 電子發(fā)燒友App
電子發(fā)燒友App


2022年11月,美國Open AI公司上線了一款名為ChatGPT的語言大模型——你可以將它理解為是一款人工智能聊天機器人程序。

比起它之前存在的那些聊天機器人,ChatGPT似乎更聰明了。雖然仍然以文字聊天的形式與人類互動,但它已經(jīng)可以和人類進行非常自然的聊天了。
甚至除了聊天,ChatGPT還能夠勝任許多較為復雜的語言工作,比如寫論文,比如寫策劃,比如寫代碼。
大量的美國學生正在利用ChatGPT的超強性能實施他們的“作弊計劃”——許多學生直接讓ChatGPT為自己生成一篇論文或者論文大綱,還有人讓ChatGPT幫自己在在線考試中答題。
可以說,這是人工智能這個概念出現(xiàn)以來人類創(chuàng)造出的“最強大腦”。
面對這個展露出前所未有“智能”的聊天機器人,人類的社會陷入一片喧囂——從北美的華盛頓到東亞的北京,幾乎所有關注科技的人都或多或少地參與了關于它的討論。
今天,我們就來聊聊ChatGPT的前世今生以及分享一些我的想法。
1/ 【ChatGPT的前世今生】
ChatGPT的故事要從2017年的一篇論文說起。2017年,谷歌發(fā)布了一篇名為《Transformer: Attention is all you need》的論文。這篇論文的核心就是提出了一個名為“Transformer”的新型模型。

眾所周知,AI的運轉(zhuǎn)背后是數(shù)學運算,工程師們將現(xiàn)實世界里的各種事物用數(shù)學的方式表達給計算機,計算機得出結(jié)果之后,再反向用數(shù)學的方式回饋一個答案。
在“Transformer”之前,主流的計算方式是順序性的——后一個時刻的輸入依賴于前一時刻的輸出,你必須先完成前序計算才能開始下一步的計算。這就好像是逐字逐句地讀書,你必須讀完上一句才能看下一句。
而“Transformer”的獨特就在于它打破了這種順序性的套路。利用獨特的“Attetion機制”(注意力機制),它可以一次性處理所有輸入的數(shù)據(jù)。如果還用讀書來做比較,它更像是“一目十行”地看書——一次性輸入大量的內(nèi)容然后自己判斷出這本書到底在寫什么。
