 電子發燒友App
電子發燒友App


從 ChatGPT 面世以來,引領了大模型時代的變革,除了大模型遍地開花以外,承載大模型進行推理的框架也是層出不窮,大有百家爭鳴的態勢。本文主要針對業界知名度較高的一些大模型推理框架進行相應的概述。
vLLM
GitHub: https://github.com/vllm-project/vllm
簡介
vLLM是一個開源的大模型推理加速框架,通過PagedAttention高效地管理attention中緩存的張量,實現了比HuggingFace Transformers高14-24倍的吞吐量。
PagedAttention 是 vLLM 的核心技術,它解決了LLM服務中內存的瓶頸問題。傳統的注意力算法在自回歸解碼過程中,需要將所有輸入Token的注意力鍵和值張量存儲在GPU內存中,以生成下一個Token。這些緩存的鍵和值張量通常被稱為KV緩存。
主要特性
通過PagedAttention對 KV Cache 的有效管理
傳入請求的continus batching,而不是static batching
支持張量并行推理
支持流式輸出
與 HuggingFace 模型無縫集成
與其他框架(HF、TGI)的性能對比
vLLM 的吞吐量比 HF 高 14 - 24 倍,比 TGI 高 2.2 - 2.5 倍。
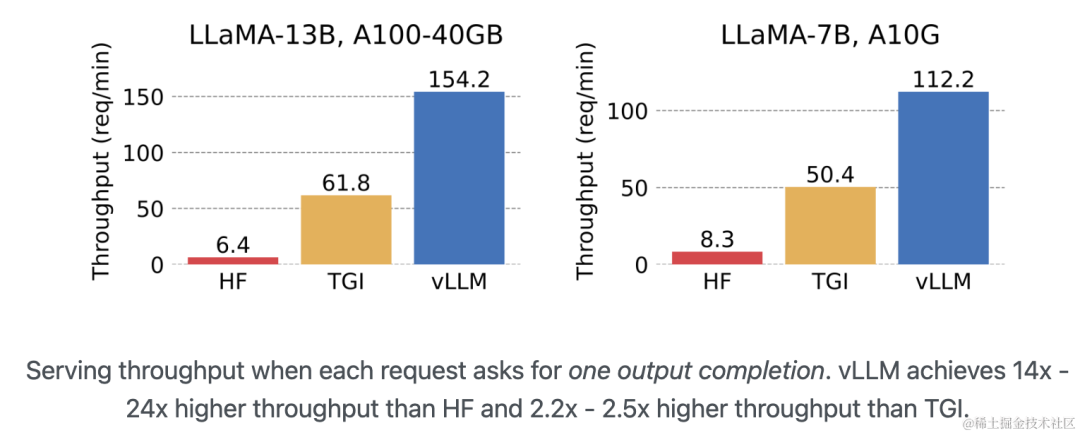
image.png
存在的問題
同樣的模型、參數和prompt條件下,vLLM推理和Huggingface推理結果不一致。
業界案例
vLLM 已經被用于 Chatbot Arena 和 Vicuna 大模型的服務后端。
HuggingFace TGI
GitHub: https://github.com/huggingface/text-generation-inference
簡介
Text Generation Inference(TGI)是 HuggingFace 推出的一個項目,作為支持 HuggingFace Inference API 和 Hugging Chat 上的LLM 推理的工具,旨在支持大型語言模型的優化推理。
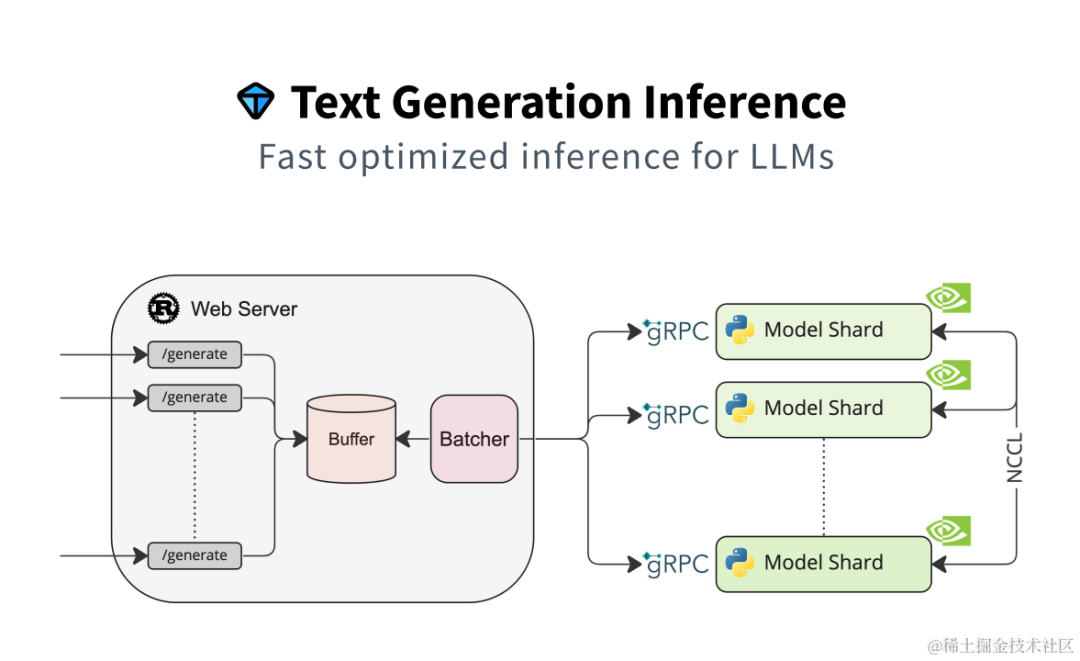
image.png
主要特性
支持張量并行推理
支持傳入請求 Continuous batching 以提高總吞吐量
使用 flash-attention 和 Paged Attention 在主流的模型架構上優化用于推理的 transformers 代碼。注意:并非所有模型都內置了對這些優化的支持。
使用bitsandbytes(LLM.int8())和GPT-Q進行量化
