本文提出了一個(gè)魯棒且快速的多模態(tài)語(yǔ)義 SLAM 框架,旨在解決復(fù)雜和動(dòng)態(tài)環(huán)境中的 SLAM 問(wèn)題。具體來(lái)說(shuō),將僅幾何聚類(lèi)和視覺(jué)語(yǔ)義信息相結(jié)合,以減少由于小尺度對(duì)象、遮擋和運(yùn)動(dòng)模糊導(dǎo)致的分割誤差的影響。
2022-08-31 09:39:14 1302
1302 與分類(lèi)不同的是,語(yǔ)義分割需要判斷圖像每個(gè)像素點(diǎn)的類(lèi)別,進(jìn)行精確分割,圖像語(yǔ)義分割是像素級(jí)別的任務(wù),但是由于CNN在進(jìn)行convolution和pooling過(guò)程中丟失了圖像細(xì)節(jié),即feature
2022-12-07 13:38:05414 使用LabVIEW實(shí)現(xiàn)deeplabV3語(yǔ)義分割
2023-03-22 15:06:521253 
使用LabVIEW實(shí)現(xiàn) DeepLabv3+ 語(yǔ)義分割含源碼
2023-05-26 10:23:01522 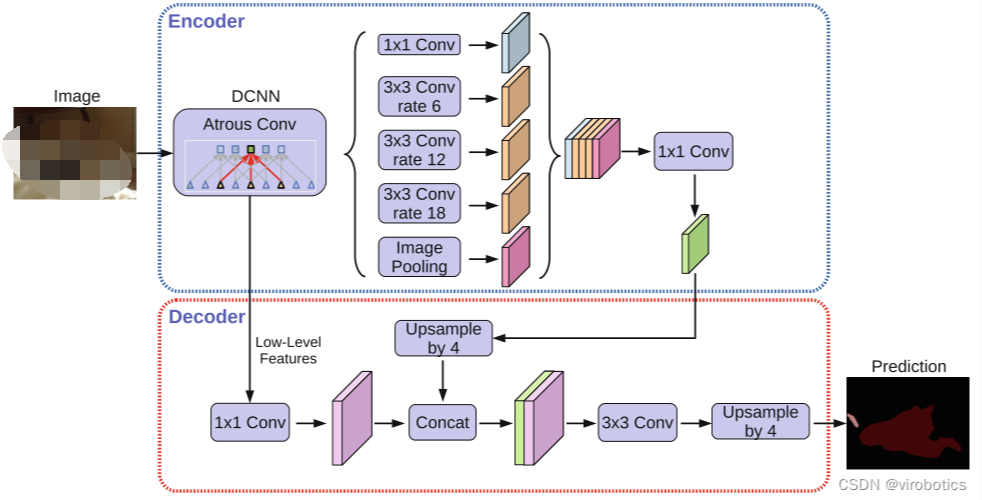
人工智能將迎來(lái)語(yǔ)義理解新時(shí)代。打破了傳統(tǒng)人工智能在語(yǔ)言交互方面反射式的應(yīng)答方式,成功地通過(guò)獨(dú)創(chuàng)的中文語(yǔ)義理解算法,讓計(jì)算機(jī)可以準(zhǔn)確理解語(yǔ)言環(huán)境,進(jìn)行上下文處理、口語(yǔ)處理、省略處理。該平臺(tái)可用于構(gòu)建
2016-03-10 16:52:17
限制了感知域的大小。基于存在的這些問(wèn)題,由Long等人在2015年提出的FCN結(jié)構(gòu),第一個(gè)全卷積神經(jīng)網(wǎng)絡(luò)的語(yǔ)義分割模型。我們要了解到的是,F(xiàn)CN是基于VGG和AlexNet網(wǎng)絡(luò)上進(jìn)行預(yù)訓(xùn)練,然后將最后
2021-12-28 11:03:35
限制了感知域的大小。基于存在的這些問(wèn)題,由Long等人在2015年提出的FCN結(jié)構(gòu),第一個(gè)全卷積神經(jīng)網(wǎng)絡(luò)的語(yǔ)義分割模型。我們要了解到的是,F(xiàn)CN是基于VGG和AlexNet網(wǎng)絡(luò)上進(jìn)行預(yù)訓(xùn)練,然后將最后
2021-12-28 11:06:01
候選粘連分割點(diǎn),以雙向最短路徑確定合適的圖像分割線路。仿真實(shí)驗(yàn)表明,該方法能有效解決粘連字符圖像的分割問(wèn)題。 關(guān)鍵詞: 字符分割; 連通狀況; 粘連字符; 輪廓; 最短路徑 隨著監(jiān)視器等設(shè)備
2009-09-19 09:19:17
基于GAC模型實(shí)現(xiàn)交互式圖像分割的改進(jìn)算法提出了一種改進(jìn)的交互式圖像分割算法。采用全變分去噪模型對(duì)圖像進(jìn)行預(yù)處理,在去除噪聲的同時(shí)更好地保護(hù)了邊緣;提出了一種對(duì)梯度模值進(jìn)行曲率加權(quán)的邊緣檢測(cè)方法
2009-09-19 09:19:45
基于改進(jìn)遺傳算法的圖像分割方法提出一種應(yīng)用于圖像分割的改進(jìn)遺傳算法,算法中引入了優(yōu)生算子、改進(jìn)的變異算子和新個(gè)體,避免了局部早熟,提高了收斂速度和全局收斂能力。 關(guān)鍵詞: 圖像分割&
2009-09-19 09:36:47
在安裝ABBYY PDF Transformer+時(shí)會(huì)讓您選擇界面語(yǔ)言。此語(yǔ)言將用于所有消息、對(duì)話框、按鈕和菜單項(xiàng)。在特殊情況下,您可能需要在安裝完成后更改界面語(yǔ)言以適應(yīng)需求,方法其實(shí)很簡(jiǎn)單,本文
2017-10-11 16:13:38
、Source-Free DA上的應(yīng)用。六、遷移學(xué)習(xí)前沿應(yīng)用遷移學(xué)習(xí)在語(yǔ)義分割中的應(yīng)用遷移學(xué)習(xí)在目標(biāo)檢測(cè)中的應(yīng)用遷移學(xué)習(xí)在行人重識(shí)別中的應(yīng)用圖片與視頻風(fēng)格遷移章節(jié)目標(biāo):掌握深度遷移學(xué)習(xí)在語(yǔ)義分割、目標(biāo)檢測(cè)
2022-04-28 18:56:07
目標(biāo)檢測(cè)和圖像語(yǔ)義分割領(lǐng)域的性能評(píng)價(jià)指標(biāo)
2020-05-13 09:57:44
PDA、Source-Free DA上的應(yīng)用。六、遷移學(xué)習(xí)前沿應(yīng)用遷移學(xué)習(xí)在語(yǔ)義分割中的應(yīng)用遷移學(xué)習(xí)在目標(biāo)檢測(cè)中的應(yīng)用遷移學(xué)習(xí)在行人重識(shí)別中的應(yīng)用圖片與視頻風(fēng)格遷移章節(jié)目標(biāo):掌握深度遷移學(xué)習(xí)在語(yǔ)義分割
2022-04-21 15:15:11
內(nèi)電層分割的一般方法,內(nèi)電層分割的一般方法,內(nèi)電層分割的一般方法。
2015-12-25 10:05:09 0
0 提出了一種目標(biāo)飛機(jī)分割提取方法,該方法采用改進(jìn)的使用金字塔式分割策略的以彩色高斯混合模型CMM(Gaussian Mixture Model)和迭代能量最小化為基礎(chǔ)的CJrabCut算法,達(dá)到將目標(biāo)
2017-11-10 15:46:297 模式的基礎(chǔ)上對(duì)動(dòng)詞進(jìn)行詳細(xì)的研究。在對(duì)語(yǔ)義進(jìn)行歸納總結(jié)以后,將動(dòng)詞的語(yǔ)義模式分為三類(lèi),再將動(dòng)詞語(yǔ)義模式庫(kù)進(jìn)行搭建,最后設(shè)計(jì)出一種以語(yǔ)義、句式以及變量為基礎(chǔ)的翻譯方法,該漢譯方法適用于英語(yǔ)句子當(dāng)中的動(dòng)詞
