 電子發(fā)燒友App
電子發(fā)燒友App


一、背景介紹
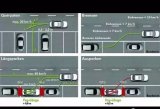
自動泊車大體可分為4個等級:
第1級,APA 自動泊車:駕駛員在車內(nèi),隨時準(zhǔn)備制動,分為雷達(dá)感知和雷達(dá)+視覺感知兩種方式。
第2級,RPA 遠(yuǎn)程泊車:駕駛員在車外,通過手機(jī)APP的方式控制泊車。
第3級,HPA 記憶泊車:泊車之前先通過 SLAM對場景建模,記憶常用的路線。泊車時,從固定的起點(diǎn)出發(fā),車輛自行泊入記憶的停車位。
第4級,AVP 自主泊車:泊車之前先通過 SLAM對場景建模,記憶常用的路線。泊車的起點(diǎn)不再固定,可以在停車場的任意位置開始,需要室內(nèi)定位技術(shù)做支撐。
1.1 自動泊車
圖2 自動泊車
自動泊車,在21世紀(jì)20年代的今天,是智能出行、輔助駕駛的強(qiáng)有力的一環(huán)。自動泊車就魯棒性和安全性而言,需要分為視覺和測距同時發(fā)生作用。其中視覺當(dāng)然是用深度學(xué)習(xí),而測距一般采用雷達(dá)。視覺在尋找車位階段作為主力,而倒車入庫時,測距(雷達(dá))發(fā)生作用。
1.2 車位檢測
車位檢測的場景一般在車庫、戶外,而自動泊車這一應(yīng)用在都市商場車庫和都市戶外車位實(shí)用性比較高,這樣可節(jié)省時間方便出行。車位檢測需要汽車進(jìn)入到有車位的區(qū)域后,汽車慢速行駛的過程中,開始檢測。
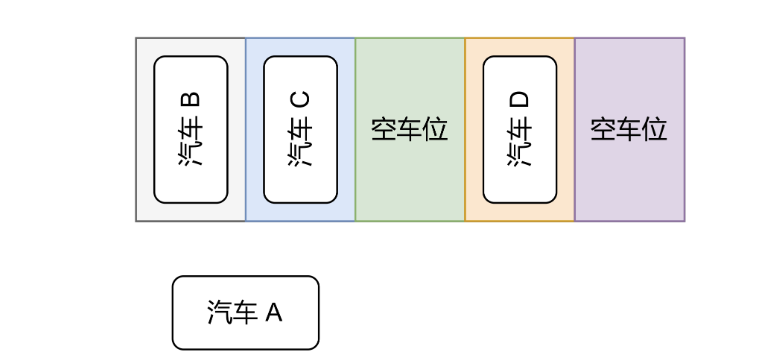
圖3 檢測可以停車的車位
1.3 魚眼相機(jī)
車身周圍一般有4路魚眼相機(jī):前、后、左、右共四個。用來拍攝車周圍的畫面。如下圖所示為車右邊的魚眼相機(jī)拍攝的畫面。魚眼相機(jī)拍攝的圖一般不用來做車位檢測,但可以用來后續(xù)做障礙物檢測。
1.4 AVM
4幅魚眼相機(jī)拍攝的畫面會經(jīng)過Around View Monitor(AVM)處理,生成一個拼接后的鳥瞰圖,車位檢測就是在AVM處理后的照片上進(jìn)行的。4幅畸變的圖,先要去畸變再做融合,這里是一塊相當(dāng)有意思的部分,甚至我覺得上限遠(yuǎn)高于車位檢測,車位檢測的質(zhì)量也由上游的AVM決定,可謂自動泊車中得AVM者得天下。另外,有效的做法可以采取在4幅拍攝的畫面去畸變后,單獨(dú)采用4幅獨(dú)立的圖送入車位檢測網(wǎng)絡(luò)中進(jìn)行處理,而不是一張整個大圖。如下的鳥瞰圖的寬長是經(jīng)過我們實(shí)際工程處理中,采取的寬高像素比例,大小需要根據(jù)硬件條件和實(shí)際夠用范圍進(jìn)行調(diào)整。
1.5 工程化
車位檢測算法搭出來以后,工程化的道路才剛剛開始,好戲還在后面,需要團(tuán)隊(duì)配合了。本文就不涉及這一范疇了。
二、車位檢測算法的相關(guān)工作
車位檢測算法,從21世紀(jì)開始說起,那一定是由傳統(tǒng)的視覺過渡到深度視覺。
2.1 傳統(tǒng)視覺的車位檢測
傳統(tǒng)視覺的介紹,這里用一些示意圖來展示:
圖7 車位檢測傳統(tǒng)視覺方法示例1,2000年,Vision-Guided Automatic Parking for Smart Car

圖7 車位檢測傳統(tǒng)視覺方法示例2,2006年,Parking Slot Markings Recognition for Automatic Parking Assist System
en.. 如上兩圖所示,利用一些算子和圖像處理的手段,先提特征,再后處理。接下來,再介紹一個比較復(fù)雜,但是比較典型的方法(2012年的):Fully-automatic recognition of various parking slot markings in Around View Monitor (AVM) image sequences 利用AVM圖,它是先檢測車位角點(diǎn),再后處理配對,一些過濾和糾正操作,最終從圖中抓出車位。圖如下:
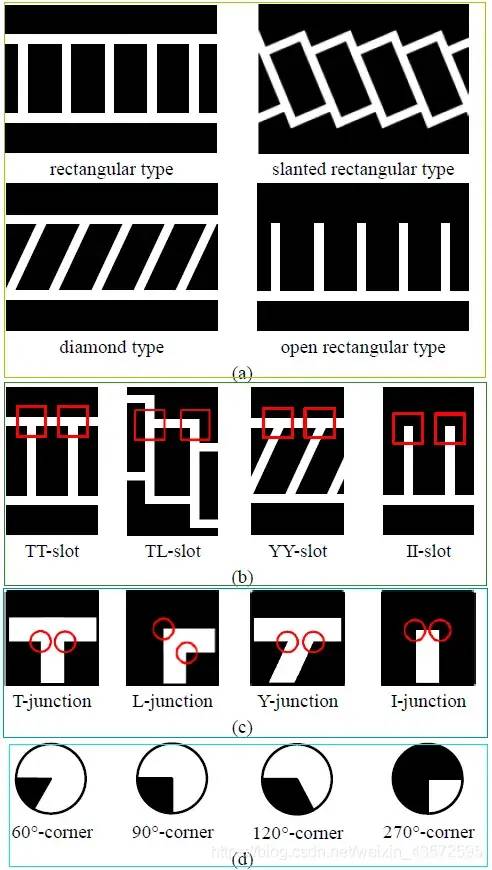
圖8 車位類型對應(yīng)的不同角點(diǎn)類型
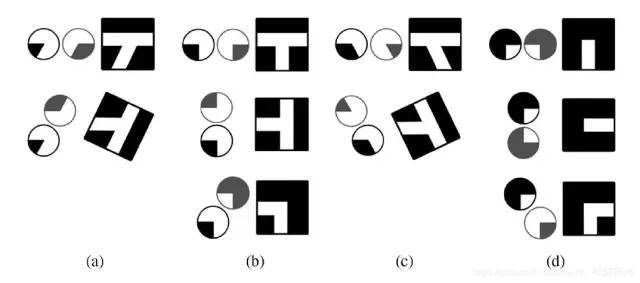
圖9 角點(diǎn)類型。多吧,不多,還有更多的... 這是模板匹配的難以窮盡之處

