 電子發燒友App
電子發燒友App


前言
MMPose是一款基于PyTorch的姿態分析開源工具箱,是OpenMMLab項目成員之一,主要特性:
支持多種人體姿態分析相關任務:2D多人姿態估計、2D手部姿態估計、動物關鍵點檢測等等
更高的精度和更快的速度:包括“自頂向下”和“自底向上”兩大類算法
支持多樣的數據集:支持了很多主流數據集的準備和構建,如 COCO、 MPII等
模塊化設計:將統一的人體姿態分析框架解耦成不同的模塊組件,通過組合不同的模塊組件,可以便捷地構建自定義人體姿態分析模型
本文主要對動物關鍵點檢測模型進行微調與測試,從數據集構造開始,詳細解釋各模塊作用。對一些新手可能會犯的錯誤做一些說明
環境配置
mmcv的安裝方式在我前面的mmdetection和mmsegmentation教程中都有寫到。這里不再提
MMPose安裝方法最好是使用git,如果沒有git工具,可以使用mim install mmpose
最后在項目文件夾下新建checkpoint、outputs、data文件夾,分別用來存放模型預訓練權重、模型輸出結果、訓練數據
from IPython import display !pip install openmim !pip install -q /kaggle/input/frozen-packages-mmdetection/mmcv-2.0.1-cp310-cp310-linux_x86_64.whl !git clone https://github.com/open-mmlab/mmdetection.git %cd mmdetection !pip install -e . %cd .. !git clone https://github.com/open-mmlab/mmpose.git %cd mmpose !pip install -e . !mkdir checkpoint !mkdir outputs !mkdir data display.clear_output()
在上面的安裝工作完成后,我們檢查一下環境,以及核對一下安裝版本
from IPython import display
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print('MMCV版本', mmcv.__version__)
%cd /kaggle/working/mmdetection
import mmdet
print('mmdetection版本', mmdet.__version__)
%cd /kaggle/working/mmpose
import mmpose
print('mmpose版本', mmpose.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('編譯器版本', get_compiler_version())
輸出:
MMCV版本 2.0.1 /kaggle/working/mmdetection mmdetection版本 3.1.0 /kaggle/working/mmpose mmpose版本 1.1.0 CUDA版本 11.8 編譯器版本 GCC 11.3
?為方便后續進行文件操作,導入一些常用庫
import os import io import json import shutil import random import numpy as np from pathlib import Path from PIL import Image from tqdm import tqdm from mmengine import Config from pycocotools.coco import COCO
預訓練模型推理
在進行姿態估計前需要目標檢測將不同的目標檢測出來,然后再分別對不同的目標進行姿態估計。所以我們要選擇一個目標檢測模型。
這里選擇的是mmdetection工具箱中的RTMDet模型,型號選擇RTMDet-l。配置文件位于mmdetection/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py,我們復制模型權重地址并進行下載。
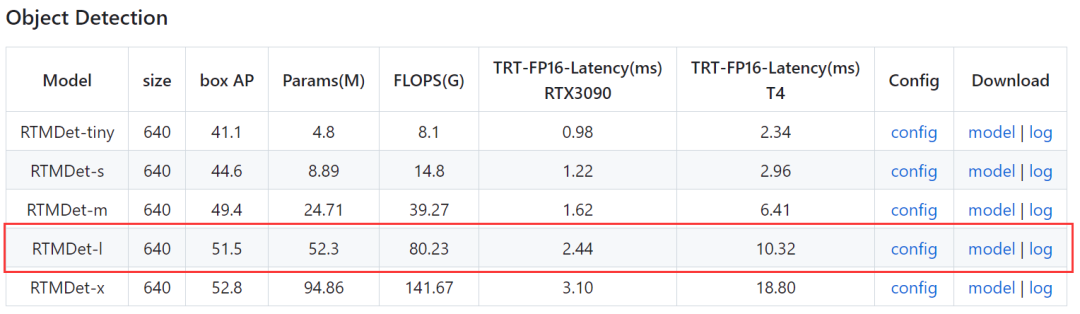
姿態估計模型選擇RTMPose模型,打開mmpose項目文件夾projects/rtmpose/README.md文檔,發現RTMPose模型動物姿態估計(Animal 2d (17 Keypoints))僅提供了一個預訓練模型。
配置文件位于projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py,我們復制模型權重地址并進行下載。

將預訓練權重模型全部放入mmpose項目文件夾的checkpoint文件夾下。
# 下載RTMDet-L模型,用于目標檢測 !wget https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_l_8xb32-300e_coco/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth -P checkpoint # 下載RTMPose模型,用于姿態估計 !wget https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth -P checkpoint display.clear_output()
MMPose提供了一個被稱為MMPoseInferencer的、全面的推理API。這個API使得用戶得以使用所有MMPose支持的模型來對圖像和視頻進行模型推理。此外,該API可以完成推理結果自動化,并方便用戶保存預測結果。