2017-11-11 12:00:0014 場(chǎng)景分類(lèi)的主要方法是基于底層特征的方法和基于視覺(jué)詞包模型的方法,前者缺乏語(yǔ)義描述能力并且時(shí)間復(fù)雜度大,后者識(shí)別率低。借鑒兩類(lèi)方法的優(yōu)勢(shì),提出了基于四層樹(shù)狀語(yǔ)義模型的場(chǎng)景語(yǔ)義識(shí)別新方法。四層語(yǔ)義模型
2017-12-07 11:17:480 針對(duì)傳統(tǒng)查詢擴(kuò)展方法在專業(yè)領(lǐng)域中擴(kuò)展詞與原始查詢之間缺乏語(yǔ)義關(guān)聯(lián)的問(wèn)題,提出一種基于語(yǔ)義向量表示的查詢擴(kuò)展方法。首先,構(gòu)建了一個(gè)語(yǔ)義向量表示模型,通過(guò)對(duì)語(yǔ)料庫(kù)中詞的上下文語(yǔ)義進(jìn)行學(xué)習(xí),得到詞的語(yǔ)義
2017-12-12 16:11:590 文本情感傾向性研究是人工智能的分支學(xué)科,涉及了計(jì)算語(yǔ)言學(xué),數(shù)據(jù)挖掘,自然語(yǔ)言處理等多個(gè)學(xué)科。基于語(yǔ)義的情感傾向研究和基于機(jī)器學(xué)習(xí)的情感傾向研究是情感傾向性分析的兩個(gè)方向。本文采用了基于語(yǔ)義的方法
2017-12-15 16:35:116 本文詳細(xì)介紹了圖像分割的基本方法有:基于邊緣的圖像分割方法、閾值分割方法、區(qū)域分割方法、基于圖論的分割方法、基于能量泛函的分割方法、基于聚類(lèi)的分割方法等。圖像分割指的是根據(jù)灰度、顏色、紋理和形狀
2017-12-20 11:06:04108009 
的方法、基于像素聚類(lèi)的方法和語(yǔ)義分割方法這3種類(lèi)型并分別加以介紹對(duì)每類(lèi)方法所包含的典型算法,尤其是最近幾年利用深度網(wǎng)絡(luò)技術(shù)的語(yǔ)義圖像分割方法的基本思想、優(yōu)缺點(diǎn)進(jìn)行了分析、對(duì)比和總結(jié).介紹了圖像分割常用的基準(zhǔn)
2018-01-02 16:52:412 。該方法將帶量測(cè)的電力網(wǎng)絡(luò)建模為量測(cè)拓?fù)鋯尉€圖,并在無(wú)注入量測(cè)節(jié)點(diǎn)處進(jìn)行了拓?fù)?b class="flag-6" style="color: red">分割,將網(wǎng)絡(luò)分割成了多個(gè)連通子網(wǎng)。利用廣度優(yōu)先雙向搜索算法對(duì)含線路潮流量測(cè)的各個(gè)子網(wǎng)進(jìn)行了可觀測(cè)性分析,在不可觀測(cè)子網(wǎng)巾分析了不可觀
2018-03-06 18:03:190 鴻溝消除方法。ModSG是一個(gè)模塊化系統(tǒng),將語(yǔ)義修復(fù)分為2部分:與用戶直接交互的在線語(yǔ)義視圖構(gòu)建和與操作系統(tǒng)知識(shí)交互的離線高級(jí)語(yǔ)義解析。二者以獨(dú)立的模塊實(shí)現(xiàn)且后者為前者提供語(yǔ)義重構(gòu)時(shí)必要的內(nèi)核語(yǔ)義信息。針對(duì)不同虛擬機(jī)狀
2018-03-09 13:47:460 最近進(jìn)行語(yǔ)義分割的結(jié)構(gòu)大多用的是卷積神經(jīng)網(wǎng)絡(luò)(CNN),它首先會(huì)給每個(gè)像素分配最初的類(lèi)別標(biāo)簽。卷積層可以有效地捕捉圖像的局部特征,同時(shí)將這樣的圖層分層嵌入,CNN嘗試提取更寬廣的結(jié)構(gòu)。隨著越來(lái)越多的卷積層捕捉到越來(lái)越復(fù)雜的圖像特征,一個(gè)卷積神經(jīng)網(wǎng)絡(luò)可以將圖像中的內(nèi)容編碼成緊湊的表示。
2018-05-25 10:09:165818 這是最早用于自動(dòng)駕駛領(lǐng)域的語(yǔ)義分割數(shù)據(jù)集,發(fā)布于2007年末。他們應(yīng)用自己的圖像標(biāo)注軟件在一段10分鐘的視頻中連續(xù)標(biāo)注了700張圖片,這些視頻是由安裝在汽車(chē)儀表盤(pán)的攝像機(jī)拍攝的,拍攝視角和司機(jī)的視角基本一致。
2018-05-29 09:42:197892 我們將當(dāng)前分類(lèi)網(wǎng)絡(luò)(AlexNet, VGG net 和 GoogLeNet)修改為全卷積網(wǎng)絡(luò),通過(guò)對(duì)分割任務(wù)進(jìn)行微調(diào),將它們學(xué)習(xí)的表征轉(zhuǎn)移到網(wǎng)絡(luò)中。然后,我們定義了一種新架構(gòu),它將深的、粗糙的網(wǎng)絡(luò)層語(yǔ)義信息和淺的、精細(xì)的網(wǎng)絡(luò)層的表層信息結(jié)合起來(lái),來(lái)生成精確的分割。
2018-06-03 09:53:56105067 來(lái)自 MIT CSAIL 的研究人員開(kāi)發(fā)了一種精細(xì)程度遠(yuǎn)超傳統(tǒng)語(yǔ)義分割方法的「語(yǔ)義軟分割」技術(shù),連頭發(fā)都能清晰地在分割掩碼中呈現(xiàn)。
2018-08-23 14:18:083630 CNN架構(gòu)圖像語(yǔ)義分割 圖像分割是根據(jù)圖像內(nèi)容對(duì)指定區(qū)域進(jìn)行標(biāo)記的計(jì)算機(jī)視覺(jué)任務(wù),簡(jiǎn)言之就是「這張圖片里有什么,其在圖片中的位置是什么?」本文聚焦于語(yǔ)義分割任務(wù),即在分割圖中將同一類(lèi)別的不同實(shí)例視為
