 電子發燒友App
電子發燒友App


去年12月1日,OpenAI推出人工智能聊天原型ChatGPT,再次賺足眼球,為AI界引發了類似AIGC讓藝術家失業的大討論。
ChatGPT 是一種專注于對話生成的語言模型。它能夠根據用戶的文本輸入,產生相應的智能回答。 這個回答可以是簡短的詞語,也可以是長篇大論。其中GPT是Generative Pre-trained Transformer(生成型預訓練變換模型)的縮寫。 通過學習大量現成文本和對話集合(例如Wiki),ChatGPT能夠像人類那樣即時對話,流暢的回答各種問題。(當然回答速度比人還是慢一些)無論是英文還是其他語言(例如中文、韓語等),從回答歷史問題,到寫故事,甚至是撰寫商業計劃書和行業分析,“幾乎”無所不能。甚至有程序員貼出了ChatGPT進行程序修改的對話。
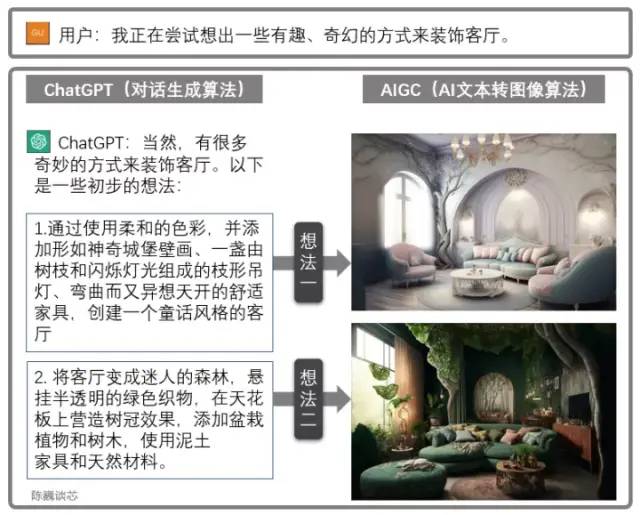
ChatGPT和AIGC的聯合使用
ChatGPT也可以與其他AIGC模型聯合使用,獲得更加炫酷實用的功能。
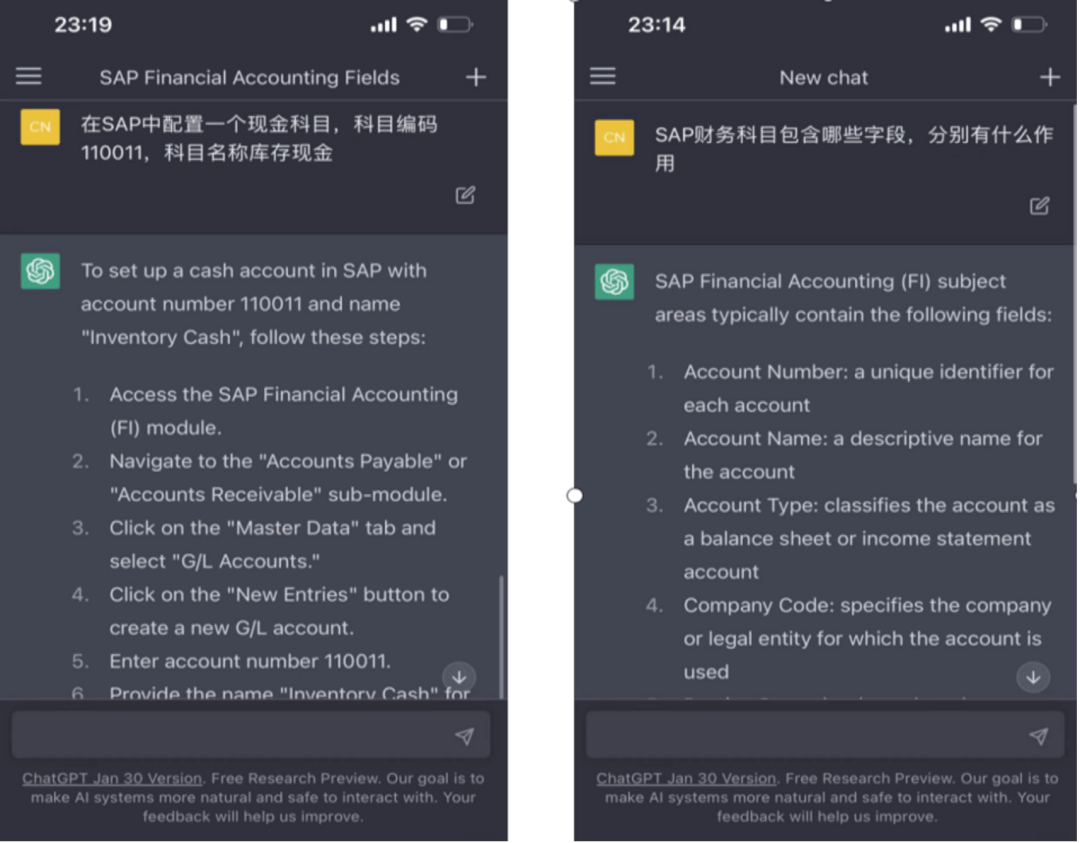
例如上面通過對話生成客廳設計圖。這極大加強了AI應用與客戶對話的能力,使我們看到了AI大規模落地的曙光。
一、ChatGPT的傳承與特點

▌1.1 OpenAI家族
我們首先了解下OpenAI是哪路大神。 OpenAI總部位于舊金山,由特斯拉的馬斯克、Sam Altman及其他投資者在2015年共同創立,目標是開發造福全人類的AI技術。而馬斯克則在2018年時因公司發展方向分歧而離開。 此前,OpenAI 因推出 GPT系列自然語言處理模型而聞名。從2018年起,OpenAI就開始發布生成式預訓練語言模型GPT(Generative Pre-trained Transformer),可用于生成文章、代碼、機器翻譯、問答等各類內容。 每一代GPT模型的參數量都爆炸式增長,堪稱“越大越好”。2019年2月發布的GPT-2參數量為15億,而2020年5月的GPT-3,參數量達到了1750億。
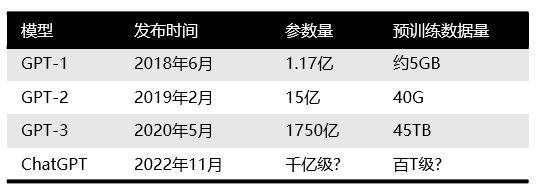
GPT家族主要模型對比
▌1.2 ChatGPT的主要特點
ChatGPT 是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架構開發的對話AI模型,是InstructGPT 的兄弟模型。 ChatGPT很可能是OpenAI 在GPT-4 正式推出之前的演練,或用于收集大量對話數據。
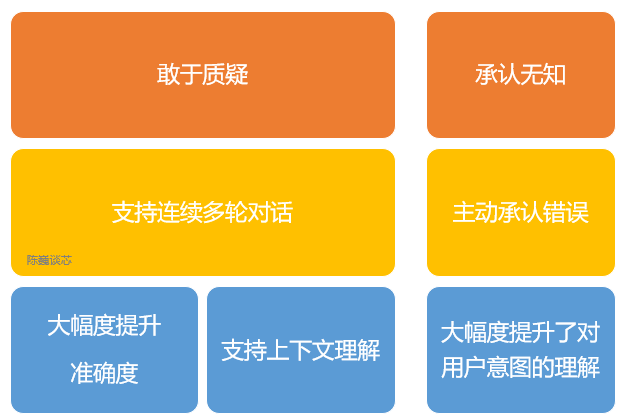
ChatGPT的主要特點
