 電子發(fā)燒友App
電子發(fā)燒友App


最近,深度學(xué)習(xí)的研究中出現(xiàn)了許多大型預(yù)訓(xùn)練模型,例如 GPT-3、BERT 等,這些模型可以在多種自然語言處理任務(wù)中取得優(yōu)異的性能表現(xiàn)。而其中,ChatGPT 模型因為在對話生成方面的表現(xiàn)而備受矚目,成為了自然語言處理領(lǐng)域的熱門研究方向。 ? 然而,這些大型預(yù)訓(xùn)練模型的訓(xùn)練成本非常高昂,需要龐大的計算資源和大量的數(shù)據(jù),一般人難以承受。這也導(dǎo)致了一些研究人員難以重復(fù)和驗證先前的研究成果。為了解決這個問題,研究人員開始研究 Parameter-Efficient Fine-Tuning(PEFT)技術(shù)。 ? PEFT 技術(shù)旨在通過最小化微調(diào)參數(shù)的數(shù)量和計算復(fù)雜度,來提高預(yù)訓(xùn)練模型在新任務(wù)上的性能,從而緩解大型預(yù)訓(xùn)練模型的訓(xùn)練成本。這樣一來,即使計算資源受限,也可以利用預(yù)訓(xùn)練模型的知識來迅速適應(yīng)新任務(wù),實現(xiàn)高效的遷移學(xué)習(xí)。因此,PEFT 技術(shù)可以在提高模型效果的同時,大大縮短模型訓(xùn)練時間和計算成本,讓更多人能夠參與到深度學(xué)習(xí)研究中來。下面我們將深入探討 PEFT 的一些主要做法。 ? ?
Adapter Tuning
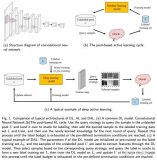
谷歌的研究人員首次在論文《Parameter-Efficient Transfer Learning for NLP》提出針對 BERT 的 PEFT 微調(diào)方式,拉開了 PEFT 研究的序幕。他們指出,在面對特定的下游任務(wù)時,如果進行 Full-fintuning(即預(yù)訓(xùn)練模型中的所有參數(shù)都進行微調(diào)),太過低效;而如果采用固定預(yù)訓(xùn)練模型的某些層,只微調(diào)接近下游任務(wù)的那幾層參數(shù),又難以達到較好的效果。 ? 于是他們設(shè)計了如下圖所示的 Adapter 結(jié)構(gòu),將其嵌入 Transformer 的結(jié)構(gòu)里面,在訓(xùn)練時,固定住原來預(yù)訓(xùn)練模型的參數(shù)不變,只對新增的 Adapter 結(jié)構(gòu)進行微調(diào)。 ? 同時為了保證訓(xùn)練的高效性(也就是盡可能少的引入更多參數(shù)),他們將 Adapter 設(shè)計為這樣的結(jié)構(gòu):首先是一個 down-project 層將高維度特征映射到低維特征,然后過一個非線形層之后,再用一個 up-project 結(jié)構(gòu)將低維特征映射回原來的高維特征;同時也設(shè)計了 skip-connection 結(jié)構(gòu),確保了在最差的情況下能夠退化為 identity。 ?
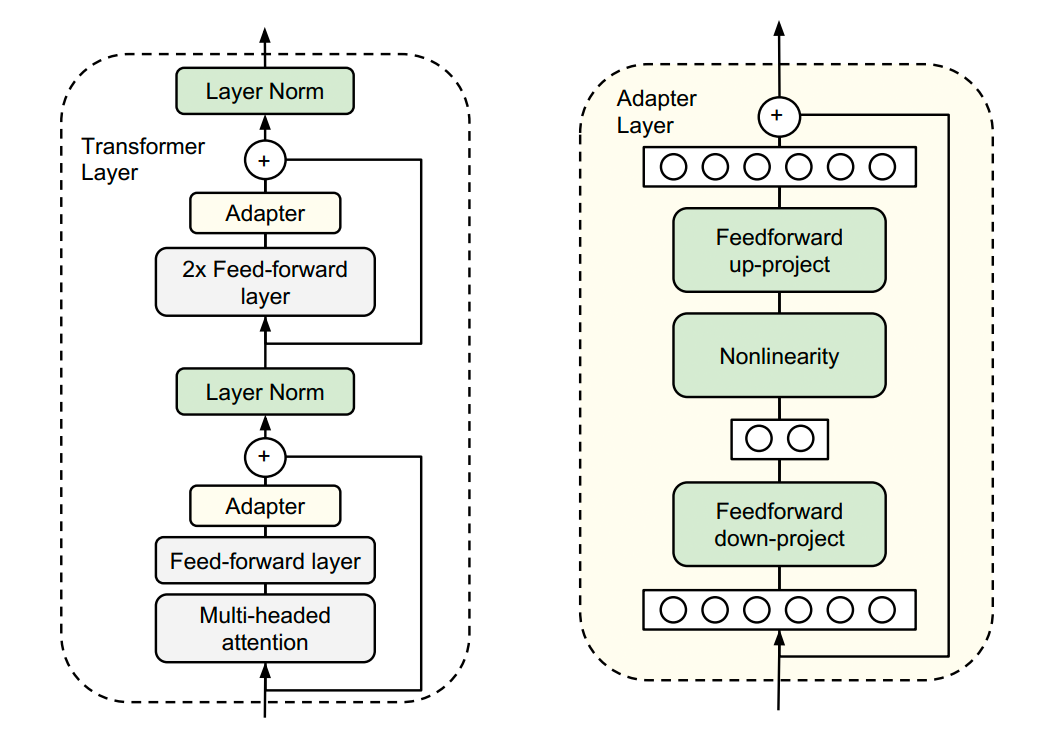
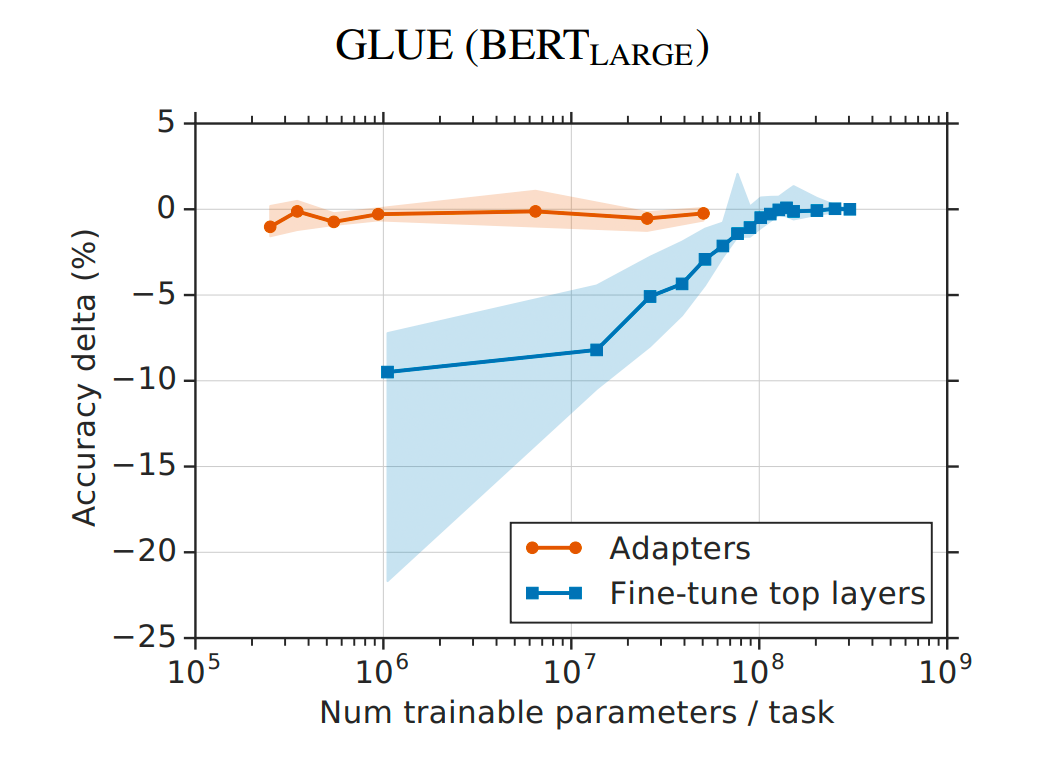
從實驗結(jié)果來看,該方法能夠在只額外對增加的 3.6% 參數(shù)規(guī)模(相比原來預(yù)訓(xùn)練模型的參數(shù)量)的情況下取得和 Full-finetuning 接近的效果(GLUE 指標(biāo)在 0.4% 以內(nèi))。 ?
