 電子發燒友App
電子發燒友App


作者:曹健,陳怡梅,李海生,蔡強
復雜道路場景下的小目標檢測能夠提高車輛對于周邊環境的感知能力,是計算機視覺和智慧交通領域的重要研究方向。
隨著深度學習技術的發展,將深度學習方法與道路小目標檢測相結合能夠有效提高檢測精度,使車輛快速對周邊環境做出反應。
本文從經典及最新的道路小目標檢測的研究成果出發,給出小目標的兩種定義方式,分析造成道路小目標檢測困難的原因,闡述數據增強、多尺度策略、生成超分辨率細節信息、加強上下文信息聯系、改進損失函數等5類基于深度學習的提高道路小目標檢測精度的優化方法,總結歸納各類方法的核心思想及目前國內外最新的研究進展。
另外介紹了常用于道路小目標檢測的大型和公共數據集,提供相應的用于評估小目標檢測性能的指標,對比分析各類方法在不同數據集上的性能檢測結果,指出道路小目標檢測研究目前仍存在的問題,并結合這些問題從多個角度對其未來研究方向進行展望。
00? 概述
道路目標檢測是智能交通監控[1]、自動駕駛[2]、車牌識別[3]、行人跟蹤[4]、車輛檢測[5]等領域的重要研究分支之一,旨在識別和檢測整個道路場景圖像中感興趣的目標,尤其是在復雜場景中的準確性和實時性是評測整個模型系統的重要指標,具有廣泛的應用價值。但是自然交通場景的復雜多變以及道路各類目標本身在尺寸與距離上的干擾,使得目標識別和檢測難度大大增加,其中小目標檢測就是研究者關注的一個難點問題。對于大中型的車輛、行人等目標,通用的Two-stage和One-stage目標檢測模型已經能夠達到不錯的檢測效果,然而小目標的尺寸較小,不具備相應的形狀和紋理特征,這些特性導致其檢測性能仍有所欠缺,不能滿足實際需求。
道路小目標的具體定義方式可參考小目標的定義方式,大致可分為兩種:一種是絕對尺寸的定義方式,在通用的目標檢測數據集MS COCO[6]中,尺寸小于32×32像素的目標被定義為小目標;另一種是相對尺寸的定義方式,根據國際光電儀器工程師協會(SPIE)的定義,小目標是指在大小為256×256像素的圖像中目標區域小于9×9像素。
目前,道路小目標檢測困難和效果相對較差的原因大致可以歸結為以下4種:
1)相較于中大型行人車輛目標,包含小目標實例的圖像較少,且道路場景復雜多變,小目標容易隱藏在背景中;
2)小目標在道路圖像中面積占比小、分辨率低,攜帶的信息少,位置缺乏多樣性,難以定位,因此,卷積神經網絡提取到的可利用的有效信息非常有限;
3)特征提取時,輸入圖像經過卷積神經網絡的多次下采樣后,小目標的細節信息丟失嚴重,影響小目標的檢測效果;
4)道路目標檢測領域缺乏大規模通用的小目標檢測數據集,目前該領域發布的公共數據集多為針對中大型的行人車輛進行檢測,難以滿足小目標的檢測需求。
針對上述問題,國內外許多研究者提出了相應的改進和優化方法來提高小目標的檢測精度。本文將主要從數據增強、多尺度策略、生成超分辨率(Super-Resolution,SR)細節信息、加強上下文信息聯系、改進損失函數等5類改進方向出發進行歸納梳理,對各類方法的特點和優缺點進行比較,在MS COCO公共數據集以及其他不同道路場景數據集上對各類方法的檢測性能進行評估和對比分析,并對道路小目標檢測的未來研究方向進行展望。
01? 針對小目標檢測的優化方法
1.1 數據增強
數據增強是一種擴展數據的技術,在缺乏數據或數據量有限的情況下,該技術可以利用有限的數據來創造盡可能多的價值并盡可能滿足研究者的需求。盡管現在有很多用于各種任務的公開數據集,但數據量在使用中遠遠不夠,而收集和制作這些數據的成本其實是非常高的且不便于采集,因此數據增強便成為了一種快速有效的改進方法。在大部分目標檢測的數據集中,小目標的實例數量占比少,在訓練和檢測中容易被忽略。通過數據增強來增加小目標的樣本數量,可有效改進小目標的檢測精準度。常用的數據增強方法可大致分為單樣本數據增強和多樣本數據增強兩類。
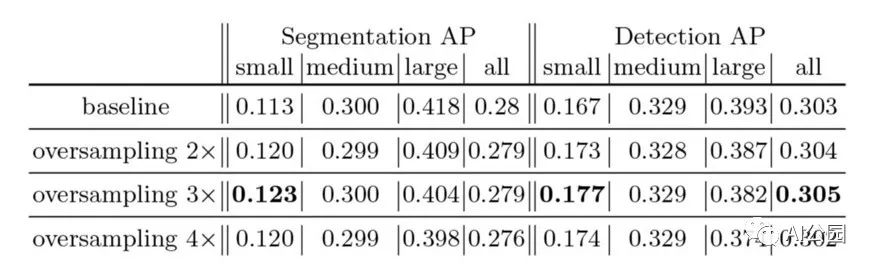
