 電子發(fā)燒友App
電子發(fā)燒友App


????這些年深度學(xué)習(xí)太火了,你肯定疑惑深度學(xué)習(xí)網(wǎng)絡(luò)看起來無比強(qiáng)大,但為什么直到這十多年才火熱起來呢?從技術(shù)上來說,深度學(xué)習(xí)并不是一個(gè)特別高深,特別新穎的技術(shù),很多是“舊瓶裝新酒”。但在此之前,由于計(jì)算資源缺乏和數(shù)據(jù)的缺失,使得嚴(yán)重依賴于“算力”和“數(shù)據(jù)”的深度學(xué)習(xí)技術(shù)難以實(shí)用化。而現(xiàn)在芯片技術(shù)快速發(fā)展,具備了暴力計(jì)算的可能;各種數(shù)據(jù)似乎隨手可得,學(xué)習(xí)資源也不再是瓶頸。當(dāng)這些限制性的天花板被一個(gè)一個(gè)被打開后,深度學(xué)習(xí)終于迎來了他的春天。現(xiàn)在,你別嫌棄它“好傻好暴力”,它就是“很強(qiáng)很實(shí)用”。
深度學(xué)習(xí)的核心就是"深度" ,從實(shí)現(xiàn)上深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)就是一種包括多個(gè)隱含層的多層感知機(jī),它通過組合低層特征,形成更為抽象的高層表示,用以描述被識別對象的高級屬性類別或特征,深度學(xué)習(xí)的“深”就是指層數(shù)多。我們把這四周一起學(xué)習(xí)的內(nèi)容串一下,你能清晰的看到從上個(gè)世紀(jì)中“感知機(jī)”一步步發(fā)展到現(xiàn)在的“深度學(xué)習(xí)網(wǎng)絡(luò)”,Deep learning幾經(jīng)起伏,走過了這條由“淺”變“深”之路。 ? ? ? ? ?
下面我們就一起來回顧一下。 1、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)是兩兄弟么? 劃重點(diǎn):學(xué)習(xí)的核心是改善性能,深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)分支,它的發(fā)展幾經(jīng)起伏。近十年伴隨著算法成熟、數(shù)據(jù)爆炸,算力俱增,深度學(xué)習(xí)走入舞臺中心。 (1)西蒙教授(Herbert Simon)是1975年圖靈獎(jiǎng)獲得者、1978年諾貝爾經(jīng)濟(jì)學(xué)獎(jiǎng)獲得者,他給學(xué)習(xí)下的定義是“學(xué)習(xí)的核心目的就是改善性能”。 (2)機(jī)器學(xué)習(xí)(Machine Learning)是人工智能(Artificial Intelligence)的一個(gè)分支,深度學(xué)習(xí)(Deep Learning)是機(jī)器學(xué)習(xí)中的一個(gè)子集,或者說,機(jī)器學(xué)習(xí)是實(shí)現(xiàn)人工智能的一種方法,而深度學(xué)習(xí)僅僅是實(shí)現(xiàn)機(jī)器學(xué)習(xí)的一種技術(shù)。 (3)上個(gè)世紀(jì)50年代至今,從1958年感知機(jī)實(shí)現(xiàn),到BP神經(jīng)網(wǎng)絡(luò)的出現(xiàn),再到2006年傳奇的辛頓(Geoffrey Hinton)及其學(xué)生掀起深度學(xué)習(xí)的第三次浪潮,幾經(jīng)起伏后深度學(xué)習(xí)終于走上前臺。而在此之后,伴隨著數(shù)據(jù)量的爆炸式增長與計(jì)算能力的與日俱增,深度學(xué)習(xí)得到了進(jìn)一步的發(fā)展。
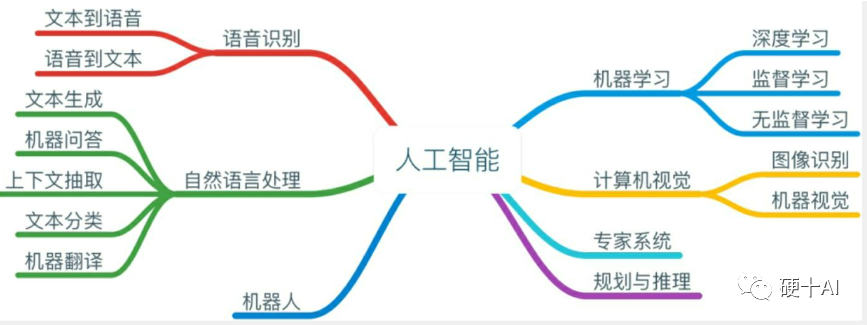
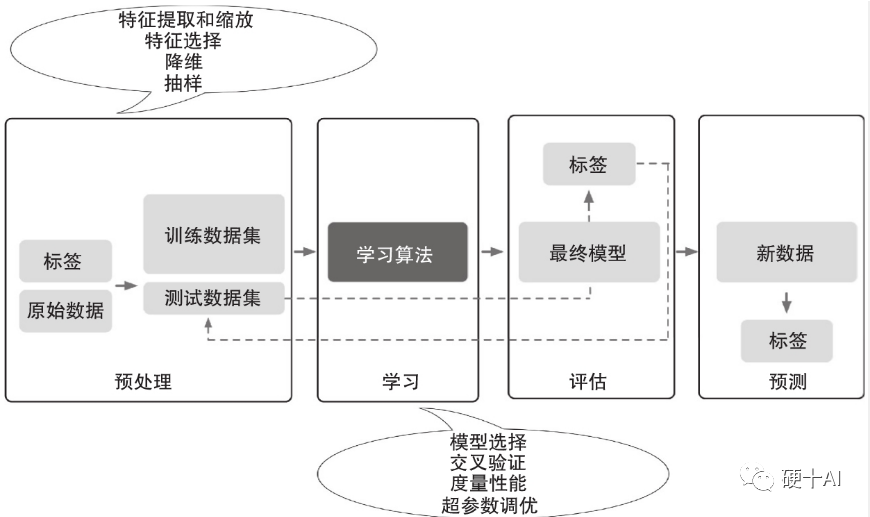
2、機(jī)器學(xué)習(xí)就是找到一個(gè)“好用的”函數(shù)? 劃重點(diǎn):研究機(jī)器學(xué)習(xí)的過程是尋找有效算法的過程,算法是由一系列函數(shù)組成的,“好算法”的基石是“好的函數(shù)”。 (1)我們可以這樣理解機(jī)器學(xué)習(xí)“從數(shù)據(jù)中學(xué)習(xí),形成有效經(jīng)驗(yàn),提升執(zhí)行任務(wù)/工作的表現(xiàn)”,因此對于研究機(jī)器學(xué)習(xí)就是不斷找尋更有效算法,而算法的基石是一個(gè)個(gè)函數(shù),臺灣大學(xué)李宏毅博士這樣定義“機(jī)器學(xué)習(xí)在形式上可近似等同在數(shù)據(jù)對象中通過統(tǒng)計(jì)或推理的方法,尋找一個(gè)有關(guān)特定輸入和預(yù)期輸出的功能函數(shù)f”。 (2)如何找到好用的函數(shù)呢?這個(gè)程包括建模、評估、優(yōu)化散步。“建模”是找一系列的函數(shù)來實(shí)現(xiàn)預(yù)期的功能,“評估”是制定每個(gè)環(huán)節(jié)的評價(jià)標(biāo)準(zhǔn),“優(yōu)化”是調(diào)試到性能最佳的函數(shù)。
3、學(xué)好數(shù)理化,走遍天下都不怕? 劃重點(diǎn):理解機(jī)器學(xué)必備的數(shù)學(xué)基礎(chǔ)知識包括線性代數(shù)、微積分、概率論等等,除了數(shù)學(xué)基礎(chǔ)以外,編程能力和英文內(nèi)功也很重要。 (1)理解機(jī)器學(xué)習(xí)必備的數(shù)學(xué)基礎(chǔ)知識包括線性代數(shù)、微積分、概率論、最優(yōu)化理論等等,我們需要把數(shù)學(xué)知識點(diǎn)串聯(lián)到自己的知識體系中,再以數(shù)學(xué)思維去理解人工智能的工具和行為。 (2)機(jī)器學(xué)習(xí)涉及到非常廣泛的知識域,要學(xué)習(xí)的東西太多就很容易讓人發(fā)慌,打好基礎(chǔ)尤為關(guān)鍵,總結(jié)起來就是“數(shù)學(xué)是基礎(chǔ),編程是手段,英文是內(nèi)功”。