我們使用Cat Dataset數據集中的一張圖片作為示例,進行模型推理。推理參數說明:
det_model:mmdetection工具箱中目標檢測模型配置文件
det_weights:mmdetection工具箱中目標檢測模型對應預訓練權重文件
pose2d:mmpose工具箱中姿態估計模型配置文件
pose2d_weights:mmpose工具箱中姿態估計對應預訓練權重文件
out_dir:圖片生成的文件夾
from mmpose.apis import MMPoseInferencer img_path = '/kaggle/input/cat-dataset/CAT_00/00000001_012.jpg' # 使用模型別名創建推斷器 inferencer = MMPoseInferencer(det_model = '/kaggle/working/mmdetection/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py', ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?det_weights = 'checkpoint/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth', ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?pose2d = 'projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py', ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?pose2d_weights = 'checkpoint/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth') # MMPoseInferencer采用了惰性推斷方法,在給定輸入時創建一個預測生成器 result_generator = inferencer(img_path, out_dir = 'outputs', show=False) result = next(result_generator) display.clear_output()
可視化推理結果
import matplotlib.pyplot as plt
img_og = mmcv.imread(img_path)
img_fuse = mmcv.imread('outputs/visualizations/00000001_012.jpg')
fig, axes = plt.subplots(1, 2, figsize=(15, 10))
axes[0].imshow(mmcv.bgr2rgb(img_og))
axes[0].set_title('Original Image')
axes[0].axis('off')
axes[1].imshow(mmcv.bgr2rgb(img_fuse))
axes[1].set_title('Keypoint Image')
axes[1].axis('off')
plt.show()
數據處理
數據內容詳解
Cat Dataset包含9000多張貓圖像。對于每張圖像,都有貓頭部的注釋,有9個點,2個用于眼睛,1個用于嘴巴,6個用于耳朵。
注釋數據存儲在1個文件中,文件名是相應的圖像名稱,末尾加上“cat”。每張貓圖像都有1個注釋文件。對于每個注釋文件,注釋數據按以下順序存儲:
?○Number of points (關鍵點數目)
?○Left Eye(左眼)
?○Right Eye(右眼)
?○Mouth(嘴)
?○Left Ear-1(左耳-1)
?○Left Ear-2(左耳-2)
?○Left Ear-3(左耳-3)
?○Right Ear-1(右耳-1)
?○Right Ear-2(右耳-2)
?○Right Ear-3(左耳-3)
數據集最初在互聯網檔案館中找到,網站(https://archive.org/details/CAT_DATASET)
數據層級目錄如下所示:
- CAT_00 ? ? - 00000001_000.jpg ? ? - 00000001_000.jpg.cat ? ? - 00000001_005.jpg ? ? - 00000001_005.jpg.cat ? ? - ... - CAT_01 ? ? - 00000100_002.jpg ? ? - 00000100_002.jpg.cat ? ? - 00000100_003.jpg ? ? - 00000100_003.jpg.cat - CAT_02 - CAT_03 - CAT_04 - CAT_05 - CAT_06
總的來說,一共有7個文件夾,每個文件夾里面有若干.jpg格式的圖片文件,且對應有.cat格式的注釋文件,.cat文件可以看做是文本文件,內容示例:
9 435 322 593 315 524 446 318 285 283 118 430 195 568 186 701 81 703 267?
