 電子發(fā)燒友App
電子發(fā)燒友App


今天分享的是:深度學習領域基于圖像的三維物體重建最新方法及未來趨勢綜述。原文:Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era 論文下載:https://arxiv.org/abs/1906.06543 摘要:三維重建是計算機視覺計算機圖形學和機器學習等領域幾十年來一個不適定問題。從2015年開始使用CNN解決基于圖像的三維重建(image-based 3D reconstruction)有了極大的關注并且展示出強大的性能。在新時代的快速發(fā)展下,我們提供了這一領域詳細的調(diào)研。本文章專注于從RGB圖像估計三維物體形狀的深度學習方法。除此之外我們還回顧了關于特定物體(如人臉)的近期研究。我們一些重要論文性能的分析和比較,總結(jié)這一領域的現(xiàn)有問題并討論未來研究的方向。
本文是深度學習做三維重建的一篇綜述
對自2015年以來本領域的149個方法做詳盡的回顧
深入分析深度學習三維重建的各個方面,包括訓練集,網(wǎng)絡架構選擇以及重建結(jié)果,訓練技巧和應用場景
總結(jié)對比了普遍的三維重建算法(88種),本文還包含了三維人臉重建算法(11種),人體形狀重建算法(6種方法)
問題陳述和分類
假設?為物體的一張或多張RGB圖片。三維重建可以總結(jié)為一個學習預測算子的過程,輸入圖像到該算子可得到一個和物體相似的模型。因此重建的目標函數(shù)為,其中為算子的參數(shù),為重建結(jié)果和目標的距離函數(shù),也稱作深度學習中的損失函數(shù)。

如上表所示,本文依據(jù)輸入數(shù)據(jù)(Input),輸出的表示(Output),神經(jīng)網(wǎng)絡結(jié)構(Network architecture)和訓練步驟(Training)對算法進行了分類。輸入可以是單張圖片,多張圖片(已知/未知外參),或是視頻流,即具有時間相關性的圖像序列;輸入也可以是描述一個或多個屬于已知/未知類別的物體;還可以包括輪廓,語義標注等先驗作為輸入數(shù)據(jù)。輸出的表示對網(wǎng)絡結(jié)構的選擇來說很重要,它影響著計算效率和重建質(zhì)量,主要有三種表示方法。體積表示(Volumetric):在早期深度學習的三維重建算法中廣泛采用,它可采用體素網(wǎng)格來參數(shù)化三維物體;這樣二維卷積可以很容易擴展到三維,但是會極大消耗內(nèi)存,也只有極少數(shù)方法達到亞像素精度。基于面的表示(Surface):如網(wǎng)格和點云,它們占用內(nèi)存小,但不是規(guī)則結(jié)構,因此很難融入深度學習架構中。中間表示(Intermidiate):不直接從圖像預測得到三維幾何結(jié)構,而是將問題分解為連續(xù)步驟,每個步驟預測一個中間表示。實現(xiàn)預測算子的網(wǎng)絡結(jié)構有很多,它的主干架構在訓練和測試階段也可能是不同的,一般由編碼器h和解碼器g組成,即。編碼器將輸入映射到稱為特征向量或代碼的隱變量x中,使用一系列的卷積和池化操作,然后是全連接層。解碼器也稱為生成器,通過使用全連接層或反卷積網(wǎng)絡(卷積和上采樣操作的序列,也稱為上卷積)將特征向量解碼為所需輸出。前者適用于三維點云等非結(jié)構化輸出,后者則用于重建體積網(wǎng)格或參數(shù)化表面。雖然網(wǎng)絡的架構和它的組成模塊很重要,但是算法性能很大程度上取決于它們的訓練方式。本文將從三方面介紹。數(shù)據(jù)集:目前有多種數(shù)據(jù)集用于深度學習三維重建,一些是真實數(shù)據(jù),一些是計算機圖形生成的。損失函數(shù):損失函數(shù)很大程度上影響著重建質(zhì)量,同時反映了監(jiān)督學習的程度。訓練步驟和監(jiān)督程度:有些方法需要用相應的三維模型標注真實的圖像,獲得這些圖像的成本非常高;有些方法則依賴于真實數(shù)據(jù)和合成數(shù)據(jù)的組合;另一些則通過利用容易獲得的監(jiān)督信號的損失函數(shù)來避免完全的三維監(jiān)督。以下為這些方面的詳細介紹
編碼階段
基于深度學習的三維重建將輸入圖像編碼為特征向量,其中為隱空間。一個好的映射方程應該滿足一下性質(zhì)。
表示相似物體的兩張圖像映射在隱空間應彼此相似
的一個小的擾動應與輸入形狀小的擾動對應
由h引起的潛在表示應和外界因素無關,如相機位姿