內置服務評估,可以監控服務器負載并深入了解其性能
輕松運行自己的模型或使用任何 HuggingFace 倉庫的模型
自定義提示生成:通過提供自定義提示來指導模型的輸出,輕松生成文本
使用 Open Telemetry,Prometheus 指標進行分布式跟蹤
支持的模型
BLOOM
FLAN-T5
Galactica
GPT-Neox
Llama
OPT
SantaCoder
Starcoder
Falcon 7B
Falcon 40B
MPT
Llama V2
Code Llama
適用場景
依賴 HuggingFace 模型,并且不需要為核心模型增加多個adapter的場景。
FasterTransformer
GitHub: https://github.com/NVIDIA/FasterTransformer
簡介
NVIDIA FasterTransformer (FT)?是一個用于實現基于Transformer的神經網絡推理的加速引擎。它包含Transformer塊的高度優化版本的實現,其中包含編碼器和解碼器部分。使用此模塊,您可以運行編碼器-解碼器架構模型(如:T5)、僅編碼器架構模型(如:BERT)和僅解碼器架構模型(如:GPT)的推理。
FT框架是用C++/CUDA編寫的,依賴于高度優化的 cuBLAS、cuBLASLt 和 cuSPARSELt 庫,這使您可以在 GPU 上進行快速的 Transformer 推理。
與 NVIDIA TensorRT 等其他編譯器相比,FT 的最大特點是它支持以分布式方式進行 Transformer 大模型推理。
下圖顯示了如何使用張量并行 (TP) 和流水線并行 (PP) 技術將基于Transformer架構的神經網絡拆分到多個 GPU 和節點上。
當每個張量被分成多個塊時,就會發生張量并行,并且張量的每個塊都可以放置在單獨的 GPU 上。在計算過程中,每個塊在不同的 GPU 上單獨并行處理;最后,可以通過組合來自多個 GPU 的結果來計算最終張量。
當模型被深度拆分,并將不同的完整層放置到不同的 GPU/節點上時,就會發生流水線并行。
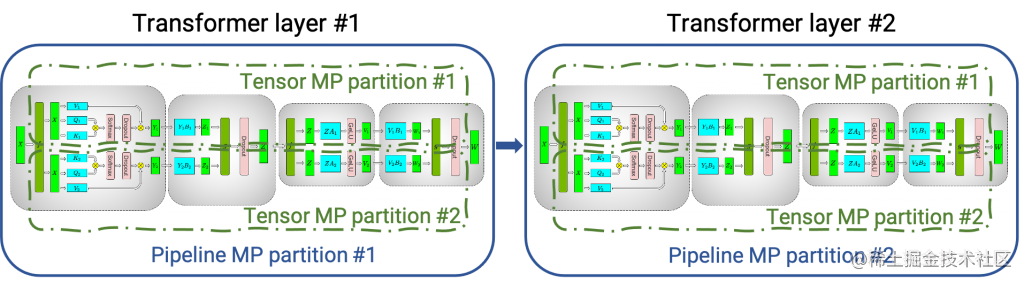
image.png
在底層,節點間或節點內通信依賴于 MPI 、 NVIDIA NCCL、Gloo等。因此,使用FasterTransformer,您可以在多個 GPU 上以張量并行運行大型Transformer,以減少計算延遲。同時,TP 和 PP 可以結合在一起,在多 GPU 節點環境中運行具有數十億、數萬億個參數的大型 Transformer 模型。
