 電子發燒友App
電子發燒友App


機器學習人人都在談論,但除了老師們知根知底外,只有很少的人能說清楚怎么回事。如果閱讀網上關于機器學習的文章,你很可能會遇到兩種情況:充斥各種定理的厚重學術三部曲(我搞定半個定理都夠嗆),或是關于人工智能、數據科學魔法以及未來工作的天花亂墜的故事。

我決定寫一篇醞釀已久的文章,對那些想了解機器學習的人做一個簡單的介紹。不涉及高級原理,只用簡單的語言來談現實世界的問題和實際的解決方案。不管你是一名程序員還是管理者,都能看懂。那我們開始吧!
為什么我們想要機器去學習?
現在出場的是Billy,Billy想買輛車,他想算出每月要存多少錢才付得起。瀏覽了網上的幾十個廣告之后,他了解到新車價格在2萬美元左右,用過1年的二手車價格是1.9萬美元,2年車就是1.8萬美元,依此類推。 作為聰明的分析師,Billy發現一種規律:車的價格取決于車齡,每增加1年價格下降1000美元,但不會低于10000美元。 用機器學習的術語來說,Billy發明了“回歸”(regression)——基于已知的歷史數據預測了一個數值(價格)。當人們試圖估算eBay上一部二手iPhone的合理價格或是計算一場燒烤聚會需要準備多少肋排時,他們一直在用類似Billy的方法——每人200g? 500? 是的,如果能有一個簡單的公式來解決世界上所有的問題就好了——尤其是對于燒烤派對來說——不幸的是,這是不可能的。 讓我們回到買車的情形,現在的問題是,除了車齡外,它們還有不同的生產日期、數十種配件、技術條件、季節性需求波動……天知道還有哪些隱藏因素……普通人Billy沒法在計算價格的時候把這些數據都考慮進去,換我也同樣搞不定。 人們又懶又笨——我們需要機器人來幫他們做數學。因此,這里我們采用計算機的方法——給機器提供一些數據,讓它找出所有和價格有關的潛在規律。 終~于~見效啦。最令人興奮的是,相比于真人在頭腦中仔細分析所有的依賴因素,機器處理起來要好得多。 就這樣,機器學習誕生了。
機器學習的3個組成部分
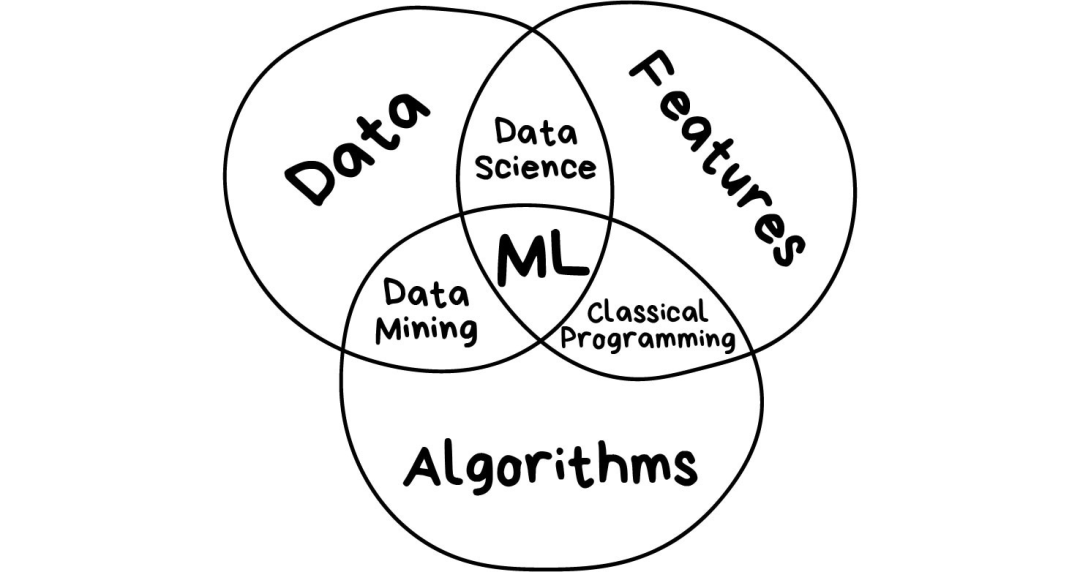
拋開所有和人工智能(AI)有關的扯淡成分,機器學習唯一的目標是基于輸入的數據來預測結果,就這樣。所有的機器學習任務都可以用這種方式來表示,否則從一開始它就不是個機器學習問題。 樣本越是多樣化,越容易找到相關聯的模式以及預測出結果。因此,我們需要3個部分來訓練機器:
(1)數據
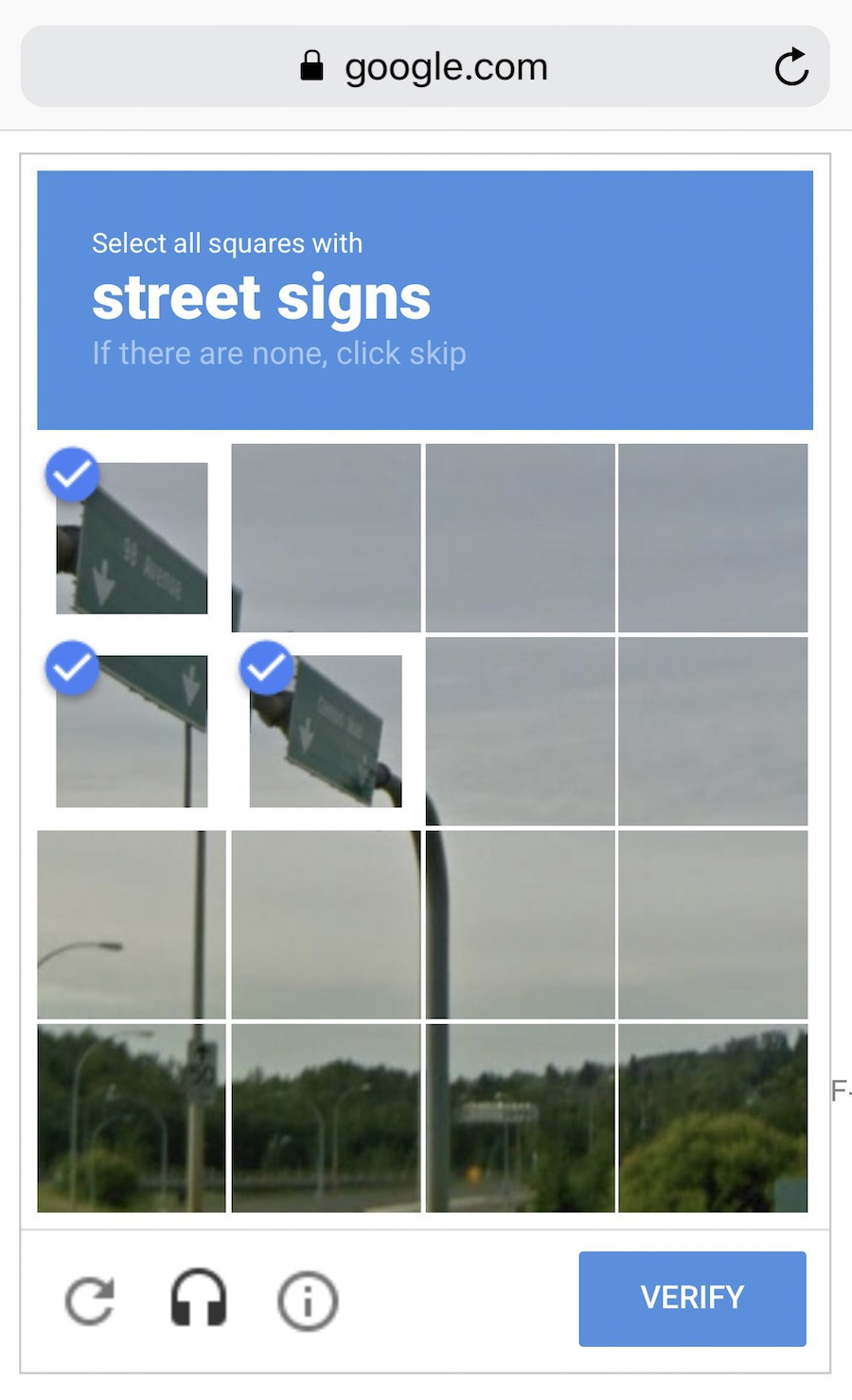
