 電子發燒友App
電子發燒友App


前言
最近在重刷李航老師的《統計機器學習方法》嘗試將其與NLP結合,通過具體的NLP應用場景,強化對書中公式的理解,最終形成「統計機器學習方法 for NLP」的系列。這篇將介紹隱馬爾可夫模型HMM(「絕對給你一次講明白」)并基于HMM完成一個中文詞性標注的任務。
HMM是什么
「隱馬爾可夫模型(Hidden Markov Model, HMM)」 是做NLP的同學繞不過去的一個基礎模型, 是一個生成式模型, 通過訓練數據學習隱變量 和觀測變量 的聯合概率分布 。
HMM具有「兩個基本假設」:
齊次馬爾可夫性假設: 時刻的隱變量 只跟前一個時刻的隱變量 有關
觀測獨立性: 任意時刻的觀測變量 只與該時刻的隱變量 有關。所以可以構成下面一個有向圖, 從而 可以分解成圖上邊的概率乘積。
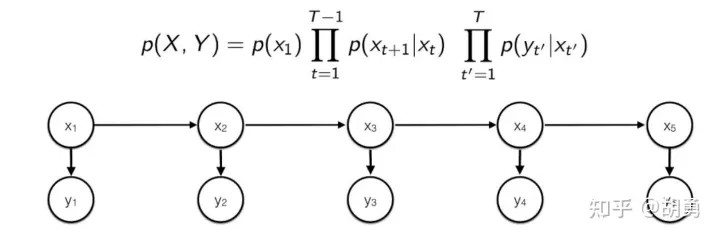
「訓練階段」:通過對訓練數據進行極大似然估計, 得到HMM模型的參數:初始概率向量 (對應圖中的 ),隱變量之間的轉移概率矩陣 (對應圖中的 ,隱變量到觀測變量之前的轉移概率矩陣 ((對應圖中的 。
「預測階段」: 給定觀測變量 ,解出使 概率最大的隱變量。因為HMM是一個生成模型, 所以模型在預測階段需要從全部可能的隱變量 中找到使得 最大的那個 。然而假設步長為 , 對于每一步 ,隱變量 可能的取值有 個, 那么全部可能的隱變量 個數為 , 這是一個指數級的時間復雜度,窮 舉 肯 定 是 不 現 實 的 。 所 以 就 引 入 了 維 特 比 算 法(Viterbi algorithm)進行剪枝。
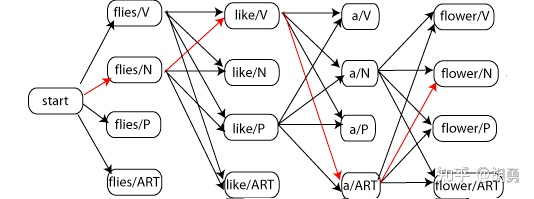
維特比算法的簡單的說就是「提前終止了不可能路徑」。具體而言, 在每一步遍歷全部的 個節點,對于每一個節點繼續遍歷可能來源于上一步的 個節點, 只保留上一步 () 個節點中概率最大的路徑, 裁剪其余的 條路徑。所以時間復雜度降低到 , 相比指數級的暴力枚舉, 這是可接受的。
值得注意的是現在在深度學習在解碼階段基本不用「維特比算法」解碼而更多的是使用「beam search」解碼。這是因為「維特比算法」需要一個很強的假設:當前節點只與上一個點有關, 這也正是齊次馬爾可夫性假設, 所以路徑整體概率才可以表示成各個子路徑相乘的形式。但是深度學習時代的解碼則不滿足這個假設, 即, 而需要整體考慮, 所以beam search始終保留「整體最優」的個結果。
基于HMM的詞性標注
詞性標注是指給定一句話(已經完成了分詞),給這個句子中的每個詞標記上詞性,例如名詞,動詞,形容詞等。這是一項最基礎的NLP任務,可以給很多高級的NLP任務例如信息抽取,語音識別等提供有用的先驗信息。

這個任務中我們認為隱變量是詞性(名詞,動詞等),觀測變量是中文的詞語,需要進行的建模。
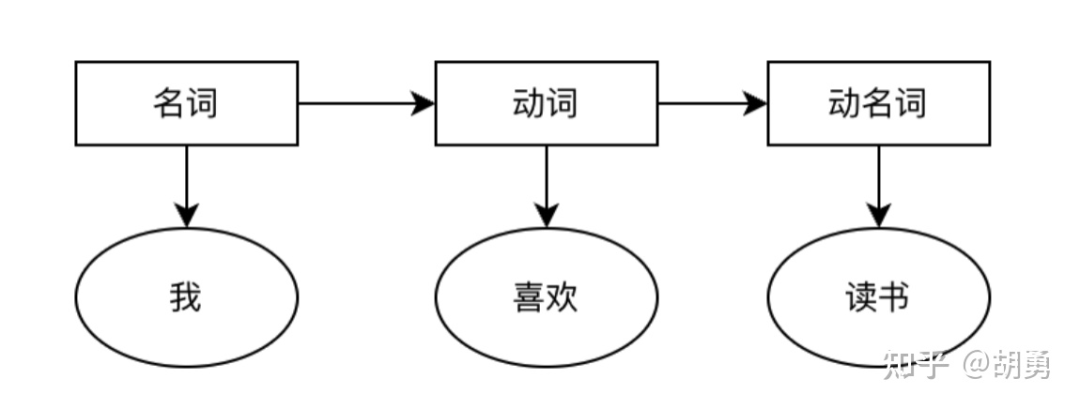
下面將分為:「數據處理,模型訓練,模型預測」 三個部分 來介紹如果利用HMM實現詞性標注
數據處理
這里采用「1998人民日報詞性標注語料庫」進行模型的訓練,包括44個基本詞性以及19484個句子。具體可以參考這里:https://www.heywhale.com/mw/dataset/5ce7983cd10470002b334de3