三維模型及其對應的二維圖像應映射在隱空間的同一點上,這確保表示的特征不模糊,從而有助于重建
前兩個條件可以通過使用編碼器解決,編碼器將輸入映射到離散或者連續(xù)的隱空間,它可以是平面的或?qū)哟蔚摹5谌齻€條件可以通過分離表示解決,最后一個在訓練階段通過使用TL架構(將在training章節(jié)中講)來解決。 離散隱空間Wu在他們的開創(chuàng)性工作[3]中引入了3D ShapeNet,這是一種編碼網(wǎng)絡,它將表示大小為的離散體積網(wǎng)格的三維模型映射到大小4000×1的向量表示中。其核心網(wǎng)絡由3個卷積層(每個卷積層使用3D卷積濾波器)和3個全連接層組成。這種標準的普通架構已經(jīng)被用于三維形狀分類和檢索,并用于從以體素網(wǎng)格表示的深度圖中進行三維重建。將輸入圖像映射到隱空間的2D編碼網(wǎng)絡有著與3D ShapeNet相似的網(wǎng)絡架構,但使用2D卷積,代表工作有[4],[5],[6],[7],[8],[9],[10]和[11]。早期的工作在使用的網(wǎng)絡層的類型和數(shù)量上有所不同,包括池化層和激活函數(shù)有所不同。 連續(xù)隱空間使用前一小節(jié)中介紹的編碼器,隱空間可能不是連續(xù)的,因此它不允許簡單的插值。換句話說,如果并且,則不能保證可以解碼為有效的3D形狀。此外,的小擾動也不會對應于輸入的小擾動。變分自編碼器(VAE)及其3D擴展(3D-VAE)具有一個讓它們適合生成建模的獨特的特性:通過設計,它們的隱空間是連續(xù)的,允許采樣和插值。其關鍵思想是,它不是將輸入映射到特征向量,而是映射到多變量高斯分布的平均向量和標準差向量。然后,采樣層獲取這兩個向量,并通過從高斯分布隨機采樣生成特征向量,該特征向量將用作隨后解碼階段的輸入。這樣的思想用于為體積表示([17],[18]),深度表示([19]),表面表示([20]),以及點云表示([21],[22])的三維重建算法學習連續(xù)隱空間。3D-VAE可以對在訓練階段沒有見過的圖片重建出不錯結(jié)果。 層次隱空間Liu[18]表明,將輸入映射到單個潛在表示(向量表示)的編碼器不能提取豐富的結(jié)構,因此可能導致模糊的重建。為提高重建質(zhì)量,Liu引入了更復雜的內(nèi)部變量結(jié)構,其具體目標是鼓勵對潛在特征檢測器的分層排列進行學習。該方法從一個全局隱變量層開始,該層被硬連接到一組局部隱變量層,每個隱變量層的任務是表示一個級別的特征抽象。跳躍連接以自上而下的定向方式將隱編碼(向量)連接在一起:接近輸入的局部代碼將傾向于表示較低級別的特征,而遠離輸入的局部代碼將傾向于表示較高級別的特征。最后,當輸入到特定于任務的模型(如三維重建)中時,將局部隱編碼連接到扁平結(jié)構。 分離表示一張圖像中物體的外觀受多個因素的影響,例如對象的形狀、相機位姿和照明條件。標準編碼器用經(jīng)過學習的編碼表示所有這些變量。這在諸如識別和分類之類的應用中是不可取的,這些應用應該對諸如位姿和照明之類的外部因素保持不變。三維重建也可以受益于分離式表示,其中形狀、位姿和燈光用不同的編碼表示。為了達到這一目的,Grant等[5]提出一個編碼器,可以將RGB圖像映射為一個形狀編碼和一個位姿變換編碼。它們將會分別解碼為三維形狀與光線條件位姿。此外,Zhu等人[24]使用相似的思想,將6DOF的位姿參數(shù)和三維模型解耦。這樣減少網(wǎng)絡中的參數(shù),提高了效率。
體積解碼
體積表示將三維物體離散化成三維體素柵格。離散化的越精細,模型也表示的更準確。解碼的目標就是輸入圖像,恢復出柵格,使得三維形狀近似真實的三維物體。使用體積柵格表示的優(yōu)點是很多為二維圖像分析設計的深度學習框架可以很簡單地擴展到三維數(shù)據(jù)(三維卷積與池化)。下面分別介紹不同體積表示方式,低精度解碼器架構以及高精度三維重建。下表為各種體積解碼器的分類:
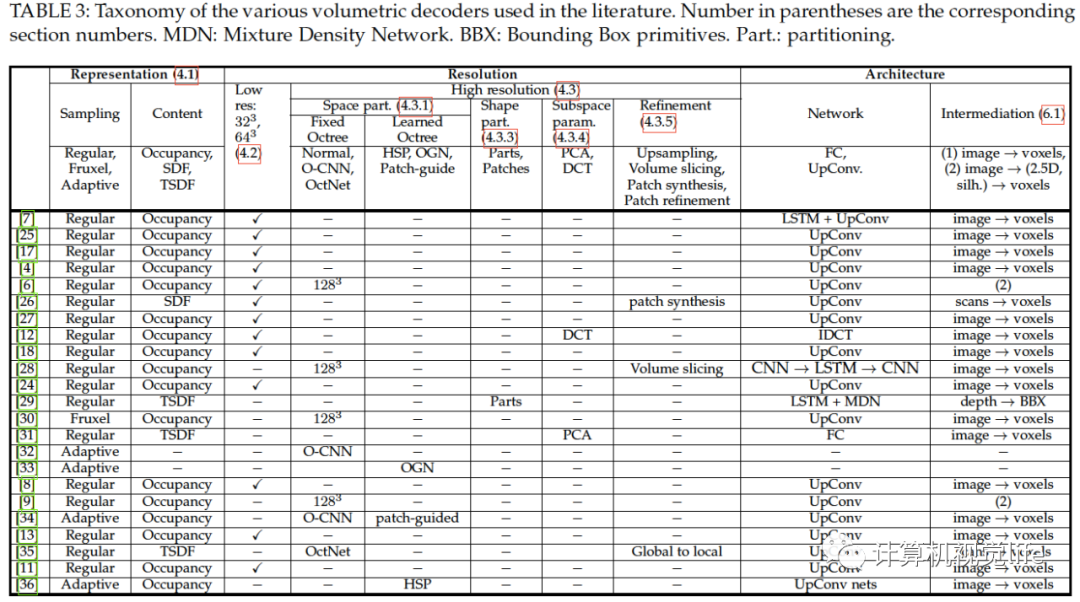
三維形狀的體積表示在文獻中主要有四種體積表示方法:
二元占用柵格(Binary occupancy grid)。在這種表示中,物體的體素被設為1,沒有物體占用的體素設為0。
概率占用柵格(Probabilistic occupancy grid)。在概率占用柵格中的每個體素編碼了它屬于物體的概率。
符號距離函數(shù)(SDF-The Signed Distance Function)。每個體素編碼了到最近表面的距離。體素在物體內(nèi)距離為負,在外距離為正。