Transformer的獨特優(yōu)勢使得它獲得相比起之前的AI模型更快的處理速度,也就更適合在超大型數(shù)據(jù)上進行訓練。
一經(jīng)提出,Transformer立刻就成為了“業(yè)界寵兒”——在它的基礎上,谷歌做出了BERT模型,另一家新成立的公司Open AI則做出了GPT模型。
從名字上我們就能看出,現(xiàn)在的ChatGPT就是從當時的GPT身上發(fā)展出來的——ChatGPT相當于是GPT的聊天機器人特化版。
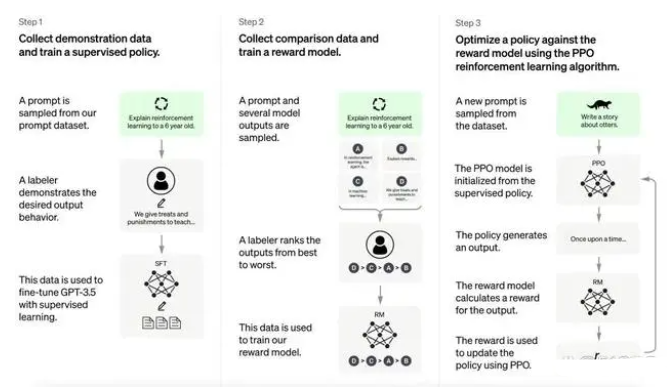
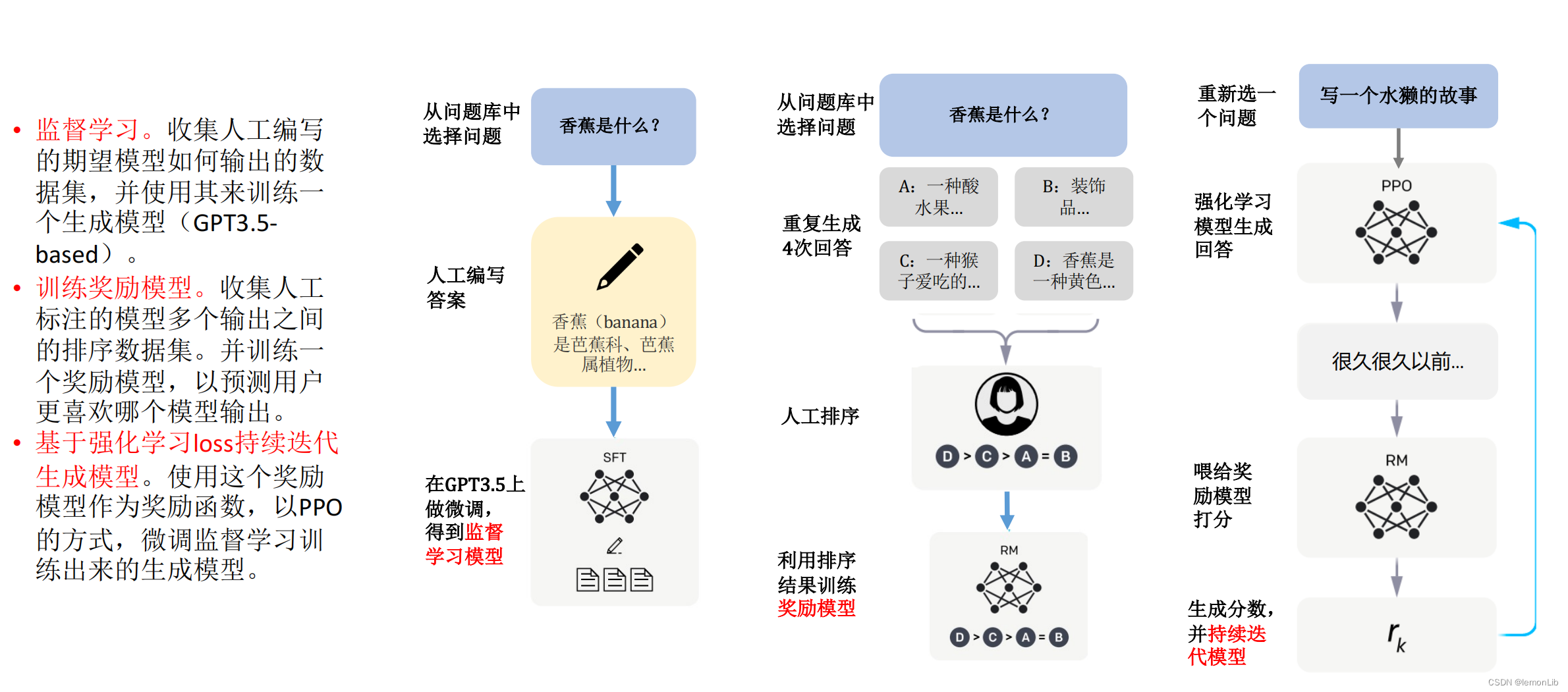
另一個比較有意思的是,ChatGPT之所以體驗起來如此絲滑,是因為它的背后有一個叫做“基于人類反饋的強化學習”的機制(HFRL)。相當于是請了人類老師來訓練AI模型,教AI模型怎么更好地和人打交道——面對AI輸出的結(jié)果,人類老師會給予評分,當這個結(jié)果符合人類的習慣,就會得高分,反之則會打低分。
某種意義上來說,HFRL可以被看作是一種“抽象的人類意志”,AI模型就是從它身上學會和人打交道所需要的一切知識。
久而久之,在HFRL的輔助下,GPT就會學會如何像真正的人類那樣交流。比起之前的模型,它對人類用戶的實際意圖理解更深刻,還具備了銜接上下文的能力和強大的知識與邏輯。
2/ 【ChatGPT,一把尚未出鞘的利刃】
了解了ChatGPT的基本原理,我們就能討論一下更多有趣的事情了。當然,現(xiàn)在的GPT還有許多毛病——比如當我的朋友孔老師問它“賈寶玉到底適合《紅樓夢》里哪一位女性?”時,ChatGPT果斷推薦了賈母——并且煞有介事地給出了自己的理由。
雖然離譜,但是這是可以理解的。畢竟ChatGPT的本質(zhì)是基于英語的,在它的訓練材料中,中國傳統(tǒng)文化相關的內(nèi)容并不會太多——哪怕它可以把維基百科里的無數(shù)詞條都當作訓練素材,其中中文內(nèi)容的占比也是少數(shù)——如果你用英文去問它一些技術(shù)問題,那么它的回答會清楚得多。
不論如何,ChatGPT的確是顯示出了強大的潛力,它現(xiàn)在雖不完美,但已經(jīng)足夠震撼了。