想檢測垃圾郵件?獲取垃圾信息的樣本。想預測股票?找到歷史價格信息。想找出用戶偏好?分析他們在Facebook上的活動記錄(不,Mark,停止收集數據~已經夠了)。數據越多樣化,結果越好。對于拼命運轉的機器而言,至少也得幾十萬行數據才夠吧。 獲取數據有兩種主要途徑——手動或者自動。手動采集的數據混雜的錯誤少,但要耗費更多的時間——通常花費也更多。自動化的方法相對便宜,你可以搜集一切能找到的數據(但愿數據質量夠好)。 一些像Google這樣聰明的家伙利用自己的用戶來為他們免費標注數據,還記得ReCaptcha(人機驗證)強制你去“選擇所有的路標”么?他們就是這樣獲取數據的,還是免費勞動!干得漂亮。如果我是他們,我會更頻繁地展示這些驗證圖片,不過,等等……
好的數據集真的很難獲取,它們是如此重要,以至于有的公司甚至可能開放自己的算法,但很少公布數據集。
(2)特征
也可以稱為“參數”或者“變量”,比如汽車行駛公里數、用戶性別、股票價格、文檔中的詞頻等。換句話說,這些都是機器需要考慮的因素。如果數據是以表格的形式存儲,特征就對應著列名,這種情形比較簡單。但如果是100GB的貓的圖片呢?我們不能把每個像素都當做特征。這就是為什么選擇適當的特征通常比機器學習的其他步驟花更多時間的原因,特征選擇也是誤差的主要來源。人性中的主觀傾向,會讓人去選擇自己喜歡或者感覺“更重要”的特征——這是需要避免的。
(3)算法
最顯而易見的部分。任何問題都可以用不同的方式解決。你選擇的方法會影響到最終模型的準確性、性能以及大小。需要注意一點:如果數據質量差,即使采用最好的算法也無濟于事。這被稱為“垃圾進,垃圾出”(garbae in - garbage out,GIGO)。所以,在把大量心思花到正確率之前,應該獲取更多的數據。
學習 V.S. 智能
我曾經在一些流行媒體網站上看到一篇題為“神經網絡是否會取代機器學習?”的文章。這些媒體人總是莫名其妙地把線性回歸這樣的技術夸大為“人工智能”,就差稱之為“天網”了。下圖展示了幾個容易混淆的概念之間的關系。
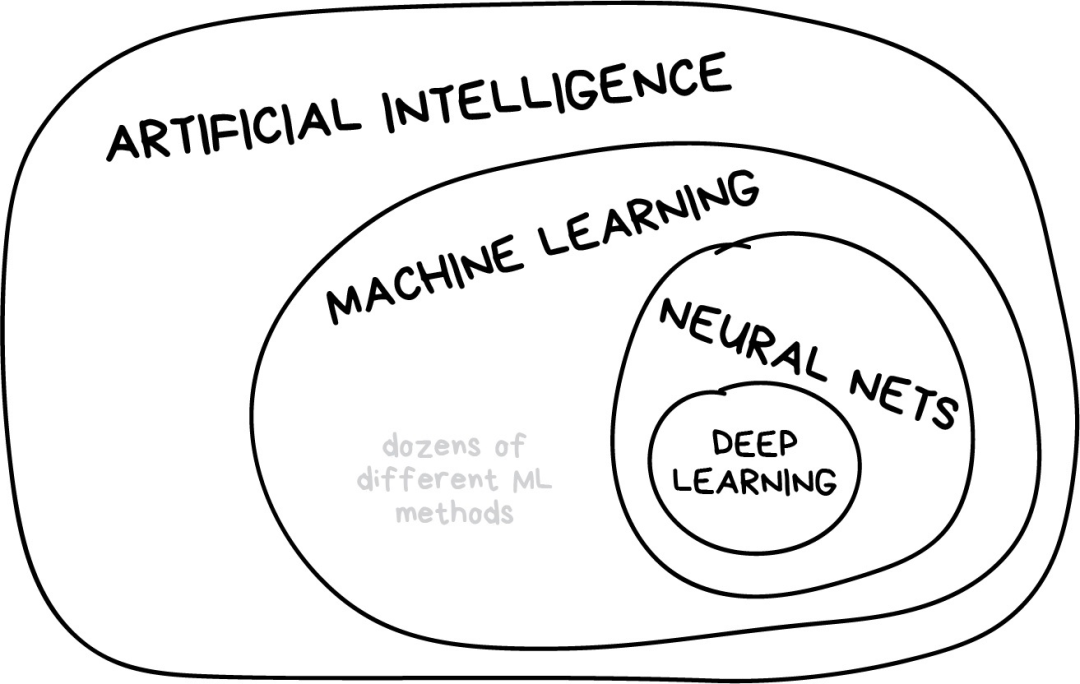
“人工智能”是整個學科的名稱,類似于“生物學”或“化學”。
“機器學習”是“人工智能”的重要組成部分,但不是唯一的部分。
“神經網絡”是機器學習的一種分支方法,這種方法很受歡迎,不過機器學習大家庭下還有其他分支。