典型的單樣本數據增強方法主要是在一張預檢測的圖像上進行翻轉、裁剪、縮放、添加噪聲、變換顏色等操作,改變圖像原有的狀態,可有效增加數據集的樣本數量和提高網絡的泛化能力。文獻[7]使用過采樣和基于復制粘貼的增強方法進行改進,并在將對象粘貼到新位置前,對其應用兩種縮放圖像和旋轉圖像的隨機變換,然后將小目標粘貼到新的位置,并確保新粘貼的目標不與任何現有目標相重疊,且距離圖像邊界至少5個像素。文獻[8]對輸入的每一張圖像先采用縮放操作,在縮放操作后進行增強對比度、翻轉、改變亮度和以0.5的概率隨機角度旋轉等操作。文獻[9]在小目標數據集上,將每張圖片上的小目標物體在訓練時復制3次,使得網絡在訓練過程中可以更容易地提取目標的特征信息。文獻[10]通過幾何變換和顏色變換等進行數據增強,增加了數據集的數據量。文獻[11]提出自動數據增強策略,與手工制定的策略不同,該策略利用自動算法在多種增強候選者中進行搜索,且該策略也可以應用于其他數據集和框級任務。文獻[12]利用自動機器學習(Auto Machine Learning,Auto ML)原理設計自動搜索數據增強技術用于行人檢測,從而產生最佳的數據增強策略。
近些年,許多研究者也提出了多種通用的多樣本數據增強方法,包括MixUp[13]、CutOut[14]、CutMix[15]、Mosaic[16]等方法,這些方法通過將多張圖像以某種方式合成到一起形成新的樣本,達到擴充數據集容量的目的。MixUp方法將兩張圖像以一定的概率和比例拼湊到一起,比例分配決定了分類結果。CutOut是在圖像中隨機選擇某一部分區域進行裁剪。CutMix是將兩種方法相結合,先裁剪掉一張圖像的某一部分,再使用另一張圖像中的某一部分進行填充形成新的樣本。Mosaic數據增強方法是目前最常用的數據增強方法之一,該方法借鑒了CutMix增強方法,將采用的2張圖像擴充為4張圖像,先對4張圖像進行隨機裁剪、縮放、翻轉等操作,然后將4張圖像拼接形成一張新的圖像。這個操作在擴充了數據集的同時也增加了小樣本的數量,并且極大地豐富了檢測對象的背景。在YOLOv4[16]和YOLOv5[17]模型結構中,均使用了Mosaic數據增強方法,以此提高了模型學習能力和效率。文獻[18]也將Mosaic數據增強方法引入改進后的CenterNet[19]中,以此優化算法的訓練模式,豐富檢測背景,優化檢測性能。
1.2 多尺度策略
在使用卷積神經網絡進行特征提取時,不同的網絡深度對應不同層次的特征。低層特征的分辨率更高,像素更豐富,包含更多的細節信息和位置信息,對于目標的定位有極大幫助,但包含的語義信息較少;高層特征包含更豐富的語義信息,極大地促進了對象的分類,但分辨率較低,像素較少,對細節位置信息的感知能力較差。對于小目標行人、車輛以及指示牌而言,它們的尺寸小,分辨率低,在多次下采樣后,特征圖不斷縮小,致使小目標的細節信息嚴重丟失,而多數通用檢測器僅采用最后一層的特征圖來定位目標和預測置信度分數,其中包含豐富的分類信息但缺乏詳細信息,使得小目標物體容易出現誤檢和漏檢的情況。多尺度策略的提出有效緩解了這一問題,在計算量不大的情況下,增強了物體特征的表達能力,提高小目標檢測的性能。目前,典型的多尺度策略有圖像金字塔、SSD算法和特征金字塔網絡(Feature Pyramid Network,FPN)。
圖像金字塔是圖像多尺度表達的一種,通過對原始圖像進行下采樣,得到一系列以金字塔形狀排列的分辨率逐漸降低的子圖集合,構成圖像金字塔。圖像金字塔結構如圖 3所示。
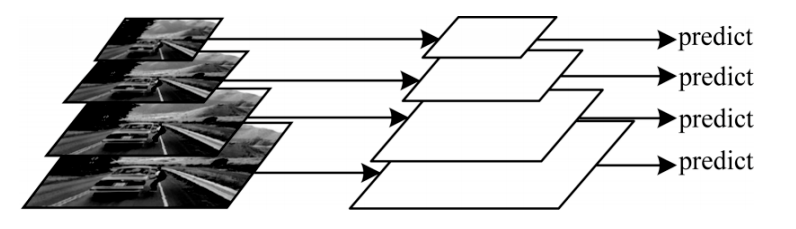
圖3 圖像金字塔結構
文獻[20]將背景差分目標檢測模型與高斯圖像金字塔相結合用于多目標的檢測,減少了誤檢測。文獻[21]指出當前在極端尺度變化下目標檢測訓練存在的缺點,在此基礎上提出一種新的訓練方案,即圖像金字塔尺度標準化(Scale Normalization for Image Pyramid,SNIP),在訓練和反向傳播更新參數時,只考慮在指定的尺度范圍內的目標,即只對大小合適的某些目標進行訓練,以此提高小目標的檢測效率。然而,圖像金字塔方法的一個明顯限制是它在處理一張圖像時需要較大的計算量,模型必須對來自所有尺度的圖像執行獨立的計算。
SSD算法使用步長為2的卷積來降低特征圖的大小,以不同尺度的特征圖作為檢測層來分別預測不同尺度目標的類別和位置坐標,較大的特征圖用來檢測小目標,較小的特征圖用來檢測大目標,實現多尺度目標的檢測。SSD算法的多尺度檢測如圖 4所示。
