 電子發燒友App
電子發燒友App


作者簡介
?Dr. Liu,劍橋大學博士,復睿微電子英國研究中心AI算法專家,常駐英國劍橋研究所。長期從事和深耕信號處理和深度學習領域,是機器人定位領域理論專家。在圖神經網絡,強化學習,機器人路徑規劃與導航領域發表了大量論文,目前從事GRUK自動駕駛規控決策領域重點前沿研發。
引言:
隨著科技的飛速發展,自動駕駛技術逐漸走進了人們的視野。在過去的幾年里,特斯拉、Waymo和Uber等公司在自動駕駛領域的投入和研發引起了廣泛關注。盡管自動駕駛技術有望改變交通行業,帶來諸多便利,但在其廣泛應用之前,我們還需要解決許多關鍵問題和挑戰。本文將重點關注自動駕駛規控決策方面的問題和挑戰,分析當前所面臨的困境,并提出一些建設性的建議與解決方案。
我們首先將深入剖析目前在制定自動駕駛規控策略過程中所面臨的問題和挑戰,如模型泛化、安全性可靠性、計算效率等。最后,結合國內外的先進經驗與實踐,我們將提出一系列可能的解決方案,以期為自動駕駛技術的發展和普及提供有益的參考。
通過本文的闡述,我們希望能夠提高人們對自動駕駛規控決策問題和挑戰的認識,促使業界加強合作與溝通,共同應對未來自動駕駛技術帶來的挑戰,為人類社會帶來更為安全、高效、可持續的交通出行方式。
01.
規控決策的重要性
規控決策在自動駕駛領域的重要性不容忽視,因為它直接影響到自動駕駛技術實際應用的成功與否。首先,規控決策對于確保自動駕駛車輛的安全性至關重要,通過合理的規控,可以有效地降低交通事故的發生率,確保人們的生命財產安全。其次,高效的規控決策有助于提升道路通行效率,緩解交通擁堵,降低能源消耗和尾氣排放,從而為實現可持續交通發展做出貢獻。
此外,規控決策還需要充分考慮法規合規性,這意味著自動駕駛技術的發展必須在法律框架內進行,以確保道路安全并維護公共利益。規范的規控決策將有助于引導自動駕駛技術朝著更加合規、安全的方向發展。同時,公眾對自動駕駛技術的信任度也是衡量規控決策重要性的一個關鍵因素。通過透明、合理的規控,可以加強公眾對自動駕駛技術的信任,為其更廣泛的應用奠定基礎。
綜上所述,規控決策在自動駕駛領域具有舉足輕重的地位。它關乎自動駕駛系統的安全性、效率、法規合規性以及公眾接受度,為實現自動駕駛技術的成功實施與廣泛應用提供關鍵支持。因此,深入研究規控決策問題,尋求有效的解決方案,是推動自動駕駛技術健康發展的重要任務。
問題與挑戰:
在接下來的文章中,我們將深入探討當前決策規劃在自動駕駛領域所面臨的問題與挑戰,以及相關的潛在解決方向和趨勢。我們將重點關注以下幾個方面:
1.模型泛化
2.不確定性估計,數據質量和數量評估
3.多智能體與智能體-環境交互
4.安全與可靠性
5.計算效率
6.利用多模態融合進行最優決策
7.可解釋性和可說明性
8.無需高清地圖的自動駕駛
9.與現有基礎設施的集成
在上一篇文章中,我們著重分析了模型泛化、不確定性估計以及數據質量和數量評估和多智能體與智能體-環境交互三個方面。本篇文章我們將繼續分析決策規劃在自動駕駛領域所面臨的問題與挑戰,著重于安全與可靠性、計算效率和利用多模態融合進行最優決策這三個方面。
02.
