 電子發燒友App
電子發燒友App


作者:崔毅博,湯仁東,邢大軍,王雋,李尚生
01??引言
光流計算作為計算機視覺的一個長期基本任務,其重要性顯而易見。由于運動視覺處理的特殊性,光流作為后面高級視覺處理的輸入,對其準確度、實時性都有著極高的要求,光流計算的性能會直接影響其后的高級視覺處理。
光流計算技術在計算機視覺的各主要研究方向如檢測、分割、導航、位姿估計、3維重建等領域中都有著重要的應用,其相關算法在更上層的應用場景如自動駕駛、氣象預報、雷達信息處理、衛星及航空影像分析、同步定位與地圖構建( SLAM)、視覺神經科學相關領域以及軍事應用領域等前沿熱點方向更是有著重要的研究價值與應用價值。由此可見光流計算技術的發展對于計算機視覺領域的重要意義。
本文按照傳統光流計算技術的主要發展過程(第2節)、基于深度學習的光流計算技術發展過程(第3節)、光流測試相關數據集和性能評價指標(第4節)、光流計算技術的具體應用(第5節)、總結及光流計算技術未來發展趨勢展望(第6節)的順序安排各節內容。
02??傳統光流計算技術的主要發展過程
通過圖像計算光流,自20世紀80年代興起,其中具有代表性的經典算法為Horn等人[1]提出的HS(Horn-Schunck)光流算法與Lucas等人[2]提出的LK(Lucas-Kanade)光流算法,而后基于這兩種算法的各種改進版本有許多。其中HS算法是基于變分法求解光流,LK算法是基于差分法求解光流,但二者都基于兩個共同的假設:
假設1 亮度恒定假設:同一目標在不同幀間運動時,其亮度不會發生改變。
假設2 小運動假設:短時間像素的位置不會劇烈變化,即相鄰幀之間像素距離變化較小。
用數學模型說明如下:若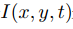 表示t時刻
表示t時刻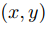 位置的像素在圖像上的亮度,則根據假設1和假設2得到
位置的像素在圖像上的亮度,則根據假設1和假設2得到
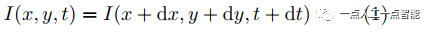
若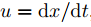 ,
,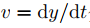 分別為像素沿x與y軸的速度,對式(1)進行泰勒展開,忽略高階無窮小后對t求導,而后代入
分別為像素沿x與y軸的速度,對式(1)進行泰勒展開,忽略高階無窮小后對t求導,而后代入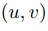 ,則可得
,則可得
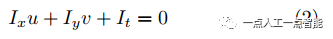
式(2)就是由光流的基本假設推出的光流基本方程。在其基礎上通過加入不同的約束、改變求解方式,得到像素的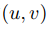 值即圖像相鄰幀之間的光流。
值即圖像相鄰幀之間的光流。
2.1 HS光流算法
HS光流算法是一種優化算法,通過在假設1、假設2的基礎上加入全局平滑約束條件,即假設值小范圍內變化很小,其加入的全局平滑約束項為
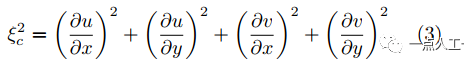
此約束項表征光流的連續性即平滑(其為0時代表光流在任意方向無變化),結合光流基本方程建立平滑約束下光流優化方程(也稱能量函數)
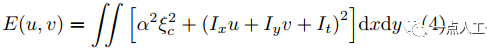
其中,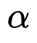 是平滑項的權重,根據假設最小化此方程,利用歐拉-拉格朗日(Euler-Lagrange)方程求解,經迭代至收斂得到光流信息。此類優化方法易陷入局部極值,其初始值很重要,而實際使用時往往無法獲得初始值,這就導致此類算法在新場景下會有一段不穩定期。