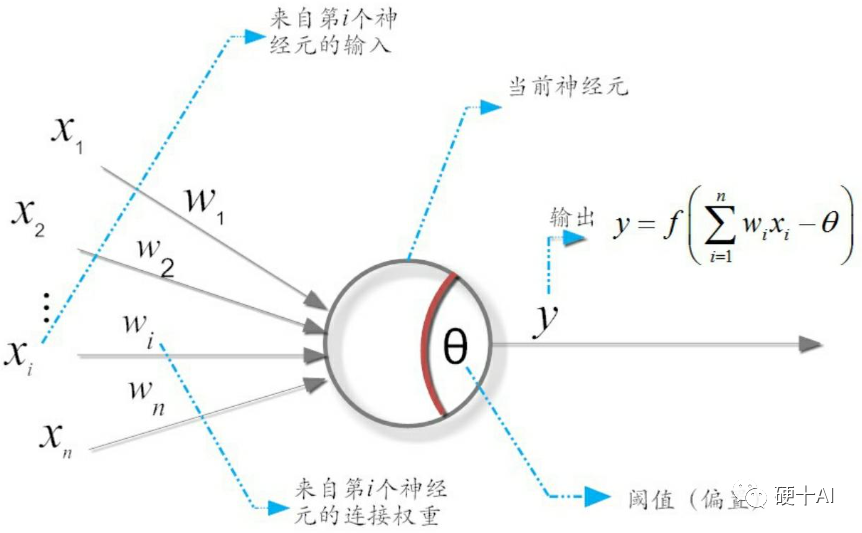
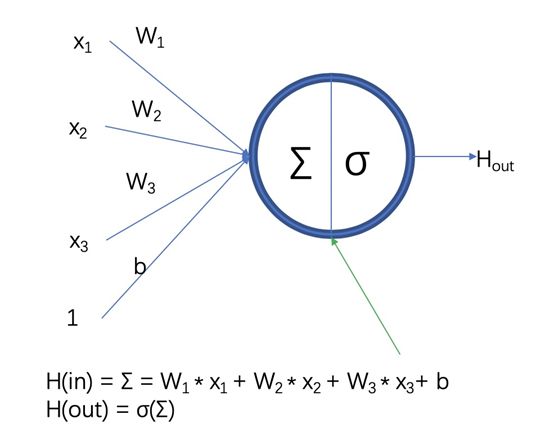
4、機(jī)器學(xué)習(xí)中的函數(shù)(1)- 激活函數(shù)和感知機(jī) 劃重點(diǎn):機(jī)器學(xué)習(xí)研究的突破始于仿生學(xué),基于“M-P神經(jīng)元模型”實(shí)現(xiàn)了感知機(jī),感知機(jī)中激活函數(shù)根據(jù)不同應(yīng)用要求不斷演進(jìn)。但感知機(jī)難以實(shí)現(xiàn)“異或”邏輯操作,成為致命短板。 (1)機(jī)器學(xué)習(xí)研究的突破始于仿生學(xué),模仿大腦神經(jīng)元的最早實(shí)例是20世紀(jì)40年代提出的“M-P神經(jīng)元模型”,提出者是神經(jīng)生理學(xué)家麥克洛克(Warren McCulloch)和數(shù)學(xué)家皮茨(Walter Pitts),論文首次實(shí)現(xiàn)了用一個(gè)簡單電路(也就是未來大名鼎鼎的感知機(jī))來模擬大腦神經(jīng)元的行為。 (2)M-P神經(jīng)元模型中,神經(jīng)元接收來自n個(gè)其他神經(jīng)元傳遞過來的輸入信號,這些信號的表達(dá)通常通過神經(jīng)元之間連接的權(quán)重Weight大小來表示,神經(jīng)元將接收到的輸入值按照某種權(quán)重疊加起來,匯集了所有其他外聯(lián)神經(jīng)元的輸入,并將其作為一個(gè)結(jié)果輸出。但這種輸出并非直接輸出,而是與當(dāng)前神經(jīng)元的閾值θ進(jìn)行比較,然后通過激活函數(shù)f(Activation Function)向外表達(dá)輸出,y即為最終輸出。激活函數(shù)不斷變化,包括Sigmoid、Tanh 、ReLU、Softmax等等,根據(jù)不同需求各顯神通。 (3)感知機(jī)是由心理學(xué)教授羅森布拉特(Frank Rosenblatt)在1957年提出的一種人工神經(jīng)網(wǎng)絡(luò),是形式最簡單的前饋式人工神經(jīng)網(wǎng)絡(luò),是一種二元線性分類器,難以實(shí)現(xiàn)常見的“異或”邏輯操作,1972年明斯基出版了《感知機(jī):計(jì)算幾何簡介》一書中點(diǎn)明了這個(gè)問題,機(jī)器學(xué)習(xí)研究進(jìn)入漫長寒冬。什么技術(shù)進(jìn)步幫助機(jī)器學(xué)習(xí)走出這個(gè)寒冬呢?