2018-09-17 15:21:01421 更具體地講,語(yǔ)義圖像分割的目標(biāo)在于標(biāo)記圖片中每一個(gè)像素,并將每一個(gè)像素與其表示的類(lèi)別對(duì)應(yīng)起來(lái)。因?yàn)闀?huì)預(yù)測(cè)圖像中的每一個(gè)像素,所以一般將這樣的任務(wù)稱為密集預(yù)測(cè)。
2018-10-15 09:51:002939 基于視覺(jué)的交通場(chǎng)景語(yǔ)義分割在智能車(chē)輛中起著重要作用。
2018-11-16 09:47:594555 簡(jiǎn)單地移植圖像分類(lèi)的方法不足以進(jìn)行語(yǔ)義分割。在圖像分類(lèi)中,NAS 通常使用從低分辨率圖像到高分辨率圖像的遷移學(xué)習(xí) [92],而語(yǔ)義分割的最佳架構(gòu)必須在高分辨率圖像上運(yùn)行。這表明,本研究需要
2019-01-15 13:51:123502 該文中作者將語(yǔ)義分割問(wèn)題看為像素分類(lèi)問(wèn)題,所以很自然的可以使用衡量分類(lèi)差異的逐像素(Pixel-wise)的損失函數(shù)Cross entropy loss,這是在最終的輸出結(jié)果Score map中計(jì)算的。
2019-03-18 10:15:372037 
這一新架構(gòu)“全景 FPN ”在 Facebook 2017 年發(fā)布的 Mask R-CNN 的基礎(chǔ)上添加了一個(gè)用于語(yǔ)義分割的分支。這一新架構(gòu)可以同時(shí)對(duì)圖像進(jìn)行實(shí)例和語(yǔ)義分割,而且精確度與只進(jìn)行實(shí)例或語(yǔ)義分割的神經(jīng)網(wǎng)絡(luò)相當(dāng),這相當(dāng)于能將傳統(tǒng)方法所需要的計(jì)算資源減半。
2019-04-22 11:46:572598 
初創(chuàng)公司Deepen AI由前谷歌工程師和產(chǎn)品經(jīng)理創(chuàng)建,開(kāi)發(fā)用于自動(dòng)駕駛系統(tǒng)的人工智能和注釋工具。據(jù)外媒報(bào)道,目前該公司正在開(kāi)發(fā)最新的激光雷達(dá)和融合傳感器數(shù)據(jù)4D語(yǔ)義分割,并聲稱能夠生成精確的、可伸縮的4D分割數(shù)據(jù),也就是跟隨時(shí)間發(fā)展的3D幀。
2019-05-26 11:13:421105 從視覺(jué)上看,道路、天空、建筑物等類(lèi)的語(yǔ)義分割結(jié)果重疊情況良好。然而,行人和車(chē)輛等較小的對(duì)象則不那么準(zhǔn)確。可以使用交叉聯(lián)合 (IoU) 指標(biāo)(又稱 Jaccard 系數(shù))來(lái)測(cè)量每個(gè)類(lèi)的重疊量。使用 jaccard 函數(shù)測(cè)量 IoU。
2019-09-12 11:30:599867 
形成更快,更強(qiáng)大的語(yǔ)義分割編碼器-解碼器網(wǎng)絡(luò)。DeepLabv3+是一種非常先進(jìn)的基于深度學(xué)習(xí)的圖像語(yǔ)義分割方法,可對(duì)物體進(jìn)行像素級(jí)分割。本文將使用labelme圖像標(biāo)注工具制造自己的數(shù)據(jù)集,并使用DeepLabv3+訓(xùn)練自己的數(shù)據(jù)集,具體包括:數(shù)據(jù)集標(biāo)注、數(shù)據(jù)集格式轉(zhuǎn)換、修改程序文
2019-10-24 08:00:0011 為了避免上述問(wèn)題,來(lái)自中科院自動(dòng)化所、北京中醫(yī)藥大學(xué)的研究者們提出一個(gè)執(zhí)行圖像語(yǔ)義分割任務(wù)的圖模型 Graph-FCN,該模型由全卷積網(wǎng)絡(luò)(FCN)進(jìn)行初始化。
2020-05-13 15:21:446735 BEV較低的運(yùn)行成本是另一個(gè)主要優(yōu)勢(shì)。較低的運(yùn)行成本是由于較低的維護(hù)成本和燃料成本。此外,BEV有更少的活動(dòng)部件和更少的流體,這意味著約50%的維護(hù)費(fèi)用比ICEV。在美國(guó),BEV每英里的平均電力成本
2020-07-16 15:00:48827 圖像語(yǔ)義分割是圖像處理和是機(jī)器視覺(jué)技術(shù)中關(guān)于圖像理解的重要任務(wù)。語(yǔ)義分割即是對(duì)圖像中每一個(gè)像素點(diǎn)進(jìn)行分類(lèi),確定每個(gè)點(diǎn)的類(lèi)別,從而進(jìn)行區(qū)域劃分,為了能夠幫助大家更好的了解語(yǔ)義分割領(lǐng)域,我們精選
2020-11-05 10:34:274435 繼大華AI取得KITTI語(yǔ)義分割競(jìng)賽第一之后,近日,大華股份基于深度學(xué)習(xí)算法的語(yǔ)義分割技術(shù),刷新了Cityscapes數(shù)據(jù)集中語(yǔ)義分割任務(wù)(Pixel-Level Semantic Labeling
2020-11-05 18:29:093895 本文介紹的論文提出了一種新的實(shí)時(shí)通用語(yǔ)義分割體系結(jié)構(gòu)RGPNet,在復(fù)雜環(huán)境下取得了顯著的性能提升。作者: Tom Hardy首發(fā):3D視覺(jué)工坊...
2020-12-10 19:15:12446 分割任務(wù)論文集與各方實(shí)現(xiàn):[鏈接]pytorch model zoo:[鏈接]gluon model zoo:[鏈接]SOTA Leaderboard:[鏈接]
2020-12-10 19:24:471338 OpenCV DNN模塊支持的圖像語(yǔ)義分割網(wǎng)絡(luò)FCN是基于VGG16作為基礎(chǔ)網(wǎng)絡(luò),運(yùn)行速度很慢,無(wú)法做到實(shí)時(shí)語(yǔ)義分割。2016年提出的ENet實(shí)時(shí)語(yǔ)義分...
