 電子發(fā)燒友App
電子發(fā)燒友App


摘要
人工智能(AI)方法在科學應用中變得至關重要,有助于加速科學發(fā)現。大語言模型(LLM)由于其跨領域的卓越泛化能力,被認為是解決一些具有挑戰(zhàn)性的問題的很有前景的方法。模型的有效性和應用程序的準確性取決于它們在底層硬件設備上的有效執(zhí)行。專門的人工智能加速器硬件系統(tǒng)可用于加速人工智能相關應用。然而,這些人工智能加速器在大語言模型上的性能比較此前尚未被研究過。在本文中,我們系統(tǒng)地研究了多個人工智能加速器和GPU上的LLM,并評估了它們在這些模型中的性能特征。我們用(i)使用Transformer block的微基準、(ii)GPT-2模型和(iii)LLM驅動的科學用例GenSLM來評估這些系統(tǒng)。文章展示了我們對模型性能的發(fā)現和分析,以更好地理解人工智能加速器的內在能力。此外,我們的分析也考慮了關鍵因素,如序列長度、縮放行為、稀疏性和對梯度累積步驟的敏感性。
I.介紹
將人工智能(AI)用于科學已經引起了科研機構和超級計算設備越來越多的興趣,目的是通過涉及AI的新方法加速科學發(fā)現。這種協(xié)同作用增加了人們對采用新型人工智能驅動技術的興趣,以幫助開發(fā)復雜科學問題的解決方案,如蛋白質結構預測、宇宙學參數預測、中微子粒子檢測、醫(yī)學藥物設計、基因組模型和天氣預報模型等。最常用的人工智能技術包括進化神經網絡、遞歸神經網絡、圖神經網絡和大語言模型(LLM),這些技術以其獨特的結構特征,能夠有效幫助科學家進行研究。近年來,人工智能中的自然語言處理領域經歷了巨大的增長,這極大促進了LLM的發(fā)展,使其能夠用于各種任務,如問答、文本摘要和語言翻譯。這些模型在科學的AI應用中將變得越來越重要。
LLM,如Generative Pre-trained Transformers(GPT)GPT-3、LLaMA、LLaMA 2和Bloom,其復雜性以及模型輸出結果質量都有了巨大的提高。這種增長的部分原因是基于Transformer的模型的迅速發(fā)展,它既是傳統(tǒng)應用程序的事實架構,也是科學用例的有力工具。從加速藥物發(fā)現到理解基因序列,基于Transformer的架構已經部署在許多應用上。例如,GenSLM提供了一個基于LLM的基礎模型來預測Sars-CoV2變異毒株。它的優(yōu)勢在于它能夠為設計有效的抗病毒藥物提供信息。GenSLM模型是在超過1.1億個原始核苷酸序列的廣泛數據集上訓練的,模型規(guī)模在2500萬至250億個可訓練參數之間。然而,訓練具有大模型參數和較長序列長度的GPT變體LLM需要專門的計算資源和軟件堆棧,從中實現技術創(chuàng)新和優(yōu)化。
為了滿足這些需求,出現了基于非傳統(tǒng)架構(如數據流)設計的人工智能加速器。這些加速器是定制的,以其強大的硬件計算引擎和新穎的軟件優(yōu)化有效支持人工智能工作負載。它們被證明可以有效地訓練多種人工智能模型,其中特別關注LLM的訓練。憑借其獨特的系統(tǒng)特性,這些人工智能加速器能夠應對LLM帶來的挑戰(zhàn)。這些加速器除了提供一套預先訓練的GPT模型外,還能夠運行一些最大規(guī)模的GPT模型。這些模型展示了人工智能加速器的多功能性和可擴展性。隨著LLM的規(guī)模和復雜性的增加,創(chuàng)新的訓練技術變得至關重要,以進一步增強具有數十億參數的LLM的訓練。
在不同的硬件平臺上評估LLM對于理解傳統(tǒng)和非傳統(tǒng)體系結構的能力和局限性至關重要。先前的工作已經在超級計算機上研究了LLM,并使用傳統(tǒng)的深度學習基準來提供對其能力的詳細評估與分析。然而,之前的研究尚未對各種人工智能加速器進行全面評估,尤其是LLM。本文旨在通過對多個人工智能加速器上的大語言模型進行詳細的性能評估來解決這一差距,這是我們所知的第一個此類基準研究。本文的主要貢獻是:
對最先進的人工智能加速器上的LLM進行了系統(tǒng)評估。
專注于Transformer block微基準,它是基于GPT的模型中的核心組件。
對GPT-2 XL 1.5B參數模型進行全面評估,以深入了解所有系統(tǒng)的模型性能。
科學應用的移植和評估:GenSLM,基因測序的基礎模型。
研究序列長度、稀疏性和梯度累積步驟對模型吞吐量的影響。
我們在第二節(jié)中概述了LLM和各種人工智能加速器,然后在第三節(jié)中介紹了評估模型的細節(jié),即Transformer block微基準、GPT-2XL和GenSLM應用。我們在第四節(jié)中描述了LLM在不同人工智能加速器上的實現。我們在第五節(jié)中展示了實驗結果,然后在第六節(jié)中給出了結論。