Prefix Tuning
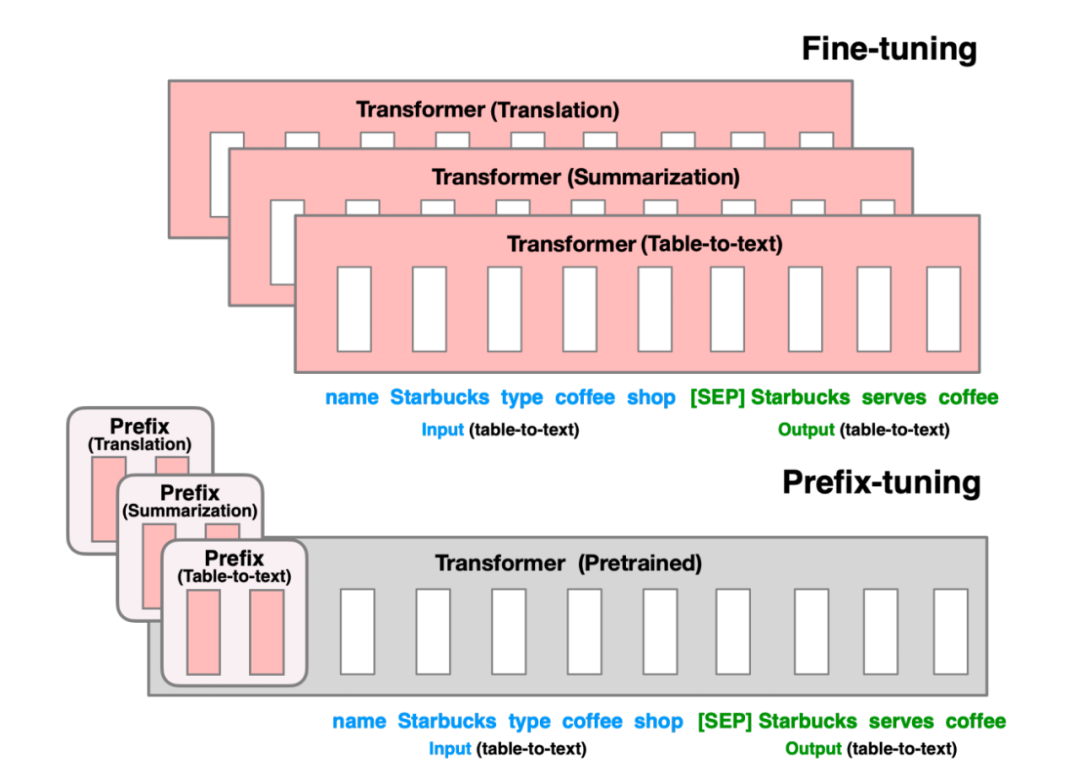
Prefix Tuning 方法由斯坦福的研究人員提出,與 Full-finetuning 更新所有參數(shù)的方式不同,該方法是在輸入 token 之前構(gòu)造一段任務(wù)相關(guān)的 virtual tokens 作為 Prefix,然后訓(xùn)練的時候只更新 Prefix 部分的參數(shù),而 Transformer 中的其他部分參數(shù)固定。該方法其實和構(gòu)造 Prompt 類似,只是 Prompt 是人為構(gòu)造的“顯式”的提示,并且無法更新參數(shù),而 Prefix 則是可以學(xué)習(xí)的“隱式”的提示。 ? 同時,為了防止直接更新 Prefix 的參數(shù)導(dǎo)致訓(xùn)練不穩(wěn)定的情況,他們在 Prefix 層前面加了 MLP 結(jié)構(gòu)(相當(dāng)于將 Prefix 分解為更小維度的 Input 與 MLP 的組合后輸出的結(jié)果),訓(xùn)練完成后,只保留 Prefix 的參數(shù)。 ? 實驗結(jié)果也說明了 Prefix Tuning 的方式可以取得不錯的效果。 ?
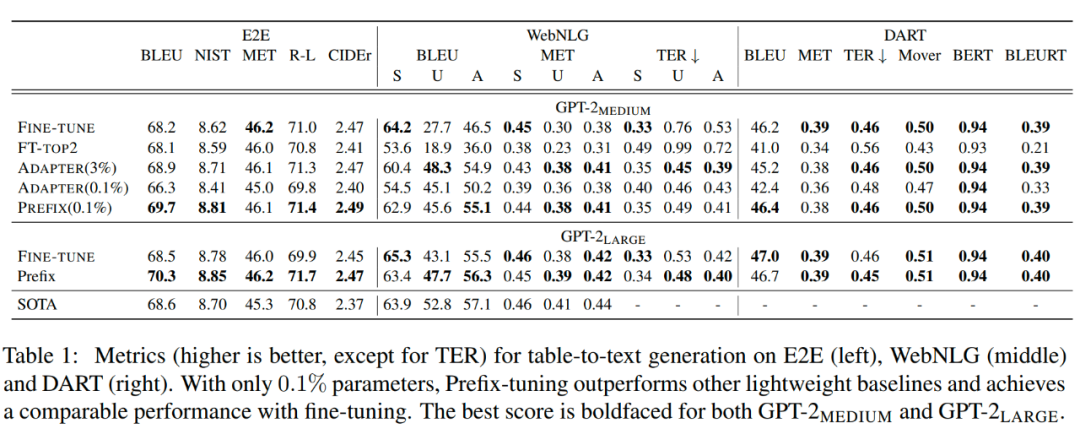
除此之外,作者還做了一系列的消融實驗說明該方法的有效性: ?
1. Prefix 長度的影響:不同的任務(wù)所需要的 Prefix 的長度有差異。
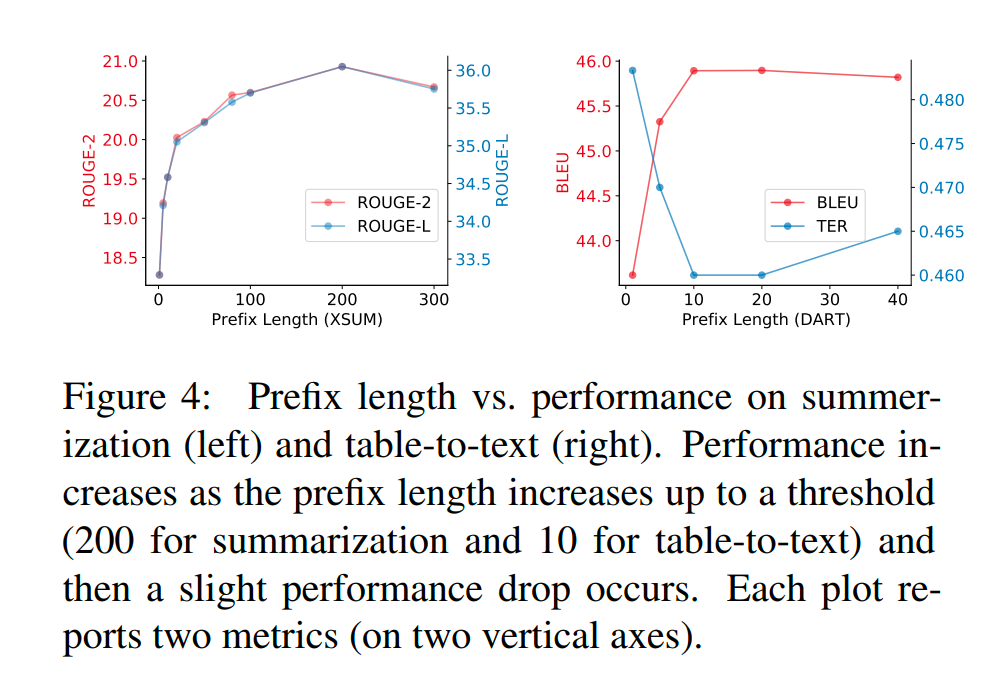
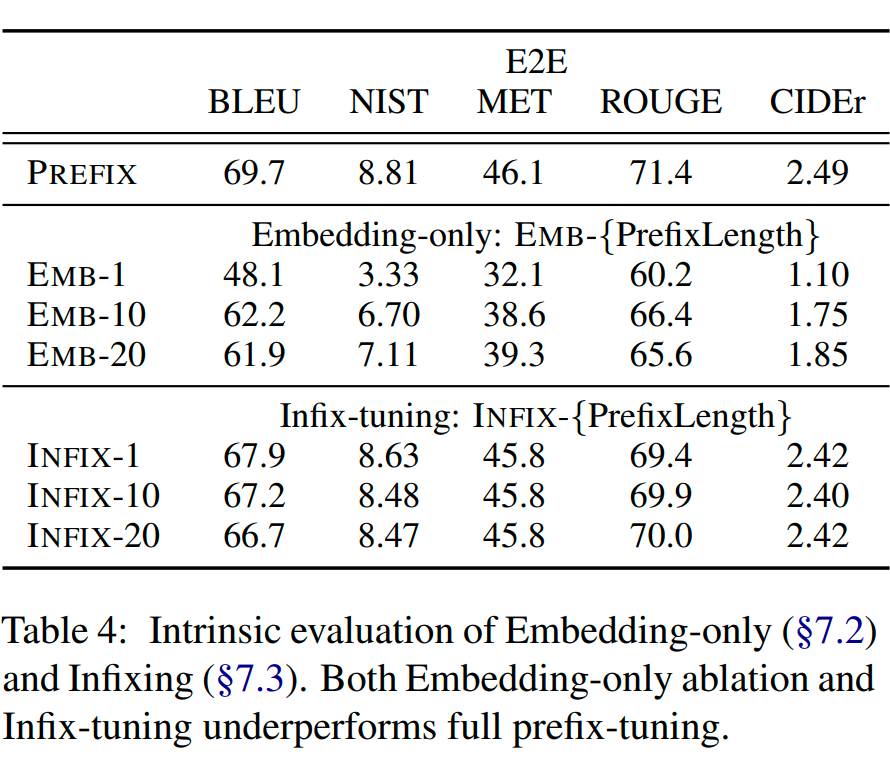