圖10 后處理
接下來介紹一個DBSCAN的方法(2016年),DBSCAN是什么,以下來自維基百科:英文全寫為Density-based spatial clustering of applications with noise?,是在 1996 年由Martin Ester, Hans-Peter Kriegel, J?rg Sander 及 Xiaowei Xu 提出的聚類分析算法, 這個算法是以密度為本的:給定某空間里的一個點(diǎn)集合,這算法能把附近的點(diǎn)分成一組(有很多相鄰點(diǎn)的點(diǎn)),并標(biāo)記出位于低密度區(qū)域的局外點(diǎn)(最接近它的點(diǎn)也十分遠(yuǎn)),DBSCAN 是其中一個最常用的聚類分析算法,也是其中一個科學(xué)文章中最常引用的。在 2014 年,這個算法在領(lǐng)頭數(shù)據(jù)挖掘會議 KDD 上獲頒發(fā)了 Test of Time award,該獎項(xiàng)是頒發(fā)給一些于理論及實(shí)際層面均獲得持續(xù)性的關(guān)注的算法。
一看到這個解釋就頭大,看看圖吧,非深度方法的處理確實(shí)很費(fèi)神。這個方法,采取了線段檢測,可利用的特征更多了,感覺好像也更復(fù)雜了。
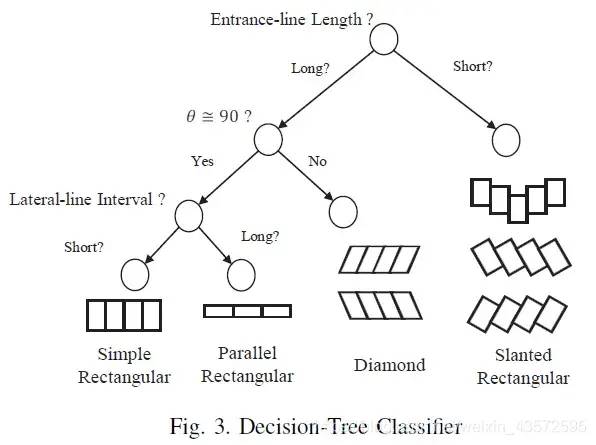
圖11 DBSCAN的處理,2016年,Directional-DBSCAN Parking-slot Detection using a Clustering Method

圖12 線段檢測出來后的結(jié)果,2016年,Directional-DBSCAN Parking-slot Detection using a Clustering Method
看到上圖的線段檢測結(jié)果,各位觀眾大佬爺想來一波后處理嗎(滑稽...):) 反正我是不會 。
傳統(tǒng)視覺的車位檢測介紹就到這兒,方法還有很多,其實(shí)不必太關(guān)心。
圖13 傳統(tǒng)視覺的車位檢測
但是可供深度學(xué)習(xí)借鑒的有:(1)角點(diǎn)檢測;(2)線段檢測;(3)后處理過濾、平滑、配對;(4)幀與幀直接的預(yù)測,即通過推算當(dāng)前幀得出下一幀的車位位置;(5)在AVM成像的鳥瞰圖上進(jìn)行處理,降低難度;(6)車位類型的分類;(7)車位角點(diǎn)和線段的分類;(8)窮舉。
2.2 深度時代的車位檢測
我們可以在傳統(tǒng)視覺處理的基礎(chǔ)上,直接替換傳統(tǒng)視覺算子,用深度學(xué)習(xí)的網(wǎng)絡(luò)提特征,來一波傳統(tǒng)向深度過渡的過程。猶如 RCNN(提特征+SVM分類) -> Fast RCNN(端到端+ROI) -> Faster RCNN (RPN+性能強(qiáng)勁+快);這樣的流程一點(diǎn)一點(diǎn),拿掉傳統(tǒng)的處理,一點(diǎn)一點(diǎn)進(jìn)行深度學(xué)習(xí)模塊的設(shè)計(jì)和整合;然后再由兩階段到單階段的過渡(YOLO -> SSD -> RetinaNet -> yolo serials)。最后用完全體的深度學(xué)習(xí)網(wǎng)絡(luò),確定車位檢測的最終解決方案。