安全與可靠性
自動駕駛汽車必須能夠在各種復雜且難以預測的場景中做出安全、可靠且值得信賴的決策[1]。這些決策必須在實時的情況下以及有限的信息條件下進行,并且必須考慮到道路上其他行駛主體的行為。這包括設計能夠檢測并從故障中恢復的系統,以及用于在各種場景中測試和驗證系統性能的方法。
自動駕駛汽車在各種錯綜復雜且充滿不確定性的場景中,必須具備做出安全、穩定且可信賴的決策能力。這意味著在實時動態環境中,自動駕駛汽車需要根據有限的信息條件迅速地做出恰當的決策,并且須充分考慮道路上其他行駛主體的行為,確保行車安全。為了達到這一目標,需要設計先進的算法和機制,以防止可能發生的事故。此外,為了不斷提升自動駕駛系統的性能,研究人員需制定一套全面且嚴謹的測試和驗證方法,以便在各種實際場景中檢驗系統性能。這包括在模擬環境中進行大量實驗,以及在實際道路條件下進行實車測試,以確保自動駕駛汽車在不同情境下都能表現出卓越的性能。總之,自動駕駛汽車在面對復雜且難以預測的場景時,需要做出安全、可靠且值得信賴的決策。為實現這一目標,設計先進的算法和機制,以及制定嚴格的測試和驗證方法,都是關鍵的研究方向。
子挑戰
1.自動駕駛汽車決策的驗證和確認:在復雜且不斷變化的環境中,驗證和確認基于深度學習模型的自動駕駛汽車決策行為可能頗具挑戰性。由于深度學習模型的內在復雜性和不透明性,傳統的測試和驗證方法很可能無法充分保證自動駕駛汽車決策的安全性和可靠性。
2.受外部數據影響的安全性:自動駕駛汽車的性能和安全性很大程度上取決于其準確感知周圍環境并處理外部數據的能力。然而,這些車輛可能會遭遇到不完整、不準確或錯誤的外部數據,這為算法的開發帶來了極大的挑戰。因此,如何開發具有魯棒性和容錯性的算法,使得自動駕駛汽車能夠在各種異常情況下保持行駛安全,是當前研究的一個重要方向。
3.在云端外部模型決策存在的情況下的安全決策:在云端外部模型決策存在的情況下,如何確保自動駕駛汽車做出安全決策是非常重要的問題。云端模型可以為自動駕駛汽車提供實時的交通信息、道路狀況等數據,幫助提升決策的準確性和效率。然而,在這一過程中,確保安全決策的實現面臨著一些挑戰。例如通信延遲與不穩定:當自動駕駛汽車依賴云端模型進行決策時,通信延遲和不穩定可能對決策的實時性產生影響;數據安全與隱私保護:在云端決策過程中,自動駕駛汽車需要與云端服務器進行數據交換,這就涉及到數據安全和隱私保護問題;魯棒性與容錯性:自動駕駛汽車在依賴云端模型進行決策時,必須具備應對云端服務中斷或其他異常情況的能力。
潛在的解決方案和趨勢
1.安全規則方法與深度學習技術的結合?[3]:這種結合策略旨在充分發揮兩種方法各自的優勢,為自動駕駛汽車提供更高的安全性能和決策能力。基于規則的方法具有較高的透明度和可解釋性,使得研究人員和工程師能夠更容易地理解和評估自動駕駛系統的決策過程。這有助于及時發現潛在的問題,提高系統的安全性和可靠性。而深度學習技術在處理復雜場景和動態環境方面具有很高的靈活性和適應性。通過結合基于規則的方法,自動駕駛汽車可以在遵循預設安全規則的前提下,靈活應對各種不確定和變化的道路條件,實現更加高效的決策過程。同時基于規則的方法可以為深度學習模型提供結構化的知識和先驗約束,從而減少訓練時間和提高決策效率。
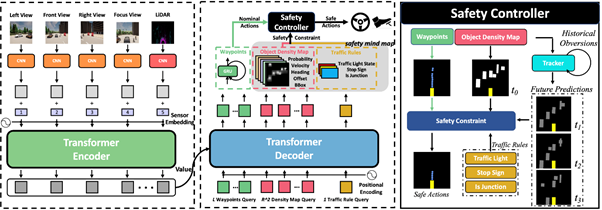
InterFuser[3]
2.模型檢查和定理證明,驗證決策方法的正確性:利用形式化方法,如模型檢查和定理證明,即便在存在不確定性和錯誤的情況下,也可以確保自動駕駛汽車在各種場景下的正確行為和決策。通過模型檢查和定理證明等形式化方法,可以對自動駕駛汽車決策系統的正確性進行嚴格驗證。這有助于在系統部署前發現并修復潛在的安全漏洞,從而確保其在實際應用中的安全性和可靠性。
3.對抗性訓練和異常檢測:為提高深度學習模型的魯棒性,可以采用諸如對抗性訓練和異常檢測的技術。對抗性訓練是一種訓練策略,通過在對抗性示例上訓練模型,提高模型在面對攻擊或干擾時的穩定性和魯棒性。這種方法有助于確保自動駕駛汽車在遇到極端或異常情況時仍能做出正確的決策。異常檢測技術可以幫助深度學習模型識別出意外輸入,并根據預設的安全策略作出適當的響應。這包括在檢測到異常情況時激活安全措施,如減速、剎車或轉向,以確保車輛和乘客的安全。
03.