除第1個數字9表示有9個關鍵點,后面每2個點表示1個部位的坐標(x,y),所以一共有1 + 2 * 9 = 19個點
文件夾規整
我們將數據集中的7個文件夾中的圖片與注釋文件分開,分別存儲在mmpose項目文件夾data文件夾中,并分別命名為images、ann
def separate_files(og_folder, trans_folder): ? ?image_folder = os.path.join(trans_folder, 'images') ? ?ann_folder = os.path.join(trans_folder, 'ann') ? ?os.makedirs(image_folder, exist_ok=True) ? ?os.makedirs(ann_folder, exist_ok=True) ? ?for folder in os.listdir(data_folder): ? ? ? ?folder_path = os.path.join(data_folder, folder) ? ? ? ?if os.path.isdir(folder_path): ? ? ? ? ? ?for file in os.listdir(folder_path): ? ? ? ? ? ? ? ?if file.endswith('.jpg'): ? ? ? ? ? ? ? ? ? ?source_path = os.path.join(folder_path, file) ? ? ? ? ? ? ? ? ? ?target_path = os.path.join(image_folder, file) ? ? ? ? ? ? ? ? ? ?shutil.copy(source_path, target_path) ? ? ? ? ? ? ? ?elif file.endswith('.cat'): ? ? ? ? ? ? ? ? ? ?source_path = os.path.join(folder_path, file) ? ? ? ? ? ? ? ? ? ?target_path = os.path.join(ann_folder, file) ? ? ? ? ? ? ? ? ? ?shutil.copy(source_path, target_path) data_folder = '/kaggle/input/cat-dataset' trans_folder = './data' separate_files(data_folder, trans_folder)
構造COCO注釋文件
本質上來說COCO就是1個字典文件,第1級鍵包含images、annotations、categories。
?○其中images包含id(圖片的唯一標識,必須要是數值型,不能有字符) 、file_name(圖片名字)、?height(圖片高度),?width(圖片寬度)這些信息
?○其中annotations包含category_id(圖片所屬種類)、segmentation(實例分割掩碼)、iscrowd(決定是RLE格式還是polygon格式)、image_id(圖片id,對應images鍵中的id)、id(注釋信息id)、bbox(目標檢測框,[x, y, width, height])、?area(目標檢測框面積)、num_keypoints(關鍵點數量),?keypoints(關鍵點坐標)
?○其中categories包含supercategory、id(類別id)、name(類別名)、keypoints(各部位名稱)、skeleton(部位連接信息)
?○更詳細的COCO(https://zhuanlan.zhihu.com/p/29393415)注釋文件解析推薦博客COCO數據集的標注格式、如何將VOC XML文件轉化成COCO數據格式(https://www.cnblogs.com/marsggbo/p/11152462.html)
?○構造read_file_as_list函數,將注釋文件中的坐標變成[x,y,v],v為0時表示這個關鍵點沒有標注,v為1時表示這個關鍵點標注了但是不可見(被遮擋了),v為2時表示這個關鍵點標注了同時可見。因為數據集中部位坐標均標注且可見,所以在x,y坐標后均插入2。
def read_file_as_list(file_path): ? ?with open(file_path, 'r') as file: ? ? ? ?content = file.read() ? ? ? ?key_point = [int(num) for num in content.split()] ? ? ? ?key_num = key_point[0] ? ? ? ?key_point.pop(0) ? ? ? ?for i in range(2, len(key_point) + len(key_point)//2, 2 + 1): ? ? ? ? ? ?key_point.insert(i, 2) ? ?return key_num,key_point
構造get_image_size函數,用于獲取圖片寬度和高度。
def get_image_size(image_path): ? ?with Image.open(image_path) as img: ? ? ? ?width, height = img.size ? ?return width, height
因為數據集沒有提供目標檢測框信息,且圖片中基本無干擾元素,所以將目標檢測框信息置為[0, 0, width, height]即整張圖片。相應的目標檢測框面積area = width * height。
# 轉換為coco數據格式
def coco_structure(ann_dir,image_dir):
? ?coco = dict()
? ?coco['images'] = []
? ?coco['annotations'] = []
? ?coco['categories'] = []
? ?coco['categories'].append(dict(supercategory = 'cat',id = 1,name = 'cat',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? keypoints = ['Left Eye','Right Eye','Mouth','Left Ear-1','Left Ear-2','Left Ear-3','Right Ear-1','Right Ear-2','Right Ear-3'],
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? skeleton = [[0,1],[0,2],[1,2],[3,4],[4,5],[5,6],[6,7],[7,8],[3,8]]))
? ?ann_list = os.listdir(ann_dir)
? ?id = 0
? ?for file_name in tqdm(ann_list):
? ? ? ?key_num,key_point = read_file_as_list(os.path.join(ann_dir, file_name))
? ? ? ?if key_num == 9:
? ? ? ? ? ?image_name = os.path.splitext(file_name)[0]
? ? ? ? ? ?image_id = os.path.splitext(image_name)[0]
? ? ? ? ? ?height, width = get_image_size(os.path.join(image_dir, image_name))
? ? ? ? ? ?image = {"id": id, "file_name": image_name, "height": height, "width": width}
? ? ? ? ? ?coco['images'].append(image)
