 電子發燒友App
電子發燒友App


經歷了幾年的高速發展之后,人工智能(簡稱AI)不再是新鮮的名詞,它已經作為一個重要的生產工具,被引入到我們工作和生活的多個領域。但在AI爆發的背后,隨之而來的是對AI算力需求的暴增。
據OpenAI的一份報告顯示,從2012年到2019年,人工智能訓練集增長了30萬倍,每3.43個月翻一番,但如果是以摩爾定律的速度,只會有 12 倍的增長。為了滿足AI算力的需求,從業人員通過設計專用的AI芯片、重配置硬件和算法創新等多方面入手來達成目標。
AI算力需求增長
然而在此過程中,我們除了看到AI對算力的要求以外,內存帶寬也是限制AI芯片發展的另一個關鍵要素。這就需要從傳統的馮諾依曼架構談起。作為當前芯片的主流架構,馮諾依曼架構的一大特征就是計算和內存分離的。那就意味著每進行一次計算,計算單元都要從內存中讀取數據然后計算,再把計算結構存回到內存當中。
經典的馮諾依曼架構
在過往,這個架構的短板并不是很明顯,因為處理器和內存的速度都都非常接近。但眾所周知的是,在摩爾定律指導下的處理器在過去幾十年里發生了翻天覆地的變化,但常用的DRAM方案與之相比,提升幅度不值一提。
再者,在AI時代,數據傳輸量越來越大。先進的駕駛員輔助系統(ADAS)為例。第3級及更高級別系統的復雜數據處理需要超過200 GB/s的內存帶寬。這些高帶寬是復雜的AI/ML算法的基本需求,在道路上自駕過程中這些算法需要快速執行大量計算并安全地執行實時決策。在第5級,即完全自主駕駛,車輛能夠獨立地對交通標志和信號的動態環境作出反應,以及準確地預測汽車、卡車、自行車和行人的移動,將需要巨大的內存帶寬。
因此,AI芯片尋找新的內存方案迫在眉睫,其中HBM和GDDR SDRAM(簡稱GDDR)就成為了行業的選擇。
為什么是HBM和GDDR ?
HBM就是High Bandwidth Memory的縮寫,也就是高帶寬內存,這是一項在2013年10月被JEDEC采納為業界標準的內存技術。按照AMD的介紹,這種新型的 CPU/GPU 內存芯片(即 “RAM”),就像摩天大廈中的樓層一樣可以垂直堆疊。基于這種設計,信息交換的時間將會縮短。這些堆疊的芯片通過稱為“中介層 (Interposer)”的超快速互聯方式連接至 CPU 或 GPU。將HBM的堆棧插入到中介層中,放置于 CPU 或 GPU 旁邊,然后將組裝后的模塊連接至電路板。
盡管這些 HBM 堆棧沒有以物理方式與 CPU 或 GPU 集成,但通過中介層緊湊而快速地連接后,HBM 具備的特性幾乎和芯片集成的 RAM 一樣。更重要的是,這些獨特的設計能給
開發者帶來功耗、性能和尺寸等多個方面的優勢。
