 電子發(fā)燒友App
電子發(fā)燒友App


近日,國(guó)際數(shù)學(xué)家大會(huì)丨鄂維南院士作一小時(shí)大會(huì)報(bào)告:從數(shù)學(xué)角度,理解機(jī)器學(xué)習(xí)的“黑魔法”,并應(yīng)用于更廣泛的科學(xué)問(wèn)題。
鄂維南院士在2022年的國(guó)際數(shù)學(xué)家大會(huì)上作一小時(shí)大會(huì)報(bào)告(plenary talk)。
今天我們帶來(lái)鄂老師演講內(nèi)容的分享。
鄂老師首先分享了他對(duì)機(jī)器學(xué)習(xí)數(shù)學(xué)本質(zhì)的理解(函數(shù)逼近、概率分布的逼近與采樣、Bellman方程的求解);
然后介紹了機(jī)器學(xué)習(xí)模型的逼近誤差、泛化性質(zhì)以及訓(xùn)練等方面的數(shù)學(xué)理論;
最后介紹如何利用機(jī)器學(xué)習(xí)來(lái)求解困難的科學(xué)計(jì)算和科學(xué)問(wèn)題,即AI for science。

機(jī)器學(xué)習(xí)問(wèn)題的數(shù)學(xué)本質(zhì)
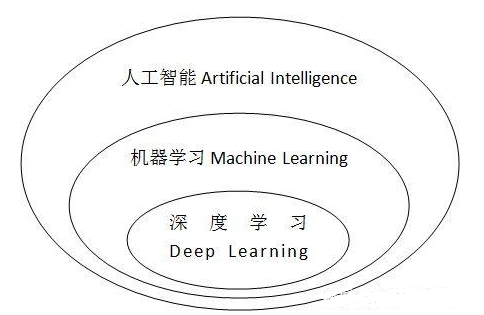
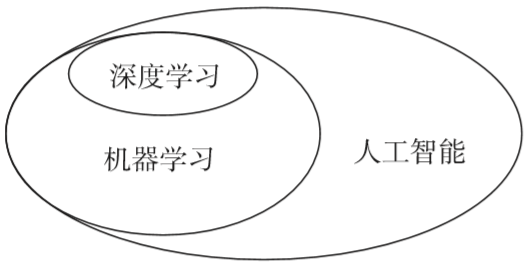
眾所周知,機(jī)器學(xué)習(xí)的發(fā)展,已經(jīng)徹底改變了人們對(duì)人工智能的認(rèn)識(shí)。機(jī)器學(xué)習(xí)有很多令人嘆為觀止的成就,例如:
比人類(lèi)更準(zhǔn)確地識(shí)別圖片:利用一組有標(biāo)記的圖片,機(jī)器學(xué)習(xí)算法可以準(zhǔn)確地識(shí)別圖片的類(lèi)別:

Cifar-10 問(wèn)題:把圖片分成十個(gè)類(lèi)別
來(lái)源:https://www.cs.toronto.edu/~kriz/cifar.html
Alphago下圍棋打敗人類(lèi):完全由機(jī)器學(xué)習(xí)實(shí)現(xiàn)下圍棋的算法:
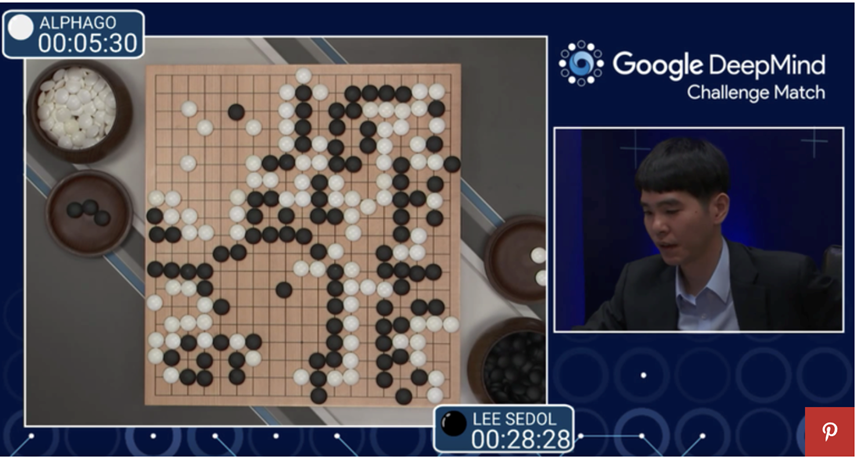
參考:https://www.bbc.com/news/technology-35761246
產(chǎn)生人臉圖片,達(dá)到以假亂真的效果:

參考:https://arxiv.org/pdf/1710.10196v3.pdf
機(jī)器學(xué)習(xí)還有很多其他的應(yīng)用。在日常生活中,人們甚至常常使用了機(jī)器學(xué)習(xí)所提供的服務(wù)而不自知,例如:我們的郵件系統(tǒng)里的垃圾郵件過(guò)濾、我們的車(chē)和手機(jī)里的語(yǔ)音識(shí)別、我們手機(jī)里的指紋解鎖……
所有這些了不起的成就,本質(zhì)上,卻是成功求解了一些經(jīng)典的數(shù)學(xué)問(wèn)題。
對(duì)于圖像分類(lèi)問(wèn)題,我們感興趣的其實(shí)是函數(shù)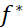 :
:
: 圖像→類(lèi)別
函數(shù)把圖像映射到該圖像所屬的類(lèi)別。我們知道在訓(xùn)練集上的取值,想由此找到對(duì)函數(shù)的一個(gè)足夠好的逼近。
一般而言,監(jiān)督學(xué)習(xí)(supervised learning)問(wèn)題,本質(zhì)都是想基于一個(gè)有限的訓(xùn)練集S,給出目標(biāo)函數(shù)的一個(gè)高效逼近。
