 電子發燒友App
電子發燒友App


本文針對自動駕駛行業的視覺感知做簡要介紹,從傳感器端的對比,到數據的采集標注,進而對感知算法進行分析,給出各個模塊的難點和解決方案,最后介紹感知模塊的主流框架設計。
視覺感知系統主要以攝像頭作為傳感器輸入,經過一系列的計算和處理,對自車周圍的環境信息做精確感知。目的在于為融合模塊提供準確豐富的信息,包括被檢測物體的類別、距離信息、速度信息、朝向信息,同時也能夠給出抽象層面的語義信息。所以道路交通的感知功能主要包括以下三個方面:
動態目標檢測(車輛、行人和非機動車)
靜態物體識別(交通標志和紅綠燈)
可行駛區域的分割(道路區域和車道線)
這三類任務如果通過一個深度神經網絡的前向傳播完成,不僅可以提高系統的檢測速度,減少計算參數,而且可以通過增加主干網絡的層數的方式提高檢測和分割精度。如下圖所示:可以將視覺感知任務分解成目標檢測、圖像分割、目標測量、圖像分類等。
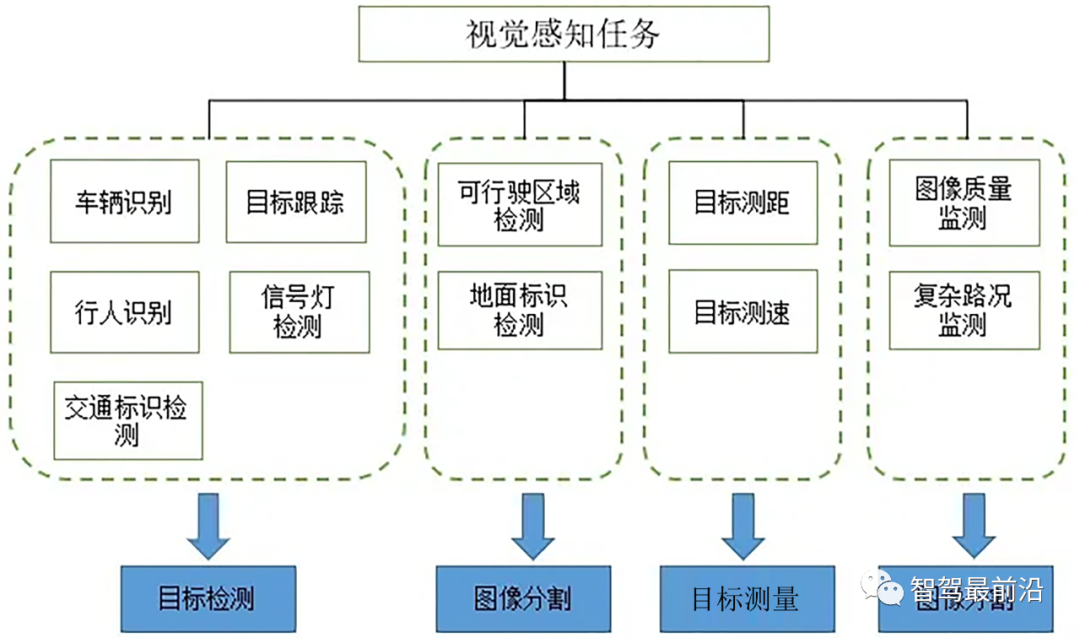
▍傳感器組件
前視線性相機
視角較小,一般采用52°左右的相機模組安裝于車輛前擋風玻璃中間,主要用來感知車輛前方較遠的場景,感知距離一般為120米以內。
?
周視廣角相機
視場角相對較大,一般采用6顆100°左右的相機模組安裝在車輛周圍一圈,主要用來感知360°的周身環境(安裝方案與特斯拉大同小異)。廣角相機存在一定的畸變現象,如下圖所示:
?