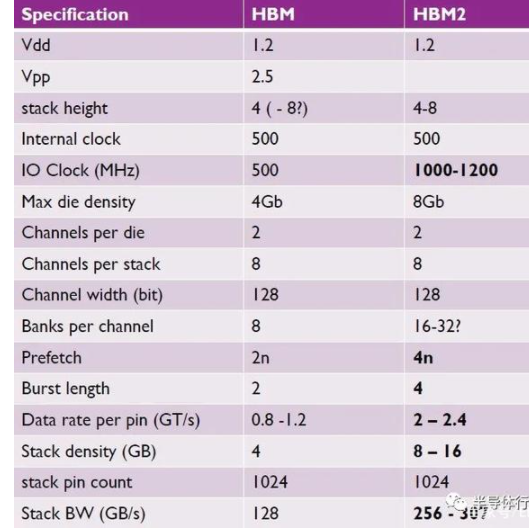
從第一代HBM與2013年面世后,JEDEC又分別在2016年和2018把HBM2和HBM2E納為行業標準。據了解,在HBM2E規范下,當傳輸速率上升到每管腳3.6Gbps時,HBM2E可以實現每堆棧461GB/s的內存帶寬。此外,HBM2E支持12個DRAM的堆棧,內存容量高達每堆棧24 GB。
具體而言,就是說每一個運行速度高達3.6Gbps的HBM2E堆棧通過1024個數據“線”的接口連接到它的相關處理器。通過命令和地址,線的數量增加到大約1700條。這遠遠超出了標準PCB所能支持的范圍。因此,硅中介層被采用作為連接內存堆棧和處理器的中介。與SoC一樣,精細數據走線可以在硅中介層中以蝕刻間隔的方式實現,以獲得HBM接口所需數量的數據線數。
得益于其巨大內存帶寬的能力,使得連接到一個處理器的四塊HBM2E內存堆棧將提供超過1.8 TB/s的帶寬。通過3D堆疊內存,可以以極小的空間實現高帶寬和高容量需求。進一步,通過保持相對較低的數據傳輸速率,并使內存靠近處理器,總體系統功率得以維持在較低水位。
根據Rambus的介紹,HBM2E的性能非常出色,所增加的采用和制造成本可以透過節省的電路板空間和電力相互的緩解 。在物理空間日益受限的數據中心環境中,HBM2E緊湊的體系結構提供了切實的好處。它的低功率意味著它的熱負荷較低,在這種環境中,冷卻成本通常是幾個最大的運營成本之一。
正因為如此,HBM2E成為了AI芯片的一個優先選擇,這也是英偉達在Tesla A100和谷歌在二代TPU上選擇這個內存方案的原因。但如前面所說,因為HBM獨特的設計,其復雜性、成本都高于其他方案,這時候,GDDR就發揮了重大的作用。
據了解,圖形DDR SDRAM(GDDR SDRAM)最初是20多年前為游戲和顯卡市場設計的。在這段時間內,GDDR經歷了幾次重大變革,最新一代GDDR6的數據傳輸速率為16Gbps。GDDR6提供了令人印象深刻的帶寬、容量、延遲和功率。它將工作電壓從1.5V降低到1.35V以獲得更高的功率效率,并使GDDR5內存的數據傳輸速率(16比8 Gbps)和容量(16比8 GB)翻了一番。Rambus已經演示了一個運行速度為18 Gbps的GDDR6接口,顯示這種內存架構還有額外的增長空間。
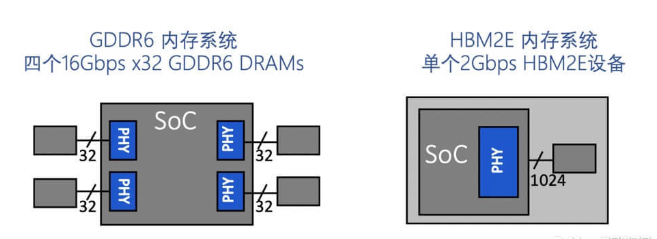
與HBM2E不同,GDDR6 DRAM采用與生產標準DDR式DRAM的大批量制造和組裝一樣的技術。更具體地說,GDDR6采用傳統的方法,通過標準PCB將封裝和測試的DRAMs與SoC連接在一起。利用現有的基礎架構和流程為系統設計者提供了熟悉度,從而降低了成本和實現的復雜性。