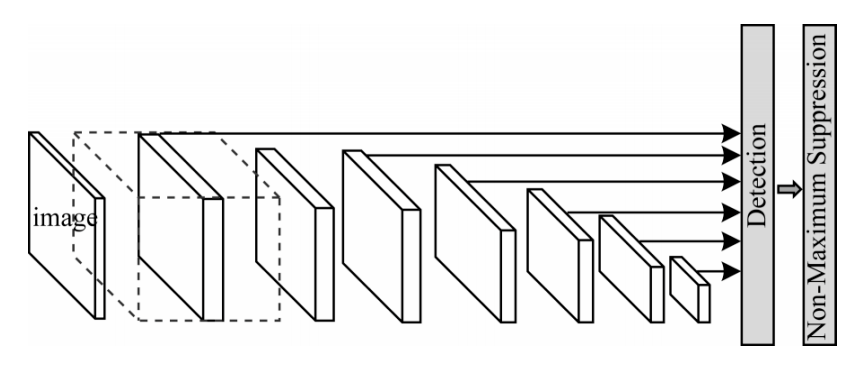
圖4 SSD算法的多尺度檢測
文獻[22]提出DSSD網絡,使用ResNet-101更換SSD的骨干網絡VGG16,提高了模型的特征提取能力,并使用反卷積層增加了上下文信息,提升了多尺度目標及小目標的檢測精度。文獻[23]提出一種基于稀疏連接和多尺度融合的Inception-SSD行人檢測方法,使用Inception模型代替骨干網絡的基礎部分,將全連接轉換為稀疏連接,有效緩解了參數空間大、容易過擬合、梯度分散、模型性能下降等問題。
由于SSD多層特征圖為非連續結構,所得到的信息不足,影響檢測性能,因此特征金字塔通過引入自上而下的連接[24]來解決SSD模型存在的問題。特征金字塔是目前最常使用的多尺度特征融合方法,針對圖像中不同物體具有不同的尺度,利用自下而上的路徑、自上而下的路徑和橫向連接三部分完成多尺度檢測。自下而上的路徑是卷積神經網絡的前向過程,選取每個階段最后一層的輸出構成特征金字塔;自上而下的路徑通過從更高的金字塔級別對空間上更抽象但語義更強的特征圖進行上采樣來生成更高分辨率的特征圖;橫向連接合并了自下而上路徑和自上而下路徑的相同空間大小的特征圖,將來自低層特征圖的詳細位置信息和來自高層特征圖的豐富語義信息相融合,實現了不同尺度的特征提取,顯著提升了小目標的檢測性能。特征金字塔結構如圖 5所示。
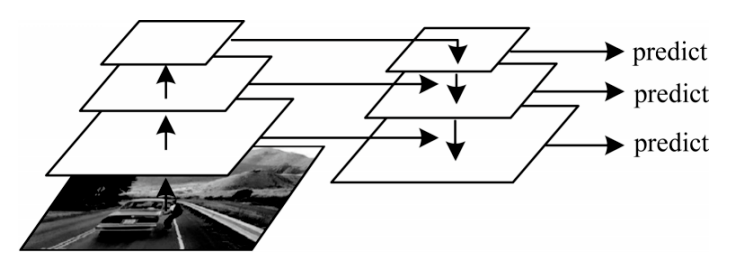
圖5 特征金字塔結構
文獻[25]將FPN網絡中的Add融合方式更改為Concat方式來融合經多次卷積后提取的特征。文獻[26]提出一種融合FPN和Faster R-CNN[27]的行人檢測算法,獲得了較好的檢測效果。文獻[28]提出基于FPN的路徑聚合網絡(PANet),在FPN后增加自下向上的路徑增強,能夠縮短信息路徑并利用低層中存在的準確定位信息來增強特征金字塔,得到語義信息和定位精度上的雙重提升,從而提高了對于多尺度目標的檢測能力。PANet結構如圖 6所示,其中,Pi和Ni表示不同層級的特征圖,Ni是由包括Pi等多個特征圖融合后的結果。
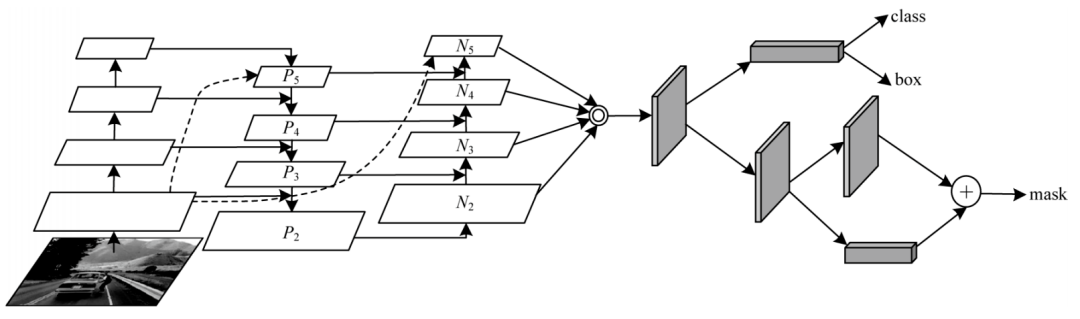
圖6 PANet結構
文獻[29]針對FPN網絡存在自頂向下路徑中信息稀釋導致較低層獲得的語義信息有限、高層特征缺乏空間信息的問題,將語義金字塔模塊和語義特征融合模塊加入檢測模型,提出語義特征金字塔網絡(SFPN),以解決信息不平衡問題并防止在特征融合過程中發生稀釋。文獻[30]提出新的圖像金字塔引導網絡(IPG-Net),創建了一條新的路徑來緩解空間信息和語義信息之間的不平衡和錯位問題,將IPG-Net信息不斷融入主干流,解決了深層空間信息不足和小物體特征丟失的問題。文獻[31]提出圖特征金字塔網絡(GraphFPN),該網絡的拓撲結構能夠動態適應輸入圖像的內在結構,并支持所有尺度特征的同時交互,繼承輸入圖像的超像素層次結構,使用上下文層和等級間交互層來分別促進相同尺度內和不同尺度間的特征交互,避免了FPN網絡中來自非相鄰尺度的特征只能間接交互的問題。
1.3 超分辨率細節信息生成
相較于低分辨率(Low-Resolution,LR)圖像,高分辨率(High-Resolution,HR)圖像的像素密度較高,能夠提供更多原始場景下精細的細節信息和可區分的特征,在檢測中能夠獲得更佳的檢測效果。因此,生成超分辨率圖像也是對小目標的檢測精度進行改進的一種有效方法,旨在從相應的低分辨率特征中恢復高分辨率特征,將生成的高分辨率圖像作為檢測模型的輸入,獲得更多小物體的細節信息。
目前,該類方法大部分主要通過生成對抗網絡(Generative Adversarial Network,GAN)[32]的方式將小目標的特征轉化為與中大型目標一樣或相近的特征表達來恢復或重建高分辨率圖像,其中生成器用于從低分辨率圖像中生成超分辨率圖像來欺騙判別器,判別器對真實圖像和生成器生成的仿真超分辨率圖像進行區分,預測目標的類別和位置,整體流程如圖 7所示。
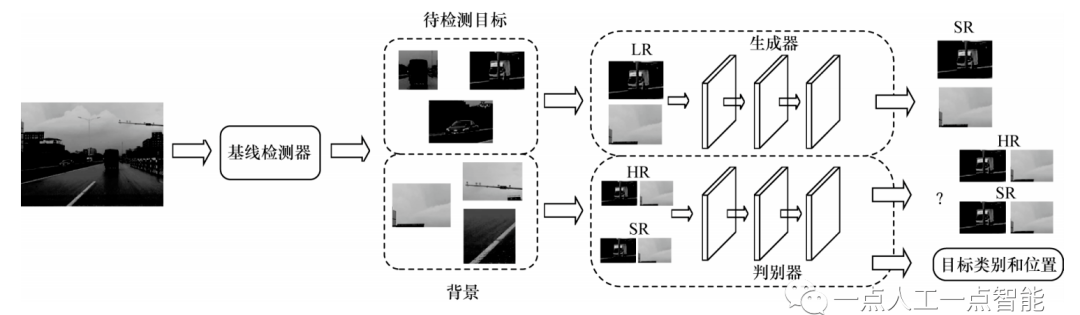
圖7 基于GAN的細節信息生成流程
?