是平滑項的權重,根據假設最小化此方程,利用歐拉-拉格朗日(Euler-Lagrange)方程求解,經迭代至收斂得到光流信息。此類優化方法易陷入局部極值,其初始值很重要,而實際使用時往往無法獲得初始值,這就導致此類算法在新場景下會有一段不穩定期。
2.2 LK光流算法
LK光流在假設1和假設2的基礎上增加假設3:
假設3 空間一致性:某一個小窗口內的像素短時間內具有相同的運動(即相同)。
若小窗口為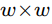 ,則其中有
,則其中有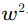 個像素,則可根據式(2)列出超定方程并用最小二乘法解此方程即可求出這個窗口的光流值。由于此類方法在大窗口下無法保證相同運動方向和假設2這個微分條件的成立,需利用圖像金字塔技術[3]把圖像分層壓縮到低分辨率,把大位移運動變成了高層金字塔的小位移運動,進而配合插值算法逐層應用此方法求解光流。
個像素,則可根據式(2)列出超定方程并用最小二乘法解此方程即可求出這個窗口的光流值。由于此類方法在大窗口下無法保證相同運動方向和假設2這個微分條件的成立,需利用圖像金字塔技術[3]把圖像分層壓縮到低分辨率,把大位移運動變成了高層金字塔的小位移運動,進而配合插值算法逐層應用此方法求解光流。
在以上兩種算法的基礎上,針對光流的不同問題有相應的改進方法,如:為解決算法易陷入局部極值問題而提出的前后向光流法[4],為解決遮擋問題而融合卡爾曼濾波運動預測的LK改進算法[5],以及各類通過改進定位角點準確度與匹配準確度來提升光流準確性的改進方法等。
隨著深度學習的興起,利用卷積神經網絡來進行光流估計已經成為一種重要方法,與計算機視覺其他領域橫向比較,基于深度學習的光流計算方法在準確度、魯棒性、實時性等方面有著天然的優勢。因此基于深度學習的光流計算通常被認為是有別于經典算法的一種新模式,也是一個極具發展前景的技術方向。
03??基于深度學習的光流計算技術發展
有別于傳統人工設計的方法來求解光流,深度學習從數據的角度出發,利用數據訓練相關模型,從而得到可以準確進行光流估計的模型,并利用此模型在應用場景中對光流進行估計。隨著GPU以及計算機算力的不斷發展,目前基于深度學習的光流計算無論在準確度還是實時性上都已經超過經典算法。
Dosovitskiy等人[6]在2015年首次提出的基于卷積神經網絡(Convolutional Neural Networks, CNN)的FlowNet實現了利用卷積神經網絡進行光流的估計(第1代監督模型),為訓練所提出的模型同時開發了Flying Chairs數據集,FlowNet的提出表明了完全基于卷積神經網絡端到端的架構有能力解決光流估計的相關問題。此后基于深度學習的模型逐步在性能上趕超經典算法。其中主要可以分為兩個大類:基于監督學習的光流估計模型和自監督學習的光流估計模型。下面分別進行介紹。
3.1 基于監督學習的光流估計模型
監督學習模型往往需要結合相關領域知識,利用監督學習的方式來對模型進行訓練,其中結合領域知識方面主要有兩種途徑:
第1種是結合數據相關知識。普遍的做法就是通過把領域知識制作成光流相關數據集,使得神經網絡可以利用這類數據集進行訓練和評估,從而使得訓練出的深度學習模型可以進行光流估計。相關數據集介紹詳見第4節。
第2種是借鑒之前已有經典算法的約束條件與計算框架。結合卷積神經網絡可以提取圖像高維度特征以及可以進行并行計算的特點,進而得到光流在準確率和實時性上的提升,其中比較有代表性的就是 DCflow[7],上述兩種領域知識結合方法在監督學習中可以同時使用。