對(duì)于人臉生成問(wèn)題,其本質(zhì)是逼近并采樣一個(gè)未知的概率分布。在這一問(wèn)題中,“人臉”是隨機(jī)變量,而我們不知道它的概率分布。然而,我們有“人臉”的樣本:數(shù)量巨大的人臉照片。我們便利用這些樣本,近似得到“人臉”的概率分布,并由此產(chǎn)生新的樣本(即生成人臉)。
一般而言,無(wú)監(jiān)督學(xué)習(xí)本質(zhì)就是利用有限樣本,逼近并采樣問(wèn)題背后未知的概率分布。
對(duì)于下圍棋的Alphago來(lái)說(shuō),如果給定了對(duì)手的策略,圍棋的動(dòng)力學(xué)是一個(gè)動(dòng)態(tài)規(guī)劃問(wèn)題的解。其最優(yōu)策略滿(mǎn)足Bellman方程。因而Alphago的本質(zhì)便是求解Bellman方程。
一般而言,強(qiáng)化學(xué)習(xí)本質(zhì)上就是求解馬爾可夫過(guò)程的最優(yōu)策略。
然而,這些問(wèn)題都是計(jì)算數(shù)學(xué)領(lǐng)域的經(jīng)典問(wèn)題!!畢竟,函數(shù)逼近、概率分布的逼近與采樣,以及微分方程和差分方程的數(shù)值求解,都是計(jì)算數(shù)學(xué)領(lǐng)域極其經(jīng)典的問(wèn)題。那么,這些問(wèn)題在機(jī)器學(xué)習(xí)的語(yǔ)境下,到底和在經(jīng)典的計(jì)算數(shù)學(xué)里有什么區(qū)別呢?答案便是:維度(dimensionality)。
例如,在圖像識(shí)別問(wèn)題中,輸入的維度為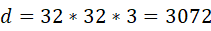 。而對(duì)于經(jīng)典的數(shù)值逼近方法,對(duì)于
。而對(duì)于經(jīng)典的數(shù)值逼近方法,對(duì)于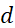 維問(wèn)題,含
維問(wèn)題,含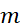 個(gè)參數(shù)的模型的逼近誤差
個(gè)參數(shù)的模型的逼近誤差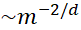 . 換言之,如果想將誤差縮小10倍,參數(shù)個(gè)數(shù)需要增加
. 換言之,如果想將誤差縮小10倍,參數(shù)個(gè)數(shù)需要增加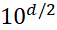 . 當(dāng)維數(shù)增加時(shí),計(jì)算代價(jià)呈指數(shù)級(jí)增長(zhǎng)。這種現(xiàn)象通常被稱(chēng)為:維度災(zāi)難(curse of dimensionality)。
. 當(dāng)維數(shù)增加時(shí),計(jì)算代價(jià)呈指數(shù)級(jí)增長(zhǎng)。這種現(xiàn)象通常被稱(chēng)為:維度災(zāi)難(curse of dimensionality)。
所有的經(jīng)典算法,例如多項(xiàng)式逼近、小波逼近,都飽受維度災(zāi)難之害。很明顯,機(jī)器學(xué)習(xí)的成功告訴我們,在高維問(wèn)題中,深度神經(jīng)網(wǎng)絡(luò)的表現(xiàn)比經(jīng)典算法好很多。然而,這種“成功”是怎么做到的呢?為什么在高維問(wèn)題中,其他方法都不行,但深度神經(jīng)網(wǎng)絡(luò)取得了前所未有的成功呢?
