 電子發燒友App
電子發燒友App


最近大模型發展卷的很,王慧文都被整抑郁了。想要研究學習大模型,應該從哪里開始呢?
目前大模型發展生態最好的當屬Meta的LLaMA模型。如果GPT系列是Windows操作系統(巧了,OpenAI的大東家目前就是微軟),那么LLaMA就是Linux。如果GPT系列是蘋果手機,那么LLaMA就是安卓。如果你想基于大模型做一些事情,無論是創業還是研究,最好選擇一個生態好的模型,畢竟有人用才有市場。
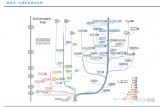
ChatGPT演化的路徑如下圖所示。

圖片中分了4個階段,但是第三個和第四個階段一般都會放在一起,屬于對齊階段。所以一般會分成如下3個階段:
Stage 1: 預訓練(Pretrain)
Stage 2: 監督微調(SFT)
Stage 3: 對齊(Reward Model + RLHF)
既然已經有了成功ChatGPT這一成功的案例,大家都想基于LLaMA把這條路再走一遍,以期望做出自己的ChatGPT。
所以基于LLaMA的模型雖然很多,但是基本都可以放到上面3個框架當中。本文就沿著預訓練、監督微調、對齊(RW+RLHF)這一路徑來梳理一下LLaMA生態中的各個模型。
主要是點出這些模型處在大模型訓練的那一個階段,以及都做了哪些創新性的工作,方便你根據自己的興趣和資源來選擇使用哪一個,對中文支持比較好的也都有注明。
Stage1 預訓練: LLaMA 復現
RedPajama
參考LLaMA論文中的訓練數據,收集并且開源可商用。
https://github.com/togethercomputer/RedPajama-Data
Baichuan-7B(支持中文)
采用LLaMA的相同架構,在中文上做預訓練。可商用。
王小川這次做大模型的切入點其實挺不錯的,綁定到LLaMA的生態上,然后在中文上有所突破。可能也在構思新三級火箭了吧。
目前Baichuan可以算是第一個LLaMA中文預訓練模型,所以后面的工作都可以在這上面都走一遍,估計沒多久Baichuan-Alapca, Baichuan-Vicuna就都出來了。
https://github.com/baichuan-inc/baichuan-7B
OpenLLaMA
參考LLaMA的代碼,在Apache 2.0 license下的重新實現和訓練。使用了RedPajama訓練集合。
https://github.com/openlm-research/open_llama
Lit-LLaMA
參考LLaMA,在Apache 2.0 license下的只有代碼的重新實現。同時支持加載原始LLaMA和OpenLLaMA的權重。
https://github.com/Lightning-AI/lit-llama
Stage 2: 監督微調
因為預訓練模型本質上還是個續寫模型,所以并不能很好的滿足人們的需求,所以監督微調的作用就是微調模型產生理想的回復。
在監督微調這里,大家目標都是一樣的,但是做法有些不同,主要是有錢和沒錢的區別。
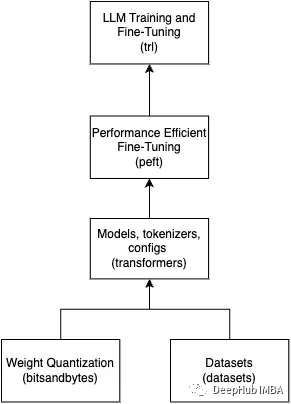
有錢你可以全參數微調,沒錢就只能使用一些低成本的方法,英文叫PEFT(Parameter-Efficient Fine-Tuning)。
PEFT確實是想我這種平民玩家的首選,但是有錢也可以用PEFT,它可以讓你微調更大的模型。比如我們就只能玩玩10B的,有點小錢用PEFT玩個幾十B的問題不大。
2.1 LLaMA + Instruction Finetuning(全量參數)
Alpaca
llama7b + self-instruct數據指令微調。算是最早邁出LLaMA+SFT這一步的模型。最開始并沒有提供權重,后來通過diff的方式給出,需要LLaMA原始模型才能恢復,github上有教程。
當時他們采用1張8卡A100(80G顯存),52k的數據,訓練了3個小時。訓練成本大概是100刀。
https://github.com/tatsu-lab/stanford_alpaca
Alpaca衍生模型
BELLE(支持中文): 最早是基于BLOOM的,后來也支持LLaMA https://github.com/LianjiaTech/BELLE
openAlpaca: OpenLLaMA + databricks-dolly-15k dataset 進行指令微調 https://github.com/yxuansu/OpenAlpaca
gpt4-x-alpaca: 用GPT4的數據微調,數據集為GPTeacher https://huggingface.co/chavinlo/gpt4-x-alpaca
Vicuna
llama13b + ShareGPT對話數據,微調
研發團隊基于Vicuna發布了FastChat對話機器人。
和Alpaca一樣,受協議限制,vicuna模型公布的權重也是個delta,每個參數要加上llama原來的權重才是模型權重。
https://github.com/lm-sys/FastChat
Vicuna衍生模型
gpt4-x-vicuna-13b: 用GPT4的數據微調,數據集為GPTeacher https://huggingface.co/NousResearch/gpt4-x-vicuna-13b