II.大語言模型和人工智能加速器綜述
大語言模型是一種使用深度學習算法處理和生成自然語言文本的人工智能系統(tǒng)。近年來,由于這些模型能夠執(zhí)行廣泛的語言相關任務,如機器翻譯、文本摘要和問答,因此它們越來越受歡迎。深度學習技術的進步推動了大語言模型的發(fā)展,特別是在Transformer模型領域。這些模型使用自注意力機制來處理文本輸入,使它們能夠捕捉語言數據中的復雜模式和關系。他們還使用無監(jiān)督學習技術在大型數據集上進行預訓練,如掩蔽語言建模和上下文預測,這有助于他們學習廣泛的語言特征和結構。對特定任務進行微調可以進一步提高它們的性能和適應性。
最著名的LLM之一是GPT(Generative Pretrained Transformer)系列,它由OpenAI開發(fā),用于回答問題、翻譯語言和生成文本。這些任務是通過在未標記文本的不同數據語料庫上生成語言模型的預訓練來實現的,然后對特定任務進行有區(qū)別的微調。微調過程中的任務感知輸入轉換有助于在對模型架構進行最小更改的情況下實現有效轉移。由于神經元結構的差異,GPT模型可以大致分為GPT、GPT-2、GPT-3和最近的GPT-4。
由基于GPU的系統(tǒng)和新型非傳統(tǒng)人工智能硬件(如數據流架構)組成的人工智能加速器已被證明可以提高各種人工智能模型的效率。下面我們將介紹本研究中使用的加速器,配置列于表I中。
表一:評估的人工智能加速器的特性
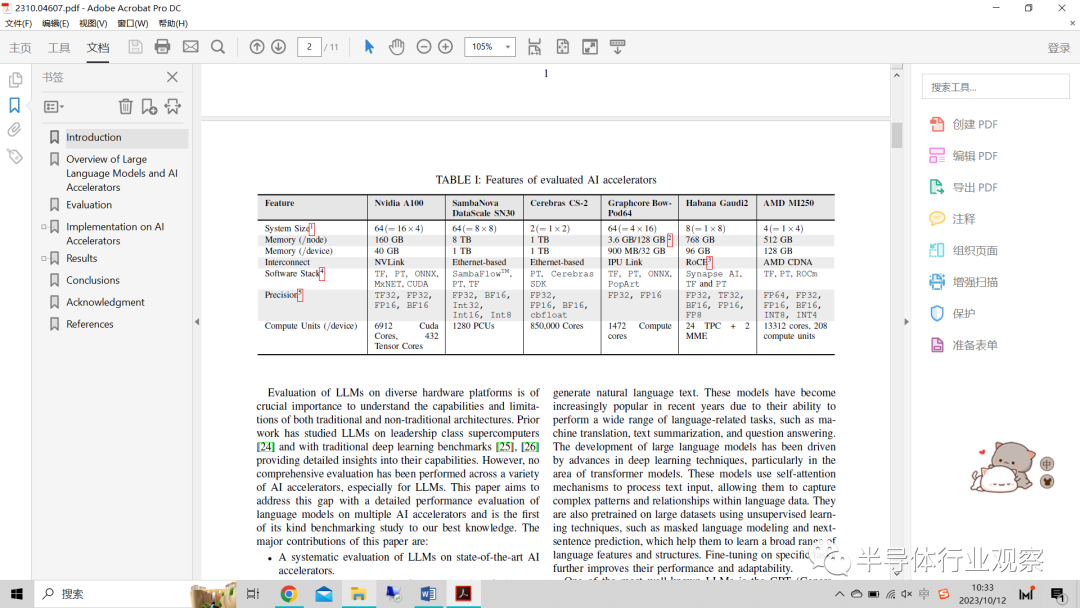
Nvidia A100:A100 GPU由6912個CUDA內核和432個Tensor內核組成,用于加速并行工作負載。在單個DGX節(jié)點上,有4個A100 GPU,與NVLink互連。我們使用微軟Megatron-DepSpeed框架的分叉實現進行評估。在這樣做的過程中,我們可以充分利用DeepSpeed的各種優(yōu)化和方便的功能,如ZeRO卸載和自動度量跟蹤(帶有通信+FLOP分析)。所有實驗都是在Argonne Leadership Computing Facility(ALCF)的Polaris超級計算機上進行的,每個節(jié)點有4個A100 GPU和40 GB內存。
Cerebras CS-2:Cerebras CS 2是一款晶圓級深度學習加速器,包括85萬個處理內核,每個內核提供48KB的專用SRAM內存,芯片總容量為40GB,并相互連接以優(yōu)化帶寬和延遲。該系統(tǒng)已擴展到通過SwarmX結構和MemoryX存儲子系統(tǒng)互連的兩個CS-2 waferscale引擎節(jié)點,以啟用大型模型。晶圓級集群支持重量流執(zhí)行模式,其中每個模型層逐個加載。該功能允許用戶運行大語言模型,其中每一層的權重都適合內存,但不適合整個模型。該軟件平臺集成了流行的機器學習框架,如PyTorch。對于單個Cerebras CS-2,支持的最大模型是GPT-3(175B參數模型),CS-2可以支持高達58k的序列長度。
SambaNova SN30:SambaNova DataScale系統(tǒng)使用第二代可重構數據流單元(RDU)處理器來實現最佳的數據流處理和加速。每個RDU具有1280個模式計算單元(PCU)和1TB的片外存儲器。該系統(tǒng)由八個節(jié)點組成,每個節(jié)點有八個互連的RDU,以實現模型和數據的并行性。SambaFlow,其軟件堆棧,從PyTorch機器學習框架中提取、優(yōu)化數據流圖并將其映射到RDU。SN30可以在4個RDU上訓練多達176B參數的模型。
Graphcore Bow Pod64:Graphcore22 PB級的Bow Pod 64系統(tǒng)是Graphcore的最新一代加速器。它是一個單機架系統(tǒng),由64個帶有自定義互連的Bow級IPU組成。Graphcore軟件堆棧包括Poplar SDK,并支持TensorFlow和PyTorch。Bow系統(tǒng)目前支持具有256個IPU的GPT-3 175B參數模型。
Habana Gaudi2:Habana Godi2處理器具有兩個矩陣乘法引擎(MME)、24個完全可編程的VLIW SIMD張量處理器內核,將24個100 GbE端口的聚合以太網RDMA(RoCE)集成到每個處理器芯片中,以有效擴展訓練。Gaudi系統(tǒng)由一個HLS-2服務器和八個Gaudi HL-225H卡組成。軟件堆棧包括SynapseAI堆棧,并支持TensorFlow和PyTorch。它支持現有的深度學習優(yōu)化庫DeepSpeed和定制庫Optimum Habana,后者是Transformer庫和Habana的Gaudi處理器(HPU)之間的接口。在Gaudi系統(tǒng)上,目前驗證的最大模型是在384張Gaudi 2卡上運行的GPT-3(175B參數模型)。
