形狀,以保持極線筆直和水平的立體要求[83]。還有一些方法繞過(guò)了極線水平的要求,例如,最近將平面掃描法[84]、[85]應(yīng)用于魚(yú)眼[86]。魚(yú)眼圖像重采樣的一個(gè)相關(guān)問(wèn)題是,噪聲函數(shù)被重采樣過(guò)程扭曲,這對(duì)于任何試圖最小化重投影誤差的方法來(lái)說(shuō)都是一個(gè)問(wèn)題。Kukelova等人[73]使用標(biāo)準(zhǔn)視場(chǎng)相機(jī)的迭代技術(shù)解決了這一問(wèn)題,該技術(shù)在避免失真的同時(shí)最小化了重投影誤差。然而,這種方法取決于特定的相機(jī)型號(hào),因此不直接適用于魚(yú)眼相機(jī)。
重建的第二個(gè)方面是從視頻序列中提取運(yùn)動(dòng)對(duì)象(運(yùn)動(dòng)分割)。由于三角剖分假設(shè)被打破,動(dòng)態(tài)對(duì)象的三維重建會(huì)導(dǎo)致全局意義上的位置不精確。重建運(yùn)動(dòng)物體幾何結(jié)構(gòu)的典型嘗試需要圖像運(yùn)動(dòng)分割、相對(duì)基本矩陣估計(jì)和重建(具有比例/投影模糊性)。例如,使用Multi-X[88],前兩步基本上可以結(jié)合起來(lái),因?yàn)榉指羁梢曰诨揪仃嚬烙?jì)進(jìn)行。然而,對(duì)于嵌入式自動(dòng)駕駛應(yīng)用來(lái)說(shuō),這種方法要么計(jì)算成本太高,要么不夠健壯。此外,這種重建必須解決比例問(wèn)題,可變形物體(如行人)可以針對(duì)身體的不同部位使用不同的基本矩陣。因此,動(dòng)態(tài)目標(biāo)檢測(cè)的任務(wù)通常只是簡(jiǎn)單的運(yùn)動(dòng)分割。
Klappstein等人[89]描述了汽車背景下運(yùn)動(dòng)分割的幾何方法,Mariotti和Hughes[90]將這項(xiàng)工作擴(kuò)展到了環(huán)視攝像頭外殼。然而,在這兩種情況下,幾何圖形都無(wú)法完全區(qū)分所有類型的移動(dòng)特征。也就是說(shuō),有一類對(duì)象運(yùn)動(dòng)使關(guān)聯(lián)特征與靜態(tài)特征無(wú)法區(qū)分,因此,必須采取全局或半全局辦法。在傳統(tǒng)方法中,這是通過(guò)將具有與被歸類為運(yùn)動(dòng)中的光流矢量相似特性的光流向量分組來(lái)實(shí)現(xiàn)的。
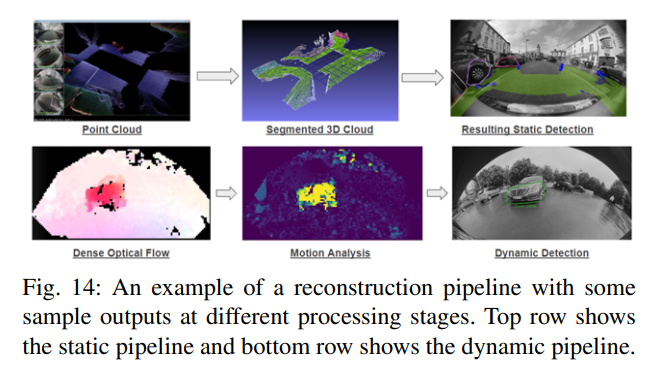