DCflow參考FullFlow[8]提出的代價體(cost volume)以及由粗糙到精細的(Coarse-To-Fine, CTF)范式,這種CTF范式結構主要分為4步:特征提取(features)、構建代價體(cost volume)、代價體處理與光流后處理。
CTF范式的主要計算量在計算和優化代價體以及后處理上,代價體表示了每個位置提取出的高維特征之間的聯系,在FlowNet2.0[9](把FlowNetS/C相關模塊進行了組合堆疊實驗)中作者也支持顯示地構建代價體,稱其往往比隱式的效果要好。繼FlowNet2.0之后,深度學習算法在實時性和精度上都開始超越經典算法,其中較為重要的借鑒經典算法結構的深度卷積網絡模型是基于CTF范式的PWC-Net(Pyramid, Warping, and Cost volume, PWC)[10](第2代監督模型),其框架如圖1所示。
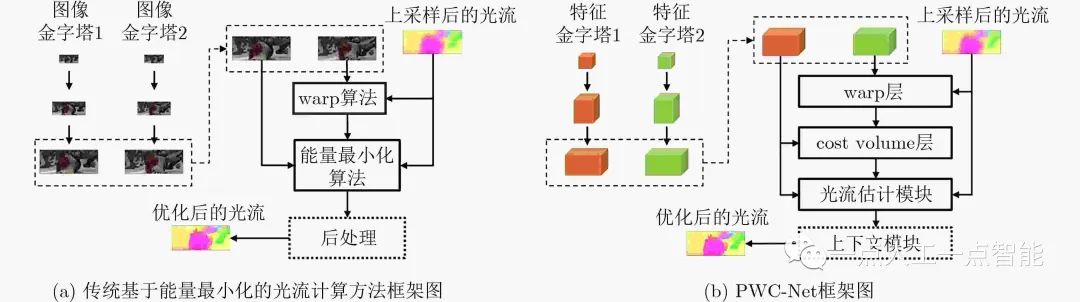
圖1 傳統框架與PWC-Net框架圖對比圖(圖片改繪自文獻[10])
PWC-Net相較于FlowNet2.0,準確率更高且速度更快,改進了FlowNet2.0模型參數量大且訓練繁瑣的問題(速度快2倍參數量下降17倍)。其主要結構借鑒傳統基于能量最小化的CTF光流計算框架(如圖1),與傳統方法不同的是,其先利用卷積層進行圖像金字塔計算;再利用warp層模仿warp算法把第2幀圖像利用上一幀光流扭曲(warp)到第1幀;然后對金字塔每一層利用卷積提取的特征(features)構建代價體(cost volume)找到特征之間的關系,把第1幀圖像的特征、代價體、上一幀的光流輸入到光流估計層得到光流估計;對應傳統光流計算的后處理模塊,最后用基于空洞卷積的上下文網絡進行后處理,這個網絡輸入上一層的光流估計值和光流估計值的倒數第2層特征,可以優化并把光流放大到所需大小,類似經典算法結構的深度學習光流模型還有許多[11]。對PWC-Net進行改進效果較好的是利用迭代殘差細化(Iterative Residual Refinement,IRR)方法的IRR-PWC模型[12],這種方法可以在維持參數數量的情況下提高準確率,在附加去遮擋模塊后,可以對遮擋情況下的光流預測更加準確。PWC-Net整體架構如圖1所示。
圖1(b)中warp層的數學表達式為
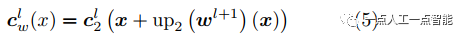
其中,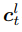 代表t時刻圖像
代表t時刻圖像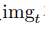 在圖像金字塔第
在圖像金字塔第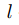 層的特征,
層的特征,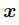 是像素坐標(包括橫縱坐標),
是像素坐標(包括橫縱坐標),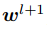 是
是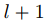 層的光流,
層的光流,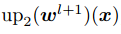 是對應位置上采樣的層的光流,式(5)表達的意思是如果光流估計準確,則在
是對應位置上采樣的層的光流,式(5)表達的意思是如果光流估計準確,則在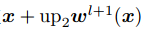 處特征
處特征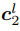 應與在
應與在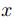 處特征
處特征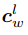 相同。
相同。
代價體(cost volume)的數學表達式可以表示為