OpenAI使用 RLHF(Reinforcement Learning from Human Feedbac,人類反饋強化學習) 技術對 ChatGPT 進行了訓練,且加入了更多人工監督進行微調。 此外,ChatGPT 還具有以下特征: 1)可以主動承認自身錯誤。若用戶指出其錯誤,模型會聽取意見并優化答案。 2)ChatGPT 可以質疑不正確的問題。例如被詢問 “哥倫布 2015 年來到美國的情景” 的問題時,機器人會說明哥倫布不屬于這一時代并調整輸出結果。 3)ChatGPT 可以承認自身的無知,承認對專業技術的不了解。 4)支持連續多輪對話。 與大家在生活中用到的各類智能音箱和“人工智障“不同,ChatGPT在對話過程中會記憶先前使用者的對話訊息,即上下文理解,以回答某些假設性的問題。 ChatGPT可實現連續對話,極大的提升了對話交互模式下的用戶體驗。 對于準確翻譯來說(尤其是中文與人名音譯),ChatGPT離完美還有一段距離,不過在文字流暢度以及辨別特定人名來說,與其他網絡翻譯工具相近。 由于 ChatGPT是一個大型語言模型,目前還并不具備網絡搜索功能,因此它只能基于2021年所擁有的數據集進行回答。 例如它不知道2022年世界杯的情況,也不會像蘋果的Siri那樣回答今天天氣如何、或幫你搜索信息。如果ChatGPT能上網自己尋找學習語料和搜索知識,估計又會有更大的突破。 即便學習的知識有限,ChatGPT 還是能回答腦洞大開的人類的許多奇葩問題。為了避免ChatGPT染上惡習, ChatGPT 通過算法屏蔽,減少有害和欺騙性的訓練輸入。
查詢通過適度 API 進行過濾,并駁回潛在的種族主義或性別歧視提示。
二、ChatGPT/GPT的原理
▌2.1 NLP
NLP/NLU領域已知局限包括對重復文本、對高度專業的主題的誤解,以及對上下文短語的誤解。 對于人類或AI,通常需接受多年的訓練才能正常對話。 NLP類模型不僅要理解單詞的含義,還要理解如何造句和給出上下文有意義的回答,甚至使用合適的俚語和專業詞匯。
NLP技術的應用領域 本質上,作為ChatGPT基礎的GPT-3或GPT-3.5 是一個超大的統計語言模型或順序文本預測模型。
▌2.2 GPT v.s. BERT
與BERT模型類似,ChatGPT或GPT-3.5都是根據輸入語句,根據語言/語料概率來自動生成回答的每一個字(詞語)。 從數學或從機器學習的角度來看,語言模型是對詞語序列的概率相關性分布的建模,即利用已經說過的語句(語句可以視為數學中的向量)作為輸入條件,預測下一個時刻不同語句甚至語言集合出現的概率分布。 ChatGPT 使用來自人類反饋的強化學習進行訓練,這種方法通過人類干預來增強機器學習以獲得更好的效果。 在訓練過程中,人類訓練者扮演著用戶和人工智能助手的角色,并通過近端策略優化算法進行微調。 由于ChatGPT更強的性能和海量參數,它包含了更多的主題的數據,能夠處理更多小眾主題。 ChatGPT現在可以進一步處理回答問題、撰寫文章、文本摘要、語言翻譯和生成計算機代碼等任務。
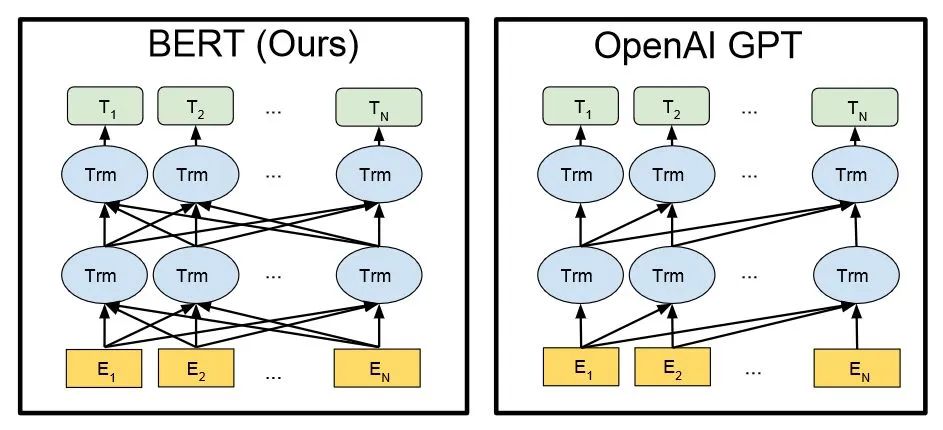
BERT與GPT的技術架構(圖中En為輸入的每個字,Tn為輸出回答的每個字) ?