除了使用 C ++ 作為后端部署,FasterTransformer 還集成了 TensorFlow(使用 TensorFlow op)、PyTorch (使用 Pytorch op)和 Triton 作為后端框架進行部署。當前,TensorFlow op 僅支持單 GPU,而 PyTorch op 和 Triton 后端都支持多 GPU 和多節點。
FasterTransformer 中的優化技術
與深度學習訓練的通用框架相比,FT 使您能夠獲得更快的推理流水線以及基于 Transformer 的神經網絡具有更低的延遲和更高的吞吐量。FT 對 GPT-3 和其他大型 Transformer 模型進行的一些優化技術包括:
層融合(Layer fusion)
這是預處理階段的一組技術,將多層神經網絡組合成一個單一的神經網絡,將使用一個單一的核(kernel)進行計算。這種技術減少了數據傳輸并增加了數學密度,從而加速了推理階段的計算。例如, multi-head attention 塊中的所有操作都可以合并到一個核(kernel)中。
自回歸模型的推理優化(激活緩存)
為了防止通過Transformer重新計算每個新 token 生成器的先前的key和value,FT 分配了一個緩沖區來在每一步存儲它們。
雖然需要一些額外的內存使用,但 FT 可以節省重新計算的成本。該過程如下圖所示,相同的緩存機制用于 NN 的多個部分。
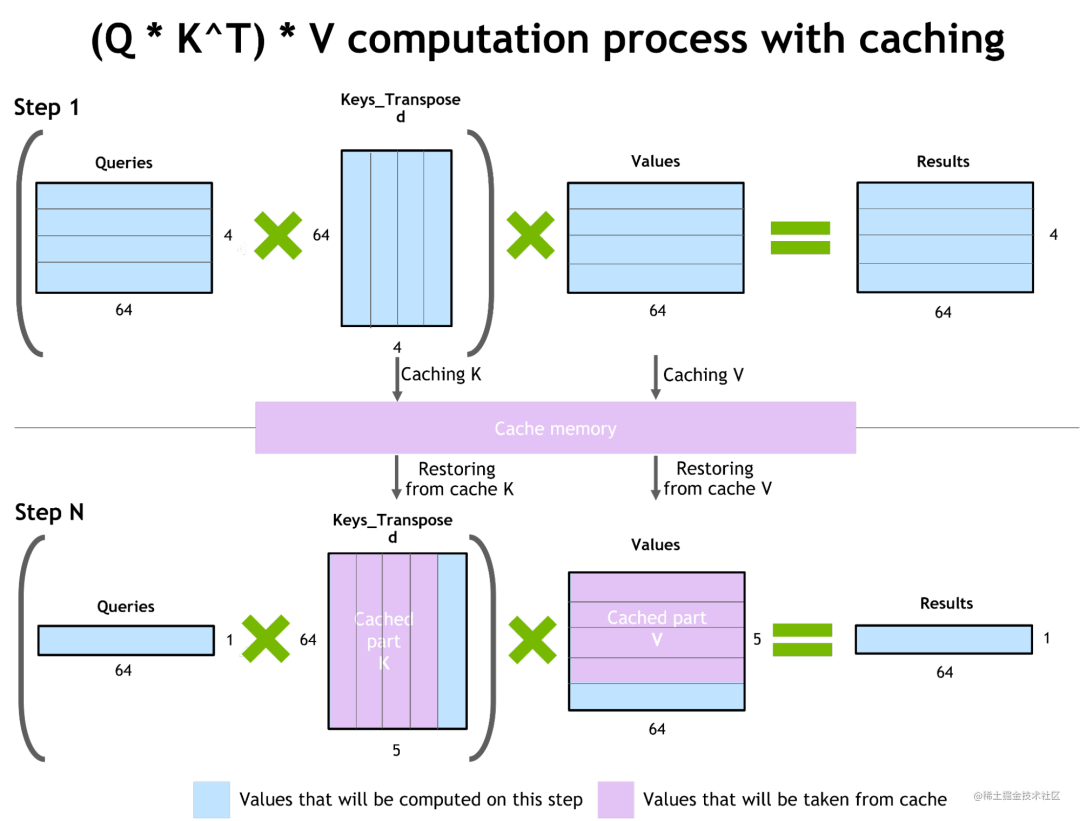
image.png
內存優化
與 BERT 等傳統模型不同,大型 Transformer 模型具有多達數萬億個參數,占用數百 GB 存儲空間。即使我們以半精度存儲模型,GPT-3 175b 也需要 350 GB。因此有必要減少其他部分的內存使用。
例如,在 FasterTransformer 中,我們在不同的解碼器層重用了激活/輸出的內存緩沖(buffer)。由于 GPT-3 中的層數為 96,因此我們只需要 1/96 的內存量用于激活。
使用 MPI 和 NCCL 實現節點間/節點內通信并支持模型并行
FasterTransormer 同時提供張量并行和流水線并行。對于張量并行,FasterTransformer 遵循了 Megatron 的思想。對于自注意力塊和前饋網絡塊,FT 按行拆分第一個矩陣的權重,并按列拆分第二個矩陣的權重。通過優化,FT 可以將每個 Transformer 塊的歸約(reduction)操作減少到兩次。
對于流水線并行,FasterTransformer 將整批請求拆分為多個微批,隱藏了通信的空泡(bubble)。FasterTransformer 會針對不同情況自動調整微批量大小。
MatMul 核自動調整(GEMM 自動調整)