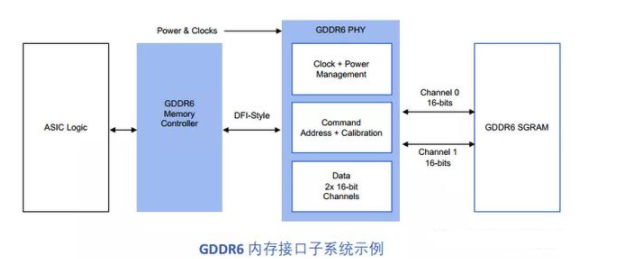
與HBM2E寬而慢的內存接口不同,GDDR6接口窄而快。兩個16位寬通道(32條數據線)將GDDR6 PHY連接到相關的SDRAM。GDDR6接口以每針16 Gbps的速度運行,可以提供64 GB/s的帶寬。回到我們之前的L3汽車示例,GDDR6內存系統以連接四個DRAM設備為例,帶寬可以達到200 GB/s。
采用GDDR6的主要設計挑戰也來自于它最強大的特性之一:速度。在較低的電壓條件,16 Gbps的信號速度下,保持信號完整性需要大量的專業經驗知識。設計人員面臨更緊的時序和電壓裕度量損失,這些損失來源與影響都在迅速增加。系統的接口行為、封裝和電路板需要相互影響,需要采用協同設計方法來保證系統的信號完整性。
總的來說,GDDR6內存的優異性能特性建立久經考驗的基礎制造過程之上,是人工智能推理的理想內存解決方案。其出色的性價比使其適合在廣泛的邊緣網絡和物聯網終端設備上大量采用。
Rambus將扮演重要角色
從上文的介紹中,我們看到了HBM2E和GDDR 6在AI中的重要作用,而要真正將其落實到AI芯片中,相應的IP供應商將是很關鍵的一環,而Rambus將扮演這個重要角色。
據Rambus大中華區總經理Raymond Su介紹,Rambus成立于上個世紀90年代,是一家領先的Silicon IP和芯片提供商,公司主要致力于讓數據傳輸得更快、更安全。而從產品上看,Rambus的產品主要聚焦于三大塊:分別是基礎架構許可、Silicon IP授權,還有buffer chip芯片業務。
“得益于這些深厚的積累,我們能提供友商所不具備的差異性服務”,Raymond Su補充說。他指出:
首先,在內存IP層面,Rambus提供一站式的采購和“turn key”服務。而公司在去年完成的對全球知名的IP控制器公司Northwest Logic和對Verimatrix安全IP業務部,可以讓Rambus能夠提供更好的一站式的服務。
“通過這樣的服務,Rambus IP可以很好地幫助客戶盡早地把產品推向市場”,Raymond Su表示。
其次,作為全球領先的HBM IP供應商,Rambus在全球已經有50多個成功項目案例,積累了大量的經驗;而在DDR5 Buffer Chip(緩沖芯片)方面,Rambus也是全球首發。這讓他們在DDR5時代有信心改變整個市場。而在AI芯片迫切需要的HBM2E和GDDR 6 IP方面,Rambus也都做好了準備。