2020-12-15 00:18:15324 語(yǔ)義分割的最簡(jiǎn)單形式是對(duì)一個(gè)區(qū)域設(shè)定必須滿足的硬編碼規(guī)則或?qū)傩裕M(jìn)而指定特定類(lèi)別標(biāo)簽. 編碼規(guī)則可以根據(jù)像素的屬性來(lái)構(gòu)建,如灰度級(jí)強(qiáng)度(gray level intensity). 基于該技術(shù)的一種
2020-12-28 14:28:234583 現(xiàn)有時(shí)序異常檢測(cè)方法存在計(jì)算效率低和可解釋性差的問(wèn)題。考慮到 Transformer模型在自然語(yǔ)言處理任務(wù)中表現(xiàn)岀并行效率髙且能夠跨距離提取關(guān)系的優(yōu)勢(shì),提岀基于 Transformer的掩膜時(shí)序
2021-03-10 16:08:381 針對(duì)已有多數(shù)交互式分割方法交互方式單一、預(yù)測(cè)結(jié)果精度較低的問(wèn)題,構(gòu)建一種基于雙階段網(wǎng)絡(luò)的目標(biāo)分割模型 Scribner,以實(shí)現(xiàn)更完整和精細(xì)的交互式目標(biāo)分割。采用靈活涂畫(huà)的交互方式,通過(guò)編碼形成交互
2021-03-11 11:48:4511 隨著深度學(xué)習(xí)技術(shù)的快速發(fā)展及其在語(yǔ)義分割領(lǐng)域的廣泛應(yīng)用,語(yǔ)義分割效果得到顯著提升。對(duì)基于深度神經(jīng)網(wǎng)絡(luò)的圖像語(yǔ)義分割方法進(jìn)行分析與總結(jié),根據(jù)網(wǎng)絡(luò)訓(xùn)練方式的不同,將現(xiàn)有的圖像語(yǔ)義分割分為全監(jiān)督學(xué)習(xí)圖像
2021-03-19 14:14:0621 為改善單目圖像語(yǔ)義分割網(wǎng)絡(luò)對(duì)圖像深度變化區(qū)域的分割效果,提出一種結(jié)合雙目圖像的深度信息和跨層次特征進(jìn)行互補(bǔ)應(yīng)用的語(yǔ)義分割模型。在不改變已有單目孿生網(wǎng)絡(luò)結(jié)構(gòu)的前提下,利用該模型分別提取雙目左、右輸入
2021-03-19 14:35:2420 近年來(lái),深度傳感器和三維激光掃描儀的普及推動(dòng)了三維點(diǎn)云處理方法的快速發(fā)展。點(diǎn)云語(yǔ)義分割作為理解三維場(chǎng)景的關(guān)鍵步驟,受到了研究者的廣泛關(guān)注。隨著深度學(xué)習(xí)的迅速發(fā)展并廣泛應(yīng)用到三維語(yǔ)義分割領(lǐng)域,點(diǎn)云語(yǔ)義
2021-04-01 14:48:4616 圖像語(yǔ)義分割是計(jì)算機(jī)視覺(jué)領(lǐng)堿近年來(lái)的熱點(diǎn)硏究課題,隨著深度學(xué)習(xí)技術(shù)的興起,圖像語(yǔ)義分割與深度學(xué)習(xí)技術(shù)進(jìn)行融合發(fā)展,取得了顯著的進(jìn)步,在無(wú)人駕駛、智能安防、智能機(jī)器人、人機(jī)交互等真實(shí)場(chǎng)景應(yīng)用廣泛。首先
2021-04-02 13:59:4611 針對(duì)傳統(tǒng)語(yǔ)義分割網(wǎng)絡(luò)速度慢、精度低的問(wèn)題,提出一種基于密集層和注意力機(jī)制的快速場(chǎng)景語(yǔ)義分割方法。在 Resnet網(wǎng)絡(luò)中加入密集層和注意力模塊,密集層部分采用兩路傳播方式,以更好地獲得多尺度目標(biāo)
2021-05-24 15:48:336 壩面缺陷檢測(cè)是水利樞紐安全巡檢的關(guān)鍵環(huán)節(jié),但復(fù)雜環(huán)境下壩面圖像存在干擾噪聲大和像素不均衡等冋題造成壩面裂縫難以精細(xì)分割。提出一種利用可分離殘差卷積和語(yǔ)義補(bǔ)償?shù)腢-Net裂縫分割方法。在U-Net網(wǎng)絡(luò)
2021-05-24 16:40:318 使用原始 SEGNET模型對(duì)圖像進(jìn)行語(yǔ)義分割時(shí),未對(duì)圖像中相鄰像素點(diǎn)間的關(guān)系進(jìn)行考慮,導(dǎo)致同一目標(biāo)中像素點(diǎn)類(lèi)別預(yù)測(cè)結(jié)果不一致。通過(guò)在 SEGNET結(jié)構(gòu)中加入一條自上而下的通道,使得 SEGNET包含
2021-05-27 14:54:5415 全景分割是一個(gè)計(jì)算機(jī)視覺(jué)任務(wù),會(huì)將語(yǔ)義分割(為每個(gè)像素分配類(lèi)標(biāo)簽)和實(shí)例分割(檢測(cè)和分割每個(gè)對(duì)象實(shí)例)合并。作為實(shí)際應(yīng)用中的核心任務(wù),全景分割通常使用多個(gè)代理 (Surrogate) 子任務(wù)