從數(shù)學(xué)出發(fā),理解機(jī)器學(xué)習(xí)的“黑魔法”:監(jiān)督學(xué)習(xí)的數(shù)學(xué)理論
2.1?記號(hào)與設(shè)定
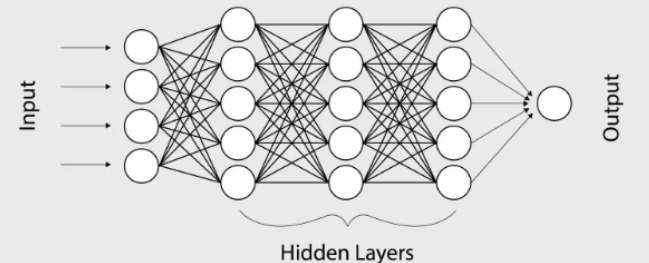
神經(jīng)網(wǎng)絡(luò)是一類(lèi)特殊的函數(shù)。比如,兩層神經(jīng)網(wǎng)絡(luò)是
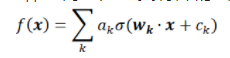
其中有兩組參數(shù)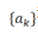 ,和
,和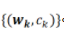 。是激活函數(shù),
。是激活函數(shù),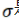 可以是:
可以是: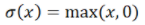 ?,ReLU函數(shù);
?,ReLU函數(shù);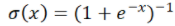 Sigmoid函數(shù)。而神經(jīng)網(wǎng)絡(luò)的基本組成部分即為:線性變換與一維非線性變換。深度神經(jīng)網(wǎng)絡(luò),一般就是如下結(jié)構(gòu)的復(fù)合:
Sigmoid函數(shù)。而神經(jīng)網(wǎng)絡(luò)的基本組成部分即為:線性變換與一維非線性變換。深度神經(jīng)網(wǎng)絡(luò),一般就是如下結(jié)構(gòu)的復(fù)合:
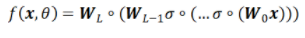
為了簡(jiǎn)便,我們?cè)诖耸÷缘羲械腷ias項(xiàng)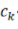 。
。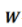 是權(quán)重矩陣,激活函數(shù)
是權(quán)重矩陣,激活函數(shù)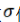 作用在每一個(gè)分量上。
作用在每一個(gè)分量上。
我們將要在訓(xùn)練集S上逼近目標(biāo)函數(shù)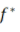
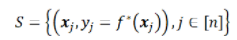 不妨假設(shè)X的定義域?yàn)?img src="https://file1.elecfans.com//web2/M00/98/48/wKgZomTnWSqAeMyZAAAHrbNnLB4888.png" alt="66bf4d06-73d8-11ed-8abf-dac502259ad0.png" />。令
不妨假設(shè)X的定義域?yàn)?img src="https://file1.elecfans.com//web2/M00/98/48/wKgZomTnWSqAeMyZAAAHrbNnLB4888.png" alt="66bf4d06-73d8-11ed-8abf-dac502259ad0.png" />。令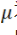 為x的分布。那么我們的目標(biāo)便是:最小化測(cè)試誤差
為x的分布。那么我們的目標(biāo)便是:最小化測(cè)試誤差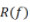 (testing error,也稱(chēng)為population risk或generalization error)
(testing error,也稱(chēng)為population risk或generalization error)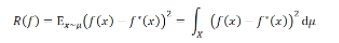
2.2?監(jiān)督學(xué)習(xí)的誤差
監(jiān)督學(xué)習(xí)一般有如下的步驟:
第一步:選取一個(gè)假設(shè)空間(測(cè)試函數(shù)的一個(gè)集合)(m正比于測(cè)試空間的維數(shù));
第二步:選取一個(gè)損失函數(shù)進(jìn)行優(yōu)化。通常,我們會(huì)選擇經(jīng)驗(yàn)誤差(empirical risk)來(lái)擬合數(shù)據(jù):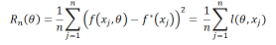
有時(shí),我們還會(huì)加上其他的懲罰項(xiàng)。
第三步:求解優(yōu)化問(wèn)題,如:
梯度下降:
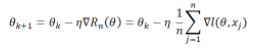