環視魚眼相機
環視魚眼相機視角較大,可以達到180°以上,對近距離的感知較好,通常用于APA,AVP等泊車場景,安裝于車輛左右后視鏡下方以及前后車牌下方等4個位置做圖像的拼接、車位檢測、可視化等功能。
?
▍相機標定
相機標定的好壞直接影響目標測距的精度,主要包括內參標定和外參標定。
內參標定用于做圖像的畸變校正,外參標定用于統一多個傳感器的坐標系,將各自的坐標原點移動到車輛后軸中心處。
最耳熟能詳的標定方法就是張正友的棋盤格方法,在實驗室里一般會做一個棋盤格板子標定相機,如下圖:

出廠標定
但是自動駕駛做前裝量產,由于批量生產的緣故,無法一輛輛使用標定板做標定,而是構建一個場地用于車輛出廠時標定,如下圖所示:
?
在線標定
另外考慮到車輛運行一段時間或者在顛簸的過程中攝像頭位置的偏移,感知系統中也有在線標定的模型,常利用消失點或車道線等檢測得到的信息實時更新俯仰角的變化。
▍數據標注
自然道路場景存在各種各樣的突發狀況,所以需要采集大量的實車數據用來訓練。高質量的數據標注成了一件至關重要的工作,其中感知系統需要檢測的全部信息均需要進行標注。標注形式包括目標級標注和像素級標注: ?
目標級標注如下圖:
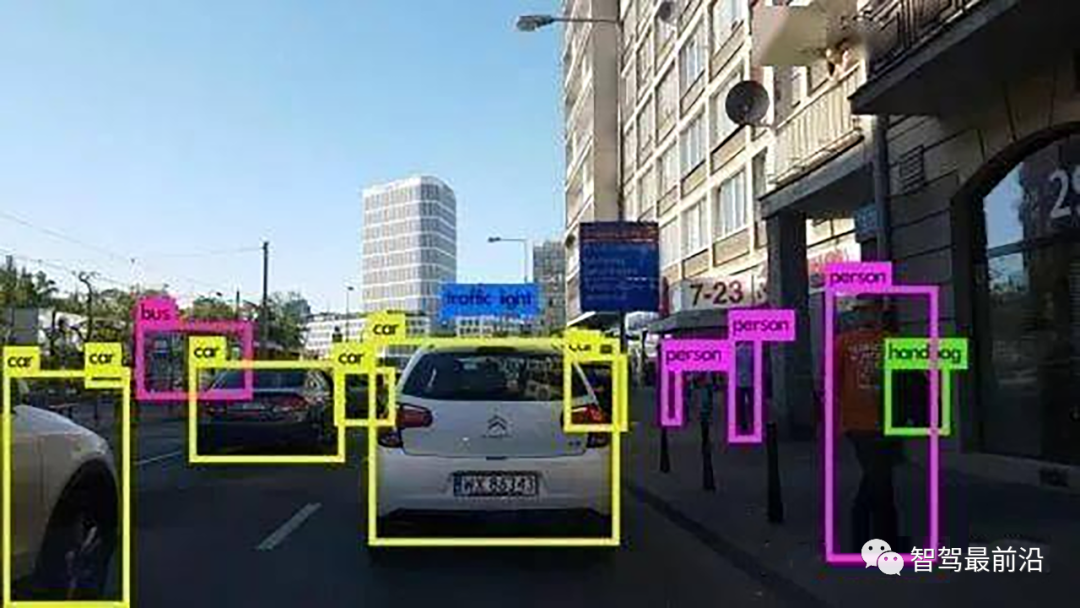
像素級標注如下圖:

由于感知系統中的檢測和分割任務常采用深度學習的方式實現,而深度學習是一項數據驅動的技術,所以需要大量的數據和標注信息進行迭代。為了提高標注的效率,可以采用半自動的標注方式,通過在標注工具中嵌入一個神經網絡用于提供一份初始標注,然后人工修正,并且在一段時間后加載新增數據和標簽進行迭代循環。
▍功能劃分
視覺感知可以分為多個功能模塊,如目標檢測跟蹤、目標測量、可通行區域、車道線檢測、靜態物體檢測等。
目標檢測跟蹤
對車輛(轎車、卡車、電動車、自行車)、行人等動態物體的識別,輸出被檢測物的類別和3D信息并對幀間信息做匹配,確保檢測框輸出的穩定和預測物體的運行軌跡。神經網絡直接做3D回歸準確度不高,通常會對車輛拆分成車頭,車身,車尾,輪胎多個部位的檢測拼成3D框。
?
