 電子發(fā)燒友App
電子發(fā)燒友App


作者:PCIPG-mach??
為三維點云實例分割提出了一個概念簡單、通用性強的新框架。我們的方法被稱為 3D-BoNet ,遵循每點多層感知器 (MLP) 的簡單設(shè)計理念。
該框架直接回歸點云中所有實例的三維邊界框(bounding boxes),同時預(yù)測每個實例的點級掩碼(a point-level mask)。它由一個骨干網(wǎng)絡(luò)和兩個并行網(wǎng)絡(luò)分支組成,前者用于邊界框回歸,后者用于點掩碼預(yù)測。3D-BoNet 是單級、無錨和端到端可訓(xùn)練的網(wǎng)絡(luò)。此外,與現(xiàn)有方法不同的是,它不需要任何后處理步驟,且具有很高的效率。
1 前言
實例分割問題,主要障礙在于點云本身是無序、非結(jié)構(gòu)化和非均勻的。廣泛使用的卷積神經(jīng)網(wǎng)絡(luò)需要對三維點云進行體素化處理,從而產(chǎn)生高昂的計算和內(nèi)存成本。
此外,它們不可避免地需要一個后處理步驟,如均值移動聚類,以獲得最終的實例標(biāo)簽,而這一步驟的計算量很大。另一種管道是基于提議的 3D-SIS 和 GSPN ,它們通常依賴于兩階段訓(xùn)練和昂貴的非最大抑制來剪切密集的對象提議。
在本文中,我們提出了一個優(yōu)雅、高效和新穎的三維實例分割框架,通過使用高效 MLP 的單向前向階段來松散但唯一地檢測對象,然后通過一個簡單的點級二元分類器來精確分割每個實例。為此,我們引入了一個新的邊界框預(yù)測模塊和一系列精心設(shè)計的損失函數(shù),以直接學(xué)習(xí)對象邊界。我們的框架與現(xiàn)有的基于提議和無提議的方法有很大不同,因為我們能夠高效地分割所有具有高對象性的實例,而無需依賴昂貴而密集的對象提議。
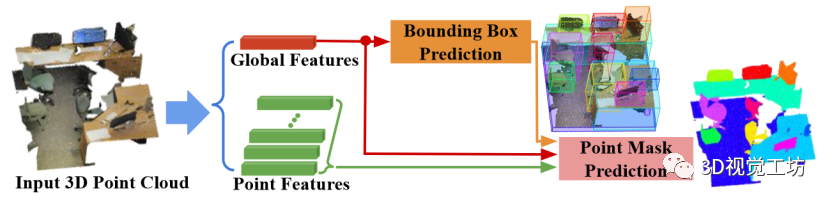
圖 1 所示,我們的框架名為 3D-BoNet ,是一種單級、無錨、端到端可訓(xùn)練的神經(jīng)架構(gòu)。它首先使用現(xiàn)有的骨干網(wǎng)絡(luò)為每個點提取局部特征向量,并為整個輸入點云提取全局特征向量。
骨干網(wǎng)絡(luò)之后有兩個分支:
1) 實例級邊界框預(yù)測
2) 用于實例分割的點級掩碼預(yù)測。總體而言,我們的框架在三個方面有別于所有現(xiàn)有的三維實例分割方法。1) 與無提議管道相比,我們的方法通過明確學(xué)習(xí)三維對象邊界來分割對象度高的實例。2) 與廣泛使用的基于提議的方法相比,我們的框架不需要昂貴而密集的提議。3) 我們的框架非常高效,因為實例級掩碼只需一次前向?qū)W習(xí),無需任何后處理步驟。
我們的主要貢獻如下:
我們提出了一種新的三維點云實例分割框架。該框架是單階段、無錨和端到端可訓(xùn)練的,無需任何后處理步驟。
我們設(shè)計了一個新穎的邊界框關(guān)聯(lián)層,然后使用多標(biāo)準(zhǔn)損失函數(shù)對邊界框預(yù)測分支進行監(jiān)督。
通過廣泛的消融研究,我們證明了與基線相比的顯著改進,并提供了我們設(shè)計選擇背后的直覺。
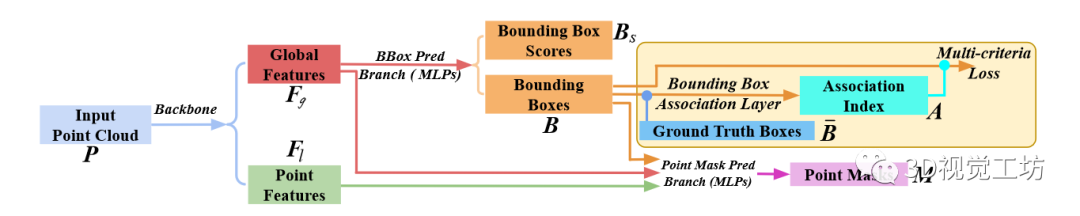