PFR語料庫是對人民日報1998年上半年的純文本語料進行了詞語切分和詞性標注制作而成的,嚴格按照人民日報的日期、版序、文章順序編排的。文章中的每個詞語都帶有詞性標記。目前的標記集里有26個基本詞類標記(名詞n、時間詞t、處所詞s、方位詞f、數詞m、量詞q、區別詞b、代詞r、動詞v、形容詞a、狀態詞z、副詞d、介詞p、連詞c、助詞u、語氣詞y、嘆詞e、擬聲詞o、成語i、習慣用語l、簡稱j、前接成分h、后接成分k、語素g、非語素字x、標點符號w)外,從語料庫應用的角度,增加了專有名詞(人名nr、地名ns、機構名稱nt、其他專有名詞nz);從語言學角度也增加了一些標記,總共使用了40多個個標記。
2. 模型訓練
根據數據估計HMM的模型參數:全部的詞性集合,全部的詞集合,初始概率向量,詞性到詞性的轉移矩陣 ?,詞性到詞的轉移矩陣。 這里直接采用頻率估計概率的方法,但是對于會存在大量的0,所以需要進一步采用「拉普拉斯平滑處理」。
#?統計words和tags words?=?set() tags?=?set() for?words_with_tag?in?sentences: ????for?word_with_tag?in?words_with_tag: ????????word,?tag?=?word_with_tag ????????words.add(word) ????????tags.add(tag) words?=?list(words) tags?=?list(tags) #?統計?詞性到詞性轉移矩陣A?詞性到詞轉移矩陣B?初始向量pi #?先初始化 A?=?{tag:?{tag:?0?for?tag?in?tags}?for?tag?in?tags} B?=?{tag:?{word:?0?for?word?in?words}?for?tag?in?tags} pi?=?{tag:?0?for?tag?in?tags} #?統計A,B for?words_with_tag?in?sentences: ????head_word,?head_tag?=?words_with_tag[0] ????pi[head_tag]?+=?1 ????B[head_tag][head_word]?+=?1 ????for?i?in?range(1,?len(words_with_tag)): ????????A[words_with_tag[i-1][1]][words_with_tag[i][1]]?+=?1 ????????B[words_with_tag[i][1]][words_with_tag[i][0]]?+=?1 #?拉普拉斯平滑處理并轉換成概率 sum_pi_tag?=?sum(pi.values()) for?tag?in?tags: ????pi[tag]?=?(pi[tag]?+?1)?/?(sum_pi_tag?+?len(tags)) ????sum_A_tag?=?sum(A[tag].values()) ????sum_B_tag?=?sum(B[tag].values()) ????for?next_tag?in?tags: ????????A[tag][next_tag]?=?(A[tag][next_tag]?+?1)?/?(sum_A_tag?+?len(tags)) ????for?word?in?words: ????????B[tag][word]?=?(B[tag][word]?+?1)?/?(sum_B_tag?+?len(words))
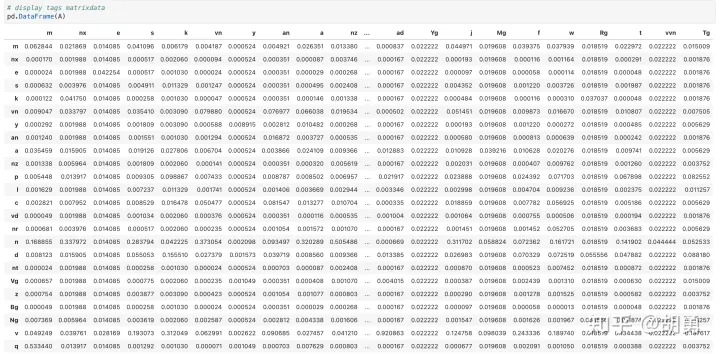
看一下詞性轉移矩陣
3. 模型預測
在預測階段基于維特比算法進行解碼
def?decode_by_viterbi(sentence):
????words?=?sentence.split()
????sen_length?=?len(words)