目標檢測難點: 遮擋情況較多,朝向角準確性問題 行人車輛類型種類較多,容易誤檢 多目標追蹤,ID切換的問題;
對于視覺目標檢測,在惡劣天氣環境下,感知性能會有一定的下降;在夜晚燈光昏暗時,容易出現漏檢的問題。如果結合激光雷達的結果進行融合,對于目標的召回率會大幅提高。
目標檢測方案:
多目標的檢測尤其是車輛的檢測,需要給出車輛的3D Bounding Box,3D的好處在于能給出車的一個朝向角信息,以及車的高度信息。通過加入多目標跟蹤算法,給車輛及行人對應的ID號。
深度學習作為一種概率形式的算法,即使提取特征能力強大,也不能覆蓋掉所有的動態物體特征。在工程開發中可以依據現實場景增加一些幾何約束條件(如汽車的長寬比例固定,卡車的長寬比例固定,車輛的距離不可能突變,行人的高度有限等)。
增加幾何約束的好處是提高檢測率,降低誤檢率,如轎車不可能誤檢為卡車。可以訓練一個3D檢測模型(或者2.5D模型)再配合后端多目標追蹤優化以及基于單目視覺幾何的測距方法完成功能模塊。
目標測量
目標測量包括測量目標的橫縱向距離,橫縱向速度等信息。根據目標檢測跟蹤的輸出借助地面等先驗知識從2D的平面圖像計算車輛等動態障礙物的距離信息、速度信息等或者通過NN網絡直接回歸出現世界坐標系中的物體位置。如下圖所示:
?
單目測量難點:
如何從缺乏深度信息的單目系統中計算出 方向上的物體距離。那么我們需要弄清楚以下幾個問題:
有什么樣的需求
有什么樣的先驗
有什么樣的地圖
需要做到什么樣的精度
能夠提供什么樣的精力
如果大量依賴模式識別技術來彌補深度的不足。那么模式識別是否足夠健壯能滿足串行生產產品的嚴格檢測精度要求?
單目測量方案:
其一,就是通過光學幾何模型(即小孔成像模型)建立測試對象世界坐標與圖像像素坐標間的幾何關系,結合攝像頭內、外參的標定結果,便可以得到與前方車輛或障礙物間的距離;
其二,就是在通過采集的圖像樣本,直接回歸得到圖像像素坐標與車距間的函數關系,這種方法缺少必要的理論支撐,是純粹的數據擬合方法,因此受限于擬合參數的提取精度,魯棒性相對較差。
可通行區域
對車輛行駛的可行駛區域進行劃分主要是對車輛、普通路邊沿、側石邊沿、沒有障礙物可見的邊界、未知邊界進行劃分,最后輸出自車可以通行的安全區域。
?
道路分割難點:
復雜環境場景時,邊界形狀復雜多樣,導致泛化難度較大。不同于其它的檢測有明確的檢測類型(如車輛、行人、交通燈),通行空間需要把本車的行駛安全區域劃分出來,需要對凡是影響本車前行的障礙物邊界全部劃分出來,如平常不常見的水馬、錐桶、坑洼路面、非水泥路面、綠化帶、花磚型路面邊界、十字路口、T字路口等進行劃分。
標定參數校正;在車輛加減速、路面顛簸、上下坡道時,會導致相機俯仰角發生變化,原有的相機標定參數不再準確,投影到世界坐標系后會出現較大的測距誤差,通行空間邊界會出現收縮或開放的問題。
邊界點的取點策略和后處理;通行空間考慮更多的是邊緣處,所以邊緣處的毛刺,抖動需要進行濾波處理,使邊緣處更平滑。障礙物側面邊界點易被錯誤投影到世界坐標系,導致前車隔壁可通行的車道被認定為不可通行區域,
?