截斷符號距離函數(shù)(TSDF-Truncated Signed Distance Function)。首先估計距離傳感器的視線方向上的距離,形成一個有符號的投影距離場,然后在較小的負值和正值處截斷該場。
概率占用柵格尤其適合輸出為似然概率的機器學習算法。符號距離函數(shù)可提供表面位姿和法向量方向的無歧義的估計。然而它們很難從部分數(shù)據(jù)(如深度圖)構建。截斷距離符號函數(shù)犧牲了使用完整的距離域,但是允許基于局部觀測來局部更新。他們適合從一組深度圖中重建三維體積。 低精度三維體積重建 一旦通過編碼器學習到輸入的向量表示,下一步就是學習解碼算子,也叫做生成器或生成模型,它把向量表示映射成體積體素柵格。方法普遍使用卷積反卷積網(wǎng)絡。Wu等人[3]是最先用這種方法從深度圖重建三維體積的。Wu等人[6]提出一個叫做MarrNet的兩階段三維重建網(wǎng)絡。第一階段輸入圖片、得到深度圖、法向量圖和輪廓圖,這三個稱作2.5簡圖。然后再輸入另一對編碼器解碼器回歸出三維體積模型。這個工作在后來被Sun等人[9]發(fā)展出也回歸輸入的位姿。這三類圖更容易從二維圖片中恢復,但很難重建出復雜精細的結(jié)構。Wu等人的工作[3]也有很多其他擴展,如[7],[8],[17],[27],[40]。尤其是近期的工作如[8],[11],[13],[18]不用中間表示回歸出三維體素柵格。 高精度三維體積重建 有方法為高精度體積重建設計深度學習架構。例如,Wu等人[6]的工作可以重建出大小為的體素柵格。但是柵格精度越高,其存儲會隨著三次方增長,因此體積柵格表示消耗大量內(nèi)存。我們把基于算法是否使用空間劃分,形狀劃分,子空間參數(shù)化,或是由粗到精的優(yōu)化策略分為四類。
空間劃分 雖然體積柵格利于卷積操作,但是它很稀疏因為物體表面只在很少的體素內(nèi)。一些論文用這個稀疏性解決分辨率問題,如[32],[33],[41],[42]。它們可以通過使用空間劃分的方法(如八叉樹)重建出到的三維體素柵格。使用八叉樹做基于深度學習的三維重建有兩個問題。一個是內(nèi)存和計算密集,第二點是八叉樹的結(jié)構是和物體有關的,因此深度神經(jīng)網(wǎng)絡需要學習如何推斷八叉樹的結(jié)構以及它的內(nèi)容。下面是兩個問題的解決方案。一是使用預先定義的八叉樹結(jié)構,即假設運行時八叉樹的結(jié)構是已知的。然而這在很多情況下八叉樹的結(jié)構是未知的且必須要預測。Riegler等[41]提出一種混合的柵格-八叉樹結(jié)構叫做OctNet,它限制八叉樹的最大深度為一個小的數(shù)字,并在一個柵格上放幾個這樣的八叉樹。二是學習八叉樹的結(jié)構:同時估計出八叉樹的結(jié)構和內(nèi)容。首先輸入編碼為一個特征向量。然后反卷積解碼得到粗糙的輸入的體積重建。將這個構建好的基分割成八份,包含邊界體素的部分通過反卷積實現(xiàn)上采樣以及后續(xù)處理,改善重建的區(qū)域。不斷遞歸知直到達到期待的精度。
占用網(wǎng)絡 雖然空間劃分方法可以減少內(nèi)存消耗,但是很難實現(xiàn)并且現(xiàn)有的算法建出的體素柵格也比較小(到)。最近一些論文提出用神經(jīng)網(wǎng)絡學習三維模型的隱式表示,如[43]和[44]。
形狀劃分 除了在空間上劃分三維模型,還可以考慮把形狀作為幾何部分來分配,獨立地重建出各個部分,再組合起來構成完整的三維模型。[42]和[29]使用了這樣的思想。
子空間參數(shù)化 所有可能形狀的空間可以使用一組正交基參數(shù)化。每一個形狀可以由基的線性組合表示,即。這個簡化了重建問題。不用學習如何重建體積柵格,取而代之的是設計一個由全連接層構成的解碼器去從隱層表示估計參數(shù),恢復出完整的三維模型。可參考文獻[12]。
由粗到細優(yōu)化 另一個提高體積表示三維重建算法分辨率的方法是使用多階段的方法,如[26],[28],[35],[45],[46]。第一階段用編碼器和解碼器恢復出低精度體素柵格()。接下來的階段作用為上采樣網(wǎng)絡在局部地方改善重建模型。
深度立方體匹配 盡管體積表示適應于任意拓撲的三維模型,但它需要一個后處理步驟,即立方體匹配(marching cubes)[49],獲得實際的三維網(wǎng)格。這樣,整個過程不可以端到端地訓練,為此Liao等人提出[50]一個可端到端訓練的網(wǎng)絡深度立方體匹配,可以預測出任意拓撲的顯式表面表示。
三維表面解碼