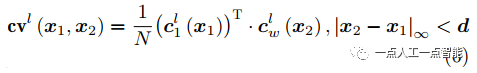
其中,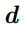 為超參,表征最大相關距離。這部分就是利用向量點積來進行特征相關性計算,從而計算出特征之間的相似性,代價體即表征這種特征之間相似性的映射。
為超參,表征最大相關距離。這部分就是利用向量點積來進行特征相關性計算,從而計算出特征之間的相似性,代價體即表征這種特征之間相似性的映射。
在監督模型中,RAFT(Recurrent All-pairs Field Transforms for optical flow)[13]是十分重要的模型(第3代監督模型),其框架如圖2所示。這個模型實現了整個網絡端到端訓練的同時,在效果上超過了PWC-Net和IRR-PWC,且實現了模型的輕量化。其主要思路是利用卷積提取兩幀圖像的特征,而后對特征做內積得到4D代價體(4D cost volumes)作為兩個特征之間相似性的度量空間,有別于其他算法,光流會通過一個門控循環單元(Gated Recurrent Unit, GRU)的一個輸出,在4D 代價體空間內進行查詢,查詢結果將用來更新GRU進行迭代細化,這樣就可以有效利用上下文信息,通過GRU最終輸出精細化后的光流,最后通過利用周圍像素上采樣恢復光流到原圖像分辨率。RAFT模型表明了端到端的深度學習模型在性能上可以超越人為模塊化設計的模型,并且截至本文成稿時間,仍是深度學習模型性能進行比較的一個基準。
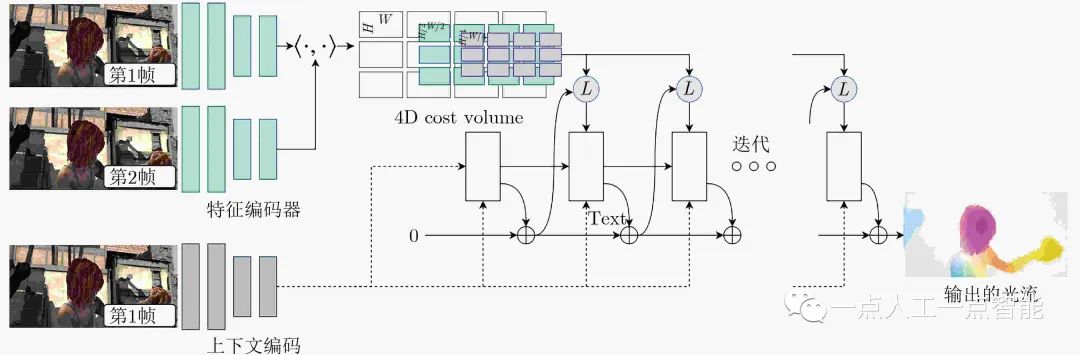
圖2 RATF模型框架圖(圖片改繪自文獻[13])
以PWC-Net, RATF為代表的這種CTF范式的神經網絡模型可以提高性能的主要途徑是優化后3步,以減少計算量、提高精度及其抗噪性能。當然還有借鑒其他范式的模型,如經典算法EpicFlow[14]的由稀疏到稠密(Sparse-To-Dense, STD)范式,其主要步驟為:計算稀疏匹配集、計算光流稀疏到稠密的插值、后處理以及優化得到光流。
另一種光流計算重要范式是STD。如PatchBatch[15]在經典EpicFlow的基礎上利用神經網絡提取高維度特征來計算稀疏匹配集,提高了匹配集的質量,結合EpicFlow的稠密插值最終得到光流。FTDM(Fully-Trainable Deep Matching)[16]通過訓練一個u型拓撲的CNN來等效深度匹配(Deep Matching, DM)算法,從而計算出稀疏匹配集,而后利用EpicFlow稠密插值得到光流。此類方法主要改進方向在于計算稀疏匹配集、計算稀疏到稠密的插值這兩個步驟上,即如何在低算力的情況下找到質量更高的稀疏匹配集,以及如何進行更好的插值計算。
以上兩種框架都是基于CNN的,而也有部分方法致力于改進CNN卷積模型本身性能,使其更適用于光流估計任務,從而在本質上提高光流估計的性能,如模型PPAC-HD3[17],利用概率像素自適應卷積提高模型性能,優化光流的邊緣及精度。
隨著深度學習模型的性能不斷提升,目前基于Transformer的模型在語言、圖像以及多模態處理方面表現出了突出的性能。截至2022年10月KITTI數據集上表現最優的純視覺光流估計模型是基于Transformer的GMFlow (Global Matching, GM)[18]作為第4代監督模型,其框架如圖3所示,其改進版GMFlow+實現了多模態處理。GMFlow主要利用attention技術優化了利用卷積處理代價體自帶的局部局限性問題,可以做到全局匹配,所以在處理大位移上優勢明顯,其基于Transformer架構的處理方法是短期內的主流方向。
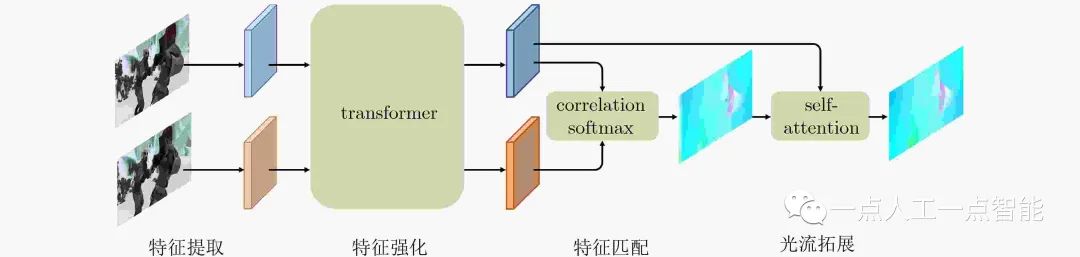
圖3 GMFlow的框架圖(圖片改繪自文獻[18])