計算效率
自動駕駛汽車必須能夠在實時、有限計算資源的條件下做出決策。為實現這一目標,我們需要開發能夠在高效、迅速執行的同時,保持準確和可靠性的決策方法。
子挑戰
1.模型復雜性導致訓練和評估成本高昂:自動駕駛的深度學習模型通常具有大量參數,這可能導致它們在計算上需要高昂的訓練和評估成本。自動駕駛系統需要處理多種復雜任務,如物體檢測、路徑規劃、車輛控制等。因此,深度學習模型需要具備足夠的表達能力來解決這些復雜問題。然而,隨著模型復雜性的增加,訓練所需的計算資源和時間成本也相應提高,這可能導致昂貴的硬件投資、電力消耗和人力成本。此外,訓練過程可能需要大量的標注數據,而獲取和標注這些數據也需要投入大量的人力和時間。評估復雜模型的性能可能同樣需要耗費大量的計算資源和時間。為了確保自動駕駛汽車的安全性和可靠性,評估過程需要在多種場景和環境下進行,這可能包括成千上萬個不同的測試用例。
2.實時處理與模型推斷,因為自動駕駛汽車必須在毫秒級時間尺度上做出決策:自動駕駛系統需要實時處理來自各種傳感器的數據,并在極短的時間內做出正確決策。這對于那些可能需要大量計算時間的深度學習模型來說,是一個巨大的挑戰。自動駕駛汽車在行駛過程中需要實時識別和響應各種復雜的道路條件、交通狀況以及其他道路用戶。為確保安全性和準確性,系統需要在毫秒級時間尺度內完成數據處理和決策推斷。深度學習模型在處理大量參數和計算復雜度時,可能需要較長時間進行推斷。這可能導致自動駕駛汽車在實時場景中無法滿足決策速度的要求。
3.便攜式NPU設備中的計算和內存資源限制:自動駕駛系統通常部署在資源受限的平臺上,如嵌入式系統或移動設備,這可能限制可用的計算能力和內存。在便攜式NPU設備上運行自動駕駛系統,需要在有限的計算資源和內存空間內完成各種任務,如圖像識別、路徑規劃和控制。這些限制可能導致模型性能下降或響應速度減緩,從而影響整體系統的可靠性和安全性。便攜式NPU設備的計算能力相對于高性能GPU或服務器來說較低,可能無法滿足復雜深度學習模型的實時推斷需求。同時,便攜式NPU設備的內存容量有限,可能無法容納大型深度學習模型。此外,內存帶寬和訪問速度的限制也可能導致模型推斷速度降低。
潛在的解決方案和趨勢
1. 剪枝、量化和知識蒸餾:開發優化深度學習模型的技術,如剪枝、量化和知識蒸餾,以減小模型的尺寸并提高其效率。這些技術有助于減少運行模型所需的計算量,使模型更適合實時處理。剪枝方法通過消除模型中不重要或冗余的參數(例如權重或神經元),來減少模型的計算量和內存需求?[5]。常見的剪枝策略包括權重剪枝(移除較小權重)和結構化剪枝(移除整個神經元或通道)。這些策略可以在保持模型性能的同時,顯著降低模型復雜度。量化方法通過減少表示模型參數所需的位數來降低模型尺寸。例如,將32位浮點數轉換為16位或更低位數的整數。量化可以顯著減小模型大小,降低內存占用和計算需求,同時僅引入較小的精度損失。知識蒸餾是一種模型壓縮技術,通過將一個大型、復雜的“教師模型”所學到的知識傳遞給一個較小、簡單的“學生模型”。這種方法通過讓學生模型模擬教師模型的輸出概率分布,從而使學生模型在保持較小尺寸的同時,獲得與教師模型相近的性能?[6]?[7]。