三、ChatGPT的技術架構
▌3.1 GPT家族的演進
說到ChatGPT,就不得不提到GPT家族。 ChatGPT之前有幾個知名的兄弟,包括GPT-1、GPT-2和GPT-3。這幾個兄弟一個比一個個頭大,ChatGPT與GPT-3更為相近。
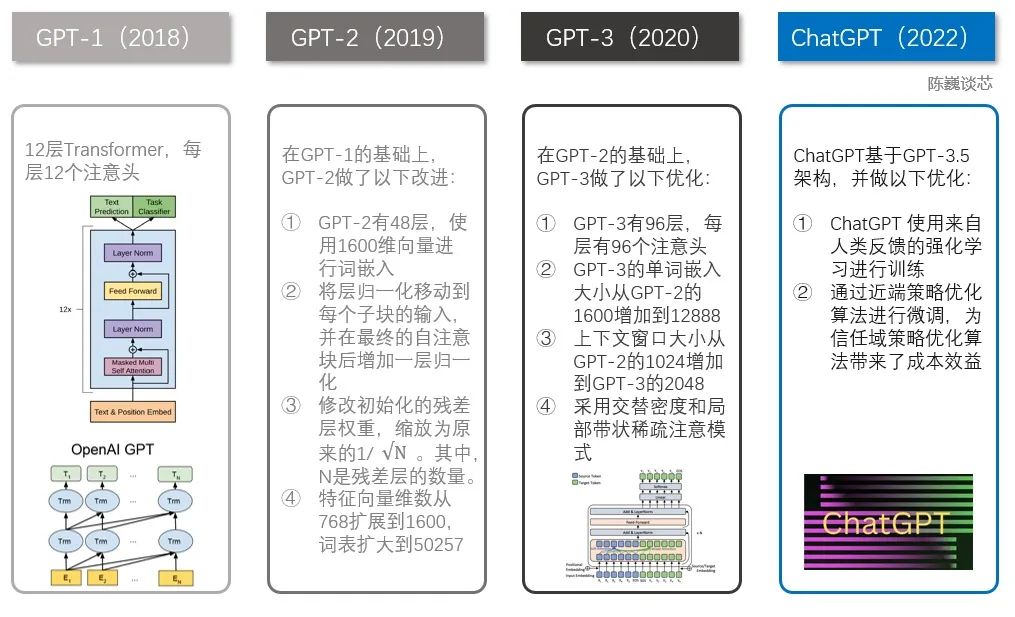
ChatGPT與GPT 1-3的技術對比
GPT家族與BERT模型都是知名的NLP模型,都基于Transformer技術。GPT-1只有12個Transformer層,而到了GPT-3,則增加到96層。
▌3.2 人類反饋強化學習
InstructGPT/GPT3.5(ChatGPT的前身)與GPT-3的主要區別在于,新加入了被稱為RLHF(Reinforcement Learning from Human Feedback,人類反饋強化學習)。 這一訓練范式增強了人類對模型輸出結果的調節,并且對結果進行了更具理解性的排序。 在InstructGPT中,以下是“goodness of sentences”的評價標準。
真實性:是虛假信息還是誤導性信息?
無害性:它是否對人或環境造成身體或精神上的傷害?
有用性:它是否解決了用戶的任務?
▌3.3 TAMER框架
這里不得不提到TAMER(Training an Agent Manually via Evaluative Reinforcement,評估式強化人工訓練代理)這個框架。 該框架將人類標記者引入到Agents的學習循環中,可以通過人類向Agents提供獎勵反饋(即指導Agents進行訓練),從而快速達到訓練任務目標。 引入人類標記者的主要目的是加快訓練速度。盡管強化學習技術在很多領域有突出表現,但是仍然存在著許多不足,例如訓練收斂速度慢,訓練成本高等特點。 特別是現實世界中,許多任務的探索成本或數據獲取成本很高。如何加快訓練效率,是如今強化學習任務待解決的重要問題之一。 而TAMER則可以將人類標記者的知識,以獎勵信反饋的形式訓練Agent,加快其快速收斂。 TAMER不需要標記者具有專業知識或編程技術,語料成本更低。通過TAMER+RL(強化學習),借助人類標記者的反饋,能夠增強從馬爾可夫決策過程?(MDP) 獎勵進行強化學習 (RL) 的過程。