2021-05-31 11:07:022892 現(xiàn)有的端到端青光眼篩査模型往往忽略細(xì)微病變區(qū)域而導(dǎo)致過(guò)擬合冋題,并且其可解釋性區(qū)域尚不明確針對(duì)上述問(wèn)題,提出一種語(yǔ)義特征圖引導(dǎo)的青光眼篩查方法。利用基于 Mobilenet v2作為特征提取網(wǎng)絡(luò)
2021-06-03 15:28:5014 地揭示句子的語(yǔ)義。為此,提出一種藏文句義分割方法,通過(guò)長(zhǎng)度介于詞語(yǔ)和句子之間的語(yǔ)義塊單元進(jìn)行句義分割。在對(duì)句子進(jìn)行分詞和標(biāo)注的基礎(chǔ)上,重新組合分詞結(jié)果,將句子分割為若干個(gè)語(yǔ)義塊,并采用空洞卷積神經(jīng)網(wǎng)絡(luò)模型對(duì)
2021-06-07 11:53:1414 和筆跡。使得現(xiàn)存書(shū)法筆跡生成軟件僅僅用于娛樂(lè),而難以上升到數(shù)字化書(shū)法教育層面。文中從計(jì)算機(jī)視覺(jué)的角度出發(fā),通過(guò)4個(gè)相機(jī)獲取毛筆的實(shí)時(shí)書(shū)寫(xiě)圖像:針對(duì) Deeplabv3+語(yǔ)義分割算法無(wú)法有效地分割小尺寸類(lèi)別的缺點(diǎn)進(jìn)行優(yōu)化,
2021-06-07 15:10:162 語(yǔ)義分割任務(wù)是對(duì)圖像中的物體按照類(lèi)別進(jìn)行像素級(jí)別的預(yù)測(cè),其難點(diǎn)在于在保留足夠空間信息的同時(shí)獲取足夠的上下文信息。為解決這一問(wèn)題,文中提出了全局雙邊網(wǎng)絡(luò)語(yǔ)義分割算法。該算法將大尺度卷積核融入
2021-06-16 15:20:2216 基于語(yǔ)義分割的輸電線路中防震錘識(shí)別
2021-06-29 16:29:0315 傳統(tǒng)方法一般會(huì)先在圖像空間生成分割結(jié)果,然后通過(guò)逆透視變換(IPM)函數(shù)轉(zhuǎn)換到BEV空間。雖然這是一種連接圖像空間和BEV空間的簡(jiǎn)單直接的方法,但它需要準(zhǔn)確的相機(jī)內(nèi)外參,或者實(shí)時(shí)的相機(jī)位姿估計(jì)。所以,視圖變換的實(shí)際效果有可能比較差。
2022-04-27 09:50:382302 語(yǔ)義分割任務(wù)作為計(jì)算機(jī)視覺(jué)中的基礎(chǔ)任務(wù)之一,其目的是對(duì)圖像中的每一個(gè)像素進(jìn)行分類(lèi)。該任務(wù)也被廣泛應(yīng)用于實(shí)踐,例如自動(dòng)駕駛和醫(yī)學(xué)圖像分割。
2022-05-10 11:30:531956 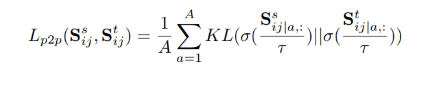
語(yǔ)義分割是一項(xiàng)重要的像素級(jí)別分類(lèi)任務(wù)。但是由于其非常依賴于數(shù)據(jù)的特性(data hungary), 模型的整體性能會(huì)因?yàn)閿?shù)據(jù)集的大小而產(chǎn)生大幅度變化。同時(shí), 相比于圖像級(jí)別的標(biāo)注, 針對(duì)圖像切割的像素級(jí)標(biāo)注會(huì)多花費(fèi)十幾倍的時(shí)間。因此, 在近些年來(lái)半監(jiān)督圖像切割得到了越來(lái)越多的關(guān)注。
2022-08-11 11:29:03696 為了解決大規(guī)模點(diǎn)云語(yǔ)義分割中的巨大標(biāo)記成本,我們提出了一種新的弱監(jiān)督環(huán)境下的混合對(duì)比正則化(HybridCR)框架,該框架與全監(jiān)督的框架相比具有競(jìng)爭(zhēng)性。
2022-09-05 14:38:00999 訓(xùn)練語(yǔ)義分割模型需要大量精細(xì)注釋的數(shù)據(jù),這使得它很難快速適應(yīng)不滿足這一條件的新類(lèi),F(xiàn)S-Seg 在處理這個(gè)問(wèn)題時(shí)有很多限制條件。
2022-09-13 08:56:041544 語(yǔ)義分割是對(duì)圖像中的每個(gè)像素進(jìn)行識(shí)別的一種算法,可以對(duì)圖像進(jìn)行像素級(jí)別的理解。作為計(jì)算機(jī)視覺(jué)中的基礎(chǔ)任務(wù)之一,其不僅僅在學(xué)術(shù)界廣受關(guān)注,也在無(wú)人駕駛、工業(yè)檢測(cè)、輔助診斷等領(lǐng)域有著廣泛的應(yīng)用。
2022-09-27 15:27:582413 本文探討了普通視覺(jué)Transformer(ViT)用于語(yǔ)義分割的能力,并提出了SegViT。以前基于ViT的分割網(wǎng)絡(luò)通常從ViT的輸出中學(xué)習(xí)像素級(jí)表示。不同的是,本文利用基本的組件注意力機(jī)制生成語(yǔ)義分割的Mask。
2022-10-31 09:57:413801 概述 在這篇論文中,提出了一種新的醫(yī)學(xué)圖像分割混合架構(gòu):PHTrans,它在主要構(gòu)建塊中并行混合 Transformer 和 CNN,分別從全局和局部特征中生成層次表示并自適應(yīng)聚合它們,旨在充分利用