“深度學習”是關于構建、訓練和使用神經網絡的一種現代方法。本質上來講,它是一種新的架構。在當前實踐中,沒人會將深度學習和“普通網絡”區分開來,使用它們時需要調用的庫也相同。為了不讓自己看起來像個傻瓜,你最好直接說具體網絡類型,避免使用流行語。
一般原則是在同一水平上比較事物。這就是為什么“神經網絡將取代機器學習”聽起來就像“車輪將取代汽車”。親愛的媒體們,這會折損一大截你們的聲譽哦。

機器學習世界的版圖
如果你懶得閱讀大段文字,下面這張圖有助于獲得一些認識。
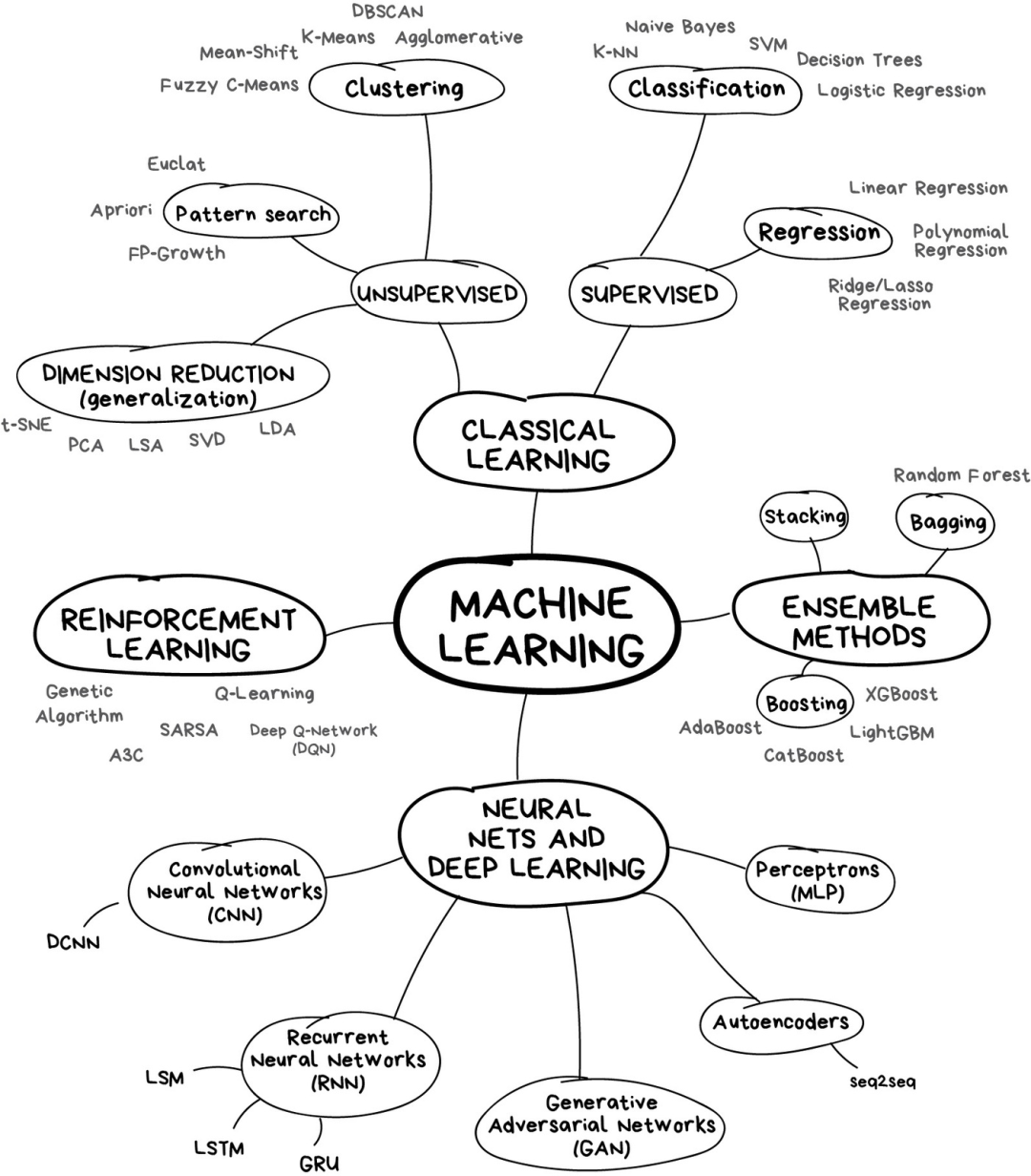
在機器學習的世界里,解決問題的方法從來不是唯一的——記住這點很重要——因為你總會發現好幾個算法都可以用來解決某個問題,你需要從中選擇最適合的那個。當然,所有的問題都可以用“神經網絡”來處理,但是背后承載算力的硬件成本誰來負擔呢? 我們先從一些基礎的概述開始。目前機器學習主要有4個方向。
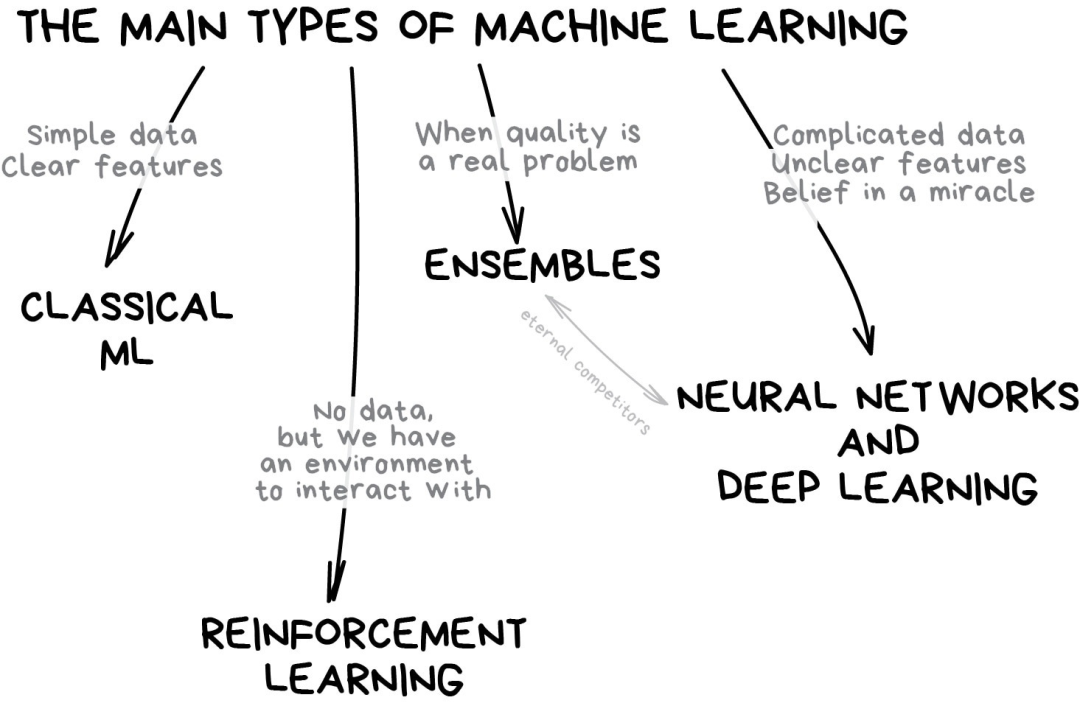
Part 1:經典機器學習算法
經典機器學習算法源自1950年代的純統計學。統計學家們解決的是諸如尋找數字中的模式、估計數據點間的距離以及計算向量方向這樣的形式數學(formal math)問題。 今天,一半的互聯網都在研究這些算法。當你看到一列“繼續閱讀”的文章,或者在某個偏僻的加油站發現自己的銀行卡被鎖定而無法使用時,很可能是其中的一個小家伙干的。 大型科技公司是神經網絡的忠實擁躉。原因顯而易見,對于這些大型企業而言,2%的準確率提升意味著增加20億的收入。但是公司業務體量小時,就沒那么重要了。我聽說有團隊花了1年時間來為他們的電商網站開發新的推薦算法,事后才發現網站上99%的流量都來自搜索引擎——他們搞出來的算法毫無用處,畢竟大部分用戶甚至都不會打開主頁。 盡管經典算法被廣泛使用,其實原理很簡單,你可以很容易地解釋給一個蹣跚學步的孩子聽。它們就像是基本的算術——我們每天都在用,甚至連想都不想。
1.1 有監督學習
經典機器學習通常分為兩類:有監督學習(Supervised Learning)和無監督學習(Unsupervised Learning)。 在“有監督學習”中,有一個“監督者”或者“老師”提供給機器所有的答案來輔助學習,比如圖片中是貓還是狗。“老師”已經完成數據集的劃分——標注“貓”或“狗”,機器就使用這些示例數據來學習,逐個學習區分貓或狗。 無監督學習就意味著機器在一堆動物圖片中獨自完成區分誰是誰的任務。數據沒有事先標注,也沒有“老師”,機器要自行找出所有可能的模式。后文再討論這些。 很明顯,有“老師”在場時,機器學的更快,因此現實生活中有監督學習更常用到。 有監督學習分為兩類:
分類(classification),預測一個對象所屬的類別;
回歸(regression),預測數軸上的一個特定點;
分類(Classification) “基于事先知道的一種屬性來對物體劃分類別,比如根據顏色來對襪子歸類,根據語言對文檔分類,根據風格來劃分音樂。”
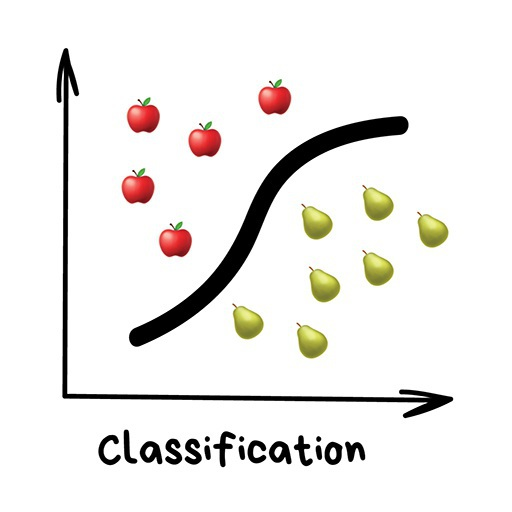
分類算法常用于:
過濾垃圾郵件;
語言檢測;
查找相似文檔;
情感分析
識別手寫字母或數字
欺詐偵測
常用的算法:
樸素貝葉斯(Naive Bayes)
決策樹(Decision Tree)
Logistic回歸(Logistic Regression)
K近鄰(K-Nearest Neighbours)
支持向量機(Support Vector Machine)
機器學習主要解決“分類”問題。這臺機器好比在學習對玩具分類的嬰兒一樣:這是“機器人”,這是“汽車”,這是“機器-車”……額,等下,錯誤!錯誤! 在分類任務中,你需要一名“老師”。數據需要事先標注好,這樣機器才能基于這些標簽來學會歸類。一切皆可分類——基于興趣對用戶分類,基于語言和主題對文章分類(這對搜索引擎很重要),基于類型對音樂分類(Spotify播放列表),你的郵件也不例外。 樸素貝葉斯算法廣泛應用于垃圾郵件過濾。機器分別統計垃圾郵件和正常郵件中出現的“偉哥”等字樣出現的頻次,然后套用貝葉斯方程乘以各自的概率,再對結果求和——哈,機器就完成學習了。
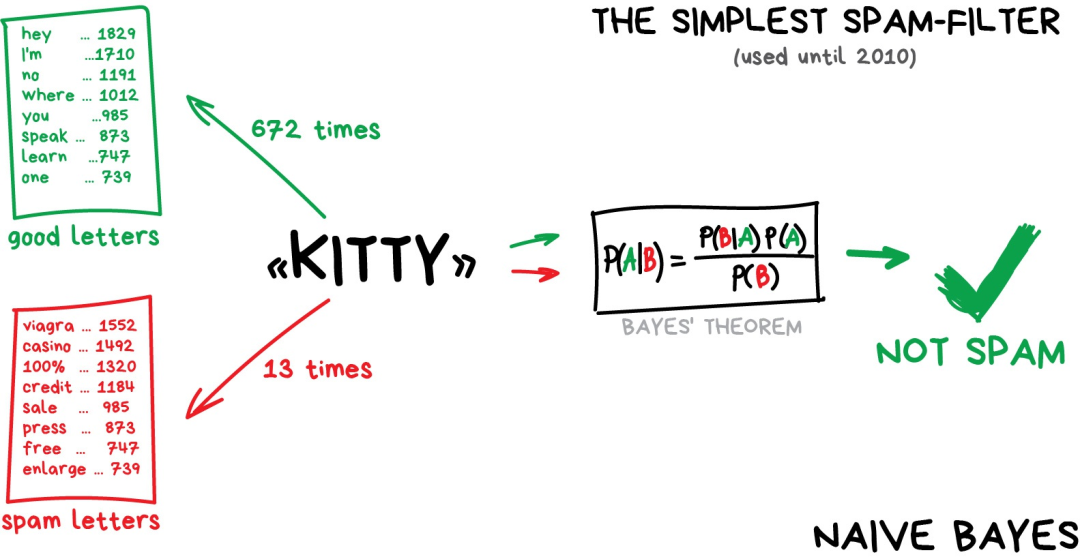
后來,垃圾郵件制造者學會了如何應對貝葉斯過濾器——在郵件內容后面添加很多“好”詞——這種方法被諷稱為“貝葉斯中毒”(Bayesian poisoning)。樸素貝葉斯作為最優雅且是第一個實用的算法而載入歷史,不過現在有其他算法來處理垃圾郵件過濾問題。 再舉一個分類算法的例子。 假如現在你需要借一筆錢,那銀行怎么知道你將來是否會還錢呢?沒法確定。但是銀行有很多歷史借款人的檔案,他們擁有諸如“年齡”、“受教育程度”、“職業”、“薪水”以及——最重要的——“是否還錢”這些數據。 利用這些數據,我們可以訓練機器找到其中的模式并得出答案。找出答案并不成問題,問題在于銀行不能盲目相信機器給出的答案。如果系統出現故障、遭遇黑客攻擊或者喝高了的畢業生剛給系統打了個應急補丁,該怎么辦? 要處理這個問題,我們需要用到決策樹(Decision Trees),所有數據自動劃分為“是/否”式提問——比如“借款人收入是否超過128.12美元?”——聽起來有點反人類。不過,機器生成這樣的問題是為了在每個步驟中對數據進行最優劃分。