2. Full vs Embedding-only:作者對比了 Embedding-only(只有最上層輸入處的 Embedding 作為參數(shù)更新,后續(xù)的參數(shù)固定)和 Full(每一層的 Prefix 相關(guān)的參數(shù)都訓(xùn)練)的方式的效果。
3. Prefixing vs Infixing:對比了 [PREFIX; x; y] 方式與 [x; INFIX; y] 方式的差異,還是 Prefix 方式最好。
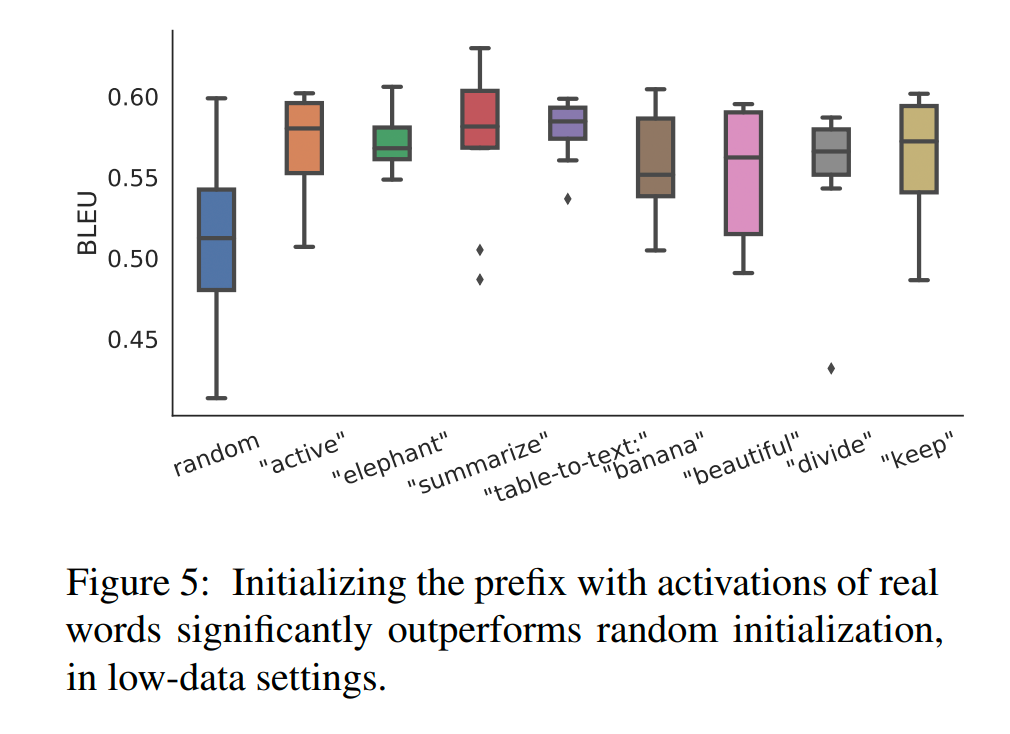
4. Initialization:用任務(wù)相關(guān)的 Prompt 去初始化 Prefix 能取得更好的效果。
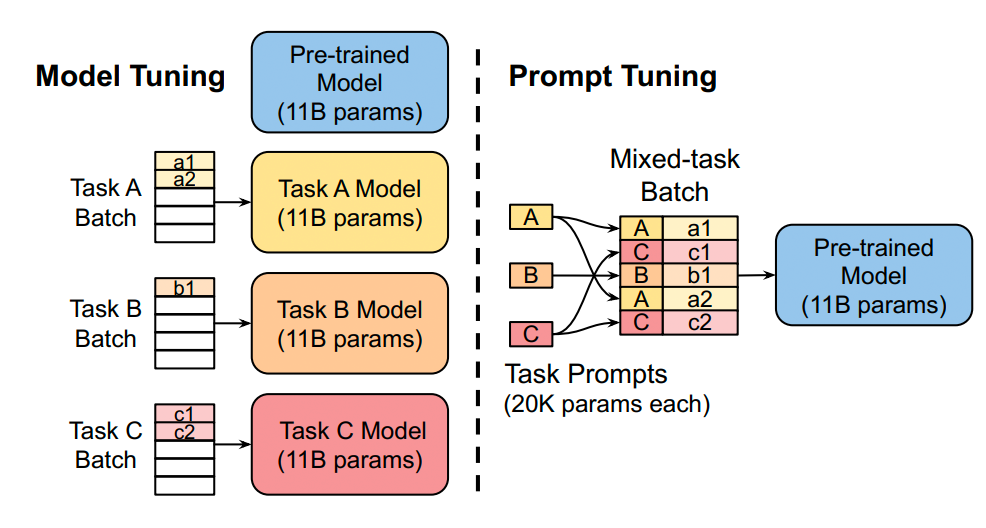
Prompt Tuning
論文《The Power of Scale for Parameter-Efficient Prompt Tuning》 ? 我給這篇文章取了個新名字:Scale is All You Need,總的來說就是,只要模型規(guī)模夠大,簡單加入 Prompt tokens 進行微調(diào),就能取得很好的效果。 ? 該方法可以看作是 Prefix Tuning 的簡化版本,只在輸入層加入 prompt tokens,并不需要加入 MLP 進行調(diào)整來解決難訓(xùn)練的問題,主要在 T5 預(yù)訓(xùn)練模型上做實驗。似乎只要預(yù)訓(xùn)練模型足夠強大,其他的一切都不是問題。作者也做實驗說明隨著預(yù)訓(xùn)練模型參數(shù)量的增加,Prompt Tuning 的方法會逼近 Fine-tune 的結(jié)果。 ?