Transformer等利用self-attention技術的深度學習模型,其核心公式表示為
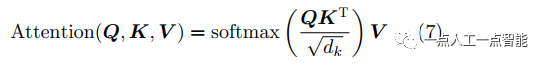
其中,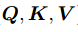 為基于圖像的嵌入向量,
為基于圖像的嵌入向量,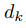 是K的維度,self-attntion其本質是找到相關特征,并有針對性地強化高維特征向量,從而使得所需相關特征突出出來,與代價體本質一致但不會受到距離限制,利用深度學習框架并行計算的優勢在計算速度上相較于代價體更快。
是K的維度,self-attntion其本質是找到相關特征,并有針對性地強化高維特征向量,從而使得所需相關特征突出出來,與代價體本質一致但不會受到距離限制,利用深度學習框架并行計算的優勢在計算速度上相較于代價體更快。
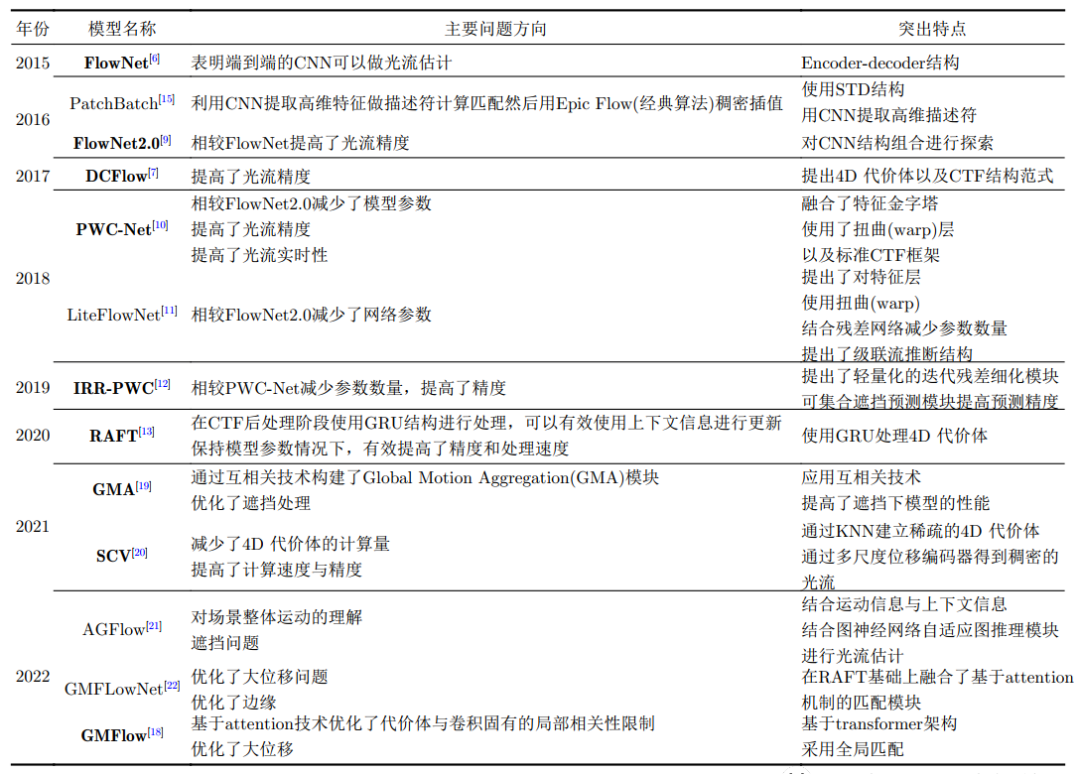
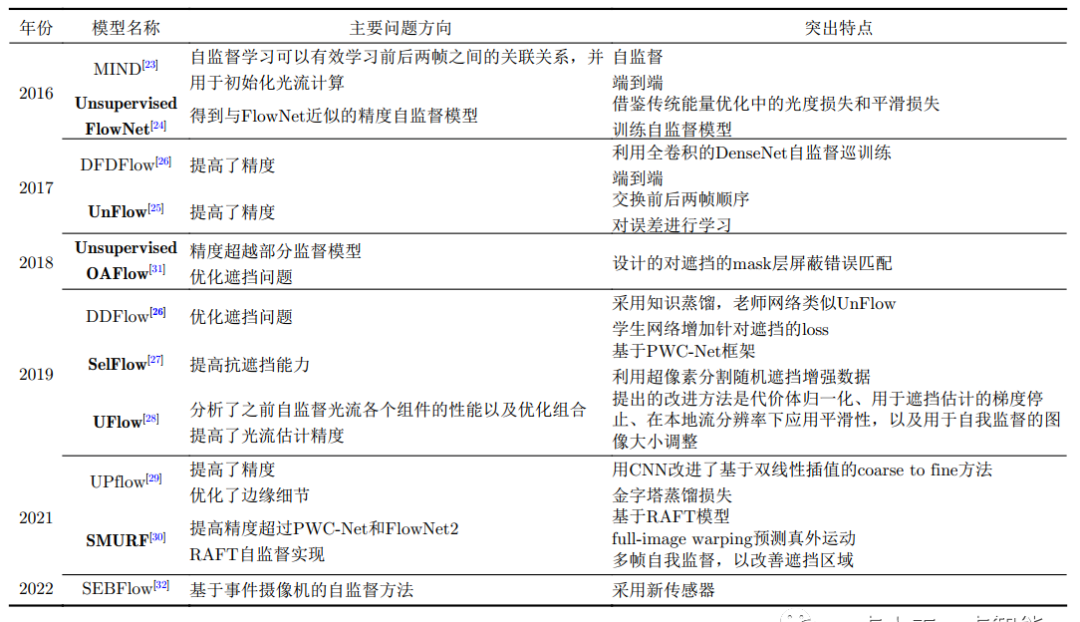
除主要創新及作為行業基準的模型外,每年還有大量基于以上模型的改進模型。近3年基于RAFT的改進居多,效果也日益增強,基于Transfomer架構的模型也逐步體現出其優勢,結合圖神經網絡技術解決卷積固有的相關缺陷是未來發展的主要方向之一。各類模型主要解決的問題和特點詳見表1,其中淺灰色為CTF范式模型,淺藍色為STD范式模型,加粗字體為行業廣泛認可的基準模型。
表1 光流估計監督模型匯總
由于域差(domain gap),以及制作光流訓練的數據集本身成本與技術難度很高,除監督學習外深度學習光流模型的另一種主要模式是自監督學習模型,不利用人工標注的數據集進行學習,可以極大降低訓練模型的成本,若可以直接利用真實數據進行自監督訓練,則可有效避免數據集與真實數據之間域差問題。
3.2 基于自監督學習的光流估計模型
在2016年Long等人[23]利用簡單的編碼解碼器(Encoder-Decoder)神經網絡MIND來對前后兩幀之間的關聯關系進行學習,并認為光流估計是這種求解關聯關系的一個子問題,其方法就是取視頻流前后3幀圖像,利用第1幀和第3幀來對第2幀進行估計,并用夏博尼爾損失(Charbonnier loss)(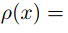
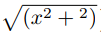 )作為損失函數(Loss)進行訓練,成功表明了自監督學習可以有效學習前后兩幀之間的關聯關系。
)作為損失函數(Loss)進行訓練,成功表明了自監督學習可以有效學習前后兩幀之間的關聯關系。
同年,Yu等人[24]提出了基于光度誤差(photometric loss,用以衡量經推測的光流扭曲(warp)后的第2幀和第1幀的差異)與平滑誤差(smoothness loss,衡量空間相鄰光流預測之間的差異)類似FlowNet的端到端自監督訓練模型UnsupervisedFlowNet,并達到了當時KITTI數據集的最佳效果。UnFlow[25]在其誤差計算的基礎上,利用交換前后兩幀順序,送入CNN預測前后雙向光流并計算誤差的方法(理論上這兩個光流方向是相反的),進一步提高了訓練模型的預測精度。DDFlow[26]在UnFlow的基礎上,采用了知識蒸餾結構,其中老師網絡與UnFlow類似,但在學生網絡中增加了對遮擋相關的損失函數(Loss),可以對遮擋進行學習,而非簡單剔除。對于遮擋問題, SelFlow[27]在PWC-Net的基礎上結合光度誤差,提出了一個自監督的模型,其主要思想是首先訓練一個無遮擋情況下光流預測的CNN,而后對圖像進行超像素分割(防止分割形式單一)并按分割隨機分配噪聲遮擋,用第1個CNN對光流的預測結果來指導第2個有遮擋情況下的CNN訓練,從而提高第2個模塊的抗遮擋能力。
