 電子發(fā)燒友App
電子發(fā)燒友App


背景
機器學習現(xiàn)在已經(jīng)被廣泛應用到計算機視覺、圖像處理、語音處理、地球物理等領域。和其他技術,比如壓縮感知等類似,在計算機和圖像處理領域掀起熱潮之后,機器學習開始在聲學嶄露頭角。雖然起步不早,但是發(fā)展很快。在人類語言語音、動物發(fā)聲、水下聲源定位等聲學子領域都有應用。
機器學習的定義想必大家或多或少都知道,可以被寬泛地定義為,無需明確指令的情況下,依賴數(shù)據(jù)中的模式和特征,通過電腦研究算法和統(tǒng)計模型,來完成特定任務的過程。機器學習大體分為三類:監(jiān)督學習 (Supervised learning) ,無監(jiān)督學習 (Unsupervised learning) 和強化學習 (Reinforcement learning)。這篇文章我們只關注前兩類。
吳恩達教授給出的監(jiān)督學習的定義:
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output。
無監(jiān)督學習:
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don‘t necessarily know the effect of the variables.
簡單說就是監(jiān)督學習對于輸出我們已經(jīng)有了預期,知道他們長什么樣;無監(jiān)督學習是不知道輸出應該是什么,最后用數(shù)據(jù)來判斷。比如同樣是分類,垃圾郵件分類是監(jiān)督學習;把同質(zhì)類的新聞分類就是無監(jiān)督學習,因為我們并不知道要分成幾類,也沒有具體分類標準。
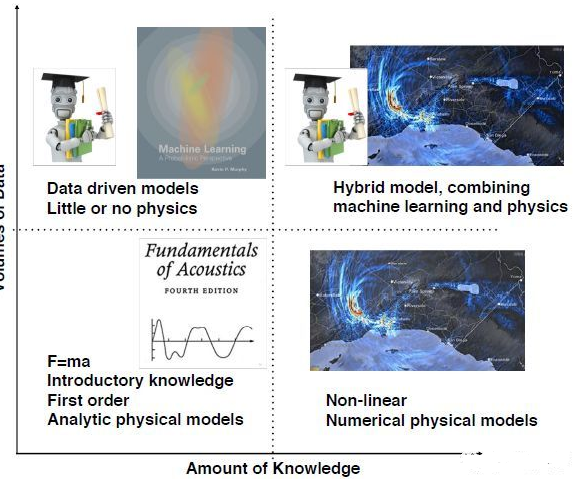
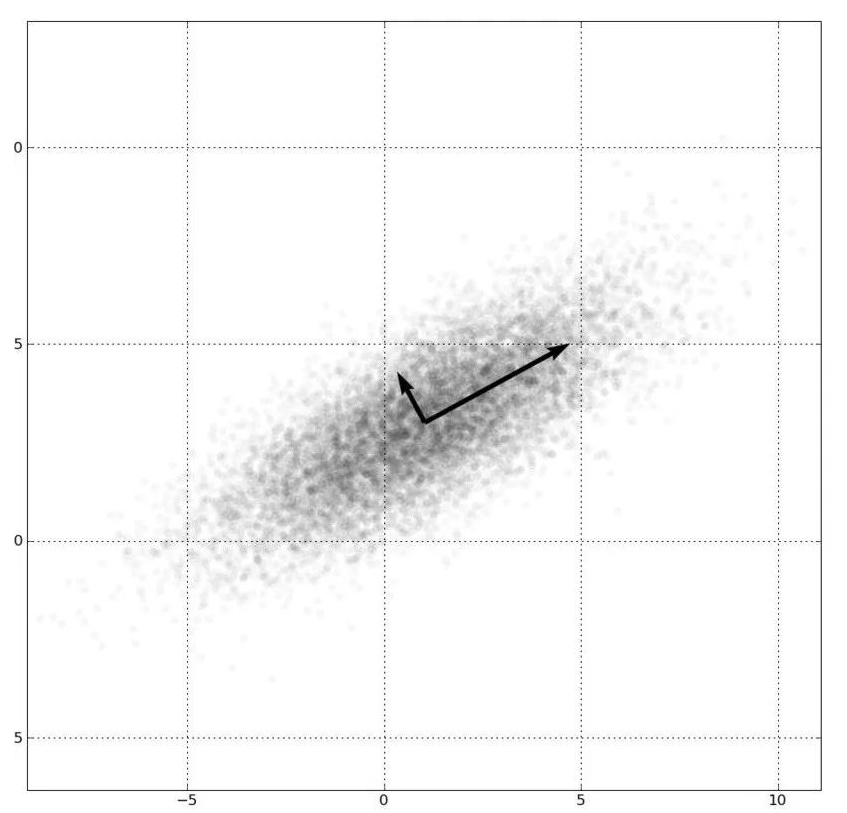