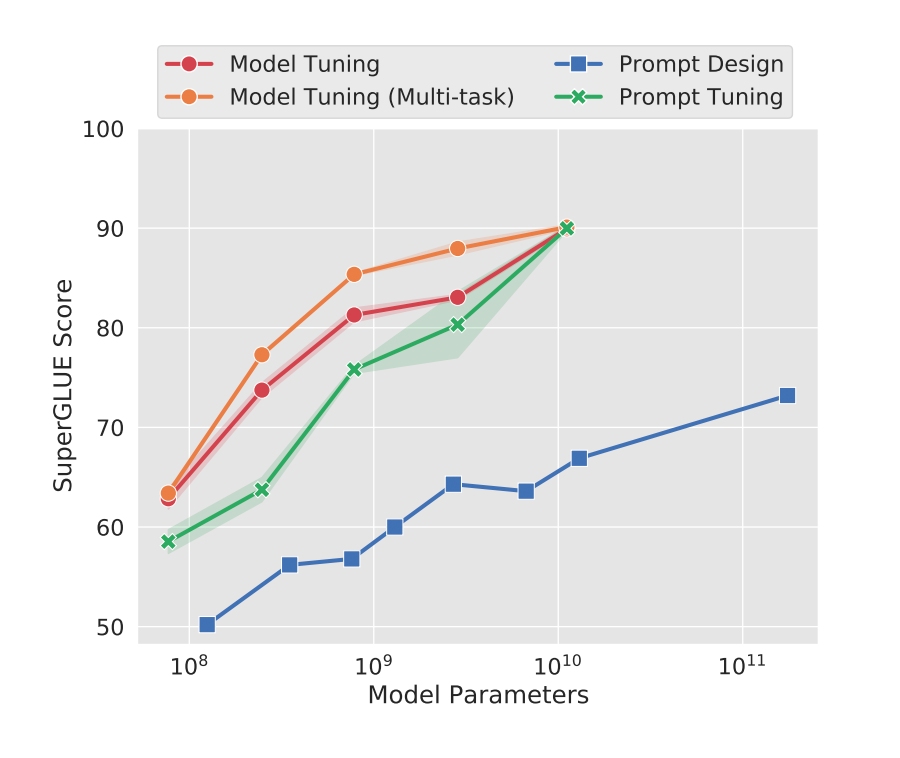
3.1 實驗
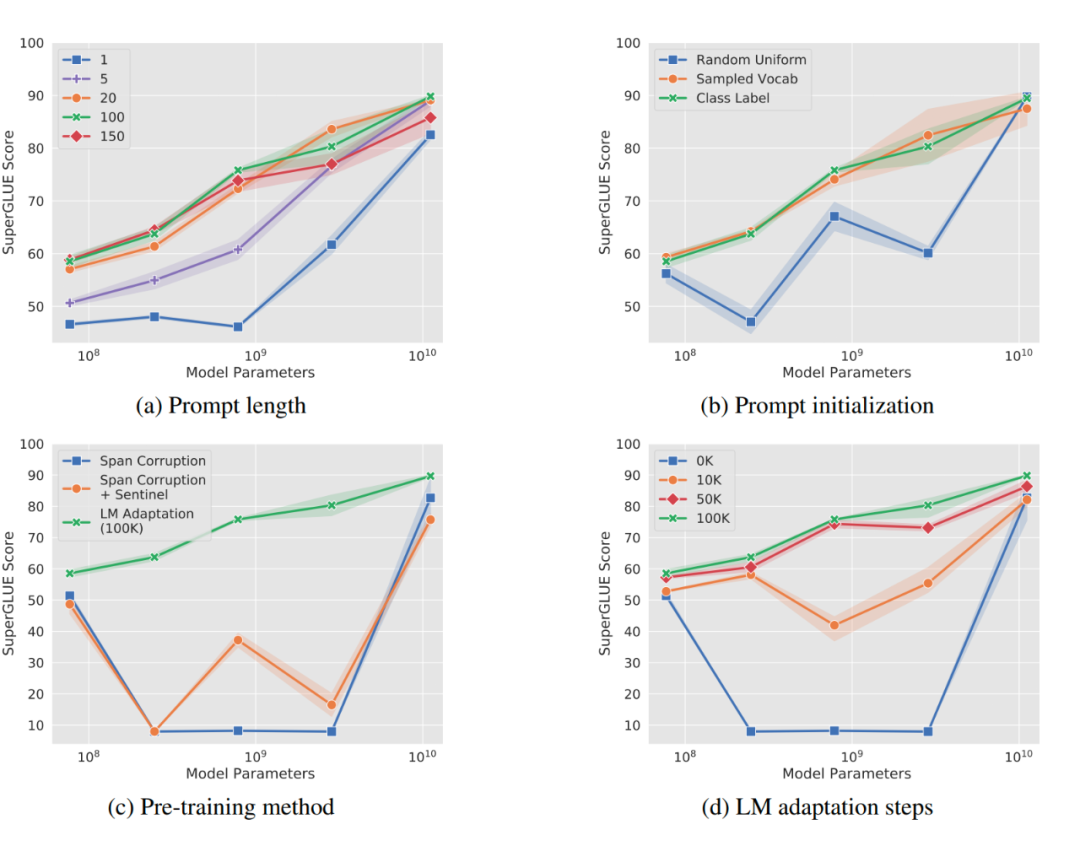
作者做了一系列對比實驗,都在說明:隨著預(yù)訓(xùn)練模型參數(shù)的增加,一切的問題都不是問題,最簡單的設(shè)置也能達到極好的效果。 ?
a)Prompt 長度影響:模型參數(shù)達到一定量級時,Prompt 長度為 1 也能達到不錯的效果,Prompt 長度為 20 就能達到極好效果。
b)Prompt 初始化方式影響:Random Uniform 方式明顯弱于其他兩種,但是當(dāng)模型參數(shù)達到一定量級,這種差異也不復(fù)存在。
c)預(yù)訓(xùn)練的方式:LM Adaptation 的方式效果好,但是當(dāng)模型達到一定規(guī)模,差異又幾乎沒有了。
d)微調(diào)步數(shù)影響:模型參數(shù)較小時,步數(shù)越多,效果越好。同樣隨著模型參數(shù)達到一定規(guī)模,zero shot 也能取得不錯效果。
P-Tuning
4.1 V1
P-Tuning 方法的提出主要是為了解決這樣一個問題:大模型的 Prompt 構(gòu)造方式嚴重影響下游任務(wù)的效果。 ?

P-Tuning 提出將 Prompt 轉(zhuǎn)換為可以學(xué)習(xí)的 Embedding 層,只是考慮到直接對 Embedding 參數(shù)進行優(yōu)化會存在這樣兩個挑戰(zhàn): ?
Discretenes:對輸入正常語料的 Embedding 層已經(jīng)經(jīng)過預(yù)訓(xùn)練,而如果直接對輸入的 prompt embedding 進行隨機初始化訓(xùn)練,容易陷入局部最優(yōu)。
Association:沒法捕捉到 prompt embedding 之間的相關(guān)關(guān)系。
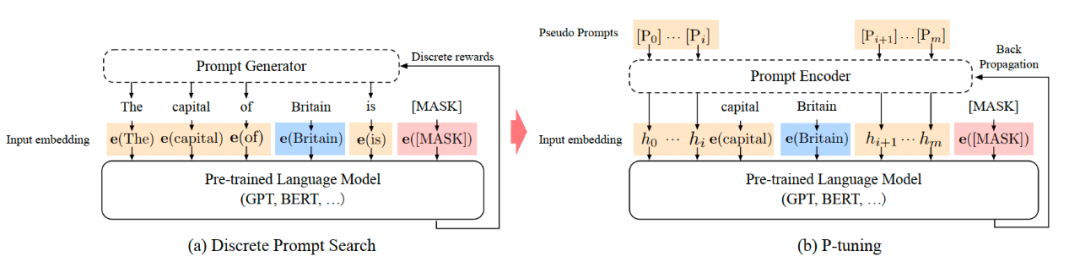
作者在這里提出用 MLP+LSTM 的方式來對 prompt embedding 進行一層處理
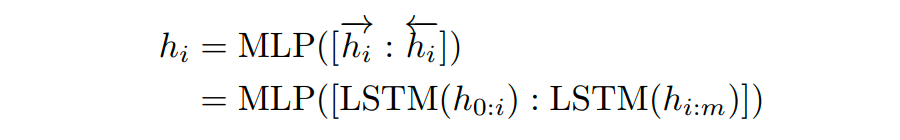
4.1.1 與 Prefix-Tuning 的區(qū)別
這篇文章(2021-03)和 Prefix-Tuning(2021-01)差不多同時提出,做法其實也有一些相似之處,主要區(qū)別在 ?