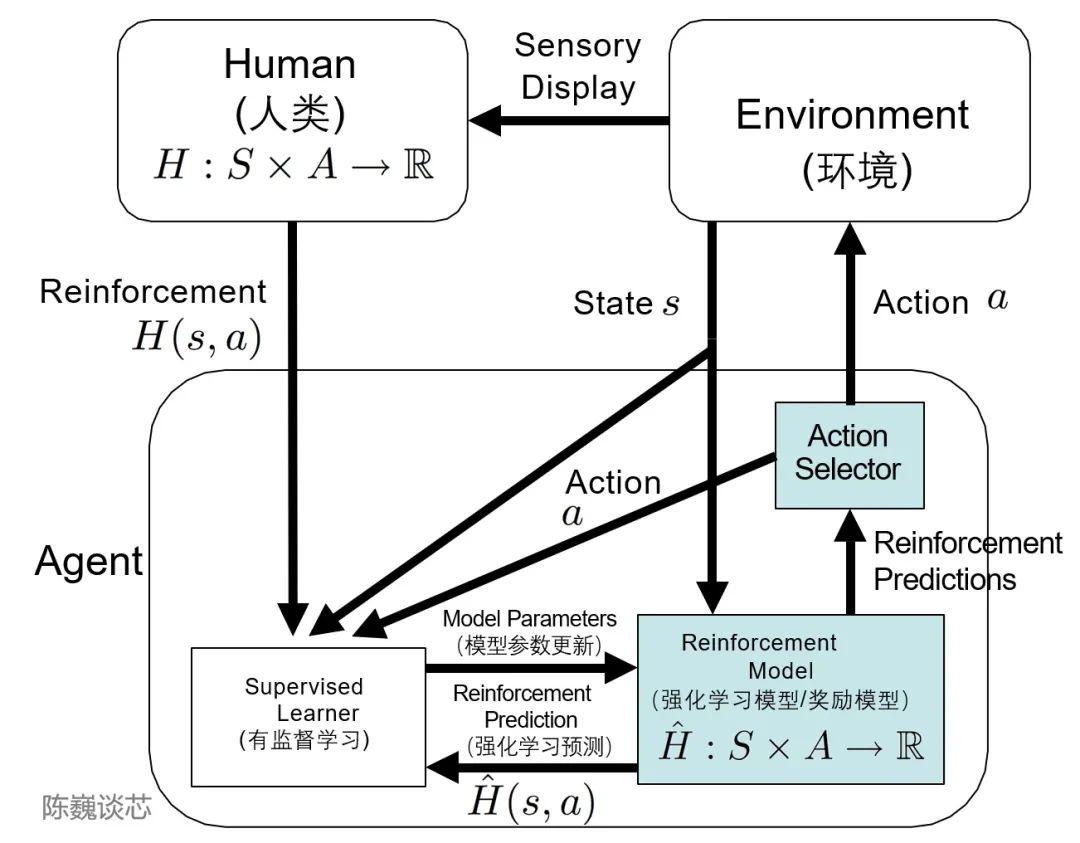
TAMER架構在強化學習中的應用 具體實現上,人類標記者扮演對話的用戶和人工智能助手,提供對話樣本,讓模型生成一些回復,然后標記者會對回復選項打分排名,將更好的結果反饋回模型中。 Agents同時從兩種反饋模式中學習——人類強化和馬爾可夫決策過程獎勵作為一個整合的系統,通過獎勵策略對模型進行微調并持續迭代。 在此基礎上,ChatGPT 可以比 GPT-3 更好的理解和完成人類語言或指令,模仿人類,提供連貫的有邏輯的文本信息的能力。
▌3.4 ChatGPT的訓練
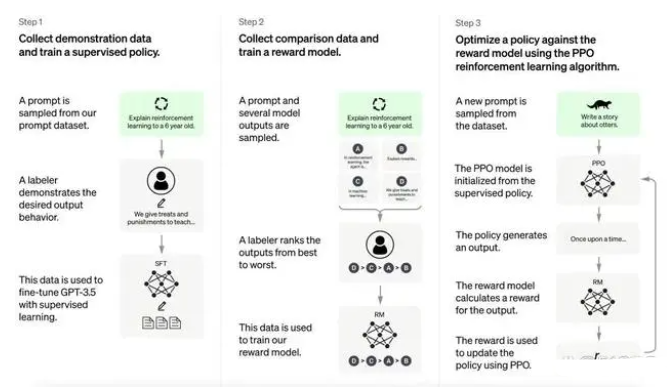
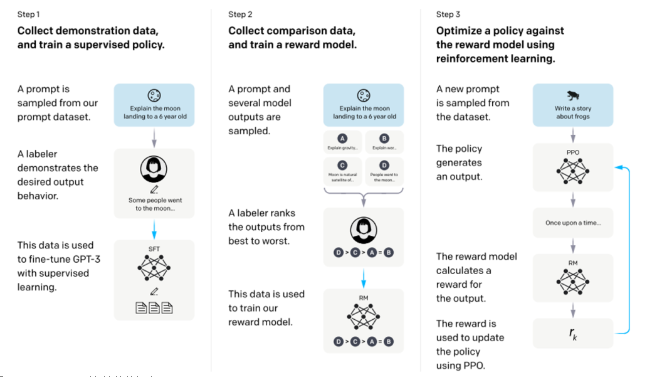
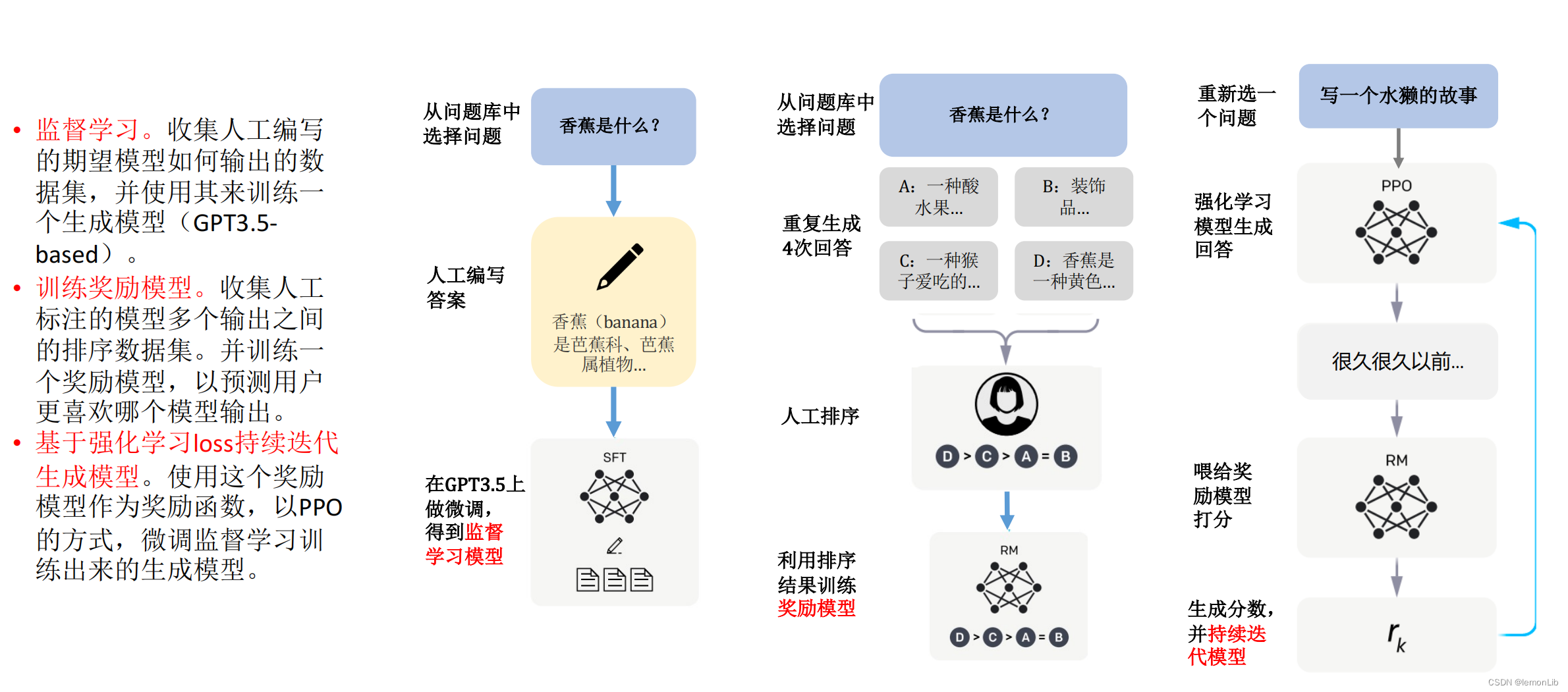
ChatGPT的訓練過程分為以下三個階段: 第一階段:訓練監督策略模型 GPT 3.5本身很難理解人類不同類型指令中蘊含的不同意圖,也很難判斷生成內容是否是高質量的結果。 為了讓GPT 3.5初步具備理解指令的意圖,首先會在數據集中隨機抽取問題,由人類標注人員,給出高質量答案,然后用這些人工標注好的數據來微調 GPT-3.5模型(獲得SFT模型, Supervised Fine-Tuning)。 此時的SFT模型在遵循指令/對話方面已經優于 GPT-3,但不一定符合人類偏好。
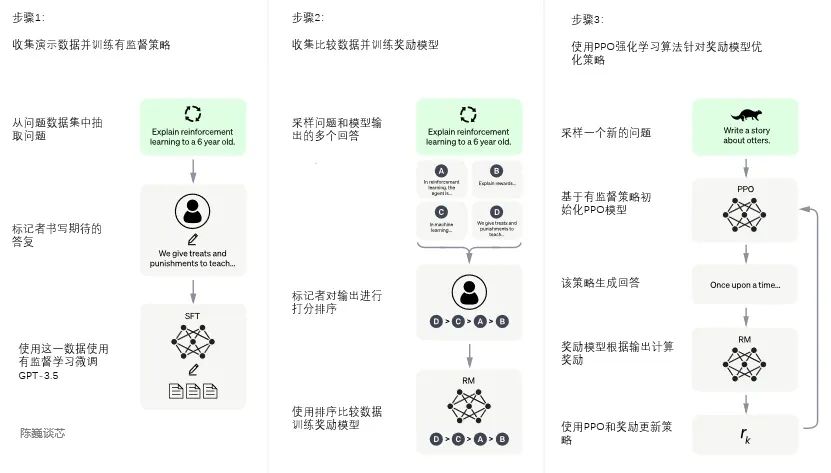