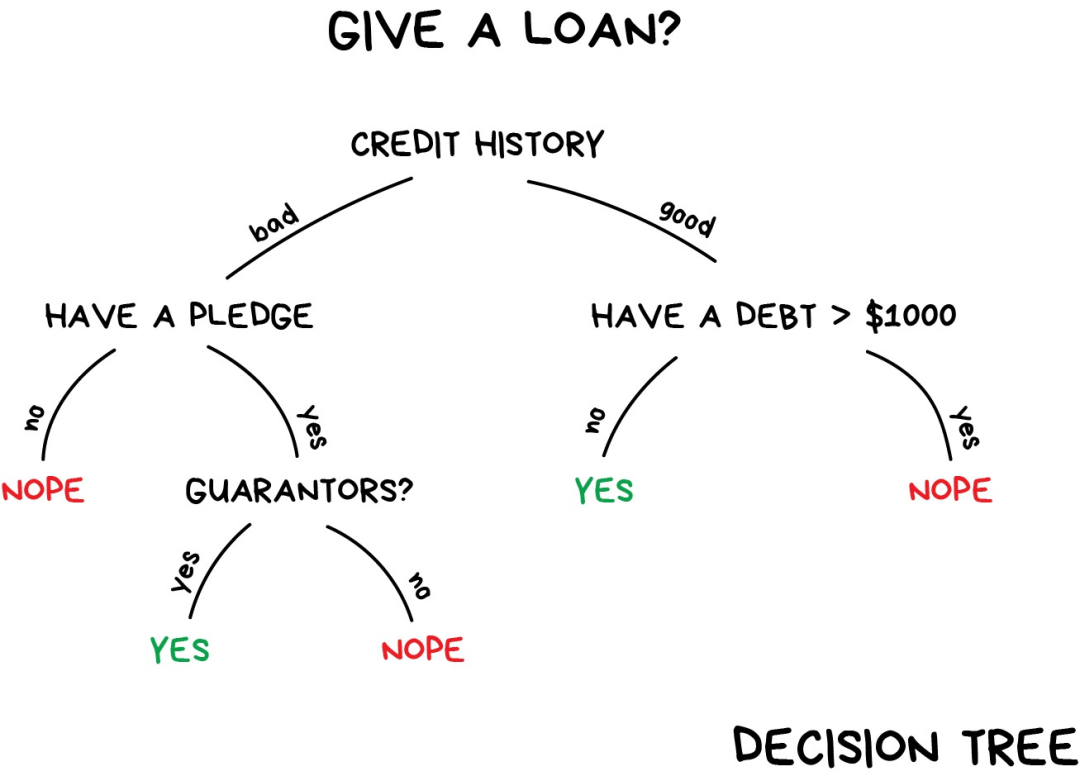
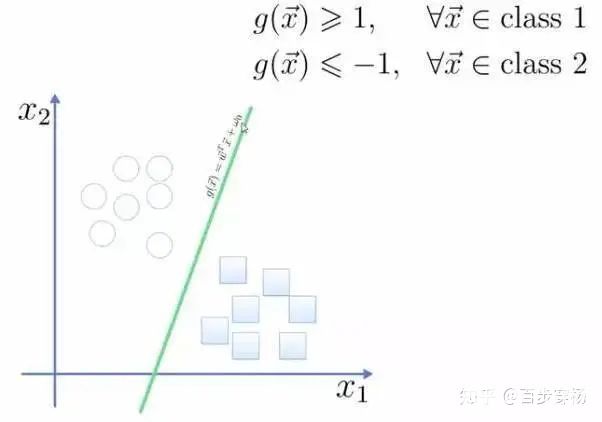
“樹”就是這樣產生的。分支越高(接近根節點),問題的范圍就越廣。所有分析師都能接受這種做法并在事后給出解釋,即使他并不清楚算法是怎么回事,照樣可以很容易地解釋結果(典型的分析師啊)! 決策樹廣泛應用于高責任場景:診斷、醫藥以及金融領域。 最廣為人知的兩種決策樹算法是 CART 和 C4.5. 如今,很少用到純粹的決策樹算法。不過,它們是大型系統的基石,決策樹集成之后的效果甚至比神經網絡還要好。這個我們后面再說。 當你在Google上搜索時,正是一堆笨拙的“樹”在幫你尋找答案。搜索引擎喜歡這類算法,因為它們運行速度夠快。 按理說,支持向量機(SVM)?應該是最流行的分類方法。只要是存在的事物都可以用它來分類:對圖片中的植物按形狀歸類,對文檔按類別歸類等。 SVM背后的思想很簡單——它試圖在數據點之間繪制兩條線,并盡可能最大化兩條線之間的距離。 如下圖示:
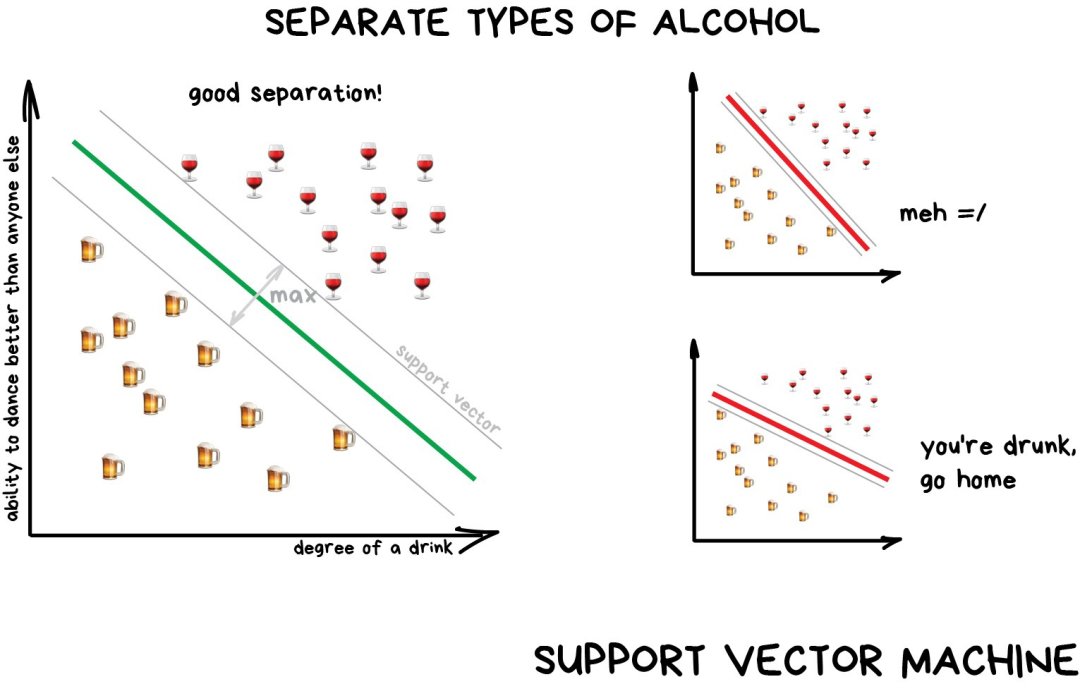
分類算法有一個非常有用的場景——異常檢測(anomaly detection),如果某個特征無法分配到所有類別上,我們就把它標出來。現在這種方法已經用于醫學領域——MRI(磁共振成像)中,計算機會標記檢測范圍內所有的可疑區域或者偏差。股票市場使用它來檢測交易人的異常行為以此來找到內鬼。在訓練計算機分辨哪些事物是正確時,我們也自動教會其識別哪些事物是錯誤的。 經驗法則(rule of thumb)表明,數據越復雜,算法就越復雜。對于文本、數字、表格這樣的數據,我會選擇經典方法來操作。這些模型較小,學習速度更快,工作流程也更清晰。對于圖片、視頻以及其他復雜的大數據,我肯定會研究神經網絡。 就在5年前,你還可以找到基于SVM的人臉分類器。現在,從數百個預訓練好的神經網絡模型中挑選一個模型反而更容易。不過,垃圾郵件過濾器沒什么變化,它們還是用SVM編寫的,沒什么理由去改變它。甚至我的網站也是用基于SVM來過濾評論中的垃圾信息的。
回歸(Regression)