Prefix Tuning 是將額外的 embedding 加在開頭,看起來更像是模仿 Instruction 指令;而 P-Tuning 的位置則不固定。
Prefix Tuning 通過在每個 Attention 層都加入 Prefix Embedding 來增加額外的參數(shù),通過 MLP 來初始化;而 P-Tuning 只是在輸入的時候加入 Embedding,并通過 LSTM+MLP 來初始化。
4.2 V2?
論文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》 ? 從標(biāo)題就可以看出這篇文章的野心,P-Tuning v2 的目標(biāo)就是要讓 Prompt Tuning 能夠在不同參數(shù)規(guī)模的預(yù)訓(xùn)練模型、針對不同下游任務(wù)的結(jié)果上都達到匹敵 Fine-tuning 的結(jié)果。 ? 那也就是說當(dāng)前 Prompt Tuning 方法未能在這兩個方面都存在局限性。 ?
不同模型規(guī)模:Prompt Tuning 和 P-tuning 這兩種方法都是在預(yù)訓(xùn)練模型參數(shù)規(guī)模夠足夠大時,才能達到和 Fine-tuning 類似的效果,而參數(shù)規(guī)模較小時效果則很差。
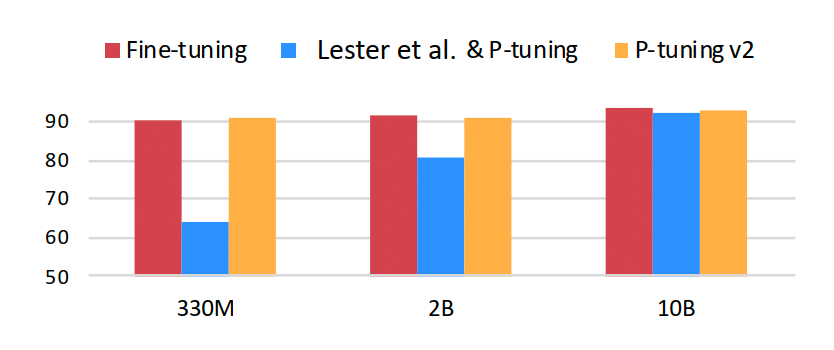
不同任務(wù)類型:Prompt Tuning 和 P-tuning 這兩種方法在 sequence tagging 任務(wù)上表現(xiàn)都很差。
4.2.1 主要結(jié)構(gòu)
相比 Prompt Tuning 和 P-tuning 的方法,P-tuning v2 方法在多層加入了 Prompts tokens 作為輸入,帶來兩個方面的好處: ? 1. 帶來更多可學(xué)習(xí)的參數(shù)(從 P-tuning 和 Prompt Tuning 的 0.1% 增加到0.1%-3%),同時也足夠 parameter-efficient。 ? 2. 加入到更深層結(jié)構(gòu)中的 Prompt 能給模型預(yù)測帶來更直接的影響。
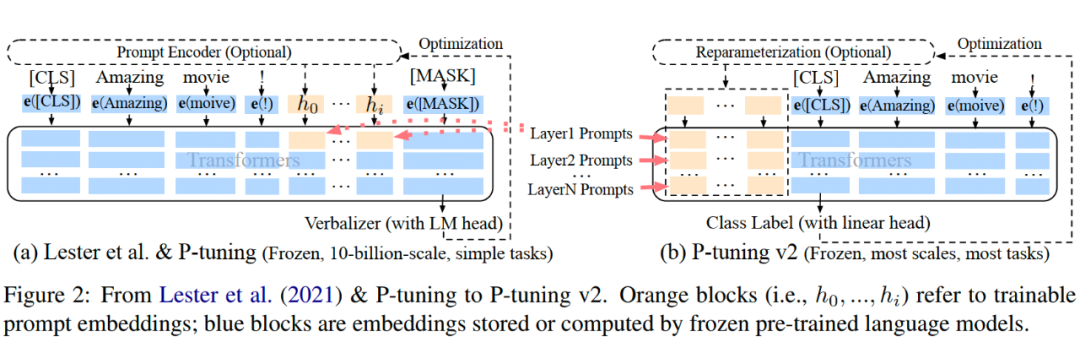
4.2.2 幾個關(guān)鍵設(shè)計因素
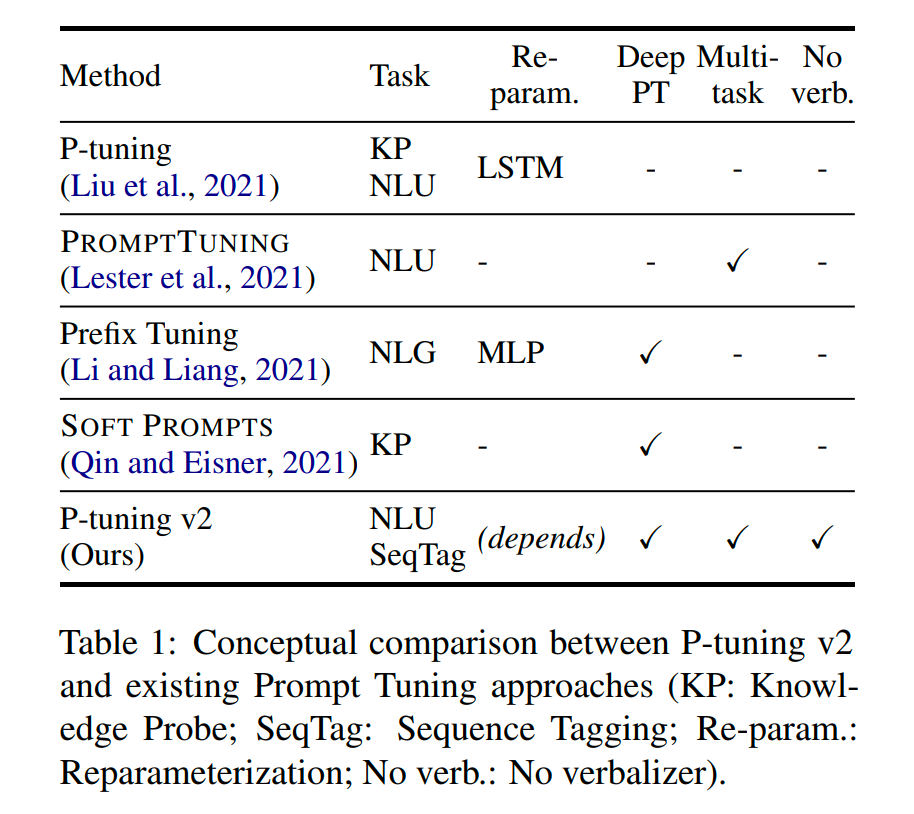
Reparameterization:Prefix Tuning 和 P-tuning 中都有 MLP 來構(gòu)造可訓(xùn)練的 embedding。本文發(fā)現(xiàn)在自然語言理解領(lǐng)域,面對不同的任務(wù)以及不同的數(shù)據(jù)集,這種方法可能帶來完全相反的結(jié)論。
Prompt Length:不同的任務(wù)對應(yīng)的最合適的 Prompt Length 不一樣,比如簡單分類任務(wù)下 length=20 最好,而復(fù)雜的任務(wù)需要更長的 Prompt Length。