矩陣乘法是基于 Transformer 的神經網絡中最主要和繁重的操作。FT 使用來自 CuBLAS 和 CuTLASS 庫的功能來執行這些類型的操作。重要的是要知道 MatMul 操作可以在“硬件”級別使用不同的底層(low-level)算法以數十種不同的方式執行。
GemmBatchedEx?函數實現了 MatMul 操作,并以cublasGemmAlgo_t作為輸入參數。使用此參數,您可以選擇不同的底層算法進行操作。
FasterTransformer 庫使用此參數對所有底層算法進行實時基準測試,并為模型的參數和您的輸入數據(注意層的大小、注意頭的數量、隱藏層的大小)選擇最佳的一個。此外,FT 對網絡的某些部分使用硬件加速的底層函數,例如:__expf、__shfl_xor_sync。
低精度推理
FT 的核(kernels)支持使用 fp16 和 int8 等低精度輸入數據進行推理。由于較少的數據傳輸量和所需的內存,這兩種機制都會加速。同時,int8 和 fp16 計算可以在特殊硬件上執行,例如:Tensor Core(適用于從 Volta 開始的所有 GPU 架構)。
除此之外還有快速的 C++ BeamSearch 實現、當模型的權重部分分配到八個 GPU 之間時,針對 TensorParallelism 8 模式優化的 all-reduce。
支持的模型
目前,FT 支持了 Megatron-LM GPT-3、GPT-J、BERT、ViT、Swin Transformer、Longformer、T5 和 XLNet 等模型。您可以在 GitHub 上的 FasterTransformer庫中查看最新的支持矩陣。
與其他框架(PyTorch)的性能對比
FT 適用于計算能力 >= 7.0 的 GPU,例如: V100、A10、A100 等。
下圖展示了 GPT-J 6B 參數的模型推斷加速比較:
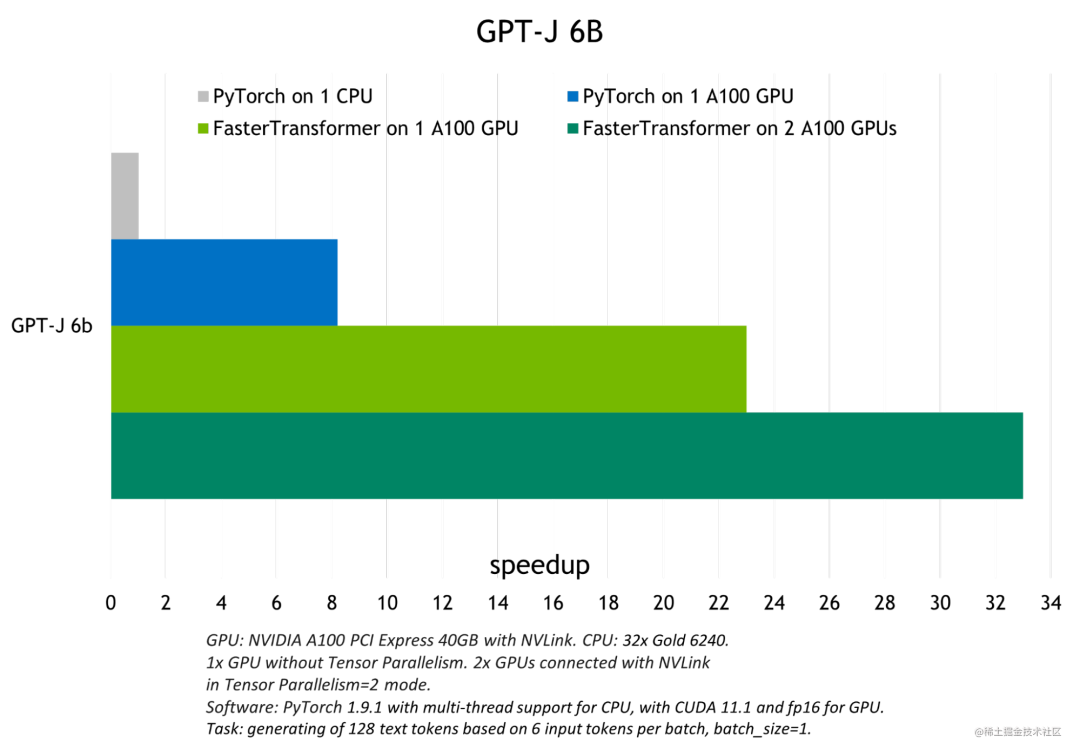
image.png
存在的問題
英偉達新推出了TensorRT-LLM,相對來說更加易用,后續FasterTransformer將不再為維護了。
DeepSpeed-MII
GitHub: https://github.com/microsoft/DeepSpeed-MII
簡介
DeepSpeed-MII 是 DeepSpeed 的一個新的開源 Python 庫,旨在使模型不僅低延遲和低成本推理,而且還易于訪問。
MII 提供了對數千種廣泛使用的深度學習模型的高度優化實現。
與原始PyTorch實現相比,MII 支持的模型可顯著降低延遲和成本。
為了實現低延遲/低成本推理,MII 利用 DeepSpeed-Inference 的一系列廣泛優化,例如:transformers 的深度融合、用于多 GPU 推理的自動張量切片、使用 ZeroQuant 進行動態量化等。