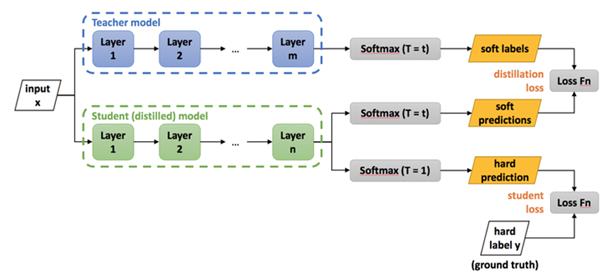
知識蒸餾通用框架?[8]
2. ?硬件加速:專用硬件,如圖形處理器(GPU)、張量處理器(TPU)和現場可編程邏輯門陣列(FPGA),為深度學習模型提供了強大的計算加速能力。借助這些專用硬件,模型能夠更高效地運行,延遲大幅降低,從而更適應實時處理場景。GPU:圖形處理器(GPU)具有大量的并行處理單元,可同時執行多個計算任務。這使得GPU非常適合處理深度學習模型中的矩陣和張量運算。相較于傳統的中央處理器(CPU),GPU能顯著提高模型的計算速度和效率。張量處理器(TPU)是專為深度學習應用設計的定制硬件加速器。TPU專注于執行深度學習模型中的矩陣和向量運算,通常比GPU在性能和能效方面更具優勢。TPU可以進一步提升模型的實時推斷??速度,從而滿足自動駕駛汽車的實時決策需求。現場可編程邏輯門陣列(FPGA)是一種可重新配置的硬件平臺,可以根據特定應用需求定制硬件邏輯。FPGA在深度學習領域的優勢在于其靈活性和低功耗。通過為特定模型定制硬件邏輯,FPGA可以實現高效的計算性能,同時降低能耗。
3.稀疏表示和神經網絡結構搜索:稀疏表示是一種高效的數據表示方法,它通過僅使用少量非零元素來精確地表示數據。這種方法可以有效地壓縮輸入數據并降低模型所需的計算量。對于深度學習模型來說,稀疏表示可以應用于權重矩陣、激活矩陣或其他相關參數,從而提高計算效率并降低內存需求。神經網絡結構搜索(Neural Architecture Search,NAS)是一種自動化技術,用于尋找最佳的神經網絡結構和超參數組合。NAS的目標是在維持模型性能的同時,找到具有更高計算效率的網絡結構。這些結構可能包括不同的層數、神經元數量、激活函數等。通過利用NAS,研究人員可以為自動駕駛汽車設計更高效且計算需求更低的深度學習模型。
4.稀疏模型、壓縮感知、降維(PCA/VAE):高效的數據管理技術有助于降低自動駕駛系統的計算和內存需求。例如,可以通過稀疏模型、壓縮感知、降維(PCA/VAE)等多種方法預處理或壓縮數據,以減少運行時所需的存儲和計算量。通過構建稀疏模型,可以減少模型參數的數量,從而降低計算和存儲需求。稀疏模型利用數據的稀疏性質,僅在關鍵參數上分配非零權重,以實現較低的計算復雜度和內存占用。壓縮感知是一種數據采樣技術,通過在少量樣本上恢復信號或圖像信息,以達到減少數據量的目的。這種方法可以有效地壓縮數據,降低自動駕駛系統的計算和存儲需求。降維技術則是通過將高維數據投影到低維空間,從而減少數據的維度和復雜性。主成分分析(PCA)和變分自編碼器(VAE)是兩種常用的降維方法,可以在保留數據中的關鍵信息的同時,降低其存儲和計算需求。
04.