?
文獻[33]將GAN引入小目標檢測構建一種Perceptual GAN,基于深度殘差特征的生成器模型將底層特征作為輸入,將小物體的原始較差特征轉換為具有高判別力的特征,從而在中間表示上生成超分辨率圖像,判別器通過對細粒度細節信息的生成進行指導以提高生成目標的質量,有利于小目標的檢測。文獻[34]提出一種可與多種檢測器相結合的SOD-MTGAN,在生成器中引入超分辨率網絡實現對小目標圖像的大范圍上采樣,生成超分辨率圖像,并在判別器中引入用于目標檢測的分類和回歸損失進行聯合識別與反向傳播,以進一步指導生成器網絡生成超分辨率圖像,使得小目標在檢測中更易定位和識別。文獻[35]提出一種新的特征級超分辨率圖像生成方法,通過空洞卷積對網絡輸入的低分辨率特征感受野和目標高分辨率特征感受野進行匹配,提高超分辨率圖像生成質量,并對超分辨率生成器進行直接監督,提高訓練穩定性,總體模型結構如圖 8所示,其中,I為原始輸入圖像,×0.5表示對圖像進行下采樣,F為來自原始圖像的低分辨率特征,T為SR目標提取器提取到的真實目標的超分辨率特征,S為生成的超分辨率特征。
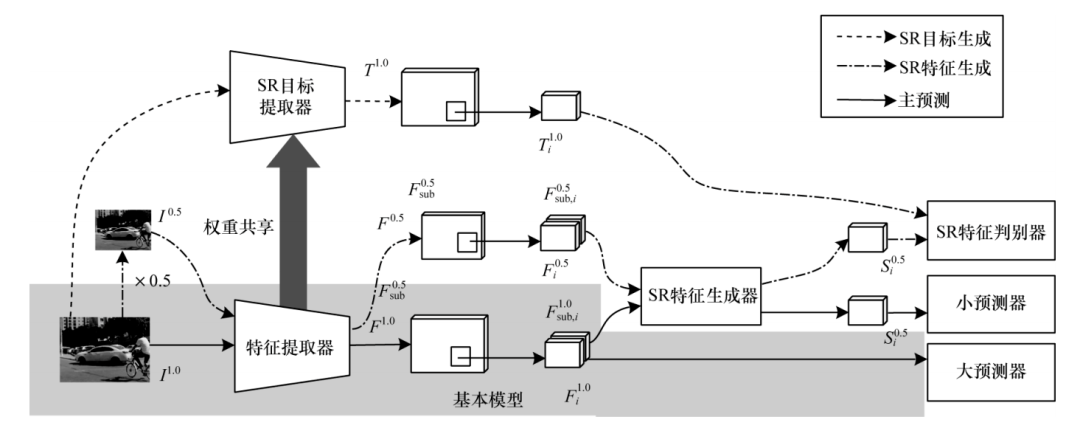
圖8 特征級超分辨率圖像生成模型結構
文獻[36]使用超分辨率子網絡從大規模行人中恢復小規模行人的詳細信息,將分類任務和超分辨率圖像生成任務集成在一個統一的JCS-Net框架中,使得重建圖像特征更適合小尺度行人的檢測。文獻[37]提出一種新的靜止小波擴張殘差超分辨率圖像生成網絡(SWDR-SR),以極大地增強圖像的邊緣信息并減少模糊現象,從而改善行人的檢測效果。
1.4 上下文信息聯系加強
在一張道路圖像中,小目標占比較小,在檢測中能夠提取到的信息和特征稀少且有限,但小目標周圍的區域總是包含很多其他對象的信息以及場景信息,這些信息在檢測中能夠提供幫助但卻容易被忽略,因此加強小目標附近的上下文信息聯系,將上下文信息加入小目標的檢測,能夠有助于增強特征表示,提高小目標的檢測精度。
文獻[38]引入一個簡單而強大的空間記憶網絡框架(SMN),對實例級上下文進行建模,該網絡本質上是將對象實例重新組合成一個偽圖像表示。文獻[39]對對象之間的關系進行建模,在檢測模型中添加對象關系模塊以增強檢測效果。文獻[40]構建一個網絡,利用行人實例之間的相關性,將行人目標的頭頂區域和較低區域作為空間上下文,利用行人與場景之間的相關性,引入GRU[41]模塊,將編碼的上下文作為輸入來指導每個候選目標的特征選擇和融合,具體的關系上下文結構如圖 9所示,其中,節點v表示選中的感興趣區域,r表示每對實例節點之間的關系,f表示感興趣區域的視覺特征,m表示其他節點到節點vi的關系消息,ht+1為GRU模型輸出的節點狀態。
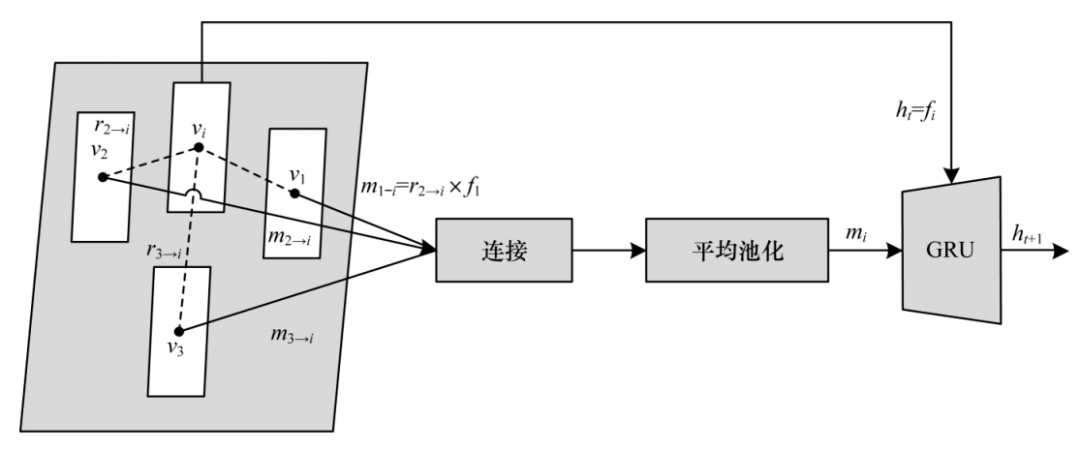
圖9 關系上下文結構
?
?