通用車位檢測算法效果1
來個效果視頻吧,前面的介紹看著都看累了,看看我們做的,這個是一版還很粗糙的實(shí)測測試,無任何后處理(可以無NMS),網(wǎng)絡(luò)直出。整個網(wǎng)絡(luò)41FLOPS,0.28M參數(shù),(python版本量化前): backbone14MFLOPs,head26MFLOPs。這里采用的單路魚眼相機(jī)去畸變圖,并把輸入處理到384和128分辨率。單階段。視頻中有閃,AVM圖的處理受限于各種狀況,工程難度高。后續(xù)解決的,這里就不放了。我們主要介紹車位檢測這一通用的方法。然后運(yùn)算量和參數(shù)量怎么設(shè)計(jì)就怎么設(shè)計(jì)。
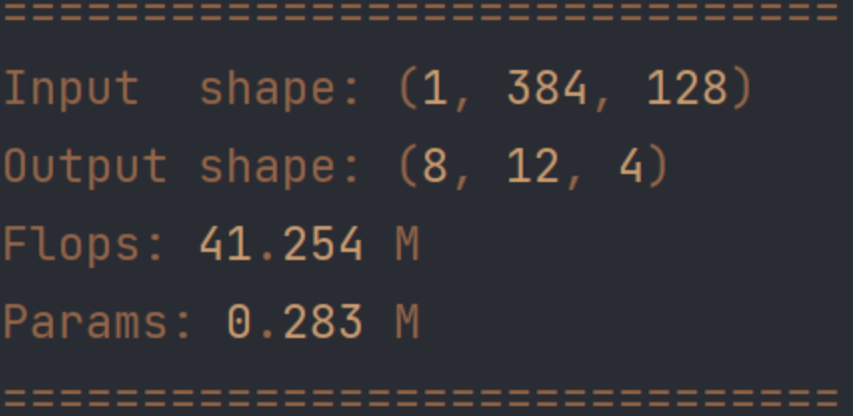
圖14 運(yùn)算量
先介紹以往的工作。我們分三種大類來概述(1)目標(biāo)檢測;(2)語義分割;它們的結(jié)合;(3)Transformer查詢;
目標(biāo)檢測的處理,一般是通過檢測車位角點(diǎn)、車位整個bounding box和檢測線段(一般不會這樣做)。
檢測車位角點(diǎn)的paper比較多,取3個方法來圖示說明。
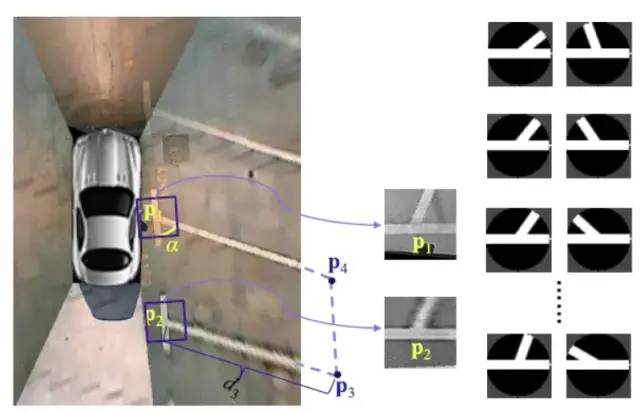
圖15 PS2.0數(shù)據(jù)集出處的方法,2018年,Vision-based parking-slot detection: A DCNN-based approach and a large-scale benchmark dataset
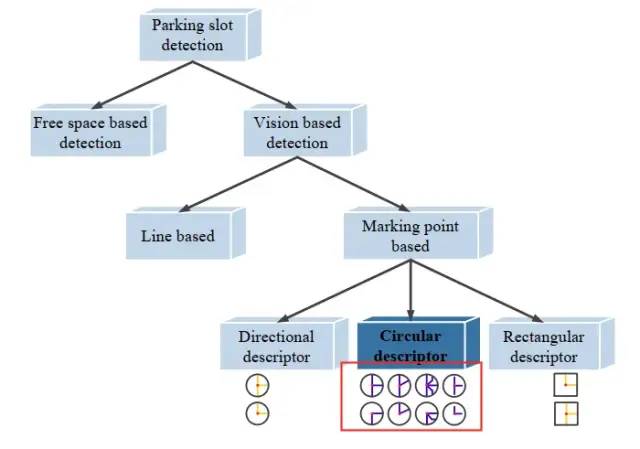
圖16 更多的角點(diǎn)分類,PSDet,2020年,Psdet: Efficient and universal parking slot detection
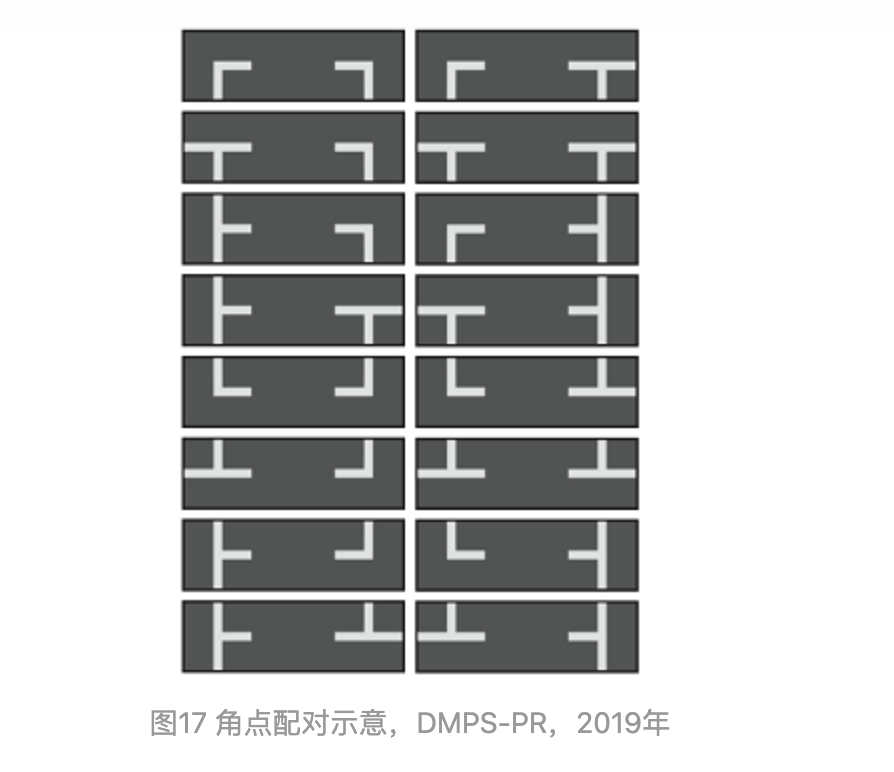
圖17 角點(diǎn)配對示意,DMPS-PR,2019年
DMPR-PS: A Novel Approach for Parking-Slot Detection Using Directional Marking-Point Regression https://ieeexplore.ieee.org/abstract/document/8784735
角點(diǎn)檢測一般會帶上分類信息和角度信息,傳統(tǒng)的模板匹配到深度學(xué)習(xí)的分類,進(jìn)化可見一斑。
用檢測框的方法居多,因?yàn)椋@樣是直接利用目標(biāo)檢測的bounding_box框來框停車位,簡直不要太好用。
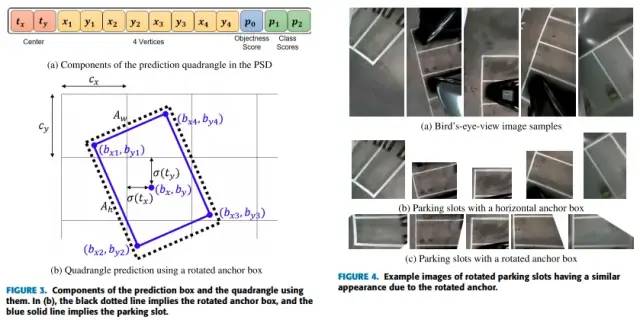
圖18 PIL_park數(shù)據(jù)集出處,bounding_box檢測示意
Context-Based Parking Slot Detection With a Realistic Dataset https://ieeexplore.ieee.org/abstract/document/9199853
上圖是回歸一個bounding_box框的做法,帶有角度信息,這個框的處理是可以是四邊形的,不一定非得矩形,可以有不同的夾角(小于90度),有點(diǎn)意思,不過需要做些限制處理,輕微的后處理。
回歸框的做法很典型,只取上述圖一篇Context-Based Parking Slot Detection With a Realistic Dataset,細(xì)微差異的方法確實(shí)會有很多,不一一介紹了。

圖19 方法截圖示意

圖20 https://github.com/lymhust/awesome-parking-slot-detection
看哇,很多。21年的沒整理成案,就不貼了。
接下來貼一下,語義分割方法的示意圖:

圖21 VH-HFCN,2018年
VH-HFCN based Parking Slot and Lane Markings Segmentation on Panoramic Surround View https://ieeexplore.ieee.org/abstract/document/8500553
語義分割,采用這種方法的童鞋可能糾結(jié)于后處理吧。

圖22 效果似乎還是有更好的出來。2018年Semantic segmentation-based parking space detection with standalone around view monitoring system
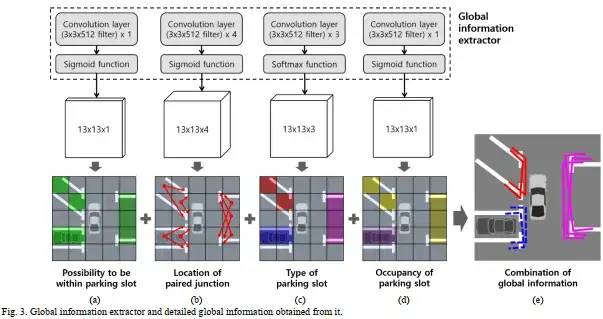
圖23 global信息
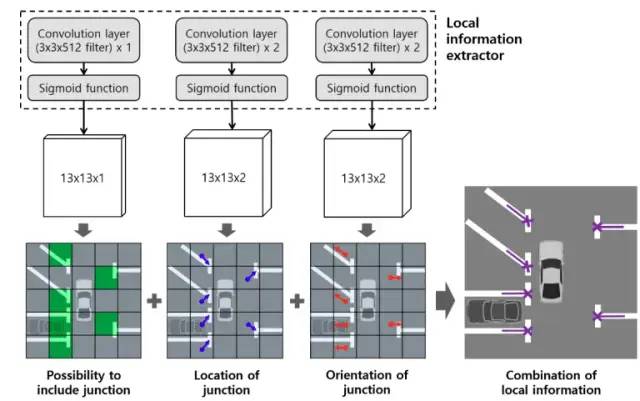
圖24 接上圖23,local信息
圖23和圖24是2021年的一篇文章:
End-to-End Trainable One-Stage Parking Slot Detection Integrating Global and Local Information https://ieeexplore.ieee.org/abstract/document/9316907/
如果端到端單階段的算法,需要以這種看起來復(fù)雜的后處理為代價,還是挺佩服作者的。