通常,運(yùn)動(dòng)分割的關(guān)鍵輸入是攝像機(jī)運(yùn)動(dòng)的知識(shí)。也就是說(shuō),必須知道相機(jī)的基本矩陣(或未校準(zhǔn)情況下的基本矩陣)。[89]和[90]中假設(shè)了這一點(diǎn),可以通過(guò)兩種方式實(shí)現(xiàn)。首先,可以直接使用車輛網(wǎng)絡(luò)上的信號(hào),例如轉(zhuǎn)向角和車輪速度,來(lái)估計(jì)車輛的運(yùn)動(dòng),從而估計(jì)攝像機(jī)的運(yùn)動(dòng)。或者,可以使用視覺(jué)方法直接從圖像序列估計(jì)運(yùn)動(dòng)。除了明確估計(jì)相機(jī)的運(yùn)動(dòng)外,另一種方法是在圖像中建模背景運(yùn)動(dòng)。有人建議使用背景運(yùn)動(dòng)的仿射模型,然而,這假設(shè)背景是遙遠(yuǎn)或近似的平面,徑向變形不存在或可忽略不計(jì)。圖14顯示了不同重建階段的示例,包括密集運(yùn)動(dòng)立體、3D點(diǎn)云和靜態(tài)障礙物集群,以及基于密集光流的運(yùn)動(dòng)分割。雖然魚(yú)眼圖像的使用肯定會(huì)影響設(shè)計(jì)決策,從理論角度來(lái)看,這是一個(gè)尚未完全解決的問(wèn)題。
重定位
視覺(jué)同步定位與映射(VSLAM)是機(jī)器人技術(shù)和自動(dòng)駕駛領(lǐng)域的一個(gè)研究熱點(diǎn)。主要有三種方法,即(1)基于特征的方法,(2)直接SLAM方法和(3)CNN方法。基于特征的方法利用描述性圖像特征進(jìn)行跟蹤和深度估計(jì),從而生成稀疏的地圖。MonoSLAM、Parallel Tracking and Mapping(PTAM)和ORBSLAM是這類算法中的開(kāi)創(chuàng)性算法。直接SLAM方法適用于整個(gè)圖像,而不是稀疏特征,以幫助構(gòu)建密集的地圖。密集跟蹤和映射(DTAM)和大規(guī)模半密集SLAM(LSD-SLAM)是基于光度誤差最小化的常用直接方法。對(duì)于Visual SLAM問(wèn)題,基于CNN的方法相對(duì)不太成熟,在[101]中對(duì)此進(jìn)行了詳細(xì)討論。
mapping是自動(dòng)駕駛的關(guān)鍵支柱之一,許多首次成功的自動(dòng)駕駛演示(如谷歌)主要依賴于對(duì)預(yù)先繪制區(qū)域的定位。TomTom RoadDNA等高清地圖為大多數(shù)歐洲城市提供了高度密集的語(yǔ)義3D點(diǎn)云地圖和定位服務(wù),典型的定位精度為10 cm。當(dāng)有準(zhǔn)確的定位時(shí),高清地圖可以被視為主要線索,因?yàn)橐呀?jīng)有了強(qiáng)大的先驗(yàn)語(yǔ)義分割,并且可以通過(guò)在線分割算法進(jìn)行細(xì)化。然而,這項(xiàng)服務(wù)很昂貴,因?yàn)樗枰澜绺鞯氐亩ㄆ诰S護(hù)和升級(jí)。
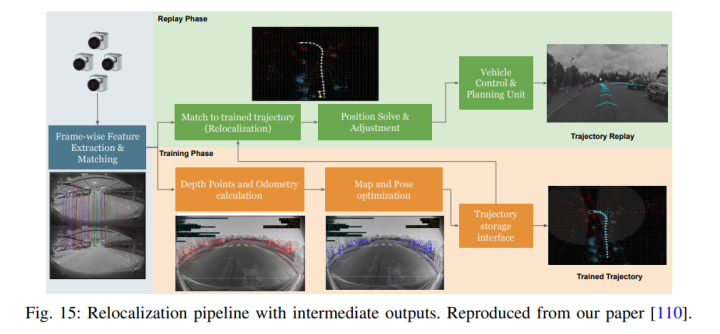