ChatGPT模型的訓練過程 第二階段:訓練獎勵模型(Reward Mode,RM) 這個階段的主要是通過人工標注訓練數據(約33K個數據),來訓練回報模型。 在數據集中隨機抽取問題,使用第一階段生成的模型,對于每個問題,生成多個不同的回答。人類標注者對這些結果綜合考慮給出排名順序。這一過程類似于教練或老師輔導。 接下來,使用這個排序結果數據來訓練獎勵模型。對多個排序結果,兩兩組合,形成多個訓練數據對。 RM模型接受一個輸入,給出評價回答質量的分數。這樣,對于一對訓練數據,調節參數使得高質量回答的打分比低質量的打分要高。 第三階段:采用PPO(Proximal Policy Optimization,近端策略優化)強化學習來優化策略。 PPO的核心思路在于將Policy Gradient中On-policy的訓練過程轉化為Off-policy,即將在線學習轉化為離線學習,這個轉化過程被稱之為Importance Sampling。 這一階段利用第二階段訓練好的獎勵模型,靠獎勵打分來更新預訓練模型參數。在數據集中隨機抽取問題,使用PPO模型生成回答,并用上一階段訓練好的RM模型給出質量分數。 把回報分數依次傳遞,由此產生策略梯度,通過強化學習的方式以更新PPO模型參數。
如果我們不斷重復第二和第三階段,通過迭代,會訓練出更高質量的ChatGPT模型。
四、ChatGPT的局限
只要用戶輸入問題,ChatGPT 就能給予回答,是否意味著我們不用再拿關鍵詞去喂 Google或百度,就能立即獲得想要的答案呢?
盡管ChatGPT表現出出色的上下文對話能力甚至編程能力,完成了大眾對人機對話機器人(ChatBot)從“人工智障”到“有趣”的印象改觀,我們也要看到,ChatGPT技術仍然有一些局限性,還在不斷的進步。 1)ChatGPT在其未經大量語料訓練的領域缺乏“人類常識”和引申能力,甚至會一本正經的“胡說八道”。ChatGPT在很多領域可以“創造答案”,但當用戶尋求正確答案時,ChatGPT也有可能給出有誤導的回答。例如讓ChatGPT做一道小學應用題,盡管它可以寫出一長串計算過程,但最后答案卻是錯誤的。
那我們是該相信ChatGPT的結果還是不相信呢?