MII 只需幾行代碼即可通過 AML 在本地和 Azure 上低成本部署這些模型。
MII 工作流程
下圖顯示了 MII 如何使用 DS-Inference 自動優化 OSS 模型;然后,使用 GRPC 在本地部署,或使用 AML Inference 在 Microsoft Azure 上部署。
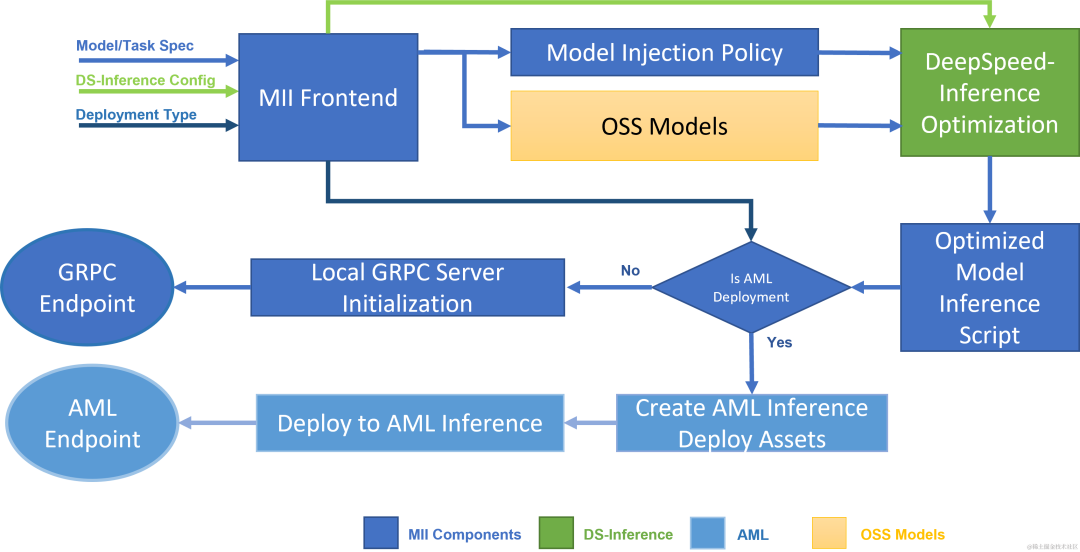
image.png
MII 的底層由 DeepSpeed-Inference 提供支持。根據模型類型、模型大小、批量大小和可用硬件資源,MII 自動應用 DeepSpeed-Inference 中的一組適當的系統優化,以最大限度地減少延遲并最大限度地提高吞吐量。它通過使用許多預先指定的模型注入策略之一來實現這一點,該策略允許 MII 和 DeepSpeed-Inference 識別底層 PyTorch 模型架構并用優化的實現替換它。在此過程中,MII 使 DeepSpeed-Inference 中一系列的優化自動可用于其支持的數千種流行模型。
支持的模型和任務
MII 目前支持超過 50,000 個模型,涵蓋文本生成、問答、文本分類等一系列任務。MII 加速的模型可通過 Hugging Face、FairSeq、EluetherAI 等多個開源模型存儲庫獲取。我們支持基于 Bert、Roberta 或 GPT 架構的稠密模型,參數范圍從幾億參數到數百億參數。除此之外,MII將繼續擴展該列表,支持即將推出的大規模千億級以上參數稠密和稀疏模型。
目前 MII 支持以下 HuggingFace Transformers 模型系列:
?
| model family | size range | ~model count |
|---|---|---|
| llama | 7B - 65B | 1,500 |
| bloom | 0.3B - 176B | 480 |
| stable-diffusion | 1.1B | 3,700 |
| opt | 0.1B - 66B | 460 |
| gpt_neox | 1.3B - 20B | 850 |
| gptj | 1.4B - 6B | 420 |
| gpt_neo | 0.1B - 2.7B | 700 |
| gpt2 | 0.3B - 1.5B | 11,900 |
| xlm-roberta | 0.1B - 0.3B | 4,100 |
| roberta | 0.1B - 0.3B | 8,700 |
| distilbert | 0.1B - 0.3B | 4,700 |
| bert | 0.1B - 0.3B | 23,600 |
?