AMD MI250:AMD MI250 GPU基于CDNA2架構,由分布在208個計算單元上的13312個流處理器組成,并配有128 GB專用HBM2e內存,內存帶寬為3.276 TB/s。它能夠實現FP16的362.1 TFlops和FP32的45.3 TFlops的峰值性能。每個GPU使用PCIe Gen4連接到主機,并使用InfiniBand進行節(jié)點間通信。AMD ROCm開放軟件平臺支持常見的DL堆棧,包括Tensorflow和PyTorch,以及rocBLAS、rocSPARSE、rocFFT和RCCL(ROCm集體通信庫)等庫。
III. 評估
在這項工作中,我們主要關注評估(i)Transformer基準,(ii)GPT 2-XL模型,以及(iii)科學應用GenSLM(這是一種基因組測序的基礎模型)。
(1) Transformer微基準:要評估AI加速器上Transformer基準的性能,必須考慮幾個關鍵因素。首先,重要的是選擇適當的微型基準,以反映所使用的Transformer模型的工作量。一旦選擇了合適的微基準,就有必要收集性能指標,例如吞吐量,這可以通過測量每秒處理以完成一定數量迭代的輸入數量來完成。此外,監(jiān)控硬件資源(如內存和計算單元)的利用率也很重要。最后,建議將傳統(tǒng)NVIDIA GPU的性能與其他AI加速器進行比較,以更全面地了解它們的優(yōu)缺點。通過仔細評估這些因素,可以有效預測AI加速器上Transformer模型的性能。
Transformer block(圖1)是基于Transformer模型的一個廣泛認可和建立的微觀基準。由于幾個原因,Transformer block是微型基準的理想選擇。首先,它是自然語言處理任務(如語言建模和文本生成)中廣泛使用的構建塊,使其成為許多LLM應用程序的相關基準。其次,與較大的Transformer模型相比,Transformer block相對簡單且尺寸較小,這使得運行和評估更容易。這也允許在評估新硬件架構時進行更快的實驗。最后,Transformer block包括Transformer模型的許多關鍵組件,包括自注意層和前饋層,使其成為Transformer模型的合適代表。總的來說,Transformer block是一個公認且廣泛接受的微型基準,是評估LLM模型性能的絕佳選擇。
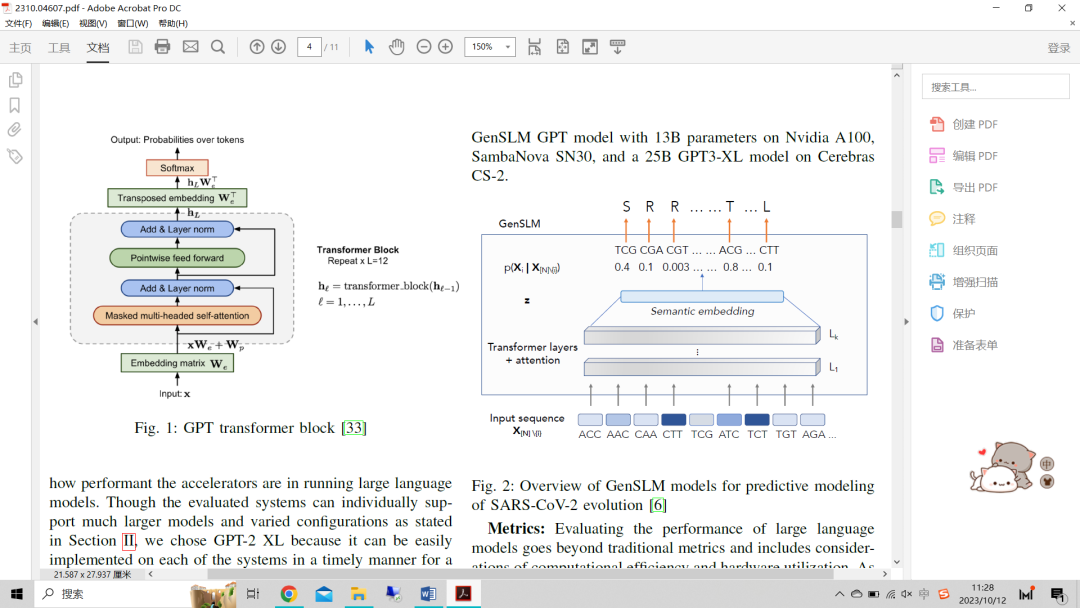
圖1:GPT transformer block
Transformer block由一個多頭自注意層和一個前饋神經網絡層組成。Transformer block的輸入是一個令牌序列。在這項工作中,我們評估的輸入序列的長度為1024。為了計算Transformer block的FLOP,我們需要考慮每層所需的操作次數。自注意層需要O(n2d)FLOP,其中n是序列長度,d是隱藏維度。前饋神經網絡層需要O(ndk)FLOP,其中k是隱藏層的大小。因此,Transformer block的FLOP的總數為O(n2d+ndk)。
(2) GPT-2XL:在這項研究中,我們使用GPT-2XL 1.5B參數模型進行預訓練實驗,以分析加速器在運行大語言模型時的性能。盡管如第二節(jié)所述,被評估的系統(tǒng)可以單獨支持更大的模型和不同的配置,但我們選擇GPT-2 XL是因為它可以及時在每個系統(tǒng)上輕松實現,以便進行公平的比較。此外,GPT-2大小的模型的內存和計算需求與每個系統(tǒng)上的最小計算單元節(jié)點非常匹配;因此,這里獲得的測試結論可以擴展,以幫助推動選擇加速器的決策,這些加速器可以為任何給定的基于Transformer的大模型架構產生最佳性能。本次評估中使用的數據集是開放式Web文本(OWT),它是WebText語料庫的開源版本。它由8013769個文檔中的38 GB文本數據組成,這些文本數據是從Reddit上共享的URL中提取的內容,至少有三次投票支持。對于這個模型,我們測量了每個系統(tǒng)上器件規(guī)模的模型吞吐量。此外,我們還評估了序列長度、梯度累積(GAS)和稀疏性對模型性能的影響。
(3) GenSLM(科學用例):除了上面描述的基準之外,我們還對評估這些模型在現實世界用例中的表現。GenSLM是一個基因組的基礎模型,可以推廣到其他模型。該模型的目標是識別和分類不同的病毒變異毒株,然后可以將其擴展到基因或蛋白質合成。它采用基于GPT的具有不同參數的大語言模型(25M-25B)和1.2B的原始核苷酸數據集,旨在獲得更大的序列長度,以幫助更好地捕捉上下文,并可推廣用于學習進化。圖2顯示了GenSLM模型的概述,該模型以SARS-CoV-2基因組(在密碼子水平編碼的核苷酸序列,其中每三個核苷酸代表一個密碼子)為輸入,將其輸入到一系列轉換層。中間層學習單個密碼子的語義嵌入,可以將其映射到29個單獨的病毒編碼的蛋白質序列。在本研究中,我們重點評估了Nvidia A100、SambaNova SN30上具有13B參數的GenSLM GPT模型和Cerebras CS-2上的25B GPT3-XL模型。