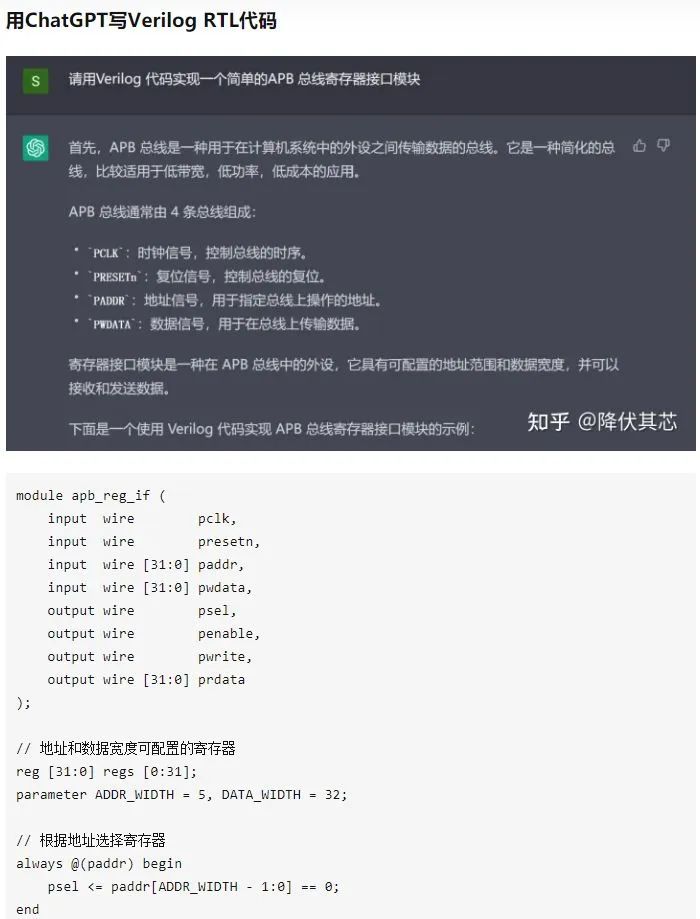
ChatGPT給出錯誤的數學題答案 2)ChatGPT無法處理復雜冗長或者特別專業的語言結構。對于來自金融、自然科學或醫學等非常專業領域的問題,如果沒有進行足夠的語料“喂食”,ChatGPT可能無法生成適當的回答。 3)ChatGPT需要非常大量的算力(芯片)來支持其訓練和部署。拋開需要大量語料數據訓練模型不說,在目前,ChatGPT在應用時仍然需要大算力的服務器支持,而這些服務器的成本是普通用戶無法承受的,即便數十億個參數的模型也需要驚人數量的計算資源才能運行和訓練。,如果面向真實搜索引擎的數以億記的用戶請求,如采取目前通行的免費策略,任何企業都難以承受這一成本。因此對于普通大眾來說,還需等待更輕量型的模型或更高性價比的算力平臺。 4)ChatGPT還沒法在線的把新知識納入其中,而出現一些新知識就去重新預訓練GPT模型也是不現實的,無論是訓練時間或訓練成本,都是普通訓練者難以接受的。如果對于新知識采取在線訓練的模式,看上去可行且語料成本相對較低,但是很容易由于新數據的引入而導致對原有知識的災難性遺忘的問題。 5)ChatGPT仍然是黑盒模型。目前還未能對ChatGPT的內在算法邏輯進行分解,因此并不能保證ChatGPT不會產生攻擊甚至傷害用戶的表述。 當然,瑕不掩瑜,有工程師貼出了要求ChatGPT寫verilog代碼(芯片設計代碼)的對話。可以看出ChatGPT水平已經超出一些verilog初學者了。
五、ChatGPT的未來改進方向
▌5.1 減少人類反饋的RLAIF
2020年底,OpenAI前研究副總裁Dario Amodei帶著10名員工創辦了一個人工智能公司Anthropic。 Anthropic 的創始團隊成員,大多為 OpenAI 的早期及核心員工,參與過OpenAI的GPT-3、多模態神經元、人類偏好的強化學習等。 2022年12月,Anthropic再次發表論文《Constitutional AI: Harmlessness from AI Feedback》介紹人工智能模型Claude。(arxiv.org/pdf/2212.0807)
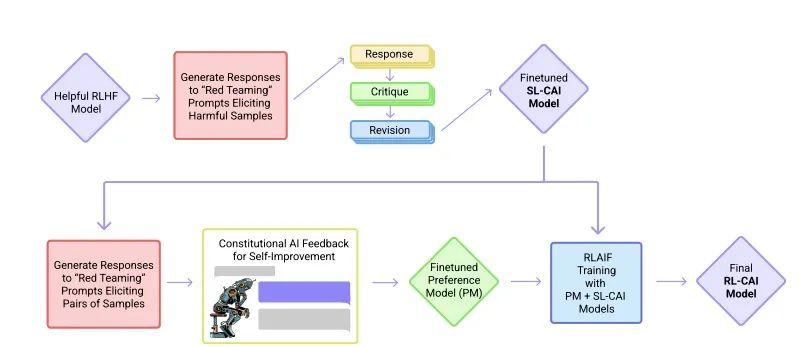
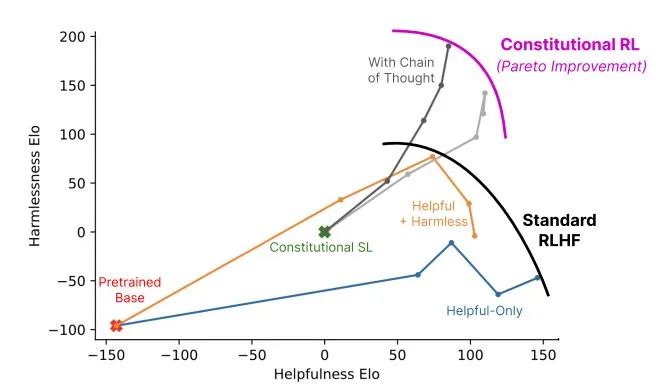
CAI模型訓練過程 Claude 和 ChatGPT 都依賴于強化學習(RL)來訓練偏好(preference)模型。CAI(Constitutional AI)也是建立在RLHF的基礎之上,不同之處在于,CAI的排序過程使用模型(而非人類)對所有生成的輸出結果提供一個初始排序結果。 CAI用人工智能反饋來代替人類對表達無害性的偏好,即RLAIF,人工智能根據一套constitution原則來評價回復內容。
