電子發燒友網報道(文/李彎彎)在深度學習中,經常聽到一個詞“模型訓練”,但是模型是什么?又是怎么訓練的?在人工智能中,面對大量的數據,要在雜亂無章的內容中,準確、容易地識別,輸出需要的圖像/語音
2022-10-23 00:19:00 24277
24277 發布類ChatGPT應用。 眾所周知,類ChatGPT應用是一個吞金獸,微軟公司為了訓練ChatGPT使用了1萬張英偉達的高端GPU。“從訓練的角度來看,計算性能再好的GPU芯片比如A100如果無法集群在一起去訓練,那么訓練一個類ChatGPT的大模型可能需要上百年。因此,AI大模型
2023-03-06 09:18:521585 隨著預訓練語言模型(PLMs)的不斷發展,各種NLP任務設置上都取得了不俗的性能。盡管PLMs可以從大量語料庫中學習一定的知識,但仍舊存在很多問題,如知識量有限、受訓練數據長尾分布影響魯棒性不好
2022-04-02 17:21:438765 CAI模型訓練過程 Claude 和 ChatGPT 都依賴于強化學習(RL)來訓練偏好(preference)模型。CAI(Constitutional AI)也是建立在RLHF的基礎之上,不同之處在于,CAI的排序過程使用模型(而非人類)對所有生成的輸出結果提供一個初始排序結果。
2023-02-16 14:16:583427 NLP領域的研究目前由像RoBERTa等經過數十億個字符的語料經過預訓練的模型匯主導。那么對于一個預訓練模型,對于不同量級下的預訓練數據能夠提取到的知識和能力有何不同?
2023-03-03 11:21:511339 Segment Anything Model (SAM)是Meta 公司最近推出的一個創新AI 模型,專門用于計算機視覺領域圖像分割任務。借鑒ChatGPT 的學習范式,將預訓練和特定任務結合
2023-08-21 04:02:501293 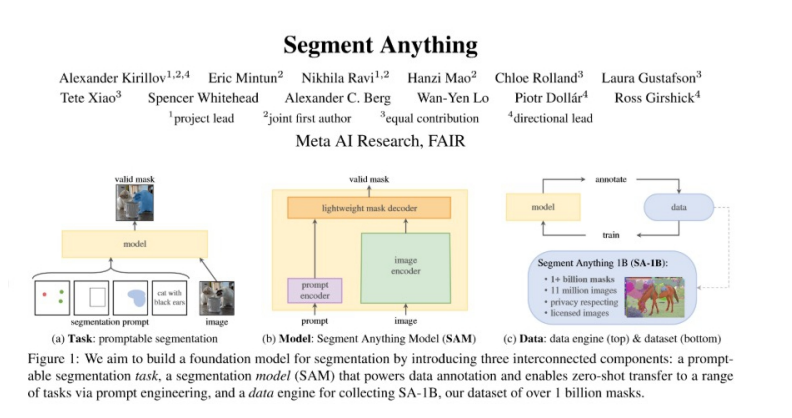
ChatGPT已經成為家喻戶曉的名字,而大語言模型在ChatGPT刺激下也得到了快速發展,這使得我們可以基于這些技術來改進我們的業務。
2023-12-06 17:02:27719 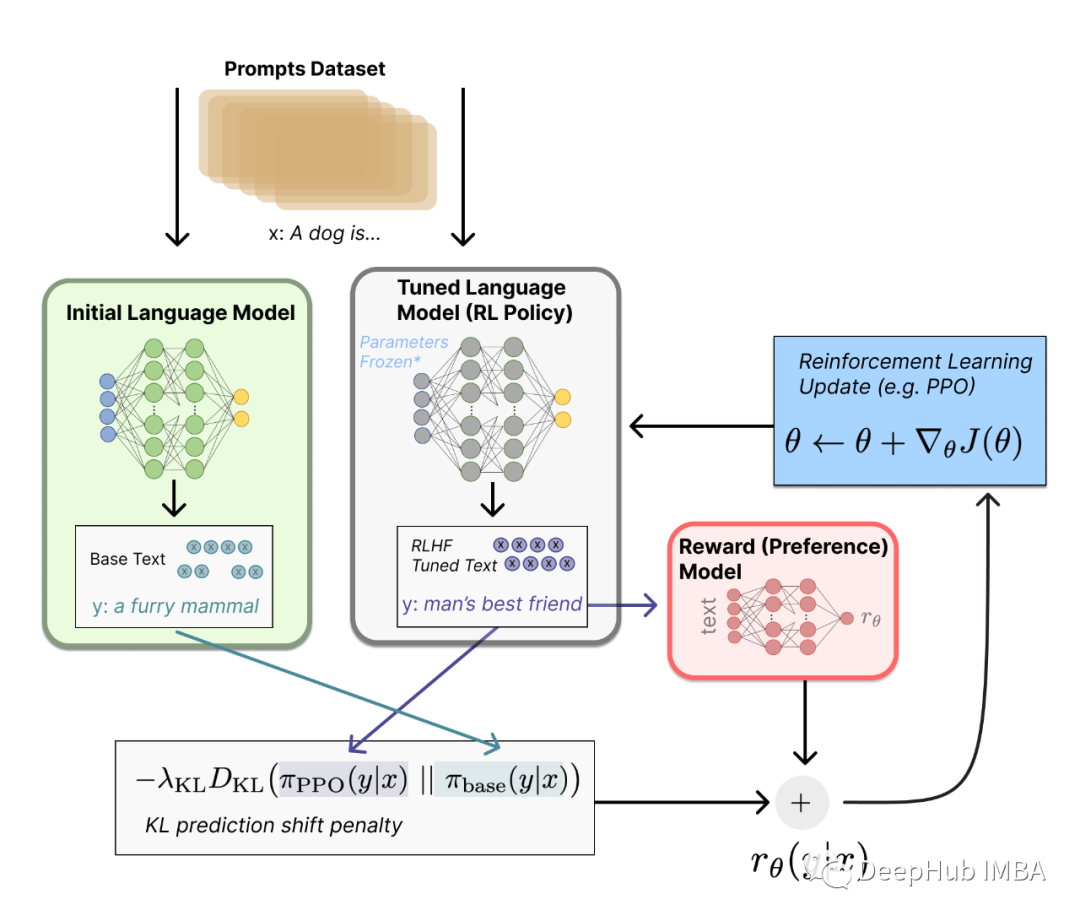
,有沒有可能做出下一個ChatGPT?以及打造這樣一個模型所需的研發成本和運營成本究竟是多少。 ? C hatGPT 背后的成本,以及 GPU 廠商等候多時的增長點 ? 首先,ChatGPT是OpenAI預訓練的對話模型,除去訓練本身所需的硬件與時間成本外,運營時的推理成本也要算
2023-02-15 01:19:004129 電子發燒友網報道(文/李彎彎)最近,在ChatGPT火了之后,國內互聯網科技圈不時傳出計劃或者正在研究類ChatGPT大模型的消息。 ? 然而在相關技術真正面世之前,近日,OpenAI又放
2023-03-07 09:15:151716 。ChatGPT是一個由OpenAI開發的人工智能語言模型,可以實現自然語言處理、對話生成等功能。要開發一個類似ChatGPT的人工智能系統軟件,可以遵循以下步驟:確定應用場景:確定人工智能系統軟件要
2023-05-18 10:16:50
主要表現為三個方面:一是代替創作中的重復環節,提升創作效率;二是將創意與創作相分離,內容創作者可以從人工智能的生成作品中找尋靈感與思路;三是綜合海量預訓練的數據和模型中引入的隨機性,有利于拓展創新
2023-04-25 16:04:09
訓練好的ai模型導入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
2023-08-04 09:16:28
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-23 14:38:58
本教程以實際應用、工程開發為目的,著重介紹模型訓練過程中遇到的實際問題和方法。在機器學習模型開發中,主要涉及三大部分,分別是數據、模型和損失函數及優化器。本文也按順序的依次介紹數據、模型和損失函數
2018-12-21 09:18:02
能否直接調用訓練好的模型文件?