? ? ? ? ? ?key_dict = dict(category_id = 1, segmentation = [], iscrowd = 0, image_id = id,
? ? ? ? ? ? ? ? ? ?id = id, bbox = [0, 0, width, height], area = width * height, num_keypoints = key_num, keypoints = key_point)
? ? ? ? ? ?coco['annotations'].append(key_dict)
? ? ? ? ? ?id = id + 1
? ?return coco
寫入注釋信息,并將其保存為mmpose項目文件夾data/annotations_all.json文件
ann_file = coco_structure('./data/ann','./data/images')
output_file_path = ?'./data/annotations_all.json'
with open(output_file_path, "w", encoding="utf-8") as output_file:
? ?json.dump(ann_file, output_file, ensure_ascii=True, indent=4)
拆分訓練、測試數據
按0.85、0.15的比例將注釋文件拆分為訓練、測試文件
def split_coco_dataset(coco_json_path: str, save_dir: str, ratios: list, ? ? ? ? ? ? ? ? ? ? ? shuffle: bool, seed: int): ? ?if not Path(coco_json_path).exists(): ? ? ? ?raise FileNotFoundError(f'Can not not found {coco_json_path}') ? ?if not Path(save_dir).exists(): ? ? ? ?Path(save_dir).mkdir(parents=True) ? ?ratios = np.array(ratios) / np.array(ratios).sum() ? ?if len(ratios) == 2: ? ? ? ?ratio_train, ratio_test = ratios ? ? ? ?ratio_val = 0 ? ? ? ?train_type = 'trainval' ? ?elif len(ratios) == 3: ? ? ? ?ratio_train, ratio_val, ratio_test = ratios ? ? ? ?train_type = 'train' ? ?else: ? ? ? ?raise ValueError('ratios must set 2 or 3 group!') ? ?coco = COCO(coco_json_path) ? ?coco_image_ids = coco.getImgIds() ? ?val_image_num = int(len(coco_image_ids) * ratio_val) ? ?test_image_num = int(len(coco_image_ids) * ratio_test) ? ?train_image_num = len(coco_image_ids) - val_image_num - test_image_num ? ?print('Split info: ====== ' ? ? ? ? ?f'Train ratio = {ratio_train}, number = {train_image_num} ' ? ? ? ? ?f'Val ratio = {ratio_val}, number = {val_image_num} ' ? ? ? ? ?f'Test ratio = {ratio_test}, number = {test_image_num}') ? ?seed = int(seed) ? ?if seed != -1: ? ? ? ?print(f'Set the global seed: {seed}') ? ? ? ?np.random.seed(seed) ? ?if shuffle: ? ? ? ?print('shuffle dataset.') ? ? ? ?random.shuffle(coco_image_ids) ? ?train_image_ids = coco_image_ids[:train_image_num] ? ?if val_image_num != 0: ? ? ? ?val_image_ids = coco_image_ids[train_image_num:train_image_num + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? val_image_num] ? ?else: ? ? ? ?val_image_ids = None ? ?test_image_ids = coco_image_ids[train_image_num + val_image_num:] ? ?categories = coco.loadCats(coco.getCatIds()) ? ?for img_id_list in [train_image_ids, val_image_ids, test_image_ids]: ? ? ? ?if img_id_list is None: ? ? ? ? ? ?continue ? ? ? ?img_dict = { ? ? ? ? ? ?'images': coco.loadImgs(ids=img_id_list), ? ? ? ? ? ?'categories': categories, ? ? ? ? ? ?'annotations': coco.loadAnns(coco.getAnnIds(imgIds=img_id_list)) ? ? ? ?} ? ? ? ?if img_id_list == train_image_ids: ? ? ? ? ? ?json_file_path = Path(save_dir, f'{train_type}.json') ? ? ? ?elif img_id_list == val_image_ids: ? ? ? ? ? ?json_file_path = Path(save_dir, 'val.json') ? ? ? ?elif img_id_list == test_image_ids: ? ? ? ? ? ?json_file_path = Path(save_dir, 'test.json') ? ? ? ?else: ? ? ? ? ? ?raise ValueError('img_id_list ERROR!') ? ? ? ?print(f'Saving json to {json_file_path}') ? ? ? ?with open(json_file_path, 'w') as f_json: ? ? ? ? ? ?json.dump(img_dict, f_json, ensure_ascii=False, indent=2) ? ?print('All done!')
輸出:
loading annotations into memory... Done (t=0.13s) creating index... index created! Split info: ====== Train ratio = 0.85, number = 8495 Val ratio = 0, number = 0 Test ratio = 0.15, number = 1498 Set the global seed: 2023 shuffle dataset. Saving json to data/trainval.json Saving json to data/test.json All done!