隨機(jī)梯度下降:
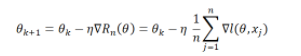
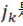 是從1,…n中隨機(jī)選取的。
是從1,…n中隨機(jī)選取的。
如果把機(jī)器學(xué)習(xí)輸出的結(jié)果記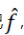 ,那么總誤差便是
,那么總誤差便是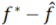 。我們?cè)俣x:
。我們?cè)俣x:
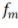 是在假設(shè)空間里最好的逼近;
是在假設(shè)空間里最好的逼近;
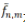 是在假設(shè)空間里,基于數(shù)據(jù)集S最好的逼近。
是在假設(shè)空間里,基于數(shù)據(jù)集S最好的逼近。
由此,我們便可以把誤差分解成三部分:
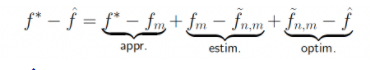
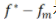 是逼近誤差(approximation error):完全由假設(shè)空間的選取所決定;
是逼近誤差(approximation error):完全由假設(shè)空間的選取所決定;
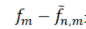 是估計(jì)誤差(estimation error):由于數(shù)據(jù)集大小有限而帶來(lái)的額外的誤差;
是估計(jì)誤差(estimation error):由于數(shù)據(jù)集大小有限而帶來(lái)的額外的誤差;
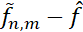 是優(yōu)化誤差(optimization error):由訓(xùn)練(優(yōu)化)帶來(lái)的額外的誤差。
是優(yōu)化誤差(optimization error):由訓(xùn)練(優(yōu)化)帶來(lái)的額外的誤差。
2.3?逼近誤差
我們下面集中討論逼近誤差(approximation error)。
我們先用傳統(tǒng)方法傅立葉變換做一個(gè)對(duì)比:
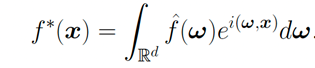
如果我們用離散的傅立葉變換來(lái)逼近:
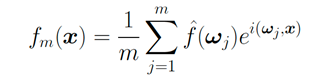
其誤差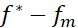 便是正比于
便是正比于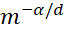 ,毫無(wú)疑問(wèn)地受到維度災(zāi)難的影響。而如果一個(gè)函數(shù)可以表示成期望的形式:
,毫無(wú)疑問(wèn)地受到維度災(zāi)難的影響。而如果一個(gè)函數(shù)可以表示成期望的形式:
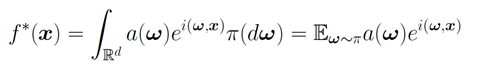
令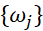 是測(cè)度
是測(cè)度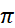 的獨(dú)立同分布樣本,我們有:
的獨(dú)立同分布樣本,我們有:
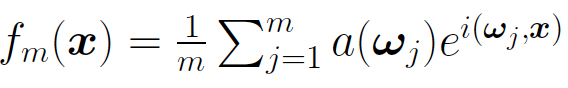
那么此時(shí)的誤差是:
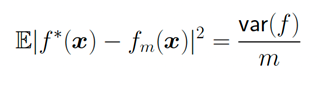
可以看到,這是與維數(shù)無(wú)關(guān)的!
如果讓激活函數(shù)為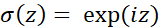 ,那么
,那么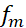 就是以
就是以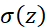 為激活函數(shù)的兩層神經(jīng)網(wǎng)絡(luò)。此結(jié)果意味著:這一類(lèi)(可以表示成期望)的函數(shù),都可以由兩層神經(jīng)網(wǎng)絡(luò)逼近,且逼近誤差的速率與維數(shù)無(wú)關(guān)!
為激活函數(shù)的兩層神經(jīng)網(wǎng)絡(luò)。此結(jié)果意味著:這一類(lèi)(可以表示成期望)的函數(shù),都可以由兩層神經(jīng)網(wǎng)絡(luò)逼近,且逼近誤差的速率與維數(shù)無(wú)關(guān)!