2021-06-22 14:51:03
準備開始為家貓做模型訓練檢測,要去官網https://maix.sipeed.com/home 注冊帳號,文章尾部的視頻是官方的,與目前網站略有出路,說明訓練網站的功能更新得很快。其實整個的過程
2022-06-26 21:19:40
TOP1的桂冠,可想大家對本書的認可和支持!
這本書為什么如此受歡迎?它究竟講了什么?下面就給大家詳細~~
本書主要內容
本書圍繞大語言模型構建的四個主要階段——預訓練、有監督微調、獎勵建模和強化
2024-03-11 15:16:39
方面。而且,由于ChatGPT 4是一個大型的語言模型。通常,FPGA會用于處理一些底層的數據流或執行特定的硬件加速任務,而ChatGPT 4這樣的模型則會在云端或高性能服務器上運行。不過
2024-02-14 21:58:43
一個對于足球的狂熱者的成長史。我們每一個人都不平凡,都有著自己的夢想。你之所以沒有達到你預期的目標可能是因為,"天時“不夠或者”地利“沒達到,更可能是”人脈“沒掌握。更有可能是你壓根
2014-05-06 13:52:52
據美國研究公司ICInsights發布報告預計,銷售額顯示,三星電子有很大可能性,超過英特爾成為全球最大的芯片商。 油柑網利用WMS物流系統在高準確率、優化倉儲空間、提高人工效率等方面的特點,為用戶提供極速發貨體驗:當天16:00前訂單當天發出,16:00后訂單最遲次日12:00前發出。油柑網全場電子元器件訂單單筆實付金額滿8.8元包郵。 ICInsights表示,考慮到存儲芯片價格漲幅這一因素的話,英特爾預計在2017年二季度將實現144億美元的銷售額,而三星電子的銷售額預計將達到146億美元。因此如果存儲芯片的市場價格在二季度及余下時間里都能持續增長,三星電子將會取代英特爾成為全球最大芯片制造商。 獨占半壁江山 但跟核心處理器芯片不同的是,三星的增長是受益于不斷漲價的存儲芯片。數據顯示,英特爾預計在2017年二季度將實現144億美元的銷售額,而三星電子的銷售額預計將達到146億美元,如果未來存儲芯片價格依舊居高不下,三星將會取代英特爾成為全球最大的芯片制造商。 換句話說,在手機領域的存儲元器件方面,三星一家幾乎占據了半壁江山。即便在去年因為手機電池爆炸事件遭受重裝,但由于日益高昂的存儲芯片,三星的賺錢能力竟毫發無損。 三星在2017年第一財年報告顯示,受到芯片業務強勁表現的提振,三星第一季度凈利潤達到7.68萬億韓元(約合67.8億美元),同比增長46.3%。 而具體到半導體部門,銷售額為15.66萬億韓元(約合138.25億美元),較上年同期的11.15萬億韓元增長40.4%;營業利潤為6.31萬億韓元(約合55.70億美元),較上年同期的2.63萬億韓元更是增長了恐怖的139.9%。 但是三星在40多年前進軍芯片行業時并非一帆風順。 白手起家的三星電子 三星電子是韓國最大的電子工業企業,同時也是三星集團旗下最大的子公司。1938年3月它于韓國大邱成立,創始人是李秉喆。現任會長是李健熙,副會長是李在镕和權五鉉,社長是崔志成,首席執行官是由權五鉉、申宗鈞、尹富根三位組成的聯席CEO。在世界上最有名的100個商標的列表中,三星電子是唯一的一個韓國商標,是韓國民族工業的象征。 李秉喆出生富裕家庭,貪玩但聰明,入讀日本早稻田大學。 1936年,與朋友合開碾米合作廠(協同精米所),不久失敗。 1938年,3萬韓元創立三星商會,主要出口干貨、蔬菜、水果到中國東北地區。 1948年,成立三星物產公司,增加經營品種,擴大貿易地區。 1953年,他建立了“第一制糖”廠,結束韓國白糖依賴進口的歷史。 1954年成立了“第一毛織”,滿足國內需求。 1960年,進軍肥料工業,籌建肥料廠。 1969年,把握趨勢進軍電子行業,“三星三洋電子公司”成立,開始生產電視機。之后與三星電子工業有限公司合并。主要是為日本三洋公司生產電視機、洗衣機、冰箱等電子。之所以會發展電子業,是因為李秉喆根據當時韓國的技術、勞動力、附加值、出口預期等多方面判斷電子業將是一條康莊大道。 1984年,三星電子工業公司更名為三星電子。 在更名之前,1976年,三星電子機械公司累計生產一千萬臺黑白電視機。 1978年,三星電子工業累計生產破四千萬臺黑白電視。 1979年,三星電子工業開始生產微波爐。 1980年,三星電子工業開始生產空調。 1981年,生產破一千萬臺彩色電視機。 三星能成為世界一流企業最關鍵的是李秉喆提出“走開發尖端科技”路線,之后三星投入巨資發展尖端科技,還引進美國技術,使韓國成為了繼美國、日本之后,第三個能獨立開發半導體的國家,這也是如今三星和蘋果能夠抗衡的資本。 把握趨勢進軍電子行業 在韓國,有句話流傳甚廣:“韓國人的一生無法避免三件事,死亡、稅收和三星。”這真是一件極恐怖的事! 雖然三星集團業務涉及各大領域,但從總的來看三星電子的收入大概占了集團的六成左右,其實主要還是以電子產業為主,這要歸功于當年李秉喆的眼光。 李秉喆是個十分會洞悉市場需求的人,用我們現在的話來說就是很會抓風口的人,每當經濟轉型,產業升級的時候他都能立即把握住趨勢。 七十年代晚期到八十年代初期,是多元化程度逐步提高,三星核心科技業務在全球范圍內增長的階段。 1978年,三星半導體以及三星電子成為兩個獨立的實體,同時也開始向全球市場提供新產品。 在1983年12月成功開發出64KDRAM(動態隨機存儲器,DynamicRandomAccessMemory)VLSI芯片,并因此成為世界半導體產品領導者。在此之前,三星只是為本國市場生產半導體。 在八十年代中期,三星開始進入系統開發業務領域,在1985年成立了三星數據系統(現在的名稱為三星SDS)作為在包括系統集成、系統管理、咨詢,以及網絡服務的信息技術服務的領導者。 在1986年成立的三星經濟研究院(SERI),以及在1987年成立的三星綜合技術研究院(SAIT)。這兩個作為先驅的R&D組織,成功地幫助三星將其業務甚至進一步擴大到電子、半導體、高分子化學、基因工程、光纖通訊、航空,以及從納米技術到先進的網絡結構等廣闊的領域。 在1987年11月19日,三星的創始人李秉喆會長在執掌三星集團近50年之后逝世。他的兒子李健熙繼任成為三星新的會長。在1988年三星集團慶祝公司成立50周年的慶典上,他宣布公司開始“二次創業”,將領導三星進一步發展,成為世界級的二十一世紀企業。 