在自動(dòng)駕駛視覺(jué)環(huán)境中,視覺(jué)SLAM(VSLAM)包括繪制車輛周圍環(huán)境的地圖,同時(shí)在地圖中估計(jì)車輛的當(dāng)前姿態(tài)。VSLAM的關(guān)鍵任務(wù)之一是根據(jù)之前記錄的車輛定位軌跡。圖15顯示了一個(gè)經(jīng)典的基于特征的重定位pipelines。在基于特征的SLAM中,第一步是提取顯著特征。圖像中的一個(gè)顯著特征可能是像素區(qū)域,其中強(qiáng)度以特定方式變化,例如邊緣、角落或斑點(diǎn)。
要估計(jì)世界上的地標(biāo),需要執(zhí)行跟蹤,其中可以匹配相同特征的兩個(gè)或多個(gè)視圖。一旦車輛移動(dòng)足夠遠(yuǎn),VSLAM會(huì)拍攝另一張圖像并提取特征。重建相應(yīng)的特征,以獲得它們?cè)谡鎸?shí)世界中的坐標(biāo)和姿態(tài)。然后,這些檢測(cè)到的、描述的和定位的地標(biāo)被存儲(chǔ)在永久存儲(chǔ)器中,以描述車輛軌跡的相對(duì)位置。如果車輛返回相同的一般位置,實(shí)時(shí)特征檢測(cè)將與存儲(chǔ)的地標(biāo)匹配,以恢復(fù)車輛相對(duì)于存儲(chǔ)軌跡的姿態(tài)。
重組
重組執(zhí)行三個(gè)功能:1)融合識(shí)別和重建,2)通過(guò)相機(jī)在世界坐標(biāo)系統(tǒng)中繪制目標(biāo)地圖,3)時(shí)空物體跟蹤。雖然識(shí)別和重組模塊可以直接輸入到環(huán)境圖中,但我們認(rèn)為在視覺(jué)層實(shí)現(xiàn)某些融合有明顯的優(yōu)勢(shì)。先用一個(gè)例子來(lái)考慮這一點(diǎn),如圖16所示,假設(shè)有一個(gè)具有單目深度估計(jì)、運(yùn)動(dòng)分割和車輛檢測(cè)的系統(tǒng)。融合這些信息的經(jīng)典方法是將所有數(shù)據(jù)轉(zhuǎn)換為世界坐標(biāo)系,然后關(guān)聯(lián)和融合數(shù)據(jù),這種方法具有優(yōu)勢(shì)。
一些汽車傳感器,如激光雷達(dá),提供本地歐幾里德數(shù)據(jù),基于這種歐幾里得地圖的融合系統(tǒng)使得包含這些附加傳感器變得容易。然而,在轉(zhuǎn)換為歐氏圖時(shí),基于相機(jī)的檢測(cè)精度將始終受到影響。眾所周知,從圖像域到世界域的投影容易出錯(cuò),因?yàn)樗鼈儠?huì)受到校準(zhǔn)不良、平地假設(shè)、檢測(cè)變化、像素密度和不完美相機(jī)模型的影響。如果目標(biāo)在感興趣的點(diǎn)上沒(méi)有實(shí)際接觸地面,那么對(duì)于投影到世界坐標(biāo)系的平地假設(shè)將存在重大錯(cuò)誤。

然而,在向世界投影之前,圖像域中的檢測(cè)不受此類錯(cuò)誤的影響,因此,圖像域不同視覺(jué)算法的檢測(cè)關(guān)聯(lián)更為穩(wěn)健,事實(shí)上,簡(jiǎn)單的檢測(cè)重疊措施通常證明是穩(wěn)健的。圖18顯示了基于CNN的車輛檢測(cè)和基于光流的運(yùn)動(dòng)分割的基于圖像的融合的實(shí)現(xiàn),盡管運(yùn)動(dòng)分割存在顯著誤差,但融合成功地將檢測(cè)到的目標(biāo)分為車輛和動(dòng)態(tài)兩類。除此之外,還必須考慮失真校正如何影響測(cè)量噪聲,許多常用的融合和跟蹤算法,如卡爾曼濾波或粒子濾波,都是從平均零假設(shè)開(kāi)始的(高斯噪聲)。
