 電子發燒友App
電子發燒友App


ChatGPT浪潮,在各行各業引起了不小的顛覆,芯片驗證也不無例外。隨著芯片設計復雜度的不斷增加,交付周期越來越短。設計工程師可能需要花費將近一半的時間在功能驗證上。功能驗證本身具有計算和數據密集的性質,因此也成為了機器學習(ML)技術的理想領域,二者的融合交叉嘗試也一直沒有間斷。
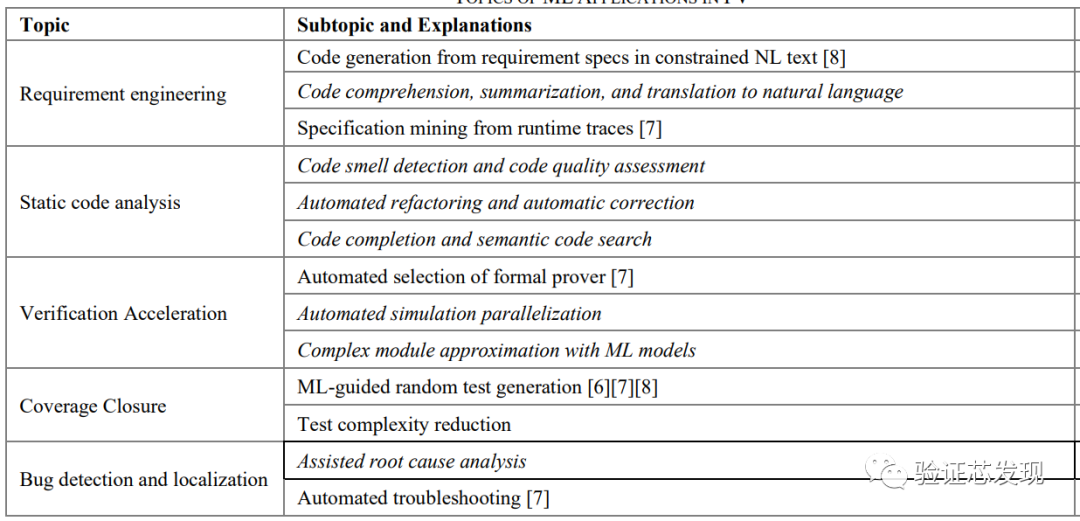
許多ML算法已經在功能驗證的不同領域進行了嘗試,并取得了不錯的效果。ML在功能驗證中的應用主要分為:需求工程、靜態代碼分析、驗證加速、覆蓋率收集和BUG的檢測及定位。
需求工程
需求工程(Requirement Engineering)一般指定義、文檔化和維護驗證需求的過程,這也是保證最終的設計符合spec的重要一環。
需求定義
需求定義(Requirement definition)將自然語言(NL)的驗證目標轉化為標準化的驗證規范。傳統的驗證flow需要多次手動校對以確保質量,借助機器學習,目前有兩種經典的方法進行自動化翻譯。
第一種方法是引入約束自然語言(CNL)進行描述需求,然后使用基于模板的翻譯引擎進行翻譯。只要CNL配套的工具足夠強大,CNL可以描述FV中遇到的大多數需求。但這需要開發人員學習新的語言,具有一定的門檻[9]。

第二種方法是使用經典的自然語言處理(NLP)來解析自然語言(NL)的需求,提取出關鍵要素[10]。隨著大模型的訓練和演進,后續可以直接將自然語言的需求翻譯為SystemVerilog、Assertions (SVA)、Property Specification Language (PSL)或其他語言。目前已經有一些端到端的翻譯嘗試,但離大規模使用還有比較大的gap,主要的障礙在于訓練數據集的稀缺[11]。
代碼總結和翻譯
Code summarization and translation to NL,與需求定義相反,將代碼翻譯成自然語言。可以幫助開發人員理解一些復雜的邏輯代碼,提升代碼的可維護性和可讀性。
但目前,IC設計驗證領域的Code summarization幾乎沒有嘗試。不過跨語言模型的發展或許有助于將其他編程語言的實踐經驗轉移至IC設計。需要注意的是,IC設計和驗證的code存在語義的并發,如fork,module等,這在其他語言中并不常見。
特性挖掘
特性挖掘(Specification mining)在軟件工程領域比較常見,Dallmeier、Valentin等人以及Wenchao、Forin和Seshia等人都曾對進行研究[14][15]。Specification mining從待測試設計(DUT)的執行中提取規范的方法,用于替代手寫spec的方法。機器學習可以從仿真中挖掘到某些重復的模式,可能是DUT的預期行為。此外很少出現的事件模式可以視為異常,也可用于debug和調試[16]。
Azeem等人提出了一種通用的軟件工程方法,利用機器學習來尋找spec,并找到可能存在問題的協議實現[17]。
代碼分析
芯片開發中的錯誤修復成本呈現一種指數級增長的規律,越是靠后的開發階段,其錯誤修復成本越高。因此靜態代碼分析(Static code analysis)可以作為設計開發早期階段的一種有效手段,用來改進代碼質量和可維護性。
代碼質量評價
Code smell detection and quality assessment.