與其他框架(PyTorch)的性能對比
MII 將 Big-Science Bloom 176B 模型的延遲降低了 5.7 倍,同時將成本降低了 40 倍以上。同樣,它將部署 Stable Diffusion 的延遲和成本降低了 1.9 倍。
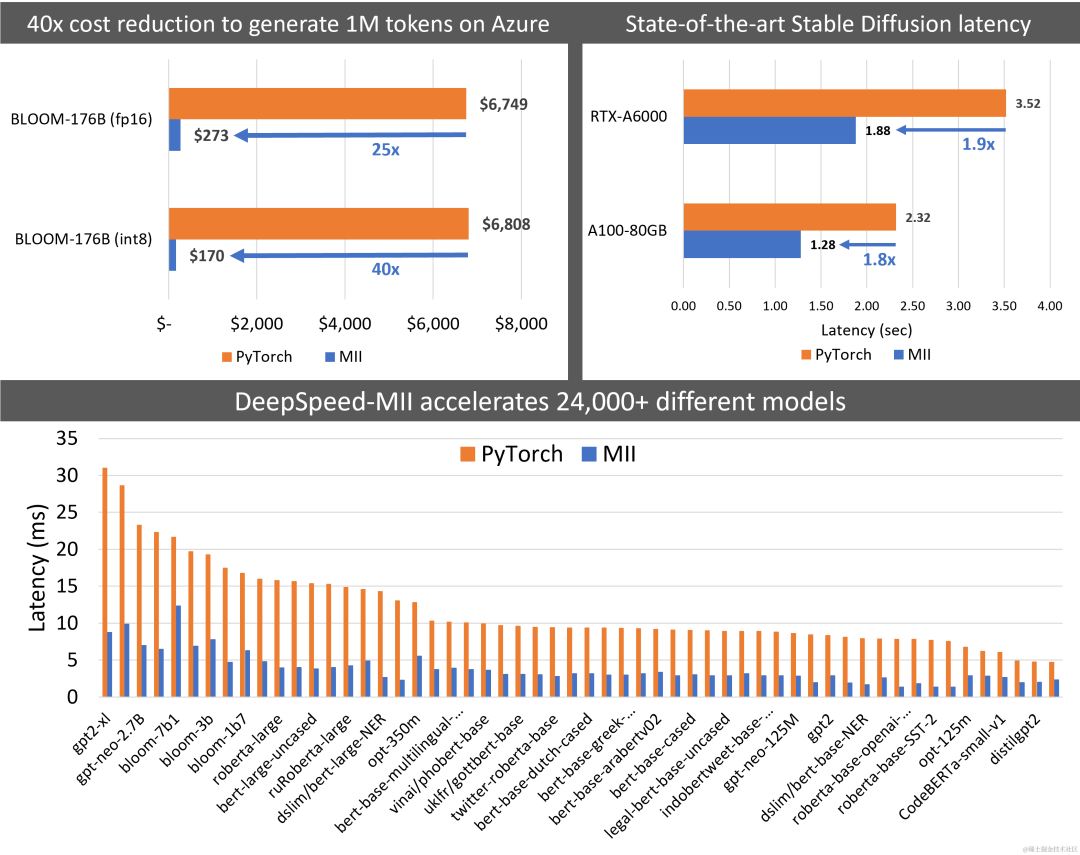
image.png
FlexFlow Server
GitHub: https://github.com/flexflow/FlexFlow/tree/inference
簡介
FlexFlow Serve 是一個開源編譯器和分布式系統,用于低延遲、高性能 LLM 服務。
主要特征
投機(Speculative) 推理
使 FlexFlow Serve 能夠加速 LLM 服務的一項關鍵技術是Speculative推理,它結合了各種集體boost-tuned的小型投機模型 (SSM) 來共同預測 LLM 的輸出;
預測被組織為token樹,每個節點代表一個候選 token 序列。使用一種新穎的基于樹的并行解碼機制,根據 LLM 的輸出并行驗證由 token 樹表示的所有候選 token 序列的正確性。
FlexFlow Serve 使用 LLM 作為 token 樹驗證器而不是增量解碼器,這大大減少了服務生成 LLM 的端到端推理延遲和計算要求,同時,可證明保持模型質量。
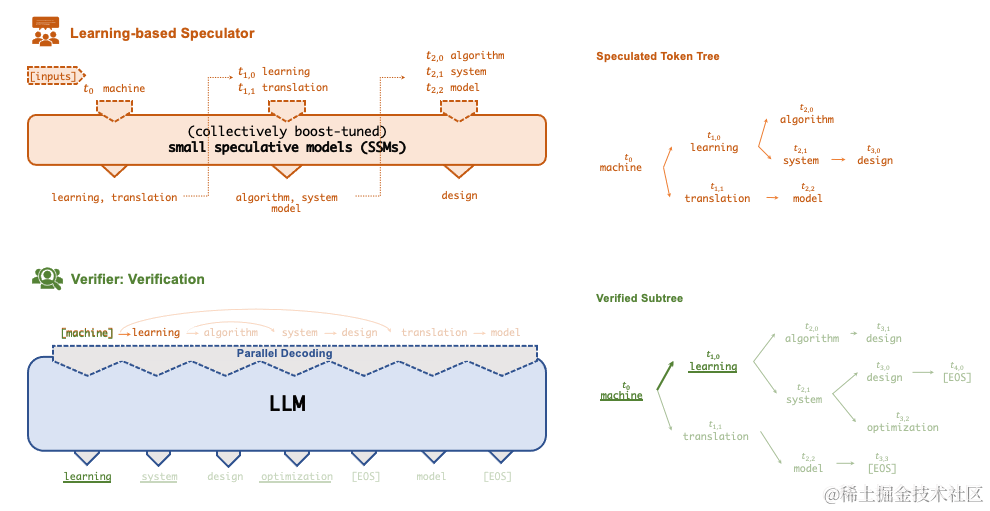
image.png
FlexFlow Serve 還提供基于Offloading的推理,用于在單個 GPU 上運行大型模型(例如:llama-7B)。
CPU Offloading是將張量保存在CPU內存中,并且在計算時僅將張量復制到GPU。
注意:
現在我們有選擇地offload最大的權重張量(線性、注意力中的權重張量)。此外,由于小模型占用的空間要少得多,如果不構成GPU內存瓶頸,offload會帶來更多的運行空間和計算成本,因此,我們只對大模型進行offload。可以通過啟用 -offload 和 -offload-reserve-space-size 標志來運行offloading。
支持量化
FlexFlow Serve 支持 int4 和 int8 量化。壓縮后的張量存儲在CPU端, 一旦復制到 GPU,這些張量就會進行解壓縮并轉換回其原始精度。
支持的 LLMs 和 SSMs
FlexFlow Serve 當前支持以下模型架構的所有Hugingface模型:
LlamaForCausalLM / LLaMAForCausalLM (例如:LLaMA/LLaMA-2, Guanaco, Vicuna, Alpaca, ...)