對(duì)于一般的雙層神經(jīng)網(wǎng)絡(luò),我們可以得到一系列類(lèi)似的逼近結(jié)果。其中關(guān)鍵的問(wèn)題是:到底什么樣的函數(shù)可以被雙層神經(jīng)網(wǎng)絡(luò)逼近?為此,我們引入Barron空間的定義:

Barron空間的定義參考:E, Chao Ma, Lei Wu (2019)
對(duì)于任意的Barron函數(shù),存在一個(gè)兩層神經(jīng)網(wǎng)絡(luò)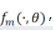 ,其逼近誤差滿(mǎn)足:
,其逼近誤差滿(mǎn)足:
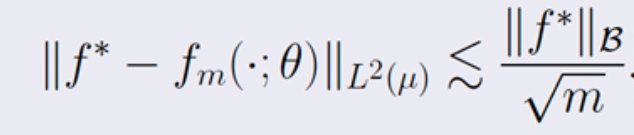
可以看到這一逼近誤差與維數(shù)無(wú)關(guān)!(關(guān)于這部分理論的細(xì)節(jié),可以參考:E, Ma and Wu (2018, 2019), E and Wojtowytsch (2020)。其他的關(guān)于Barron space的分類(lèi)理論,可以參考Kurkova (2001), Bach (2017),Siegel and Xu (2021))
類(lèi)似的理論可以推廣到殘差神經(jīng)網(wǎng)絡(luò)(residual neural network)。在殘差神經(jīng)網(wǎng)絡(luò)中,我們可以用流-誘導(dǎo)函數(shù)空間(flow-induced function space)替代Barron空間。
2.4 泛化性:訓(xùn)練誤差與測(cè)試誤差的差別
人們一般會(huì)期待,訓(xùn)練誤差與測(cè)試誤差的差別會(huì)正比于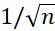 (n是樣本數(shù)量)。然而,我們訓(xùn)練好的機(jī)器學(xué)習(xí)模型和訓(xùn)練數(shù)據(jù)是強(qiáng)相關(guān)的,這導(dǎo)致這樣子的Monte-Carlo速率不一定成立。為此,我們給出了如下的泛化性理論:
(n是樣本數(shù)量)。然而,我們訓(xùn)練好的機(jī)器學(xué)習(xí)模型和訓(xùn)練數(shù)據(jù)是強(qiáng)相關(guān)的,這導(dǎo)致這樣子的Monte-Carlo速率不一定成立。為此,我們給出了如下的泛化性理論:

簡(jiǎn)言之,我們用Rademacher復(fù)雜度來(lái)刻畫(huà)一個(gè)空間在數(shù)據(jù)集上擬合隨機(jī)噪聲的能力。
Rademacher復(fù)雜度的定義為:
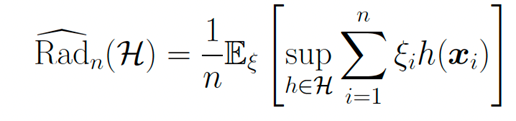
其中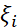 是取值為1或-1的獨(dú)立同分布的隨機(jī)變量。
是取值為1或-1的獨(dú)立同分布的隨機(jī)變量。
當(dāng)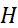 是李樸西斯空間中的單位球時(shí),其Rademacher復(fù)雜度正比于
是李樸西斯空間中的單位球時(shí),其Rademacher復(fù)雜度正比于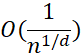 。 當(dāng)d增加時(shí),可以看到擬合需要的樣本大小指數(shù)上升。這其實(shí)是另一種形式的維度災(zāi)難。 2.5 訓(xùn)練過(guò)程的數(shù)學(xué)理解 ? 關(guān)于神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,有兩個(gè)基本的問(wèn)題:
。 當(dāng)d增加時(shí),可以看到擬合需要的樣本大小指數(shù)上升。這其實(shí)是另一種形式的維度災(zāi)難。 2.5 訓(xùn)練過(guò)程的數(shù)學(xué)理解 ? 關(guān)于神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,有兩個(gè)基本的問(wèn)題:
梯度下降方法到底能不能快速收斂?
訓(xùn)練得到的結(jié)果,是否有比較好的泛化性?
對(duì)于第一個(gè)問(wèn)題,答案恐怕是悲觀的。Shamir(2018)中的引理告訴我們,基于梯度的訓(xùn)練方法,其收斂速率也受維度災(zāi)難的影響。而前文提到的Barron space,雖然是建立逼近理論的好手段,但對(duì)于理解神經(jīng)網(wǎng)絡(luò)的訓(xùn)練卻是一個(gè)過(guò)大的空間。 特別地,這樣子的負(fù)面結(jié)果可以在高度超參數(shù)(highly over-parameterized regime)的情形(即m>>n)下得到具體刻畫(huà)。在此情形下,參數(shù)的動(dòng)力學(xué)出現(xiàn)了尺度分離的現(xiàn)象:對(duì)于如下的兩層神經(jīng)網(wǎng)絡(luò):
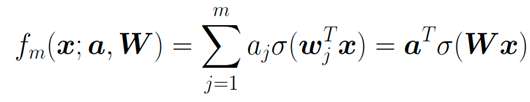
在訓(xùn)練過(guò)程中,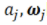 的動(dòng)力學(xué)分別為:
的動(dòng)力學(xué)分別為:
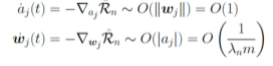
。 ? 由此可以看到尺度分離的現(xiàn)象:當(dāng)m很大的時(shí)候,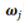 的動(dòng)力學(xué)幾乎被凍結(jié)住。 ? ? ? 這種情形下,好消息是我們有了指數(shù)收斂(Du et al, 2018);壞消息卻是這時(shí)候,神經(jīng)網(wǎng)絡(luò)表現(xiàn)得并不比從random feature model模型好。 我們也可以從平均場(chǎng)的角度理解梯度下降方法。令:,并令:則是下列梯度下降問(wèn)題的解:當(dāng)且僅當(dāng)是下面方程的解(參考:Chizat and Bach (2018), Mei, Montanari and Nguyen (2018), Rotsko? and Vanden-Eijnden (2018), Sirignano and Spiliopoulos (2018)):這一平均場(chǎng)動(dòng)力學(xué),實(shí)際上是在Wassenstein度量意義下的梯度動(dòng)力學(xué)。人們證明了:如果其初始值的支集為全空間,且梯度下降的確收斂,那么其收斂結(jié)果必然是全局最優(yōu)(參考:Chizat and Bach (2018,2020), Wojtowytsch (2020))。