圖25 它的效果還是可以的。
這里介紹個2021年的別出心裁的方法:
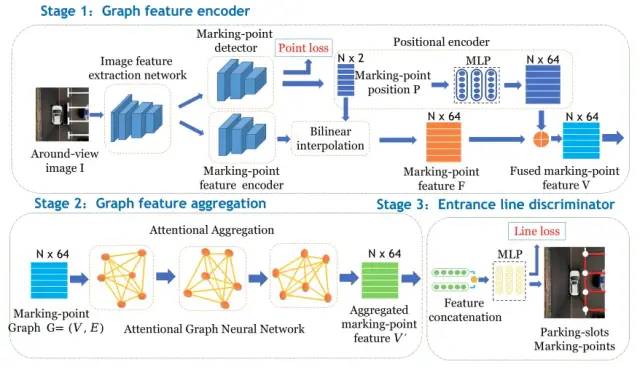
圖26 2021年,Attentional Graph Neural Network for Parking Slot Detection
https://github.com/Jiaolong/gcn-parking-slotgithub.com/Jiaolong/gcn-parking-slot
Transformer來一波:
2021年,Order-independent Matching with Shape Similarity for Parking Slot Detection
https://www.bmvc2021-virtualconference.com/assets/papers/1378.pdfwww.bmvc2021-virtualconference.com/assets/papers/1378.pdf
用Transformer(DETR)來做,實(shí)在沒必要。
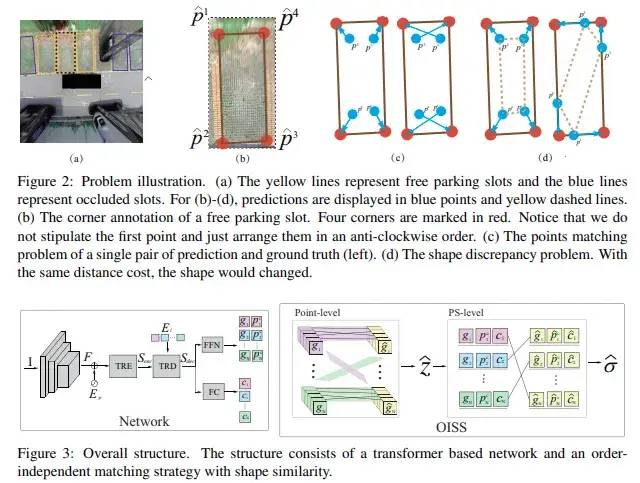
圖27 沒必要1
圖28 沒必要2
效果也沒見到好到哪里去,難度車位圖也沒貼。此條路,工程化不容易的。
三、我們的方法
花了大量篇幅介紹前人的工作,無外乎是為了引出我們的工作。
先貼下圖吧:

圖29 效果圖1

圖30 效果圖2
再來個視頻:
車位檢測推理
我們的方法,我們把它命名為通用停車位檢測,簡稱為GPSD。
在正式介紹之前,先解釋為什么要做這一件事。
3.1 為什么還要重復(fù)造輪子?
可能是因?yàn)榍叭说姆椒ú粔蚝茫赡苁亲约簭?fù)現(xiàn)不了,可能是吃數(shù)據(jù)集,可能是不夠簡單粗暴穩(wěn)準(zhǔn)狠,也可能是泛化性能不強(qiáng),總之,有各種各樣的原因。
理性的說:車位數(shù)據(jù)集越來越復(fù)雜的情況下,一旦沾有分類和利用車位標(biāo)線(就是車位最常見的白色的線),這就注定了算法吃數(shù)據(jù)集。一家車企要hold住每年上百萬的銷量如果還帶有優(yōu)質(zhì)的自動泊車,那么它的自動泊車算法(或工程)得有多魯棒啊,但一般來說,只給正確結(jié)果,要出錯難度車位它不檢就是:)。AVM的成像質(zhì)量也影響著車位檢測算法的準(zhǔn)確度上限,但AVM成像受制于魚眼相機(jī)的拍攝,畸變矯正的插值本就是難為了AVM了,是系統(tǒng)誤差!試想,在商場車庫中(比較常見吧)這個場景,魚眼相機(jī)遠(yuǎn)處拍到了一堆,給你來一堆立體停車位,整個一塊鋼板,還上下層,燈光有偏暗,地面還反光,去畸變插值拼接后,這個要去抽取角點(diǎn)特征?要去抽取車位標(biāo)線?可能用bounding_box加數(shù)據(jù)train來得痛快吧。
感性的說:實(shí)際中的情況是,車位會受各種現(xiàn)實(shí)情況的影響。如磨損,各種花哨的樣式,遮擋(AVM成像本身就有臨近車身畸變遮擋車位),甚至沒有標(biāo)線。反正就是非理想的車位,非理想的停車環(huán)境。這時,做好這些車位檢測,或者說是工程應(yīng)對,才能使車使自動泊車開得更遠(yuǎn),應(yīng)用場景更廣。
理性感性也分不清了。在自己拿到采集的數(shù)據(jù)集時,要去做檢測,發(fā)現(xiàn)不是調(diào)個YOLO系列就能搞定的事。網(wǎng)上公開的數(shù)據(jù)集可用同濟(jì)的ps2.0,首爾的PIL_park,這兩個數(shù)據(jù)集可以用來練兵,再去應(yīng)對現(xiàn)實(shí)場景。
實(shí)際上,就嫌之前的方法看起來麻煩,還不容易在短時間內(nèi)上手,在做工程的時候,當(dāng)然是又快又好,抄作業(yè)難以抄到好的情況下,考慮造一個好用又泛化的算法。這就是通用停車位檢測算法GPSD的由來。
3.2 怎么來定義一個停車位?
要放一些圖
其實(shí)原理也很簡單,但想泛化,需要考慮的還是有一些。
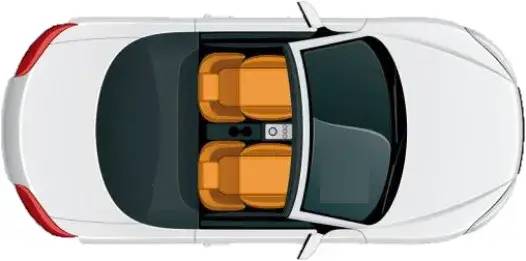
圖31 來個汽車,鳥瞰上帝視角
汽車長這樣,占地區(qū)域是方方正正。就一個矩形。
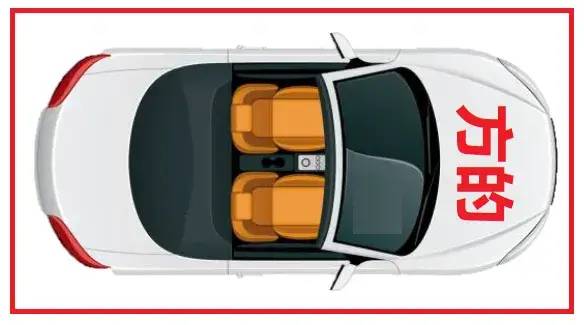
圖32 汽車占地面積是方的
再看看魚眼相機(jī),

圖33 魚眼相機(jī)拍攝
車位只要能放得下一輛汽車即可,線段是直的。
來看看鳥瞰圖:

圖34 鳥瞰圖1
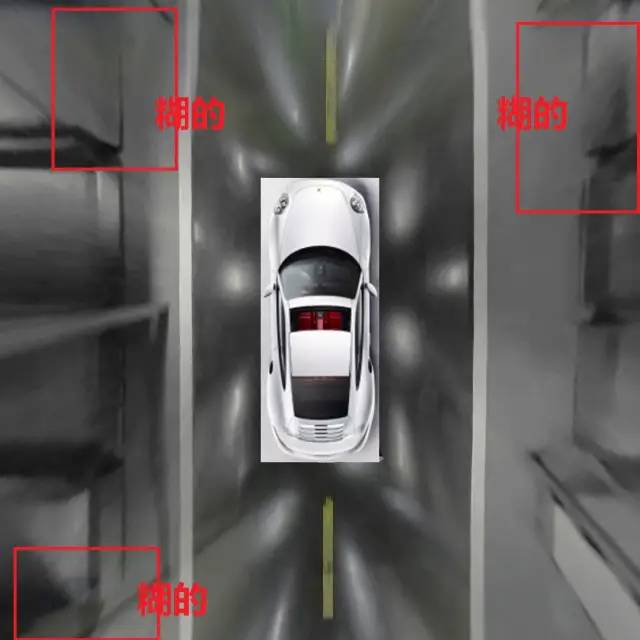
圖35 立體停車位鳥瞰圖
圖36 車位線被AVM成像畸變的汽車所遮擋
鳥瞰圖里,一個停車位人眼看起來是放不下一個車位的,哈哈
這是AVM成像帶來的,不可避免的,畸變。但是深度學(xué)習(xí)就強(qiáng)大在這個地方,我們?nèi)搜壅J(rèn)為他是一個車位,不要被圖像而蒙蔽,深度學(xué)習(xí)從圖片中學(xué)習(xí)特征,這里還要再深層次一點(diǎn),從圖像中去學(xué)習(xí)高級的人為推斷的抽象特征,而這種特征不是顯性的不是顯式的不是正確的,甚至是錯誤圖像帶來的錯誤信息,需要讓深度學(xué)習(xí)去學(xué)到,這個時候,目標(biāo)檢測、語義分割、角點(diǎn)檢測、線段檢測分割,種種,從CV里拿來就用的拿來主義,似乎受到了一點(diǎn)挑戰(zhàn)。如果只是就圖檢圖的化,畸變的車位,和車庫里畸變的柱子,就已經(jīng)可以橫跨好幾個車位把車位遮擋完了,我們必須警醒:從實(shí)際物理的角度而不是成像的像素分布去看待一個車位。

圖37 車庫柱子也可以遮擋車位
我們這樣來看一個車位:

圖38 它實(shí)際上就是兩個車位
讓深度學(xué)習(xí)去理解,我們要學(xué)習(xí)這樣一個車位。汽車什么的遮擋無關(guān)緊要,深度學(xué)習(xí)真的可以辦到。
再抽像點(diǎn):
停車位的概念,來源于車。先有車,再有停車位。如此簡單。車位一定必定是抽象出來四四方方像車一樣,是方的,最多的變化占地是平行四邊形而已:

圖41 平行四邊形車位,非矩形
3.2 車位幾何抽象
還是以圖示來進(jìn)行說明。
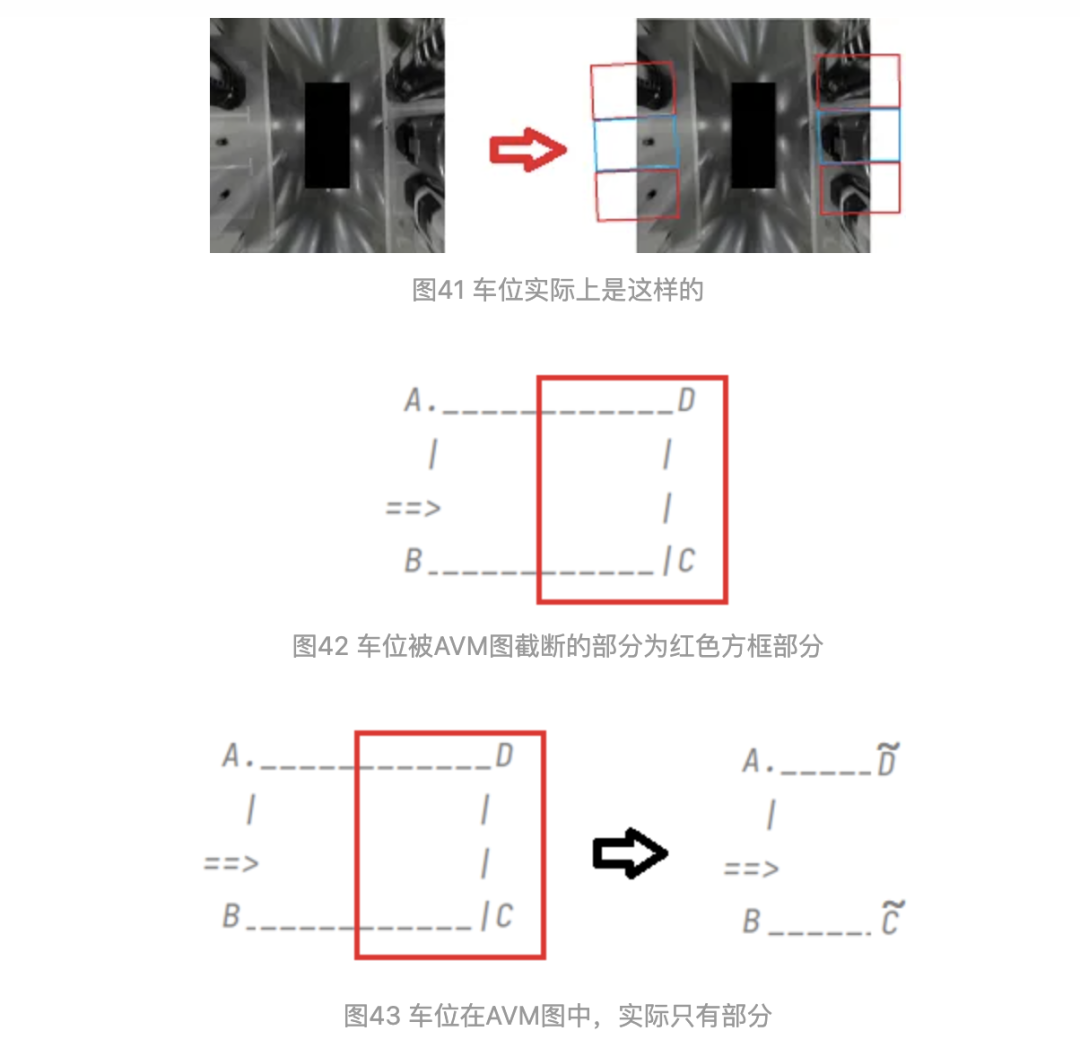
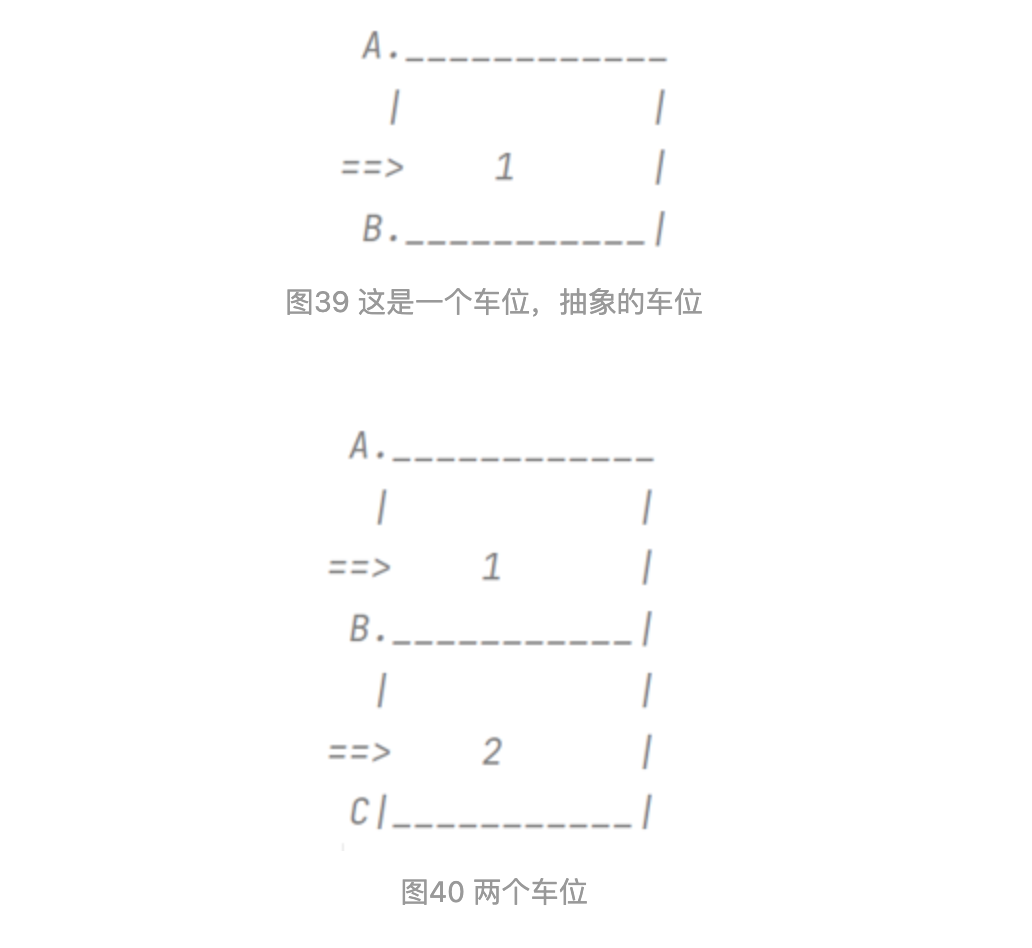
車位可以如上圖的簡單幾何表示。如果只是這么簡單就好了。實(shí)際上,車位是挨個連排的,車位周圍干擾線也比較多。而車位分布,總結(jié)為如下三種情況

