 電子發(fā)燒友App
電子發(fā)燒友App


人工智能領(lǐng)域邊緣側(cè)的應(yīng)用場景多種多樣,在功能、性能、功耗、成本等方面存在差異化的需求,因此一款優(yōu)秀的人工智能邊緣計(jì)算平臺(tái),應(yīng)當(dāng)具備靈活快速適配全場景的能力,能夠在安防、醫(yī)療、教育、零售等多維度行業(yè)應(yīng)用中實(shí)現(xiàn)快速部署。
百度大腦EdgeBoard嵌入式AI解決方案,以其豐富的硬件產(chǎn)品矩陣、自研的多并發(fā)高性能通用CNN(Convolution Neural Network)設(shè)計(jì)架構(gòu)、靈活多樣的軟核算力配置,搭配移動(dòng)端輕量級Paddle Lite高效預(yù)測框架,通過百度自定義的MODA (Model Driven Architecture)工具鏈,依據(jù)各應(yīng)用場景定制化的模型和算法特點(diǎn),向用戶提供高性價(jià)比的軟硬一體的解決方案,同時(shí)和百度大腦模型開發(fā)平臺(tái)(AIStudio、EasyDL)深度打通,實(shí)現(xiàn)模型的訓(xùn)練、部署、推理等一站式服務(wù)。
1. EdgeBoard計(jì)算平臺(tái)的多產(chǎn)品矩陣
EdgeBoard是基于Xilinx 16nm工藝Zynq UltraScale+ MPSoC的嵌入式AI解決方案,采用Xilinx異構(gòu)多核平臺(tái)將四核ARM Cortex-A53處理器和FPGA可編程邏輯集成在一顆芯片上,高性能計(jì)算板卡上搭載了豐富的外部接口和設(shè)備,具有開發(fā)板、邊緣計(jì)算盒、抓拍機(jī)、小型服務(wù)器、定制化解決方案等表現(xiàn)形態(tài)。
EdgeBoard計(jì)算卡產(chǎn)品可以分為FZ9、FZ5、FZ3三個(gè)系列,是基于Xilinx XCZU9EG、XAZU5EV、XAZU3EG研發(fā)而來,分別具有高性能,視頻硬解碼,低成本等特點(diǎn),同時(shí)還有不同的DDR容量版本。以上三個(gè)版本PS側(cè)同樣采用四核Cortex-A53 、雙核Cortex-R5、以及GPU Mali-400MP2等處理器配置,PS到PL的接口均為12x32/64/128b AXI Ports,主要的區(qū)別在于PL側(cè)擁有的芯片邏輯資源大小不同,可參見下表。
采用上述三種標(biāo)準(zhǔn)產(chǎn)品的硬件板卡或者一致的硬件參考設(shè)計(jì),用戶可無縫適配運(yùn)行EdgeBoard公開發(fā)布的最新版標(biāo)準(zhǔn)鏡像,也可根據(jù)自身項(xiàng)目需求定制相關(guān)的硬件設(shè)計(jì),并進(jìn)一步根據(jù)性能、成本和功耗要求,以及其他功能模塊的集成需求,對軟核的算力和資源進(jìn)行個(gè)性化配置。(多款開發(fā)板適配視頻教程:https://ai.baidu.com/forum/topic/show/957750)
2. 高性能的通用CNN設(shè)計(jì)架構(gòu)
2.1 CNN加速軟核的整體設(shè)計(jì)框架
EdgeBoard的CNN加速軟核(整體的加速方案稱之為軟核)提供了一套計(jì)算資源和性能優(yōu)化的AI軟件棧,由上至下分別包括應(yīng)用層軟件API、計(jì)算加速單元的SDK調(diào)度管理、Paddle Lite預(yù)測框架基礎(chǔ)管理器、Linux操作系統(tǒng)、負(fù)責(zé)設(shè)備管理和內(nèi)存分配的驅(qū)動(dòng)層和CNN算子的專用硬件加速單元,用來完成卷積神經(jīng)網(wǎng)絡(luò)模型的加載、解析、優(yōu)化和執(zhí)行等功能。
