 電子發燒友App
電子發燒友App


作者丨疾星@知乎來 ?
導讀
圖像處理領域是深度學習和機器視覺領域重要的研究分支,本文第一部分將介紹深度學習中圖像處理的常用技巧,第二部分則會淺析深度學習中圖像處理的主流應用。
近年以來,隨著深度學習在圖像識別領域取得巨大突破(以AI之父Geoffry Hinton在2012年提出的高精度AlexNet圖像識別網絡為代表),掀起了以神經網絡為基礎的深度學習研究熱潮。目前為止,圖像處理已成為深度學習中重要的研究領域,幾乎所有的深度學習框架都支持圖像處理工具。 當前深度學習在圖像處理領域的應用可分為三方面:圖像處理(基本圖像變換)、圖像識別(以神經網絡為主流的圖像特征提取)和圖像生成(以神經風格遷移為代表)。本文第一部分介紹深度學習中圖像處理的常用技巧,第二部分淺析深度學習中圖像處理的主流應用,最后對本文內容進行簡要總結。
一.深度學習中圖像處理的常見技巧
目前幾乎所有的深度學習框架均支持圖像處理工具包,包括Google開發的Tensorflow、Microsoft的CNTK等。以操作簡單的Keras前端,Tensorflow后端開發框架為例介紹圖像處理中的常見操作技巧:
1. 數據增強
制約深度學習發展的三要素分別為算法、算力和數據,其中算法性能由設計方式決定,算力供給的關鍵在于硬件處理器效能,算法和算力相同時,數據量的多少直接決定模型性能的最終優劣。進行圖像識別時,經常出現因原始圖像數目不足而導致的輸出曲線過擬合,從而無法訓練出能泛化到新圖像集上的模型。數據增強根據當前已知的圖像數據集生成更多的訓練圖像,具體實現是利用多種能夠生成可信圖像的隨機變換來增加原始圖像數量。數據增強前后的對比結果如圖1所示:  圖1a 原始圖像
圖1a 原始圖像

圖1b 數據增強后的圖像 其中關鍵代碼如下(定義增強數據的操作,包括縮放,平移和旋轉等):

對比可知,數據增強的實質是在未改變原始圖像特征內容的基礎上(例如上圖中的關鍵對象:貓、鐵籠、食物)對圖像數量的擴充,從而避免因圖像不足而導致的模型過擬合與泛化性差等缺陷,在小型圖像數據集上進行訓練時尤其有效。
2. 圖像去噪
現實的圖像在傳播過程中,由于傳輸波動和受外界噪聲干擾而很容易引起圖像質量下降。圖像去噪是指濾除圖像包含的干擾信息而保留有用信息,常見去噪方法包括非局部平均過濾算法、高斯濾波算法和自適應濾除噪聲的卷積神經網絡等。簡要介紹如下: 2.1 非局部平均過濾算法 非局部平均過濾算法的降噪原理如下:圖片中像素的設定通過與其周圍的像素點加權而成,也就是圖片中某點的像素設定和其周圍像素的權重設定有關。具體原理如下式所示: 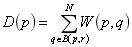
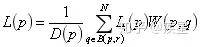 式中??代表??位置像素點受??位置像素點影響的權重大小,??代表選取像素 點??周圍半徑為??范圍內的像素點作為加權參照。?和??分別代表像素點周圍像 素權值的大小統計和像素點受周圍 半徑內像素影響的加權總和。 對原始圖像添加噪聲,隨機設定3000個像素點為白色(RGB值均為255),可以看出添加噪聲后的圖像相對原始圖像增添了許多噪聲白斑,如圖2所示:
式中??代表??位置像素點受??位置像素點影響的權重大小,??代表選取像素 點??周圍半徑為??范圍內的像素點作為加權參照。?和??分別代表像素點周圍像 素權值的大小統計和像素點受周圍 半徑內像素影響的加權總和。 對原始圖像添加噪聲,隨機設定3000個像素點為白色(RGB值均為255),可以看出添加噪聲后的圖像相對原始圖像增添了許多噪聲白斑,如圖2所示:

圖2a 原始海灘背景圖像

圖2b 添加噪聲后的背景圖像 然后使用openCV內置的非局部平均噪聲過濾算法濾除圖片噪聲,結果如圖3所示:

圖3 非局部平均噪聲濾波后得到的背景圖像 觀察非局部平均噪聲算法濾波前后的圖像,可知濾波后圖像的白斑噪聲點明顯減少,圖像的質量得到有效提升,有利于后續的編碼處理和傳輸。 2.2 去噪神經網絡 去噪神經網絡通常是以CNN(卷積神經網絡為基礎),其實質是:利用在無噪圖像集上訓練完成的去噪模型,濾除預測圖像中包含的噪聲信息。使用圖像識別中最常見的mnist手寫圖像庫為訓練集,mnist包含6萬張訓練集圖像和1萬張測試集圖像,其大小均為28*28,按照圖像內容的不同分為手寫數字0-9,mnist數據庫內置于keras中。搭建去噪神經網絡結構,如圖4所示:
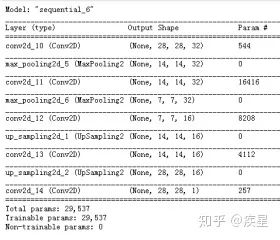
圖4 簡單的去噪神經網絡結構 使用去噪神經網絡對mnist圖像庫中添加噪聲的圖像去噪,去噪前后對比結果如圖5、圖6所示,其中下標相同的Noise與Fliter相對應:

圖5 對原始圖像添加噪聲
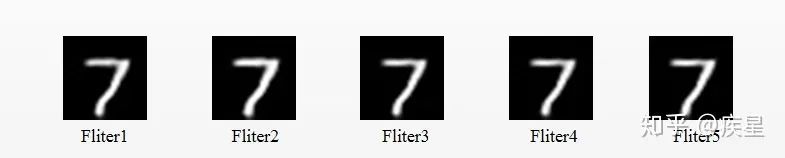
圖6 使用去噪神經網絡濾除噪聲 觀察去噪前后圖片可知,去噪神經網絡通過特征提取和監督學習等方式,對Mnist手寫圖像集實現了非必要噪聲信息濾除,是簡單常用的圖像去噪器。 2.3 圖像超分辨率重建(SR,Super Resolution) SR是圖像處理中的經典應用,是圖像增強領域的重要技術。其基本思想是通過提取低分辨率的原始圖像特征來重構高分辨率的圖像。按照其參考低分辨率圖像種類和數目的不同,主要分為以下兩種:
Image SR:特點是重構圖像時,可供參考的原始低分辨率圖像少,通常不依賴于其他圖像而只參考當前的低分辨率圖像,也稱為單圖超分辨率(SISR,single image super resolution)。
Video SR:特點是重構圖像需要參照多個不同的原始低分辨率圖像,也稱為多幀超分辨率(MFSR,multi-frame super resolution)。通常MFSR相對SISR具有更高的重構質量和更多的特征匹配,代價是計算資源的更多消耗。
SR重構質量可通過圖像質量評估的參考標準PSNR和SSIM進行評價,PSNR值和SSIM值越高,代表重建圖像像素值與標準值越接近。其中PSNR定義如下(MSE代表圖像評估中的均方誤差): 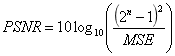 其中MSE的定義如下:
其中MSE的定義如下:
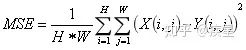
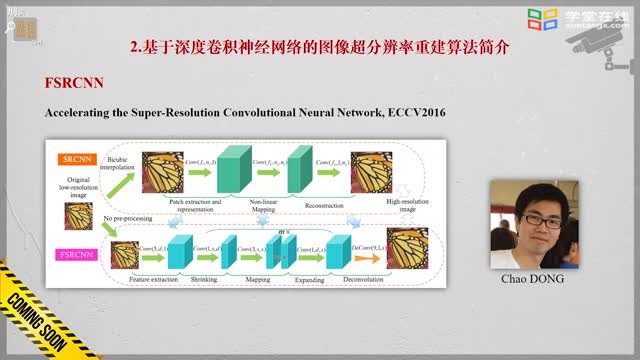
SSIM定義簡化如下(其中代表??均值,??代表均方差): 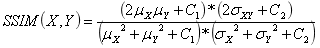 近年以來,圖像超分辨率重建技術逐漸成為深度學習領域的研究熱點,先后涌現出SRCNN(Super-Resolution Convontional Netural Network,超分辨率卷積神經網絡)和FSRCNN(Fast Super-Resolution Convontional Netural Network,快速超分辨卷積神經網絡)等超分辨率重構結構,分別介紹如下:
近年以來,圖像超分辨率重建技術逐漸成為深度學習領域的研究熱點,先后涌現出SRCNN(Super-Resolution Convontional Netural Network,超分辨率卷積神經網絡)和FSRCNN(Fast Super-Resolution Convontional Netural Network,快速超分辨卷積神經網絡)等超分辨率重構結構,分別介紹如下:
SRCNN:SRCNN是香港中文大學在2014年提出的一種Image SR重構網絡,核心結構是利用CNN網絡對原始的低分辨率圖像進行特征提取和映射,最后完成高分辨率圖像重構,其實質是利用深度學習神經網絡實現稀疏自編碼器。SRCNN網絡核心結構如圖7所示:
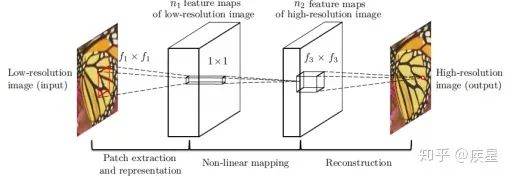
圖7 SRCNN網絡的結構示意圖 如圖7所示,SRCNN網絡完成圖像超分辨率轉換的過程分為三部分:首先通過插值法對原始低分辨率圖像進行維度擴展,目標是保證輸入網絡的圖像與目標圖像尺寸相同;然后將拓展后的原始圖像通過卷積網絡擬合的非線性映射進行特征提取,完成低分辨率特征圖到高分辨率特征圖的映射。CNN特征提取網絡是SRCNN網絡的關鍵結構,文中采用的特征提取網絡為3層堆疊的CNN;最后根據獲得的高分辨率圖像特征對目的圖片進行維度與內容的組合重建,輸出生成的高分辨率圖像。 對比SRCNN網絡與同類算法進行的高分辨率圖像重構,結果如圖8所示:

圖8a 對相同的圖像使用不同超分辨率方法重構

圖8b 常見超分辨重構方法的PSNR和SSIM標準評估 如圖8所示,相同條件下SRCNN網絡的SSIM和PSNR值絕大多數情況下優于傳統算法,說明SRCNN網絡的編碼質量相對傳統算法有所提升。與傳統超分辨算法相比,SRCNN網絡具有結構原理簡單、重構質量高等優點,不足之處在于圖像的轉換重構速率較低。
FSRCNN:FSRCNN網絡同樣由SRCNN開發團隊提出,目的是針對SRCNN網絡圖像轉換速率低的缺點進行改進。改進后網絡的圖像轉換速率較SRCNN網絡大幅提升,圖像重構質量稍有提升。FSRCNN網絡對SRCNN網絡添加的改變總結如下:
維度變換上: 原始SRCNN網絡從圖片輸入網絡開始即對其進行插值變換,以完成與目的圖像維度匹配的維度拓展。這樣使得網絡開頭增加的張量維度參與到端與端間的所有變換運算,大大增加了網絡計算復雜度和運算開銷。改進后的FSRCNN網絡將維度拓展的結構放置于網絡終端,避免了引入網絡內部的非必要運算消耗,提高了圖像的轉換速率。 運算結構上: FSRCNN改進了特征映射中的非線性映射方式,并且減小了卷積運算時的卷積核維度,結果使得網絡運算和特征提取的參數數量大幅減少、圖像的高分辨率重構效率大為提升。由于網絡內部結構的改變,FSRCNN重構圖像質量相對SRCNN略有提升。FSRCNN與SRCNN的對比結果如圖9所示,改進后FSRCNN網絡編碼質量和效率相對傳統SRCNN網絡均有所提升。
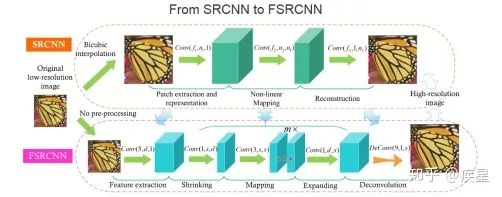
圖9a SRCNN與FSRCNN的結構對比
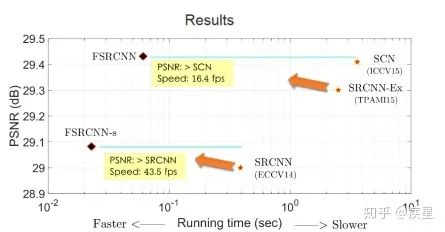
圖9b FSRCNN與SRCNN的質量及效率對比
二.深度學習中的圖像處理應用
當前深度學習在圖像處理方面的應用和發展主要歸納為三方面:圖像變換、圖像識別和圖像生成,分別從這三方面進行介紹:
1. 圖像變換
指對圖片進行的常規操作,包括圖像縮放、復制等簡單操作和上文提及的去噪、提升超分辨率等常見操作,其目的是提升圖片質量,得到理想的目標圖片。總體來說,深度學習進行的圖像變換依賴于內置工具的強大功能,使用者可根據不同需求學習對應圖像處理工具的使用,此處不再贅述。
2. 圖像識別
計算機視覺(CV,Computering Version)已成為深度學習領域的重要發展方向,CV的主要內容就是進行目標識別,圖像作為生活中的常見目標一直是CV方向研究熱點。使用深度學習進行圖像識別的通常方法是:構建識別對象為圖像的神經網絡,達到圖像識別的高精度與低運算資源消耗。 簡要介紹使用神經網絡進行圖像識別,以2013年Kaggle競賽提供的貓狗圖像集為例,構建圖10所示的貓狗圖像集識別神經網絡:
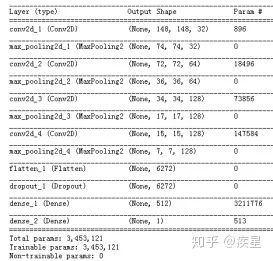
圖10 簡單的貓狗圖像識別神經網絡 設定訓練輪數epochs為50,對4000張貓狗圖像進行分類,得到圖像識別網絡對貓狗圖像集進行訓練過程中損失和精度的變化趨勢,如圖11所示:
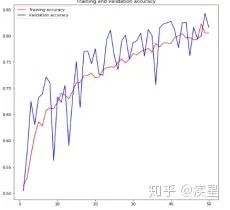
圖a 圖像識別過程中的精度變化
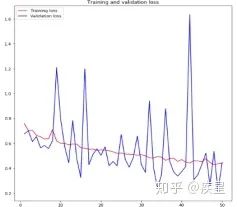