5、機(jī)器學(xué)習(xí)中的函數(shù)(2)- 多層前饋網(wǎng)絡(luò)巧解“異或”問題,損失函數(shù)上場優(yōu)化網(wǎng)絡(luò)性能? 劃重點(diǎn):前饋神經(jīng)網(wǎng)絡(luò)由單層前饋?zhàn)兂啥鄬忧梆伜螅芰ι墸梢越鉀Q“異或”問題。多層神經(jīng)網(wǎng)絡(luò)利用損失函數(shù)計(jì)算調(diào)節(jié)網(wǎng)絡(luò)中參數(shù),但面對越來越復(fù)雜的網(wǎng)絡(luò)高效尋找參數(shù)是一個(gè)很大挑戰(zhàn)。 (1)多層前饋網(wǎng)絡(luò)(Multi-layer Feedforward NeuralNetworks)誕生了,在輸出層與輸入層之間的再增加多層神經(jīng)元,即增加“隱含層(hidden layer),大大提升網(wǎng)絡(luò)能力,升級后可以解決“異或”問題。 (2)機(jī)器學(xué)習(xí)的應(yīng)用中,多層神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的本質(zhì)就是利用損失函數(shù)來調(diào)節(jié)網(wǎng)絡(luò)中的權(quán)重,然后根據(jù)網(wǎng)絡(luò)輸出與預(yù)期輸出之間的差值,采用迭代的算法,改變前面各層的參數(shù),直至網(wǎng)絡(luò)收斂穩(wěn)定。 (3)網(wǎng)絡(luò)層數(shù)增加,變得更加復(fù)雜了,遇到的問題變成如何從眾多網(wǎng)絡(luò)參數(shù)中找到最佳參數(shù),包括神經(jīng)元之間的連接權(quán)值和偏置等。簡單粗暴的方法當(dāng)然就是枚舉所有可能的權(quán)值,然后優(yōu)中選優(yōu),但對于稍微復(fù)雜的網(wǎng)絡(luò),這種策略的計(jì)算量是天文數(shù)字,根本不可行。如何高效地找到這些能讓損失函數(shù)達(dá)到極小值的參數(shù)呢?