UFlow[28]綜合了之前所提出的各類方法,并對各類方法中所有組件進行了評估測試,從而選擇出最優組合,并通過總結得到了4種模型優化方法:代價體歸一化、遮擋梯度停止、同級流分辨率下應用平滑度、調整圖像大小用以自監督訓練,從而提高了模型性能。在UFlow的基礎上, UPFlow[29]通過把傳統上采樣用到的雙線性插值優化為可學習的雙線性插值,降低了以往CTF模式上采樣造成的誤差,合并其提出的模型蒸餾損失,使得光流預測的邊緣更加清晰。直到目前較新的SMURF[30]實現了RAFT架構自監督的方法,自監督光流性能已經超越之前監督模型的基準(PWC-Net和FlowNet2)。自監督模型相關進展總結如表2,其中加粗字體為基準模型。
表2 光流估計自監督模型匯總
除監督與自監督模型之外,還有半監督模型,這類模型可以充分利用監督數據提高模型的精度,同時擁有自監督模型訓練數據易于獲取的優點,但從另一個角度看,這類模型也同時有著這兩類模型的缺點。其中比較有代表性的是SSFlow(Semi-Supervised, SS)[33],其主要思想是利用生成對抗神經網絡(Generative Adversative Nets, GAN),通過真實數據和合成數據同時訓練,GAN的判斷模塊可以學習到合成數據與真實數據之間的域差(domain gap),從而指導生成器生成的光流更加準確,但GAN模型往往難以訓練。
以上是基于深度學習的光流計算技術的大致發展過程,基于深度學習的模型很大程度上解決了經典算法中不滿足假設1和假設2的相關的問題,例如遮擋或物體存在變形的情況下,則亮度恒定假設無法保證;物體位移較大的情況下,光流變化無法滿足假設2,因此傳統基于變分與優化的方法無法滿足微分條件等。而且由于計算機分布式計算性能的提升,基于深度學習的方法在實時性上往往優于經典算法,所以在2017年后深度學習逐漸成為光流估計方面的主流算法。
04??光流測試相關數據集和性能評價指標
數據集對于訓練深度學習模型非常重要,深度學習也可以認為是由數據驅動的一種算法,數據集的質量直接影響訓練出的模型的性能,常用的用于訓練和測試的公開數據集包括:簡單但實用、利用椅子模型和隨機圖像生成的合成光流數據集(FlowNet驗證過的)FlyingChairs[6],主要用于車輛自動駕駛方面包含激光雷達和真實場景光流的KITTI Flow數據集[34,35],城市自動駕駛數據集HD1K,廣為使用的合成動畫數據集MPI-Sintel[36],密集小目標行人運動數據集Crowd-Flow[37],可以根據需求生成虛擬數據集的無人機模擬平臺AirSim以及基于動畫引擎Unreal Engine 4生成的高質量虛擬駕駛場景的模擬平臺Carla。光流數據集的發展促進了光流相關算法的發展,相關模型與算法的性能可以在數據集上得到驗證,在公開數據集上的測試結果往往作為評價光流算法與模型效果的重要參考。
常用的評估數據集,也是公認的模型評價標準,通常有以下幾個(見表3)。
表3 光流估計模型評估公開數據集

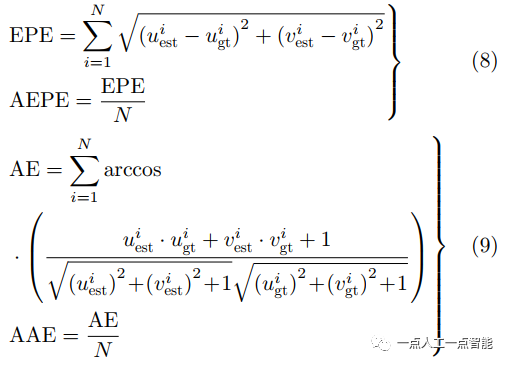
在光流計算性能指標上,5個最重要的指標分別是端點誤差(End-Point Error, EPE)、平均端點誤差(Average End-Point Error, AEPE)、每秒幀速率(Frame Per Second,FPS)、角度誤差(Angular Error,AE)和平均角度誤差(Average Angular Error,AAE)。其中EPE為估計光流和真實光流之間的歐氏距離,用來衡量光流估計的準確程度,AE常用于評估角度誤差,二者是互補的,AE對小幅度運動誤差敏感,EPE對大幅度運動誤差敏感。其定義分別為
其中,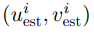 表示第