為了“二次創業”,三星挑戰自己,重組了舊的業務,并開始進入新的業務領域,目標是成為世界五大電子公司之一。1988年,三星電子與三星半導體&無線通訊的合并無疑是向這個目標前進的一個關鍵。因為在公司的歷史上,這是第一次,三星那時走上了最大化技術資源、開發增值產品之路。 重疊項目的綜合節約了成本,并有效地運用資金與人力。到八十年代后半葉,三星在創建穩固電子與重工業的努力終于有了回報,公司獲得了與高技術產品相匹配的聲譽。 三星電子邁上世界舞臺 二十世紀九十年代初期,高技術產業面臨著前所未有的巨大挑戰。兼并、聯合以及收購等商業行為非常普遍,競爭與合并風起云涌。各個公司都不得不重新思考自己的技術與服務的定位。業務開始跨出國家與國家、公司與公司之間的界限。為了把握這些機會,三星在1993年提出來“新經營”規劃。 “新經營”不僅僅是三星業務結構的重新設計,而是一場旨在制造世界一流產品、提供全體客戶滿意,以及成為一個優秀的企業公民的全面革新運動。回顧過去,“新經營”是三星發展過程中決定性的轉折點,是整個公司以“質量第一”為基礎重新進行定位的階段。 在此期間,17種不同的產品,從半導體到計算機顯示器,從TFT-LCD顯示屏到彩色顯像管,在其各自領域中,產品的全球市場份額躍居前五位。12種其他產品也在其各自領域中名列前茅。在一些領域,比如LCD等,三星從一開始就是第一。 自從1993年進入LCD以來,三星就毫無爭議地是世界領導者。另外一個實例是三星重工業的鉆井船,自從三星開始進入這個領域,就擁有了世界市場60%的份額。 毫無疑問,三星在這些領域的成功,一部分歸功于三星在其遍布世界的工廠中嚴格的質量控制。 由于實行“一站停線(LineStop)”系統,任何員工只要在生產流程中發現不合格產品,都可以立即關閉組裝生產線。整個生產線會被停下來,直到問題得以解決。在總體質量管理過程中,三星還堅持采用“六西格瑪(SixSigma)”方法。 當然,“新經營”不僅僅是為了獲得優質產品,同時也是為了獲得優秀的人才。無論三星的業務開展到世界的什么地方,三星人力開發院就會專門為所有直接與客戶接觸的人員提供客戶服務的講座。三星旗下位于首爾市中心的世界級酒店——新羅飯店甚至還為三星生命保險、三星證券和三星信用卡等公司的雇員提供禮儀培訓課程。 劫后重生的三星電子 1997對于幾乎所有的韓國人來說都是黑暗的。在那一年,幾乎所有的韓國公司都處于萎縮狀態,三星也不例外。公司通過將下屬公司的數量減少到45個(附屬公司數量的標準根據“公平貿易法”(FairTradeLaw)確定),幾乎裁減了50,000人,改善了公司財務結構的合理性,使公司的負債率從1997年的365%降低到1999年的148%。 公司以15億美元的價格將公司原有的10個業務單位賣給了國外公司,包括三星重工業旗下深受好評的施工設備業務賣給了瑞典的VolvoAB,將叉車業務賣給了Clark。 雖然這個消息令人感到凄涼,但是由于其在數字以及網絡技術方面的領先地位,及其在電子、金融,以及其他相關服務方面的穩定與專注,使三星成為為數不多的幾個能夠在經濟危機后繼續增長的公司之一。 1998年2月三星電子開發出世界第一個128MB同步DRAM以及128MBFlash內存。 7月三星電子開發出世界最小的半導體封裝。同年,三星電子成為世界第一個擁有4-GB半導體處理生產技術的廠商 1999年7月三星電子世界第一個1GDDRDRAM芯片實現商業化,并引入世界最快的3DGraphics圖形卡專用222MHz32-MbitSGRAM。 2001年,三星電子移動電話生產量超過5千萬臺,并開發出世界最大的40英寸TFT-LCD顯示器。 2001年,三星電子銷售額達到247億美元,創利潤22億美元。在存儲器芯片和超薄顯示器市場都是世界第一,并且已經穩居全球第四大手機生產商位置,三星開始領軍全球電子業。 2007年,開發出了世界第一款30nm64GbNANDFlash內存。 2010年,三星電子開發出世界上第一個30nmDRAM,銷售業績創歷史新高——總銷售額100萬億韓元和營業利潤10億韓元同時突破。 時至今日,三星電子已經發展成為全世界最大的消費電子企業,除了消費者熟知的智能手機、電視機之外,三星還擁有半導體、顯示面板在內的零部件業務。今年二季度,三星電子將超越英特爾,成為全球半導體市場的營收霸主。 負面不斷,卻觸底反彈 “炸機”和高層賄賂事件曝光后,世人都認為三星要完蛋了。8月,三星股價下跌3.2%至110.4萬韓元,創下自前年10月28日以來新低。可三星電子股價在經歷了連續3個月劇烈震蕩后,于11月中旬開始,奇跡般觸底反彈,大漲20%,到12月,股價多次超過180萬韓元,創下自上市以來的新高。 一般而言,在手機元器件的分類中,存儲的元器件包括了內存和閃存,內存即大眾所理解的DRAM,而包括eMMC、UFS都是閃存(NANDFlash)加上控制器的套件,這個解決方案也廣泛應用了當下的手機行業。 根據調研機構trendforce的數據,目前三星內存(DRAM)整體市場份額超過50%,應用在智能手機的內存更是超過60%,eMMC、UFS所屬于的閃存(NANDFlash)方面,三星的市場份額接近40%。 就市場情況而言,目前可以生產eMMC型號閃存的廠商很多,但能夠生產UFS卻只有三星、東芝、SK海力士三家,而在具體的量產能力上,三星比起其他兩家公司來說更勝一籌。 在主流的高端手機上,也會有更多廠商選會選擇UFS,因此可以說國產手機在存儲芯片方面對三星處于絕對依賴的狀態。 價格趨勢方面,trendforce的分析師對36氪記者說,存儲器產品從2016年下半年開始一直呈現大幅上漲狀態了40%,持續到今年一季度,從二季度開始上漲趨勢減緩,但是上漲勢頭還會持續到年底,預計應用于智能手機等產品的行動式內存2017年全年漲幅將大于10%。 而反映到智能手機產品上,今年以來,包括小米、酷派、魅族等手機公司都有不同程度的漲價,而華為發布的P10更是比上一代產品P9,貴了將近1000元。 所以,雖然三星在2016年遭遇了“Note7爆炸事件”,但其股價在2016年仍然大漲了接近50%。進入2017年,短短的四個來月,股價又上漲了25%。 學習三星,中國芯片任重而道遠 目前,全球芯片生產商主要集中在美國、日本、韓國和中國的***地區。 