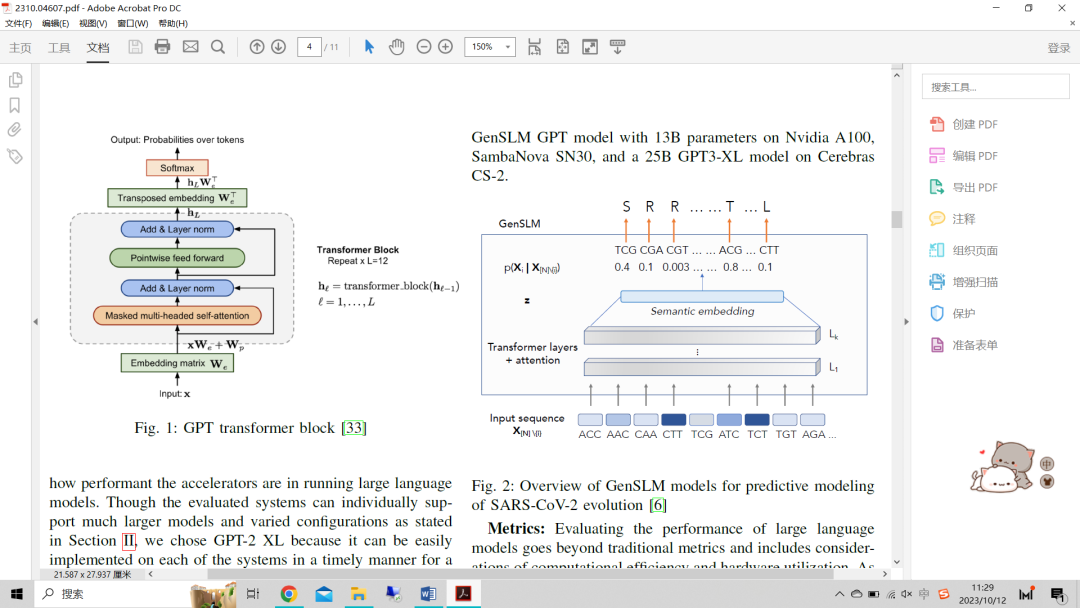
圖2:用于嚴重急性呼吸系統(tǒng)綜合征冠狀病毒2型進化預測建模的GenSLM模型概述
度量:評估大語言模型的性能超出了傳統(tǒng)的度量,包括計算效率和硬件利用率的考慮。隨著這些模型的規(guī)模和復雜性的增長,評估它們有效處理和生成文本的能力至關重要,尤其是考慮到訓練和推理所需的計算資源。吞吐量是衡量大型語言模型處理給定數量輸入數據的速率的關鍵性能指標。它通常以每秒處理的令牌或語句來量化。更高的吞吐量值表示更好的效率和有效處理大規(guī)模語言處理任務的能力。在這項工作中,我們以每秒令牌數的形式展示了評估系統(tǒng)的吞吐量。
硬件利用率是評估大語言模型的另一個重要指標,因為它評估了在模型訓練和推理過程中計算資源的有效利用率。它涉及多種設計選擇,如模型并行性、內存管理和高效的數據處理技術。分析模型以提取評估系統(tǒng)的硬件利用率的工作正在進行中,并將包含在報告的最終版本中。
IV. AI加速器的實現
由于不同的軟件堆棧和規(guī)模,評估模型在每個系統(tǒng)上的實現方式各不相同。在這里,我們描述了三種情況下每個系統(tǒng)的實現細節(jié):Transformer微基準測試、GPT-2XL預訓練和GenSLM科學應用。
A. Transformer微基準
Transformer微基準的評估涉及一個細致的實施過程,旨在評估該內核在不同AI加速器上的計算效率和性能特征。Transformer微基準是為了模擬Transformer模型中的內核操作而設計的,廣泛用于各種自然語言處理任務。Transformer微基準使用標準化GPT-2XL模型中的一層,輸入序列為1024,確保不同平臺之間的結果一致且可比較。實現是使用相同的深度學習框架PyTorch進行的,PyTorch針對每個平臺的獨特功能進行定制。工作負載用于利用并行性和特定于硬件的優(yōu)化,并實現最佳吞吐量和計算速度。我們會仔細注意批量大小等因素,以避免瓶頸并充分利用可用的硬件資源。
對于不同的配置,我們使用8、16、32和64的批量大小。收集性能指標,如TFLOPS,以量化每個硬件平臺在處理Transformer模型所需的苛刻計算方面的能力。該評估為處理基于Transformer的工作負載時不同硬件的優(yōu)勢和劣勢提供了有價值的見解。
B. GPT-2 XLA預訓練
作為GPT-2 XL研究的一部分,我們在OWT數據集上預訓練模型,其中對給定序列長度的原始數據進行預處理和標記。下面描述每個系統(tǒng)的標記化和模型實現的細節(jié)。
Nvidia A100:我們在不同的節(jié)點計數上運行了具有不同微塊大小、序列長度和張量平行度的模型,最多可達64個A100 GPU。這些都是用Megatron-DeepSpeed實現的,使用的是fp16精度的ZeRO Stage 1。在這些實驗中,啟用了flash-attn,這可以緩解內存壓力,通常可以提高吞吐量。實驗使用了2k的序列長度。使用Nvidia的NeMo生成人工智能框架進行的實驗是未來計劃工作的一部分。
Cerebras CS-2:在Cerebra CS-2系統(tǒng)上,我們在單個CS-2引擎上運行在PyTorch框架中實現的GPT-2 XL模型,序列長度為1024和2048,批量大小為112。該實現使用了一個基于字節(jié)對編碼(BPE)的自定義GPT-2標記器,vocab大小為50257。使用1(默認值)和2的混合精度和精度選擇級別來訓練模型。它使用了一個AdamW優(yōu)化器,其權重衰減率為0.011。該模型使用密集和稀疏配置進行訓練。在稀疏性方法中,基于所提供的程度來稀疏密集層的所有權重。我們運行了具有各種稀疏性值的GPT-3 6.7B和GPT-3 30B模型。這里,稀疏度值為0.3意味著修剪了30%的權重。第V節(jié)將討論稀疏性對模型吞吐量和損失的影響。
SambaNova SN30:我們評估了SambaNovas下一代SN30上OWT數據集的預訓練性能,它的每個節(jié)點有8個RDU,每個RDU有8個Tile。我們使用了適用于4個Tile或半個RDU的GPT-1.5B模型的SN參考實現。該實現基于PyTorch的SambaFlow框架,使用混合精度(16位乘法器和32位累加器)。它使用基于BPE的GPT-2標記器,vocab大小為50260。我們使用數據并行性來跨多個Tile和節(jié)點進行擴展。我們最多可擴展8個節(jié)點(對應于128個數據并行運行實例),每個實例的微批大小為16。