文獻[42]提出一種用于目標重新檢測的空間上下文分析方法(FS-SSD),通過考慮一定距離內多類對象的相互作用,計算不同對象實例之間的類間和類內距離作為空間上下文,以重新驗證某些對象實例的置信度,這種重檢測方法充分利用空間關系,有助于處理多類小目標檢測。文獻[43]使用來自更高層的更多抽象特征作為上下文,并從小物體的周圍像素中提取上下文信息,然后將上下文感知信息添加到SSD網絡,以便更好地進行檢測。文獻[44]提出高效的選擇性上下文網絡(ESCNet)來解決SSD網絡上下文探索不足的問題,其中增強上下文模塊(ECM)通過利用原始尺度、小尺度和大規模上下文信息來增強淺層特征,而三重注意力模塊(TAM)用來融合上下文信息并選擇性地細化特征。
1.5 損失函數改進
在目標檢測任務中,損失函數具有重要作用。損失函數往往用于檢測模型最后一部分,一般的目標檢測算法包含兩類損失函數:一類是分類損失函數;另一類是回歸損失函數,而YOLO系列檢測算法還包含置信度損失函數。針對不同的檢測器和檢測場景,選擇或設計不同的損失函數會產生不同的收斂效果,通過對損失函數進行改進,可以對小目標取得更高的檢測準確率。目前,常用的損失函數改進方法大致可分為兩種:一種是對模型本身的損失函數進行優化;另一種是更換模型的損失函數。
針對實驗中所選用的不同數據集,根據實際需求,對模型本身的損失函數進行優化和調整是提高小目標檢測精度的一種有效方法。文獻[45]考慮到尺寸小的待檢測目標的損失函數通常會被忽略,使得小目標檢測精度受到影響,通過調整大小尺度目標對損失值的影響權重,降低大目標誤差對小目標檢測效果的影響,使得小目標和大目標對損失函數的影響程度相同。文獻[46]考慮到道路行人、車輛等各類目標數據量的不同,增加損失函數中目標分類誤差的權重,并增強負樣本對損失貢獻的懲罰,有效降低了小目標的誤檢率。
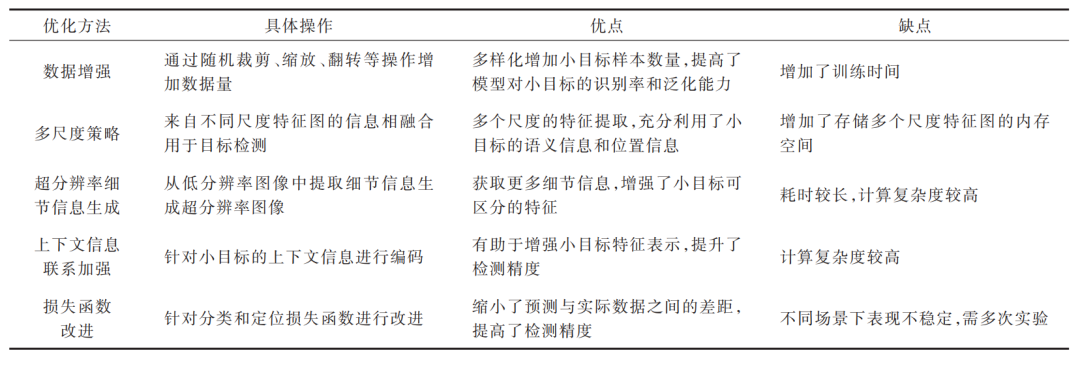
雖然對模型本身損失函數進行調整能適當提高小目標檢測精度,但由于小目標物體在道路圖像中占比低、數量少,訓練階段小目標對損失函數的貢獻較小,且會加劇樣本不均衡的問題。為了緩解這種情況,采用性能更優、收斂速度更快的損失函數替代模型原有的分類損失函數成為目前常用的改進方法。文獻[47]設計一種新的損失函數(CUA),通過進一步考慮訓練階段的類別不確定性來指導目標檢測,使得網絡專注于輸出小目標不明確等情況。文獻[48]針對現有錨框匹配不平衡的問題,設計尺度平衡損失函數取代FSSD[49]、RefineDet[50]等方法中使用的保持匹配平衡的對應函數,通過在原有的基礎上進行加權運算,減少匹配次數多的目標所占的比例,增大匹配次數少的小目標的權重,提高小目標的檢測精度和召回率。文獻[51]鑒于小目標物體屬于困難檢測樣本,在引入Focal Loss增大困難樣本的損失權重的同時結合反饋機制與空洞卷積,提高了道路小目標的檢測精度。文獻[52]針對目標預測框出現在真實框的內部時GIoU[53]退化為IoU[54]使得位置關系無法區分的問題,使用CIoU[55]代替GIoU作為回歸損失,使得目標框在回歸過程中更穩定,收斂精度更高。各類道路小目標檢測優化方法的優缺點對比如表 1所示。