基于體積表示的重建算法浪費大量計算資源,因為信息只在三維物體表面附近豐富。基于表面的重建(mesh,點云)主要挑戰(zhàn)是他們不是均勻的結(jié)構,因此它們很難放在深度學習框架。這一章節(jié)把基于表面重建算法分為三類:基于參數(shù)的,基于模版變形的,以及基于點的方法。前兩類為基于網(wǎng)格的解碼器,下表為它的分類。
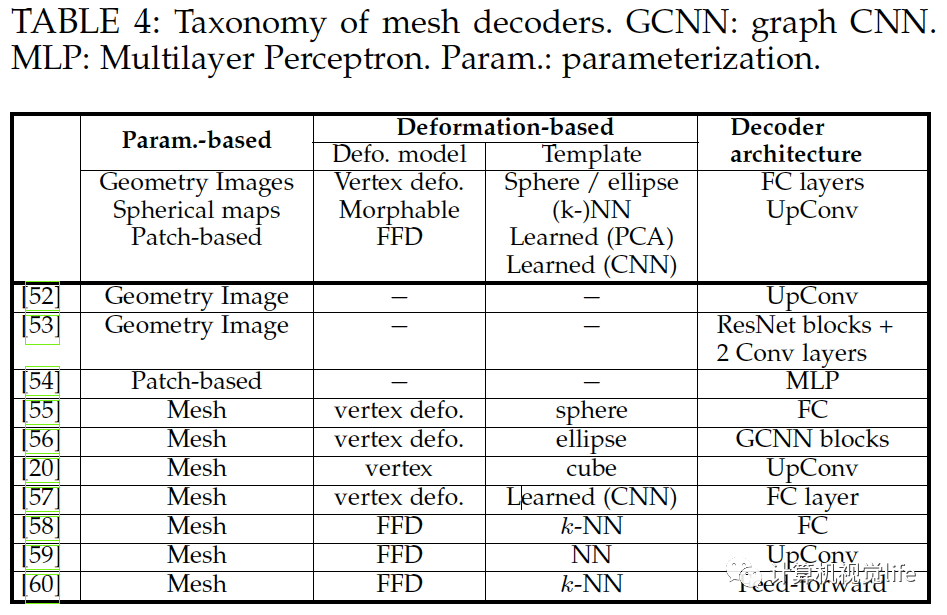
基于參數(shù)的三維建模(Parameterization-based 3D reconstruction) 我們可以用一個映射,其中為一個正則參數(shù)域。三維建模的目標是從輸入中恢復出形狀的函數(shù)。當為三維域內(nèi)時,重建算法就是上一節(jié)的體積重建。本節(jié)取為二維域內(nèi)參數(shù),它可以是一個二維空間平面的子集。球形參數(shù)和幾何圖像[62],[63]和[64]為最常用的參數(shù)化方法,但它們只適合0形(genus-0)和近似圓盤的表面,任意拓撲的表面需要分成像圓盤的幾部分,然后展開成一個二維域。這樣它適合重建屬于同一類外形的物體重建,如人臉和軀干。 基于形變的三維重建(Deformation-based 3D reconstruction) 這類算法輸入圖像然后估計一個形變域,當運用在一個三維模版模型上時,就得到重建好的三維模型。現(xiàn)有的算法在形變模型的使用,模板定義的方式,以及用于估計形變域的網(wǎng)絡架構上有所不同。我們假設三維模型由n個頂點和表面組成。定義為一個模板形狀。
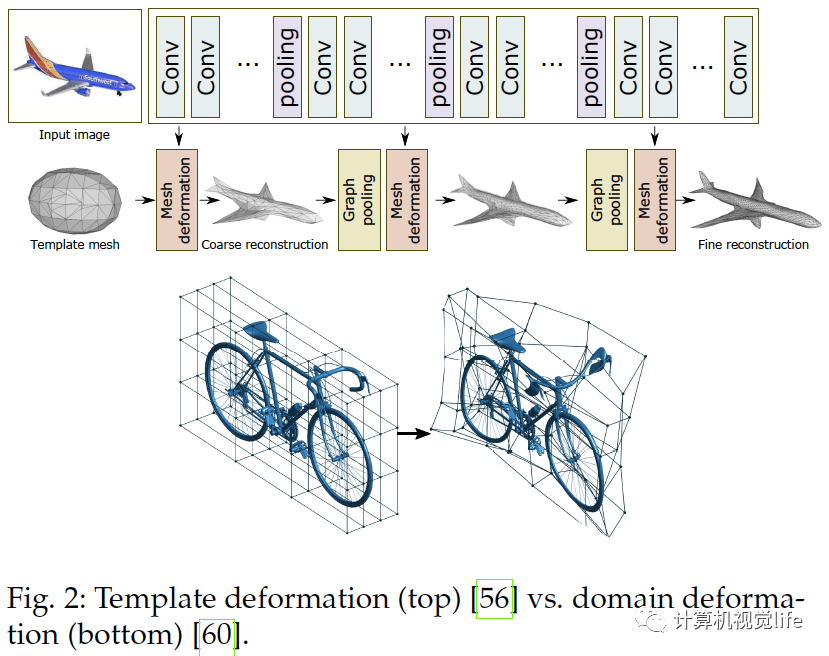
形變模型:大致分三種。一是頂點形變:假設三維模型可以寫作模版獨立頂點的線形組合,這個形變域定義為,該形變模型如上圖的上半部分所示,假設了物體和模版的頂點一一對應且有相似的拓撲結(jié)構,[55],[56],[57]用了該模型。二是可漸變模型:假設為平均形狀,?為一組正交基,任何形狀可以表達為,它的第二項可以視為形變域,算法[68],[69],[70]使用了該模型。三為自由式形變(FFD):除了對模版頂點形變,還可以如上圖下半部分所示對附近空間形變,它被用于[58],[59],[60],它的優(yōu)點是不需要頂點一對一的對應。
定義模版:Kato等人[55]用球形做模板,Wang等人[56]使用橢圓,Henderson等人[20]定義兩種模板。為了加速收斂,Kuryenkov等人[59]提出DeformNet,可以輸入一張圖片,在數(shù)據(jù)庫找到最近臨形狀再用FFD形變。其他定義模板方法如[70],[57]。
網(wǎng)絡架構 基于形變的算法也使用編碼器解碼器架構。編碼器使用連續(xù)卷積操作把輸入映射到隱空間,解碼器通常使用全連接層估計形變域,用球形匹配輸入輪廓。[59]如之前所述,在數(shù)據(jù)庫找到相似模板,這個模板首先體素化,用三維CNN編碼到隱空間表示,再通過反卷積解碼到定義在體素柵格頂點的FFD域,相似的算法還有[60]。
基于點的算法(Point-based techniques) 一個三維模型可以由一組無序的N個點表示。基于點的表示簡單但消耗內(nèi)存小從而較有效。很多論文如[72],[21],[22],[73],[74],[75],[76],[77],[79],[80],[81],[82]等使用點云重建。 點的表示 點云的主要問題是它們沒有規(guī)則的結(jié)構因此很難用于探索空間特征的神經(jīng)網(wǎng)絡。應對這種局限有三種方法解決。一是用點云集表示把點云當作的矩陣,如[21],[22],[72],[75],[77],[81]。二是使用一個或多個大小為的三通道柵格,如[72],[73],[82]。每一個柵格內(nèi)的像素編碼了三維點的坐標。三是用多視角得到的深度圖,如[78],[83]。后兩種解決方法可稱為柵格表示,適合用于卷積網(wǎng)絡,同時計算上也有效率因為它們可以只用二維卷積來預測。 網(wǎng)絡架構 和體積與基于表面表示的算法一樣,基于點表示的算法也使用編碼器解碼器模型,如下圖所示,它們使用解碼器的種類和架構不同。
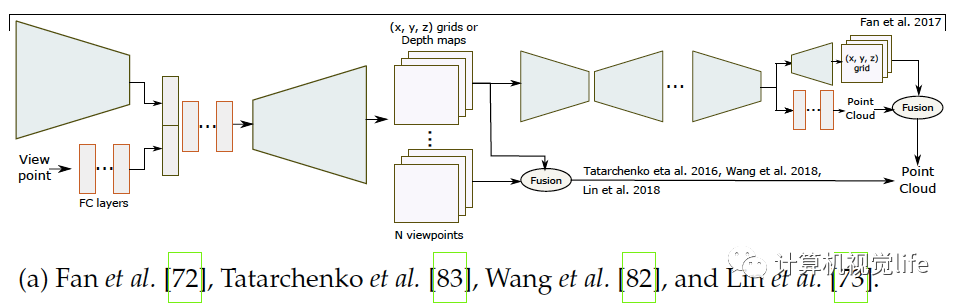
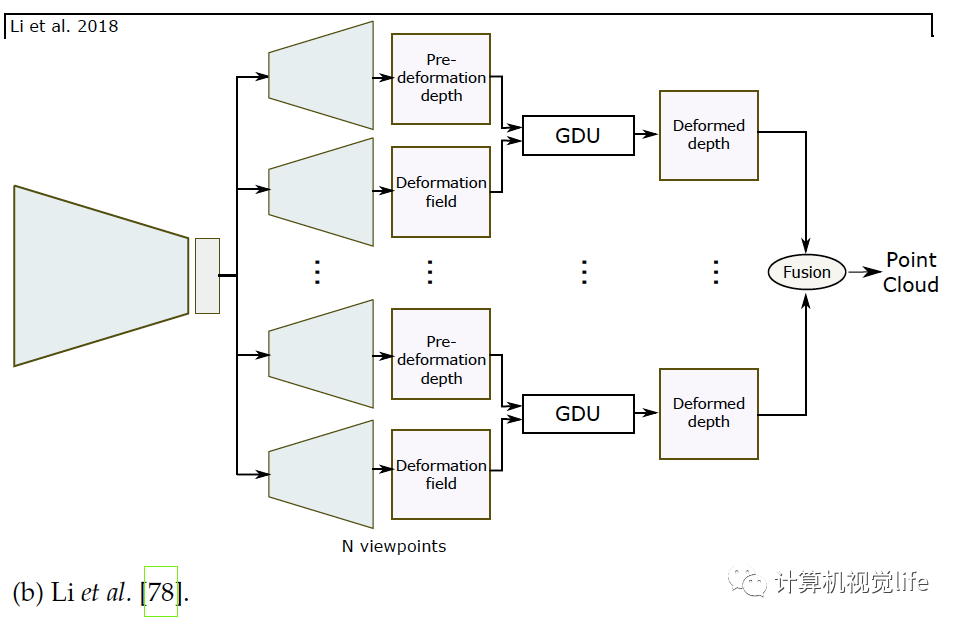
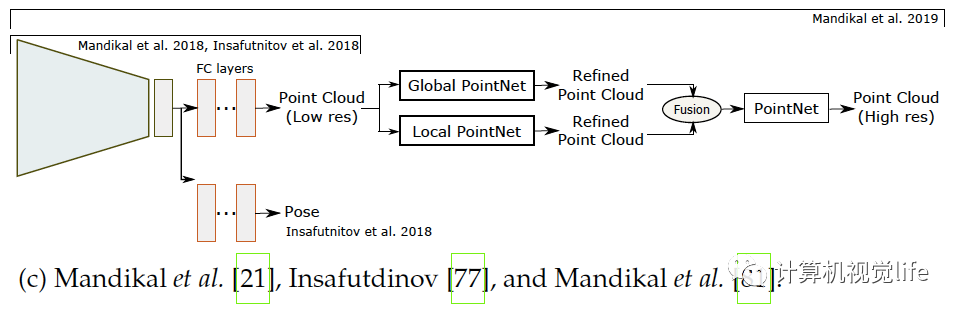
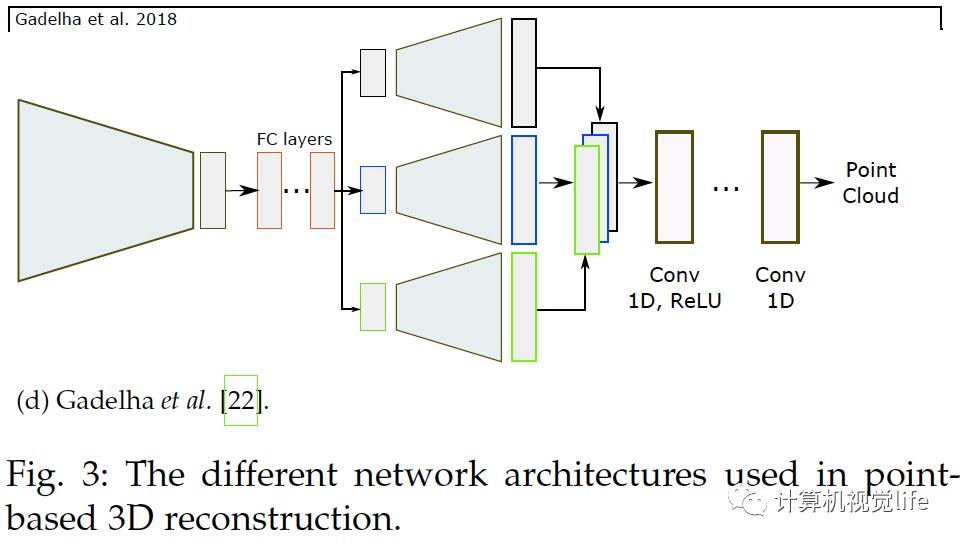