Multi-task Learning 多任務(wù)對于 P-Tuning v2 是可選的,但可以利用它提供更好的初始化來進一步提高性能。
Classification Head 使用 LM head 來預(yù)測動詞是 Prompt Tuning 的核心,但我們發(fā)現(xiàn)在完整的數(shù)據(jù)設(shè)置中沒有必要這樣做,并且這樣做與序列標(biāo)記不兼容。P-tuning v2 采用和 BERT 一樣的方式,在第一個 token 處應(yīng)用隨機初始化的分類頭。
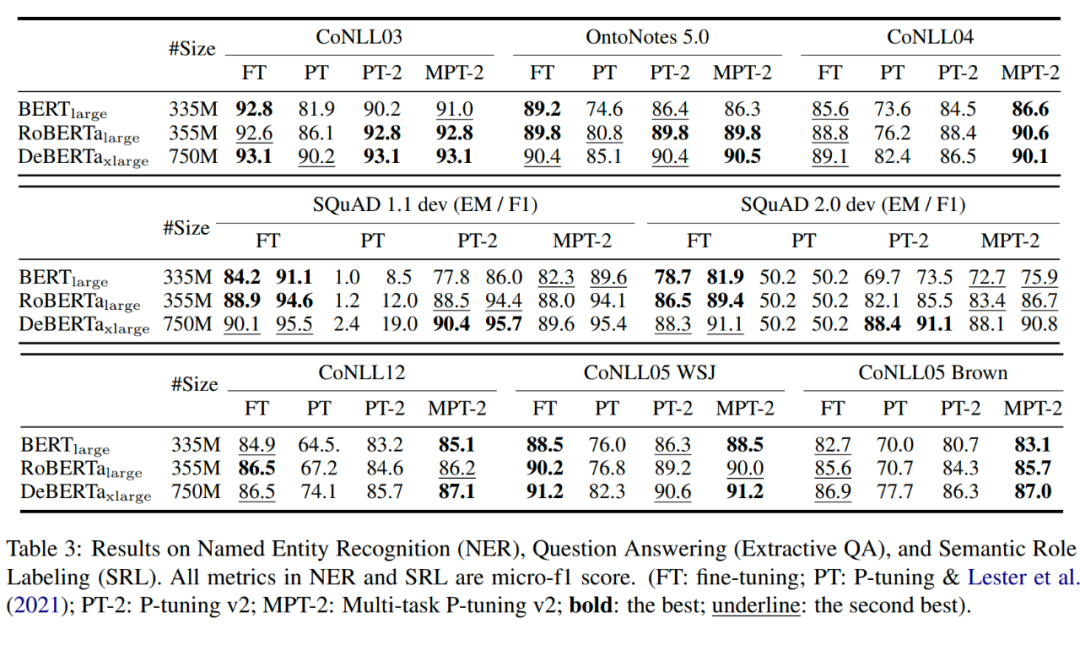
4.2.3 實驗結(jié)果
不同預(yù)訓(xùn)練模型大小下的表現(xiàn),在小模型下取得與Full-finetuning相近的結(jié)果,并遠遠優(yōu)于P-Tuning。
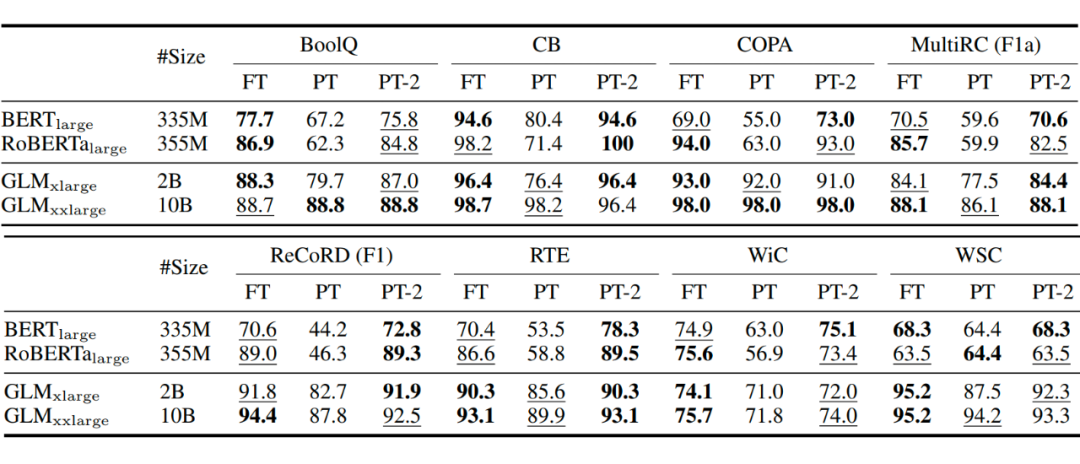
不同任務(wù)下的 P-Tuning v2 效果都很好,而 P-Tuning 和 Prompt Learning 效果不好;同時,采用多任務(wù)學(xué)習(xí)的方式能在多數(shù)任務(wù)上取得最好的結(jié)果。
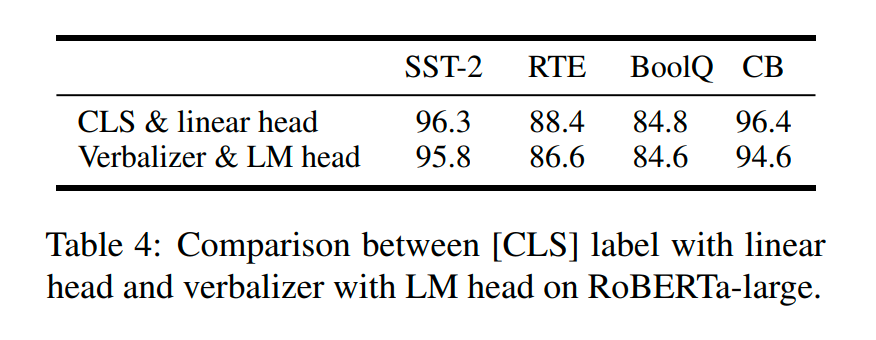
Verbalizer with LM head v.s. [CLS] label with linear head,兩種方式?jīng)]有太明顯的區(qū)別
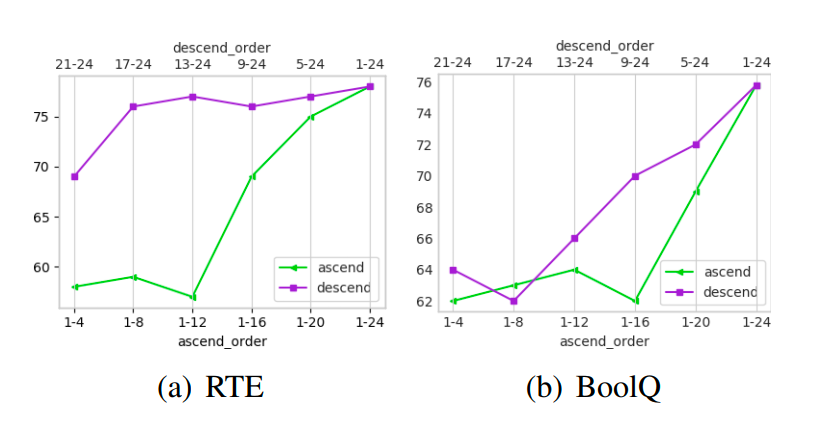
Prompt depth,在加入相同層數(shù)的 Prompts 前提下,往更深層網(wǎng)絡(luò)加效果優(yōu)于往更淺層網(wǎng)絡(luò)(只有 BoolQ 中 17-24 反而低于 1-8 是例外)。
微軟和 CMU 的研究者指出,現(xiàn)有的一些 PEFT 的方法還存在這樣一些問題: ?
由于增加了模型的深度從而額外增加了模型推理的延時,如 Adapter 方法
Prompt 較難訓(xùn)練,同時減少了模型的可用序列長度,如 Prompt Tuning、Prefix Tuning、P-Tuning 方法
往往效率和質(zhì)量不可兼得,效果差于 full-finetuning
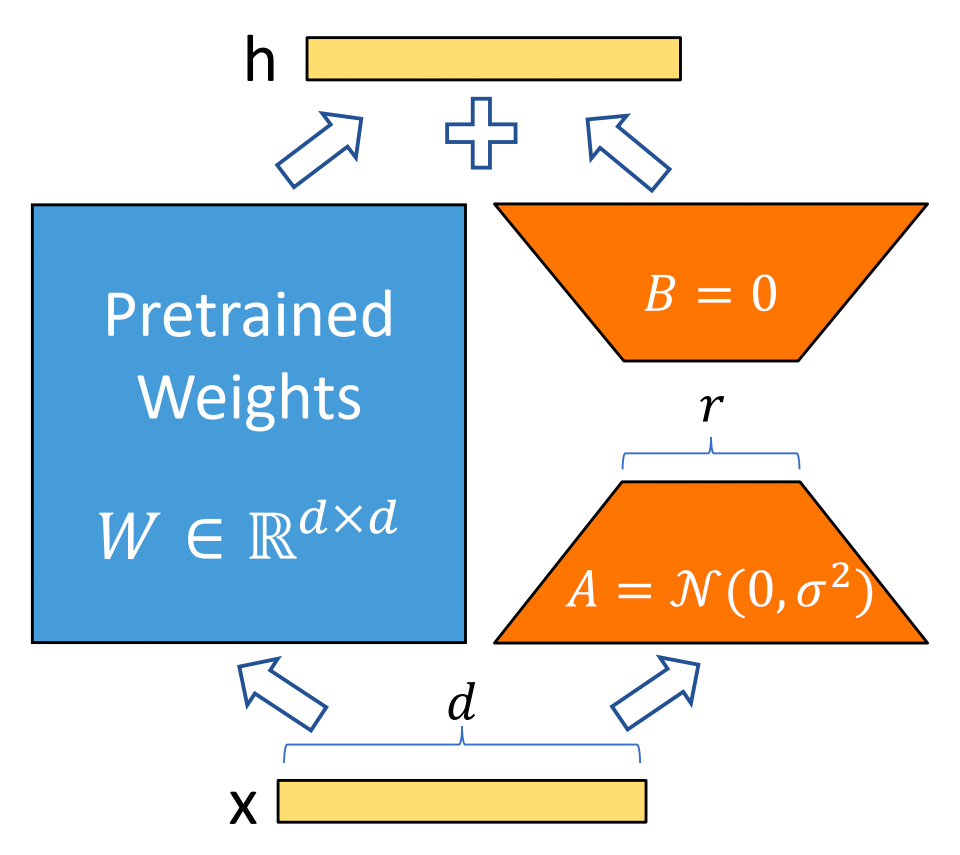
有研究者對語言模型的參數(shù)進行研究發(fā)現(xiàn):語言模型雖然參數(shù)眾多,但是起到關(guān)鍵作用的還是其中低秩的本質(zhì)維度(low instrisic dimension)。本文受到該觀點的啟發(fā),提出了 Low-Rank Adaption(LoRA),設(shè)計了如下所示的結(jié)構(gòu),在涉及到矩陣相乘的模塊,引入 A、B 這樣兩個低秩矩陣模塊去模擬 Full-finetune 的過程,相當(dāng)于只對語言模型中起關(guān)鍵作用的低秩本質(zhì)維度進行更新。 ?