▌5.2 補足數理短板
ChatGPT雖然對話能力強,但是在數理計算對話中容易出現一本正經胡說八道的情況。 計算機學家Stephen Wolfram 為這一問題提出了解決方案。Stephen Wolfram 創造了的 Wolfram 語言和計算知識搜索引擎 Wolfram | Alpha,其后臺通過Mathematica實現。
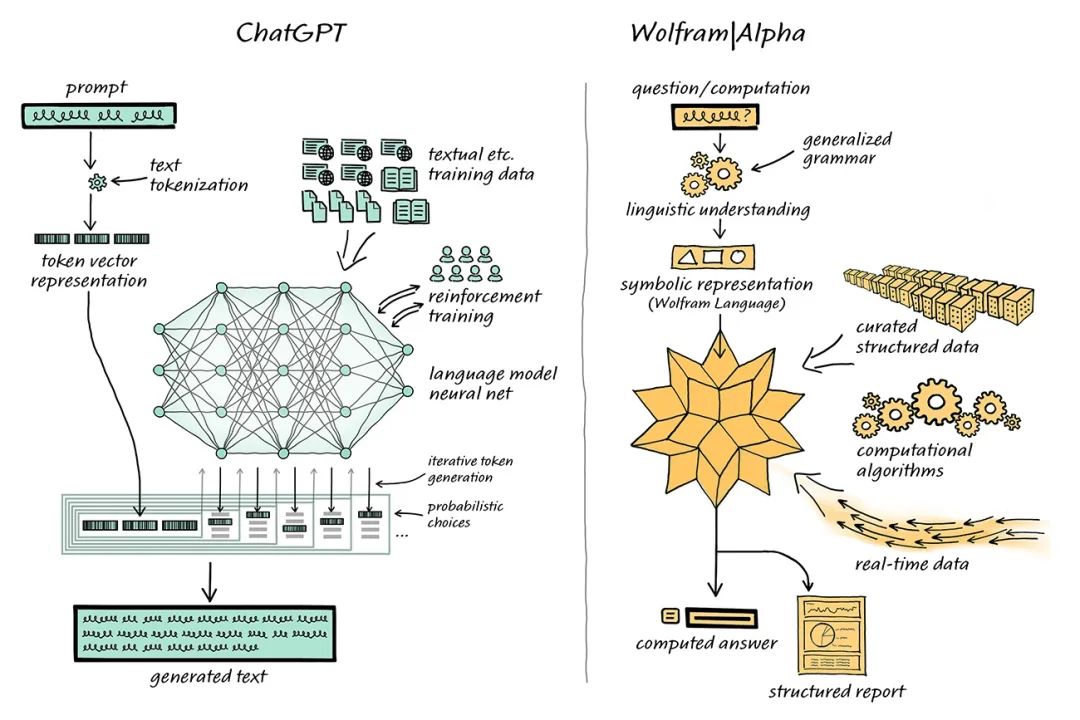
ChatGPT與Wolfram | Alpha結合處理梳理問題 在這一結合體系中,ChatGPT 可以像人類使用 Wolfram|Alpha 一樣,與 Wolfram|Alpha “對話”,Wolfram|Alpha 則會用其符號翻譯能力將從 ChatGPT 獲得的自然語言表達“翻譯”為對應的符號化計算語言。 在過去,學術界在 ChatGPT 使用的這類 “統計方法” 和 Wolfram|Alpha 的 “符號方法” 上一直存在路線分歧。 但如今 ChatGPT 和 Wolfram|Alpha 的互補,給NLP領域提供了更上一層樓的可能。 ChatGPT 不必生成這樣的代碼,只需生成常規自然語言,然后使用 Wolfram|Alpha 翻譯成精確的 Wolfram Language,再由底層的Mathematica進行計算。
▌5.3 ChatGPT的小型化
雖然ChatGPT很強大,但其模型大小和使用成本也讓很多人望而卻步。 有三類模型壓縮(model compression)可以降低模型的大小和成本。 第一種方法是量化(quantization),即降低單個權重的數值表示的精度。比如Tansformer從FP32降到INT8對其精度影響不大。 第二種模型壓縮方法是剪枝(pruning),即刪除網絡元素,包括從單個權重(非結構化剪枝)到更高粒度的組件如權重矩陣的通道。這種方法在視覺和較小規模的語言模型中有效。 第三種模型壓縮方法是稀疏化。例如奧地利科學技術研究所 (ISTA)提出的SparseGPT (arxiv.org/pdf/2301.0077)可以將 GPT 系列模型單次剪枝到 50% 的稀疏性,而無需任何重新訓練。對 GPT-175B 模型,只需要使用單個 GPU 在幾個小時內就能實現這種剪枝。
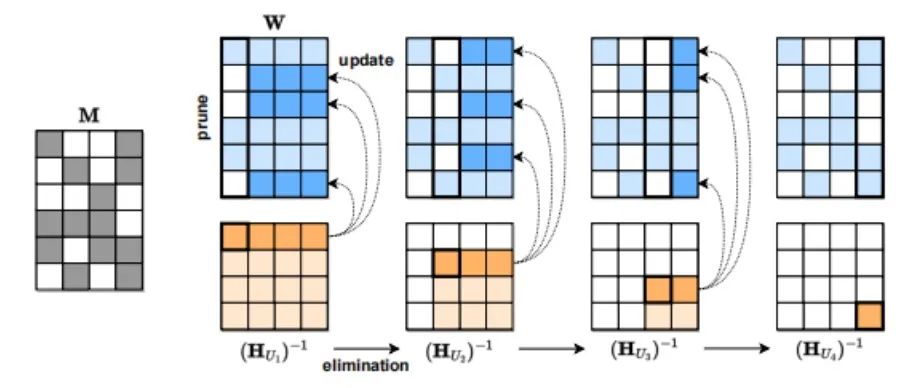
SparseGPT 壓縮流程
六、ChatGPT的產業未來與投資機會
▌6.1 AIGC
說到ChaGPT不得不提AIGC。 AIGC即利用人工智能技術來生成內容。與此前Web1.0、Web2.0時代的UGC(用戶生產內容)和PGC(專業生產內容)相比,代表人工智能構思內容的AIGC,是新一輪內容生產方式變革,而且AIGC內容在Web3.0時代也將出現指數級增長。 ChatGPT 模型的出現對于文字/語音模態的 AIGC 應用具有重要意義,會對AI產業上下游產生重大影響。
