 電子發燒友App
電子發燒友App


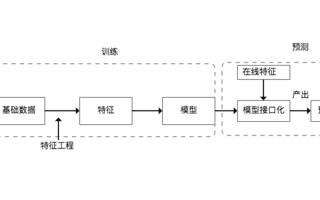
1、特征工程與意義
特征就是從數據中抽取出來的對結果預測有用的信息。
特征工程是使用專業知識背景知識和技巧處理數據,是得特征能在機器學習算法上發揮更好的作用的過程。
2、基本數據處理
數據采集
- 需要思考那些數據有用
- 數據是否容易采集到
- 線上實時計算的時候獲取是否快捷
數據清洗
數據清洗做的事情:洗掉臟數據
思考角度:
1、單維度考量
身高3m的人?顯然不可能
一個月買臉盆墩布花了10w的人?也不太可能
組合或統計屬性判定
號稱在美國但IP卻一直在大陸的新聞閱讀用戶?
要統計一個人是否會去買籃球鞋,然而你的樣本中女性占80%?
2、統計方法
使用箱線圖/boxplot上下界
取出缺省值多的字段
不可信的樣本要去掉,缺省值極多的字段考慮不用
數據采樣
分類問題中,很多情況下正負樣本是不均衡的。比如患某些疾病的患者和健康人。
大多數模型對正負樣本比是敏感的(如邏輯回歸LR)
解決方法:隨機采樣、分層采樣
如果是正樣本>>負樣本,而且量都很大:在正樣本下采樣。(如正樣本200萬個,負樣本20萬個,此時在正樣本中隨機采樣20萬個,正負樣本1:1構建分類器)
如果是正樣本>>負樣本,量不大:1、采集更多數據;2、可以oversampling,即過采樣(如有10萬正樣本,1000負樣本,最簡單的方法是將1000負樣本多重復幾遍。然而這樣做可能會加大過擬合風險,故會將負樣本經過一些小的處理。如圖像識別里面判斷是否為貓,可將圖片旋轉?鏡像處理?加上一些噪聲?均可);3、修改損失函數。
3、常見特征工程
數值型
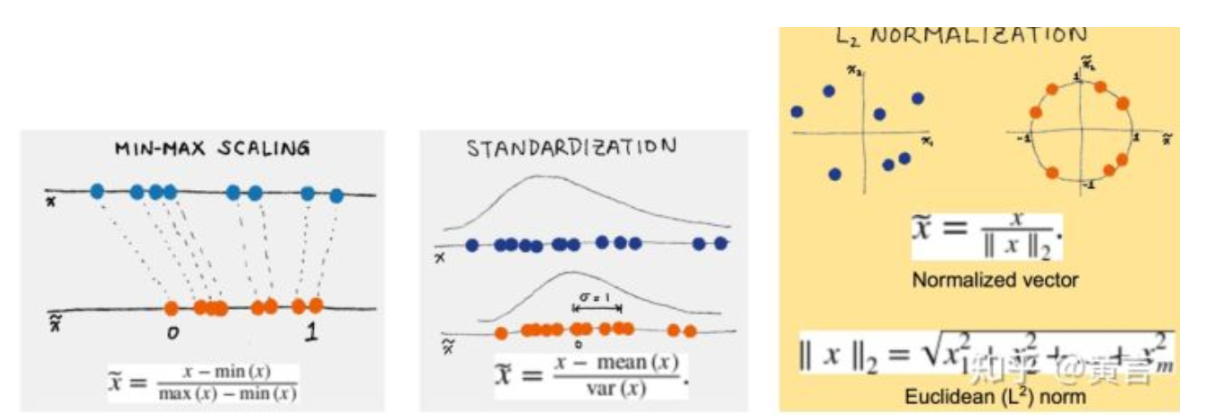
1、幅度調整/歸一化
- 幅度縮放Scaling
- 標準化Standardization
- 歸一化Normalization
2、將數值進行Log等變化
3、統計值max、min、mean、std
4、離散化
對連續值可以將其離散化,按照一個區間來分(分箱、分桶)
下面代碼生成滿足標準高斯分布的20個隨機數,使用pandas的cut函數可以將數據劃分。
import numpy as np import pandas as pd arr = np.random.randn(20) factor = pd.cut(arr,4) factor Out[5]: [(-0.643, 0.329], (0.329, 1.302], (-1.616, -0.643], (-1.616, -0.643], (-0.643, 0.329], ..., (-0.643, 0.329], (-0.643, 0.329], (-0.643, 0.329], (0.329, 1.302], (-1.616, -0.643]] Length: 20 Categories (4, interval[float64]): [(-2.593, -1.616] < (-1.616, -0.643] < (-0.643, 0.329] < (0.329, 1.302]]
5、高次與四則運算特征
通過高次多項式或四則運算來將數據升維。
6、數值轉為類別
類別型
1、one_hot編碼/啞變量
原數據