這些主要組成部分在軟件棧中功能和作用相互依賴,承載著數(shù)據(jù)流、計(jì)算流和控制流。基于上圖設(shè)計(jì)框架,EdgeBoard的AI軟件棧主要分為4個(gè)層次:
?應(yīng)用使能層
面向用戶的應(yīng)用級(APP)封裝,主要是面向計(jì)算機(jī)視覺領(lǐng)域提供圖像處理和神經(jīng)網(wǎng)絡(luò)推理的業(yè)務(wù)執(zhí)行API。
?執(zhí)行框架層
Paddle Lite預(yù)測框架提供了神經(jīng)網(wǎng)絡(luò)的執(zhí)行能力,支持模型的加載、卸載、解析和推理計(jì)算執(zhí)行。
?調(diào)度使能層
SDK調(diào)度使能單元負(fù)責(zé)給硬件派發(fā)算子層面的任務(wù),完成算子相應(yīng)任務(wù)的調(diào)度、管理和分發(fā)后,具體計(jì)算任務(wù)的執(zhí)行由計(jì)算資源層啟動(dòng)。
計(jì)算資源層
專用計(jì)算加速單元搭配操作系統(tǒng)和驅(qū)動(dòng),作為CNN軟核的計(jì)算資源層,主要承載著部分CNN算子的高密度矩陣計(jì)算,可以看作是Edgeboard的硬件算力基礎(chǔ)。
2.2 CNN算子的加速分類
專用計(jì)算加速單元基于FPGA的可編程邏輯資源開發(fā)實(shí)現(xiàn),采用ARM CPU和FPGA共享內(nèi)存的方式,通過高帶寬DMA(Direct Memory Access)實(shí)現(xiàn)二者數(shù)據(jù)的高速交互,共享內(nèi)存也并作為異構(gòu)計(jì)算平臺(tái)各算子數(shù)據(jù)在CPU和FPGA協(xié)同處理的橋梁,減少了數(shù)據(jù)在CPU與FPGA之間的重復(fù)傳輸。此外,CNN算子功能模塊可直接發(fā)起DDR讀寫操作,充分發(fā)揮了FPGA的實(shí)時(shí)響應(yīng)特性,減少了CPU中斷等待的時(shí)間消耗。
根據(jù)CNN算子的計(jì)算特點(diǎn),EdgeBoard的算子加速單元可劃分為如下兩類:
復(fù)雜算子加速單元
顧名思義,是指矩陣計(jì)算規(guī)則較為復(fù)雜,處理數(shù)據(jù)量較多,由于片上存儲(chǔ)資源限制,通常需要多次讀寫DDR并進(jìn)行分批處理的算子加速單元。
(1) 卷積(Convolution):包含常規(guī)卷積、空洞卷積、分組卷積、轉(zhuǎn)置卷積,此外全連接(Full Connection)也可通過調(diào)用卷積算子實(shí)現(xiàn)。
(2) 池化(Pooling):包含Max和Average兩種池化方式。
(3) 深度分離卷積(Depth-wise Convolution):與Pooling的處理特點(diǎn)類似,因此復(fù)用同樣的硬件加速單元,提高資源利用率。
(4) 矩陣元素點(diǎn)操作(Element-wise OP):可轉(zhuǎn)換為特定參數(shù)的Pooling操作,因此復(fù)用同樣的硬件加速單元,提高資源利用率。
(5) 歸一化函數(shù)(L2-Normalize):擁有較高處理精度,且實(shí)現(xiàn)資源最優(yōu)設(shè)計(jì)。
(6) 復(fù)雜激活函數(shù)(Softmax):與Normalize處理特點(diǎn)相似,復(fù)用同樣的硬件加速單元和處理流程,提高資源利用率。
通路算子加速單元
通路算子是指在復(fù)雜算子加速單元的計(jì)算數(shù)據(jù)寫回DDR的流水路徑上實(shí)現(xiàn)的算子,適合一些無需專門存儲(chǔ)中間結(jié)果,可快速計(jì)算并流出數(shù)據(jù)的簡單算子。