如上圖(a)和(b),普遍柵格表示使用反卷積網(wǎng)絡解碼隱空間變量[72],[73],[78],[82]。基于點集的表示如(c)所示使用全連接層[21],[72],[74],[77],[81],因為點云是無序的。使用全連接層的主要優(yōu)點是它可以捕捉全局信息。然而和卷積操作相比計算量較大。為了高效的卷積計算,Gadelha等人用空間劃分空間排序點云(如KD樹)然后用一維卷積處理它們,如上圖(d),他們?yōu)榱艘黄鹄萌趾途植啃畔ⅲ央[空間變量解碼為三個不同的分辨率,把它們連接起來再用卷積層處理生成點云。Fan等人提出[72]生成深度網(wǎng)絡結(jié)合了點集表示和柵格表示,上圖(a)。網(wǎng)絡結(jié)構由幾個級聯(lián)的編碼器-解碼器組成。[74]和它類似,區(qū)別在于訓練過程。和基于體積重建的算法類似,基于點的三維重建普遍也只恢復出低精度幾何結(jié)構。對于高精度重建,Mandikal等人[81]如上圖(c)所示,使用級聯(lián)的多個網(wǎng)絡結(jié)構:第一個網(wǎng)絡預測低精度點云,之后的每個模塊輸入之前預測的點云,利用類似于PointNet[87]和PointNet++[88]的多層感受結(jié)構(MLP)去計算全局特征,在每個點周圍MLP計算局部特征。局部和全局特征合在一起送進另一個MLP預測出稠密點云。這個過程可以不斷重復直到得到需要的分辨率。Mandikal等人[21]還結(jié)合TL架構和變分自動編碼器。基于點云表示的算法可以處理任意拓撲的三維物體。但是它們需要一個后處理步驟,例如泊松表面重建[89]或者SSD[90]來提取需要的三維表面網(wǎng)格。整個過程不能端到端訓練。因此,這些方法只優(yōu)化一個定義在中間表示的輔助損失函數(shù)。
利用其他信息重建
之前章節(jié)討論了直接從二維觀測重建三維物體。本節(jié)介紹其他額外信息(如中間表示和時間關系)如何用來幫助三維重建。 中間表示 一些方法把三維重建問題分解為幾步,首先估計2.5維的信息,例如深度圖,法向圖或語義分割的區(qū)塊,最后再用傳統(tǒng)的方法(如空間分割或三維反向投影)再濾波,數(shù)據(jù)關聯(lián),恢復出完整的三維幾何結(jié)構及輸入的位姿。早期算法對不同模塊單獨訓練,而如今的工作提出了端到端的解決方案如[6],[9],[38],[53],[80],[91],[92]。還有的算法從預先定義或任意的視角估計多個深度圖,再利用深度圖得到重建結(jié)果,如[83],[19],[73],[93]。[83],[73]和[9]除了深度圖還估計出了輪廓圖。使用多階段方法的優(yōu)點是深度圖,向量圖和輪廓圖更容易從二維圖像恢復出。從這三個恢復出三維模型要比單獨直接從二維圖像中恢復三維模型要更簡單。 時空關系 有時候可以獲取到從不同角度對同一物體拍攝的照片。基于單張圖片的重建算法可以用來處理單幀得到三維建模,再通過配準合成完整模型。比較理想的是,我們可以利用圖片間的時空關系來解決歧義,尤其是在遮擋以及特別雜亂的場景。也就是說,cnn在t時刻應該知道t-1時刻重建了什么,使用它以及新時刻的輸入來重建t時刻的物體或場景。處理這樣連續(xù)時刻數(shù)據(jù)已經(jīng)使用RNN和LSTM解決,它們可以使網(wǎng)絡記住一段時間內(nèi)的輸入。Choy等人提出[7]叫做3D循環(huán)重建網(wǎng)絡(3D-R2N2),它可以從不同視角的信息學習物體的三維表示。這個算法讓神經(jīng)網(wǎng)絡記住看過的圖片并在輸入新圖片時更新存儲,這可以解決物體自我遮擋問題。LSTM和CNN比較耗時并且RNN在輸入圖片輸入順序變化時不能再估計物體形狀,為了解決這樣問題,Xie等人提出[86]叫做Pix2Vox,由并行的多個編碼器解碼器組成。
訓練
除了網(wǎng)絡結(jié)構,深度學習網(wǎng)絡也依賴它們訓練的方法。本節(jié)討論文獻中使用的不同監(jiān)督模式和訓練步驟。 監(jiān)督的程度 早期算法依賴于三維監(jiān)督。然而不管是手動還是用傳統(tǒng)三維重建算法來獲取三維數(shù)據(jù)的真值都比較困難。因此最近一些算法嘗試通過其他監(jiān)督信號例如一致性通過列表最小化三維監(jiān)督程度。
三維監(jiān)督的訓練:訓練時需要有三維真值,損失函數(shù)最小化重建的三維形狀與真值之間的差異,有體積損失函數(shù),點集損失函數(shù),N個重建的最小損失函數(shù)(MoN)。