做one_hot編碼之后

注:不適合類別特別多的字段
2、Hash技巧
如上圖,將文本型映射成向量
時間型
時間型數據既可以看成連續值,又可以看成離散值。
其他類型
1、文本型
詞袋模型/bag of words
word2vec
文本數據預處理后,去掉停用詞,剩下的詞組成的list,在詞庫中的映射稀疏向量。

上述向量沒有加上詞的順序,可以將詞袋中的詞擴充到n-gram。下圖即為將“Bi-grams are cool!”這句話映射成1個單詞和兩個單詞。

Tf-idf特征
Tf-idf是一種統計方法,用以評估一個字詞對于一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨著它在文件中出現的次數成正比增加,但同時會隨它在語料庫中出現的頻率成反比下降。
TF:Term Frequency
TF(t) = (詞t在當前文中出現的次數)/(t在全部語料庫中出現的次數)
IDF:
IDF(t)=ln(總文檔數/含t的文檔數)
TF-IDF權重 = TF(t)*IDF(t)
2、統計特征
加減平均
分位線
次序型
比例型
特征處理示例

4、特征選擇方法
特征選擇意義:
冗余:部分特征相關度太高了,消耗計算性能
噪聲:部分特征是對預測結果有負影響
特征選擇VS降維:
前者剔除原本特征里和結果預測關系不大的,后者做降維操作,但是保存大部分信息
SVD或PCA確實也能解決一定的高維問題
過濾式特征選擇
評估單個特征和結果值之間的相關程度,排序留下Top相關的特征部分
Pearson系數,互信息,距離相關度
缺點:沒有考慮到特征之間的關聯作用,可能把有用的關聯特征誤剔除
相關的Python包:

#SelectKBest選擇排名前k個的特征 from sklearn.datasets import load_iris from sklearn.feature_selection import SelectKBest #chi2是卡方統計量 from sklearn.feature_selection import chi2 iris = load_iris() X,y = iris.data,iris.target # 之前的X數據集是有4個特征的 X.shape Out[13]: (150, 4) # 使用SelectKBest,使用卡方統計量,選出top2的兩個特征 X_new = SelectKBest(chi2,k=2).fit_transform(X,y) X_new.shape Out[15]: (150, 2)
包裹式(wrapper)特征選擇
把特征選擇看做一個特征子集搜索問題,篩選出各種特征子集,用模型評估結果。
典型的包裹式算法為“遞歸特征刪除算法”(recusive feature elimination algorithm)
如用邏輯回歸,如何去做?
用全量跑一個模型
根據線性模型系數(體現相關性),刪掉5%-10%的特征,觀察準確率/AUC的變化
逐步進行,直至準確率/AUC出現大的下滑停止
相關python包

幾個參數estimato為選擇的模型,n_features_to_select為迭代到最后幾個特征值。
from sklearn.feature_selection import RFE from sklearn.linear_model import LinearRegression from sklearn.datasets import load_boston boston = load_boston() lr= LinearRegression() rfe = RFE(lr,n_features_to_select=1) X = boston["data"] # 數據有13個特征 X.shape Out[27]: (506, 13) Y = boston["target"] names = boston["feature_names"] rfe.fit(X,Y) Out[28]: RFE(estimator=LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False), n_features_to_select=1, step=1, verbose=) # 使用遞歸特征刪除算法,將數據的13個特征排序,數字為對應特征的序號 rfe.ranking_ Out[29]: array([ 8, 10, 9, 3, 1, 2, 13, 5, 7, 11, 4, 12, 6])
嵌入式特征選擇
根據模型來分析特征的重要性(有別于上面的方式,是從生產的模型權重等)
最常見的方式為正則化方法來做特征選擇
一般用L1正則化來進行特征選擇,用L2正則化來防止過擬合。
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_selection import SelectFromModel iris = load_iris() X,y = iris.data,iris.target # 之前的特征數為4 X.shape Out[6]: (150, 4) # 使用線性SVM分類器,正則化選L1正則化 lsvc = LinearSVC(C=0.01,penalty='l1',dual=False).fit(X,y) model = SelectFromModel(lsvc,prefit=True) X_new = model.transform(X) # L1正則化后選擇的特征數為3 X_new.shape Out[10]: (150, 3)






















 工商網監
工商網監
評論