Code smell指那些功能正確,但是維護性以及可讀性差,違反一些規范或者最佳實踐。典型的例子就是在多處重復編寫相同功能的代碼。
常見的code smell檢測,依賴于定義好的規則來識別源代碼中的問題。而機器學習的方法是,在大量可用的源代碼上進行訓練,以識別出code smell的模式,而不是手動編寫這些規則或指標。Fontana等和Aniche等所述的研究表明,使用機器學習的方法可以顯著減少模式實現的工作量[18][19],并幫助開發人員持續改進產品質量。此外,基于機器學習的代碼重構可以為改善code smell提供有用的提示,甚至進一步提供更改方案。

遺憾的是,這方面的應用在FV中還不太明顯,而且缺乏大規模的訓練數據集也是其重要的阻礙因素。
輔助編碼
簡單的代碼補全或者提示是集成開發環境(IDE)的標準功能,開發人員的效率也可以得到提升。而深度學習則提出了更高級的技術[21],并且正在快速迭代成熟[22]。現在可以從許多大規模開源代碼庫中訓練具有數十億個參數的人工神經網絡(ANN),并給出開發人員實現意圖或基于上下文的合理代碼片段的建議。
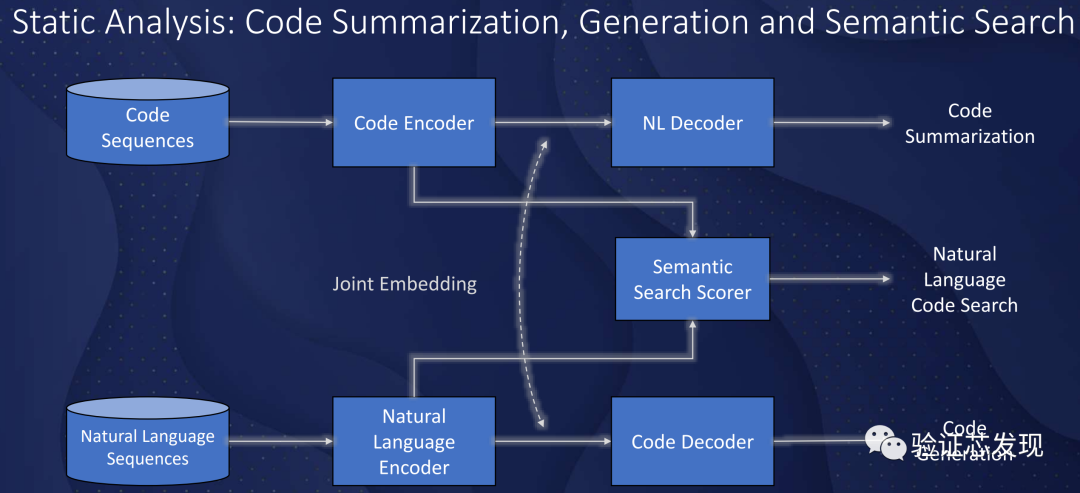
ML也有可能幫助IC開發人員通過語義代碼來進行搜索,通過自然語言查詢來檢索相關代碼[23]。雖然理論上,應用于其他編程語言的相同ML技術可以應用于IC設計,但目前還沒有相關的研究。
驗證加速
Verification Acceleration包括Formal和Simulation-based兩種。
Formal verification
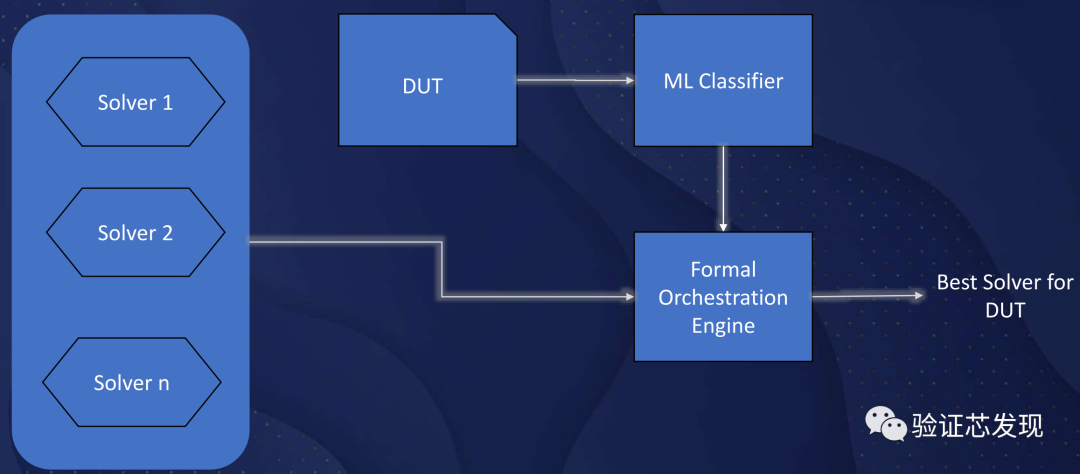