圖b 圖像識別中的損失變化 圖11 構建圖像識別網絡對貓狗數據集的識別結果 由圖11可知,構建的簡單圖像識別網絡經50輪迭代后,對目標圖像集達成了80%以上的識別精度。雖然識別過程中存在過擬合現象,并且識別精度不盡人意,但結果證明神經網絡進行圖像識別的簡便性與可行性。圖像過擬合帶來的負面影響可以通過減少網絡參數量(數據削弱等)和訓練圖像量等方法減小,目標圖像的識別精度可以通過添加預訓練模型等方法進行提升。 當前神經網絡構建的高精度圖像識別已廣泛應用于人臉識別等智能領域,相關實例可上網查閱自行了解,本文不再贅述。

圖12 使用神經網絡進行人臉識別的結果
3. 圖像生成
圖像生成是指從已知圖像中學習特征后進行組合,生成新圖像的過程。不同于圖像的高分辨率重建,圖像生成通常需要學習不同圖像的特征并進行組合,生成的圖像是所有被學習圖像特征的結合。常見的圖像生成應用包括神經風格遷移、Google公司開發的Deep Dream算法和變分自編碼器等,分別介紹如下: 3.1. Deep Dream 由Google公司在2015年夏首次發布,使用早期常見的Caffe架構編寫實現,由于其生成的圖像布滿了算法式的迷幻錯覺偽影而引起轟動。DeepDeram生成圖像的顯著特征是鳥羽毛和狗眼睛數量較多,原因是DeepDream學習的原始圖像庫為鳥樣本和狗樣本特別多的ImageNet(Google開源的大型數據庫,常用作預訓練模型的權重訓練)。 Deep Dream與傳統的卷積神經網絡可視化過程思路相同,均為對卷積神經網絡的輸入進行梯度上升,以便將靠近網絡輸出端的某個過濾器可視化;區別在于Deep Dream算法直接從現有的圖像提取特征,并且嘗試最大化激活神經網絡中所有層的激活。使用Deep Dream算法,在Keras框架上對已知圖像進行特征遷移,結果如圖13所示,Deep Dream生成的圖像相對原圖增添了許多特征(主要是鳥羽波紋和狗眼睛):  圖13a 原始貓圖像
圖13a 原始貓圖像  圖13b Deep Dream貓圖像
圖13b Deep Dream貓圖像  圖13c 原始狗圖像
圖13c 原始狗圖像  圖13d Deep Dream 狗圖像 圖13 使用Deep Dream算法生成的圖像 3.2. 神經風格遷移(NST,Neural Style Transfe) ?神經風格遷移是指將參考圖像的風格應用于目標圖像,同時保留目標圖像的內容。風格是指圖像中不同空間尺度的紋理,顏色和視覺圖案,內容則是指圖像的高級宏觀結構。 實現神經風格遷移的思路與尋常深度學習方法相同,均為實現定義損失的最小化。不同于通常的深度學習算法,神經風格遷移的損失函數與圖像內容和風格的數學定義有關,具體定義如下式所示:
圖13d Deep Dream 狗圖像 圖13 使用Deep Dream算法生成的圖像 3.2. 神經風格遷移(NST,Neural Style Transfe) ?神經風格遷移是指將參考圖像的風格應用于目標圖像,同時保留目標圖像的內容。風格是指圖像中不同空間尺度的紋理,顏色和視覺圖案,內容則是指圖像的高級宏觀結構。 實現神經風格遷移的思路與尋常深度學習方法相同,均為實現定義損失的最小化。不同于通常的深度學習算法,神經風格遷移的損失函數與圖像內容和風格的數學定義有關,具體定義如下式所示:

式中 Loss 代表定義的參考圖像與生成圖像損失,由 Style 風格損失和 Content 內容損失兩部分構成。Style 和 Content 分別定義為風格損失函數和內容損失函數。 內容損失函數由神經網絡中更靠近頂層的網絡激活 L2 范數對參考圖像和生成圖像計算差值得到,由于選取的網絡層更靠近輸出端,可認為內容損失函數得到的差值代表目的圖像和生成圖像中更加全局抽象的圖片內容差異。 風格損失函數的定義則使用神經網絡的多個層,目的是保證風格參考圖像和生成圖像間在神經網絡中各層激活保存相似的內部關系。不同于內容損失函數只關注更全局、更主要的圖像內容,風格損失函數需要在網絡較高層和較低層保持類似的相互關系,從而在根本上保證參考圖片的風格不隨特征提取進行而變化。 實現神經風格遷移的流程分為三個步驟:
加載預訓練網絡,創建能夠同時計算風格參考圖像、目標圖像和生成圖像預訓練網絡激活的神經網絡。
使用三張圖像上計算的對應層激活來定義內容損失與風格損失,得到總體損失函數。
設置批量梯度下降,最小化目標損失。
使用Keras內置的VGG19預訓練模型實現神經風格遷移,目標是實現2015年提出的原始神經風格遷移算法,遷移結果如圖13所示:  星空原始圖像
星空原始圖像  荷池原始圖像圖14a 實現神經風格遷移的原始圖像
荷池原始圖像圖14a 實現神經風格遷移的原始圖像  繁星荷池
繁星荷池  荷池繁星圖14b 交換參考圖像和目標圖像得到的遷移結果 觀察圖13可知,遷移式神經網絡成功完成了風格參考圖像到目標圖像的風格遷移,并且保留了目標圖像的內容。分別以星空和荷池作為參考對象,得到目標圖像繁星荷池和荷池繁星。合理選取原始圖像和定義遷移參數,就能生成一系列美輪美奐的圖像。 3.3 變分式自編碼器(VAE,Variational autoencoder) 變分自編碼器由Kingma和Welling在2013年12月首次提出,是一種利用深度學習中生成式模型構建的自編碼器,特點是將深度學習思想和貝葉斯推斷結合在一起,以完成輸入目標向低維向量空間的編碼映射和向高維向量空間的反解碼。經典的圖像自編碼器首先使用編碼器模塊編碼接收的圖像,將其映射到包含圖片特征的概念向量構成的潛在向量空間;然后通過解碼器模塊將其解碼為與目標圖片同維度大小的輸出,經典自編碼器的工作流程如圖15所示。 實踐中,由于經典自編碼器不具備良好結構的潛在學習空間而常常導致生成圖像不連續,未達成對原始訓練圖像特征的高效提取。變分式自編碼器在經典自編碼器上基礎上改變了其編解碼方式,得到學習連續、高度結構化的潛在空間。VAE不是將輸入圖像壓縮成潛在空間中的固定編碼,而是將圖像轉換為統計分布參數(平均值和方差)。然后,VAE使用這兩個參數從分布中隨機采樣一個元素并將其解碼到原始輸入。這個過程的隨機提高了其穩健性,并迫使潛在空間的任何位置都對應有意義的表示,即潛在空間采樣的每個點都能解碼為有效的輸出,變分自編碼器的工作流程如圖16所示。 圖像變分自編碼器與一般的深度學習模型相同,采用和輸入圖像相同類型大小的圖片來訓練模型,以完成對輸入圖像的特征提取和目標圖像的自動重構生成。可以通過指定編碼器的輸出來限制編碼器學習的具體特征。
荷池繁星圖14b 交換參考圖像和目標圖像得到的遷移結果 觀察圖13可知,遷移式神經網絡成功完成了風格參考圖像到目標圖像的風格遷移,并且保留了目標圖像的內容。分別以星空和荷池作為參考對象,得到目標圖像繁星荷池和荷池繁星。合理選取原始圖像和定義遷移參數,就能生成一系列美輪美奐的圖像。 3.3 變分式自編碼器(VAE,Variational autoencoder) 變分自編碼器由Kingma和Welling在2013年12月首次提出,是一種利用深度學習中生成式模型構建的自編碼器,特點是將深度學習思想和貝葉斯推斷結合在一起,以完成輸入目標向低維向量空間的編碼映射和向高維向量空間的反解碼。經典的圖像自編碼器首先使用編碼器模塊編碼接收的圖像,將其映射到包含圖片特征的概念向量構成的潛在向量空間;然后通過解碼器模塊將其解碼為與目標圖片同維度大小的輸出,經典自編碼器的工作流程如圖15所示。 實踐中,由于經典自編碼器不具備良好結構的潛在學習空間而常常導致生成圖像不連續,未達成對原始訓練圖像特征的高效提取。變分式自編碼器在經典自編碼器上基礎上改變了其編解碼方式,得到學習連續、高度結構化的潛在空間。VAE不是將輸入圖像壓縮成潛在空間中的固定編碼,而是將圖像轉換為統計分布參數(平均值和方差)。然后,VAE使用這兩個參數從分布中隨機采樣一個元素并將其解碼到原始輸入。這個過程的隨機提高了其穩健性,并迫使潛在空間的任何位置都對應有意義的表示,即潛在空間采樣的每個點都能解碼為有效的輸出,變分自編碼器的工作流程如圖16所示。 圖像變分自編碼器與一般的深度學習模型相同,采用和輸入圖像相同類型大小的圖片來訓練模型,以完成對輸入圖像的特征提取和目標圖像的自動重構生成。可以通過指定編碼器的輸出來限制編碼器學習的具體特征。
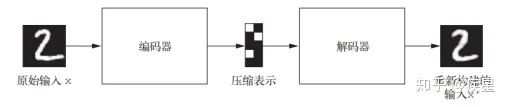
圖15 經典自編碼器的工作流程示意圖
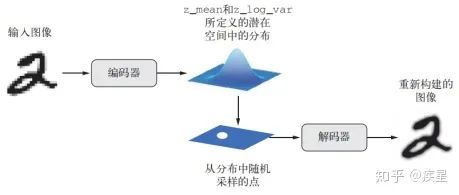
圖16 變分自編碼器的工作流程(z_mean和z_log_var分別代表潛在圖像通過編碼器映射后的均值和方差) 使用mnist數據集作為變分自編碼器訓練數據集,生成的圖像如圖17所示:

圖17 VAE生成的手寫數字圖像 3.4 生成式對抗網絡(GAN,Generative adversarial network) GAN由Goodfello等人于 2014 年提出,它可以替代VAE來學習圖像的潛在空間,其生成的圖像與真實圖像在統計上幾乎無法區分,從而生成相當逼真的合成圖像。 GAN結構由一個偽造者網絡和一個專家網絡組成,二者訓練的目的都是為了打敗彼此。生成器網絡(generator network)以一個隨機向量(潛在空間中的一個隨機點)作為輸入,并將其解碼為一張合成圖像。判別器網絡(discriminator network)又稱為對手網絡(adversary),以一張圖像(真實或合成均可)作為輸入,并預測該圖像來自訓練集還是生成器網絡。訓練生成器網絡的目的是使其能夠欺騙判別器網絡,因此隨著訓練的進行,它能夠逐漸生成越來越逼真的圖像,即看起來與真實圖像無法區分的人造圖像,以至于判別器網絡無法區分二者。GAN工作流程如圖18所示:
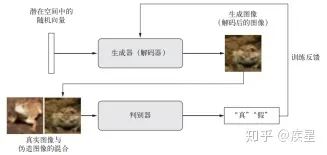
圖18 GAN網絡的訓練流程示意圖 訓練GAN和調節GAN實現的過程非常困難,此處不再贅述,讀者可自行查閱相關資料了解,使用GAN生成的人臉圖像如圖19所示:

圖19 GAN在人臉圖像集上訓練生成的圖像
三.總結
本文第一部分介紹了深度學習領域中圖像處理的常用技巧,主要包括數據增強、圖像去噪以及圖像增強領域中的圖像高分辨率重建技術(SR,Super Resolution)。數據增強能根據原始圖像生成內容、風格相似的更多訓練圖像,可有效解決因訓練圖像不足帶來的曲線過擬合;圖像去噪技術的代表是常見的高斯濾波算法和去噪神經網絡,其共同特征是有效過濾圖片傳輸中受到的干擾波動,有利于后續的圖像處理;圖像高分辨率重建是圖像增強領域的顯著代表,其基本思想是通過提取原始低分辨率圖片的特征,變換映射得到高分辨率圖片。這種技術不僅完整保留了原始圖片的內容和風格(圖像的有效信息),也提升了變換后的圖片質量。 本文第二部分簡要分析深度學習技術在圖像處理領域的主要應用,按照不同功能劃分為圖像變換、圖像識別和圖像生成三個領域。圖像變換是圖像處理最簡單、基本的操作;圖像識別是計算機視覺的重要分支研究領域,目的是達到深度學習圖像識別網絡識別精度和效率的提升,實際應用于人臉識別和遙感圖像識別等方面;最后概述了圖像生成應用的幾個分支:包括神經風格遷移(NST,Neural Style Transfer)和變分自編碼器(VAE,Variational autoencode)等。Deep Dream可以看做訓練集為Image Net的神經風格遷移網絡,它們的共同特點是:從參考圖像中進行內容和風格的提取組合后,根據要求生成不同種類的目標圖片。圖像生成領域的另一個重要分支為生成式對抗網絡(GAN,Generative adversarial network),可以生成與原始圖像非常相似的目標圖像,感興趣的讀者可以自行了解。 圖像處理領域是深度學習和機器視覺領域重要的研究分支,相信在未來必將得到蓬勃的發展。本文涉及的圖像和代碼可在https://github.com/asbfighting/-.git中下載和訪問。 ? 參考文獻: [1](美)Francois Chollet著,python深度學習[M],張亮譯,北京;人民郵電出版社,2018.8 [2] 候宜軍著,Keras深度學習實戰[M],北京;北京圖靈文化發展公司,2017,6 [3]Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: ECCV. (2014) 184–199 [4] Aharon, M., Elad, M., Bruckstein, A.: K-SVD: An algorithm for designing over complete dictionaries for sparse representation. TSP 54(11), 4311–4322 (2006) [5] Burger, H.C., Schuler, C.J., Harmeling, S.: Image denoising: Can plain neural net works compete with BM3D? In: CVPR. pp. 2392–2399 (2012) [6] Freedman, G., Fattal, R.: Image and video upscaling from local self-examples. TOG 30(2), 12 (2011) [7] Yang, J., Lin, Z., Cohen, S.: Fast image super-resolution based on in-place example regression. In: CVPR. pp. 1059–1066 (2013) [8] Dong, C., Loy, C.C., He, K., Tang, X.:Accelerating the Super-Resolution Convolutional Neural (https://Network.In) ECCV.(2016) [9] Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. TPAMI?38(2) (2015) 295–307 [10] Yang, C.Y., Yang, M.H.: Fast direct super-resolution by simple functions. In: ICCV. (2013) 561–568 [11] Timofte, R., De Smet, V., Van Gool, L.: Anchored neighborhood regression for fast example based super-resolution. In: ICCV. (2013) 1920–1927 [12] Gatys L A , Ecker A S , Bethge M . A Neural Algorithm of Artistic Style[J]. Computer Science, 2015. [13] Rezende D J , Mohamed S , Wierstra D . Stochastic Backpropagation and Approximate Inference in Deep Generative Models[J]. 2014. [14] Kingma D P , Welling M . Auto-Encoding Variational Bayes[J]. 2013.
編輯:黃飛
























 工商網監
工商網監
評論