聲學是物理學分支,人們幾百年來一直致力于發(fā)展聲學的物理模型,如下圖的x軸所示;隨著數(shù)據(jù)量的增大,以數(shù)據(jù)為驅(qū)動的方法也逐漸被運用,如圖的y軸。右上角方向就是聲學發(fā)展的方向:更先進完備的物理模型和大數(shù)據(jù)驅(qū)動的機器學習的結(jié)合。機器學習中,數(shù)據(jù)特征是關鍵。
機器學習的常見方法
機器學習有海量的學習資料,我一個外行就不再班門弄斧講基礎知識。在這里簡單列幾個比較常用的機器學習方法。
監(jiān)督學習
1. 回歸和分類
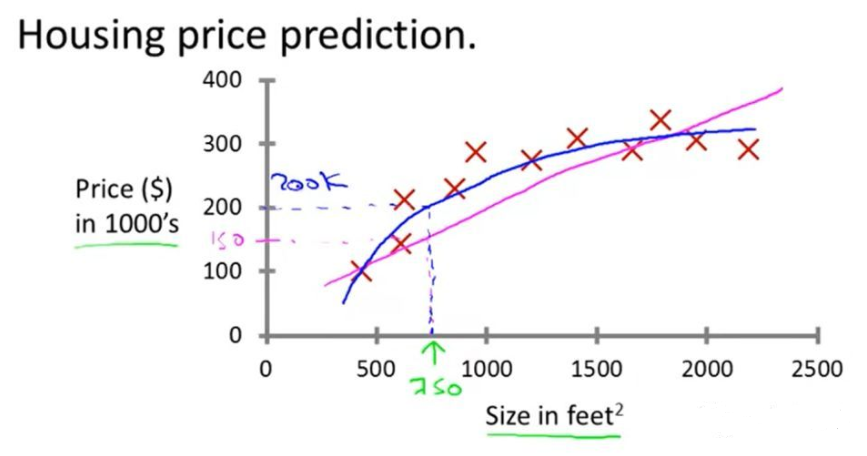
用吳恩達老師在Coursera的Machine Learning里面的一張圖展示什么是回歸。橫坐標房子面積,縱坐標房價,我們可以用各種曲線來代表房價趨勢,從而由面積預測房價。
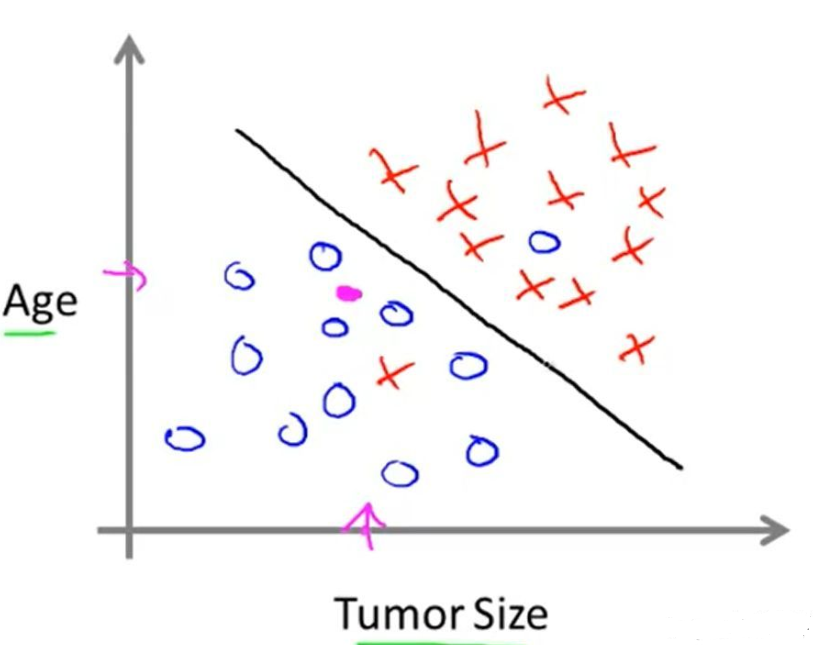
分類很好理解,一個簡單的例子
其他的方法還有支持向量機SVM (Support Vector Machine)、神經(jīng)網(wǎng)絡等。其中支持向量機要比回歸更靈活,而神經(jīng)網(wǎng)絡可以利用非線性模型進行預測或分類。