Formal使用形式化數學算法來證明設計的正確性。作為一種統計方法,機器學習雖然不能直接解決Formal驗證的復雜度問題,但是在資源調度方面很有幫助。通過預測計算資源和解決問題的概率,然后以最佳方式利用這些資源來縮短驗證時間 [25],即先調度具有更低計算資源消耗、可求解成功的任務。基于Ada-boost決策樹的分類器可以將成功解決的比例從95%提高到97%,平均加速1.85倍。[25]中的另一個實驗能夠預測Formal驗證的資源需求,平均誤差為32%。
Simulation-based verification
和Formal驗證不同,simulation通過對DUT添加隨機或固定模式的激勵,把DUT輸出和參考輸出進行比較,以驗證設計行為的正確性。基于simulation的功能驗證也是芯片開發流程中耗時較長的一步。
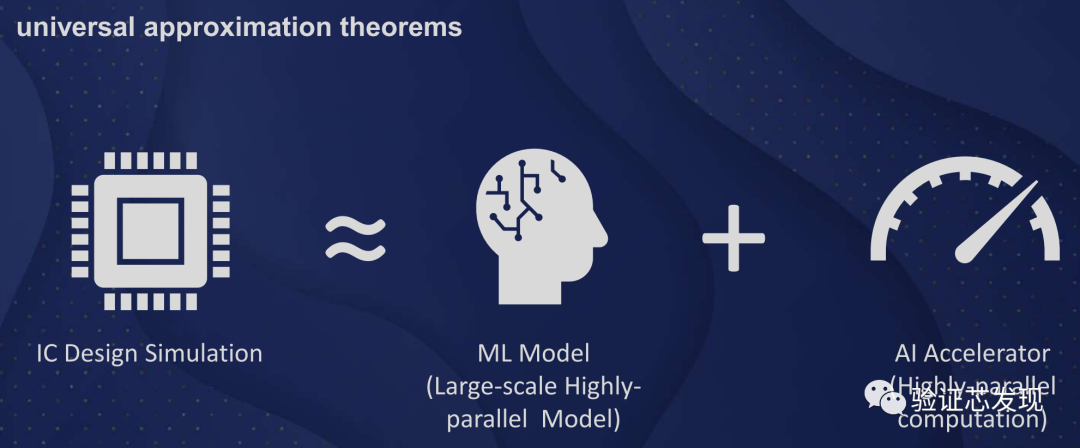
機器學習在該領域的一個可能思路是對復雜系統的行為進行建模和預測。多層感知器(MLP)(一種至少具有一個隱藏層的前饋人工神經網絡)可以以任意精度逼近任何連續函數。而標準化循環神經網絡(RNNs)(一種特殊形式的人工神經網絡)則可以逼近任何具有存儲器的動態系統。先進的機器學習可以使人工神經網絡可以對一些IC設計模塊的行為進行建模,以加速其仿真。根據人工智能加速器的能力和機器學習模型的復雜性,可能會實現顯著的加速。
測試激勵產生和覆蓋率收集
在simulation中,除了手工編寫測試用例外,還有較為常見的受限隨機測試方法,以及基于圖形化的測試平臺生成技術。覆蓋率在驗證前期會增長很快,但也存在“長尾”效應。最后20%的覆蓋率閉環,可能需要80%的資源消耗。所以機器學習在這方面的應用,也都集中在如何提升覆蓋率的收集速度。
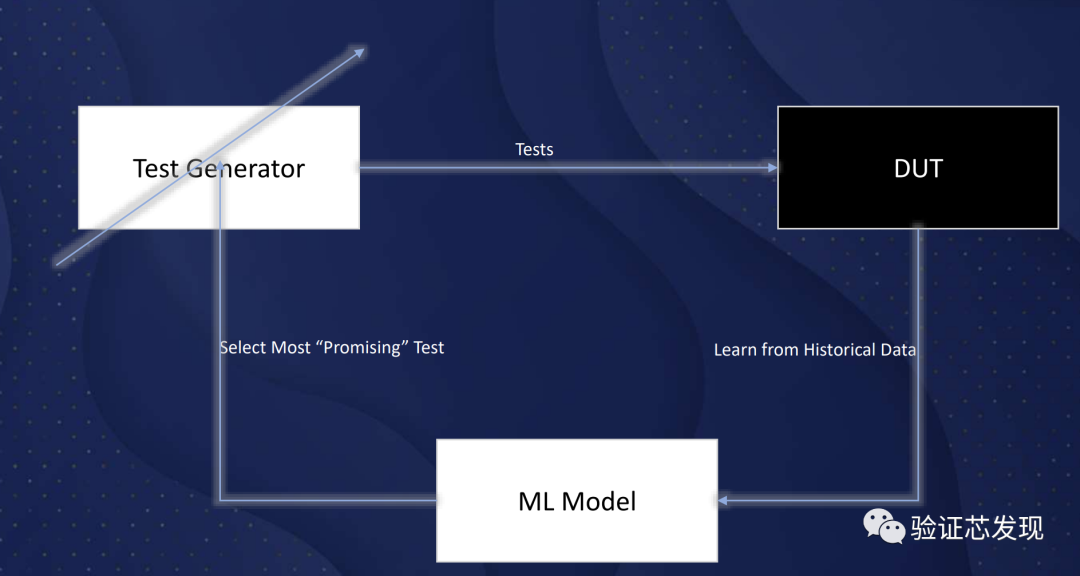
一些研究表明引入機器學習,可以獲取比隨機測試更有效的case。大多數研究也都是基于“黑盒模型”,假設DUT是一個黑盒,其輸入有測試激勵控制,并監測輸出。其重點是從歷史輸入/輸出/觀測數據中學習,進而調整隨機測試生成器或減少不必要的測試上,而不是試圖學習DUT的行為。