image.png 圖 3:3D-BoNet 框架的一般工作流程。
3D-BoNet的總體框架如圖所示,它主要由1) Instance-level bounding box prediction 2) Point-level mask prediction兩個分支組成。顧名思義,bounding box prediction分支用于預(yù)測點云中每個實例的邊界框,mask prediction分支用于為邊界框內(nèi)的點預(yù)測一個mask,進一步區(qū)分邊界框內(nèi)的點是屬于instance還是背景。
2 3D-BoNet
2.1 Bounding Box Prediction(邊界框預(yù)測)
邊界框編碼:在現(xiàn)有的物體檢測網(wǎng)絡(luò)中,邊界框通常由中心位置和三維長度或相應(yīng)的殘差以及方向來表示。為了簡單起見,我們只用兩個最小-最大頂點來表示矩形邊界框的參數(shù):
神經(jīng)層:如圖 4 所示,全局特征向量通過兩個全連接層,以 Leaky ReLU 作為非線性激活函數(shù)。然后再經(jīng)過另外兩個平行的全連接層。一層輸出 6H 維向量,然后將其重塑為 H × 2 × 3 張量。H 是一個預(yù)定義的固定邊框數(shù),整個網(wǎng)絡(luò)可預(yù)測的最大邊框數(shù)。另一層輸出一個 H 維向量,然后用 sigmoid 函數(shù)表示邊界框得分。分數(shù)越高,預(yù)測的邊框越有可能包含一個實例,因此邊框越有效。

圖 4:邊界框回歸分支的結(jié)構(gòu)。在計算多標(biāo)準(zhǔn)損失之前,將預(yù)測的 H 邊框與 T 地面真實邊框進行優(yōu)化關(guān)聯(lián)。
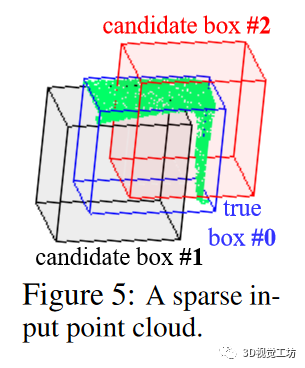
邊框關(guān)聯(lián)層:給定先前預(yù)測的 H 個邊界框(即 ),利用地面實況框來監(jiān)督網(wǎng)絡(luò)并不簡單,因為在我們的框架中,沒有預(yù)定義的錨點可以將每個預(yù)測框追溯到相應(yīng)的地面實況框。此外,對于每個輸入點云,地面實況箱的數(shù)量 都是不同的,通常與預(yù)定義的數(shù)量 不同,不過我們可以有把握地假設(shè)所有輸入點云的預(yù)定義數(shù)量 。此外,預(yù)測方框和地面實況方框都沒有方框順序。
最優(yōu)關(guān)聯(lián)公式:_為了從 中為的每個地面實況框關(guān)聯(lián)一個唯一的預(yù)測邊界框,我們將這一關(guān)聯(lián)過程表述為一個最優(yōu)分配問題。形式上,讓 成為布爾關(guān)聯(lián)矩陣,如果第 個預(yù)測框被分配給第個地面實況框,則其為1。在本文中也稱為關(guān)聯(lián)索引。讓 成為關(guān)聯(lián)成本矩陣,其中表示第 i 個預(yù)測方框被分配到第 j 個地面實況方框的成本。基本上,代價 代表兩個方框之間的相似度;代價越小,兩個方框越相似。因此,邊界方框關(guān)聯(lián)問題就是要找到成本最小的最優(yōu)分配矩陣 :