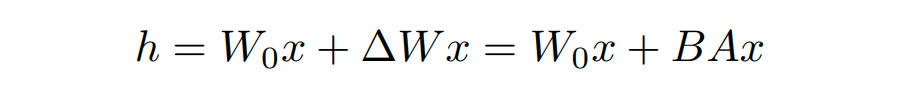
這么做就能完美解決以上存在的 3 個問題: ?
相比于原始的 Adapter 方法“額外”增加網(wǎng)絡(luò)深度,必然會帶來推理過程額外的延遲,該方法可以在推理階段直接用訓(xùn)練好的 A、B 矩陣參數(shù)與原預(yù)訓(xùn)練模型的參數(shù)相加去替換原有預(yù)訓(xùn)練模型的參數(shù),這樣的話推理過程就相當(dāng)于和 Full-finetune 一樣,沒有額外的計算量,從而不會帶來性能的損失。
由于沒有使用 Prompt 方式,自然不會存在 Prompt 方法帶來的一系列問題。
該方法由于實際上相當(dāng)于是用 LoRA 去模擬 Full-finetune 的過程,幾乎不會帶來任何訓(xùn)練效果的損失,后續(xù)的實驗結(jié)果也證明了這一點。
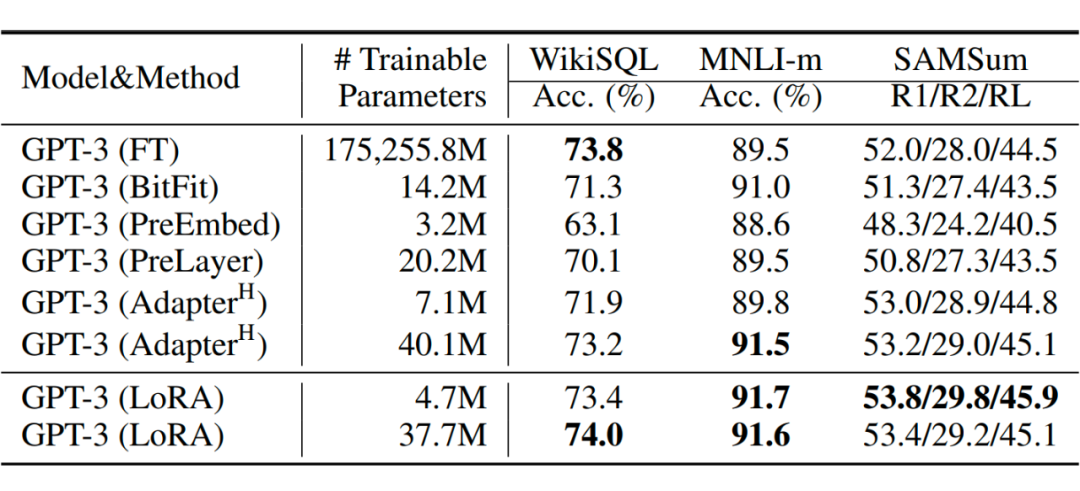
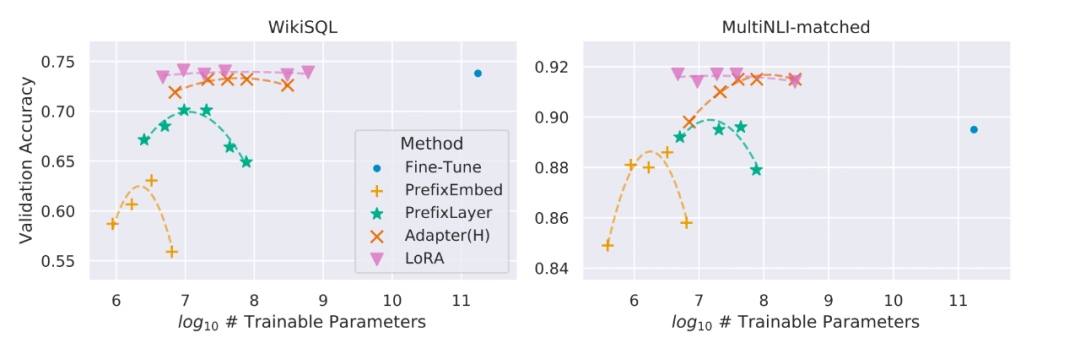
在實驗中,研究人員將這一 LoRA 模塊與 Transformer 的 attention 模塊相結(jié)合,在 RoBERTa 、DeBERTa、GPT-2 和 GPT-3 175B 這幾個大模型上都做了實驗,實驗結(jié)果也充分證明了該方法的有效性。 ?
5.1 Towards a Unified View of PETL
這篇 ICLR2022 的文章研究了典型的 PEFT 方法,試圖將 PEFT 統(tǒng)一到一個框架下,找出它們起作用的具體原因,并進行改進。主要研究了三個問題: ?
典型的PEFT方法有什么聯(lián)系?
典型的PEFT方法中是哪些關(guān)鍵模塊在起作用?
能否對這些關(guān)鍵模塊進行排列組合,找出更有用的 PEFT 方法?
5.1.1 通用形式

通過對 Prefix Tuning 的推導(dǎo),得出了和 Adapter Tuning 以及 LoRA 形式一致的形式。
更近一步地,可以將這些 Tuning 的方法統(tǒng)一在同一套框架下, ?
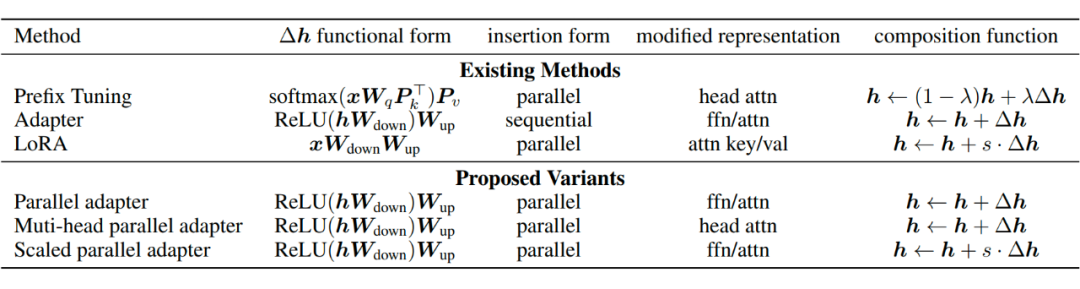
包括這幾大要素: ?
的形式
嵌入 Transformer 結(jié)構(gòu)的方式(分為 Parrell 和 Sequential 兩種。Parallel 指的是在輸入層嵌入,這樣與原有結(jié)構(gòu)可以并行計算;Sequential 指的是在輸出層嵌入,相當(dāng)于增加了網(wǎng)路的深度,與原有結(jié)構(gòu)存在依賴關(guān)系)
修改的表示層(主要指對 attention層的修改還是對 ffn 層的修改)
組合方式。怎么與原有的參數(shù)組合,包括簡單相加(Adapter)、門控式(Prefix Tuning)、縮放式(LoRA)三種)
根據(jù)這個統(tǒng)一的框架,還另外設(shè)計了三種變體Parallel Adapter、Multi-head Parallel Adapter、Scaled Parallel Adapter。 ?