的動(dòng)力學(xué)幾乎被凍結(jié)住。 ? ? ? 這種情形下,好消息是我們有了指數(shù)收斂(Du et al, 2018);壞消息卻是這時(shí)候,神經(jīng)網(wǎng)絡(luò)表現(xiàn)得并不比從random feature model模型好。 我們也可以從平均場(chǎng)的角度理解梯度下降方法。令:,并令:則是下列梯度下降問(wèn)題的解:當(dāng)且僅當(dāng)是下面方程的解(參考:Chizat and Bach (2018), Mei, Montanari and Nguyen (2018), Rotsko? and Vanden-Eijnden (2018), Sirignano and Spiliopoulos (2018)):這一平均場(chǎng)動(dòng)力學(xué),實(shí)際上是在Wassenstein度量意義下的梯度動(dòng)力學(xué)。人們證明了:如果其初始值的支集為全空間,且梯度下降的確收斂,那么其收斂結(jié)果必然是全局最優(yōu)(參考:Chizat and Bach (2018,2020), Wojtowytsch (2020))。
機(jī)器學(xué)習(xí)的應(yīng)用
3.1 解決高維科學(xué)計(jì)算問(wèn)題 ? 既然機(jī)器學(xué)習(xí)是處理高維問(wèn)題的有效工具,我們便可運(yùn)用機(jī)器學(xué)習(xí)解決傳統(tǒng)計(jì)算數(shù)學(xué)方法難以處理的問(wèn)題。 第一個(gè)例子便是隨機(jī)控制問(wèn)題。傳統(tǒng)方法求解隨機(jī)控制問(wèn)題需要求解一個(gè)極其高維的Bellman方程。運(yùn)用機(jī)器學(xué)習(xí)方法,可以有效求解隨機(jī)控制問(wèn)題。其思路與殘差神經(jīng)網(wǎng)絡(luò)頗為類(lèi)似(參考Jiequn Han and E (2016)): ?
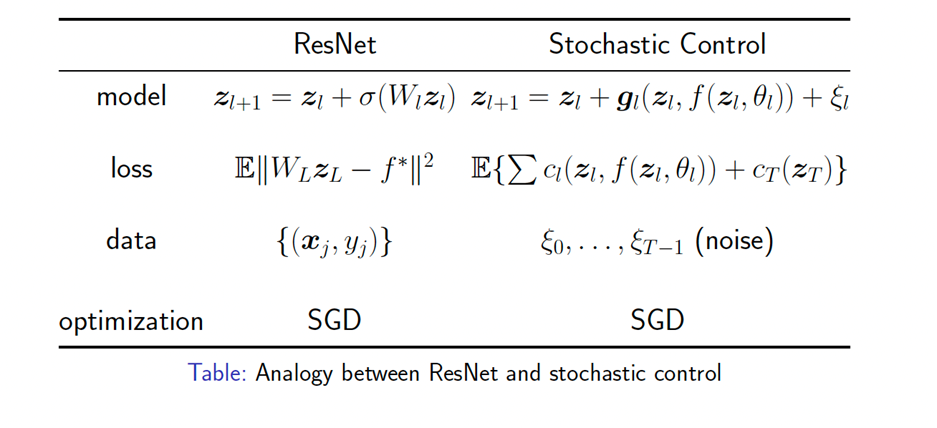
第二個(gè)例子便是求解非線性拋物方程。非線性拋物方程可以被改寫(xiě)成一個(gè)隨機(jī)控制問(wèn)題,其極小點(diǎn)是唯一的,對(duì)應(yīng)著非線性拋物方程的解。
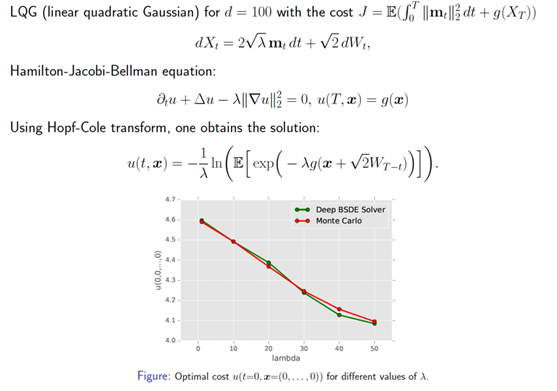
? 3.2 AI for science ? 利用機(jī)器學(xué)習(xí)處理高維問(wèn)題的能力,我們可以解決更多科學(xué)上的難題。這里我們舉兩個(gè)例子。第一個(gè)例子是Alphafold。
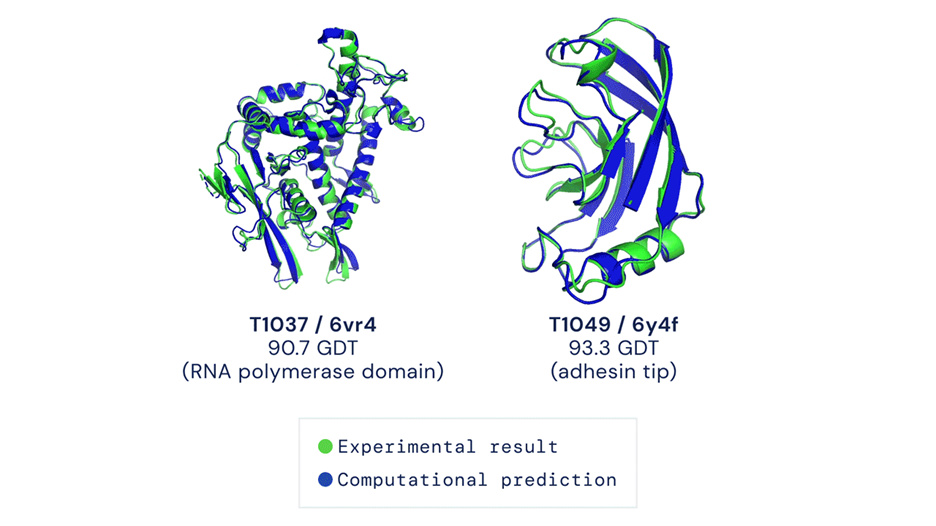
參考:J. Jumper et al. (2021) ? 第二個(gè)例子,便是我們自己的工作:深度勢(shì)能分子動(dòng)力學(xué)(DeePMD)。這是能達(dá)到從頭計(jì)算精度的分子動(dòng)力學(xué)。我們所使用的新的模擬“范式”便是:
利用量子力學(xué)第一性原理計(jì)算提供數(shù)據(jù);
利用神經(jīng)網(wǎng)絡(luò),給出勢(shì)能面準(zhǔn)確的擬合(參考:Behler and Parrinello (2007), Jiequn Han et al (2017), Linfeng Zhang et al (2018))。
運(yùn)用DeePMD,我們能夠模擬一系列材料和分子,可以達(dá)到第一性層面的計(jì)算精度: ?
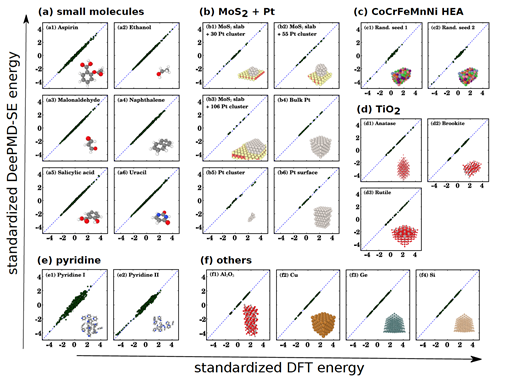
我們還實(shí)現(xiàn)了一億原子的第一性原理精度的模擬,獲得了2020年的戈登貝爾獎(jiǎng): ?