OPTForCausalLM (OPT家族模型)
RWForCausalLM (Falcon家族模型)
GPTBigCodeForCausalLM (Starcoder家族模型)
以下是我們已經測試過并且可以使用 SSM 的模型列表:
?
| 模型 | 在 HuggingFace 中的模型 id | Boost-tuned SSMs |
|---|---|---|
| LLaMA-7B | decapoda-research/llama-7b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-13B | decapoda-research/llama-13b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-30B | decapoda-research/llama-30b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-65B | decapoda-research/llama-65b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-7B | meta-llama/Llama-2-7b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-13B | meta-llama/Llama-2-13b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-70B | meta-llama/Llama-2-70b-hf | LLaMA-68M , LLaMA-160M |
| OPT-6.7B | facebook/opt-6.7b | OPT-125M |
| OPT-13B | facebook/opt-13b | OPT-125M |
| OPT-30B | facebook/opt-30b | OPT-125M |
| OPT-66B | facebook/opt-66b | OPT-125M |
| Falcon-7B | tiiuae/falcon-7b | ? |
| Falcon-40B | tiiuae/falcon-40b | ? |
| StarCoder-15.5B | bigcode/starcoder | ? |
?
與其他框架(vLLM、TGI、FasterTransformer)的性能對比
FlexFlow Serve 在單節點多 GPU 推理方面比現有系統高 1.3-2.0 倍,在多節點多 GPU 推理方面比現有系統高 1.4-2.4 倍。
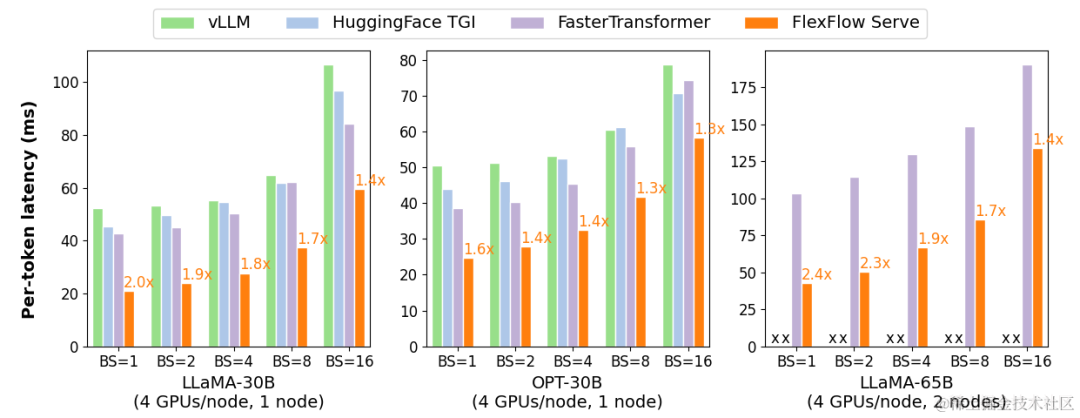
image.png
提示數據集
FlexFlow 提供了五個用于評估 FlexFlow Serve 的提示數據集:
Chatbot 指令提示:https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatbot.json
ChatGPT 提示:https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatgpt.json
WebQA:https://specinfer.s3.us-east-2.amazonaws.com/prompts/webqa.json
Alpaca:https://specinfer.s3.us-east-2.amazonaws.com/prompts/alpaca.json
PIQA:https://specinfer.s3.us-east-2.amazonaws.com/prompts/piqa.json
未來的規劃
FlexFlow Serve 正在積極開發中,主要專注于以下任務:
AMD 基準測試。目前正在積極致力于在 AMD GPU 上對 FlexFlow Serve 進行基準測試,并將其與 NVIDIA GPU 上的性能進行比較。