“畫一條線穿過這些點,嗯~這就是機器學習”
回歸算法目前用于:
股票價格預測
供應和銷售量分析
醫學診斷
計算時間序列相關性
常見的回歸算法有:
線性回歸(Linear Regression)
多項式回歸(Polynomial?Regression)
“回歸”算法本質上也是“分類”算法,只不過預測的是不是類別而是一個數值。比如根據行駛里程來預測車的價格,估算一天中不同時間的交通量,以及預測隨著公司發展供應量的變化幅度等。處理和時間相關的任務時,回歸算法可謂不二之選。 回歸算法備受金融或者分析行業從業人員青睞。它甚至成了Excel的內置功能,整個過程十分順暢——機器只是簡單地嘗試畫出一條代表平均相關的線。不過,不同于一個拿著筆和白板的人,機器是通過計算每個點與線的平均間隔這樣的數學精確度來完成的這件事。
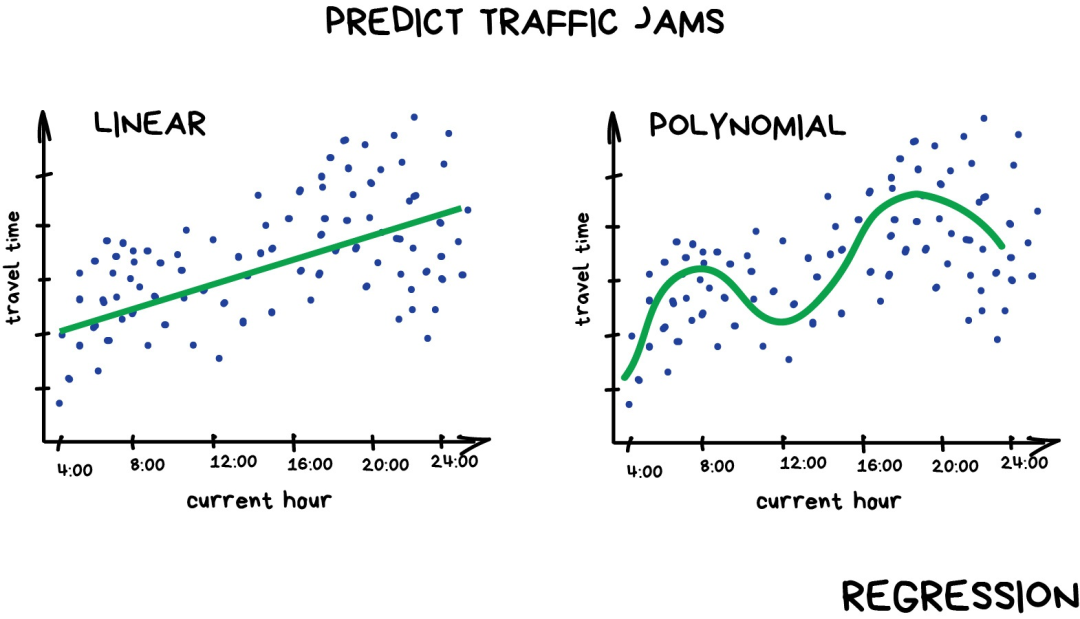
如果畫出來的是直線,那就是“線性回歸”,如果線是彎曲的,則是“多項式回歸”。它們是回歸的兩種主要類型。其他類型就比較少見了。不要被Logistics回歸這個“害群之馬”忽悠了,它是分類算法,不是回歸。 不過,把“回歸”和“分類”搞混也沒關系。一些分類器調整參數后就變成回歸了。除了定義對象的類別外,還要記住對象有多么的接近該類別,這就引出了回歸問題。 如果你想深入研究,可以閱讀文章《寫給人類的機器學習》[1](強烈推薦)。
1.2 無監督學習
無監督學習比有監督學習出現得稍晚——在上世紀90年代,這類算法用的相對較少,有時候僅僅是因為沒得選才找上它們。 有標注的數據是很奢侈的。假設現在我要創建一個——比如說“公共汽車分類器”,那我是不是要親自去街上拍上幾百萬張該死的公共汽車的照片,然后還得把這些圖片一一標注出來?沒門,這會花費我畢生時間,我在Steam上還有很多游戲沒玩呢。 這種情況下還是要對資本主義抱一點希望,得益于社會眾包機制,我們可以得到數百萬便宜的勞動力和服務。比如Mechanical Turk[2],背后是一群隨時準備為了獲得0.05美元報酬來幫你完成任務的人。事情通常就是這么搞定的。 或者,你可以嘗試使用無監督學習。但是印象中,我不記得有什么關于它的最佳實踐。無監督學習通常用于探索性數據分析(exploratory data analysis),而不是作為主要的算法。那些擁有牛津大學學位且經過特殊訓練的人給機器投喂了一大堆垃圾然后開始觀察:有沒有聚類呢?沒有。可以看到一些聯系嗎?沒有。好吧,接下來,你還是想從事數據科學工作的,對吧?