????T1?=?[{tag:?float('-inf')?for?tag?in?tags}?for?i?in?range(sen_length)]
????T2?=?[{tag:?None?for?tag?in?tags}?for?i?in?range(sen_length)]
????#?先進行第一步
????for?tag?in?tags:
????????T1[0][tag]?=?math.log(pi[tag])?+?math.log(B[tag][words[0]])
????#?繼續后續解碼
????for?i?in?range(1,?sen_length):
????????for?tag?in?tags:
????????????for?pre_tag?in?tags:
????????????????current_prob?=?T1[i-1][pre_tag]?+?math.log(A[pre_tag][tag])?+?math.log(B[tag][words[i]])
????????????????if?current_prob?>?T1[i][tag]:
????????????????????T1[i][tag]?=?current_prob
????????????????????T2[i][tag]?=?pre_tag
????#?獲取最后一步的解碼結果
????last_step_result?=?[(tag,?prob)?for?tag,?prob?in?T1[sen_length-1].items()]
????last_step_result.sort(key=lambda?x:?-1*x[1])
????last_step_tag?=?last_step_result[0][0]
????#?向前解碼
????step?=?sen_length?-?1
????result?=?[last_step_tag]
????while?step?>?0:
????????last_step_tag?=?T2[step][last_step_tag]
????????result.append(last_step_tag)
????????step?-=?1
????result.reverse()
????return?list(zip(words,?result))
最后進行簡單的測試
decode_by_viterbi('我?和?我?的?祖國')
[('我',?'r/代詞'),?
?('和',?'c/連詞'),?
?('我',?'r'/代詞),?
?('的',?'u'/助詞),?
?('祖國',?'n'/名詞)]
decode_by_viterbi('中國?經濟?迅速?發展?,?對?世界?經濟?貢獻?很?大')?
[('中國',?'ns/地名'),
?('經濟',?'n/名詞'),
?('迅速',?'ad/形容詞'),
?('發展',?'v/動詞'),
?(',',?'w/其他'),
?('對',?'p/介詞'),
?('世界',?'n/名詞'),
?('經濟',?'n/名詞'),
?('貢獻',?'n/名詞'),
?('很',?'d'/副詞),
?('大',?'a'/形容詞)]
可以看到基本都是正確的,根據文獻HMM一般中文詞性標注的準確率能夠達到85%以上 :)
當然「HMM的缺陷也很明顯」,主要是兩個強假設在實際中是不成立的。因為隱變量不僅僅跟前一個狀態的隱變量有關(跟之前全部的隱藏變量和觀測變量有關),同時當前觀測變量也不僅僅跟當前的隱變量有關(跟之前全部的隱藏變量和觀測變量有關),這也是后面深度學習中RNN等模型嘗試解決的問題了。
編輯:黃飛













 工商網監
工商網監
評論