道路分割方案:
其一,相機標定(若能在線標定最好,精度可能會打折扣),若不能實現實時在線標定功能,增加讀取車輛的IMU信息,利用車輛IMU信息獲得的俯仰角自適應地調整標定參數;
其二,選取輕量級合適的語義分割網絡,對需要分割的類別打標簽,場景覆蓋盡可能的廣;使用極坐標的取點方式進行描點,并采用濾波算法平滑后處理邊緣點。
車道線檢測
車道線檢測包括對各類單側/雙側車道線、實線、虛線、雙線檢測,線型的顏色(白色/黃色/藍色)和特殊的車道線(匯流線、減速線等)檢測。如下圖所示:
?
車道線檢測難點:
線型種類多,不規則路面檢測車道線難度大;如遇地面積水、無效標識、修補路面、陰影情況下的車道線容易誤檢、漏檢。
上下坡、顛簸路面,車輛啟停時,容易擬合出梯形、倒梯形的車道線。
彎曲的車道線、遠端的車道線、環島的車道線,車道線的擬合難度較大,檢測結果易閃爍;
車道線檢測方案:
其一,傳統的圖像處理算法需經過攝像頭的畸變校正,對每幀圖片做透視變換,將相機拍攝的照片轉到鳥瞰圖視角,再通過特征算子或顏色空間來提取車道線的特征點,使用直方圖、滑動窗口來做車道線曲線的擬合,傳統算法最大的弊端在于場景的適應性不好。
其二,采用神經網絡的方法進行車道線的檢測跟通行空間檢測類似,選取合適的輕量級網絡,打好標簽;車道線的難點在于車道線的擬合(三次方程、四次方程),所以在后處理上可以結合車輛信息(速度、加速度、轉向)和傳感器信息做航位推算,盡可能的使車道線擬合結果更佳。
靜態物體檢測
靜態物體檢測包括對交通紅綠燈、交通標志牌等靜態目標的檢測識別。
?
靜態物體檢測難點:
紅綠燈、交通標識屬于小物體檢測,在圖像中所占的像素比極少,尤其遠距離的路口,識別難度更大。在強光照的情況下,人眼都難以辨別,而停在路口的斑馬線前的汽車,需要對紅綠燈進行正確的識別才能做下一步的判斷。
交通標識種類眾多,采集到的數據易出現數量不均勻的情況。
交通燈易受光照的影響,在不同光照條件下顏色難以區分(紅燈與黃燈),且到夜晚時,紅燈與路燈、商店的燈顏色相近,易造成誤檢;
靜態物檢測方案:
通過感知去識別紅綠燈,效果一般,適應性差,條件允許的話(如固定園區限定場景),可以借助V2X/高精地圖等信息。多個備份冗余,V2X > 高精度地圖 > 感知識別。若碰上GPS信號弱的時候,可以根據感知識別的結果做預測,但是大部分情況下,V2X足以覆蓋掉很多場景。
▍共性問題