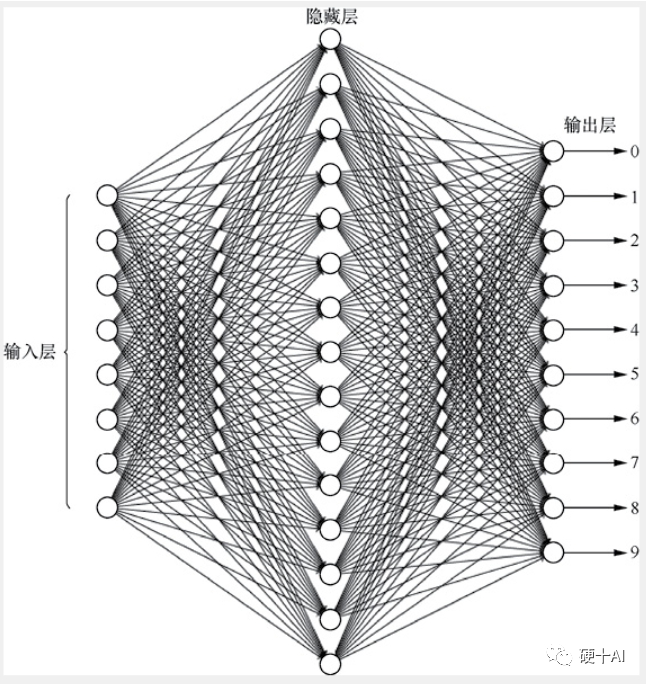
6、機(jī)器學(xué)習(xí)中的函數(shù)(3) - "梯度下降"走捷徑,"BP算法"提效率? 劃重點(diǎn):基于梯度下降策略的BP算法提出,能高效地找到復(fù)雜網(wǎng)絡(luò)中損失函數(shù)的極小值,但是BP算法本身的缺點(diǎn)又限制了神經(jīng)網(wǎng)絡(luò)“變深變強(qiáng)”,神經(jīng)網(wǎng)絡(luò)研究慢慢走入低潮。 (1)為了高效地找到復(fù)雜網(wǎng)絡(luò)中損失函數(shù)的極小值,沃伯斯(Paul Werbos)提出了誤差反向傳播(error BackPropagation)BP算法,大神辛頓(Geoffrey Hinton)積極推動(dòng)BP算法應(yīng)用。 (2)BP算法其實(shí)是一個(gè)雙向算法,正向傳播信號,輸出分類信息;反向傳播誤差,調(diào)整網(wǎng)絡(luò)權(quán)值 。BP算法基于梯度下降(gradient descent)策略,梯度下降法是一種常用的最優(yōu)化問題求解方法,BP算法以目標(biāo)的負(fù)梯度方向?qū)?shù)進(jìn)行調(diào)整,采用“鏈?zhǔn)椒▌t”求解復(fù)合函數(shù)的導(dǎo)數(shù),獲得梯度值作為調(diào)整依據(jù)。 (3)BP算法的缺點(diǎn)也有很多,在神經(jīng)網(wǎng)絡(luò)的層數(shù)更多時(shí),很容易陷入局部最優(yōu)解,亦容易過擬合,同時(shí)它也只能應(yīng)用于一個(gè)全連接的網(wǎng)絡(luò)。在上個(gè)世紀(jì)最后10年,他的這個(gè)缺陷在某種程度上又把神經(jīng)網(wǎng)絡(luò)研究送到了一個(gè)新的低潮期,什么技術(shù)進(jìn)步幫助機(jī)器學(xué)習(xí)走出這個(gè)寒冬呢?
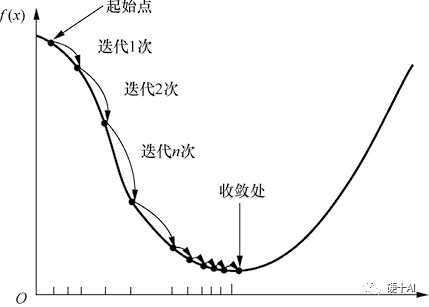
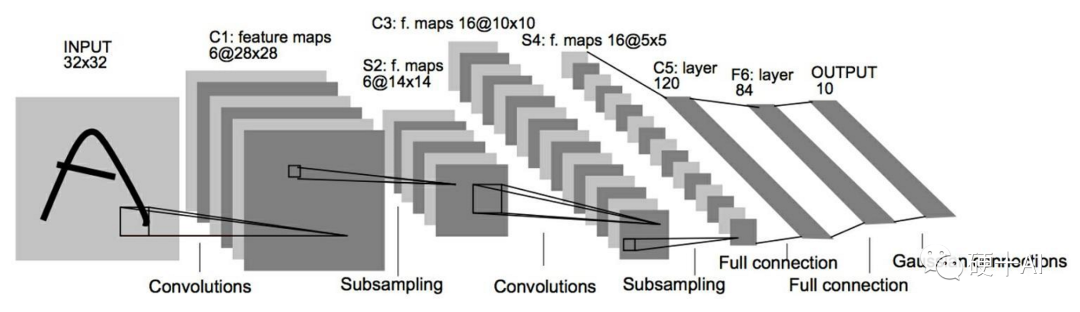
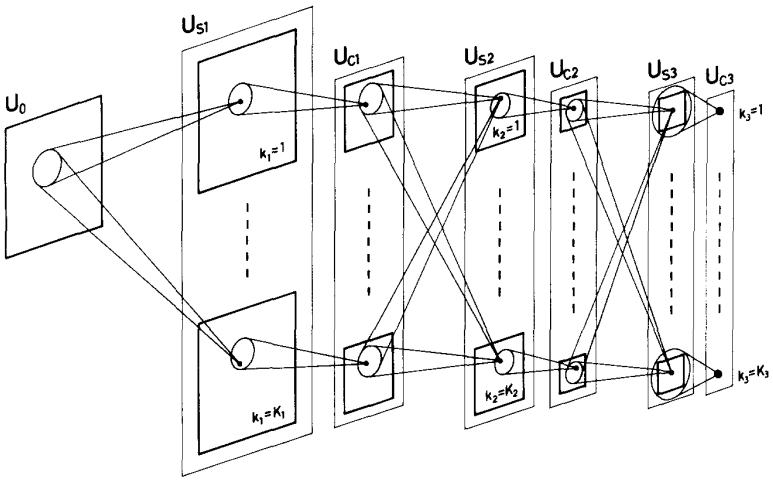