在[31]的研究中,使用基于強化學習(RL)的模型來從DUT的輸出中學習并預測緩存控制器的最有效的case。當ML模型給出的反饋是FIFO深度時,模型能夠從歷史結果中學習,并在幾次迭代中達到FIFO深度的全覆蓋,明顯優于基于隨機測試的方法。但文中沒有進一步實驗證明在更復雜的設計中的表現,在較為復雜的設計中,反饋不容易定義。
[28]引入了一個更精細的ML架構,對每個覆蓋點都訓練一個ML模型。還采用了三進制分類器:是否應模擬測試、丟棄或用于進一步訓練模型。使用支持向量機(SVM)、隨機森林和深度神經網絡對CPU設計進行了實驗,結果表明,達到100%的覆蓋率時,模型能夠減少67% ~ 80%的case數量。對存在狀態機設計的結果表明,與定向序列生成相比,減少了69%和72%。
但是,上面的這些研究都僅針對自有的設計進行,其模型的訓練結果無法作為先驗知識,被其他模型使用。其原因也是模型的訓練數據不可用。
Bug analysis
Bug analysis是指找出潛在的bug,定位包含bug的代碼塊,并提供修改建議。機器學習已用于幫助開發人員識別設計中的bug,并更快地修復bug。Bug analysis需要解決三個問題:通過其根本原因進行bug聚類、分類根本原因和提供修改建議。大部分的研究集中在前兩個問題上,還沒有第三個問題的研究結果。
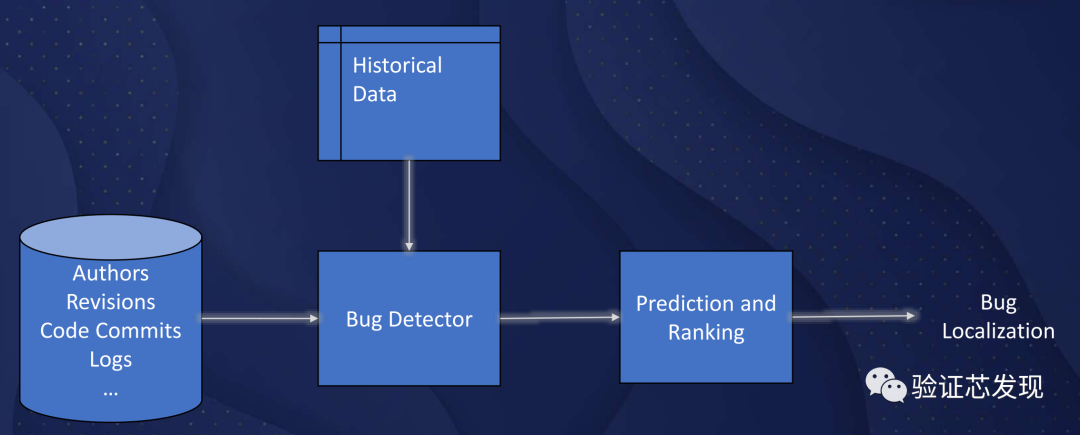
在研究[34]中的方法,使用半結構化的模擬日志文件。它從日志文件中提取元數據和消息行的616個不同特征。機器學習可以預測哪些提交最有可能包含bug,可以顯著減少手動bug-hunting的時間。但是,由于采用的ML技術一般相對簡單,無法兼顧代碼中多樣化的語義,以及無法從歷史bug修復中學習。因此,這些模型一般也無法解釋bug發生的原因和方式,無法自動或半自動地修復bug。
ML前沿技術及其在FV中的應用