(1) 各類簡單激活函數(shù)(Relu, Relu6, Leaky-Relu, Sigmoid, Tanh):基本涵蓋了CNN網(wǎng)絡(luò)中常見的激活函數(shù)類型。
(2) 歸一化(Batch norm/Scale):通常用于卷積算子后的流水處理,也可支持跟隨在其他算子后的流水處理。
另外一種分類方式,是根據(jù)CNN網(wǎng)絡(luò)里的算子常用程度劃分為必配算子和選配算子,前者指CNN軟核必需的算子單元,通常對應(yīng)大部分網(wǎng)絡(luò)都涉及的算子,或者是芯片資源消耗極少的算子;后者指CNN軟核可以選擇性配置的算子單元,通常是特定的網(wǎng)絡(luò)會(huì)有的特定算子。這樣劃分的好處是,用戶根據(jù)MODA工具鏈自定義選擇,減少了模型中無用算子造成的邏輯資源的開銷和和功耗的增加。
必配算子:Convolution, Pooling, Element-Wise, Depth-Wise Convolution, BN/Scale, Relu, Relu6
選配算子:Normalize, Softmax, Leaky-Relu, Sigmoid, Tanh
2.3 卷積計(jì)算加速單元的設(shè)計(jì)思路
作為CNN網(wǎng)絡(luò)中比重最大、最為核心的卷積計(jì)算加速單元,是CNN軟核性能加速的關(guān)鍵,也占用了FPGA芯片的大部分算力分配和邏輯資源消耗。下面將針對EdgeBoard卷積計(jì)算加速單元的設(shè)計(jì)思路進(jìn)行簡要介紹,此章節(jié)也是理解CNN軟核算力彈性配置的技術(shù)基礎(chǔ)。
每一層網(wǎng)絡(luò)的卷積運(yùn)算,有M個(gè)輸入圖片(稱之為feature map,對應(yīng)著一個(gè)輸入通道),N個(gè)輸出feature map(N個(gè)輸出通道),M個(gè)輸入會(huì)分別進(jìn)行卷積運(yùn)算然后求和,獲得一幅輸出map。那么需要的卷積核數(shù)量就是M*N。
針對上述計(jì)算特點(diǎn),EdgeBoard的卷積單元采用脈動(dòng)陣列的數(shù)據(jù)流動(dòng)結(jié)構(gòu),將數(shù)據(jù)在PE之間通過寄存器進(jìn)行打拍操作,可以實(shí)現(xiàn)在第二個(gè)PE計(jì)算結(jié)果出來的同時(shí)完成和前一個(gè)PE的求和。這樣可以使數(shù)據(jù)在運(yùn)算單元的陣列中進(jìn)行流動(dòng),減少訪存的次數(shù),并且結(jié)構(gòu)更加規(guī)整,布線更加統(tǒng)一,提高系統(tǒng)工作頻率,避免了采用加法樹等并行結(jié)構(gòu)所造成的高扇出問題。
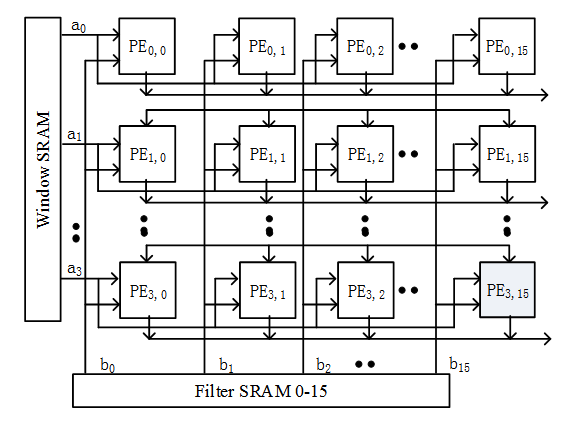
因此,如上圖所示,我們可以分別從Feature Map和Kernel兩個(gè)維度去定義脈動(dòng)陣列的并行結(jié)構(gòu)。從Feature Map的角度,縱向的行與行直接卷積窗口相互獨(dú)立,也就是輸出的每行之間所對應(yīng)的數(shù)據(jù)計(jì)算互不干擾,在此維度定義的多并發(fā)計(jì)算稱之為Window維度的并行度。從Kernel的角度,為了達(dá)到計(jì)算結(jié)果的快速流出減少片上緩存占用,我們設(shè)計(jì)了每個(gè)Kernel核之間的多并發(fā)計(jì)算,稱之為Kernel維度的并行度。以上兩個(gè)維度同時(shí)并發(fā)既可以提高整體并行計(jì)算效率,也充分利用了脈動(dòng)陣列的數(shù)據(jù)流水特性。
2.4 卷積計(jì)算加速單元的通用性擴(kuò)展