從Rambus IP核產品營銷高級總監Frank Ferro的介紹我們得知,他們將HBM2E的性能提升到了4Gbps。在他看來,這個速度是一個全新的行業標桿,而此次Rambus發布我們全新的HBM2E產品也正是實現了這一行業最高標準。
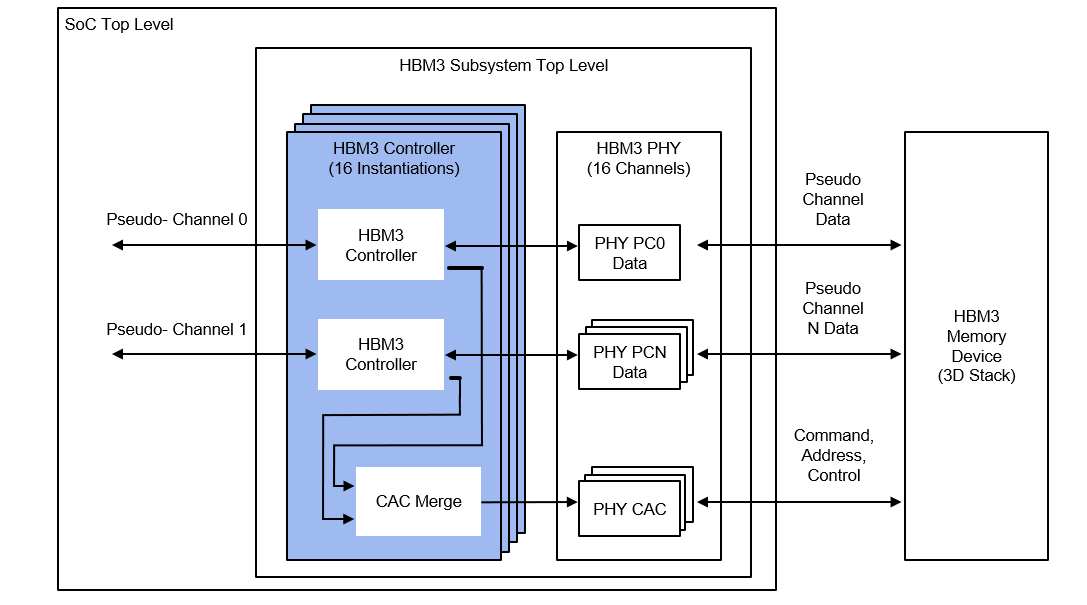
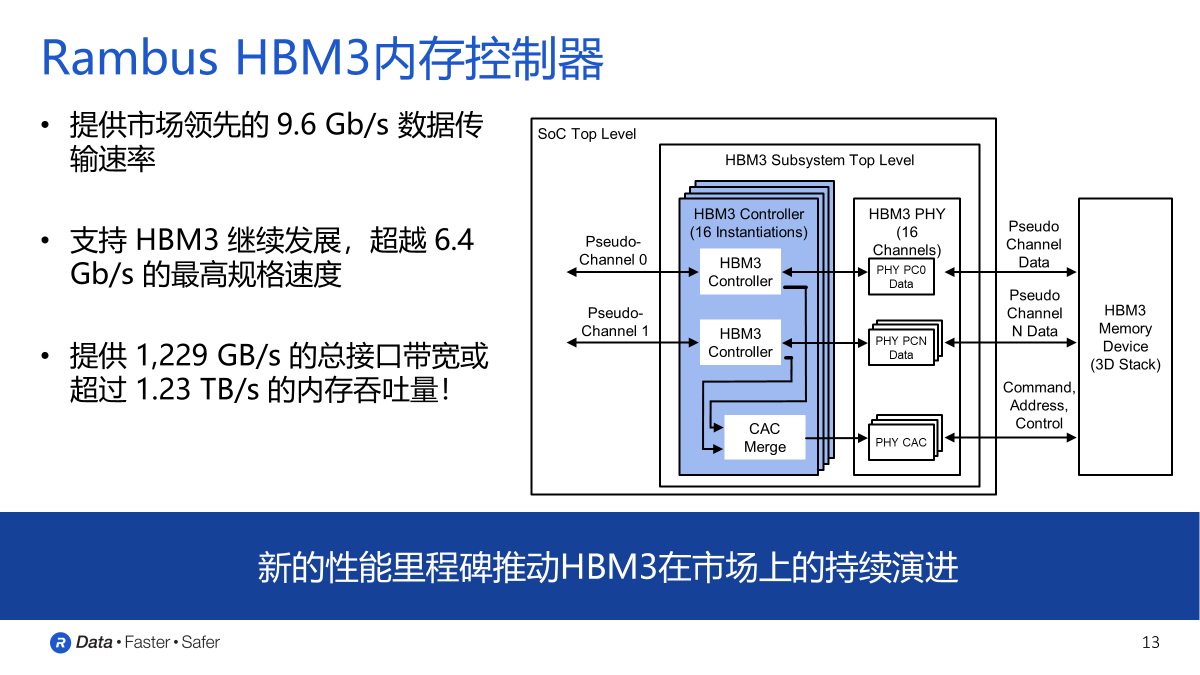
根據Rambus發布的白皮書介紹,他們HBM2E接口完全符合JEDEC JESD235B標準。支持每個數據引腳高達3.6 Gbps的數據傳輸速率。該接口具有8個獨立的通道,每個通道包含128位,總數據寬度為1024位。由此每個堆棧支持的帶寬是461GB/s,每個堆棧由2、4、8或12個DRAMs組成。
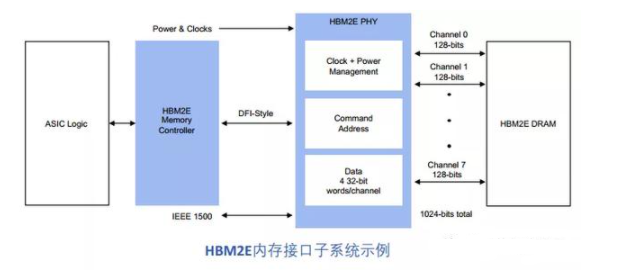
作為一個為2.5D系統設計的IP,它有一個用于在3D-DRAM堆棧和SoC上的PHY之間的中介層由提供信號繞線。這種信號密度和堆積尺寸的組合需要特殊的設計考慮。為了便于實施和提高了設計的靈活性,Rambus對整個2.5D系統進行完整的信號和功率完整性分析,以確保所有信號、功率和散熱要求都得到滿足。而在于其他競爭對手相比,Rambus的HBM IP則有著大多數廠商布局的幾點核心優勢:
第一,Rambus提供的是完全集成而且經過驗證的PHY以及內存控制器IP解決方案,在物理層面實現完整的集成互聯。除了完整的內存子系統之外,他們的PHY也經過了硬核化處理,同時也完成了timing closed也就是時序收斂的工作。
“我們給客戶提供的并不僅僅是自己的IP授權、IP產品,我們也會向客戶提供系統級的全面的集成支持,以及相關的工具套件,以及我們的技術服務。同時,我們也可以幫助客戶更加進一步地減少設計實現的難度。” Frank Ferro補充說。他進一步指出,在發布了這個IP之后,Rambus將會為人工智能以及機器學習的應用客戶提供更加完整的解決方案,幫助他們進一步地提高帶寬,滿足他們在帶寬上的需求。
第二,Rambus擁有非常強大的HBM生產經驗,在這方面,公司已經擁有了全球超過50家成功的客戶案例,這在全球是名列前茅的。更重要的一點,Rambus所有合作客戶的芯片從設計到原型再到投產,并不需要任何的設計返工,基本上所有的芯片都會實現一次的成功。這足以體現他們的實力。
第三,Rambus為客戶提供非常完整的參考設計框架,其中最重要的一點就是如何更好地對中介層進行完整的設計和表征化的處理。“因為對于中介層來,講它是PHY層和DRAM層之間溝通的重要環節,在這個過程中,因為速度非常快,所以說如何保證信號完整性也是必須要去考慮的。” Frank Ferro表示。