相比之下,中國內地雖然是全球最大的電子消費市場,每年生產銷售了最大量的手機、電腦、汽車和各種家電,但芯片90%依靠進口。雖然也有部分企業(比如華為)力圖在芯片上實現突破,但取得的進展一直不大。 全球每年生產的芯片,50%左右被中國人高價買走。這意味著,中國電子產業仍然處于全球生產鏈條的中低端,還意味著最豐厚的利潤被芯片生產商拿走了。而中國市場,則淪為了三星、英特爾、高通這些企業的提款機。 你知道中國目前每年進口金額最大的單一商品是什么嗎?估計很多人還以為是石油,事實上過去幾年芯片已經超過石油,成為我們從海外購買最多的商品,每年進口額超過2200億美元。換句話說,中國的“芯片安全問題”,已經超過了“石油安全問題”。 “薩德入韓”事件后,中韓經貿關系受到了影響。這時候,很多中國人才驚聞:中國最大的商品進口國竟然是韓國,每年中國從韓國的進口額超過了美國、日本;中國最大的貿易逆差,也是韓國帶來的,相當于韓國順差來源的73%。 2016年全球主要芯片企業排名,中國只有***地區的企業上榜 很顯然,芯片已經成為中國經濟崛起過程中,下一個急需攻克的陣地。而三星,就是我們實現跨越的最大對手。我們不能為手機在中低端市場擊敗三星而沾沾自喜,而應該清醒地看到三星在芯片業務上的強大優勢。 主要來說,中國企業應當學習三星“兩頭抓”的戰略。
2019-04-24 17:17:53
這個說法并不準確。盡管ChatGPT等語言模型已經在一定程度上改變了我們獲取信息、學習知識的方式,但它們并不能替代人類進行創造性思考和創造性活動。
雖然一些人可能會利用ChatGPT等語言模型快速
2023-11-19 12:06:10
醫療模型人訓練系統是為滿足廣大醫學生的需要而設計的。我國現代醫療模擬技術的發展處于剛剛起步階段,大部分仿真系統產品都源于國外,雖然對于模擬人仿真已經出現一些產品,但那些產品只是就模擬人的某一部分,某一個功能實現的仿真,沒有一個完整的系統綜合其所有功能。
2019-08-19 08:32:45
技術改變生活。最近一段時間,OpenAI旗下的ChatGPT大火。根據官網自身的介紹(見圖1),其是由 OpenAI 提出的大型預訓練語言模型,使用了許多深度學習技術,可以生成文本內容,也可以進行
2023-02-21 15:16:46
問題最近在Ubuntu上使用Nvidia GPU訓練模型的時候,沒有問題,過一會再訓練出現非常卡頓,使用nvidia-smi查看發現,顯示GPU的風扇和電源報錯:解決方案自動風扇控制在nvidia
2022-01-03 08:24:09
CV:基于Keras利用訓練好的hdf5模型進行目標檢測實現輸出模型中的臉部表情或性別的gradcam(可視化)
2018-12-27 16:48:28
我正在嘗試使用 eIQ 門戶訓練人臉檢測模型。我正在嘗試從 tensorflow 數據集 (tfds) 導入數據集,特別是 coco/2017 數據集。但是,我只想導入 wider_face。但是,當我嘗試這樣做時,會出現導入程序錯誤,如下圖所示。任何幫助都可以。
2023-04-06 08:45:14
PyTorch Hub 加載預訓練的 YOLOv5s 模型,model并傳遞圖像進行推理。'yolov5s'是最輕最快的 YOLOv5 型號。有關所有可用模型的詳細信息,請參閱自述文件。詳細示例此示例
2022-07-22 16:02:42
Transformers已成為計算機視覺最新進展的核心。然而,從頭開始訓練ViT模型可能會耗費大量資源和時間。在本文中旨在探索降低ViT模型訓練成本的方法。引入了一些算法改進,以便能夠在有限的硬件
2022-11-24 14:56:31
tensorflow模型部署系列的一部分,用于tflite實現通用模型的部署。本文主要使用pb格式的模型文件,其它格式的模型文件請先進行格式轉換,參考tensorflow模型部署系列————預訓練模型導出。從...
2021-12-22 06:51:18
。 圖源:OpenAI官網 中國AI水平與ChatGPT有多大的差距?中國如何訓練出這樣的GPT大模型?難點又在哪里? ChatGPT是AIGC的一種實現。在AIGC的大模型建設和應用層面,國內
2023-03-03 14:28:48
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-25 15:02:15
目前官方的線上模型訓練只支持K210,請問K510什么時候可以支持
2023-09-13 06:12:13
學習過程成長到了現在的資深電子工程師?我從事電機行業已經有5年的實際經驗,從參加工作就開始接觸電機控制。主要是做電機控制的相關工作,如工業機器人的伺服電機,工業控制的異步電動機,以及變頻器。在做項目
2019-09-26 17:01:14
德信成長史:模擬IC公司如何擺脫同質化
在今天的半導體市場上,同質化是一個非常突出的問題,尤其以電源產品為甚。而且,因為電源市場較大,該市場又吸引了中
2010-02-05 08:52:04781 MOS管常需要偏置在弱反型區和中反型區,就是未來在相同的偏置電流下獲得更高的增益。目前流行的MOS管模型大致可分為兩類,本文將詳解MOS管模型的類型和NMOS的模型圖。
2018-02-23 08:44:0051664 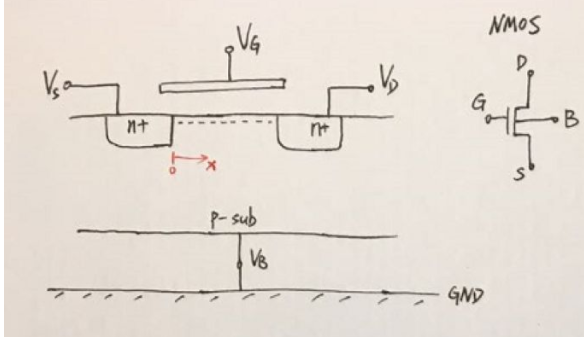
前段時間,我寫了很多關于嵌入式學習的文章,通過不少學習者的反饋使我有成就感。分享的樂趣使我決定繼續寫下去。在接下來的時間,我計劃也開始寫關于Java的內容。希望對你或多或少提供方向,當然,老規矩,遇到問題或者想發展確沒方向的新手都可以私我。話不多說,給大家帶來一個軟件工程師的成長史:
2018-06-19 15:28:002386 本文把對抗訓練用到了預訓練和微調兩個階段,對抗訓練的方法是針對embedding space,通過最大化對抗損失、最小化模型損失的方式進行對抗,在下游任務上取得了一致的效果提升。 有趣的是,這種對抗
2020-11-02 15:26:491802 
量化感知訓練(Quantization Aware Training )是在模型中插入偽量化模塊(fake\_quant module)模擬量化模型在推理過程中進行的舍入(r...