Chatbot prompt 模板和多輪對話
支持 FastAPI
與LangChain集成進行文檔問答
LMDeploy
GitHub: https://github.com/InternLM/lmdeploy
簡介
LMDeploy 由 MMDeploy 和 MMRazor 團隊聯合開發,是涵蓋了 LLM 任務的全套輕量化、部署和服務解決方案。這個強大的工具箱提供以下核心功能:
高效推理引擎 TurboMind:基于 FasterTransformer推理引擎,實現了高效推理引擎 TurboMind,支持 InternLM、LLaMA、vicuna等模型在 NVIDIA GPU 上的推理。
交互推理方式:通過緩存多輪對話過程中 attention 的 k/v,記住對話歷史,從而避免重復處理歷史會話。
多 GPU 部署和量化:提供了全面的模型部署和量化(支持使用AWQ算法對模型權重進行 INT4 量化,支持 KV Cache INT8 量化)支持,已在不同規模上完成驗證。
persistent batch 推理:進一步優化模型執行效率。
支持張量并行推理(注意:量化部署時不支持進行張量并行)
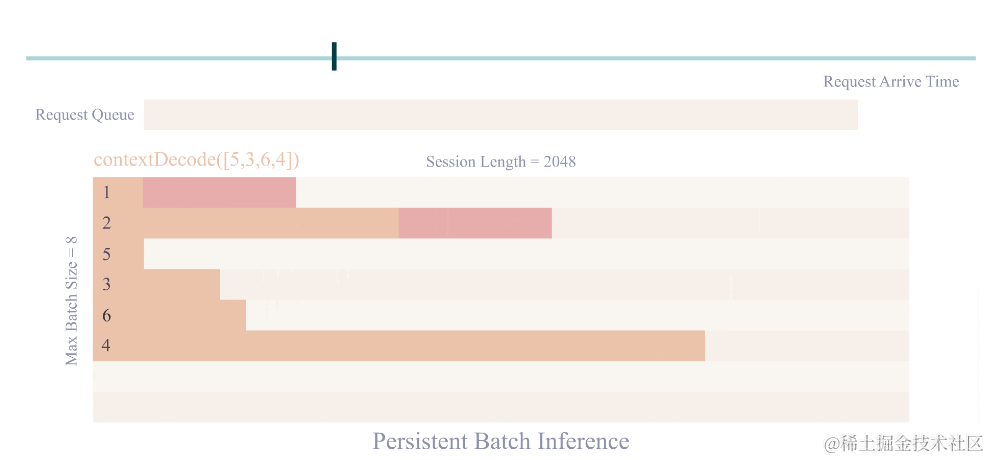
image.png
支持的模型
LMDeploy 支持 TurboMind 和 Pytorch 兩種推理后端。
TurboMind
注意:
W4A16 推理需要 Ampere 及以上架構的 Nvidia GPU
?
| 模型 | 模型并行 | FP16 | KV INT8 | W4A16 | W8A8 |
|---|---|---|---|---|---|
| Llama | Yes | Yes | Yes | Yes | No |
| Llama2 | Yes | Yes | Yes | Yes | No |
| InternLM-7B | Yes | Yes | Yes | Yes | No |
| InternLM-20B | Yes | Yes | Yes | Yes | No |
| QWen-7B | Yes | Yes | Yes | No | No |
| Baichuan-7B | Yes | Yes | Yes | Yes | No |
| Baichuan2-7B | Yes | Yes | No | No | No |
| Code Llama | Yes | Yes | No | No | No |
?
Pytorch
?
| 模型 | 模型并行 | FP16 | KV INT8 | W4A16 | W8A8 |
|---|---|---|---|---|---|
| Llama | Yes | Yes | No | No | No |
| Llama2 | Yes | Yes | No | No | No |
| InternLM-7B | Yes | Yes | No | No | No |
?
與其他框架(HF、DeepSpeed、vLLM)的性能對比
場景一: 固定的輸入、輸出token數(1,2048),測試 output token throughput
場景二: 使用真實數據,測試 request throughput
測試配置:LLaMA-7B, NVIDIA A100(80G)
TurboMind 的 output token throughput 超過 2000 token/s, 整體比 DeepSpeed 提升約 5% - 15%,比 huggingface transformers 提升 2.3 倍在 request throughput 指標上,TurboMind 的效率比 vLLM 高 30%。
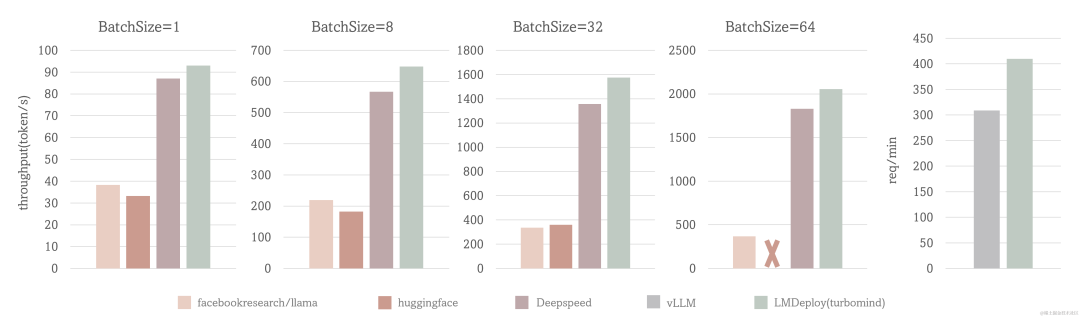
image.png
結語
總而言之,大模型推理框架的核心目標都是為了降低延遲;同時,盡可能地提升吞吐量;從上面的框架中可以看到,每個框架各有優缺點,但是目前來看,還沒有一個LLM推理框架有一統天下的態勢,大家都在加速迭代。
編輯:黃飛
?


















 工商網監
工商網監
評論