利用多模態融合進行最優決策
在自動駕駛領域中,實現多模態融合以制定最優決策是一項巨大的挑戰。自動駕駛汽車必須具備根據來自各種傳感器和信息源的數據進行決策的能力,這些傳感器和信息源包括相機、激光雷達、雷達、GPS和地圖等。然而,在實際應用中,這些不同的信息源可能會提供相互矛盾或不完整的信息,這進一步增加了確定最優決策的難度。
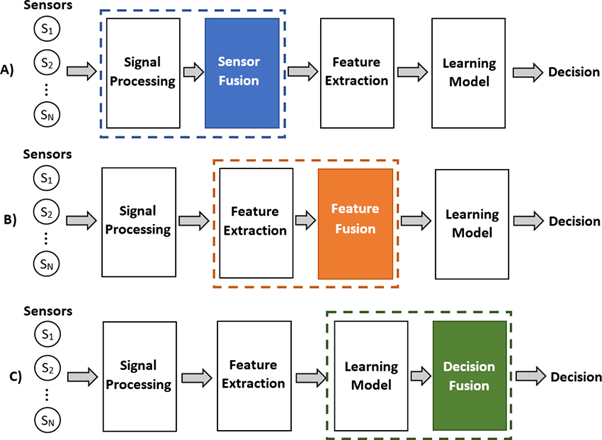
三種融合[9]
子挑戰
1.數據預處理以最大化多模態融合中的信息信號:在自動駕駛領域,收集的數據需要經過預處理過程來消除噪聲、異常值和不一致性,從而確保決策的準確性和可靠性。然而,針對不同類型的數據進行有效預處理是一項頗具挑戰性的任務,因為各種數據類型可能需要應用不同的預處理技術
2.來自多個傳感器的多模態數據集成:多模態數據集成主要涉及將來自不同傳感器和信息源(如相機、激光雷達、雷達、GPS和地圖)的數據高效地整合在一起,同時要盡量減少噪聲、冗余和不一致性。
3.從具有不同特征的多模態輸入數據中提取特征:不同模態(如視覺、雷達和激光雷達等)的數據具有各自獨特的特點,因此識別能夠幫助自動駕駛系統做出最優決策的關鍵特征至關重要,挑戰在于識別可用于做出最優決策的最相關特征。
4.設計模型以最大化融合特征對最終決策的貢獻:設計一個能夠處理多模態數據的深度學習模型是一項復雜的任務。這樣的模型不僅需要處理各種不同類型的數據,還需要以最優方式融合它們。此外,為了適應可能未在訓練數據中出現的新場景,模型必須具備一定的泛化能力。
潛在的解決方案和趨勢
1.數據增強、過濾和歸一化:研究人員可以使用高級數據預處理技術,如數據增強、過濾和歸一化,以消除噪聲和異常值。這有助于確保數據質量高,并可用于最優決策。數據增強技術通過對原始數據進行變換和擴展,以產生具有多樣性和代表性的新數據?[10]。這些變換包括旋轉、縮放、翻轉、平移等,能夠增加模型的泛化能力,提高其在面對新場景時的性能。在自動駕駛領域,數據增強有助于模型更好地適應不同的道路條件、光線和天氣狀況。過濾技術可以去除數據中的噪聲和異常值,使模型專注于學習有意義和關鍵的特征。在自動駕駛系統中,過濾可以通過傳統的信號處理方法(如卡爾曼濾波器、中值濾波器等)或機器學習算法(如支持向量機、隨機森林等)實現,從而提高模型的準確性和穩定性。歸一化技術可以將來自不同傳感器和數據源的數據統一到一個共同的尺度上,以消除數據分布的差異。這樣可以簡化模型的訓練過程,加快收斂速度,并提高模型的可靠性。
2.使用融合模型進行數據集成:融合模型旨在將多種數據源的信息融合到一個統一的表示中,以便為自動駕駛系統提供更準確和可靠的決策依據。這些模型可以是基于機器學習的方法(如多層感知器、支持向量機等)或深度學習的方法(如卷積神經網絡、循環神經網絡等)。通過對多種傳感器(如相機、激光雷達、雷達和GPS)的數據進行融合,這些模型可以捕捉到更豐富和更具辨識度的環境特征從而優化決策。
3.基于領域特定知識或設計的物理知識引導深度網絡進行特征提取:在提取特征時,一種有效的方法是利用深度學習模型自動從多模態數據中挖掘相關特征。此外,研究人員還可以結合領域特定知識和物理原理來引導深度學習網絡的特征提取過程,從而更精準地識別對最優決策具有關鍵作用的特征。這種方法有助于提高自動駕駛系統在處理復雜場景時的準確性和魯棒性。
4.對于具有相似數據格式的輸入采用并行子模型處理:為解決模型設計的挑戰,可以考慮使用并行子模型來分別處理具有相似數據格式的多模態輸入。這些子模型可以采用高級深度學習架構,如卷積神經網絡(CNN)、循環神經網絡(RNN)和注意力機制等。這些架構有助于更有效地處理和融合多模態數據,進而實現最優決策。此外,通過將這些子模型的輸出進行適當整合,可以構建一個高效且魯棒的自動駕駛系統。 05. 小結 本文主要討論了自動駕駛領域的三個關鍵問題:安全與可靠性、計算效率以及利用多模態融合進行最優決策。在安全與可靠性方面,我們探討了如何采用多種方法,如安全規則方法與深度學習技術的結合、模型檢查和定理證明、對抗性訓練和異常檢測,來確保自動駕駛汽車在各種道路和環境條件下的安全行駛。在計算效率方面,我們強調了通過剪枝、量化、知識蒸餾等技術來降低計算需求,從而提高系統的實時性和效率。在利用多模態融合進行最優決策方面,我們關注了如何整合來自多種傳感器和信息源的數據,實現高效的決策過程。
參考文獻:
[1]M. Martínez-Díaz and F. Soriguera, “Autonomous vehicles: theoretical and practical challenges,” Transportation Research Procedia, vol. 33, pp. 275-282, 2018.