2020-12-08 22:57:051722 導讀:預訓練模型在NLP大放異彩,并開啟了預訓練-微調的NLP范式時代。由于工業領域相關業務的復雜性,以及工業應用對推理性能的要求,大規模預訓練模型往往不能簡單直接地被應用于NLP業務中。本文將為
2020-12-31 10:17:112217 
在某一方面的智能程度。具體來說是,領域專家人工構造標準數據集,然后在其上訓練及評價相關模型及方法。但由于相關技術的限制,要想獲得效果更好、能力更強的模型,往往需要在大量的有標注的數據上進行訓練。 近期預訓練模型的
2021-09-06 10:06:533351 
NLP中,預訓練大模型Finetune是一種非常常見的解決問題的范式。利用在海量文本上預訓練得到的Bert、GPT等模型,在下游不同任務上分別進行finetune,得到下游任務的模型。然而,這種方式
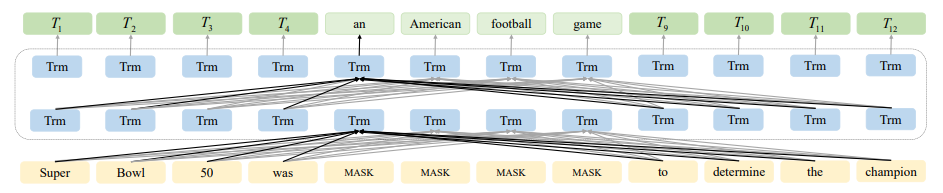
2022-03-21 15:33:301843 由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT模型結構與BERT模型一致,因此在下游預訓練時,不需要修改原始BERT模型的任何代碼與腳本。
2022-05-10 15:01:271173 電子發燒友網報道(文/李彎彎)在深度學習中,經常聽到一個詞“模型訓練”,但是模型是什么?又是怎么訓練的?在人工智能中,面對大量的數據,要在雜亂無章的內容中,準確、容易地識別,輸出需要的圖像/語音
2022-10-23 00:20:037253 ChatGPT是OpenAI開發的大型預訓練語言模型,GPT-3模型的一個變體,經過訓練可以在對話中生成類似人類的文本響應。
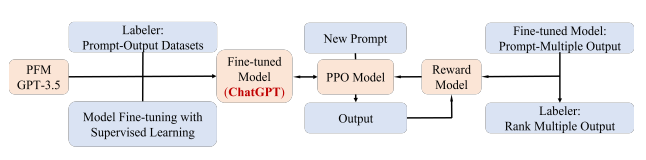
2022-12-15 12:28:561368 通過人工標注等方式,使用監督學習的模式對GPT3模型(對這個是chatGPT模型的base)進行初步訓練(有監督微調,SFT),從而得到一個初步能夠理解語言的模型,尤其是prompt的模式。
2023-01-03 17:38:581909 ChatGPT中GPT的意思是generative pre-training,(關于語言模型的)生成式預訓練,這也是這款聊天機器人奠基的理論模型。GPT理論最早2018年在OpenAI上分享,2020年,OpenAI發布了GPT-3,已經可以連貫地形成即興文本。
2023-02-08 17:23:4623581 
chatGPT是一種基于轉移學 習的大型語言模型,它使用GPT-2 (Generative PretrainedTransformer2)模型的技術,并進行了進一步的訓練和優化。
2023-02-09 15:09:567657 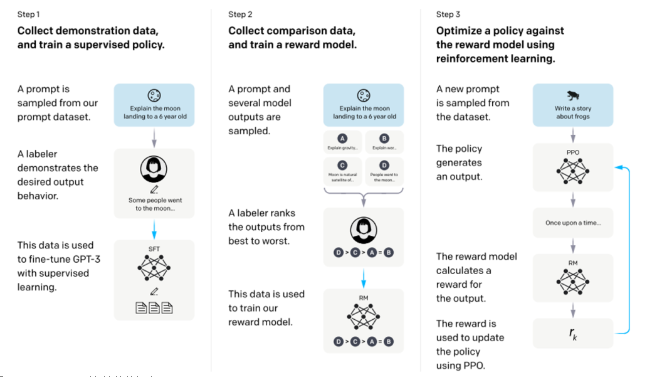
近日, ChatGPT在圈內大火。那么什么是ChatGPT呢? ChatGPT是一種自然語言生成模型,由OpenAI開發。它基于GPT(Generative
2023-02-10 11:58:40 2
2 ChatGPT使用基于人類反饋的強化學習進行訓練,這種方法通過人類干預以增強機器學習的效果,從而獲得更為逼真的結果。其使用基于GPT-3.5架構的語言模型。在訓練過程中,人類訓練師扮演著用戶與人
2023-02-10 11:30:321 這兩天,ChatGPT模型真可謂稱得上是狂拽酷炫D炸天的存在了。一度登上了知乎熱搜,這對科技類話題是非常難的存在。不光是做人工智能、機器學習的人關注,而是大量的各行各業從業人員都來關注這個模型
2023-02-10 11:15:062 是基于聊天的生成預訓練transformer模型的縮寫,是一個強大的工具,可以以各種方式使用,以提高您在許多領域的生產力。 ChatGPT是一種人工智能(AI)技術,被稱為自然語言處理(NLP)模型
由人工智能研發公司OpenAI創建。它使用機器學習算法來分析和理解書面或口頭語言,然后根據該輸
2023-02-10 11:19:067 撰寫郵件、視頻腳本、文案、翻譯、代碼等任務,有望成為提高辦公、學習效率的工具,應用場景廣闊。 ? ChatGPT:“殺手級”AI應用的出圈 ChatGPT是一個“萬事通”:基于GPT 3.5架構的大型語言模型(LLM),通過與用戶的自然互動對話完成各種復雜的任務,如求解數學方程式、寫
2023-02-10 10:38:20482 如此受歡迎,是因為它具有如下優秀特點: 1、強大的語言生成能力:ChatGPT是一種被訓練有素的語言模型,可以生成各種文本內容,如問答、對話、描述等。 2、語言知識豐富:ChatGPT是在大量語料庫上進行訓練的,因此它對語言知識的理解非常深刻,可以產生高質量的文
2023-02-10 14:11:58195750 chatgpt怎么用 chatgpt怎么用?chatgpt 簡介 ChatGPT是一種語言模型,它被訓練來對對話進行建模。它能夠通過學習和理解人類語言來進行對話,并能夠生成適當的響應。ChatGPT
2023-02-10 14:22:2757024 最近 一直聽到ChatGPT,如雷貫耳,目前只能在國外用。近期找了個時間專門研究了怎么使用ChatGPT.