可以看到訓練集有8495張圖片,測試集有1498張圖片
模型配置文件
打開項目文件夾下的projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py文件,發現模型配置文件僅繼承_base_/default_runtime.py文件
需要修改主要有dataset_type、data_mode、dataset_info、codec、train_dataloader 、test_dataloader 、val_evaluator、base_lr、max_epochs、default_hooks。還有一些細節我在代碼中有標注,可以參照著修改
修改完成后將文件寫入./configs/animal_2d_keypoint/cat_keypoint.py中
custom_config = """
_base_ = ['mmpose::_base_/default_runtime.py']
# 數據集類型及路徑
dataset_type = 'CocoDataset'
data_mode = 'topdown'
data_root = './data/'
work_dir = './work_dir'
# cat dataset關鍵點檢測數據集-元數據
dataset_info = {
? ?'dataset_name':'Keypoint_cat',
? ?'classes':'cat',
? ?'paper_info':{
? ? ? ?'author':'Luck',
? ? ? ?'title':'Cat Keypoints Detection',
? ?},
? ?'keypoint_info':{
? ? ? ?0:{'name':'Left Eye','id':0,'color':[255,0,0],'type': '','swap': ''},
? ? ? ?1:{'name':'Right Eye','id':1,'color':[255,127,0],'type': '','swap': ''},
? ? ? ?2:{'name':'Mouth','id':2,'color':[255,255,0],'type': '','swap': ''},
? ? ? ?3:{'name':'Left Ear-1','id':3,'color':[0,255,0],'type': '','swap': ''},
? ? ? ?4:{'name':'Left Ear-2','id':4,'color':[0,255,255],'type': '','swap': ''},
? ? ? ?5:{'name':'Left Ear-3','id':5,'color':[0,0,255],'type': '','swap': ''},
? ? ? ?6:{'name':'Right Ear-1','id':6,'color':[139,0,255],'type': '','swap': ''},
? ? ? ?7:{'name':'Right Ear-2','id':7,'color':[255,0,255],'type': '','swap': ''},
? ? ? ?8:{'name':'Right Ear-3','id':8,'color':[160,82,45],'type': '','swap': ''}
? ?},
? ?'skeleton_info': {
? ? ? ?0: {'link':('Left Eye','Right Eye'),'id': 0,'color': [255,0,0]},
? ? ? ?1: {'link':('Left Eye','Mouth'),'id': 1,'color': [255,0,0]},
? ? ? ?2: {'link':('Right Eye','Mouth'),'id': 2,'color': [255,0,0]},
? ? ? ?3: {'link':('Left Ear-1','Left Ear-2'),'id': 3,'color': [255,0,0]},
? ? ? ?4: {'link':('Left Ear-2','Left Ear-3'),'id': 4,'color': [255,0,0]},
? ? ? ?5: {'link':('Left Ear-3','Right Ear-1'),'id': 5,'color': [255,0,0]},
? ? ? ?6: {'link':('Right Ear-1','Right Ear-2'),'id': 6,'color': [255,0,0]},
? ? ? ?7: {'link':('Right Ear-2','Right Ear-3'),'id': 7,'color': [255,0,0]},
? ? ? ?8: {'link':('Left Ear-1','Right Ear-3'),'id': 8,'color': [255,0,0]},
? ?}
}
# 獲取關鍵點個數
NUM_KEYPOINTS = len(dataset_info['keypoint_info'])
dataset_info['joint_weights'] = [1.0] * NUM_KEYPOINTS
dataset_info['sigmas'] = [0.025] * NUM_KEYPOINTS
# 訓練超參數
max_epochs = 100
val_interval = 5
train_cfg = {'max_epochs': max_epochs, 'val_begin':20, 'val_interval': val_interval}
train_batch_size = 32
val_batch_size = 32
stage2_num_epochs = 10
base_lr = 4e-3 / 16
randomness = dict(seed=2023)
# 優化器
optim_wrapper = dict(
? ?type='OptimWrapper',
? ?optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
? ?paramwise_cfg=dict(
? ? ? ?norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
# 學習率
param_scheduler = [
? ?dict(type='LinearLR', start_factor=1.0e-5, by_epoch=False, begin=0, end=600),
? ?dict(
? ? ? ?type='CosineAnnealingLR',
? ? ? ?eta_min=base_lr * 0.05,
? ? ? ?begin=max_epochs // 2,
? ? ? ?end=max_epochs,
? ? ? ?T_max=max_epochs // 2,
? ? ? ?by_epoch=True,