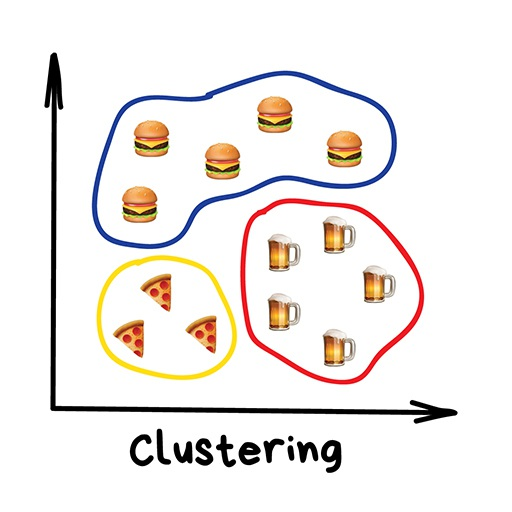
聚類(Clustering)
“機器會選擇最好的方式,基于一些未知的特征將事物區分開來。”
聚類算法目前用于:
市場細分(顧客類型,忠誠度)
合并地圖上鄰近的點
圖像壓縮
分析和標注新的數據
檢測異常行為
常見算法:
K均值聚類
Mean-Shift
DBSCAN
聚類是在沒有事先標注類別的前提下來進行類別劃分。好比你記不住所有襪子的顏色時照樣可以對襪子進行分類。聚類算法試圖找出相似的事物(基于某些特征),然后將它們聚集成簇。那些具有很多相似特征的對象聚在一起并劃分到同一個類別。有的算法甚至支持設定每個簇中數據點的確切數量。 這里有個示范聚類的好例子——在線地圖上的標記。當你尋找周圍的素食餐廳時,聚類引擎將它們分組后用帶數字的氣泡展示出來。不這么做的話,瀏覽器會卡住——因為它試圖將這個時尚都市里所有的300家素食餐廳繪制到地圖上。 Apple Photos和Google Photos用的是更復雜的聚類方式。通過搜索照片中的人臉來創建你朋友們的相冊。應用程序并不知道你有多少朋友以及他們的長相,但是仍可以從中找到共有的面部特征。這是很典型的聚類。 另一個常見的應用場景是圖片壓縮。當圖片保存為PNG格式時,可以將色彩設置為32色。這就意味著聚類算法要找出所有的“紅色”像素,然后計算出“平均紅色”,再將這個均值賦給所有的紅色像素點上。顏色更少,文件更小——劃算! 但是,遇到諸如藍綠這樣的顏色時就麻煩了。這是綠色還是藍色?此時就需要K-Means算法出場啦。 先隨機從色彩中選出32個色點作為“簇心”,剩余的點按照最近的簇心進行標記。這樣我們就得到了圍繞著32個色點的“星團”。接著我們把簇心移動到“星團”的中心,然后重復上述步驟知道簇心不再移動為止。 完工。剛好聚成32個穩定的簇形。 給大家看一個現實生活中的例子:
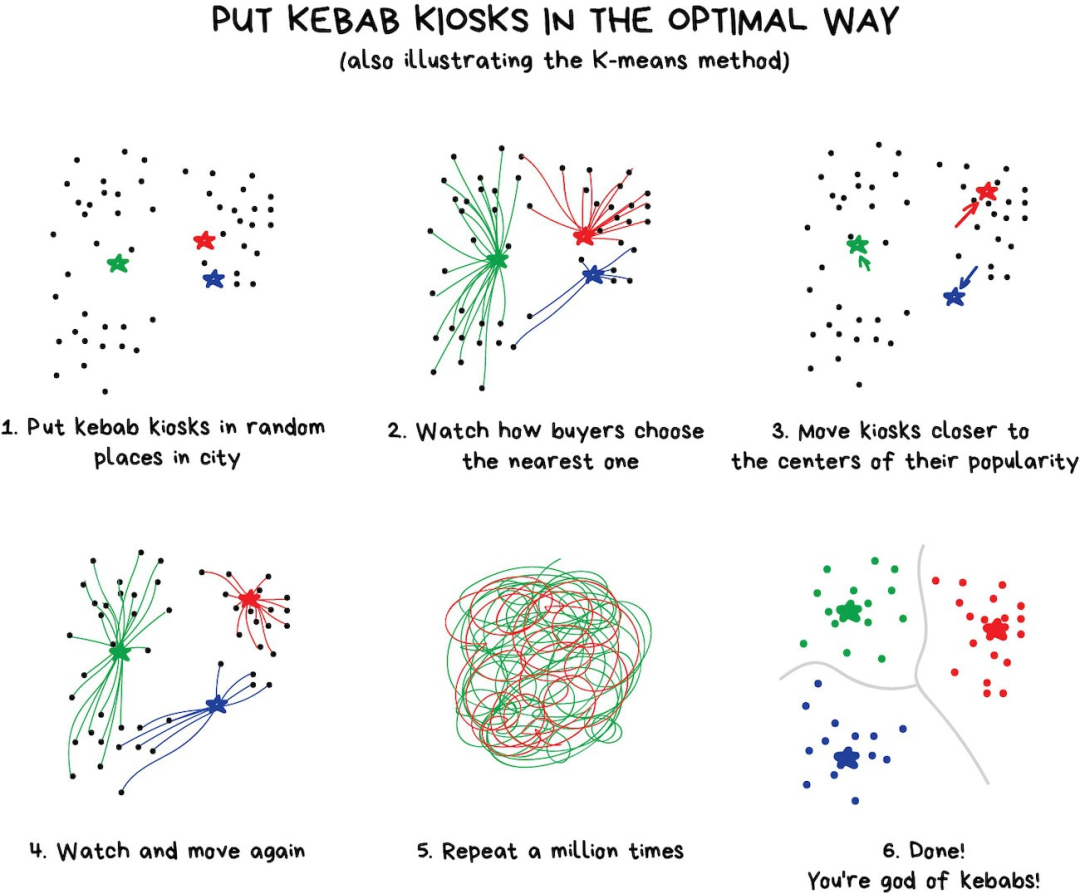
尋找簇心這種方法很方便,不過,現實中的簇并不總是圓形的。假如你是一名地質學家,現在需要在地圖上找出一些類似的礦石。這種情形下,簇的形狀會很奇怪,甚至是嵌套的。甚至你都不知道會有多少個簇,10個?100個? K-means算法在這里就派不上用場了,但是DBSCAN算法用得上。我們把數據點比作廣場上的人,找到任何相互靠近的3個人請他們手拉手。接下來告訴他們抓住能夠到的鄰居的手(整個過程人的站立位置不能動),重復這個步驟,直到新的鄰居加入進來。這樣我們就得到了第一個簇,重復上述過程直到每個人都被分配到簇,搞定。 一個意外收獲:一個沒有人牽手的人——異常數據點。 整個過程看起來很酷。

有興趣繼續了解下聚類算法?可以閱讀這篇文章《數學科學家需要知道的5種聚類算法》[3]. 就像分類算法一樣,聚類可以用來檢測異常。用戶登陸之后的有不正常的操作?讓機器暫時禁用他的賬戶,然后創建一個工單讓技術支持人員檢查下是什么情況。說不定對方是個“機器人”。我們甚至不必知道“正常的行為”是什么樣,只需把用戶的行為數據傳給模型,讓機器來決定對方是否是個“典型的”用戶。這種方法雖然效果不如分類算法那樣好,但仍值得一試。
降維(Dimensionality Reduction)
“將特定的特征組裝成更高級的特征 ”
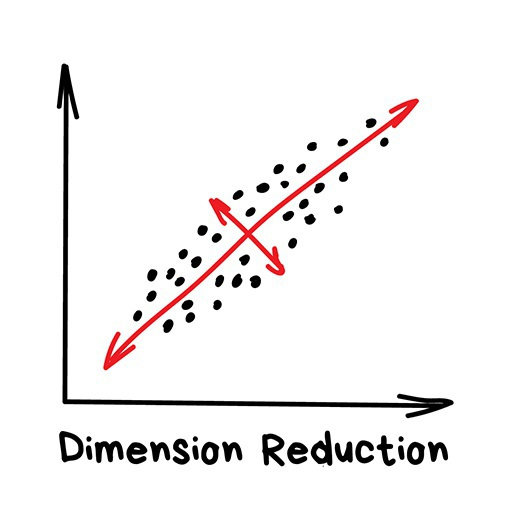
“降維”算法目前用于:
推薦系統
漂亮的可視化
主題建模和查找相似文檔
假圖識別
風險管理
常用的“降維”算法:
主成分分析(Principal Component Analysis?,PCA)
奇異值分解(Singular Value Decomposition?,SVD)
潛在狄里克雷特分配(?Latent Dirichlet allocation, LDA)