前一章節(jié)詳細(xì)介紹了基于PL實(shí)現(xiàn)的卷積計(jì)算加速單元的設(shè)計(jì)原理,那么如果是由于芯片的SRAM存儲(chǔ)資源不夠而導(dǎo)致的CNN網(wǎng)絡(luò)參數(shù)支持范圍較小,EdgeBoard將如何拓展CNN軟核的網(wǎng)絡(luò)支持通用性? 我們可以利用靈活的SDK調(diào)度管理單元提前將Feature Map或者Kernel數(shù)據(jù)進(jìn)行拆分,然后再執(zhí)行算子任務(wù)的下發(fā)。
一條滑窗鏈的Feature Map數(shù)據(jù)不夠存儲(chǔ)
SDK可以將一條滑窗鏈的Feature Map數(shù)據(jù)分成B塊,并將分塊數(shù)B和每個(gè)塊的數(shù)據(jù)量告訴卷積計(jì)算加速單元,那么后者則可以分批依次從DDR讀取B次Feature Map數(shù)據(jù),每次的數(shù)據(jù)量是可以存入到Image SRAM內(nèi)。
Kernel的總體數(shù)據(jù)不夠存儲(chǔ)
SDK可以將Kernel的數(shù)量分割成S份,使得分割后的每份Kernel數(shù)量可以下發(fā)到PL側(cè)的Filter SRAM中,然后SDK分別調(diào)度S次卷積算子執(zhí)行操作,所有的數(shù)據(jù)返回DDR后,再從通道(Channel)維度做這S次計(jì)算結(jié)果的數(shù)據(jù)拼接(Concat)即可。不過要注意的是,我們的Filter SRAM雖然不需存儲(chǔ)所有Kernel的數(shù)據(jù)量,但至少要保證能夠存儲(chǔ)一個(gè)Kernel的數(shù)據(jù)量。
由此看來,即使EdgeBoard三兄弟中最小的FZ3擁有極其有限的片上存儲(chǔ)資源,也是能夠很好地完成大多數(shù)CNN網(wǎng)絡(luò)的參數(shù)適配。
3.軟核算力的彈性配置
Edgeboard的CNN軟核除了公開發(fā)布的標(biāo)準(zhǔn)版本外,還可以由用戶根據(jù)自身模型需求和FPGA芯片選型,進(jìn)行CNN卷積計(jì)算單元算力的定制化配置。配置算力的兩個(gè)關(guān)鍵指標(biāo)包括Window維度并行度和Kernel維度并行度,具體含義可參考2.3章節(jié),此處不再贅述。
我們以卷積計(jì)算加速單元的核心矩陣乘加運(yùn)算消耗DSP硬核(Hard core)的個(gè)數(shù)作為CNN軟核核心算力的考察指標(biāo)。當(dāng)然,這并不包括卷積前處理、后處理模塊,以及其他算子加速單元或者用戶自定義功能模塊所消耗的DSP數(shù)量,因此這并不是整個(gè)解決方案在FPGA芯片內(nèi)部的DSP資源消耗。我們的設(shè)計(jì)可以支持Window并行度1-8的任意整數(shù),支持Kernel并行度包括4,8,16。具體的卷積雙維度配置組合所對應(yīng)的核心DSP消耗可以參見下表。
目前,EdgeBoard公開版針對卷積計(jì)算加速單元Window維度和Kernel維度的并行度配置,以及核心矩陣乘加運(yùn)算的DSP硬核消耗可參見下表。
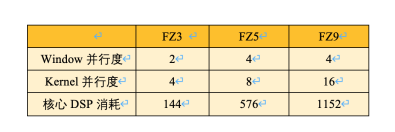
EdgeBoard的CNN軟核以其靈活的算力搭配組合以及算子可定制化的特點(diǎn),既可以根據(jù)具體模型的算子組合和所占比例,將一定成本和資源條件內(nèi)的芯片性能發(fā)揮到極致,還可以在滿足場景所要求性能的前提下減少不必要的功耗支出,此外還允許開發(fā)者縮減軟核尺寸并將芯片資源應(yīng)用于自定義功能的IP中,極大地增強(qiáng)了EdgeBoard人工智能多場景覆蓋的能力。

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論