損失函數(shù) 在邊框關(guān)聯(lián)層之后,預(yù)測的邊框 和分數(shù) 都將使用關(guān)聯(lián)索引 進行重新排序,從而使最先預(yù)測的個邊框和分數(shù)與 個地面實況邊框很好地配對。_邊框預(yù)測的多標(biāo)準(zhǔn)損失_:上一個關(guān)聯(lián)層根據(jù)最小成本為每個地面實況箱找到最相似的預(yù)測箱,最小成本包括1) 頂點歐氏距離;2) 點上的 sIoU 成本;3) 交叉熵得分。因此,邊界框預(yù)測的損失函數(shù)自然是為了持續(xù)最小化這些成本而設(shè)計的。
其形式定義如下
請注意,我們只最小化 個配對方框的成本;其余個預(yù)測方框?qū)⒈缓雎裕驗樗鼈儧]有相應(yīng)的地面實況。因此,這個方框預(yù)測子分支與預(yù)定義的 值無關(guān)。由于負預(yù)測沒有受到懲罰,網(wǎng)絡(luò)可能會對一個實例預(yù)測出多個相似的方框。幸運的是,平行邊框得分預(yù)測的損失函數(shù)能夠緩解這一問題。
框選得分的預(yù)測差_:預(yù)測的框得分旨在表明相應(yīng)預(yù)測方框的有效性。通過關(guān)聯(lián)指數(shù) A 重新排序后,前 T 個得分的地面實況得分均為 "1",其余無效的個得分均為 "0"。
我們使用交叉熵損失來完成這項二元分類任務(wù):
基本上,這個損失函數(shù)獎勵的是預(yù)測正確的邊界框,而隱含地懲罰了對一個實例回歸多個相似邊界框的情況。
2.2Point Mask Prediction(點掩膜預(yù)測)
給定預(yù)測的邊界框 、學(xué)習(xí)到的點特征 和全局特征 ,點掩碼預(yù)測分支通過共享神經(jīng)層單獨處理每個邊界框。
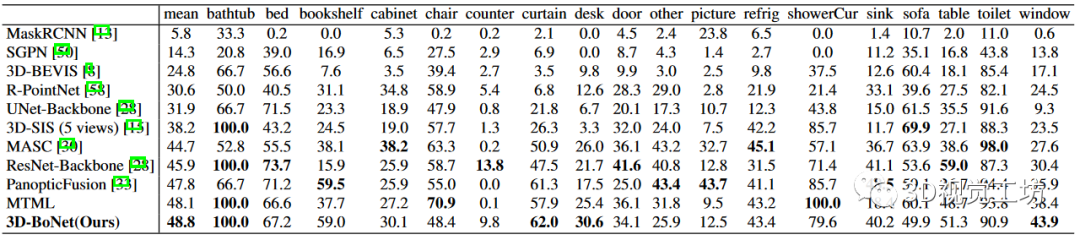
表 1:ScanNet(v2) 基準(zhǔn)(隱藏測試集)上的實例分割結(jié)果。指標(biāo)為 AP(%),IoU 閾值為 0.5。訪問日期:2019 年 6 月 2 日。
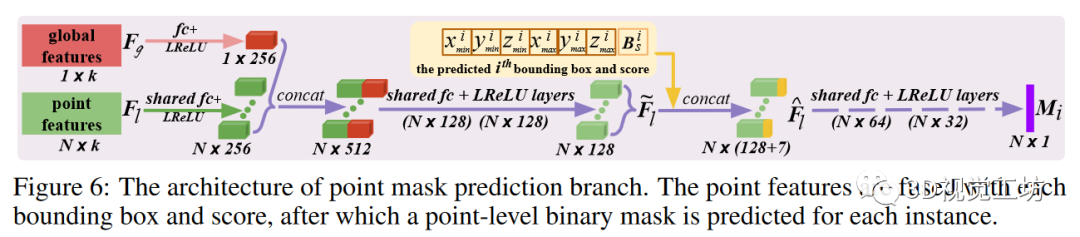
神經(jīng)層:如圖 6 所示,通過全連接層將點特征和全局特征壓縮為 256 維向量,然后進行連接并進一步壓縮為 128 維混合點特征。對于第 i 個預(yù)測的邊界框,估計的頂點和分數(shù)通過連接與特征 融合,產(chǎn)生框感知特征 然后,這些特征通過共享層,預(yù)測出一個點級二進制掩碼,表示為 我們使用 sigmoid 作為最后一個激活函數(shù)。
這種簡單的盒式融合方法計算效率極高,而現(xiàn)有技術(shù)中常用的 RoI Align則涉及昂貴的點特征采樣和對齊。損失函數(shù):根據(jù)先前的關(guān)聯(lián)指數(shù),預(yù)測的實例掩碼 與地面實況掩碼具有相似的關(guān)聯(lián)。由于實例點和背景點的數(shù)量不平衡,我們使用帶有默認超參數(shù)的焦點損失(focal loss),而不是標(biāo)準(zhǔn)的交叉熵損失(cross-entropy loss)來優(yōu)化這一分支。只有有效的 配對掩碼才會被用于損失
2.3 End-to-End Implementation(端到端實現(xiàn))