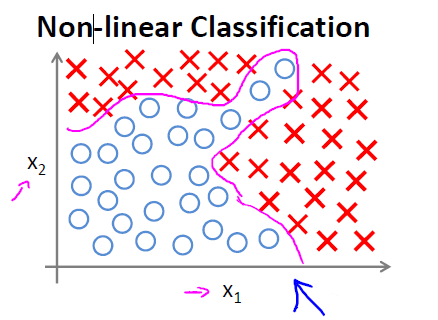
神經(jīng)網(wǎng)絡非線性分類?
無監(jiān)督學習
主要方法有:
1. 主成分分析 PCA (Principal components analysis)
PCA: 通過正交變換把數(shù)據(jù)轉(zhuǎn)化成線性無關的主成分,對數(shù)據(jù)進行降維打擊,讓特征更具代表意義?
2. K-means
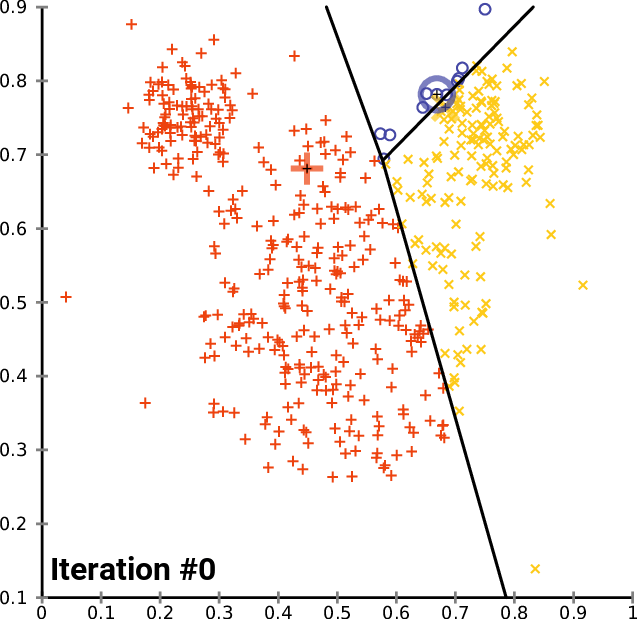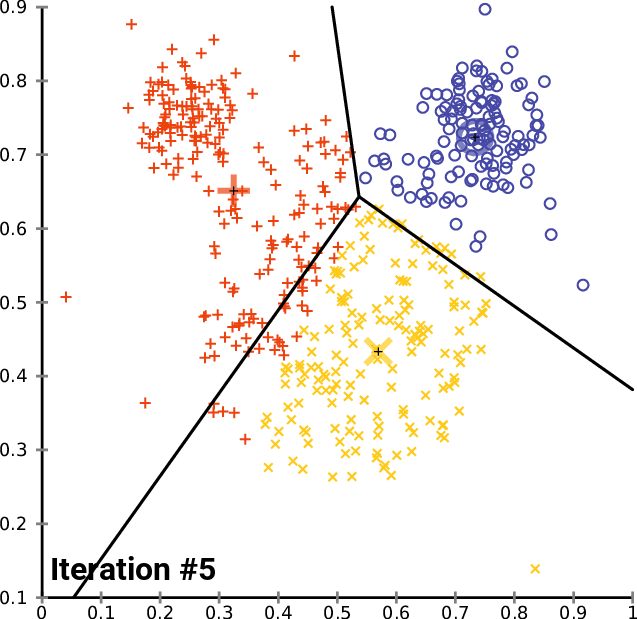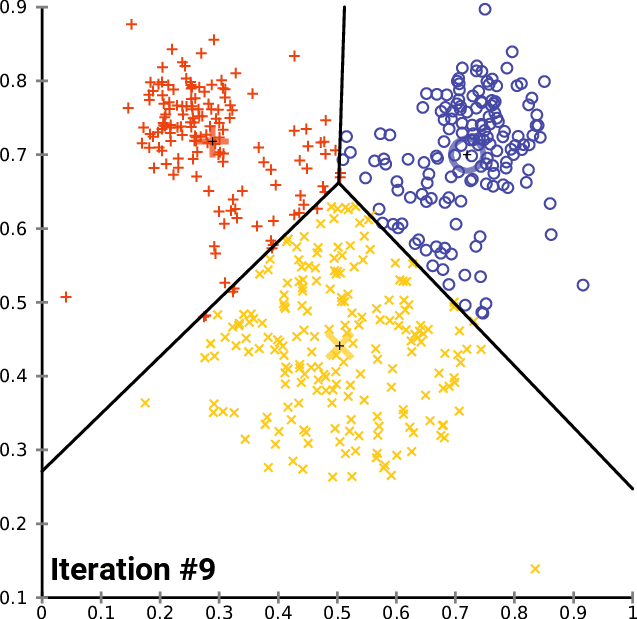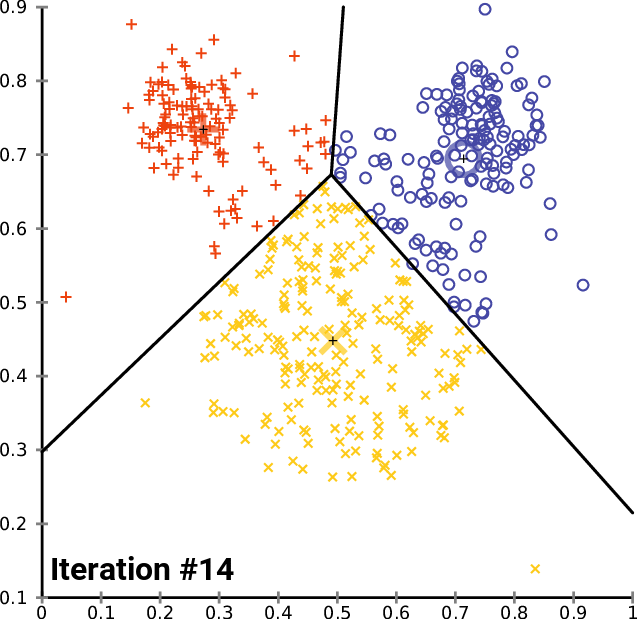
k-mean: 通過迭代找到不同類數(shù)據(jù)的中心點,從而對數(shù)據(jù)分類?