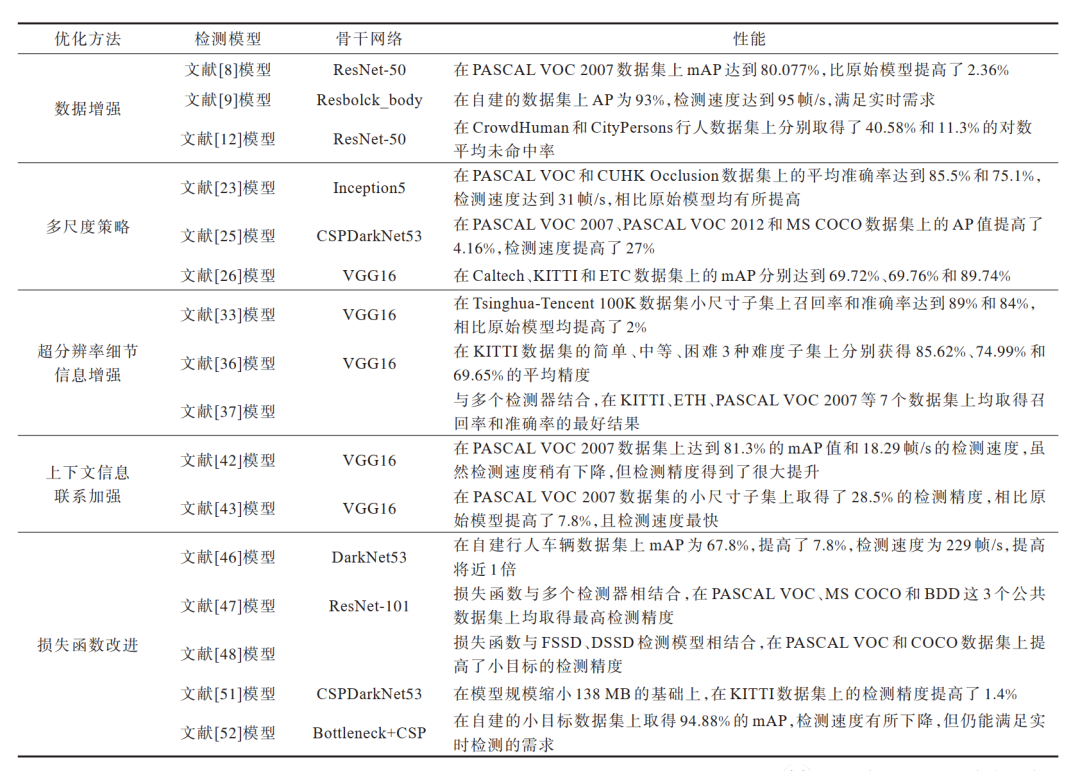
表 1 各類道路小目標檢測優化方法的優缺點對比
02? 數據集、評價指標及性能對比
2.1 數據集
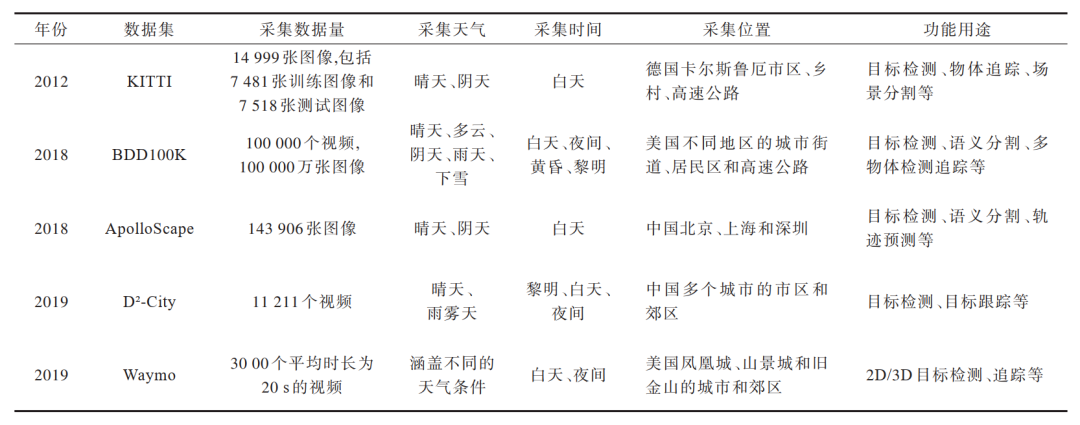
構建一個小目標檢測數據集需要花費大量時間,并且對于小目標的有限像素而言,正確放置邊界框的定位等都是有困難的。在目前的研究中,對于小目標的檢測并沒有通用的數據集,多數研究者選擇在一些大型公共的數據集上進行性能驗證。當前,道路目標檢測領域已經公開了許多公共的大型數據集,包括KITTI[56]、BDD100K[57]、ApolloScape[58]、D2-City[59]和Waymo[60],這些數據集通常包括數據量大、數據源豐富、應用場景覆蓋全面等特點,這對于道路目標檢測的方法研究和成果展示起著至關重要的推動作用和貢獻。除了前面介紹的幾種數據集,研究者還提出了其他的道路目標檢測數據集,例如A*3D[61]、nuScenes[62]等。
1)KITTI數據集
2012年,德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創辦了KITTI數據集,該數據集是目前自動駕駛場景下常用的計算機視覺算法評測數據集之一。KITTI數據集中的圖像包含在卡爾斯魯厄市區、鄉村、高速公路等場景中采集到的真實圖像數據,采集到的每張圖像中最多可達15輛車和30個行人以及各種不同程度的遮擋與截斷,包含的類別可分為汽車、貨車、卡車、有軌電車、行人、坐著的行人、騎自行車的人等7種與道路交通有關的對象類別。
2)BDD100K數據集
2018年,美國伯克利人工智能研究實驗室發布了BDD100K開源視覺駕駛場景數據集,該數據集收集了美國不同地區的城市街道、居民區和高速公路的100 000個視頻,每個視頻時長約40 s,在每個視頻的第10秒對關鍵幀進行采樣,得到100 000張1 280×720像素的圖像。該數據集涵蓋了晴天、多云、陰天、雨天、霧天、下雪等6種不同的天氣狀況以及黎明、黃昏、白天、夜間等不同時段,包含的目標類別可分為公共汽車、交通燈、交通標志、行人、自行車、卡車、摩托車、小汽車、火車、騎手等。
3)ApolloScape數據集
2018年,百度發布了一個大規模自動駕駛數據集——ApolloScape,其是一個像素級標注的場景解析數據集,圖像采集來自中國的北京、上海和深圳。該數據集包括143 906張像素級語義標注圖像,屬于業界環境復雜、標注精準、數據量大的公開3D自動駕駛數據集,標注精度上超過了同類型的KITTI和BDD100K數據集,致力于向研究者提供具有挑戰性的數據支持。
4)D2-City數據集