WizardLM
采用了Evol-Instruct來構造指令,可以產生一些很難的指令.
深度演化包括五種操作:添加約束、深化、具體化、增加推理步驟并使輸入復雜化。
In-breadth Evolving 是突變,即根據給定的指令生成全新的指令
進化是通過提示+LLM來實現的。
https://github.com/nlpxucan/WizardLM
TüLU
使用LLaMA + Human/GPT data mix 微調
驗證了很多結論,論文值得一看。https://arxiv.org/abs/2306.04751
https://github.com/allenai/open-instruct
GPT4ALL
LLaMA用80w的GPT3.5的數據(code, story, conversation)微調而來。
https://github.com/nomic-ai/gpt4all
Koala
LLaMA13B基于ChatGPT Distillation Data和Open Source Data訓練而來。
具體數據見下面:
https://bair.berkeley.edu/blog/2023/04/03/koala/
OpenBuddy(支持中文)
基于LLaMA,Falcon, OpenLLaMA微調的,只說用了對話數據,細節沒透漏。
https://github.com/OpenBuddy/OpenBuddy
Pygmalion 7B
給予LLaMA微調,使用了不同來源的56MB 的對話數據,包含了人工和機器。
https://huggingface.co/PygmalionAI/pygmalion-7b
2.2 LLaMA + PEFT
PEFT目前最流行的是LoRA,挺巧妙的架構,可以看看https://arxiv.org/abs/2106.09685。
下面大多數的模型都是LLaMA+lora的架構,不只是文本,AIGC的頭部網站civitai.com上很多模型也都是基于lora的。
最近還出了QLoRA,在LoRA的基礎上加入了量化,進一步降低顯存的使用。https://arxiv.org/abs/2305.14314。
Baize
LLaMA + Lora
https://github.com/project-baize/baize-chatbot
LLaMA-Adapter
LLaMA + Adapter Layer
https://github.com/OpenGVLab/LLaMA-Adapter
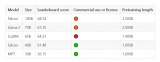
CalderaAI/30B-Lazarus
似乎是多個LoRA的merge,但是沒太公布太多細節。
在huggingface的leaderboard上排名還挺靠前。
https://huggingface.co/CalderaAI/30B-Lazarus
Chinese-LLaMA-Alpaca(支持中文)
https://arxiv.org/pdf/2304.08177.pdf
LLaMA + 擴詞表 + lora
Chinese LLaMA是屬于局部參數預訓練
Stage1: frozen encoder,只用來訓練Embedding層。
Stage2: 只訓練Embedding, LM head, lora weights
在Chinese LLaMA的基礎上,仿照Alpaca訓練了Chinese Alpaca
https://github.com/ymcui/Chinese-LLaMA-Alpaca
Chinese-Vicuna(支持中文)
基于:https://github.com/tloen/alpaca-lora
lora + 中文instruction數據
chatv1的數據使用了50k中文指令+對話混合數據。
并沒有擴充詞表,據說Vicuna1.1并沒有擴充詞表,但是中文效果不錯。
https://github.com/Facico/Chinese-Vicuna
Stage 3: 對齊(LLaMA + FT + RHLF)
這部分可以說是把ChatGPT的路徑完整走了一遍。
StableVicuna
Vicuna = LLaMA + FT
StableVicuna = Vicuna + RLHF
https://github.com/Stability-AI/StableLM
StackLLaMA
SFT: LLaMA + Lora
RM: LLaMA + Lora + 分類
https://huggingface.co/blog/zh/stackllama
其他:LLaMA 推理優化
llama.cpp
用C/C++實現的推理,不依賴顯卡。
https://github.com/ggerganov/llama.cpp
GPTQ-for-LLaMA
4 bits quantization of LLaMA using GPTQ.
https://github.com/qwopqwop200/GPTQ-for-LLaMa
進NLP群—>加入NLP交流群
原文標題:其他:LLaMA 推理優化
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
?
































 工商網監
工商網監
評論