雖然我們的框架并不局限于任何點云網(wǎng)絡(luò),但我們采用 PointNet++ 作為骨干來學(xué)習(xí)局部和全局特征。與此同時,我們還實現(xiàn)了另一個獨立的分支,利用標(biāo)準(zhǔn)的 sof tmax 交叉熵損失函數(shù) 來學(xué)習(xí)每個點的語義。
骨干和語義分支的架構(gòu)與中使用的相同。給定輸入點云 P 后,上述三個分支被連接起來,并使用單一的組合多任務(wù)損失進行端到端訓(xùn)練:
我們使用 Adam 求解器及其默認超參數(shù)進行優(yōu)化。初始學(xué)習(xí)率設(shè)置為 5e-4,然后每 20 個歷元除以 2。整個網(wǎng)絡(luò)在 Titan X GPU 上從頭開始訓(xùn)練。我們在所有實驗中使用相同的設(shè)置,這保證了我們框架的可重復(fù)性。
3 Experiments
3.1 Evaluation on ScanNet Benchmark(ScanNet 基準(zhǔn)評估)
在實驗中,我們發(fā)現(xiàn)基于虛構(gòu) PointNet++ 的語義預(yù)測子分支性能有限,無法提供令人滿意的語義。得益于我們框架的靈活性,我們可以輕松地訓(xùn)練一個并行 SCN 網(wǎng)絡(luò),為我們的 3D-BoNet 預(yù)測實例估算出更精確的每點語義標(biāo)簽。

圖 7:這是一個有數(shù)百個物體(如椅子、桌子)的階梯教室,凸顯了實例分割所面臨的挑戰(zhàn)。不同的顏色表示不同的實例。相同的實例可能沒有相同的顏色。我們的框架能比其他框架預(yù)測出更精確的實例標(biāo)簽。
3.2 Evaluation on S3DIS Dataset(S3DIS 數(shù)據(jù)集評估)
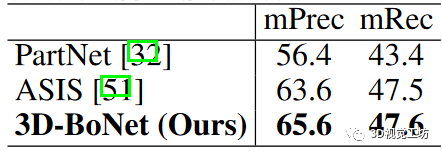
為了進行公平比較,我們使用與我們的框架相同的 PointNet++ 主干網(wǎng)和其他設(shè)置對 PartNet 基線進行了仔細訓(xùn)練。為了進行評估,我們報告了 IoU 閾值為 0.5 的經(jīng)典指標(biāo)平均精度(mPrec)和平均召回率(mRec)。需要注意的是,我們使用了相同的 BlockMerging 算法來合并我們的方法和 PartNet 基線中來自不同區(qū)塊的實例。最終得分是 13 個類別的平均值。列出了 mPrec/mRec 分數(shù), 顯示了定性結(jié)果。我們的方法遠遠超過了 PartNet 基線 ,也優(yōu)于 ASIS ,但并不顯著,主要原因是我們的語義預(yù)測分支(基于 vanilla PointNet++)不如 ASIS,后者將語義和實例特征緊密融合,實現(xiàn)了相互優(yōu)化。我們將把特征融合作為未來的探索方向。
3.3 Ablation Study(消融研究)
為了評估框架各組成部分的有效性,我們在S3DIS數(shù)據(jù)集最大的區(qū)域5上進行了6組消融實驗。
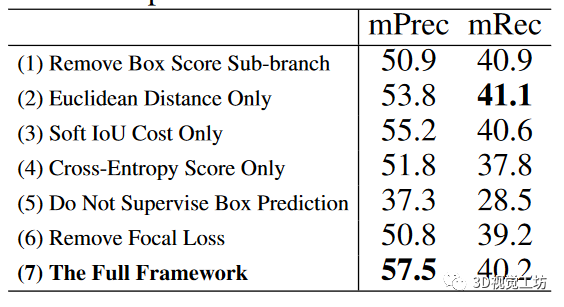