D2-City是一個大規模行車視頻數據集,采集自運行在中國多個城市的市區和郊區的滴滴運營車輛,涵蓋了中國不同城市的道路行車場景,提供了更多復雜和具有挑戰性的天氣、交通等狀況,包括道路擁堵、雨霧天氣、低光環境、圖像清晰度低等。該數據集提供了12類道路對象的注釋,包括汽車、面包車、公共汽車、卡車、人、自行車、摩托車、開放式三輪車、封閉式三輪車、叉車以及大小街區。
5)Waymo數據集
2019年,自動駕駛公司Waymo發布了大規模、高質量、多樣化的Waymo數據集,該數據集包含1 150個場景,每個場景跨越20 s,包括在美國鳳凰城、山景城和舊金山的城市和郊區捕獲的經過良好同步和校準的高質量LiDAR和相機數據。目前,該數據集定義了2D和3D對象檢測和跟蹤任務,未來研究者計劃添加地圖信息、更多標記和未標記數據,使其更加多樣化。
表 2根據不同的應用場景,簡要對這些比較有影響力的常用大型道路目標檢測數據集進行了介紹。
表2 道路場景數據集
除了上述列舉的常用大型數據集外,很多研究者也會在MS COCO[6]、PASCAL VOC[63]等包含有關小目標類別的大型數據集或自建的數據集上對檢測模型或優化方法進行驗證。表 3對MS COCO、PASCAL VOC這兩類常用的公共數據集進行了簡要介紹。
表3 MS COCO 和 PASCAL VOC 數據集

2.2 評價指標
對于道路場景小目標檢測的評價指標主要包括檢測精度和檢測速度這兩方面。檢測精度主要使用平均精度(Average Precision,AP)和多個類別的平均精度均值(mean Average Precision,mAP)來衡量模型檢測性能的優劣,AP和mAP的計算公式分別如式(1)和式(2)所示:

其中: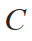 代表所有類別數;
代表所有類別數;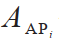 代表模型對于第i個類別的物體的平均精度。
代表模型對于第i個類別的物體的平均精度。
模型檢測速度主要反映了算法的實時性,也是一個重要的評價指標,通常采用每秒幀率(Frame Per Second,FPS),即算法平均每秒檢測的圖像數量進行衡量。FPS越高,模型檢測速度越快,實時性能越好。
2.3 性能對比
一部分優化方法基于MS COCO數據集訓練模型并進行驗證,另外一部分優化方法在PASCAL VOC 2007、KITTI道路場景數據集以及自建的數據集上進行模型性能驗證,這里將分為兩部分進行性能對比。
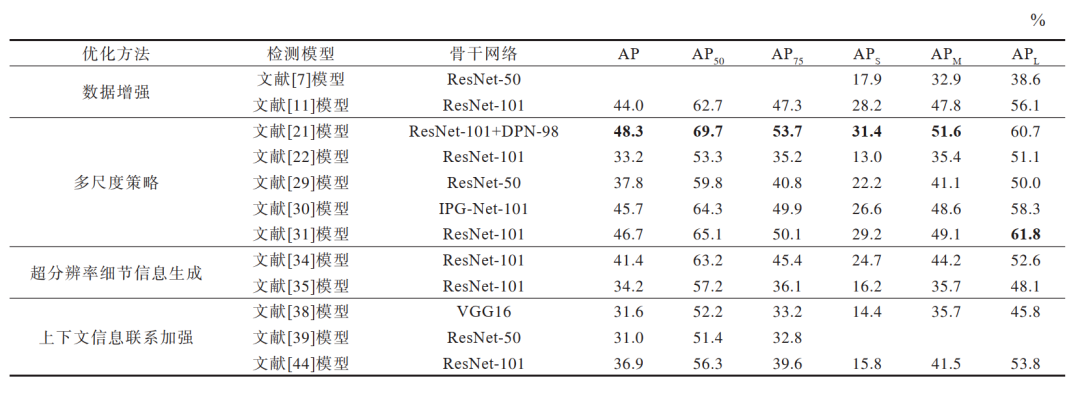
不同檢測模型在MS COCO數據集上的性能測試結果如表 4所示,其中,AP50和AP75分別表示IoU閾值為0.5和0.75時目標檢測的平均精度,APS、APM和APL分別表示小、中、大尺度檢測目標的平均精度,最優指標值用加粗字體標示。
表4 不同檢測模型在 MS COCO 數據集上的測試結果
?