3. GMM 和最大期望Expectation Maximization (EM)
和k-mean類似,也是一種聚類分析。通過混合幾個不同的高斯分布,對特征分類。
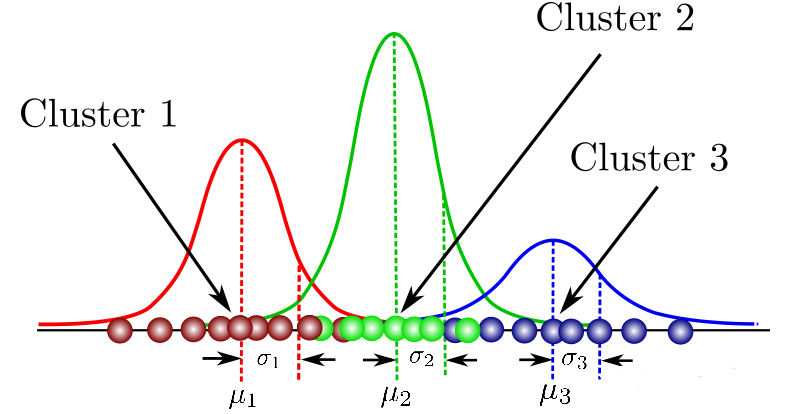
GMM?
其他方法還有字典學習 Dictionary learning,Autoencoder network、深度學習(包括卷積神經(jīng)網(wǎng)絡)等。
機器學習在聲學中的應用
1. 音頻處理中的聲源定位
在音頻處理中,對聲源或者發(fā)聲者的語音增強是核心問題。機器學習和聲學的結(jié)合,在手機、汽車、助聽器和智能家居等領域都有廣泛應用。雖然這個方向的發(fā)展非常迅猛,但是在高背景噪聲和房間混響的環(huán)境下準確識別聲源依然是最大的挑戰(zhàn)。LOCATA項目最近發(fā)起了一項聲源定位和追蹤的挑戰(zhàn),建立了一個基于現(xiàn)實生活錄音的數(shù)據(jù)庫可以用來訓練聲源定位算法。現(xiàn)在國內(nèi)外各大語音相關企業(yè)都在開展這方面的研究。
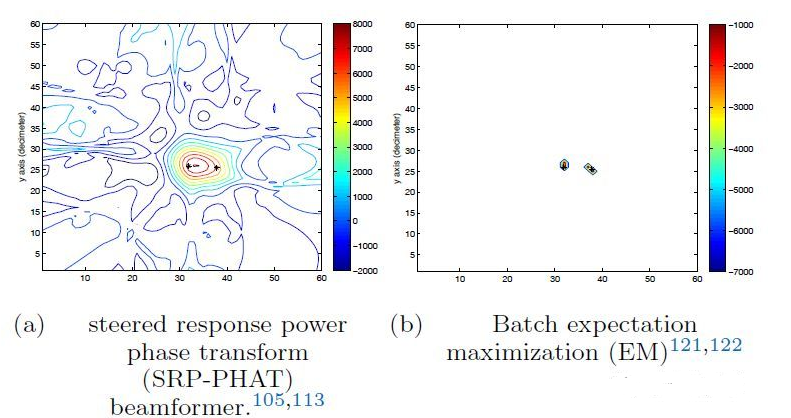
GMM結(jié)合EM提高定位精度?
2. 海洋聲學中的聲源定位
海洋聲源定位主要利用聲吶系統(tǒng)結(jié)合Matched field processing (MFP)算法。由于空間中聲源絕大多數(shù)為稀疏分布(不是空間里布滿了聲源),所以壓縮感知 (Compressive sensing)在近十幾年被引入聲學。正如前述所說,聲學一般都是滯后引入其他學科中的新技術,這似乎是聲學學科的特點。
神經(jīng)網(wǎng)絡被用到過準確定位貨輪位置[5]。對于淺海和傾斜的海洋環(huán)境,需要針對不同的海水深度訓練time delay neural network (TDNN)模型從而避免mismatch [6]。今年又有學者成功利用單個水聽器hydrophone結(jié)合deep residual CNN (Res-Net)預測聲源范圍和深度[7]。隨著計算機能力的提升(比如量子計算機,雖然不知道還要多少年才能商用),結(jié)合機器學習和物理模型,有望實現(xiàn)更精準的實時海洋聲源定位。
三個船不同時間的時頻圖?
