 電子發燒友App
電子發燒友App


深度學習隨著AlphaGo大勝李世石之后被“神話”,很多人認為深度學習就是挑戰人類智力的“神器”。可是,深度學習真的如他們想象的那般“戰無不勝”嗎?本文編譯自hyperparameter.space,作者是Pablo Cordero,就讀于加利福尼亞大學圣克魯斯校區,主攻方向為細胞生物學和再生醫學背景下的應用機器學習研究。閱讀此文后,你便能夠從深層理解,為什么深度學習其實并不像普通百姓想象的那般“神”了,甚至,你還會發現它有時還有些“笨”。
我知道以一種較為消極的態度來作為博客的開頭是很奇怪的方式,但是在過去幾天里有一波討論,我認為這是關于我最近一直在思考的話題一個很好的切入點。這一切都從Jeff Leek在Simply Stats博客中發表了一篇關于在小樣本規模體系中使用深度學習的注意事項開始的。總之,他認為,當樣本量很小(這在生物領域頻繁發生)時,即使有一些層和隱藏單元,具有較少參數的線性模型的表現是優于深度網絡的。他還表示,當在一個使用僅僅80個樣本的MNIST數據集中進行0和1的分類時,一個具有十大最具特征值的非常簡單的線性預測器的表現要比一個簡單的深度網絡好得多。這促使Andrew beam寫出一篇文章來反駁,一個適當訓練的深度網絡能夠擊敗簡單的線性模型,即使是很少的訓練樣本。現如今頻繁出現的是,越來越多的生物醫學信息學研究人員正在使用深度學習來解決各種問題。這種肆無忌憚的宣傳是真的有效嗎?或者說這種線性模型是我們所需要的嗎?答案一如既往的是——這取決于先決條件。在這篇文章中,我想探索機器學習中的使用案例,實際上,深度學習并不是真正意義上對所有應用都有效,同時探索出我認為可以使得深度學習得到有效使用的解決想法,特別是針對新來者。
打破深度學習之偏見
首先,我們要剔除一些先入為主的偏見,很多圈外的人們還處于一知半解的狀態。有兩個廣泛的認知點,而我將要對這個更為技術性的做一個詳細說明。這有點像是對Andrew Beam在他的帖子中所完美地闡述的“誤解”部分的延伸。
深層學習確實可以在小樣本的情況下進行
深度學習是隨著大數據的背景下產生的(請牢記,第一個Google大腦項目正在向深度網絡提供大量YouTube視頻),并自此不斷地被宣稱運行在大量數據中的復雜算法。不幸的是,這個大數據/深度學習對不知為何也被誤解:在小樣本條件下不能使用的虛構體。如果你只有幾個樣本,在一個具有高樣本參數比例的神經網絡中進行開發,看起來似乎會出現過度擬合。然而,僅僅考慮給定問題的樣本容量和維度,無論是監督還是無監督,都幾乎是在真空中對數據進行建模的,而無需任何背景。可能的情況是,你擁有與你問題相關的數據源,或者該領域專家可以提供強有力的數據源,或者數據可以以非常特殊的方式進行構建(例如,以圖形或圖像編碼的方式進行)。在所有這些情況下,深度學習有機會成為一種可供選擇的方法——例如,你可以編碼較大的相關數據集的有用表示,并將其應用于你的問題中。這種經典的示例常見于自然語言處理,你可以學習大型語料庫中嵌入的詞語,然后將它們作為一個較小的、較窄的語料庫嵌入到一個監督的任務中。在極端情況下,你可以擁有一套神經網絡,共同學習一種表示方式,并在小型樣本中重用該表示的有效方式。這被稱為一次性學習(one-shot learning),并已經成功應用于包括計算機視覺和藥物發現在內的高維數據的許多領域當中。
藥物發現中的一次性學習神經網絡,摘自Altae-Tran et al. ACS Cent. Sci. 2017
深度學習不是一切的答案