?
由表 4可以看出,文獻[21]模型在多個指標上都取得了最佳的檢測結果,在多尺度策略的基礎上,采用一種新的圖像金字塔尺度歸一化(SNIP)訓練策略,只選取分辨率落入所需尺度范圍的目標進行訓練,忽略其他目標。通過這種訓練設置,可在最合理的范圍內處理小目標物體,以此提高了小目標的檢測精度,卻不影響對中大型對象的檢測性能。文獻[7]模型基于數據增強的優化方法相比于其他模型性能較差,主要原因為其在大型數據集中僅使用數據增強,對小目標檢測的性能提升是有限的,還需與其他方法結合使用。對于同一個優化方法,IoU閾值設置為0.5時取得的AP值較高,當IoU提高時,精度也會降低。雖然優化后的模型在小尺度目標上的檢測精度有所提升,但整體上小尺度的檢測精度與中大尺度的檢測精度仍有著明顯的差距,僅約為大尺度目標的1/2,這也說明了小目檢測的難度較大。
總體來看,針對小目標檢測的優化方法對于3個尺度目標的檢測性能均有一定提升,各類檢測模型均在大尺度目標上的敏感性更好,獲得的檢測精度最高,而其中基于多尺度策略的檢測模型在3個尺度目標的檢測上得到了最好的檢測結果,基于超分辨率細節信息生成的檢測模型次之,而僅基于數據增強方法的檢測模型對目標的敏感度最低,性能提升微弱。因此,當數據集容量偏小且數據集構成比較簡單時,采用數據增強能對目標檢測性能有一定的提升,而在大型復雜數據集中,其他方法改進效果更加顯著,而使用基于多尺度策略的優化方法得到的小目標的平均精度要高于其他方法,因此可以成為未來一個主要的研究方向。
表 5展示了一些檢測模型在KITTI等道路場景數據集及自建的數據集上的檢測性能,與原始模型相比,優化后的模型在精度和速度上都得到了一定的提升,但與在MS COCO數據集上進行的實驗結果相比,在這些數據集上的實驗結果無法表現出明顯的交叉評估性能。
表5 不同檢測模型在其他數據集上的測試結果
03? 未來研究方向
目前,在道路場景下的小目標檢測已取得了較大進步,下一步將對其在多個數據集上的檢測性能以及在可靠性、通用性、魯棒性等方面的表現做進一步研究。
1)構建適應性和普適性更強的檢測模型。許多通用的檢測模型對于復雜道路場景下行人、車輛等小目標的類型、大小等較敏感,需要根據不同的場景調整參數,例如學習率:當設置較大的學習率時模型可能永遠不會收斂,當設置較小的學習率時模型會給出次優結果。因此,建立適應性和普適性更強的檢測模型是一個重要的研究方向。
2)設計性能更優和更適合小目標檢測的專用骨干網絡。深層次的骨干網絡可能不利于小目標提取高質量的特征表示,因此需要設計一個有效的骨干網絡,既具有強大的特征提取能力,能更好地提升小目標的檢測性能,又能減少高昂的計算成本和目標信息的丟失,這也是目前研究的一大趨勢。
3)構建更輕量化的檢測模型。不同的應用場景對檢測精度和速度的側重不同,當應用于智能交通等領域時,對于檢測速度的追求是首選,在檢測模型中融入特征融合結構已成為道路小目標檢測中的最常用的研究方法,但該方法會降低檢測速度,增加時間消耗,因此需要構建更輕量化的檢測模型,在保持一定精度的前提下設計靈活度更高的網絡結構,滿足模型輕量化、易于移植的需求,實現模型在車輛設備上的快速部署,具有很強的現實意義。
4)構建大規模通用的道路小目標檢測數據集。小目標數據集的缺乏是影響小目標檢測的一個重要因素,現有的數據集或自建的數據集包含多類小目標的數量非常有限,無法支持基于深度學習的小目標檢測定制模型的訓練以及性能評估,因此構建小目標數據集對于推進小目標檢測的發展具有重要的意義。
5)采用合適的訓練策略。在大部分數據集中,小目標物體占比小、數量少,因此可采用一些特定的訓練方式,包括多尺度訓練、增加小目標的訓練權重以及多個數據集進行聯合訓練等,使得模型對小尺度目標的泛化能力增強,在訓練時對小目標的學習更加充分。這也是提高小目標檢測性能的有效措施,具有廣闊的發展前景。
04? 結束語
道路小目標檢測是計算機視覺領域的一個極具挑戰性的問題。本文從數據增強、多尺度策略、生成超分辨率細節信息、加強上下文信息聯系、改進損失函數等5個方面對基于深度學習的道路場景下的小目標檢測優化方法的最新研究進展進行歸納和總結,并根據定量和定性結果對各類優化方法的性能進行評估。后續將對探索設計性能更優和更輕量化的檢測模型、構建小目標數據集、改進訓練策略等方向進行更深入研究。
編輯:黃飛
?








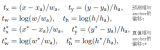









 工商網監
工商網監
評論