? ? ? ?convert_to_iter_based=True),
]
# automatically scaling LR based on the actual training batch size
auto_scale_lr = dict(base_batch_size=1024)
# codec settings
# input_size可以換成128的倍數
# sigma高斯分布標準差,越大越易學,但進度低。高精度場景,可以調小,RTMPose 原始論文中為 5.66
# input_size、sigma和下面model中的in_featuremap_size參數需要成比例縮放
codec = dict(
? ?type='SimCCLabel',
? ?input_size=(512, 512),
? ?sigma=(24, 24),
? ?simcc_split_ratio=2.0,
? ?normalize=False,
? ?use_dark=False)
# 模型:RTMPose-M
model = dict(
? ?type='TopdownPoseEstimator',
? ?data_preprocessor=dict(
? ? ? ?type='PoseDataPreprocessor',
? ? ? ?mean=[123.675, 116.28, 103.53],
? ? ? ?std=[58.395, 57.12, 57.375],
? ? ? ?bgr_to_rgb=True),
? ?backbone=dict(
? ? ? ?_scope_='mmdet',
? ? ? ?type='CSPNeXt',
? ? ? ?arch='P5',
? ? ? ?expand_ratio=0.5,
? ? ? ?deepen_factor=0.67,
? ? ? ?widen_factor=0.75,
? ? ? ?out_indices=(4, ),
? ? ? ?channel_attention=True,
? ? ? ?norm_cfg=dict(type='SyncBN'),
? ? ? ?act_cfg=dict(type='SiLU'),
? ? ? ?init_cfg=dict(
? ? ? ? ? ?type='Pretrained',
? ? ? ? ? ?prefix='backbone.',
? ? ? ? ? ?checkpoint='https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth'
? ? ? ?)),
? ?head=dict(
? ? ? ?type='RTMCCHead',
? ? ? ?in_channels=768,
? ? ? ?out_channels=NUM_KEYPOINTS,
? ? ? ?input_size=codec['input_size'],
? ? ? ?in_featuremap_size=(16, 16),
? ? ? ?simcc_split_ratio=codec['simcc_split_ratio'],
? ? ? ?final_layer_kernel_size=7,
? ? ? ?gau_cfg=dict(
? ? ? ? ? ?hidden_dims=256,
? ? ? ? ? ?s=128,
? ? ? ? ? ?expansion_factor=2,
? ? ? ? ? ?dropout_rate=0.,
? ? ? ? ? ?drop_path=0.,
? ? ? ? ? ?act_fn='SiLU',
? ? ? ? ? ?use_rel_bias=False,
? ? ? ? ? ?pos_enc=False),
? ? ? ?loss=dict(
? ? ? ? ? ?type='KLDiscretLoss',
? ? ? ? ? ?use_target_weight=True,
? ? ? ? ? ?beta=10.,
? ? ? ? ? ?label_softmax=True),
? ? ? ?decoder=codec),
? ?test_cfg=dict(flip_test=True))
backend_args = dict(backend='local')
# pipelines
train_pipeline = [
? ?dict(type='LoadImage', backend_args=backend_args),
? ?dict(type='GetBBoxCenterScale'),
? ?dict(type='RandomFlip', direction='horizontal'),
? ?# dict(type='RandomHalfBody'),
? ?dict(
? ? ? ?type='RandomBBoxTransform', scale_factor=[0.8, 1.2], rotate_factor=30),
? ?dict(type='TopdownAffine', input_size=codec['input_size']),
? ?dict(type='mmdet.YOLOXHSVRandomAug'),
? ?dict(
? ? ? ?type='Albumentation',
? ? ? ?transforms=[
? ? ? ? ? ?dict(type='ChannelShuffle', p=0.5),
? ? ? ? ? ?dict(type='CLAHE', p=0.5),
? ? ? ? ? ?# dict(type='Downscale', scale_min=0.7, scale_max=0.9, p=0.2),
? ? ? ? ? ?dict(type='ColorJitter', p=0.5),
? ? ? ? ? ?dict(
? ? ? ? ? ? ? ?type='CoarseDropout',
? ? ? ? ? ? ? ?max_holes=4,
? ? ? ? ? ? ? ?max_height=0.3,
? ? ? ? ? ? ? ?max_width=0.3,
? ? ? ? ? ? ? ?min_holes=1,
? ? ? ? ? ? ? ?min_height=0.2,
? ? ? ? ? ? ? ?min_width=0.2,
? ? ? ? ? ? ? ?p=0.5),
? ? ? ?]),
? ?dict(type='GenerateTarget', encoder=codec),
? ?dict(type='PackPoseInputs')
]
val_pipeline = [
? ?dict(type='LoadImage', backend_args=backend_args),
? ?dict(type='GetBBoxCenterScale'),
? ?dict(type='TopdownAffine', input_size=codec['input_size']),