ChatGPT是一種大型語言模型,由 OpenAI 訓練。它可以生成
2023-02-13 10:11:071 話式人工智能的預期。因此一經推出就驚艷世界,引爆了全球對 ChatGPT的關注。ChatGPT的模型架構基于生成預訓練轉換器(Generative Pre-training Transformer),并基于大量文本數據進行訓練。因此除了對話,ChatGPT還能夠理解復雜問題并執行高級任務。
2023-02-13 09:57:170 )是由OpenAI發明的一種自然語言處理技術。它是一種預訓練的深度學習模型,可以用來生成文本,識別語義,做文本分類等任務。 ChatGPT實現原理 火爆的ChatGPT,得益于AIGC 背后的關鍵技術NLP
2023-02-13 17:32:3674276 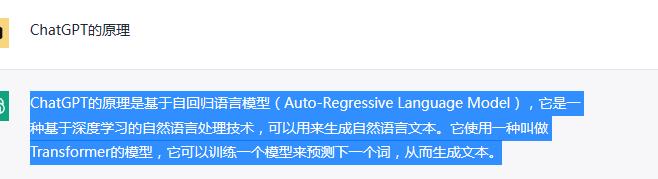
一. ChatGPT 1. ChatGPT的自我介紹 2. ChatGPT的前世 2.1GPT-3是啥?General Pre-Training(GPT),即通用預訓練語言模型,是一種利用
2023-02-14 09:33:232 離強大到危險的人工智能不遠了”。
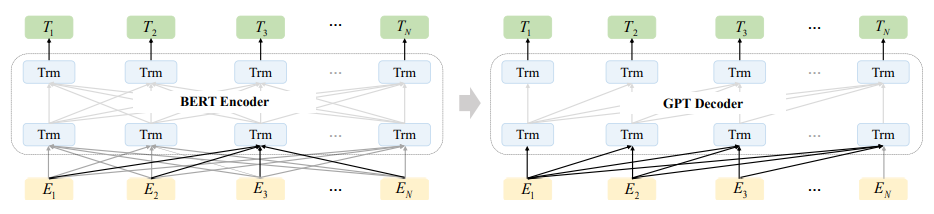
自2018年的BERT預訓練模型被提出后,迅速刷新了各大NLP
2023-02-14 09:14:343 ChatGPT是由OpenAI開發的一個人工智能聊天機器人程序,由 OpenAI 公司于2022年11月推出。該程序使用基于GPT-3.5架構的大型語言模型并通過強化學習進行訓練
2023-02-14 09:19:190 ),而在中國以百度等為代表的互聯網科技公司也紛紛表示正在研發此類技術并且將于近期上線。 以ChatGPT為代表的生成類模型有一個共同的特點,就是使用了海量數據做預訓練,并且往往會搭配一個較為強大的語言模型。語言模型主要的功能是從海量的現有語料庫中進行
2023-02-17 09:45:07521 2022年下半年開始,涌現出一大批“大模型”的優秀應用,其中比較出圈的當屬AI作畫與ChatGPT,刷爆了各類社交平臺,其讓人驚艷的效果,讓AI以一個鮮明的姿態,站到了廣大民眾面前,讓不懂AI的人也能直觀地體會到AI的強大。大模型即大規模預訓練模型 。
2023-02-20 14:09:111391 
隨著新型 AI 技術的快速發展,模型訓練數據集的相關文檔質量有所下降。模型內部到底有什么秘密?它們又是如何組建的?本文綜合整理并分析了現代大型語言模型的訓練數據集。
2023-02-21 10:06:231432 ChatGPT是一種由OpenAI開發的通用聊天機器人模型。
2023-02-21 15:32:463294 ChatGPT 是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架構開發的對話AI模型,是InstructGPT 的兄弟模型。 ChatGPT很可能是OpenAI 在GPT-4 正式推出之前的演練,或用于收集大量對話數據。
2023-02-24 10:05:131421 模型選擇:ChatGPT 的開發人員選擇了 GPT-3.5 系列中的預訓練模型,而不是對原始 GPT-3 模型進行調優。使用的基線模型是最新版的 text-davinci-003(通過對程序代碼調優的 GPT-3 模型)。
2023-03-08 09:28:00352 ChatGPT升級 史上最強大模型GPT-4發布 OpenAI正式推出了ChatGPT升級版本,號稱史上最強大模型GPT-4發布。OpenAI期待GPT-4成為一個更有價值的AI工具。 GPT-4
2023-03-15 18:15:582363 ChatGPT是自然語言處理(NLP)下的AI大模型,通過大算力、大規模訓練數據突破AI瓶頸。2022年11月,OpenAI推 出ChatGPT,ChatGPT基于GPT-3.5,使用人類反饋強化學習技術,將人類偏好作為獎勵信號并微調模型,實現有邏輯 的對話能力。