我聽到最多的第二個偏見就是過度宣傳。許多尚未從事AI職業的人,期望深度網絡能夠給他們一個神話般的表現提升力,僅僅因為它在其他領域有效。其他人則從深度學習在圖像、音樂和語言(最貼近人類的三種數據類型)中的令人印象深刻的表現中受到鼓舞,并通過嘗試訓練最新的GAN架構,而匆匆一頭扎進這個領域。當然,在許多方面這種過度宣傳也是真實存在的。深度學習已經成為機器學習中不可否認的力量,也是數據建模者的重要工具。它的普及帶來了諸如tensorflow和pytorch等重要框架,它們即使是在深度學習之外也是非常有用的。失敗者的巨星崛起的故事激勵了研究人員重新審視其他以前模糊的方法,如進化方法和強化學習。但這不是萬能的。除了考慮天下沒有免費的午餐之外,深度學習模型可以非常細微,并且需要仔細,有時甚至是非常昂貴的超參數搜索、調整和測試(文章后續將有更多講解)。此外,有很多情況下,從實踐的角度來看,使用深度學習是沒有意義的,而更簡單的模型工作得更好。
深度學習不僅僅是.fit()
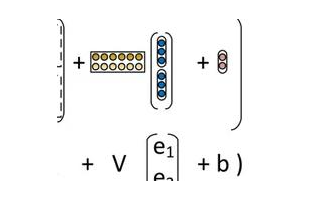
深度學習模型還有另外一個方面的應用,我認為在其他機器學習領域方面是有所損失的。大多數深度學習的教程和介紹性材料描述了這些模型由層次連接的節點層組成,其中第一層是輸入,最后一層是輸出,并且你可以使用某種形式的隨機梯度下降(SGD)來訓練它們。可能有一些簡要的介紹隨機梯度下降是如何工作的,以及什么是反向傳播,大部分解釋集中在神經網絡類型(卷積、循環等)。而優化方法本身卻沒有什么人關注,這是很不幸的,因為很有可能深度學習為什么能夠起作用的很大(如果不是最大的)一部分原因就是這些特定的方法(例如來自Ferenc Huszár’s的這篇文章和從該文中引用的論文,并且要知道,如何優化它們的參數,以及如何分割數據,從而有效地使用它們以便在合理的時間內獲得良好的收斂,是至關重要的。不過,為什么隨機梯度如此關鍵卻仍然是未知的,現在也或多或少地出現了一些線索。我最喜歡的一個是將該方法解釋為執行貝葉斯推理的一部分。實質上,每當你做某種形式的數值優化時,你都會用特定的假設和先驗來執行一些貝葉斯推理。實際上,有一個被稱為概率數值計算(probabilistic numerics)的整個領域,就是從這個角度出現的。隨機梯度下降是沒有什么不同,最新的研究成果表明,該程序實際上是一個馬爾可夫鏈,在某些假設下,可以看作是后向變分近似的靜態分布。所以當你停止你的SGD并采用最后的參數時,你基本上是從這個近似分布中抽樣的。我發現這個想法是有啟發性的,因為優化器的參數(在這種情況下是學習率)使得這種方式更有意義。例如,當你增加SGD的學習參數時,馬可夫鏈就會變得不穩定,直到找到大面積采樣的局部極小值;也就是說,增加了程序的方差。另一方面,如果你減少學習參數,馬爾可夫鏈慢慢接近狹義極小值,直到它收斂于一個區域;那就是你增加某個區域的偏差。而另一個參數,SGD中的批量大小也可以控制算法收斂的區域是什么類型的區域:小批量的較大區域和大批次的小區域。
SGD根據學習速率或批量大小而選擇較大或極限最小值
這種復雜性意味著深度網絡的優化器變得非常重要:它們是模型的核心部分,與層架構一樣重要。這與機器學習中的許多其他模型并不完全相同。線性模型(甚至是正則化的,像LASSO算法)和支持向量機SVM都是凸優化問題,沒有那么多的細微差別,而且只有一個答案。這就是為什么來自其他領域和/或使用諸如scikit-learn工具的人在他們沒有找到一個非常簡單的具有.fit()方法的API時會感到困惑。盡管有一些工具,如skflow,嘗試將網絡簡化成一個.fit()簽名,我認為這有點誤導,因為深度學習的全部重點就是它的靈活性。
何時不需要深度學習?