2022-11-05 11:38:085577 全面性和可讀性:本文根據(jù)它們?cè)谌齻€(gè)基本CV任務(wù)(即分類(lèi)、檢測(cè)和分割)和數(shù)據(jù)流類(lèi)型(即圖像、點(diǎn)云、多流數(shù)據(jù))上的應(yīng)用,全面回顧了100多個(gè)視覺(jué)Transformer。論文選擇了更具代表性的方法
2022-11-08 14:20:352123 繼醫(yī)學(xué)圖像處理系列之后,我們又回到了小樣本語(yǔ)義分割主題上,之前閱讀筆記的鏈接我也在文末整理了一下。
2022-11-15 10:05:341000 自動(dòng)駕駛領(lǐng)域的下游任務(wù),我認(rèn)為主要包括目標(biāo)檢測(cè)、語(yǔ)義分割、實(shí)例分割和全景分割。其中目標(biāo)檢測(cè)是指在區(qū)域中提取目標(biāo)的候選框并分類(lèi),語(yǔ)義分割是對(duì)區(qū)域中不同類(lèi)別的物體進(jìn)行區(qū)域性劃分,實(shí)例分割是將每個(gè)類(lèi)別進(jìn)一步細(xì)化為單獨(dú)的實(shí)例,全景分割則要求對(duì)區(qū)域中的每一個(gè)像素/點(diǎn)云都進(jìn)行分類(lèi)。
2022-12-14 14:25:381787 BEV+Transformer是目前智能駕駛領(lǐng)域最火熱的話題,沒(méi)有之一,這也是無(wú)人駕駛低迷期唯一的亮點(diǎn),BEV+Transformer徹底終結(jié)了2D直視圖+CNN時(shí)代
2023-02-16 17:14:262097 從最簡(jiǎn)單的像素級(jí)別“閾值法”(Thresholding methods)、基于像素聚類(lèi)的分割方法(Clustering-based segmentation methods)到“圖劃分”的分割方法
2023-04-20 10:01:331891 物體分割是計(jì)算機(jī)視覺(jué)中的核心任務(wù)之一,旨在識(shí)別圖像中屬于特定對(duì)象的像素。通常實(shí)現(xiàn)圖像分割的方法有兩種,即交互式分割和自動(dòng)分割。交互式分割可以對(duì)任何類(lèi)別的對(duì)象進(jìn)行分割,但需要人工引導(dǎo),并通過(guò)反復(fù)精細(xì)化掩碼來(lái)完成。
2023-04-23 11:16:25862 
語(yǔ)義分割是計(jì)算機(jī)視覺(jué)領(lǐng)域中的一個(gè)重要問(wèn)題,它的目標(biāo)是將圖像或視頻中的語(yǔ)義信息(如人、物、場(chǎng)景等)從背景中分離出來(lái),以便于進(jìn)行目標(biāo)檢測(cè)、識(shí)別和分類(lèi)等任務(wù)。語(yǔ)義分割數(shù)據(jù)集是指用于訓(xùn)練和測(cè)試語(yǔ)義分割算法的數(shù)據(jù)集合。本文將從語(yǔ)義分割數(shù)據(jù)集的理論和實(shí)踐兩個(gè)方面進(jìn)行介紹。
2023-04-23 16:45:00473 隨著人工智能技術(shù)的不斷發(fā)展,語(yǔ)義分割標(biāo)注已經(jīng)成為計(jì)算機(jī)視覺(jué)領(lǐng)域的一個(gè)熱門(mén)話題。語(yǔ)義分割是指將圖像中的每個(gè)像素分配給一個(gè)預(yù)定義的語(yǔ)義類(lèi)別,以便在計(jì)算機(jī)視覺(jué)應(yīng)用中進(jìn)行分類(lèi)和分析。標(biāo)注語(yǔ)義分割的圖像可以幫助計(jì)算機(jī)視覺(jué)系統(tǒng)更好地理解和分析圖像中的內(nèi)容,并在許多任務(wù)中取得更好的性能。
2023-04-30 21:20:24721 語(yǔ)義分割是區(qū)分同類(lèi)物體的分割任務(wù),實(shí)例分割是區(qū)分不同實(shí)例的分割任務(wù),而全景分割則同時(shí)達(dá)到這兩個(gè)目標(biāo)。全景分割既可以區(qū)分彼此相關(guān)的物體,也可以區(qū)分它們?cè)趫D像中的位置,這使其非常適合對(duì)圖像中所有類(lèi)別的目標(biāo)進(jìn)行分割。
2023-05-17 14:44:24810 
電子發(fā)燒友網(wǎng)站提供《PyTorch教程14.9之語(yǔ)義分割和數(shù)據(jù)集.pdf》資料免費(fèi)下載
2023-06-05 11:10:380 14.9. 語(yǔ)義分割和數(shù)據(jù)集? Colab [火炬]在 Colab 中打開(kāi)筆記本 Colab [mxnet] Open the notebook in Colab Colab [jax
2023-06-05 15:44:37375 
了許多解決深度多模態(tài)感知問(wèn)題的方法。
然而,對(duì)于網(wǎng)絡(luò)架構(gòu)的設(shè)計(jì),并沒(méi)有通用的指導(dǎo)方針,關(guān)于“融合什么”、“何時(shí)融合”和“如何融合”的問(wèn)題仍然沒(méi)有定論。本文系統(tǒng)地總結(jié)了自動(dòng)駕駛