2023-03-16 11:16:551815 ChatGPT的最強輸出能力便是他的文字輸出能力,而文字輸出變現的軟件有很多例如知乎百家號等,ChatGPT的語言生成模型,它能夠通過訓練集自動生成文本。這使得利用ChatGPT進行文字變現成為一種可能性ChatGPT可以從給定主題生成無數種可能的文章。
2023-03-17 10:28:553247 預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。 如果要教一個剛學會走路的孩子什么是獨角獸,那么我們首先應
2023-04-04 01:45:021025 DeepSpeed-RLHF 模塊:DeepSpeed-RLHF 復刻了 InstructGPT 論文中的訓練模式,并確保包括 a) 監督微調(SFT),b) 獎勵模型微調和 c) 基于人類反饋
2023-04-14 09:36:28782 ChatGPT 的出現讓人類見證了大預言模型的能力,正在影響著多個行業的發展。作為 AI 技術的重要應用場景之一,“AI+教育”已經到了一個從結合過渡到融合的關鍵節點。如何將 AI 技術融入啟蒙成長
2023-05-11 15:12:18607 從Transformer提出到“大規模預訓練模型”GPT(Generative Pre-Training)的誕生,再到GPT2的迭代標志Open AI成為營利性公司,以及GPT3和ChatGPT的“出圈”;再看產業界
2023-05-16 09:56:00523 
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。
2023-05-25 17:10:09595 本文介紹了支持 ChatGPT 的機器學習模型的概況,文章將從大型語言模型的介紹開始,深入探討用來訓練 GPT-3 的革命性自我注意機制,然后深入研究由人類反饋的強化學習機制這項讓 ChatGPT 與眾不同的新技術。
2023-05-26 11:44:32541 
ChatGPT(Chat Generative Pre-trained Transformer)是一種基于Transformer架構的預訓練語言模型,其目標是生成自然流暢的對話文本。它由OpenAI
2023-05-29 09:41:1314486 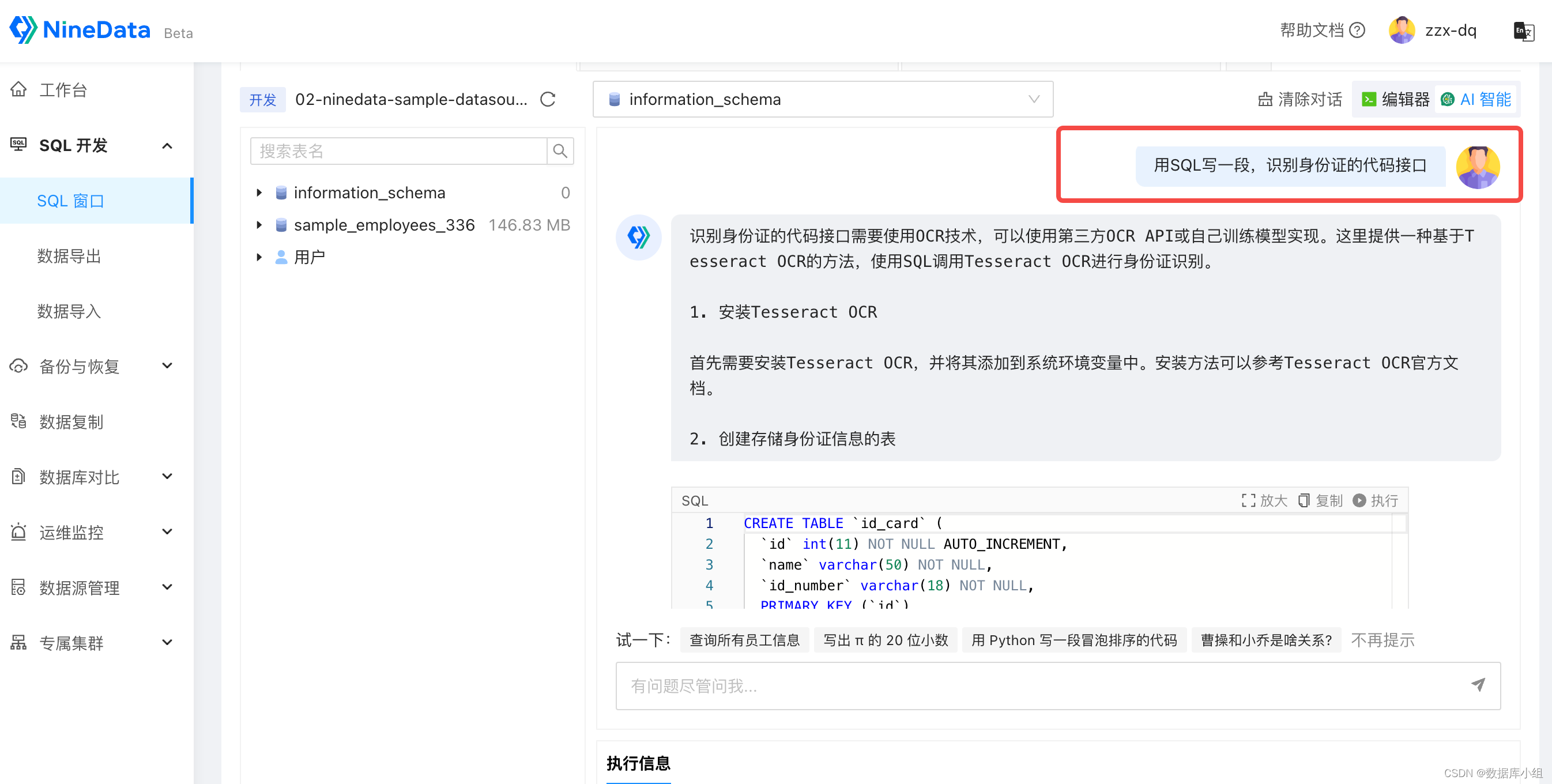
由于ChatGPT可以適用于非常多的任務,很多人認為 AI 已經迎來拐點。李開復將此前的 AI 定義為 AI 1.0,此后的AI定義為AI 2.0。AI 1.0 中模型適用于單領域,AI 2.0
2023-05-29 11:16:05858 
電子發燒友網報道(文/李彎彎)ChatGPT的出現讓大模型迅速出圈,事實上,在過去這些年中,模型規模在快速提升。數據顯示,自2016年至今,模型大小每18個月增長40倍,自2019年到現在,更是
2023-05-30 13:56:091502 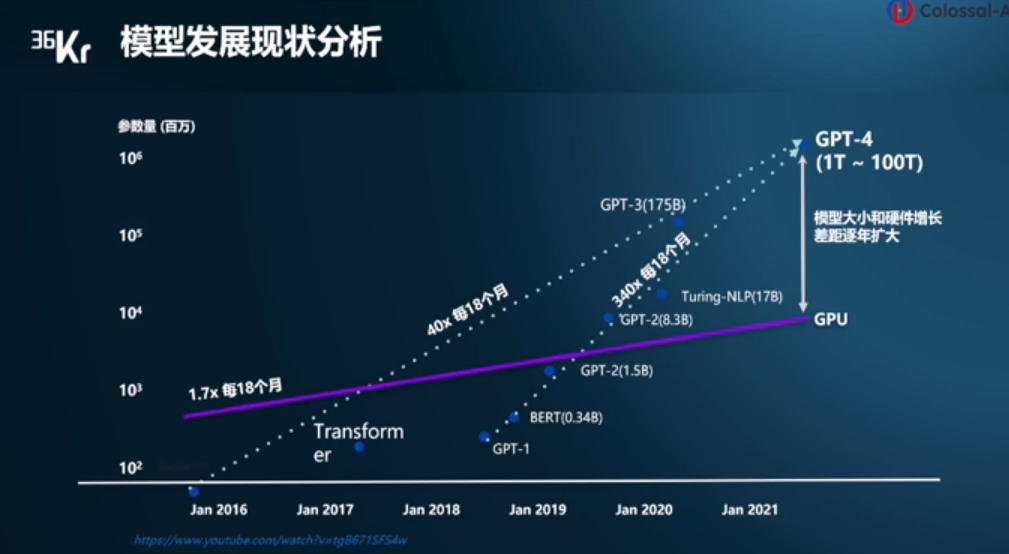
ChatGPT的橫空出世拉開了大語言模型產業和生成式AI產業蓬勃發展的序幕。本報告將著重分析“OpenAI ChatGPT的成功之路”、“中國類ChatGPT產業發展趨勢”、“ChatGPT應用場景與生態建設”、“ChatGPT浪潮下的‘危’與‘機’”四個問題。
2023-06-01 16:49:42777 
ChatGPT是什么 ChatGPT是一種人工智能聊天機器人,可以與用戶進行自然語言對話,回答問題,提供建議和娛樂等服務。它的名字"GPT"代表著"生成預訓練模型
2023-06-04 17:01:572330 ChatGPT實際上是一個大型語言預訓練模型(即Large Language Model,后面統一簡稱LLM)。什么叫LLM?LLM指的是利用大量文本數據來訓練的語言模型,這種模型可以產生出強大
2023-06-06 17:39:101 問題并幫助您完成撰寫電子郵件、論文和代碼等任務。這種類型的生成式 AI 模型根據來自互聯網的大量信息進行訓練,包括網站、書籍、新聞文章等。 chatgpt國內能用嗎? chatgpt國內暫時無法直接使用,企業辦公場景需要使用ChatGPT時,需要開通國際專線。 國際專線為企業