? ?dict(type='PackPoseInputs')
]
train_pipeline_stage2 = [
? ?dict(type='LoadImage', backend_args=backend_args),
? ?dict(type='GetBBoxCenterScale'),
? ?dict(type='RandomFlip', direction='horizontal'),
? ?dict(type='RandomHalfBody'),
? ?dict(
? ? ? ?type='RandomBBoxTransform',
? ? ? ?shift_factor=0.,
? ? ? ?scale_factor=[0.75, 1.25],
? ? ? ?rotate_factor=60),
? ?dict(type='TopdownAffine', input_size=codec['input_size']),
? ?dict(type='mmdet.YOLOXHSVRandomAug'),
? ?dict(
? ? ? ?type='Albumentation',
? ? ? ?transforms=[
? ? ? ? ? ?dict(type='Blur', p=0.1),
? ? ? ? ? ?dict(type='MedianBlur', p=0.1),
? ? ? ? ? ?dict(
? ? ? ? ? ? ? ?type='CoarseDropout',
? ? ? ? ? ? ? ?max_holes=1,
? ? ? ? ? ? ? ?max_height=0.4,
? ? ? ? ? ? ? ?max_width=0.4,
? ? ? ? ? ? ? ?min_holes=1,
? ? ? ? ? ? ? ?min_height=0.2,
? ? ? ? ? ? ? ?min_width=0.2,
? ? ? ? ? ? ? ?p=0.5),
? ? ? ?]),
? ?dict(type='GenerateTarget', encoder=codec),
? ?dict(type='PackPoseInputs')
]
# data loaders
train_dataloader = dict(
? ?batch_size=train_batch_size,
? ?num_workers=2,
? ?persistent_workers=True,
? ?sampler=dict(type='DefaultSampler', shuffle=True),
? ?dataset=dict(
? ? ? ?type=dataset_type,
? ? ? ?data_root=data_root,
? ? ? ?metainfo=dataset_info,
? ? ? ?data_mode=data_mode,
? ? ? ?ann_file='trainval.json',
? ? ? ?data_prefix=dict(img='images/'),
? ? ? ?pipeline=train_pipeline,
? ?))
val_dataloader = dict(
? ?batch_size=val_batch_size,
? ?num_workers=2,
? ?persistent_workers=True,
? ?drop_last=False,
? ?sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
? ?dataset=dict(
? ? ? ?type=dataset_type,
? ? ? ?data_root=data_root,
? ? ? ?metainfo=dataset_info,
? ? ? ?data_mode=data_mode,
? ? ? ?ann_file='test.json',
? ? ? ?data_prefix=dict(img='images/'),
? ? ? ?pipeline=val_pipeline,
? ?))
test_dataloader = val_dataloader
default_hooks = {
? ?'checkpoint': {'save_best': 'PCK','rule': 'greater','max_keep_ckpts': 2},
? ?'logger': {'interval': 50}
}
custom_hooks = [
? ?dict(
? ? ? ?type='EMAHook',
? ? ? ?ema_type='ExpMomentumEMA',
? ? ? ?momentum=0.0002,
? ? ? ?update_buffers=True,
? ? ? ?priority=49),
? ?dict(
? ? ? ?type='mmdet.PipelineSwitchHook',
? ? ? ?switch_epoch=max_epochs - stage2_num_epochs,
? ? ? ?switch_pipeline=train_pipeline_stage2)
]
# evaluators
val_evaluator = [
? ?dict(type='CocoMetric', ann_file=data_root + 'test.json'),
? ?dict(type='PCKAccuracy'),
? ?dict(type='AUC'),
? ?dict(type='NME', norm_mode='keypoint_distance', keypoint_indices=[0, 1])
]
test_evaluator = val_evaluator
"""
config = './configs/animal_2d_keypoint/cat_keypoint.py'
with io.open(config, 'w', encoding='utf-8') as f:
? ?f.write(custom_config)
模型訓練
使用訓練腳本啟動訓練
!python tools/train.py {config}
因為訓練輸出太長,這里截取一段模型在測試集上最佳精度:
08/06 19:15:56 - mmengine - INFO - Evaluating CocoMetric... Loading and preparing results... DONE (t=0.07s) creating index... index created! Running per image evaluation... Evaluate annotation type *keypoints* DONE (t=0.57s). Accumulating evaluation results... DONE (t=0.03s). Average Precision ?(AP) @[ IoU=0.50:0.95 | area= ? all | maxDets= 20 ] = ?0.943 Average Precision ?(AP) @[ IoU=0.50 ? ? ?| area= ? all | maxDets= 20 ] = ?0.979 Average Precision ?(AP) @[ IoU=0.75 ? ? ?| area= ? all | maxDets= 20 ] = ?0.969 Average Precision ?(AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = -1.000 Average Precision ?(AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = ?0.944 Average Recall ? ? (AR) @[ IoU=0.50:0.95 | area= ? all | maxDets= 20 ] = ?0.953 Average Recall ? ? (AR) @[ IoU=0.50 ? ? ?| area= ? all | maxDets= 20 ] = ?0.987 Average Recall ? ? (AR) @[ IoU=0.75 ? ? ?| area= ? all | maxDets= 20 ] = ?0.977 Average Recall ? ? (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = -1.000 Average Recall ? ? (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = ?0.953 08/06 19:15:56 - mmengine - INFO - Evaluating PCKAccuracy (normalized by ``"bbox_size"``)... 08/06 19:15:56 - mmengine - INFO - Evaluating AUC... 08/06 19:15:56 - mmengine - INFO - Evaluating NME... 08/06 19:15:57 - mmengine - INFO - Epoch(val) [60][47/47] ? ?coco/AP: 0.943453 ?coco/AP .5: 0.979424 ?coco/AP .75: 0.969202 ?coco/AP (M): -1.000000 ?coco/AP (L): 0.944082 ?coco/AR: 0.953471 ?coco/AR .5: 0.987316 ?coco/AR .75: 0.977303 ?coco/AR (M): -1.000000 ?coco/AR (L): 0.953471 ?PCK: 0.978045 ?AUC: 0.801710 ?NME: 0.121770 ?data_time: 0.101005 ?time: 0.435133 08/06 19:15:57 - mmengine - INFO - The previous best checkpoint /kaggle/working/mmpose/work_dir/best_PCK_epoch_55.pth is removed 08/06 19:16:01 - mmengine - INFO - The best checkpoint with 0.9780 PCK at 60 epoch is saved to best_PCK_epoch_60.pth.
可以看到模型PCK達到了0.978,AUC達到了0.8017,mAP也都挺高,說明模型效果非常不錯!
模型精簡
mmpose提供模型精簡腳本,模型訓練權重文件大小減少一半,但不影響精度和推理
將在驗證集上表現最好的模型權重進行精簡
import glob
ckpt_path = glob.glob('./work_dir/best_PCK_*.pth')[0]
ckpt_sim = './work_dir/cat_pose_sim.pth'
# 模型精簡
!python tools/misc/publish_model.py
? ? ? ?{ckpt_path}
? ? ? ?{ckpt_sim}
模型推理
這里和上面的模型推理使用相同的思路,使用RTMDet模型進行目標檢測,使用我們自己訓練的RTMPose模型進行姿態估計。
不過pose2d參數是我們上面保存的配置文件./configs/animal_2d_keypoint/cat_keypoint.py,pose2d_weights為最佳精度模型精簡后的權重文件glob.glob('./work_dir/cat_pose_sim*.pth')[0]。
img_path = '/kaggle/input/cat-dataset/CAT_00/00000001_012.jpg'
inferencer = MMPoseInferencer(det_model = '/kaggle/working/mmdetection/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?det_weights = 'checkpoint/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?pose2d = './configs/animal_2d_keypoint/cat_keypoint.py',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?pose2d_weights = glob.glob('./work_dir/cat_pose_sim*.pth')[0])
result_generator = inferencer(img_path, out_dir = 'outputs', show=False)
result = next(result_generator)
display.clear_output()
可視化訓練結果
img_og = mmcv.imread(img_path)
img_fuse = mmcv.imread('outputs/visualizations/00000001_012.jpg')
fig, axes = plt.subplots(1, 2, figsize=(15, 10))
axes[0].imshow(mmcv.bgr2rgb(img_og))
axes[0].set_title('Original Image')
axes[0].axis('off')
axes[1].imshow(mmcv.bgr2rgb(img_fuse))
axes[1].set_title('Keypoint Image')
axes[1].axis('off')
plt.show()
編輯:黃飛
?






















 工商網監
工商網監
評論