如上圖,車位1,2為連續(xù)的車位分布;車位3,4為間隔的車位分布;車位5,6為錯開的車位分布。矩形可換成平行四邊形表示。車位1,2這種情況最常見。車位3,4這種也常見,比如車庫中有柱子,車位需要隔開。
空車位好做檢測,而車位上有汽車的時候,畫面大部分是畸變的汽車,給車位檢測帶來了一定的難度。
這時候,用anchor_based的方法bounding_box總覺得很怪,另外,車位在AVM中,成像不一定是完整的,比如:

圖45 車位的各種姿勢
如上圖,人為的對圖像中的車位進(jìn)行各種處理,為什么要這樣做呢?因?yàn)檐囋谛旭傔^程中,各種轉(zhuǎn)向,和離車位開得近開得遠(yuǎn),AVM成像出來的畫面都是不一樣的。這時,車位抽象出來不一定就是實(shí)際的方的了,完整的方形,被AVM成像給截?cái)嗔恕_@時采用錨點(diǎn)框做bounding_box檢測,又遇到點(diǎn)麻煩。

不采用bounding_box或許是最好的選擇。
此時,需要對車位的幾何抽象做數(shù)學(xué)上的表征,使它代表一個車位,并且不受AVM成像和汽車行駛所影響,且完美避開汽車畸變帶來的影響。見如下:
我盡量用白話文說清楚。
老規(guī)矩,先上圖:
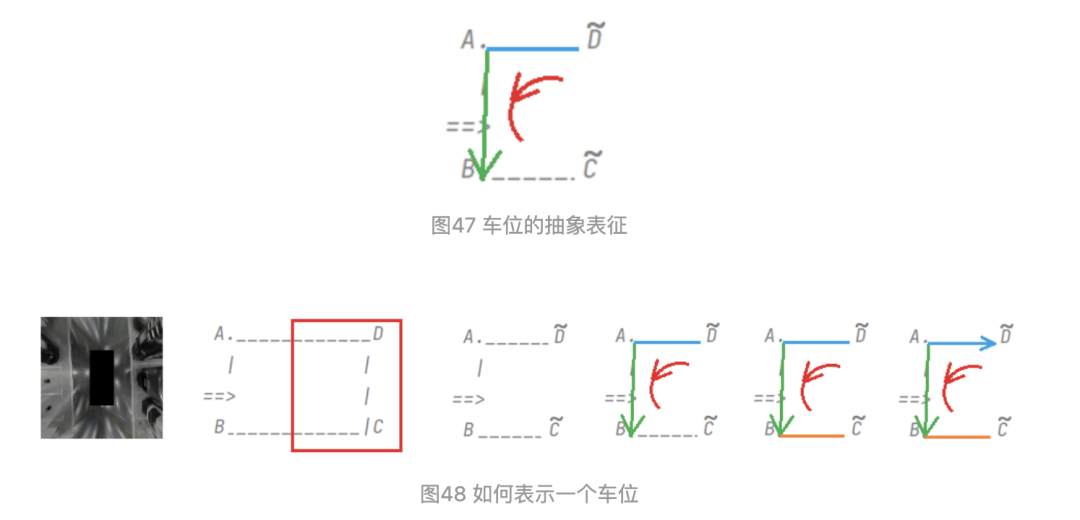
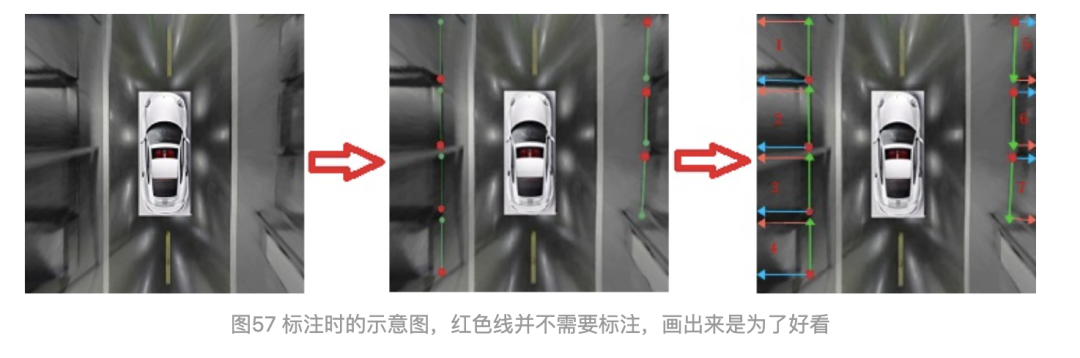
如圖47所示:
定義1:把AB定義為車位的進(jìn)入線,此進(jìn)入線需確定方向和長度。
定義2:把AD定義為車位的分隔線,此分隔線有兩種定義方式,(1)確定的長度和方向;(2)只定義方向。
定義3:對AD做平行線BC,線的起始端點(diǎn)為A,BC不做處理,通過AB和AD計(jì)算即可。
定義4:長度和方向這樣確定,以AB為例進(jìn)行說明:delta_x=x_A-x_B,delta_y=y_A-y_B;delta_x和delta_y需要做歸一化處理,即除以W和H。先知道A點(diǎn)的坐標(biāo)后,此時長度和方向均已確定。
定義5:只確定方向時,需要預(yù)測AD的線的cos和sin值,通過反算arctan,得到角度。先知道A點(diǎn)的坐標(biāo)后,方向即可確定。
定義6:對AVM圖,需要把它處理成右攝像頭視角,即左邊的成像需要旋轉(zhuǎn)到對其右邊視角,進(jìn)行統(tǒng)一處理。

圖49 公式
3.2 車位幾何抽象
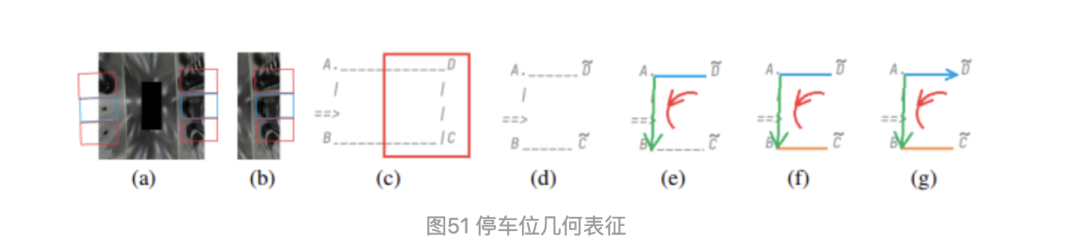
車位抽象出來后,我們只需預(yù)測車位的幾何表征信息,而無需糾結(jié)于車位具體是哪種類型,角點(diǎn)具體用哪種模板,復(fù)雜抽象的幾何表征,恰恰是對復(fù)雜的現(xiàn)實(shí)環(huán)境的一種數(shù)學(xué)表示。