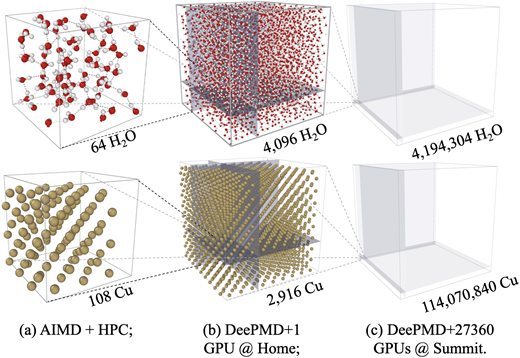
參考:Weile Jia, et al, SC20, 2020 ACM Gordon Bell Prize
我們給出了水的相圖:
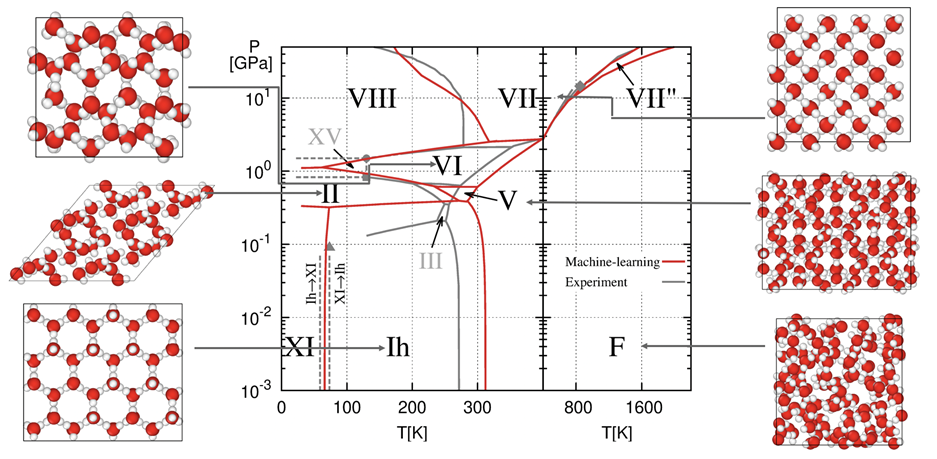
參考:Linfeng Zhang, Han Wang, et al. (2021)
而事實(shí)上,物理建模橫跨多個(gè)尺度:宏觀、介觀、微觀,而機(jī)器學(xué)習(xí)恰好提供了跨尺度建模的工具。
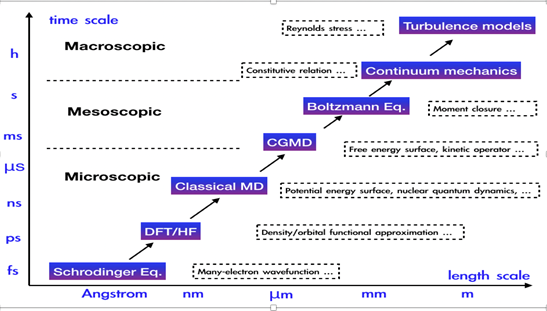
AI for science,即用機(jī)器學(xué)習(xí)解決科學(xué)問(wèn)題,已經(jīng)有了一系列重要的突破,如:
量子多體問(wèn)題:RBM (2017), DeePWF (2018), FermiNet (2019),PauliNet (2019),…;
密度泛函理論: DeePKS (2020), NeuralXC (2020), DM21 (2021), …;
分子動(dòng)力學(xué): DeePMD (2018), DeePCG (2019), …;
動(dòng)理學(xué)方程: 機(jī)器學(xué)習(xí)矩封閉 (Han et al. 2019);
連續(xù)介質(zhì)動(dòng)力學(xué):?? (2020)
(2020)
在未來(lái)五到十年,我們有可能做到:跨越所有物理尺度進(jìn)行建模和計(jì)算。這將徹底改變我們?nèi)绾谓鉀Q現(xiàn)實(shí)問(wèn)題:如藥物設(shè)計(jì)、材料、燃燒發(fā)動(dòng)機(jī)、催化……

總結(jié)
機(jī)器學(xué)習(xí)根本上是高維中的數(shù)學(xué)問(wèn)題。神經(jīng)網(wǎng)絡(luò)是高維函數(shù)逼近的有效手段;這便為人工智能領(lǐng)域、科學(xué)以及技術(shù)領(lǐng)域提供了眾多新的可能性。
這也開(kāi)創(chuàng)了數(shù)學(xué)領(lǐng)域的一個(gè)新主題:高維的分析學(xué)。簡(jiǎn)而言之,可以總結(jié)如下:
監(jiān)督學(xué)習(xí):高維函數(shù)理論;
無(wú)監(jiān)督學(xué)習(xí):高維概率分布理論;
強(qiáng)化學(xué)習(xí):高維Bellman方程;
時(shí)間序列學(xué)習(xí):高維動(dòng)力系統(tǒng)。

編輯:黃飛
?












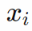








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論