對(duì)于計(jì)算機(jī)視覺(jué)中的感興趣點(diǎn)測(cè)量(例如,圖像特征或邊界框足跡估計(jì)),通常認(rèn)為這是一個(gè)有效的假設(shè)。然而,魚(yú)眼畸變和地平面投影過(guò)程扭曲了該噪聲模型(圖19)。此外,由于測(cè)量噪聲的失真取決于圖像中感興趣點(diǎn)的位置以及相機(jī)相對(duì)于路面的位置,因此解決這一問(wèn)題變得更加復(fù)雜。

系統(tǒng)同步協(xié)同
本節(jié)將討論系統(tǒng)協(xié)同效應(yīng),主要研究重定位、重建和識(shí)別任務(wù)如何相互支持,并描述雙檢測(cè)源在安全關(guān)鍵應(yīng)用中提供冗余的重要性。
識(shí)別和重建
如前所述,深度估計(jì)在幾何感知應(yīng)用中非常重要。除了前面已經(jīng)討論過(guò)的內(nèi)容外,目前最先進(jìn)的是基于神經(jīng)網(wǎng)絡(luò)的方法[115]、[116],可以通過(guò)重投影損失以自我監(jiān)督的方式學(xué)習(xí)[117]。研究表明,單目深度估計(jì)的最新單幀嘗試通常會(huì)引發(fā)識(shí)別任務(wù),然后使用圖像中的垂直位置等線索推斷深度,運(yùn)動(dòng)目標(biāo)檢測(cè)似乎也嚴(yán)重依賴于識(shí)別。事實(shí)證明,[48]和[58]都對(duì)通常移動(dòng)的靜態(tài)物體(例如行人,見(jiàn)圖20)顯示出誤報(bào),但這并沒(méi)有降低這種嘗試的重要性。相反,它指出了識(shí)別和重建之間的一種非常深刻的聯(lián)系,從一種聯(lián)系中,可以推斷出另一種。

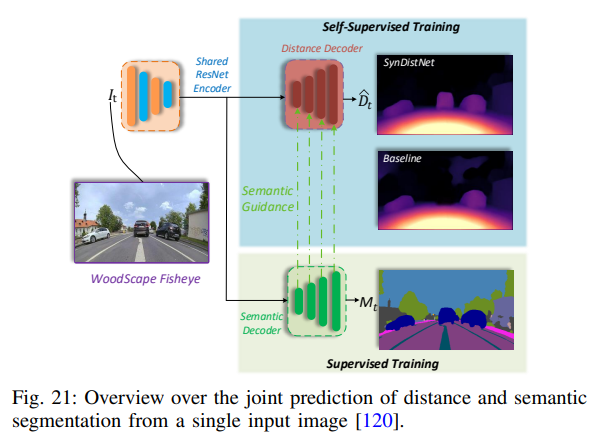
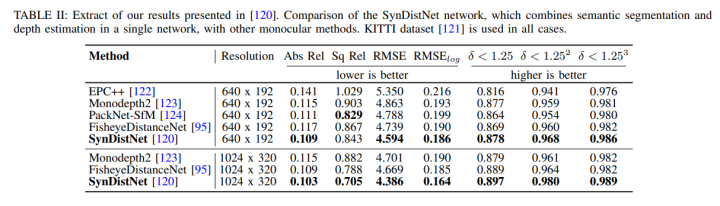
當(dāng)行人檢測(cè)處于最先進(jìn)水平時(shí),在語(yǔ)義和實(shí)例分割之前,大多數(shù)汽車行人檢測(cè)研究人員都會(huì)考慮根據(jù)邊界框的高度或行人在圖像中的垂直位置編碼深度。[81]對(duì)此進(jìn)行了詳細(xì)討論。然而,基于深度神經(jīng)網(wǎng)絡(luò)的識(shí)別可以產(chǎn)生物體深度,這是有點(diǎn)直觀的,特別是當(dāng)神經(jīng)網(wǎng)絡(luò)的精度提高時(shí)。最近的工作證明了聯(lián)合學(xué)習(xí)語(yǔ)義標(biāo)簽和深度的有效性[119]。例如,在[120]中顯示,對(duì)于單目深度估計(jì),在每個(gè)距離解碼器層中添加語(yǔ)義指導(dǎo)(如圖21所示)可以提高對(duì)象邊緣的性能,甚至可以為動(dòng)態(tài)目標(biāo)返回合理的距離估計(jì)。