Graphcore Bow Pod64:在Bow Pod 64上,我們利用64個IPU來訓練評估的模型。在PyTorch框架中實現的GPT-2 XL 1.5B模型可以跨4個IPU進行模型劃分。作為數據預處理的一部分,該實現使用Nvidia的Megatron庫來生成具有BPE標記器和50272的vocb大小的訓練樣本。Poplar SDK使用多指令多數據(MIMD)方式的映射來利用IPU并行進行計算和通信。我們在FP16中使用了1的局部批量大小,并結合了128和1024的大梯度累積步長值。這樣大的值有助于最小化通信開銷,因為它模擬了更大的全局批量大小。特別是對于較小的GAS值,我們使用了1、2、4和16的復制因子來實現更好的擴展。
Habana Gaudi2:我們在PyTorch中運行了GPT-2 XL模型,每個HPU設備的序列長度為1024,本地批量大小為32。在Habana Gaudi2上對GPT-2 XL模型進行的訓練代表了軟件和硬件功能的強大組合。訓練中使用的數據格式為BF16。訓練樣本是使用BPE標記器生成的。
AMD MI250:在AMD MI250系統(tǒng)上,我們評估了GPT-2的性能,其中在多達8個GPU的OWT數據集上訓練的絕對位置中,使用因果語言建模(CLM)目標進行嵌入。我們使用了基于字節(jié)對編碼的GPT-2標記器,并使用了Hugging Face中的PyTorch 2.0參考設計來實現這一點。針對1024的序列長度、每個GPU 16和32的批處理大小以及1和4的GAS值來評估性能。
C. GenSLM
我們在Nvidia A100、SambaNova SN30和Cerebras CS-2上實現了GenSLM科學應用程序。在三個系統(tǒng)上,均使用PyTorch框架實現該模型。它使用基因組序列數據集,并使用密碼子級標記器將其標記化,該標記器將基因組拆分為3個核酸塊。由于GenSLM應用程序包含多種模型,它們的模型參數數量從25M到25B不等,因此我們在本實驗中使用了兩種不同的模型參數大小。
GenSLM的SN30實現基于GPT-2 13B參數模型,該模型使用1024的上下文長度、44層、64個注意力頭、4992的嵌入大小和71的詞匯表大小。該批量大小為32的GPT-2 13B參數模型可以映射在4個Tile內或相當于半個RDU內。Cerebras上使用的模型是GPT-3 XL,這是一個1.5B參數的模型,有24個隱藏層和16個注意力頭。該模型使用70的詞匯大小和2048的嵌入大小。該模型針對序列長度為10240且局部大小為27的基因組序列進行訓練。其他模型參數類似于上面列出的GPT-2XL實現細節(jié)。GPT3-XL模型在兩個CS-2上進行了縮放,以提供54的全局批量大小。在Nvidia A100上,我們使用了一個相同的GPT-2 13B模型,該模型由40層隱藏維度和40個注意力頭組成。
V. 結論
在本節(jié)中,我們介紹了三個評估案例的實驗結果。我們從第V-A節(jié)中以三個精度評估的Transformer微基準開始。接下來,我們介紹了GPT-2 XL 1.5B參數模型的結果,重點是第V-B1節(jié)中的可擴展性、第V-B3節(jié)中的GAS研究、第V-B2節(jié)中的序列長度分析和第V-B4節(jié)中的稀疏性研究。最后,我們詳細介紹了GenSLM模型在三個系統(tǒng)上的實驗結果,這些系統(tǒng)具有三種尺寸的模型:SectionV-C中的1.5B、13B和25B個參數。
A.Transformer微基準
在單個NVIDIA A100 GPU、SambaNova SN30 RDU、Graphcore Bow IPU、Habana Gaudi2和AMD MI250上的Transformer微基準評估結果如圖3和圖4所示,顯示了FP32、FP16和BF16三種精度的前向和后向通道的吞吐量。與A100的2039 GB/s相比,Mi250具有更高的內存帶寬(3276.8 GB/s),更高的帶寬能夠用于提高單精度的性能。但是MI250的總效率低于A100。
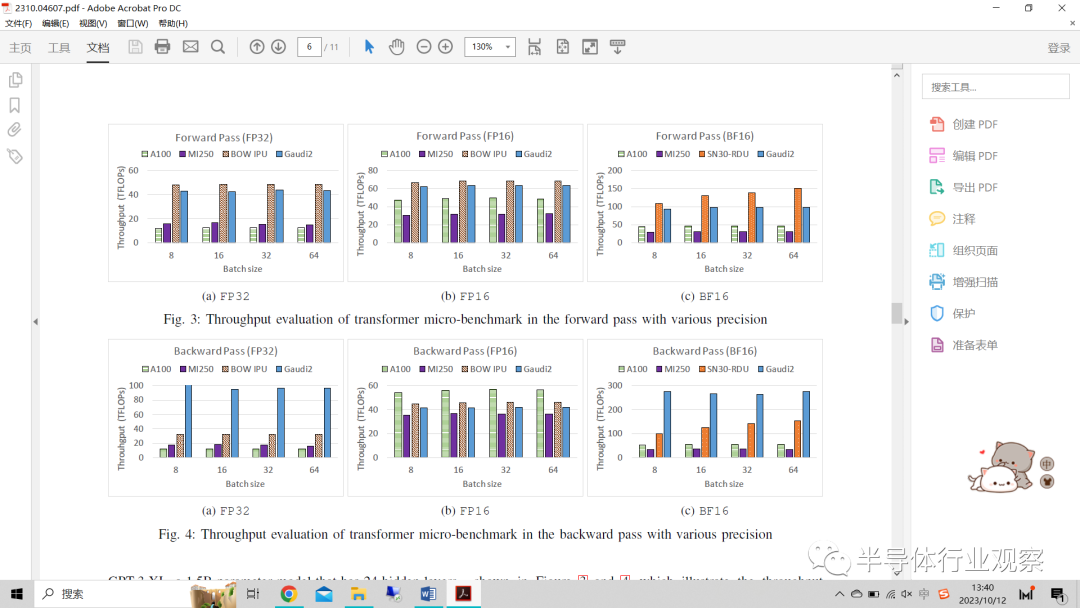
圖3:Transformer微基準在不同精度的正向通道中的吞吐量評估
圖4:Transformer微基準在不同精度的后向通道中的吞吐量評估