潛在語義分析(?Latent Semantic Analysis?,LSA, pLSA, GLSA),
t-SNE?(用于可視化)
早年間,“硬核”的數據科學家會使用這些方法,他們決心在一大堆數字中發現“有趣的東西”。Excel圖表不起作用時,他們迫使機器來做模式查找的工作。于是他們發明了降維或者特征學習的方法。
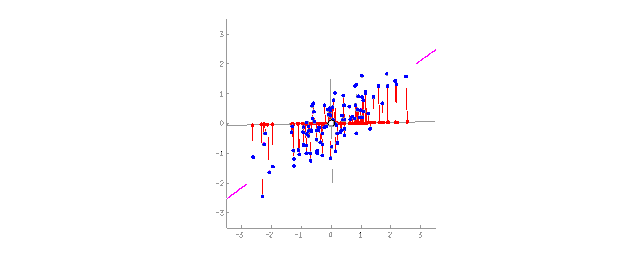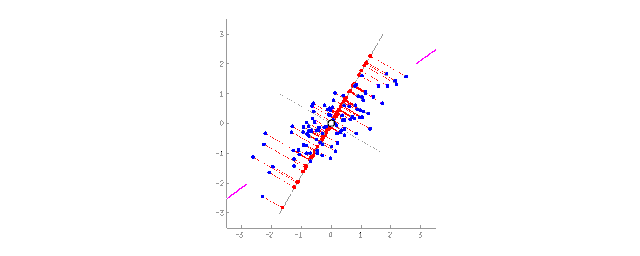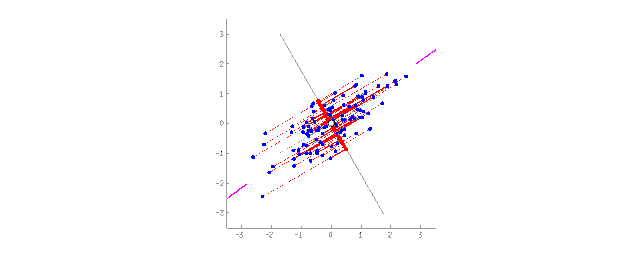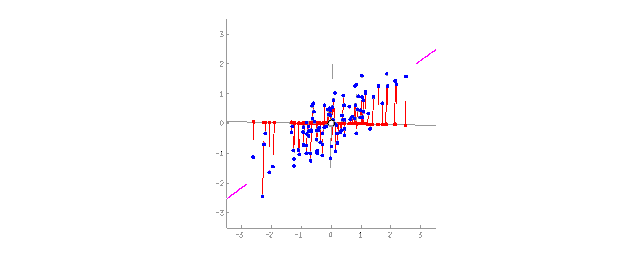
將2D數據投影到直線上(PCA) 對人們來說,相對于一大堆碎片化的特征,抽象化的概念更加方便。舉個例子,我們把擁有三角形的耳朵、長長的鼻子以及大尾巴的狗組合出“牧羊犬”這個抽象的概念。相比于特定的牧羊犬,我們的確丟失了一些信息,但是新的抽象概念對于需要命名和解釋的場景時更加有用。作為獎勵,這類“抽象的”模型學習速度更快,訓練時用到的特征數量也更少,同時還減少了過擬合。
這些算法在“主題建模”的任務中能大顯身手。我們可以從特定的詞組中抽象出他們的含義。潛在語義分析(LSA)就是搞這個事情的,LSA基于在某個主題上你能看到的特定單詞的頻次。比如說,科技文章中出現的科技相關的詞匯肯定更多些,或者政治家的名字大多是在政治相關的新聞上出現,諸如此類。
我們可以直接從所有文章的全部單詞中來創建聚類,但是這么做就會丟失所有重要的連接(比如,在不同的文章中battery 和 accumulator的含義是一樣的),LSA可以很好地處理這個問題,所以才會被叫做“潛在語義”(latent semantic)。
因此,需要把單詞和文檔連接組合成一個特征,從而保持其中的潛在聯系——人們發現奇異值分解(SVD)能解決這個問題。那些有用的主題簇很容易從聚在一起的詞組中看出來。

推薦系統和協同過濾是另一個高頻使用降維算法的領域。如果你用它從用戶的評分中提煉信息,你就會得到一個很棒的系統來推薦電影、音樂、游戲或者你想要的任何東西。
這里推薦一本我最愛的書《集體編程智慧》(Programming Collective Intelligence),它曾是我大學時代的枕邊書。
要完全理解這種機器上的抽象幾乎不可能,但可以留心觀察一些相關性:有些抽象概念和用戶年齡相關——小孩子玩“我的世界”或者觀看卡通節目更多,其他則可能和電影風格或者用戶愛好有關。
僅僅基于用戶評分這樣的信息,機器就能找出這些高等級的概念,甚至不用去理解它們。干得漂亮,電腦先生。現在我們可以寫一篇關于“為什么大胡子的伐木工喜歡我的小馬駒”的論文了。
關聯規則學習(Association rule learning)
“在訂單流水中查找模式”
“關聯規則”目前用于:
預測銷售和折扣
分析“一起購買”的商品
規劃商品陳列
分析網頁瀏覽模式
常用的算法:
Apriori
Euclat
FP-growth
用來分析購物車、自動化營銷策略以及其他事件相關任務的算法都在這兒了。如果你想從某個物品序列中發現一些模式,試試它們吧。
比如說,一位顧客拿著一提六瓶裝的啤酒去收銀臺。我們應該在結賬的路上擺放花生嗎?人們同時購買啤酒和花生的頻次如何?是的,關聯規則很可能適用于啤酒和花生的情形,但是我們還可以用它來預測其他哪些序列? 能否做到在商品布局上的作出微小改變就能帶來利潤的大幅增長?
這個思路同樣適用電子商務,那里的任務更加有趣——顧客下次要買什么?
不知道為啥規則學習在機器學習的范疇內似乎很少提及。經典方法是在對所有購買的商品進行正面檢查的基礎上套用樹或者集合方法。算法只能搜索模式,但沒法在新的例子上泛化或再現這些模式。
編輯:黃飛
?














 工商網監
工商網監
評論