我最為震撼的地方就在于此:ChatGPT的出現(xiàn),可能已經(jīng)宣告著AI技術(shù)將會迎來大規(guī)模的普及——在ChatGPT之前,AI技術(shù)在現(xiàn)實中的運用往往都是大型企業(yè)的“專利”,只有大型企業(yè)才有錢為自己量身定制。但在ChatGPT之后,通用型的AI已經(jīng)不再是一個可望而不可及的目標了。
就在今天。2023年的2月8日,微軟就將ChatGPT接入了自己的搜索引擎Bing——我們普通人已經(jīng)可以非常低成本使用它了。
結(jié)合已有的成熟技術(shù),現(xiàn)在已經(jīng)有了無數(shù)值得我們想象的未來應用場景。
ChatGPT這種簡單的聊天式交互,非常符合我們的日常習慣——暫且忽略掉它胡說八道的事情,當你向它詢問某些事情的時候,它的反應的確和真人并無太大的區(qū)別。哪怕僅憑這一個特色,就已經(jīng)有很多值得想象的地方了。
以現(xiàn)在的一些企業(yè)辦公軟件為例,當你打開這些辦公軟件,首先看到的就是被各種圖標各種菜單填滿的界面。
如果你和我一樣不屬于那種每天都需要用辦公軟件走程序的崗位,那么哪怕是簡簡單單請個假或者申請一個報銷單,你可能都需要在里面找半天。
但如果這個辦公軟件是基于ChatGPT的呢?那么情況可能就完全不同了——基于ChatGPT的辦公軟件等于是給公司里的每個人都配了個助理。
你想請兩天年假?那么直接告訴它“我要請假”就可以了,它就會直接甩給你一份表格讓你填寫。
你想去杭州拜訪一下客戶?那么直接告訴它“我下周三要去杭州出差”,它就會直接用公司的名義和賬戶幫你訂好往返的機票和酒店,順便還會提醒你保留在杭州的各種發(fā)票。
當然了,這些都還只是小兒科,犯不著用ChatGPT也可以解決。但如果你想策劃一個活動的話,你可以直接問ChatGPT如何策劃,它會直接返回給你一個像模像樣的策劃案——已經(jīng)有人通過多次詢問的方式讓ChatGPT幫他生成了“辯論比賽策劃案”了。
再比如去醫(yī)院掛號看病,現(xiàn)在雖然有了微信小程序掛號和自助掛號機,但是大家都知道這玩意兒操作起來有多繁瑣麻煩,年輕人都要填半天表格,更何況老年人呢?