表示第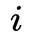 個像素的估計光流值,
個像素的估計光流值,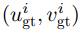 表示第個像素光流真值,
表示第個像素光流真值,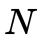 為總像素個數。AEPE與AAE越小說明估計的光流值與標準值誤差越小,即越準確。FPS則是衡量實時性能的指標,其值越大代表方法的實時性越強,也常用1/FPS(即處理每一幀所用時間)來衡量此項性能。
為總像素個數。AEPE與AAE越小說明估計的光流值與標準值誤差越小,即越準確。FPS則是衡量實時性能的指標,其值越大代表方法的實時性越強,也常用1/FPS(即處理每一幀所用時間)來衡量此項性能。
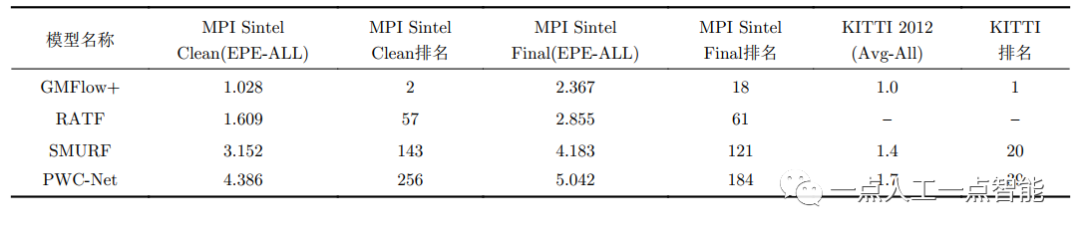
在上述指標中EPE, AEPE是最常用的比較算法準確度的性能指標,在所有數據集上通用,可以對模型整體性能進行評估,但無法衡量在某單一方面的性能。目前模型評估普遍利用的是KITTI2012, KITTI2015, Sintel Clean, Sintel Final 4個數據集。由于不同數據集數據分布以及對光流的衡量指標不一致,同一模型在不同數據集的性能也不同,但整體與表格所列順序正相關。詳細信息以及各類模型與算法準確度排名各類數據集官網都有實時更新,僅以本文介紹的部分模型及其改進型為例,準確率以Sintel 與KITTI數據集官網截至成稿時公布數據為準,其性能如表4所示。
表4 部分模型在Sintel及KITTI數據集上的性能(截至2023年3月)
05??光流計算技術的具體應用
光流計算技術在實際應用時,常作為一個單獨模塊來使用,也可以和其他模塊組合使用,準確的光流可以提供物體有效的運動、結構等信息。
在視頻處理方面,常常直接利用光流信息。如在視頻檢測領域,常利用光流信息來進行特征聚合以及特征在非關鍵幀之間傳播;在視頻跟蹤領域,比較經典的跟蹤-學習-檢測(Tracking-Learning-Detection, TLD)算法[42]分為跟蹤模塊、學習模塊、檢測模塊3大部分,其中的跟蹤模塊最早就是基于光流計算技術的經典LK算法來估計物體運動的,隨著光流計算技術的發展,此框架下的光流模塊也可以被更先進的模塊替換;基于雙流框架的視頻檢測與行為識別也常利用光流作為輸入之一,以光流提供的物體運動信息來輔助進行行為識別;基于光流的運動信息,也可以為人面部表情識別、手勢識別、動作識別等相關技術提供有效信息等。
光流在視頻跟蹤技術的具體應用場景也有很多,在交通監控上,對車輛、行人的異常行為進行檢測,用以檢測可疑滯留物、人群異常聚集、突發火情等;在體育比賽中,可以利用此項技術進行運動員跟蹤;在軍事領域,目標的鎖定與跟蹤應用更加廣泛,各類基于視頻的武器平臺與彈藥的導引頭都需要視頻跟蹤技術,尤其是目前許多國家出現了智能化的無人武器平臺,其中利用視頻進行檢測跟蹤鎖定目標已經是此類武器平臺的重要組件之一。
基于光流的動作識別技術的應用場景也很廣泛,如在安防監控領域,可以利用動作識別來預防公共場所的突發事件,若利用人工監控,則往往成本高、效率低;在視頻檢索中應用動作識別,根據視頻動作分析其視頻行為,進而對相關視頻進行檢索與推薦;在人機交互領域用動作識別技術完成人機對話,目前已經在許多游戲中廣泛使用等。
在實時定位與地圖構建(SLAM)中,可以利用光流信息配合相機模型的3維運動約束,經過優化算法,可以從光流中得到相機的3維位姿進而確定與其連接的物體的位姿,這種基于光流的位姿測量技術常被用于無人機、自動駕駛等領域,許多基于視覺導航的機器人也是利用此項技術進行實時導航,尤其是在紋理豐富的室內場景較為常用,與基于慣導與GPS的導航不同,基于計算機視覺的導航無需接受其他任何信號且沒有慣導那種累積誤差,在軍事領域的具體應用場景有無人飛行器自動著陸、導彈精確導航、基于光流的目標鎖定跟蹤技術、爆炸云分析、與陀螺儀結合進行彈體高度估計等應用也比較普遍等。視覺SLAM定位及點云生成效果如圖4所示。