雖然感知子任務的實現是相互獨立的,但是它們之間上下游的依賴關系以及算法共性問題:
真值來源
定義,校準,分析比對,絕不是看檢測結果圖或幀率,需要以激光的數據或者RTK的數據作為真值來驗證測距結果在不同工況(白天、雨天、遮擋等情況下)的準確性;
資源消耗
多個網絡共存,多個相機共用都是要消耗cpu、gpu資源的,如何處理好這些網絡的分配,多個網絡的前向推理可能共用一些卷積層,能否復用;引入線程、進程的思想來處理各個模塊,更高效的處理協調各個功能塊;在多相機讀取這一塊,做到多目輸入的同時不損失幀率,在相機碼流的編解碼上做些工作。
多目融合
一般在汽車上會配備4個(前、后、左、右)四個相機,對于同一物體從汽車的后方移動到前方,即后視相機可以看到,再移至側視相機能看到,最后移至前視相機能看到,在這個過程中,物體的id應保持不變(同一個物體,不因相機觀測的變化而改變)、距離信息跳變不宜過大(切換到不同相機,給出的距離偏差不宜太大,)
場景定義
針對不同的感知模塊,需要對數據集即場景定義做明確的劃分,這樣在做算法驗證的時候針對性更強;如對于動態物體檢測,可以劃分車輛靜止時的檢測場景和車輛運動時的場景。對于交通燈的檢測,可以進一步細分為左轉紅綠燈場景、直行紅綠燈、掉頭紅綠燈等特定場景。公用數據集與專有數據集的驗證。
▍模塊架構
目前開源的感知框架Apollo和Autoware,不少研究人員或者中小公司的感知系統開發會借鑒其中的思想,所以在這里介紹一下Apollo感知系統的模塊組成。
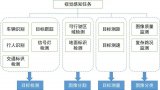
相機輸入-->圖像的預處理-->神經網絡-->多個分支(紅綠燈識別、車道線識別、2D物體識別轉3D)-->后處理-->輸出結果(輸出物體類型、距離、速度代表被檢測物的朝向)
即輸入攝像頭的數據,以每幀信息為基礎進行檢測、分類、分割等計算,最后利用多幀信息進行多目標跟蹤,輸出相關結果。整個感知流程圖如下:
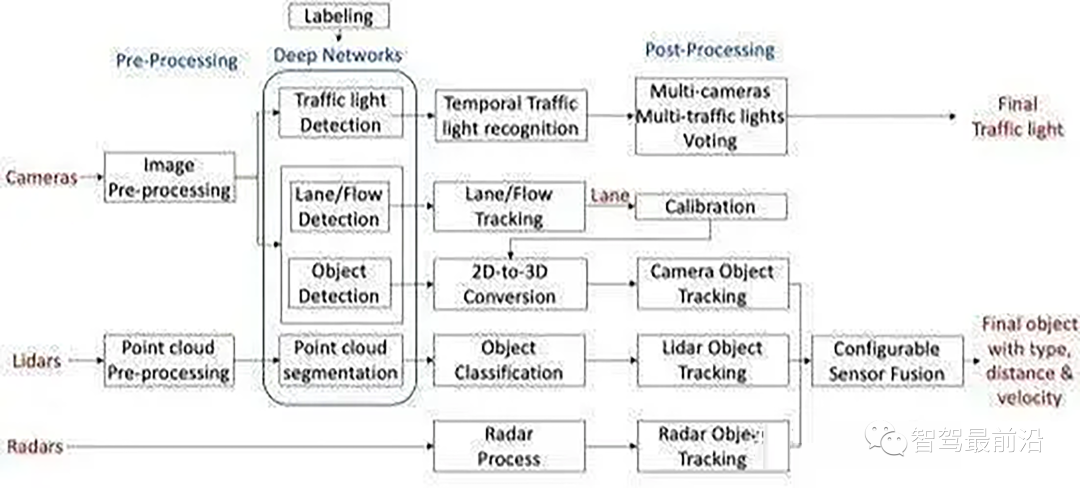
上述核心環節仍是神經網絡算法,它的精度、速度、硬件資源利用率都是需要衡量考慮的指標,哪一個環節做好都不容易,物體檢測最容易誤檢或漏檢、車道線檢測擬合4次方程曲線不容易、紅綠燈這類小物體檢測難度大(現有路口長度動則50米以上),通行空間的邊界點要求高。
?
審核編輯:黃飛
?










 工商網監
工商網監
評論