▌6.2 受益場景
從下游相關受益應用來看,包括但不限于無代碼編程、小說生成、對話類搜索引擎、語音陪伴、語音工作助手、對話虛擬人、人工智能客服、機器翻譯、芯片設計等。
從上游增加需求來看,包括算力芯片、數據標注、自然語言處理(NLP)等。
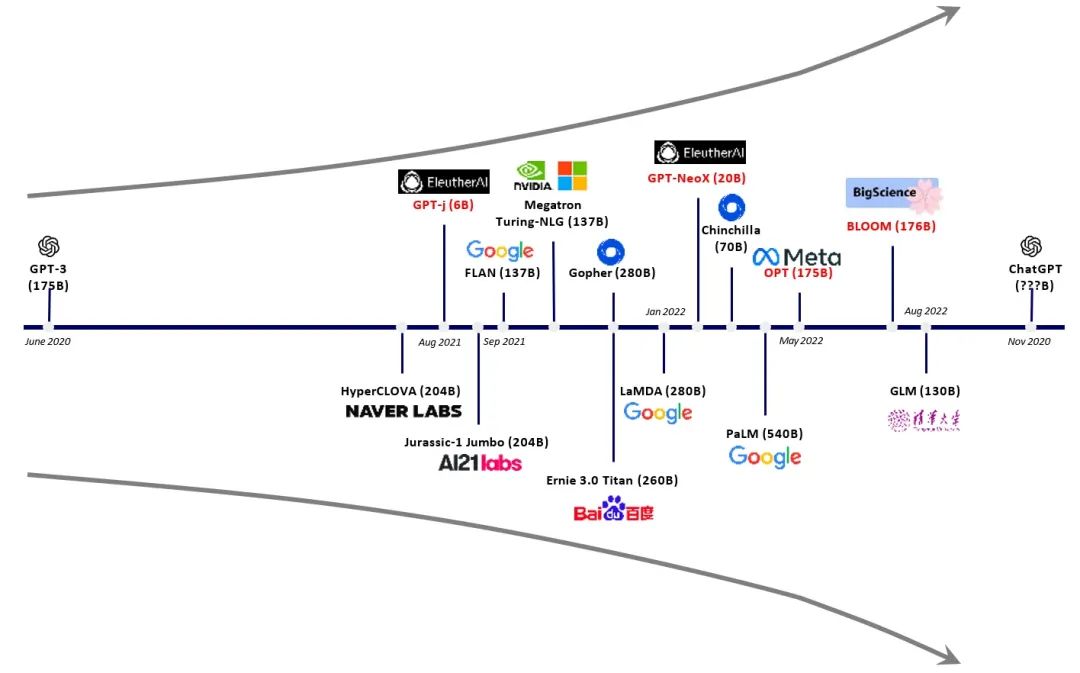
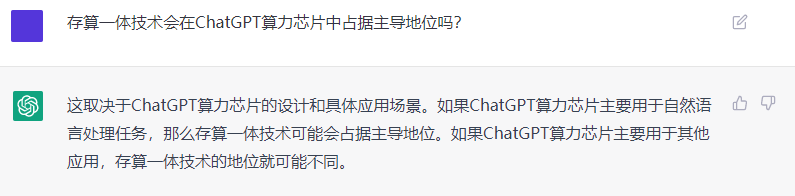
大模型呈爆發態勢(更多的參數/更大的算力芯片需求) 隨著算法技術和算力技術的不斷進步,ChatGPT也會進一步走向更先進功能更強的版本,在越來越多的領域進行應用,為人類生成更多更美好的對話和內容。 最后,作者問存算一體技術在ChatGPT領域的地位(作者本人目前在重點推進存算一體芯片的產品落地),ChatGPT想了想,大膽的預言存算一體技術將在ChatGPT芯片中占據主導地位。(深得我心 )
)
? 參考文獻:
ChatGPT: Optimizing Language Models for Dialogue?ChatGPT: Optimizing Language Models for Dialogue
GPT論文:Language Models are Few-Shot Learners Language Models are Few-Shot Learners
InstructGPT論文:Training language models to follow instructions with human feedback Training language models to follow instructions with human feedback
huggingface解讀RHLF算法:Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
RHLF算法論文:Augmenting Reinforcement Learning with Human Feedback cs.utexas.edu/~ai-lab/p
TAMER框架論文:Interactively Shaping Agents via Human Reinforcement cs.utexas.edu/~bradknox
PPO算法:Proximal Policy Optimization Algorithms Proximal Policy Optimization Algorithms
編輯:黃飛
?














 工商網監
工商網監
評論