那么,什么時候深度學習不適合于某些任務呢?從我的角度來看,以下這些情況下,深度學習更多是一種阻礙,而不是福音。
低預算或低投入問題
深度網絡是非常靈活的模型,具有多種架構和節點類型、優化器和正則化策略。根據應用程序,你的模型可能具有卷積層(多大?使用什么池操作?)或循環結構(有沒有門控?);它可能真的很深(hourglass、siamese,或者其他的架構)?還是只是具有很少的幾個隱藏層(有多少單元?);它可能使用整流線性單元或其他激活函數;它可能或可能不會有退出(在什么層次中?用什么分數?),權重應該是正則化的(l1、l2,或者是某些更奇怪的東西?)。這只是一部分列表,還有很多其他類型的節點、連接,甚至損失函數。即便只是訓練一個大型網絡的示例,那些需要調整的參數以及需要探索的框架的過程也是非常耗時的。谷歌最近吹噓自己的AutoML方法可以自動找到最好的架構,這是非常令人印象深刻的,但仍然需要超過800個GPU,全天候運行數周,這幾乎對于任何人來說是都遙不可及的。關鍵在于訓練深層網絡時,在計算和調試部分都會花費巨大的代價。這種費用對于許多日常預測問題并沒有意義,即使調整小型網絡。調整網絡的投資回報率可能太低。即使有足夠的預算和承諾,也沒有理由不嘗試替代方法,即使是基準測試。你可能會驚喜地發現,線性SVM對于你就夠用了。
解釋和傳達模型參數對一般受眾的重要性
深度網絡也是各臭名昭著的黑匣子,它具有高預測能力但可解釋性不足。盡管最近有很多工具,諸如顯著圖(saliency maps)和激活差異(https://arxiv.org/abs/1704.02685),對某些領域而言是非常有用的,但它們不會完全遷移到所有的應用程序中。主要是,當你想要確保網絡不會通過記住數據集或專注于特定的虛假特征來欺騙你時,這些工具就能很好地工作,但仍然難以將每個功能的重要性解釋為深度網絡的整體決策。在這個領域,沒有什么能夠真正地打敗線性模型,因為學習系數與響應有著直接的關系。當將這些解釋傳達給一般受眾時,這就顯得尤為重要。例如,醫生需要包含各種不同的數據來確認診斷。變量和結果之間的關系越簡單、越直接,醫生就能更好地利用,而不是低于/高于實際值。此外,有些情況下,模型的精度并不像可解釋性那樣重要。例如,策略制定者可能想知道一些人口統計變量對于死亡率的影響,并且相較于預測的準確性來說,可能對這種關系的直接近似比更有興趣。在這兩種情況下,與更簡單、更易滲透的方法相比,深度學習處于不利地位。
建立因果機制
模型可解釋性的極端情況是當我們試圖建立一個機械模型,即實際捕捉數據背后的現象的模型。一個好的例子包括試圖猜測兩個分子(例如藥物、蛋白質、核酸等)是否在特定的細胞環境中相互作用,或者假設特定的營銷策略如何對銷售產生實際的影響。在這個領域,根據專家意見,沒有什么可以擊敗老式的貝葉斯方法,它們是我們表達并推斷因果關系的最好方式。Vicarious有一些很好的最新研究成果,說明為什么這個更原則的方法在視頻游戲任務中比深度學習表現得更好。
學習“非結構化”特征
這可能是具有爭議性的。我發現深度學習擅長的一個領域是為特定任務找到有用的數據表示。一個很好的例子就是上述的詞語嵌入。自然語言具有豐富而復雜的結構,可以說與“上下文感知”(context-aware)網絡相近似:每個單詞都可以在向量中表示,而這個向量可以編碼其經常使用的文本。在大型語料庫中學習的NLP任務中使用單詞嵌入,它有時可以在另一個語料庫的特定任務中提升效果。然而,如果所討論的語料庫是完全非結構化的,則可能不會起到任何作用。例如,假設你正在通過查看關鍵字的非結構化列表來對對象進行分類,由于關鍵字不是在任何特定結構中都會使用的(比如在一個句子中),所以單詞嵌入不太可能有助于所有這些情況。在這種情況下,數據是真正的一個單詞包,這種表示很有可能足以滿足任務所需。與此相反的是,如果你使用預訓練的話,可以更好地捕獲關鍵字的相似度,而且單詞嵌入并不是那么昂貴。不過,我還是寧愿從一個單詞的表示開始,看看能否得到很好的預測結果。畢竟,這個詞包的每個維度都比對應的詞嵌入槽更容易解讀。
前景廣闊
深度學習目前非常火爆,且資金充足,并且發展異常迅速。當你還在閱讀會議上發表的論文時,它可能已經有兩三次迭代了。這給我上述列出的幾點提出了很大的挑戰:深度學習在不久的將來可能在這些情景中是非常有用的。用于解釋圖像和離散序列的深度學習模型的工具越來越好。最近的軟件,如Edward與貝葉斯結合建模和深度網絡框架,將量化神經網絡參數的不確定性考慮在內,通過概率編程的簡易貝葉斯推理和自動變分推理。從長遠來看,可能會有一個簡化的建模詞匯表,指出深度網絡可以具有的顯著屬性,從而減少需要嘗試的參數空間。























 工商網監
工商網監
評論