圖52 看看立體停車位的幾何表征,紅色線是做的的藍(lán)色線的平行線。
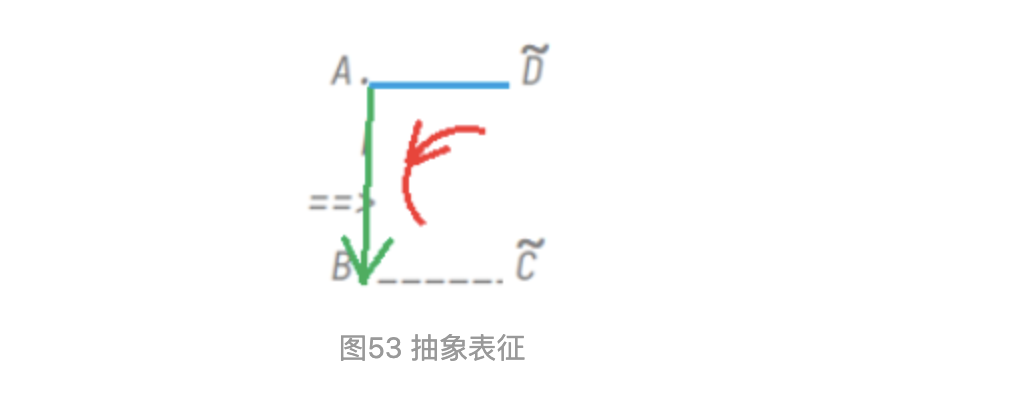
圖53中的紅色曲線箭頭,代表車位的幾何方向,進(jìn)入線是AB,分隔線是AD,車位角點(diǎn)是A,紅色方向?yàn)榉指艟€->車位角點(diǎn)->進(jìn)入線。AD->A->AB
3.3 數(shù)據(jù)集的制作

圖54 整張AVM的切圖處理

圖55 魚眼相機(jī)4路輸入
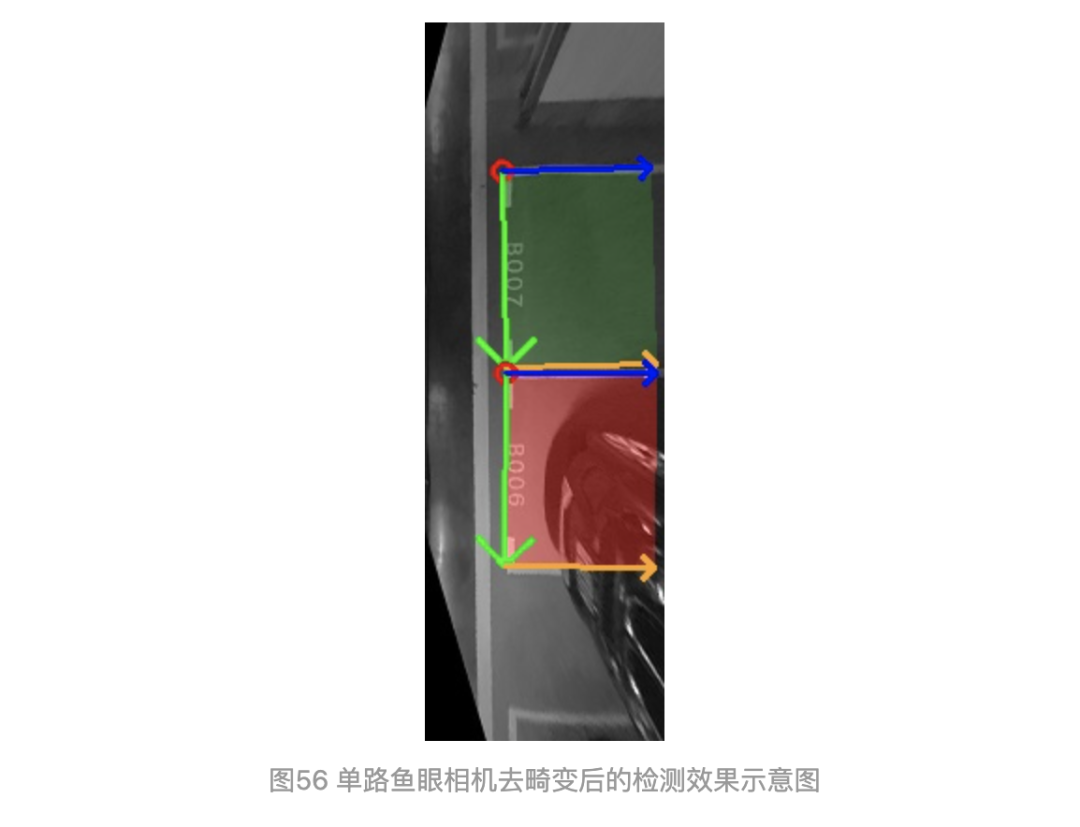
圖54是整張AVM圖(4路圖像去畸變和拼接后)做的處理,圖56是單路魚眼相機(jī)圖像做的處理。
在制作數(shù)據(jù)集時,可以在AVM圖上進(jìn)行標(biāo)注,也可以在單路圖像上進(jìn)行標(biāo)注。
整張AVM圖標(biāo)注時,遵循圖53的右子圖標(biāo)注原則:即在AVM整圖的右邊,找到車位,對車位角點(diǎn)A打標(biāo);再標(biāo)注進(jìn)入線AB,AB應(yīng)盡可能準(zhǔn)確;標(biāo)注AD時,可任意選擇AD的長度,因?yàn)锳D的預(yù)測有兩種方法,再上篇的圖49公式里,是計(jì)算方式。此時整個車位就是逆時針順序。相對而言,AVM圖左邊的標(biāo)注也是按照逆時針原則,但要注意標(biāo)注進(jìn)入線和分隔線。
單路圖像標(biāo)注時,把左邊相機(jī)拍攝的左子圖全部旋轉(zhuǎn)到右子圖,進(jìn)行統(tǒng)一標(biāo)注。
另外,還可以給車位上是否占用,即是否可用打上標(biāo)簽。
標(biāo)注的圖像通過裁剪和放縮,處理到W=128,H=384,W/H=1/3,送入網(wǎng)絡(luò)。這個比例和大小自己定,這里職位為了除以下采樣32的倍數(shù),選128的倍數(shù)更方便。