3. 生物聲學
這個方向的應用比較有意思,主要研究自然界生物對各種聲音的產(chǎn)生和感知,這里的聲音不僅僅局限于語音。機器學習已經(jīng)用于回答以下問題:為什么動物會發(fā)聲?為什么會出現(xiàn)喊叫和歌聲?這些聲音之間有什么聯(lián)系?這些方面有豐富的數(shù)據(jù),可供機器學習使用。
通過采集動物叫聲,來對他們的生物和生態(tài)方面的行為進行分類,從而鑒定某一個區(qū)域的動物分布密度,以及密度如何隨時間變化,月亮圓缺如何影響動物覓食行為等。早在90年代就有人研究過海洋動物的特征 ,通過提取音頻中特征對應的心理聲學參數(shù)、時頻特征等來訓練機器學習模型。80年代就有人通過海豚的叫聲來對海豚種類進行分類,后來GMM被用到了齒鯨叫聲頻譜參數(shù)數(shù)值變化的研究,用隱形馬爾科夫模型HMM通過鳥叫來給鳥分類,用多層神經(jīng)網(wǎng)絡分類蝙蝠和鯨魚,并識別出殺人虎鯨的叫聲——方便及時跑路。還有用ensemble learning來給大黃蜂進行分類。無監(jiān)督學習目前還沒有被大面積用到生物聲學領域。
幾個有趣的生物聲學數(shù)據(jù)庫:
https://www.macaulaylibrary.org
Sharing bird sounds from around the world
MobySound.org
British Library - Sounds
https://www.ngdc.noaa.gov/mgg/pad/
在醫(yī)學領域機器學習和聲學也有結(jié)合,用來做疾病診斷。比如澳大利亞的Noisy Guts(http://www.noisyguts.net/)公司用聲學信號結(jié)合機器學習,診斷腸道疾病。
還有對語音信號進行情感情緒分析,來預判危險行為的發(fā)聲,提前介入防止暴力發(fā)生,可以用在幼兒園和監(jiān)獄等場所。荷蘭的一家公司就在做這方面的研究。
通過語音時頻譜可以看出人的突然發(fā)生很大變化?
4. 地質(zhì)探測
對碳水化合物的地質(zhì)探測主要通過收集發(fā)射的地震波的反射波,來分析地表下反射層是否存在不連續(xù),從而探測地下是否存在碳水資源。這個領域傳統(tǒng)方法是結(jié)合信號和圖像處理,利用聲學做地質(zhì)探測也是近期的事情。
5. 混響和環(huán)境聲
人類每天都在和復雜的聲環(huán)境打交道,各種各樣的聲源包括語音、音樂、沖擊、摩擦、流動、動物、機器等。每個聲源發(fā)出的聲音和其他聲源以及周圍環(huán)境發(fā)生交互,導致傳到人耳里面的聲音非常復雜,并不包含聲源的原始聲音。像之前提到的,去混響和反射、提取聲源聲音都是聲學和機器學習結(jié)合面臨的挑戰(zhàn),如何在混合信號中提取出聲源聲。比如,我們需要讓助聽器能夠在背景噪聲中分辨出人聲,自動駕駛的汽車能在嘈雜的街道上聽出警笛并讓道(雖然這個功能在國內(nèi)應該是雞肋)。
在自然環(huán)境中,聲源辨別面臨以下幾個問題:
聲源種類繁多;
每種聲源又有很大多樣性;
自然環(huán)境中都是多個聲音時間同時發(fā)生并互相干擾。
現(xiàn)在有好多的數(shù)據(jù)庫來提供自然界的錄音來訓練classifier,比如DCASE challenges,ESC,TUT,Audio set,Urban Sound and scene classication (DCASE; TUT)。
通過聲學結(jié)合先進的圖像處理來進行聲音場景和聲源分類識別可以增強識別效果。還可以通過物理模型來模擬聲音,用來方便產(chǎn)生更多數(shù)據(jù)來提取特征,訓練模型。
通過物理模型合成大型對比聲音數(shù)據(jù)庫?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論