他進一步指出,Rambus與客戶非常緊密地進行合作,并為他們提供非常完整的參考設計框架,然后幫助他們更好地去設計自己的中介層以及產品的封裝。除此之外,Rambus也幫助客戶做仿真分析,讓他們對自己每個信號的通道進行完整的分析,來實現整個產品的最高性能。
第四,這也是非常重要的一點,那就是Rambus有一套非常重要的工具——Lab Station。借助這個工具,Rambus會與客戶進行合作,讓他們將其HBM2E解決方案直接插入到他們的終端系統當中,來構建一個非常獨立的內存子系統。
能在HBM2E IP獲得這樣的成就,一方面,Rambus的研發投入功不可沒;另一方面,他們與SK海力士、AIChip和臺積電多方人員的通力合作,也是他們能提供快速服務的原因之一。例如在SK海力士方面,它為Rambus提供的HBM2E內存達到了3.6G的數據傳輸速率,而在和合作過程中,兩者又將HBM2E的速率進一步地推進到了4.0 Gbps;AIchip則為Rambus提供了ASIC的相關解決方案以及產品,幫助其設計了相關中介層以及封裝;此外,臺積電提供了一個交鑰匙的2.5D Cowos封裝以及解決方案,來更好地為Rambus打造一個晶圓上的基本架構。
“我們的解決方案適用于人工智能以及機器學習的訓練,同時也非常適用于高性能計算系統和5G網絡的基礎設施建設”,Frank Ferro最后說。
除了面向AI訓練的HMB2E IP,Rambus還推出了面向AI推理的GDDR 6產品。
據Rambus的白皮書介紹,公司的GDDR6接口專為性能和功率效率而設計,支持AI/ML和ADAS推理高帶寬與低延遲要求。它由一個經共同驗證的PHY和數字控制器組成,提供一個完整的GDDR6內存子系統。Rambus GDDR6接口完全符合JEDEC GDDR6 JESD250標準,每個引腳支持高達16 Gbps。GDDR6接口支持2個通道,每個通道有16位,
總數據寬度為32位。Rambus GDDR6接口每針16 Gbps,提供帶寬為64 GB/s。
通過直接與客戶合作,Rambus能提供完整的系統信號和電源完整性(SI/PI)分析,創建優化的芯片布線版圖。客戶收到一個硬核解決方案與全套測試軟件可以快速啟動,定性和調試。
在“內存墻”的限制下,為了滿足AI應用的數據搬運需求,產業界正在探索不同的方法來解決問題。例如英國AI芯片初創企業Graphcore就希望通過分布式內存設計的方法解決這個問題。
而Rambus的這兩個方案出現那就給開發者們提供了在傳統架構設計上獲得性能大提升的可能。
編輯:hfy















 工商網監
工商網監
評論