圖4 光流SLAM效果圖(圖片出自文獻[43])
與此技術相關的還有基于光流的3維重建技術,其基本原理也是通過光流解算相機位姿,而后基于不同視角的相機位姿利用幾何約束生成點云以實現物體的3維重建等,此項技術的具體應用場景包括文物3D數據錄入、3D動畫建模、醫療影像、3D光流(場景流)、軍事戰場測繪等領域。
此外,在氣象預報方面,基于雷達數據的雷暴識別追蹤和外推預報技術,可以利用光流替代交叉相關法,對云團等進行外推預報,提高天氣預報的準確度;在醫學上,3維光流可以用于器官運動估計,以及基于光流場的圖像配準等應用;由于光流相關算法部分基于變分優化,在紅外圖像配準方面也有相關算法的應用;在軍事應用方面基于光流的目標鎖定跟蹤技術、爆炸云分析、與陀螺儀結合進行彈體高度估計等應用也比較普遍;在火災煙霧預防檢測等領域,光流法也有著重要的應用;自動駕駛領域光流與激光雷達的組合達到了KITTI數據集光流最佳效果,這種多傳感器融合也是光流計算技術應用的一個重要方面等等。
光流計算技術的進展與腦科學視覺運動感知等領域既相互交叉也相互啟發,大腦對視覺進行編碼的過程在某些方面與深度神經網絡類似。如Mountcastle (1957), Hubel(1962)以及 Wiesel (1963)等人研究發現,在大腦皮層若干區域,反應特性上表現出相似選擇性的細胞聚集在一起,這與卷積神經網絡中卷積核提取某一高維特征的特點類似。通過和其他動物實驗數據比對發現,不同物種和皮質區域的組織類型的相似性表明存在著將方向和旋轉域映射到皮層表面的普遍原則(即運動感知),而光流計算技術可以認為是對這種映射原則的一種模擬。
除上述外光流的應用場景可以覆蓋基于計算機視覺技術的大部分領域,相關算法在其他場景的應用也很多。作為計算機視覺的基本問題之一,光流計算技術的發展有助于其所覆蓋相關領域的技術進步與性能提高。
06??總結與發展趨勢展望
本文介紹了光流相關的基礎知識,總結了光流計算技術主要的技術發展路線,對技術發展過程中比較典型的算法與模型進行了簡要的闡述,對相關算法的核心創新點與思路進行了歸納,對光流評估數據集與指標方面做了簡要分析,并對光流的應用場景進行了簡要總結。
光流計算技術結合深度學習是目前光流計算的主要發展趨勢,其主要的技術方向是獲得一種可以適用于任何場景快速且精確的光流估計方法,個人認為其中主流技術的發展趨勢是利用更加先進的深度學習架構如圖神經網絡、transformer架構、3D卷積模型等,提高模型預測的準確度,強化模型的泛化能力和推理能力,解決諸如遮擋、小目標、大位移、光照、邊界模糊、形變、噪聲等方向的光流計算問題。
從目前光流計算的發展來看,利用深度學習模型來進行更準確、實時性更好的光流預測依舊是光流計算發展的長期目標;在基于現有深度學習的模型上進行優化,在保證精度的同時加強實時性與降低模型參數的規模,這也是基于深度學習的光流模型可以繼續優化的方向;2D光流相關算法可以結合深度信息,向3D光流(場景流)方向發展,加強動態環境中對3D運動的理解;隨著腦科學的發展,人類視覺機制將被進一步解析,利用仿生模擬人類視覺過程,如利用神經動力學模型結合深度學習對物體運動進行預測,也是目前重要的發展方向之一;生物視覺具有高穩定性、高適應性和低功耗等特點,是下一代人工智能算法開發的重要參考借鑒對象,生物視覺系統中存在專門處理運動信息的神經元和神經環路[44,45],相關神經機制也得到了初步解析[46,47],如何借鑒相關機制,開發出性能更優的類腦算法,將是光流計算領域極具潛力的發展方向之一。
編輯:黃飛
?












 工商網監
工商網監
評論