據觀察,NVIDIA A100 GPU得益于其先進的張量內核和并行處理能力,展示了基線吞吐量。FP16和BF16精度的吞吐量比FP32高約4倍。A100的單精度理論性能是半精度理論性能的兩倍。由于使用半精度減少了內存訪問,可能會帶來額外的性能改進。SambaNova SN30具有可重新配置的數據流架構,在BF16精度方面表現出令人印象深刻的性能,展示了其使用半精度格式處理復雜Transformer工作負載的潛力。由于RDU上的管道化/融合執(zhí)行,與任何管道一樣,自然會有一個預熱和冷卻階段。一批中的更多樣本會具有更長的穩(wěn)態(tài)行為和更高的有效吞吐量。由IPU提供動力的Graphcore Bow IPU在FP32和FP16精度方面表現出色,突出了其適用于NLP任務。同時,Habana Gaudi2在所有三種格式中都表現出強大的性能,強調了其在高效執(zhí)行各種Transformer計算方面的能力。在后向通道中,我們認為這是由于硬件利用率更高,從而帶來更高的吞吐量。AMD MI250利用其專用張量處理內核陣列,在后向傳輸中表現出顯著的加速和一致的吞吐量。
B.GPT-2 XL
對于該模型,我們將設備數量的不同配置的預訓練吞吐量作為縮放研究。稍后我們將討論序列長度和梯度累積步驟對模型吞吐量的敏感性。
1) 縮放研究:這部分,我們展示了在不同系統(tǒng)上縮放GPT-2XL模型的發(fā)現。由于資源的可用性,縮放研究中使用的設備數量因系統(tǒng)而異。我們使用了64個Nvidia A100 GPU、2個CS-2引擎、64個SambaNova SN30 RDU、64個Graphcore Bow IPU、4個AMD MI250 GPU和64個Habana Gaudi2 HPU。圖5顯示了設備數量的增加,對模型吞吐量(以log為單位)的影響。需要注意的是,每個系統(tǒng)上使用的精度是不同的,并且每個系統(tǒng)上的批量大小都針對該配置進行了調整。
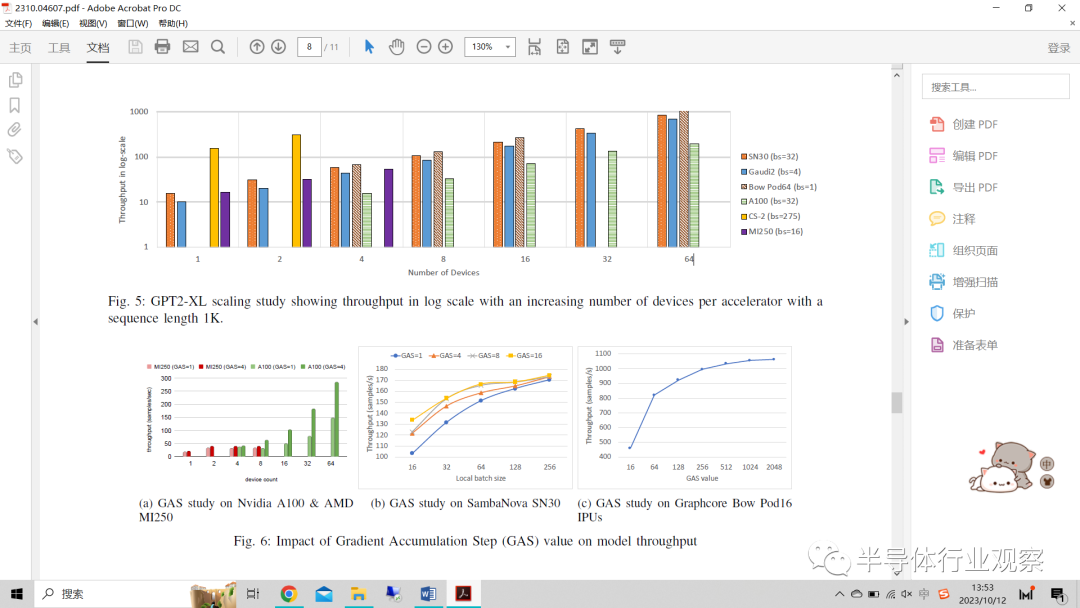
圖5:GPT2-XL縮放研究顯示,序列長度為1K的加速器數量增加對吞吐量(以log為單位)的影響。
表II列出了每個評估系統(tǒng)上設備數量對加速以及縮放效率的影響。這項研究的一個引人注目的觀察結果表明,在16個SN30 RDU、2個CS-2和16個IPU上訓練的模型優(yōu)于在64個A100上的運行。此外,Gaudi 2具有104%的最高縮放效率,這是由于Synapse軟件堆棧的優(yōu)化,這些優(yōu)化有助于最大限度地減少跨多個HPU劃分模型和數據的開銷。緊隨其后的是Bow Pod64,其縮放效率達到100%。超線性縮放是通過使用復制張量分片來實現的——隨著縮放的增加,DRAM I/O上的重量加載壓力降低,IPU鏈接被用來交換重量張量的分片。此外,Bow IPU有900 MB的SRAM,目前它不使用DRAM來運行,因此,由于SRAM大小的限制,我們無法將其安裝到單個IPU中。我們使用4個IPU,并行運行管道,模型層分布在IPU上。Cerebras CS-2的縮放效率為95.7%,這證明了具有專用節(jié)點的權重流技術的效率,MemoryX用于保存所有模型權重,SwarmX用于將這些權重流式傳輸到計算引擎。值得注意的是,SN30和MI250的縮放效率約為80%,高于75.8%的A100。
表II:GPT-2 XL模型的縮放行為研究
結果表明,隨著模型在越來越多的設備上運行,所有評估的加速器都表現出了更高的吞吐量。盡管計算成本很高,但使用更多的設備可以更好地訓練具有大量參數的模型。隨著模型大小按萬億參數的順序擴大,在不斷增加的設備數量上運行它們可能是不可行的,從而強調了實施新方法的必要性,以在給定計算預算的情況下優(yōu)化訓練模型的時間。
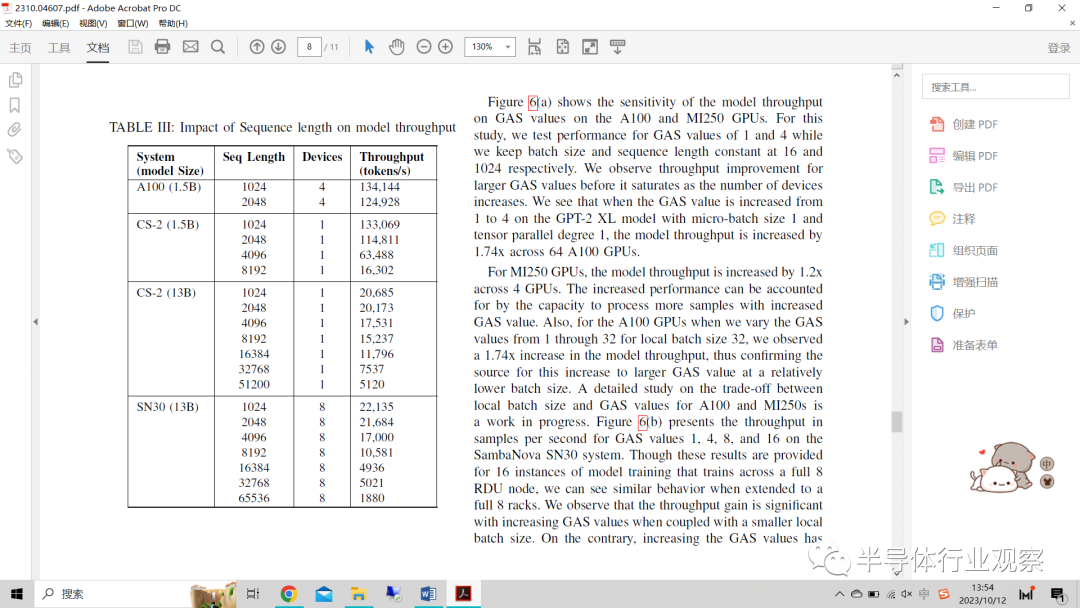
2) 序列長度的影響:近期的研究強調了在大語言模型任務中縮放序列長度(縮放到1B以上的令牌)的必要性。在GenSLM科學應用中,大的上下文長度在合成基因組數據方面極其重要。因此,我們研究了GPT-2模型的序列長度縮放的影響,并在Nvidia A100、SambaNova SN30和Cerebras CS-2上給出了結果,并由于支持有限或正在進行的工作而排除了其他結果。在本研究中,我們在A100和Cerebras系統(tǒng)上使用了GPT-2XL 1.5B參數模型,Cerebras CS-2和SambaNova SN30都使用了GPT2-13B參數模型。正如我們從表III中看到的,Nvidia A100至少需要4個設備來適應較小序列長度的數據集。另一方面,SambaNova SN30和Cerebras CS-2由于其大的本地內存和計算架構,可以在單個計算設備上適應具有較長序列長度的模型。SambaNova SN30可以適應13B參數模型,序列長度從1K到64K不等,所有這些都在一個RDU上。我們在數據并行模式下在一個節(jié)點上運行該模型的8個實例,并給出了結果。我們可以預見,隨著序列長度的增加,吞吐量會下降。此外,從32k的序列長度來看,該實現使用分段softmax實現。對于GPT-2XL模型的CS-2系統(tǒng),當序列長度從1K增加到8K時,我們可以看到序列長度影響吞吐量的趨勢。