二維監(jiān)督的訓練:相對三維來說獲取2D或2.5D的視角更加容易,損失函數(shù)為真實的視角與重建物體的投影之間的差異。這需要定義估計的三維模型投影的計算子以及重投影誤差方程。重投影誤差方程主要有基于輪廓的損失函數(shù),基于表面向量和深度的損失函數(shù),或者結(jié)合二維與三維損失函數(shù)。
視頻監(jiān)督訓練 另一個降低監(jiān)督程度的方法是使用運動代替三維監(jiān)督。為此,Novotni等人提出[100]使用運動估計結(jié)構(SFM)從視頻生成監(jiān)督信號:在訓練階段用視頻序列生成部分點云和相對的相機參數(shù)。誤差函數(shù)為網(wǎng)絡訓練的深度圖和SFM得到的深度圖的差異。在測試時,這個網(wǎng)絡就可以直接從RGB圖像恢復出三維幾何結(jié)構。 訓練步驟 除了數(shù)據(jù)集,損失函數(shù)和監(jiān)督程度,還有一些訓練神經(jīng)網(wǎng)絡做三維重建的實踐經(jīng)驗。
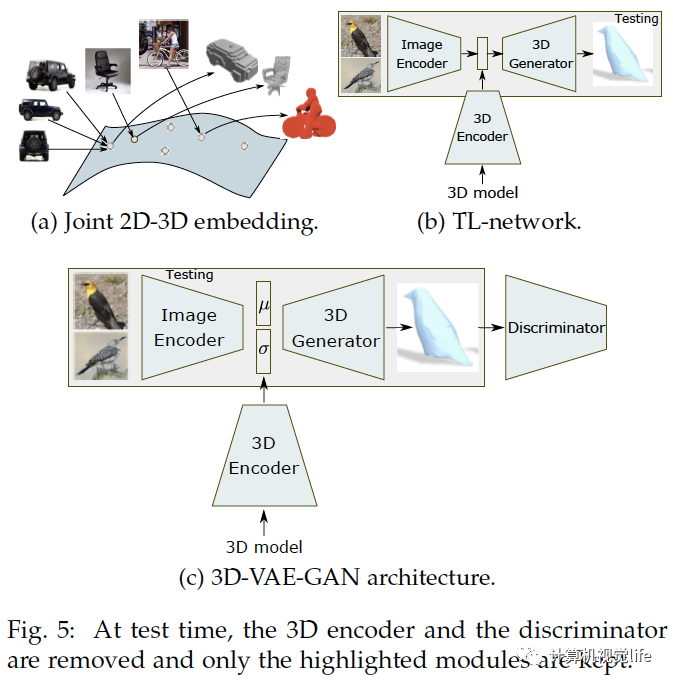
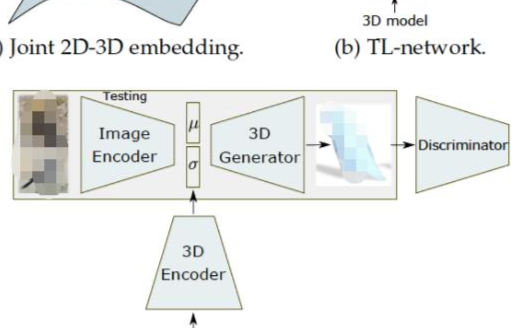
聯(lián)合二維與三維:如上圖(a)和(b),TL-embedding網(wǎng)絡一起訓練編碼:有二維編碼器和三維編碼器。它們分別把二維圖像和它的三維標注映射到隱空間的同一個點。[25],[79],[21]用這樣的方法訓練網(wǎng)絡。
對抗訓練:通常步驟訓練的可能結(jié)果在沒見過的數(shù)據(jù)上重建效果不好。Yang等人[46],[103]開始用生成對抗網(wǎng)絡(GAN)訓練。GAN的潛力很大,因為它們可以模仿任何分布的數(shù)據(jù)。在單視圖重建方面它們已用于體積重建[13],[17],[30],[40],[46],[103]以及基于點云的重建[74],[75]。三維監(jiān)督的有[17],[30],[40],[46],[103],二維監(jiān)督的有[13],[27],[97]。GAN很難訓練,對于高精度的模型很不穩(wěn)定,因此要平衡生成器和分辨器的學習,否則梯度會消失。
和其他任務聯(lián)合訓練:聯(lián)合訓練重建與分割會讓它們互相促進。如Mandikal等人[107]的方法。
應用和特殊案例
很多應用處理特定類別的物體如人的身體部位(臉和手等),野外的動物和汽車。使用這些物體類別的先驗知識可以顯著提高重建質(zhì)量。 三維人體重建 虛擬的(數(shù)字的)人在很多應用如游戲,視覺體驗影片中很重要,一些算法可以輕量地只從幾個RGB圖像中恢復出人體形狀和位姿。有基于體積表示的,也有基于模板或參數(shù)表示的算法。一些算法只重建出人體模型[108],[109],還有算法也重建出了衣服[110],[111]。基于參數(shù)的算法主要把問題轉(zhuǎn)化為不同的統(tǒng)計模型,三維人體模型估計就變?yōu)槟P蛥?shù)估計。主要模型有SCAPE[108],[109],[115]和SMPL[110],[116],[117],[118],[119]。基于體積的方法直接推斷占用柵格,在之前章節(jié)描述的基于體積的方法可直接用于人體重建[121],[122]。 三維人臉重建 大多數(shù)方法使用參數(shù)表示來重建,廣泛使用的是Blanz和Vetter提出的[68]三維形變模型(3DMM)。該模型從幾何和紋理的角度捕捉面部的變化。Gerig等人[124]通過將表情作為單獨的空間擴展了這個方法。 三維場景解析 除了單獨的物體重建,場景解析問題在于遮擋,聚類,形狀和位姿的不確定還需要估計場景布局。該問題結(jié)局方案涉及到三維物體檢測和識別,位姿估計和三維重建。主要方法有[136],[138]。
數(shù)據(jù)集
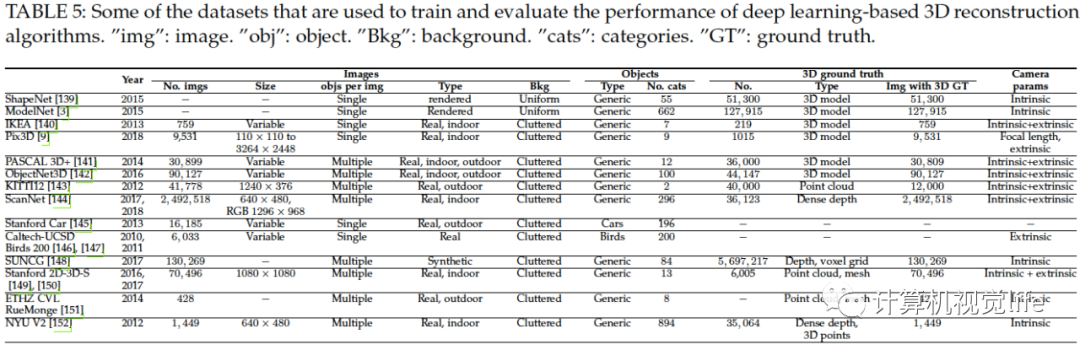
下面表格列出并總結(jié)了普遍使用的數(shù)據(jù)集的屬性。基于深度學習的三維重建需要特別大的訓練數(shù)據(jù)集,監(jiān)督學習還需要對應的三維標注,弱監(jiān)督和無監(jiān)督學習依賴外界監(jiān)督信號如相機內(nèi)外參。下表為一些數(shù)據(jù)集的信息。
性能對比