中深度多模態(tài)目標(biāo)檢測(cè)和語(yǔ)義分割的方法,
2023-06-06 10:37:110 BEV感知是自動(dòng)駕駛的重要趨勢(shì)。常規(guī)的自動(dòng)駕駛算法方法基于在前視圖或透視圖中執(zhí)行檢測(cè)、分割、跟蹤,而在BEV中可表示周?chē)鷪?chǎng)景,相對(duì)而言更加直觀,并且在BEV中表示目標(biāo)對(duì)于后續(xù)模塊最為理想。
2023-06-06 17:47:22843 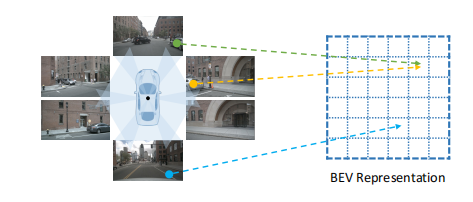
是指將周?chē)鄠€(gè)攝像頭的連續(xù)幀作為輸入,然后將像平面視角轉(zhuǎn)換為鳥(niǎo)瞰圖視角,在得到的鳥(niǎo)瞰圖特征上執(zhí)行諸如三維目標(biāo)檢測(cè)、地圖視圖語(yǔ)義分割和運(yùn)動(dòng)預(yù)測(cè)等感知任務(wù)。 ? BEV感知性能的提高取決于如何快速且精準(zhǔn)地獲取道路和物體特征表示。圖
2023-06-15 14:20:38575 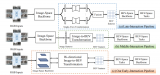
3.2.4語(yǔ)義分割圖3-7所示為機(jī)器視覺(jué)語(yǔ)義分割示例。計(jì)算機(jī)視覺(jué)的核心是分割,它將整個(gè)圖像分成一個(gè)個(gè)像素組,然后對(duì)其進(jìn)行標(biāo)記和分類(lèi)。語(yǔ)義分割試圖在語(yǔ)義上理解圖像中每個(gè)像素的角色(例如,識(shí)別它是道路
2022-03-07 09:35:42279 
SAM被認(rèn)為是里程碑式的視覺(jué)基礎(chǔ)模型,它可以通過(guò)各種用戶交互提示來(lái)引導(dǎo)圖像中的任何對(duì)象的分割。SAM利用在廣泛的SA-1B數(shù)據(jù)集上訓(xùn)練的Transformer模型,使其能夠熟練處理各種場(chǎng)景和對(duì)象。
2023-06-28 15:08:332574 
自蒸餾正則化實(shí)現(xiàn)內(nèi)存高效的 CoTTA 推薦對(duì)領(lǐng)域適應(yīng)不了解的同學(xué)先閱讀前置文章。目前的 TTA 方法針對(duì)反向傳播的方式可以大致劃分為: 請(qǐng)?zhí)砑訄D片描述 之前介紹過(guò)的 CoTTA 可以屬于 Fully
2023-06-30 15:10:59318 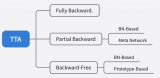
TTA 在語(yǔ)義分割中的應(yīng)用,效率和性能都至關(guān)重要。現(xiàn)有方法要么效率低(例如,需要反向傳播的優(yōu)化),要么忽略語(yǔ)義適應(yīng)(例如,分布對(duì)齊)。此外,還會(huì)受到不穩(wěn)定優(yōu)化和異常分布引起的誤差積累的困擾。
2023-06-30 15:13:00571 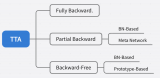
RSPrompter的目標(biāo)是學(xué)習(xí)如何為SAM生成prompt輸入,使其能夠自動(dòng)獲取語(yǔ)義實(shí)例級(jí)掩碼。相比之下,原始的SAM需要額外手動(dòng)制作prompt,并且是一種類(lèi)別無(wú)關(guān)的分割方法。
2023-07-04 10:45:21456 
一篇關(guān)于 ?Transformer-Based 的 Segmentation 的綜述,系統(tǒng)地回顧了近些年來(lái)基于 Transformer? 的分割與檢測(cè)模型,調(diào)研的最新模型
2023-07-05 10:18:39463 
Adapter Network (SAN)的新框架,用于基于預(yù)訓(xùn)練的視覺(jué)語(yǔ)言模型進(jìn)行開(kāi)放式語(yǔ)義分割。該方法將語(yǔ)義分割任務(wù)建模為區(qū)域識(shí)別問(wèn)題,并通過(guò)附加一個(gè)側(cè)面的可學(xué)習(xí)網(wǎng)絡(luò)來(lái)實(shí)現(xiàn)。該網(wǎng)絡(luò)可以重用CLIP
2023-07-10 10:05:02523 
?動(dòng)機(jī)&背景 Transformer 模型在各種自然語(yǔ)言任務(wù)中取得了顯著的成果,但內(nèi)存和計(jì)算資源的瓶頸阻礙了其實(shí)用化部署。低秩近似和結(jié)構(gòu)化剪枝是緩解這一瓶頸的主流方法。然而,作者通過(guò)分析發(fā)現(xiàn),結(jié)構(gòu)化
2023-07-17 10:50:431172 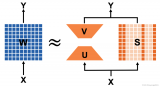
論文在III-B部分描述了論文方法背后的SLAM管道。論文的2D潛在先驗(yàn)網(wǎng)絡(luò)(LPN)在III-C中描述。LPN輸出融合到論文在III-D中描述的論文新穎的準(zhǔn)平面超分段(QPOS)方法分割的地圖
2023-07-19 15:55:21275 