表III:序列長度對模型吞吐量的影響
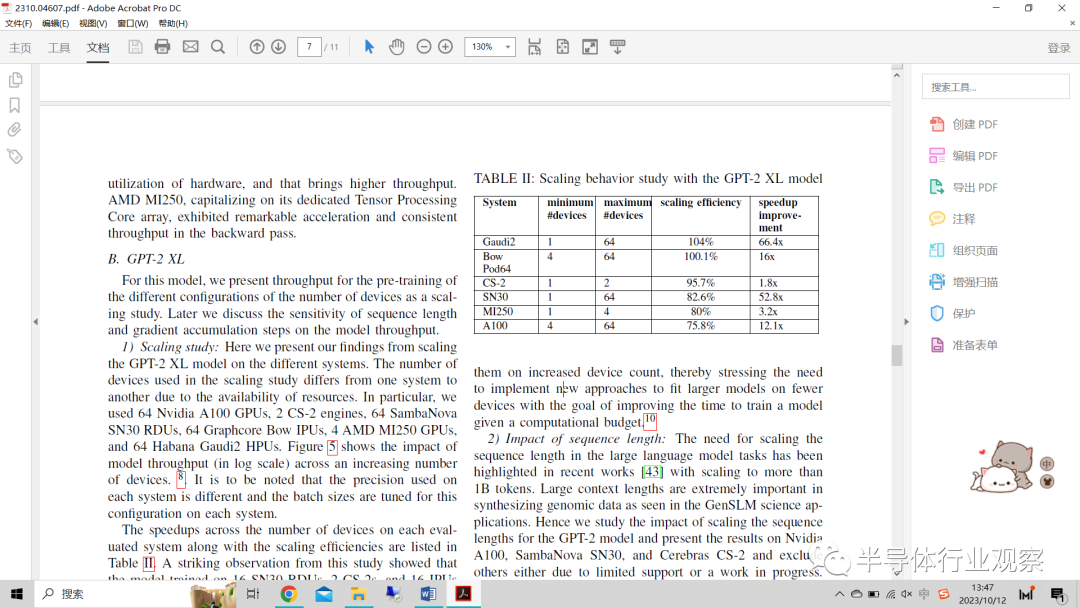
3) 梯度積累積的影響:大語言模型,尤其是那些具有數十億參數的模型,在訓練過程中會消耗大量內存。梯度累積允許在更新模型的權重之前在多個小批量上累積梯度。與處理每個單獨的小批量后更新模型相比,這減少了內存需求。當使用內存容量有限的硬件時,這一點尤為重要。在本研究中,我們研究了增加GAS值對模型性能的影響。
圖6:GAS值對模型吞吐量的影響
圖6(a)顯示了A100和MI250 GPU上模型吞吐量對GAS值的敏感性。在這項研究中,我們測試了GAS值為1和4的性能,同時我們將批量大小和序列長度分別保持為16和1024。我們觀察到,隨著設備數量的增加,在GAS值飽和之前,較大的GAS值的吞吐量有所提高。我們看到,當微批量大小為1、張量平行度為1的GPT-2XL模型上的GAS值從1增加到4時,64個A100 GPU的模型吞吐量增加了1.74倍。
對于MI250 GPU,4個GPU的模型吞吐量增加了1.2倍。性能的提高可以通過處理GAS值增加的更多樣本的能力來解釋。此外,對于A100 GPU,當我們將本地批量大小為32的GAS值從1增加到32時,我們觀察到模型吞吐量增加了1.74倍,從而證實了在相對較低的批量大小下,GAS值更容易增大。關于A100和MI250的本地批量大小和GAS值之間的權衡的詳細研究正在進行中。圖6(b)顯示了SambaNova SN30系統(tǒng)上GAS值為1、4、8和16的每秒采樣吞吐量。我們觀察到,當與較小的本地批量相結合時,隨著GAS值的增加,吞吐量增益是顯著的。相反,增加GAS值對吞吐量的影響較小或沒有影響,吞吐量在較大的本地批量時飽和。這一觀察結果可歸因于這樣一個事實,即在較大的批量下,與通過減少優(yōu)化步驟數量節(jié)省的時間相比,在反向通過計算的情況下加載梯度的額外任務非常耗時。
圖6(c)顯示了Graphcore POD16上模型吞吐量對GAS值的敏感性。在本研究中,我們考慮了復制因子為4的情況,即表明模型的單個實例(在4個IPU上分片)被復制4次,以跨越整個POD16系統(tǒng)。結果可以擴展到POD64的整個構架。正如我們所看到的,Graphcore可以支持從16到2048的非常大的GAS值。這是通過處理多個批次并將梯度聚合到累加器張量中而不增加內存使用量來實現的。SambaNova SN30在技術上也可以支持非常大的GAS值,盡管它對模型吞吐量的影響尚待研究。Cerebras梯度累積步驟(GAS)由Cerebras軟件堆棧自動確定,以在給定所需全局批量大小和CS-2s數量的情況下驅動最佳吞吐量。鑒于用戶調整該參數的功能有限,我們在本研究中排除了CS-2。
4) 權重稀疏性對模型吞吐量的敏感性:稀疏性對于訓練大語言模型很重要,這主要是由于幾個因素,例如通過只存儲非零參數提高了內存效率,由于減少了每個優(yōu)化步驟中更新的參數數量而提高了訓練速度,以及有效的可擴展性。它還有助于更快的推理,因為計算僅限于非零權重。在此,我們對模型稀疏性對Cerebras CS-2吞吐量的敏感性進行了研究。稀疏度反映了為加速訓練而修剪的權重的百分比。從圖7中可以觀察到,模型吞吐量從密集模型(s=0)增加到高度稀疏模型(s=0.9)的變化。對于GPT-2XL模型,與完全密集模型(s=0)相比,我們觀察到在具有極端稀疏性(s=0.90)的情況下吞吐量加速了1.8倍到2倍。此外,稀疏度對較大模型的吞吐量提高有更高的影響。對于GPT-3 6.7B,在單個CS-2上的密集模型上,0.9的稀疏度產生2.1倍,而對于GPT--3 30B,在單個CS-2上的密集模型上,0.9的稀疏度獲得3.79倍。進一步擴展,與單個CS-2相比,8和16 各CS-2上的6.7B型號的加速系數分別提高了7.75倍和15.49倍。該實驗表明,模型稀疏性可以顯著提高吞吐量,并有可能幫助在相對較少的設備上運行更大的模型。
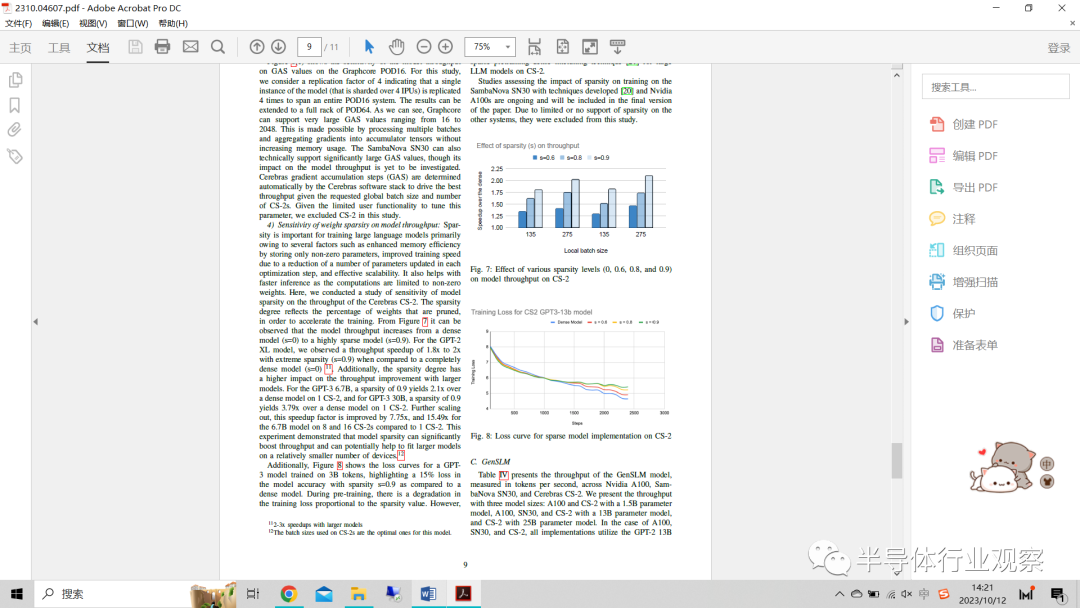
圖7:不同稀疏度水平(0、0.6、0.8和0.9)對CS-2上模型吞吐量的影響
此外,圖8顯示了在3B令牌上訓練的GPT-3模型的損失曲線,強調了與密集模型相比,稀疏性s=0.9的模型精度損失了15%。在預訓練期間,訓練損失與稀疏性值成正比。然而,模型的密集微調可以恢復這樣的差距,正如Cerebras過去在稀疏預訓練和密集微調框架上的工作所證明的那樣。1.3B GPT-3XL模型以75%的稀疏性進行預訓練,在減少2.5倍預訓練FLOP的同時,下游任務精度沒有顯著損失。我們目前正在探索用于CS-2上的大型LLM模型的稀疏預訓練密集微調技術。