重定位和識(shí)別
重定位是車輛識(shí)別先前學(xué)習(xí)的位置或路徑的過(guò)程,如前所述。然而,在現(xiàn)實(shí)的自動(dòng)駕駛視覺(jué)中,很多事情都會(huì)干擾這一點(diǎn)。例如,場(chǎng)景可能會(huì)因可移動(dòng)對(duì)象而改變,例如,停放的車輛可能會(huì)在場(chǎng)景學(xué)習(xí)時(shí)間和請(qǐng)求重定位時(shí)間之間移動(dòng)。在這種情況下,語(yǔ)義分割方法可用于識(shí)別可能移動(dòng)的對(duì)象(車輛、自行車、行人),并刪除與此類對(duì)象相關(guān)的映射特征。如[101]中詳細(xì)描述的,利用深度學(xué)習(xí)技術(shù)支持傳統(tǒng)的Visual SLAM pipelines還有更多的機(jī)會(huì)(圖22)。
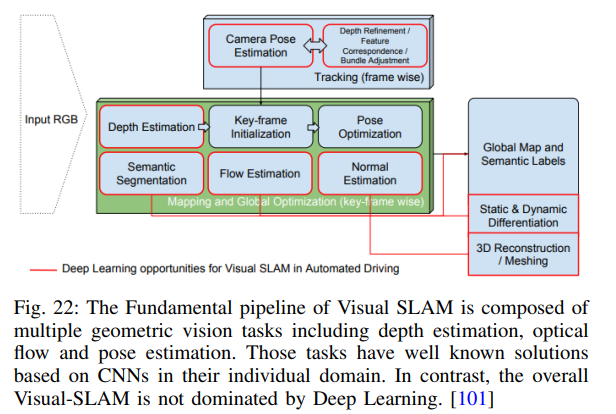
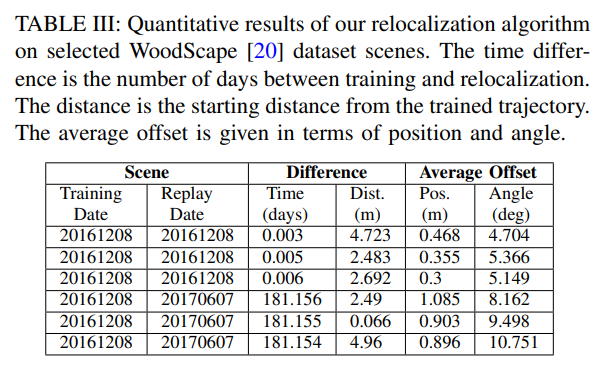
Visual SLAM中的地點(diǎn)識(shí)別有幾個(gè)應(yīng)用程序。首先,它允許循環(huán)閉合以糾正累積漂移,其次,它允許從同一場(chǎng)景的多個(gè)過(guò)程中創(chuàng)建和維護(hù)地圖。使用單詞袋的經(jīng)典方法(如[128])被證明是相當(dāng)成功的,盡管可能缺乏穩(wěn)健性。基于CNN的方法被證明更為穩(wěn)健,外觀不變的方法顯示出有希望的初步結(jié)果[129]。當(dāng)重要的時(shí)間過(guò)去時(shí),對(duì)地點(diǎn)的識(shí)別是一個(gè)重要的話題。表III顯示了Visual SLAM pipelines的一小組結(jié)果,并表明隨著訓(xùn)練和重定位之間的六個(gè)月時(shí)間差的增加,錯(cuò)誤顯著增加。最后,可以考慮視圖不變的定位。當(dāng)重定位的camera視點(diǎn)與訓(xùn)練時(shí)的camera視角顯著不同時(shí),這一點(diǎn)很重要,例如,由于以大角度接近訓(xùn)練軌跡而導(dǎo)致車輛旋轉(zhuǎn),基于特征描述符的傳統(tǒng)Visual SLAM方法失敗了。研究表明,將語(yǔ)義標(biāo)簽附加到場(chǎng)景地標(biāo)(通過(guò)bounding box分類)可以顯著提高視點(diǎn)不變性的性能。
重定位和重建