7、機(jī)器學(xué)習(xí)中的函數(shù)(4) - 全連接限制發(fā)展,卷積網(wǎng)絡(luò)閃亮登場 劃重點(diǎn):引入卷積核進(jìn)行特征提取,再通過池化層進(jìn)一步降低數(shù)據(jù)規(guī)模,神經(jīng)網(wǎng)絡(luò)經(jīng)過改良后,具備了“由淺變深”的能力,卷積神經(jīng)網(wǎng)絡(luò)即將出場。 (1)BP算法的種種缺陷使它終歸只能適用于“淺層”網(wǎng)絡(luò),當(dāng)這種全連接結(jié)構(gòu)的網(wǎng)絡(luò)“變深”后,海量的連接權(quán)值難以訓(xùn)練,并且多而雜的信息獲取和處理方式使它很難提取到有用的特征,特征歸納能力差,這種“淺層”網(wǎng)絡(luò)難堪大用了,解決這個(gè)問題需要引入有“高效的執(zhí)行特征抽取”能力的網(wǎng)絡(luò)。 (2)應(yīng)用卷積進(jìn)行特征提取是卷積神經(jīng)網(wǎng)絡(luò)中的第一步,在楊立昆(Yann LeCun)提出的經(jīng)典LeNet-5神經(jīng)網(wǎng)絡(luò)中,先用卷積核完成特征提取,卷積之后再通過池化層(又稱亞采樣層)降低數(shù)據(jù)規(guī)模,進(jìn)一步完善特征提取和數(shù)據(jù)整理的工作,這樣進(jìn)入全連接層的數(shù)據(jù)品質(zhì)大大提高,不再是那種“魚龍混雜”的海量數(shù)據(jù)了,而是經(jīng)過反復(fù)提純過的優(yōu)質(zhì)數(shù)據(jù)了。這么好的工具我們怎么樣放到神經(jīng)網(wǎng)絡(luò)里?我們的主角卷積神經(jīng)網(wǎng)絡(luò)(Convolutional NeuralNetwork,CNN)要出現(xiàn)了。
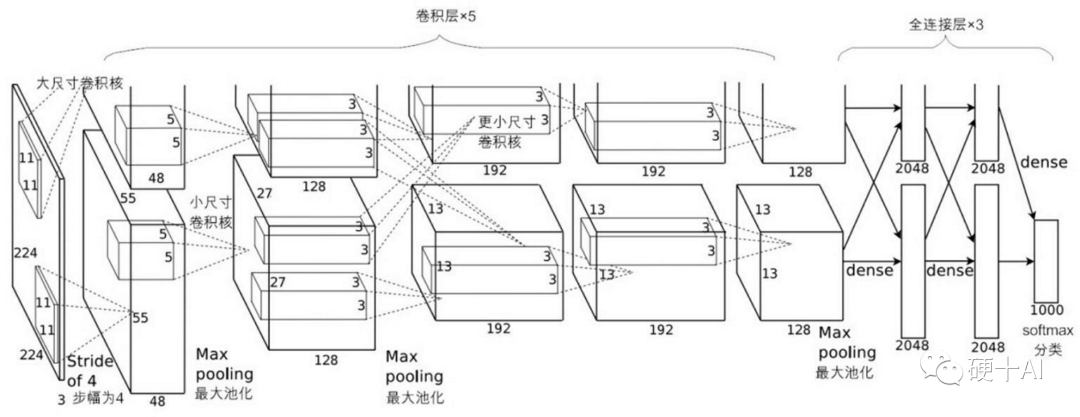
8、機(jī)器學(xué)習(xí)中的函數(shù)(5) - “算法、算力,數(shù)據(jù)”已齊備,深度學(xué)習(xí)走入舞臺中心 劃重點(diǎn):卷積神經(jīng)網(wǎng)絡(luò)通過技術(shù)創(chuàng)新成功的應(yīng)用在了機(jī)器視覺領(lǐng)域,推動(dòng)深度學(xué)習(xí)進(jìn)入繁榮期,結(jié)合不同類型的應(yīng)用,RNN、GAN等網(wǎng)絡(luò)也各顯神威。 (1)典型的卷積神經(jīng)網(wǎng)絡(luò)通常由若干個(gè)卷積層(Convolutional Layer)、激活層(Activation Layer)、池化層(Pooling Layer)及全連接層(Fully Connected Layer)組成,各個(gè)層各司其職,卷積層從數(shù)據(jù)中提取有用的特征;激活層在網(wǎng)絡(luò)中引入非線性,通過彎曲或扭曲映射,來實(shí)現(xiàn)表征能力的提升;池化層通過采樣減少特征維度,并保持這些特征具有某種程度上的尺度變化不變性;在全連接層實(shí)施對象的分類預(yù)測。 (2)2012年,辛頓(Hinton)和他的博士生(Alex Krizhevsky)等提出了AlexNet ,一舉拿下當(dāng)時(shí)ImageNet比賽的冠軍。Alexnet強(qiáng)化了典型CNN的架構(gòu),應(yīng)用到更深更寬的網(wǎng)絡(luò)中,還首次在CNN中成功應(yīng)用了ReLU、Dropout等技術(shù)。由于它的出現(xiàn),人們更加相信深度學(xué)習(xí)可以被應(yīng)用于機(jī)器視覺領(lǐng)域,點(diǎn)燃了大家對深度學(xué)習(xí)的熱情,深度學(xué)習(xí)很快進(jìn)入了繁榮期。 (3)卷積神經(jīng)網(wǎng)絡(luò)是實(shí)現(xiàn)深度學(xué)習(xí)的重要方法之一,但它也不是能包攬所有應(yīng)用的,我們把卷積神經(jīng)網(wǎng)絡(luò)(CNN,Convolutional Neural Network)稱作破譯圖像的神器,把循環(huán)神經(jīng)網(wǎng)絡(luò)( RNN,Recurrent Neural Network)定義洞悉語言的內(nèi)涵的好工具,我們引入生成對抗網(wǎng)絡(luò)(GAN, Generative Adversarial Network),提升網(wǎng)絡(luò)性能。總之,結(jié)合實(shí)際應(yīng)用深度學(xué)習(xí)的技術(shù)還是在快速發(fā)展之中。
我們分享這些知識也僅僅是深度學(xué)習(xí)這個(gè)龐大的知識域中很小的一部分,比如過擬合、Relu函數(shù),超參數(shù),對抗網(wǎng)絡(luò)等等有趣的話題我們還沒有機(jī)會和大家一起學(xué)習(xí)。不過大家千萬不要被知識內(nèi)容的龐雜嚇到了,就像我們這四周的學(xué)習(xí)過程一樣,先把主干建立起來,當(dāng)你有一個(gè)體系化、成脈絡(luò)的知識主干后,再不斷添磚加瓦,逐步修正,你一定能修建出你自己的知識教堂來
編輯:黃飛
?





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論