利用開發(fā)的技術和Nvidia A100評估稀疏性對SambaNova SN30訓練的影響的研究正在進行中,并將包含在論文的最終版本中。由于稀疏性在其他系統(tǒng)上的支持有限或沒有,他們被排除在本研究之外。
C.GenSLM
表IV顯示了GenSLM模型在Nvidia A100、SambaNova SN30和Cerebras CS-2之間的吞吐量,以每秒令牌數為單位進行測量。我們給出了三種模型大小的吞吐量:A100和CS-2具有1.5B參數模型,A100、SN30和CS-2帶有13B參數模型以及CS-2帶有25B參數模型。在A100、SN30和CS-2的情況下,所有實現都使用GPT-2 13B參數模型,并且用1024的序列長度進行訓練。A100和SN30都使用32的微批量大小,但由于SN30可以在4個Tile上適應32微批量大小的13B模型,因此它可以在8個設備上并行容納該模型的16個實例。對于表III中使用的相同型號,SN30和A100使用不同的批大小。
表IV:GenSLM模型性能評估
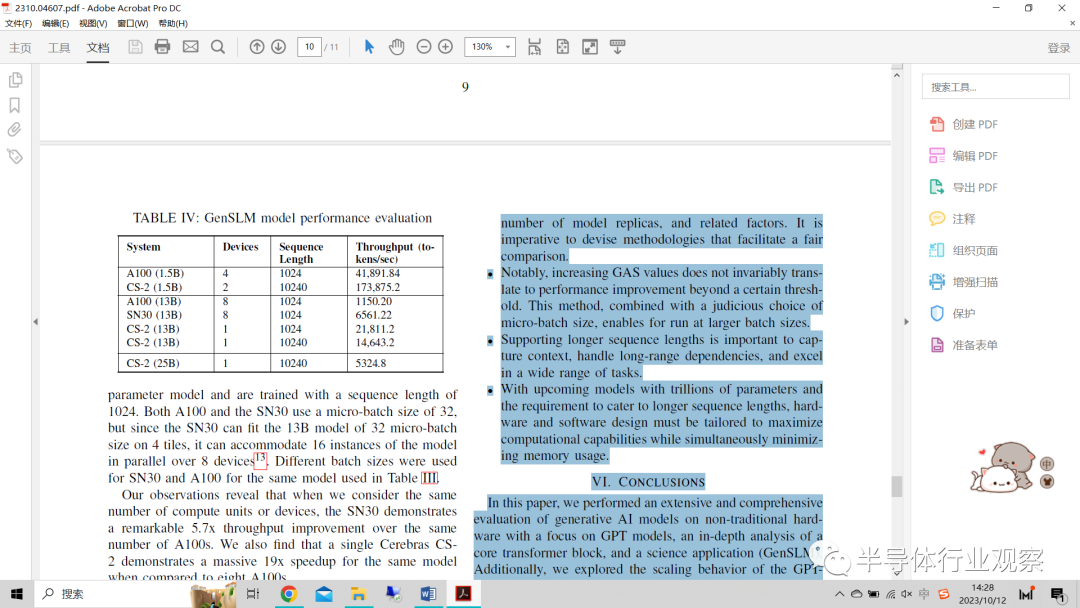
我們的觀察結果表明,當我們考慮相同數量的計算單元或設備時,SN30的吞吐量比相同數量的A100顯著提高了5.7倍。我們還發(fā)現,與8個A100相比,同一型號的一個Cerebras CS-2表現出了19倍的巨大加速。
當我們進一步比較在Nvidia A100和Cerebras CS-2上訓練的1.5B參數GenSLM模型的性能時,出現了一個有趣的趨勢。CS-2能夠處理比A100 GPU上運行的序列長度長十倍的序列長度,同時比A100實現了顯著的2倍加速改進。
這一嚴格的評估強調了這些加速器在解決大規(guī)模現實世界科學應用方面的重大貢獻。它們在加速大規(guī)模科學應用領域的準確性方面發(fā)揮著關鍵作用。
D. 觀察結果
這項對最關鍵的人工智能工作負載之一的全面基準評估得出了幾個值得注意的觀察結果。下面,我們將介紹一些有趣且有價值的見解。
?在單個設備中容納相當大的模型的能力取決于可用的計算資源和內存容量。即使使用了強大的計算引擎,采用旨在最大限度地減少內存消耗的創(chuàng)新技術,特別是權重和激活等參數,也是至關重要的。
促進開源模型的執(zhí)行和簡化Hugging Face模型的擴展對于利用這些人工智能加速器進行大量新興的人工智能科學應用非常重要。
實現人工智能加速器之間的公平比較是一個顯著的挑戰(zhàn)。差異源于局部/微批量大小、GAS值、模型副本數量和相關因素的變化。必須制定有利于公平比較的方法。
值得注意的是,GAS值的增加并不總是轉化為超過某個閾值的性能改進。這種方法結合了對微批量大小的明智選擇,可以在更大的批量大小下運行。
支持較長的序列長度對于捕獲上下文、處理長期依賴關系以及在各種任務中表現出色非常重要。
隨著即將推出的具有數萬億參數的模型以及滿足更長序列長度的要求,硬件和軟件設計必須進行定制,以最大限度地提高計算能力,同時最大限度地減少內存使用。
VI.結論
在本文中,我們對非傳統(tǒng)硬件上的生成人工智能模型進行了廣泛而全面的評估,重點是GPT模型、Transformer block的深入分析和科學應用(GenSLM)。此外,我們探索了GPT-2模型的縮放行為,以深入了解其性能特征。我們的一個重要觀察結果是硬件固有的內存限制,這限制了可以安裝在單個設備上的模型大小的可行性。它還需要分布式實現,例如數據并行,并增加設備數量。隨著設備數量的增加,也觀察到接近線性的縮放。此外,采用優(yōu)化,如權重稀疏性,有助于有效減少分布式實現中的通信開銷。
我們計劃繼續(xù)進行這項評估,重點關注更長的序列長度,并為新興的科學應用生成具有代表性的人工智能基準模型。我們還希望將這項全面的基準研究擴展到更大的模型,如175B參數模型,以及具有不同架構的生成模型,如Llama。據觀察,為了促進更大模型的有效訓練,例如用于科學應用的人工智能中的萬億參數,利用非傳統(tǒng)人工智能硬件將是至關重要的。優(yōu)化除模型吞吐量之外的其他指標,如訓練中的功耗和I/O,特別是在增加計算和利用更大數據集的情況下,也是至關重要的。
本文作者
Murali Emani、Sam Foreman、Varuni Sastry、Zhen Xie、Siddhisanket Raskar、William Arnold、Rajeev Thakur、Venkatram Vishwanath、Michael E. Papka
編輯:黃飛
?











 工商網監(jiān)
工商網監(jiān)
評論