重定位和視覺(jué)SLAM通常可以被視為場(chǎng)景重建(即構(gòu)建地圖)的存儲(chǔ),以及通過(guò)bundle adjustment調(diào)整對(duì)所述地圖的迭代細(xì)化(見(jiàn)圖15)。這樣,重建和視覺(jué)里程表就成為傳統(tǒng)Visual SLAM方法的種子。有一些直接的方法可以繞過(guò)這種seed方法,例如LSD-SLAM(及其全向相機(jī)擴(kuò)展[100]),其中光度誤差相對(duì)于重投影誤差被最小化。然而,如果考慮bundle adjustment調(diào)整地圖的時(shí)間切片,也可以看出,Visual SLAM可用于優(yōu)化重建(場(chǎng)景結(jié)構(gòu)和視覺(jué)里程計(jì))。此外,移動(dòng)目標(biāo)會(huì)導(dǎo)致任何Visual SLAM管道的性能顯著下降。因此,動(dòng)態(tài)對(duì)象檢測(cè)(例如[90]、[48]、[58])可以用作Visual SLAM pipelines的輸入,以抑制所述移動(dòng)目標(biāo)引起的異常值。
討論下冗余
還有另一個(gè)首要的協(xié)同考慮:冗余。在自動(dòng)化車輛中,冗余對(duì)應(yīng)用程序的安全性起著重要作用。當(dāng)系統(tǒng)部件發(fā)生故障時(shí),必須提供另一個(gè)部件,以確保車輛保持安全狀態(tài)。例如,F(xiàn)useModNet展示了提供密集信息的相機(jī)與在弱光下表現(xiàn)良好的激光雷達(dá)的協(xié)同融合。在傳感方面,這通常是通過(guò)使用多種傳感器類型來(lái)實(shí)現(xiàn)的,例如計(jì)算機(jī)視覺(jué)系統(tǒng)、radar和激光雷達(dá)。對(duì)于近場(chǎng)傳感,超聲波傳感器陣列是一種成熟的低成本傳感器,可在車輛周圍提供強(qiáng)大的安全性。
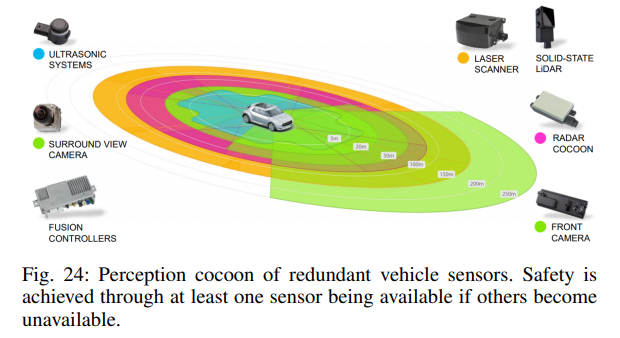
論文認(rèn)為,通過(guò)并行使用不同的計(jì)算機(jī)視覺(jué)算法類型,可以實(shí)現(xiàn)更高的安全性。也就是說(shuō),可以配置計(jì)算機(jī)視覺(jué)系統(tǒng)架構(gòu)以最大限度地提高冗余度。這一點(diǎn)尤其正確,因?yàn)閿?shù)據(jù)源是完全不同的處理類型。例如,識(shí)別pipelines的統(tǒng)計(jì)處理和重建管道的幾何pipelines。此外,這種處理通常會(huì)在SoC內(nèi)的不同硅組件上運(yùn)行。然而,必須意識(shí)到,如果你最大限度地發(fā)揮其他協(xié)同作用,冗余的可能性就會(huì)降低。例如,如果使用基于CNN的深度作為Visual SLAM算法的種子,則不能將CNN聲明為Visual SLAM的冗余,因?yàn)閂isual SLAM現(xiàn)在依賴于CNN處理。還必須注意,這兩個(gè)處理元件可能使用相同的視頻饋送,因此相機(jī)本身和相關(guān)硬件/軟件的安全性也可能是一個(gè)限制因素。
審核編輯:劉清












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論