分析結(jié)果表顯示了消融實驗的得分。(1) 邊框得分的這一個子分支確實有利于整體實例分割性能,因為它傾向于懲罰重復(fù)的邊框預(yù)測。(2)與歐氏距離和交叉熵得分相比,由于我們的可微分算法 1,sIoU 成本往往更有利于方框關(guān)聯(lián)和監(jiān)督。由于三個標(biāo)準(zhǔn)各自偏好不同類型的點結(jié)構(gòu),在特定數(shù)據(jù)集上,三個標(biāo)準(zhǔn)的簡單組合不一定總是最優(yōu)的。(3) 如果沒有方框預(yù)測的監(jiān)督,性能就會顯著下降,這主要是因為網(wǎng)絡(luò)無法推斷出令人滿意的實例三維邊界,預(yù)測點掩模的質(zhì)量也會相應(yīng)下降。(4) 由于實例和背景點數(shù)不平衡。與焦點損失相比,標(biāo)準(zhǔn)交叉熵損失對點掩膜預(yù)測的效果較差。
3.4 Computation Analysis(計算分析)
(1) 對于基于點特征聚類的方法,包括 SGPN、ASIS、JSIS3D、3D-BEVIS、MASC,后聚類算法(如 Mean Shift)的計算復(fù)雜度趨向于 O(T N 2),其中 T 為實例數(shù),N 為輸入點數(shù)。(2) 對于基于密集提議的方法,包括 GSPN[58]、3D-SIS[15]和 PanopticFusion[33],通常需要區(qū)域提議網(wǎng)絡(luò)和非最大抑制來生成和修剪密集提議,計算成本高昂[33]。(3) PartNet 基線和我們的 3D-BoNet 都具有類似的高效計算復(fù)雜度 O(N)。根據(jù)經(jīng)驗,我們的 3D-BoNet 處理 4k 個點大約需要 20 毫秒的 GPU 時間,而 (1)(2) 中的大多數(shù)方法處理相同數(shù)量的點需要 200 毫秒以上的 GPU/CPU 時間。
4 Related Work(相關(guān)工作)
要從三維點云中提取特征,傳統(tǒng)方法通常是手工制作特征。近期基于學(xué)習(xí)的方法主要包括基于體素的方案和基于點的方案。語義分割 廣泛運用的包括PointNet 和基于卷積核的方法,基本上,這些方法中的大多數(shù)都可以用作我們的骨干網(wǎng)絡(luò),并與我們的 3D-BoNet 并行訓(xùn)練,以學(xué)習(xí)每個點的語義。物體檢測:相比現(xiàn)有方法,我們的方框預(yù)測分支與它們完全不同。我們的框架通過一次前向傳遞,直接從緊湊的全局特征回歸三維物體邊界框。實例分割 相比現(xiàn)有方法,我們的框架直接為明確檢測到的對象邊界內(nèi)的每個實例預(yù)測點級掩碼,而不需要任何后處理步驟。
5 Conclusion(結(jié)論)
其框架對于三維點云的實例分割來說簡單、有效且高效。但是,它也有一些局限性,這也是未來工作的方向。(1) 與其使用三個標(biāo)準(zhǔn)的非加權(quán)組合,不如設(shè)計一個模塊來自動學(xué)習(xí)權(quán)重,以適應(yīng)不同類型的輸入點云。(2) 與其訓(xùn)練一個單獨的語義預(yù)測分支,不如引入更先進的特征融合模塊,使語義分割和實例分割相互促進。(3) 我們的框架采用 MLP 設(shè)計,因此與輸入點的數(shù)量和順序無關(guān)。我們希望借鑒最近的研究成果,直接在大規(guī)模輸入點云上進行訓(xùn)練和測試,而不是分割成小塊。
編輯:黃飛
?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論