[2]K. Khalaf, “Autonomous Cars- Technologies & Safety,” 30 05 2017. [Online]。 Available: https://medium.com/@kylekhalaf/autonomous-cars-technologies-safety-8b87380af5e8. [Accessed 03 05 2023]。
[3]H. Shao, L. Wang, R. Chen, H. Li and Y. Liu, “InterFuser: Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer,” in 2022 Conference on Robot Learning, Auckland, 2022.
[4]T. B. Brown and C. Olsson, “Introducing the Unrestricted Adversarial Examples Challenge,” Google, 13 09 2018. [Online]。 Available: https://ai.googleblog.com/2018/09/introducing-unrestricted-adversarial.html. [Accessed 03 05 2023]。
[5]J. I. Choi and Q. Tian, “Visual Saliency-Guided Channel Pruning for Deep Visual Detectors in Autonomous Driving,” arXiv preprint arXiv:2303.02512, 2023.
[6]Q. Lan and Q. Tiany, “Adaptive Instance Distillation for Object Detection in Autonomous Driving,” arXiv preprint arXiv:2201.11097, 2022.
[7]C. Sautier, G. Puy, S. Gidaris, A. Boulch, A. Bursuc and R. Marlet, “Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data,” in The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), Louisiana, 2022.
[8]03 07 2021. [Online]。 Available: https://zhuanlan.zhihu.com/p/384521670. [Accessed 03 05 2023]。
[9]E. Debie, R. Fernandez Rojas, J. Fidock, M. Barlow, K. Kasmarik, S. Anavatti, M. Garratt and H. A. Abbass, “Multimodal Fusion for Objective Assessment of Cognitive Workload: A Review,” IEEE Transactions on Cybernetics, vol. 51, pp. 1542-1555, 2021.
[10]S. Y. Feng, V. Gangal, J. Wei, S. Chandar, S. Vosoughi, T. Mitamura and E. Hovy, “A Survey of Data Augmentation Approaches for NLP,” in The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021), Thailand, 2021.
[11]21 04 2019. [Online]。 Available: https://zhuanlan.zhihu.com/p/61759947. [Accessed 03 05 2023]。
[12][Online]。 Available: https://blog.ml.cmu.edu/2020/08/31/6-interpretability/。
[13][Online]。 Available: https://www.engineering.com/story/systems-engineering-will-skyrocket-the-world-to-autonomous-vehicles.
[14][Online]。 Available: https://come-in.fr/les-avantages-de-la-5g-pour-les-entreprises/.
? ? ? ? ?編輯:黃飛








 工商網監
工商網監
評論