圖58 這些車位標(biāo)注起來也有點(diǎn)難度
公開數(shù)據(jù)中,我們采用了ps2.0和PIL_park,并進(jìn)行數(shù)據(jù)集的改造。以符合我們的幾何抽象定義。另外還自行采取和制作了商場停車場的數(shù)據(jù)集(就不貼上來了)。
ps2.0:?Vision-based parking-slot detection: A DCNN-based approach and a large-scale benchmark dataset
PIL_park:?Context-based parking slot detection with a realistic dataset
3.4 車位預(yù)測
在feature map上,一個feature_map像素,回歸一個車位。輸入的分辨率是128*384,吐出的特征圖分辨率是4*12,輸入的通道是3(RGB)或者1(Gray灰度圖),輸出的通道根據(jù)需要而定,我們采用的8個輸出通道,具體為:confidence置信度,車位角點(diǎn)A_x/A_y,進(jìn)入線delta_x/delta_y,分隔線delta_x/delta_y或者分隔線cos/sin,是否占用標(biāo)志isOccupied(或者是否可用標(biāo)志available)。
這里的車位角點(diǎn),并不是真正意義上的圖像中一定存在的車位角點(diǎn),進(jìn)入線和分隔線也不是真正意義上圖像中存在的線、實(shí)線、虛線、各種線,我們回歸的是一種抽象的數(shù)學(xué)幾何表示。
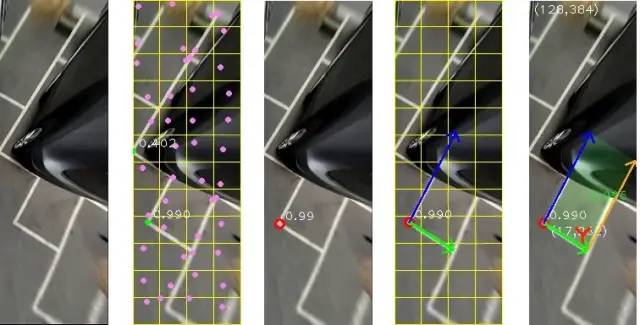
圖59 畫圖可視化1

圖60 畫圖可視化2
是不是有點(diǎn)像CenterNet?或者YOLO系列,YOLO1/2/3/X,Anchor Free,但是這里最大的區(qū)別在于,沒有利用圖像中的具體像素,利用實(shí)例的形狀和位置來確定實(shí)例,這里就解釋不通,因?yàn)槠囉谢儯鼡踝×塑囄唬⒉皇钦嬲膶?shí)際成像,我們回歸可以說是一個二維平面(地面)的車位,而3維空間中的汽車被AVM壓到了二維成像中,像素分布并不可靠了,學(xué)習(xí)圖像具體的像素不可行,必須讓網(wǎng)絡(luò)學(xué)習(xí)抽象的幾何表征。有點(diǎn)難以解釋,讓整個車位的信息,壓縮到車位角點(diǎn),即便車位角點(diǎn)實(shí)際并不存在,或者車位角點(diǎn)難以區(qū)分,如圖58所示。車位角點(diǎn)只是一個承載的載體,也可換到圖像中任何其他位置,如進(jìn)入線AB中點(diǎn),(沒試過),設(shè)計(jì)的時候考慮到了這一點(diǎn)。
3.5 網(wǎng)絡(luò)架構(gòu)
這個就很隨意了,backbone和detection head,任選,只是輸出特征圖的大小要特別注意,拿feature_map的分辨率4x12來說,一張128x384的圖最多給48個車位預(yù)測,實(shí)際上沒有這么多,只是為了適應(yīng)車位在圖中的分布,需要4x12去適應(yīng)車位出現(xiàn)在圖中的不同位置。我們選擇了單階段的網(wǎng)絡(luò)設(shè)計(jì),直出,就用單分辨率特征圖,發(fā)現(xiàn)已經(jīng)把公開數(shù)據(jù)集ps2.0和PIL_park的AP快刷滿了。
3.6 公開數(shù)據(jù)集上的測試結(jié)果
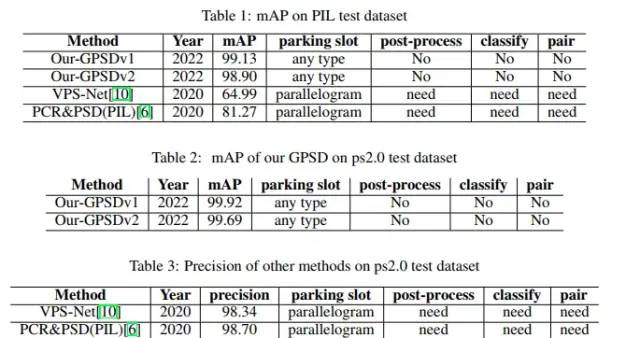
圖61 在ps2.0和PIL_park測試集上的結(jié)果
ps2.0數(shù)據(jù)集是同濟(jì)在2018年發(fā)布的,在車位檢測極具影響力,但比較簡單。PIL_park發(fā)布得更晚,文章引用少,但難度足夠。

圖62 ps2.0數(shù)據(jù)集圖片舉例

圖63 PIL數(shù)據(jù)集圖片舉例
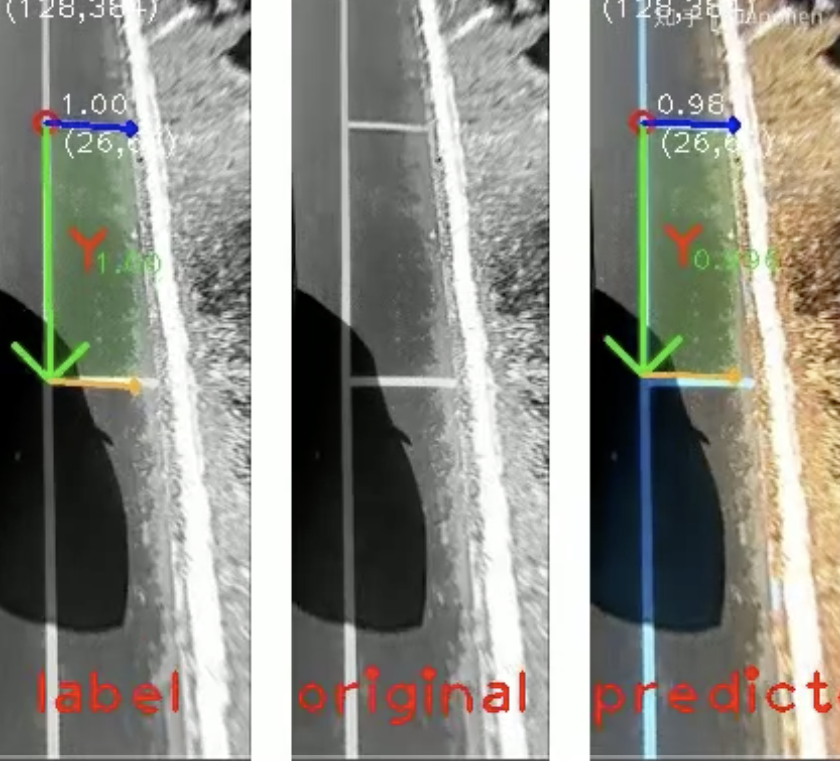
再貼下效果圖:

圖64 左列是標(biāo)簽,中間是原圖,右列是預(yù)測
3.7 設(shè)計(jì)實(shí)驗(yàn)
為了模仿實(shí)際泊車的AVM成像,比較關(guān)鍵的增強(qiáng)手段就是旋轉(zhuǎn)ratote,然后就是平移shift。
上篇有說,就是汽車在行駛過程中,前行、轉(zhuǎn)向和靠近車位的距離。
輸入采用RGB和灰度圖均可,灰度圖只是為了實(shí)際工程應(yīng)用,但RGB的AP更高。
實(shí)驗(yàn)參照一些影響廣泛的檢測網(wǎng)絡(luò)設(shè)計(jì)即可,不是本篇討論的范圍。
但是在設(shè)計(jì)loss的時候,因?yàn)閏onfidence、角點(diǎn)坐標(biāo)、進(jìn)入線、分隔線、是否占用,它們的loss量級有差,于是乎,做了對比實(shí)驗(yàn),發(fā)現(xiàn)需要給上述的每個單項(xiàng)加系數(shù),使網(wǎng)絡(luò)更關(guān)注角點(diǎn)坐標(biāo)和進(jìn)入線,而對是否占用的影響降低。采用了L2-norm。
不采用任何增強(qiáng)手段的粗糙網(wǎng)絡(luò)在PIL_park的test上也能達(dá)到超過90的mAP。方法很重要。
編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論