近年來,機器學習技術、模型和算法方面取得了重大突破。如果將這些新興技術引入到FV中,則有希望可以解決FV面臨的諸多難題。基于大量文本語料庫訓練出的具有數十億參數的自然語言處理模型,表現出接近或超過人類水平的性能,例如問答、機器翻譯、文本分類、概括性總結等。
在代碼分析中應用這些研究成果,也展示了這些模型的優勢[12][24]。這些模型可以吸收大量的訓練數據,將所學習的知識進行結構化,并提供易于訪問的方式。這種能力在靜態代碼分析、需求工程和代碼輔助工具中是非常重要。
圖形神經網絡(GNN)的進展為FV帶來了新的機遇[33]。其研究將設計轉換成一種代碼/數據流圖,然后進一步使用GNN來幫助預測case的覆蓋率。這種白盒方法可以洞悉設計中的控制和數據流,從而生成針對性的測試。圖形可以表示在驗證過程中遇到的復雜多樣化的關系、結構和語義信息。進而通過在圖上訓練機器學習模型,可以為許多FV問題提供解決方案,例如bug analysis和coverage closure。
大規模開源驗證數據現狀
盡管在 FV 中應用機器學習取得了一些不錯的研究成果,但要實現成熟和大規模的應用,還必須解決許多難題。其中最大的挑戰是缺乏訓練數據集。
由于缺乏大型數據集,許多研究只能采用相對原始的機器學習技術,這些技術只需要數百個樣本的小型訓練數據集。這種情況不利于高級機器學習技術和算法的應用。IC設計一直以來是私有化的,設計及其關聯的驗證數據(包括驗證計劃、仿真設置、斷言、回歸結果、仿真日志、覆蓋數據、跟蹤文件、修訂和提交)都是其公司內部的商業秘密數據。一項調查顯示,典型的機器學習項目會花費團隊高達70%的時間用于數據準備。包括數據清理、報告和可視化。
缺乏高質量的訓練數據和高成本的數據準備是研究 FV 的機器學習面臨的重大障礙。目前很少有研究人員愿意公開分享他們的數據、代碼或機器學習模型,因此其研究結果難以被其他研究人員重復或驗證。
在2022年5月在GitHub、RISC-V和OpenCores上的搜索結果,在開源可用的設計數據有限,驗證數據更少。