本節(jié)討論一些關鍵算法的性能,下面介紹各種性能的標準和度量,并討論和比較一些算法的性能。 精度指標和性能標準 設為真實三維形狀,為重建結(jié)果。 精度指標: ·均方誤差(MSE):重建結(jié)果和真值的對稱表面距離 這里和分別是和的采樣點數(shù)量,是p到沿垂直方向到的距離,如L1和L2,距離越小,重建越好。 ·交并比(IoU):IoU測量重建預測出的形狀體積與真實體積的交集與兩個體積的并集的比率 其中是指示函數(shù),是第i個體素的預測值,是真值,是閾值。IoU值越高,重建效果越好,這一指標適用于體積重建。因此,在處理基于曲面的表示時,需要對重建的和真實的三維模型進行體素化。 ·交叉熵損失的均值:熵的均值越低,重建效果越好。 ·搬土距離(EMD)和倒角距離(Chamfer Distance) 性能標準: ·三維監(jiān)督程度:基于深度學習的三維重建算法的一個重要方面是訓練時三維監(jiān)督的程度。事實上,雖然獲取RGB圖像很容易,但獲取其相應的真實3D數(shù)據(jù)卻相當具有挑戰(zhàn)性。因此,在訓練過程中,與那些需要真實三維信息的算法相比,通常更傾向于需要較少或不需要三維監(jiān)督的技術。 ·計算時間:雖然訓練時間慢,通常希望可以達到實時表現(xiàn)。 ·內(nèi)存占用:神經(jīng)網(wǎng)絡需要大量參數(shù)。一些算法在體積上使用三維卷積,這樣就會消耗大量內(nèi)存,會影響實時性能限制它們的應用范圍。 比較和討論 下圖展示了過去四年重建算法精度的改進。
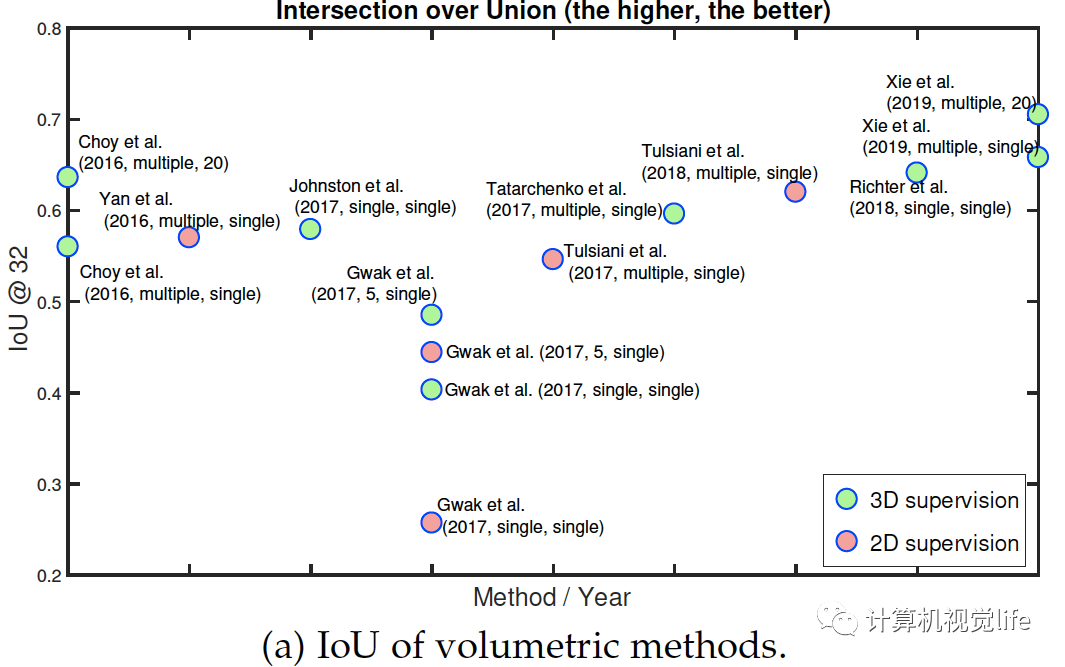
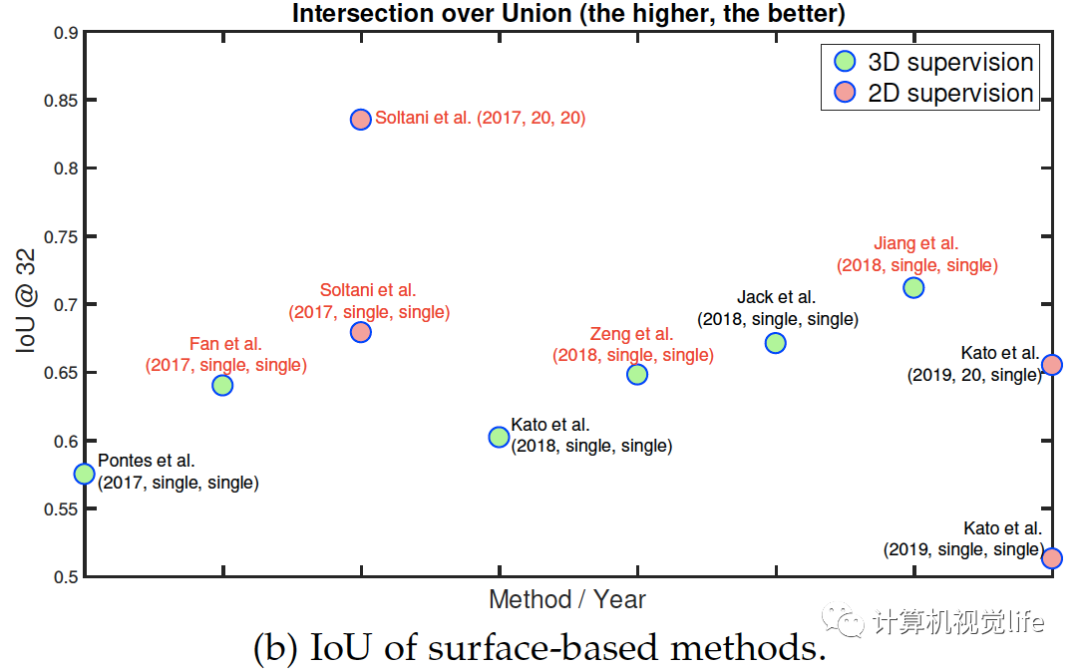
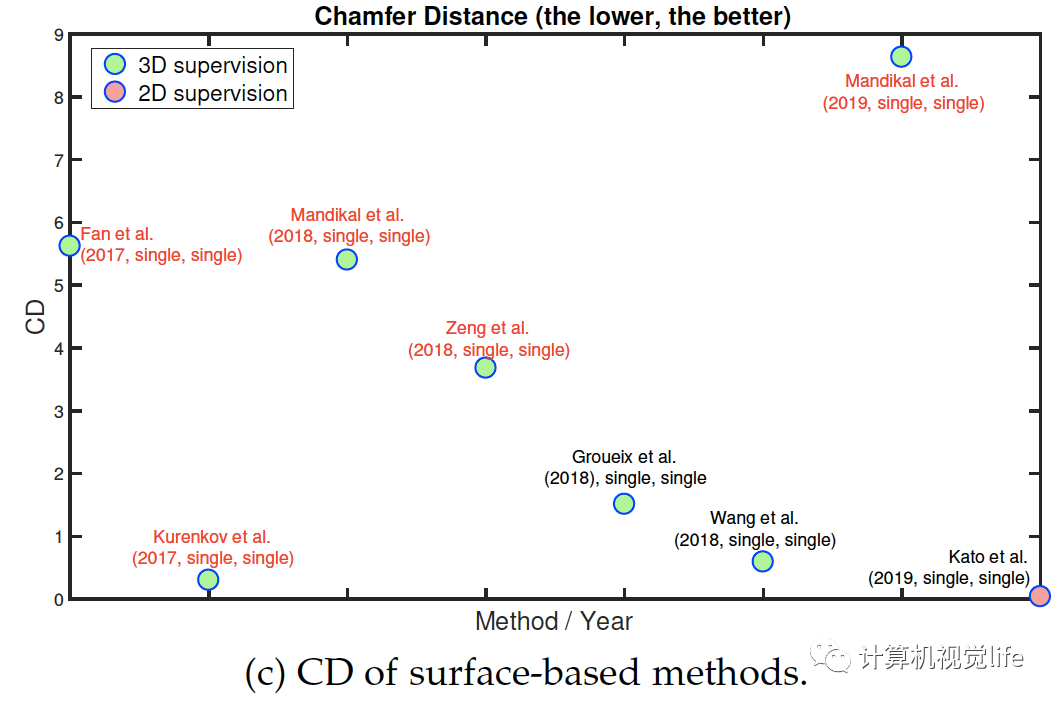
Fig. 6: Performance of some key methods on the ShapeNet dataset. References highlighted in red are point-based. The IoU is computed on grids of size?. The label next to each circle is encoded as follow: First author et al. (year, n at training, n at test), where n is the number of input images. 早期的研究大多用體素化表示,這樣可以表示任意拓撲復雜物體的表面和內(nèi)部細節(jié)。隨著O-CNN,OGN和OctNet等空間分割技術提出,體積表示的算法可以達到相對較高的分辨率,例如。這是由于內(nèi)存效率的顯著提高。然而只有很少論文采用這些方法因為它們的實現(xiàn)比較復雜。為了實現(xiàn)高分辨率的三維體積重建,最近的許多論文都使用了中間表示,通過多個深度圖,然后進行體積或基于點的融合。最近有幾篇論文開始關注學習連續(xù)的有符號距離函數(shù)的機制或連續(xù)占用網(wǎng)格,這些機制在內(nèi)存需求方面要求較低。它們的優(yōu)點是,由于它們學習了一個連續(xù)的場,因此可以在所需的分辨率下提取重建的三維物體。圖片顯示出自2016年以來,使用ShapeNet數(shù)據(jù)集作為基準的幾年來性能的演變。在大小為的體積柵格上計算的IoU度量上,我們可以看到在訓練和測試時使用多個視圖的方法優(yōu)于僅基于單個視圖的方法。此外,2017年開始出現(xiàn)的基于表面的重建算法略優(yōu)于體積算法。圖片還可看出2017年基于二維監(jiān)督的算法出現(xiàn)后,性能越來越高。(a)和(b)兩圖看出基于三維監(jiān)督的算法性能稍微更好。論文中表6為一些有代表性的算法的性能,見文尾原文的參考鏈接。
未來研究方向
在過去五年的大量研究中,使用深度學習進行基于圖像的三維重建取得了很好的效果。然而這一課題仍在初級階段,有待進一步發(fā)展。這一節(jié)介紹一些當前的問題,并強調(diào)未來研究的方向。
訓練數(shù)據(jù)問題。深度學習技術的成功在很大程度上取決于訓練數(shù)據(jù)的可用性,不幸的是,與用于分類和識別等任務的訓練數(shù)據(jù)集相比,包含圖像及其3D注釋的公開數(shù)據(jù)集的大小很小。二維監(jiān)督技術被用來解決缺乏三維訓練數(shù)據(jù)的問題。然而,它們中的許多依賴于基于輪廓的監(jiān)督,因此只能重建視覺外殼。因此,期望在未來看到更多的論文提出新的大規(guī)模數(shù)據(jù)集、利用各種視覺線索的新的弱監(jiān)督和無監(jiān)督方法,以及新的領域適應技術,其中使用來自某個領域的數(shù)據(jù)訓練的網(wǎng)絡(例如,合成渲染圖像)適應新的領域。研究能夠縮小真實圖像和綜合渲染圖像之間差距的渲染技術,可能有助于解決訓練數(shù)據(jù)問題。