2023-06-16 09:24:309768 ChatGPT簡介ChatGPT(GenerativePre-trainedTransformer)是由OpenAI開發的一個包含了1750億個參數的大型自然語言處理模型。它基于互聯網可用數據訓練
2023-02-02 15:10:33715 
上具有更優的表現。它代表了 OpenAI 最新一代的大型語言模型,并且在設計上非常注重交互性。 OpenAI 使用監督學習和強化學習的組合來調優 ChatGPT,其中的強化學習組件使 ChatGPT 獨一無二。OpenAI 使用了「人類反饋強化學習」(RLHF)的訓練方法,該方法在訓練中使用人類反饋,以最
2023-06-27 13:57:09197 今天我們為大家帶來的文章,深入淺出地闡釋了ChatGPT背后的技術原理,沒有NLP或算法經驗的小伙伴,也可以輕松理解ChatGPT是如何工作的。 ChatGPT是一種機器學習自然語言處理模型
2023-07-18 17:12:300 有不少教程,搜索觀看即可。 ChatGPT 是一款由 OpenAI 開發的大型語言模型,主要功能是回答用戶的問題和完成各種語言任務,如對話生成、文本摘要、翻譯、生成文本 等。它使用了先進的深度學習技術和海量的語言數據進行訓練,可以在 各種語言領域提供高質量的語言處理服務
2023-07-19 14:21:003 ChatGPT 的工作原理可以分為兩個主要步驟:預訓練和微調。 (1)預訓練階段 ChatGPT 使用大量的文本數據進行訓練,以了解不同語言結構和上下文之間的關系。這樣它就能夠學習到自然語言
2023-07-20 11:29:589 ChatGPT作為智能對話生成模型,可以幫助打造智能客服體驗的重要工具。以下是一些方法和步驟: 1.數據收集和準備:收集和整理與客服相關的數據,包括常見問題、回答示例、客戶對話記錄等。這將用于訓練
2023-08-06 16:02:36308 
的影響,其注冊相對繁瑣。那么國內如何注冊ChatGPT賬號?本文跟大家詳細分享GPT賬戶注冊教程,手把手教你成功注冊ChatGPT。 ChatGPT是一種自然語言處理模型,ChatGPT全稱Chat
2023-12-06 16:28:00315 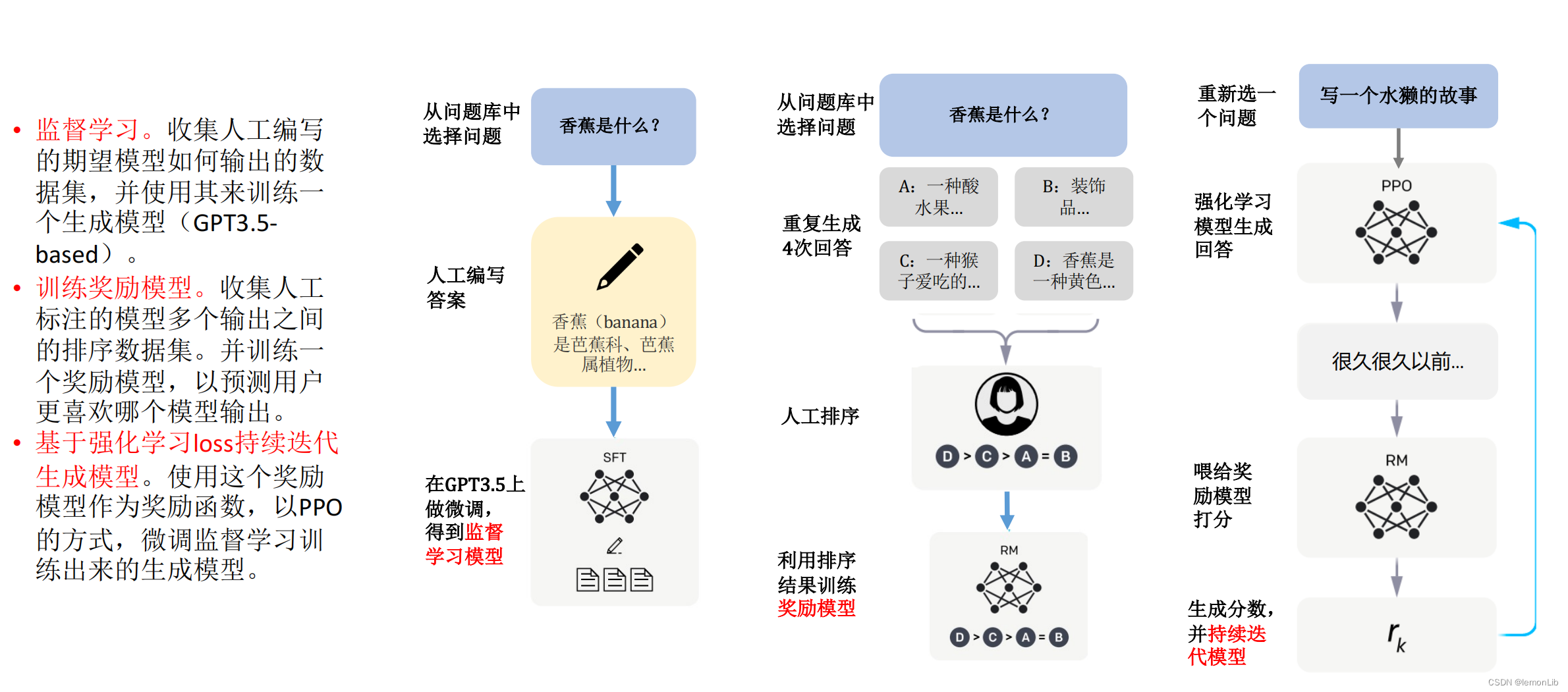
卷積神經網絡模型訓練步驟? 卷積神經網絡(Convolutional Neural Network, CNN)是一種常用的深度學習算法,廣泛應用于圖像識別、語音識別、自然語言處理等諸多領域。CNN
2023-08-21 16:42:00885 盤古大模型和ChatGPT4的區別 對于大家尤其是人工智能領域的從業者而言,盤古大模型(PanGu-α)和ChatGPT-4是兩個大家的比較關注的模型,這是因為它們都是在當前最先進的自然語言處理領域
2023-08-30 18:27:443558 盤古大模型和ChatGPT4 盤古大模型和ChatGPT4:人工智能領域重要的兩大進展 隨著人工智能技術的不斷發展,越來越多的模型和算法被開發出來,相繼出現了眾多重要的技術突破。其中,盤古大模型
2023-08-31 10:15:423484 生成式AI和大語言模型(LLM)正在以難以置信的方式吸引全世界的目光,本文簡要介紹了大語言模型,訓練這些模型帶來的硬件挑戰,以及GPU和網絡行業如何針對訓練的工作負載不斷優化硬件。
2023-09-01 17:14:561046 
華為盤古大模型以Transformer模型架構為基礎,利用深層學習技術進行訓練。模型的每個數量達到2.6億個,是目前世界上最大的漢語預備訓練模型之一。這些模型包含許多小模型,其中最大的模型包含1億4千萬個參數。
2023-09-05 09:55:561229 大規模預訓練:華為盤古大模型采用了大規模預訓練的方法,通過對大量的中文語料進行預訓練,使模型具有更強的泛化能力和適應能力。
2023-09-05 09:58:321431 谷歌在模型訓練方面提供了一些強大的軟件工具和平臺。以下是幾個常用的谷歌模型訓練軟件及其特點。
2024-03-01 16:24:01184
 電子發燒友App
電子發燒友App









 工商網監
工商網監
評論