但如果某家醫(yī)院配備了基于ChatGPT的問診系統(tǒng),這些問題瞬間就會變的簡單起來——你只需要告訴它你哪里,它就會很自然地問你是簡單的咨詢還是要去掛號。如果你想咨詢或者只是單純想開點藥,它完全可以給你提供一個足夠靠譜的解答。
如果你說要掛號,ok,它直接就會幫你分配科室掛號并且順便甩你一個付款鏈接。另外,現(xiàn)在語音識別功能這么先進了,就算是普通話不好的老人,通過語音輸入也可以實現(xiàn)這套操作。
再比如處理各種必要的證件和手續(xù)——想當初我買第一套房的時候,銀行的各種手續(xù)、房管局的各種流程把我整的要死要活的。如果AI能接管這些事情,我想總還是比親自跑來跑去要省事兒的多。
總而言之,ChatGPT的強悍之處就在于它那個和真人聊天一樣的感覺以及它背后的想象空間——用自然語言指揮一切、實現(xiàn)一切。
3/ 【語言生成模型,必須國產(chǎn)化】
但我們需要注意的是:任何事情都有兩面性——ChatGPT的想象空間有多大,它能造成的麻煩就有多大——互聯(lián)網(wǎng)興起之后,依托互聯(lián)網(wǎng)的黑色產(chǎn)業(yè)也在不斷壯大,如今AI崛起已經(jīng)是時間問題,基于AI的黑產(chǎn)問題也不容小覷。
甚至黑產(chǎn)都是小問題,因為沒有人能確保AI不被武器化。
今天,即便是大學教授也無法分辨一篇文章到底是ChatGPT寫的還是人類學生寫的。既然這樣,那么會不會有人專門就做這個生意呢?考試作弊、論文代寫……如果這些黑產(chǎn)從業(yè)者熟練掌握了ChatGPT,那么他們的破壞力只會更高。
畢竟,原來的“論文代寫”是真的要請人寫的,幾百上千塊錢的辛苦費是少不了的,但現(xiàn)在,用AI就可以操作了,整套操作下來做多也就畫個十幾塊錢。
我們再往下想一層,既然ChatGPT寫的東西大學教授都無從分辨,那么它如果放在日常的網(wǎng)聊中就更不會被人察覺了。
再結(jié)合一下現(xiàn)在非常流行的AI繪圖、AI語音,以及現(xiàn)在已經(jīng)開始起步的AI視頻……當你的網(wǎng)聊對象會發(fā)語音,會發(fā)自拍,會和你視頻,且對答如流、口齒伶俐的時候,你如何確定對方是真人還是AI呢?
或許到了那天,即便對面是個摳腳大漢也是一種幸運……起碼對方是個人呢。
更恐怖的是,如果有人將ChatGPT這樣的AI用在干擾輿論、挑動社會情緒上呢?要知道,這些東西其實并不新鮮,之前早就已經(jīng)存在了——ChatGPT的出現(xiàn),某種意義上讓這些黑產(chǎn)的犯罪成本更低了。
最根本的是,ChatGPT不是中國的,它的管理大權(quán),并不掌握在我們手中。未來如果AI技術(shù)大規(guī)模普及,深入到了千家萬戶,如果我們只能用外國的AI,那么就等于是把命脈交到了別人手里——這背后不僅是一個個公民的信息,更是整個國家的種種數(shù)據(jù)。
因此,在我看來,中國必須開發(fā)自己的“ChatGPT”,否則在未來很可能陷入被動局面——因為只有擁有國產(chǎn)自主的“ChatGPT”,我們才能既保證中國社會可以享受到AI產(chǎn)業(yè)帶來的技術(shù)升級,又能夠免于被人卡脖子以及無法管理的問題。
昨天,百度的“文心一言”正式得到了官宣。在此之前,2020年的時候,百度就已經(jīng)開發(fā)出了有16億個參數(shù)的、類似ChatGPT的通用對話生成模型PLATO-2——比當時的GPT-2的參數(shù)量(15億)基本處于同一個級別。
不過,我們也還是要正視差距的。在類似ChatGPT這樣的大型語言模型的訓練中,億級、十億級、百億級、千億級、萬億級參數(shù)的訓練難度和成本是完全不同的——背后不僅考驗金錢投入,也考驗從業(yè)人員的技術(shù)水平。
2018年,GPT剛出來的時候,參數(shù)量不過1億多,數(shù)據(jù)量只有5GB。不過四年之后,現(xiàn)在的ChatGPT,參數(shù)量以及達到了1750億,數(shù)據(jù)量45TB。
幸運的是,AI行業(yè)是一個沒有秘密的行業(yè)。而且目前全球范圍內(nèi)來看,也只有中美兩國有大規(guī)模發(fā)展AI產(chǎn)業(yè)的機會。
因此,中國獨立自主的“ChatGPT”的到來只是時間問題,國內(nèi)已經(jīng)有一些企業(yè)打造出了GPT-3水準的大模型了,以中國人的能力,最多一年,我們也可以實現(xiàn)ChatGPT的水平。
編輯:黃飛

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論