5.1.2 一些實驗
哪種嵌入形式更好:Parallel or Sequencial?
答案是:Parallel 更好
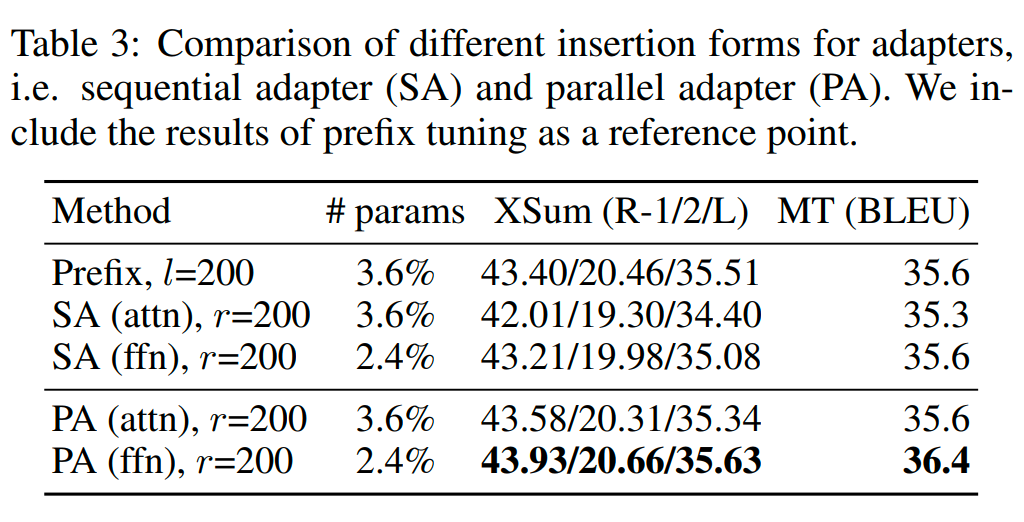
對哪塊結(jié)構(gòu)做修改更好?Attention or FFN?
當(dāng)微調(diào)的參數(shù)量較多時,從結(jié)果來看,對 FFN 層進行修改更好。一種可能的解釋是 FFN 層學(xué)到的是任務(wù)相關(guān)的文本模式,而 Attention 層學(xué)到的是成對的位置交叉關(guān)系,針對新任務(wù)并不需要進行大規(guī)模調(diào)整。
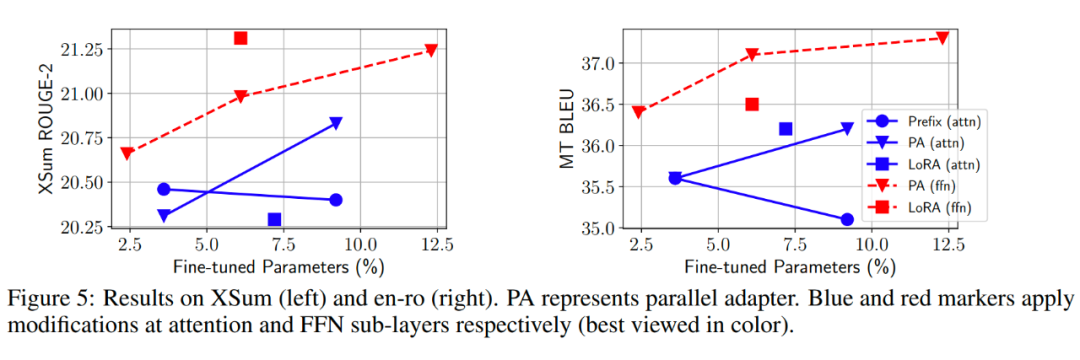
當(dāng)微調(diào)參數(shù)量較少(0.1%)時,對 Attention 進行調(diào)整效果更好。
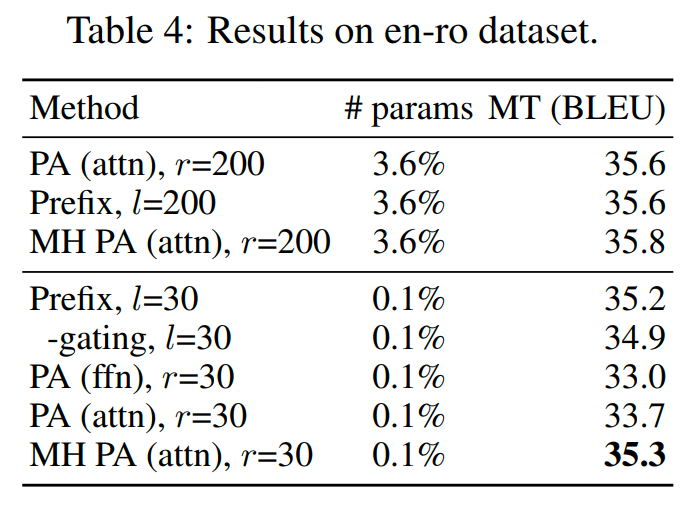
哪種組合方式效果更好? 從結(jié)果來看,縮放式的組合效果更好。
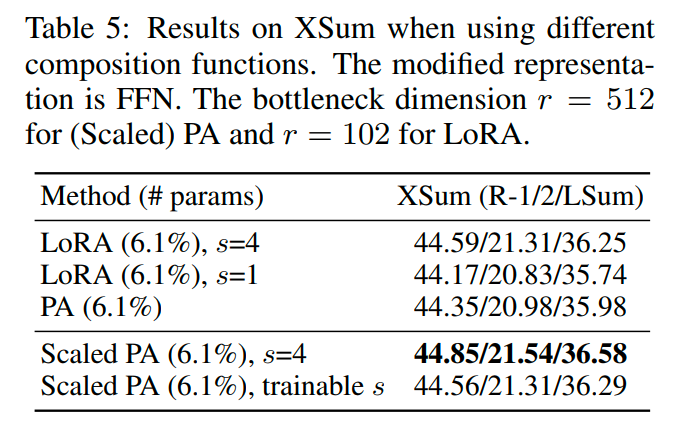
5.1.3 結(jié)論
基于以上的經(jīng)驗,
Scaled parallel adapter is the best variant to modify FFN
FFN can better utilize modification at larger capacities
modifying head attentions like prefix tuning can achieve strong performance with only 0.1% parameters
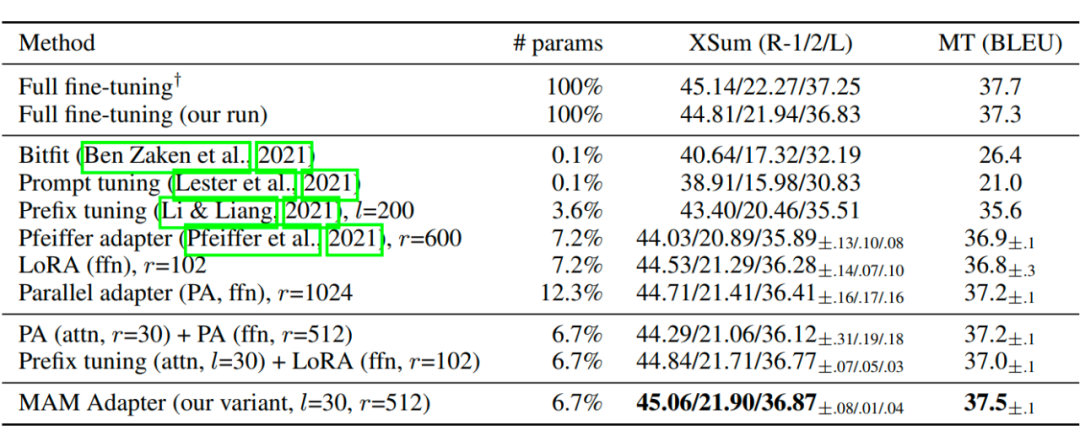
研究者設(shè)計出最新的結(jié)構(gòu) MAM Adapter,取得了最好的效果:
編輯:黃飛















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論