對看不見的物體的一般化。大多數(shù)最新的論文將數(shù)據(jù)集分成三個子集進行訓練、驗證和測試,例如ShapeNet或Pix3D,然后測試子集的性能。但是,還不清楚這些方法如何在完全不可見的對象/圖像類別上執(zhí)行。實際上,三維重建方法的最終目標是能夠從任意圖像中重建任意三維形狀。然而,基于學習的技術僅在訓練集覆蓋的圖像和對象上表現(xiàn)良好。
精細的三維重建。目前最先進的技術能夠恢復形狀的粗糙三維結(jié)構,雖然最近的工作通過使用細化模塊顯著提高了重建的分辨率,但仍然無法恢復植物、頭發(fā)和毛皮等細小的部分。
重建與識別。圖像三維重建是一個不適定問題。因此,有效的解決方案需要結(jié)合低層次的圖像線索、結(jié)構知識和高層次的對象理解。如Tatarchenko[44]最近的論文所述,基于深度學習的重建方法偏向于識別和檢索。因此,他們中的許多人沒有很好地概括,無法恢復精細的尺度細節(jié)。期望在未來看到更多關于如何將自頂向下的方法(即識別、分類和檢索)與自下而上的方法(即基于幾何和光度線索的像素級重建)相結(jié)合的研究,這也有可能提高方法的泛化能力。
專業(yè)實例重建。期望在未來看到特定于類的知識建模和基于深度學習的三維重建之間的更多協(xié)同作用,以便利用特定于領域的知識。事實上,人們對重建方法越來越感興趣,這些方法專門用于特定類別的物體,如人體和身體部位、車輛、動物、樹木和建筑物。專門的方法利用先前和特定領域的知識來優(yōu)化網(wǎng)絡體系結(jié)構及其訓練過程。因此,它們通常比一般框架表現(xiàn)得更好。然而,與基于深度學習的三維重建類似,建模先驗知識需要三維注釋,這對于許多類型的形狀(例如野生動物)來說是不容易獲得的。
在有遮擋和雜亂背景的情況下處理多個對象。大多數(shù)最先進的技術處理包含單個對象的圖像。然而,在野生圖像中,包含不同類別的多個對象。以前的工作采用檢測,然后在感興趣的區(qū)域內(nèi)重建。然而,這些任務是相互關聯(lián)的,如果共同解決,可以從中受益。為實現(xiàn)這一目標,應處理兩個重要問題。一是缺乏多目標重建的訓練數(shù)據(jù)。其次,設計合適的CNN結(jié)構、損失函數(shù)和學習方法是非常重要的,特別是對于沒有3D監(jiān)督的訓練方法。這些方法通常使用基于輪廓的損失函數(shù),需要精確的對象級分割。
3D視頻。本文研究的是一幅或多幅圖像的三維重建,但沒有時間相關性,而人們對三維視頻越來越感興趣,即對連續(xù)幀具有時間相關性的整個視頻流進行三維重建。一方面,幀序列的可用性可以改善重建,因為可以利用后續(xù)幀中可用的附加信息來消除歧義并細化當前幀處的重建。另一方面,重建的圖像在幀間應該平滑一致。
走向全三維場景解析。最后,最終目標是能夠從一個或多個圖像中語義分析完整的3D場景。這需要聯(lián)合檢測、識別和重建。它還需要捕獲和建模對象之間和對象部分之間的空間關系和交互。雖然在過去有一些嘗試來解決這個問題,但它們大多局限于室內(nèi)場景,對組成場景的對象的幾何和位置有很強的假設。
總結(jié)和評論
這篇論文綜述了近五年來利用深度學習技術進行基于圖像的三維物體重建的研究進展,將頂級的算法分為基于體積、基于表面和基于點的算法。然后,根據(jù)它們的輸入、網(wǎng)絡體系結(jié)構和它們使用的訓練機制討論了每個類別中的方法,還討論并比較了一些關鍵方法的性能。該調(diào)研重點是將三維重建定義為從一個或多個RGB圖像中恢復對象的三維幾何體的問題的方法。然而,還有許多其他相關問題也有類似的解決辦法。包括RGB圖像的深度重建[153]、三維形狀補全[26],[28],[45],[103],[156],[160],[161],深度圖像的三維重建[103]、新視角合成[164],[165]和三維形狀結(jié)構恢復[10],[29],[83],[96]等等。在過去五年中,這些主題已被廣泛調(diào)查,需要單獨的總結(jié)論文。
編輯:黃飛
?




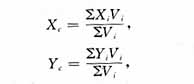






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論