摘 要:點(diǎn)云分割是點(diǎn)云數(shù)據(jù)理解中的一個(gè)關(guān)鍵技術(shù),但傳統(tǒng)算法無(wú)法進(jìn)行實(shí)時(shí)語(yǔ)義分割。近年來(lái)深度學(xué)習(xí)被應(yīng)用在點(diǎn)云分割上并取得了重要進(jìn)展。綜述了近四年來(lái)基于深度學(xué)習(xí)的點(diǎn)云分割的最新工作,按基本思想分為
2023-07-20 15:23:590 BEV人工智能transformer? 人工智能Transformer技術(shù)是一種自然語(yǔ)言處理領(lǐng)域的重要技術(shù),廣泛應(yīng)用于自然語(yǔ)言理解、機(jī)器翻譯、文本分類(lèi)等任務(wù)中。它通過(guò)深度學(xué)習(xí)算法從大規(guī)模語(yǔ)料庫(kù)中自動(dòng)
2023-08-22 15:59:28549 將BEV下的每個(gè)grid作為query,在高度上采樣N個(gè)點(diǎn),投影到圖像中sample到對(duì)應(yīng)像素的特征,且利用了空間和時(shí)間的信息。并且最終得到的是BEV featrue,在此featrue上做Det和Seg。
2023-09-04 10:22:33776 
深度學(xué)習(xí)在圖像語(yǔ)義分割上已經(jīng)取得了重大進(jìn)展與明顯的效果,產(chǎn)生了很多專注于圖像語(yǔ)義分割的模型與基準(zhǔn)數(shù)據(jù)集,這些基準(zhǔn)數(shù)據(jù)集提供了一套統(tǒng)一的批判模型的標(biāo)準(zhǔn),多數(shù)時(shí)候我們?cè)u(píng)價(jià)一個(gè)模型的性能會(huì)從執(zhí)行時(shí)間、內(nèi)存使用率、算法精度等方面進(jìn)行考慮。
2023-10-09 15:26:12120 
BEV是一種將三維環(huán)境信息投影到二維平面的方法,以俯視視角展示環(huán)境中的物體和地形。在自動(dòng)駕駛領(lǐng)域,BEV 可以幫助系統(tǒng)更好地理解周?chē)h(huán)境,提高感知和決策的準(zhǔn)確性。在環(huán)境感知階段,BEV 可以將激光雷達(dá)、雷達(dá)和相機(jī)等多模態(tài)數(shù)據(jù)融合在同一平面上。
2023-10-11 16:16:03367 
現(xiàn)有的圖像分割方法主要分以下幾類(lèi):基于閾值(threshold)的分割方法、基于區(qū)域的分割方法、基于邊緣的分割方法以及基于特定理論的分割方法等。
2023-11-02 10:26:39199 
統(tǒng)用于檢測(cè)和跟蹤車(chē)輛路徑中的行人、車(chē)輛和障礙物等物體。 BEV圖往往是利用四路環(huán)視魚(yú)眼圖,經(jīng)過(guò)內(nèi)外參標(biāo)定后拼接而成。對(duì)于拼接后的BEV視圖,可以利用深度學(xué)習(xí)進(jìn)行語(yǔ)義分割。分割后的BEV視圖,通過(guò)計(jì)算機(jī)視覺(jué)算法可以提取出車(chē)輛、行人等障礙物的外輪廓。利用這些特征,我們可
2023-11-14 11:37:19287 本文提出了一種在線激光雷達(dá)語(yǔ)義分割框架MemorySeg,它利用三維潛在記憶來(lái)改進(jìn)當(dāng)前幀的預(yù)測(cè)。傳統(tǒng)的方法通常只使用單次掃描的環(huán)境信息來(lái)完成語(yǔ)義分割任務(wù),而忽略了觀測(cè)的時(shí)間連續(xù)性所蘊(yùn)含的上下文信息
2023-11-21 10:48:00197 
由于大量的相機(jī)和激光雷達(dá)特征以及注意力的二次性質(zhì),將 Transformer 架構(gòu)簡(jiǎn)單地應(yīng)用于相機(jī)-激光雷達(dá)融合問(wèn)題是很困難的。
2024-01-23 11:39:39137 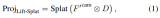
 電子發(fā)燒友App
電子發(fā)燒友App


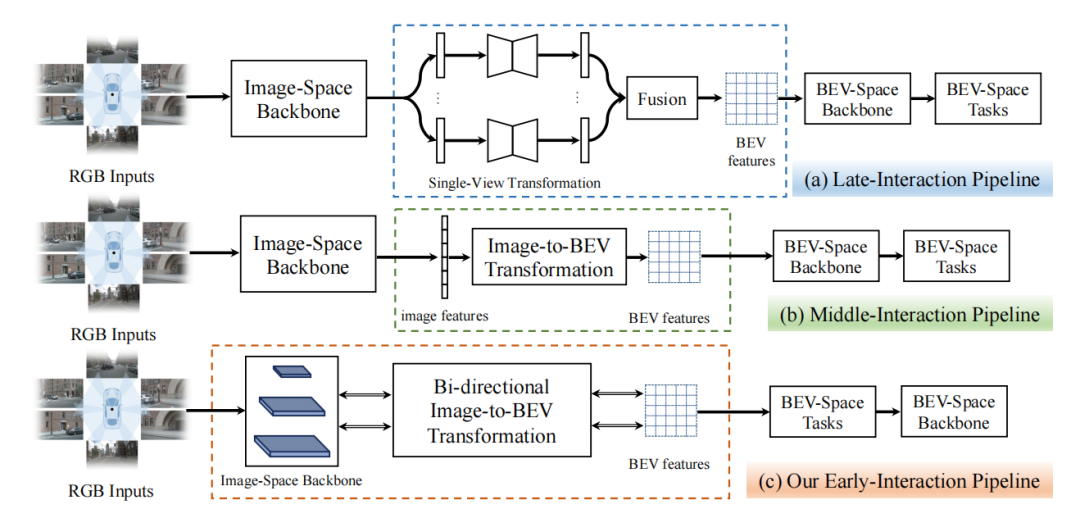
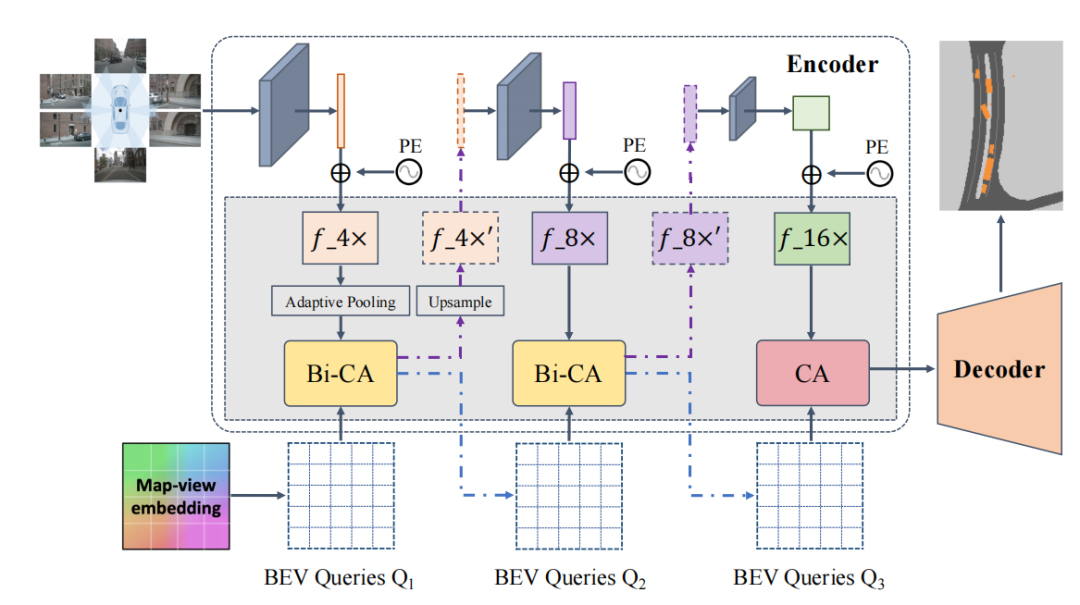
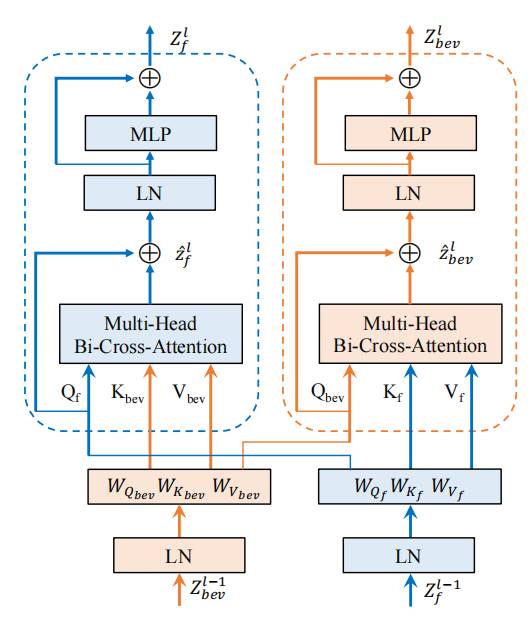
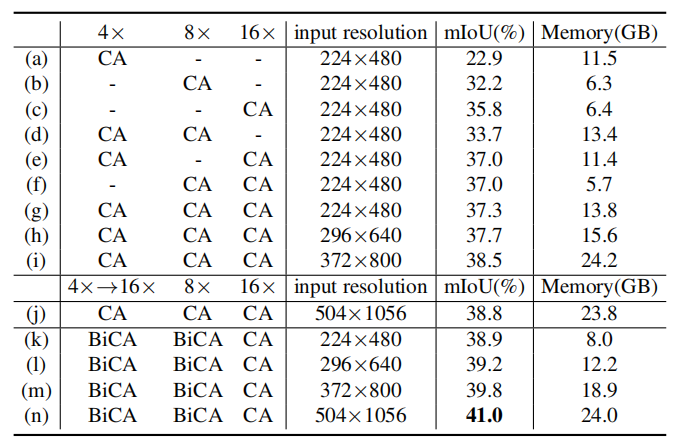
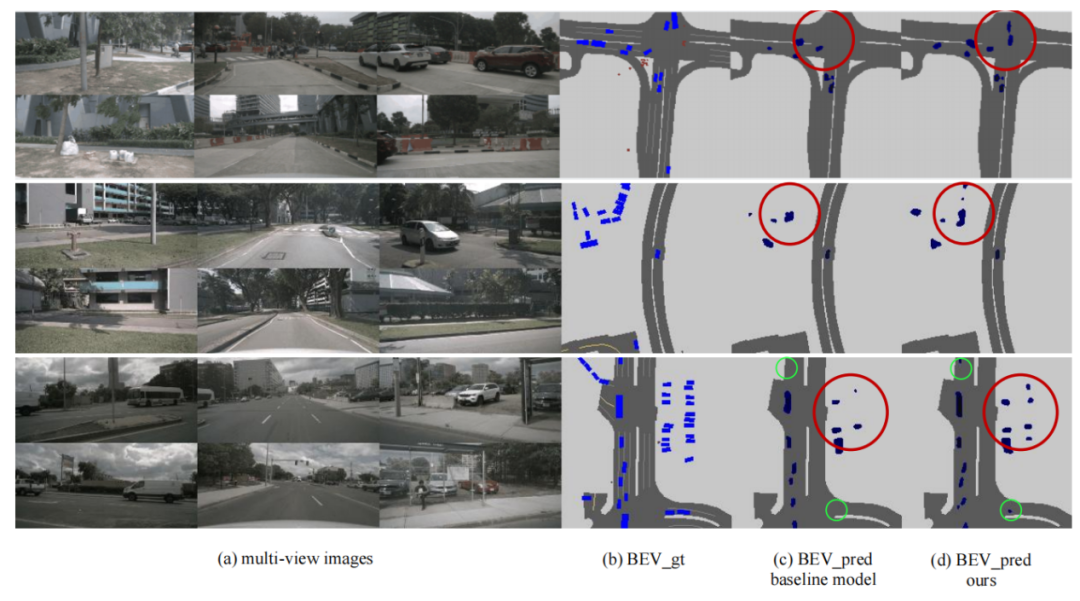
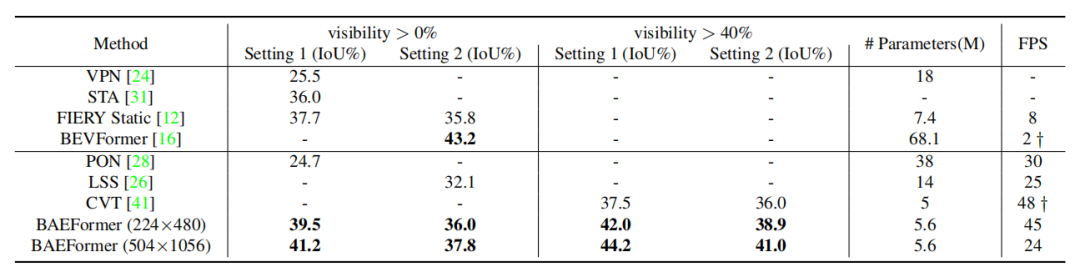 表1:nuScenes數(shù)據(jù)集上車(chē)輛類(lèi)別的語(yǔ)義分割結(jié)果
表1:nuScenes數(shù)據(jù)集上車(chē)輛類(lèi)別的語(yǔ)義分割結(jié)果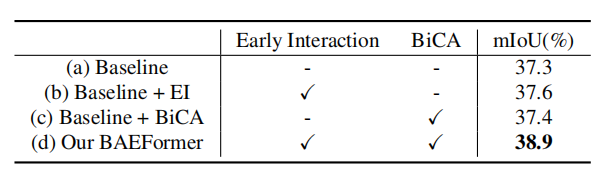







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論