共約1000萬行代碼和注釋,這個規模幾乎無法與其他流行編程語言中的數百萬個項目和數十億行源代碼相比。更重要的是,與驗證相關的數據非常稀缺。即使可以從源代碼集中生成驗證數據,但也必須投入巨大的人力來進行仿真驗證,以提取有效數據。

業界觀察
如果機器學習能在FV中的成功應用,除了數據的稀缺性問題外,還有幾個問題需要解決。
模型泛化是許多機器學習研究結果中最常見的挑戰之一。泛化能力衡量了將訓練出來的模型應用于新問題時的易用性。在特定類型的設計、編碼風格、某些特定項目或某些小眾數據的數據集上訓練出的模型,可能無法很好地適用于其他領域。如果模型無法做到很好的泛化能力,其工業應用價值非常有限。

模型的可擴展性是另一個挑戰。一個模型可能在相對簡單的設計中表現得很好。然而,無法保證它在應用于數十億個RTL門的大型設計,以及來自多個開發團隊的代碼時能夠同樣有效。模型壓縮投入、額外的計算資源,都是引入機器學習需要考慮的成本。
第三個挑戰與機器學習應用中的數據管理有關。在實際應用中,用于訓練機器學習模型的數據集所有者、FV工具開發者和工具用戶可能屬于不同的組織。結合計算能力的分布和 MLOps 專業知識的可用性,他們共同決定了選擇哪些機器學習模型。例如,數據私有化,而且沒有機器學習基礎設施的組織,可能無法使用需要大量計算的機器學習模型。
總結
FV本質上是一個數據分析問題,盡管使用了不同的機器學習技術,但研究大多仍采用原始的機器學習技術,并受到訓練數據規模的限制。目前的機器學習應用還沒有完全利用許多語義、關系和結構信息,開源和高質量的訓練數據可能是目前遇到的最大問題。機器學習在FV領域的應用是非常有希望的,前途是光明的,不過目前距離大規模的應用,還須更多努力。

本文譯自于:DVCov US 2023:A Survey of Machine Learning Applications in Functional Verification.
編輯:黃飛
?












 工商網監
工商網監
評論