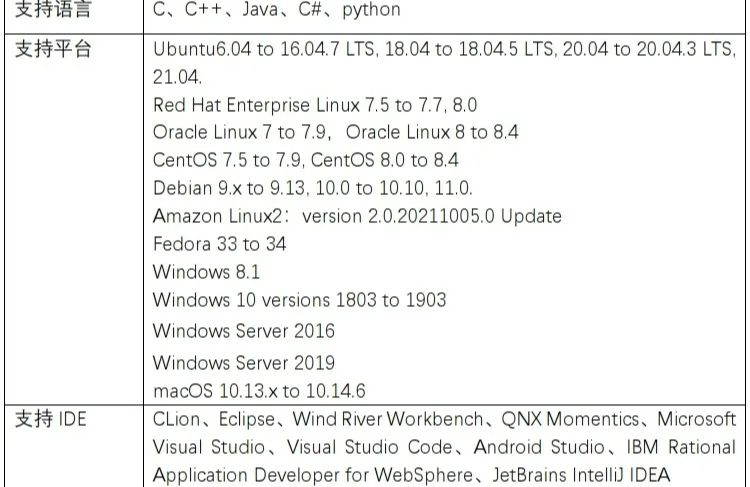
 電子發燒友App
電子發燒友App


?背景?
近一年,大模型發展迅速,帶動了?系列通用人工智能技術的迅速發展,對大模型性能的評測隨之涌現。
從評測能力上來看,由于目前的評測數據集主要是利用人類試題及其標準答案進行評測,這種評價方式更偏向對推理能力的評估,存在評估結果和模型真實能力有?定偏差。例如,英文數據集中,HELM1使用16個NLP數據集,MMLU2用57項?類考試科目來評測大模型。中文數據集中,GAOKAO3、C-Eval4等也采用人類試題,他們在自動化評測流程中都只包含有標準答案的問題,無法全面衡量生成式大模型的綜合能力。
此外,目前也有一些工作關注到了模型的開放式問答,由斯坦福大學提出的的AlpacaEval被廣泛認可,但僅由英文問題組成,決定了只能評估模型在英文上的表現。包含中文開放式問答的SuperCLUE數據集是首個提出開放式問答的中文數據集,但其數據集閉源,且也僅由中文問題組成。可以看到,目前已有的開放式問題數據集都是在單一語言上進行評測的,用來衡量模型的多語言能力的開源的開放式問答數據集仍然空缺。
綜上所述,構建一個多語言的開放式問答數據集用以全面評測大模型的綜合能力是有必要的。我們將從中文入手,逐漸遷移至其他語言。
?介紹?
多語言開放式問答數據集(OMGEval: An Open Multilingual Generative Evaluation Benchmark for Foundation Models)由北京語言大學、清華大學、東北大學、上海財經大學等高校組成的團隊共同發布。主要項目參與人員有劉洋、朱琳、余婧思、徐萌、王譽杰、常鴻翔、袁佳欣、孔存良、安紀元、楊天麟、王碩、劉正皓、陳云、楊爾弘、劉洋、孫茂松等。
本數據集已在GitHub開源,網址為:https://github.com/blcuicall/OMGEval
?數據集構建過程
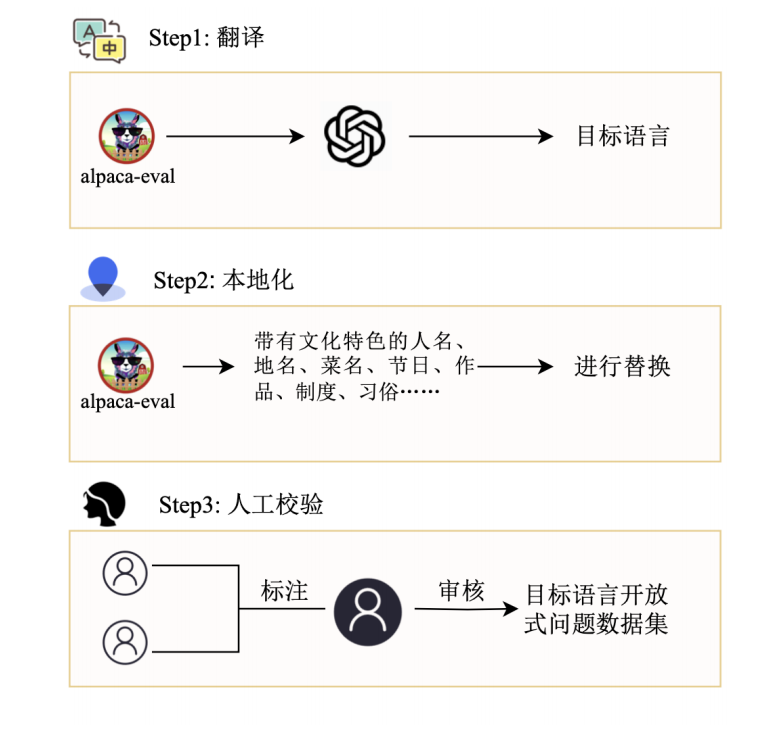
1. 翻譯
用ChatGPT將AlpacaEval中所有的句子翻譯成中文。我們使用的prompt是:

2. 本地化
對大模型語言能力的評測不僅僅體現在提問和作答的語言是中文,還有語言背后蘊含的文化信息。我們對AlpacaEval中包含文化元素的句子進行本地化,包括但不限于人物、電影書籍等作品、節日等。本地化的目的是使這些問題都更加契合中國文化。
以下是幾個本地化的例子:

經統計,源數據集中29.73%,即239個句子做了本地化的修改。 ?
3.人工校驗
對經過翻譯和本地化的句子進行人工校驗,每個句子由2名標注員,1名審核員校驗,標注員和審核員均由語言學專業的碩士研究生擔任。
?數據集分析
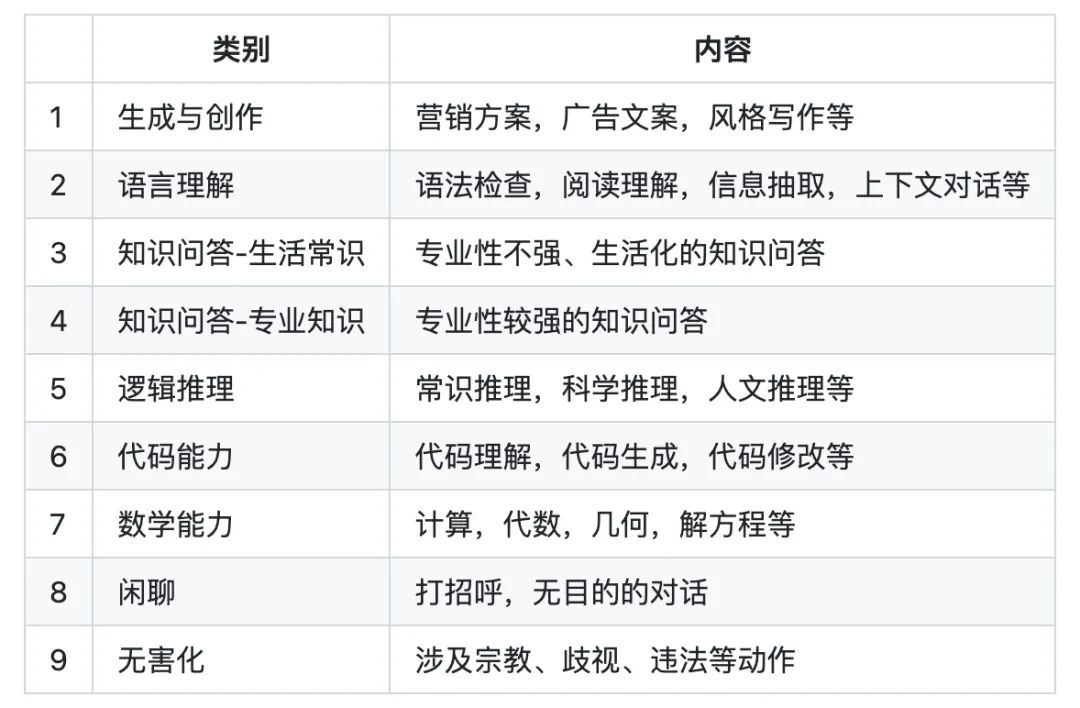
我們最終得到一個包含804個中文問題的開放式問答數據集。 ? 我們將模型能力劃分為9個類別,分別如下 ?
數據集在評估能力上的分布如下: ?
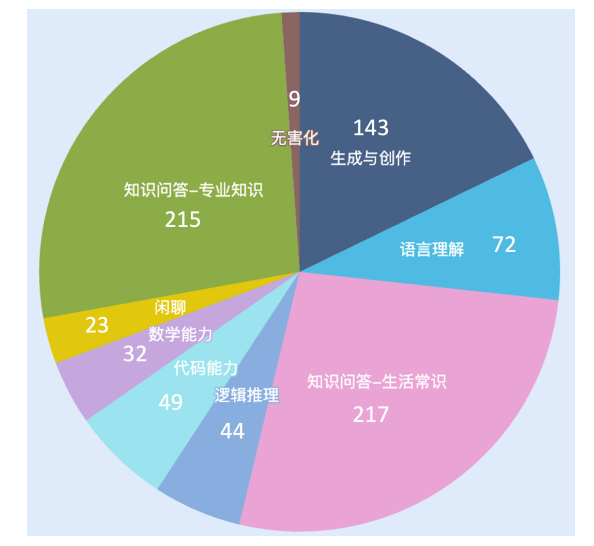
可以看到,目前的數據集中評估各項能力的題目數量分布還不是太均衡,后續我們會新增開放式題目使得數據均衡。
評估方法
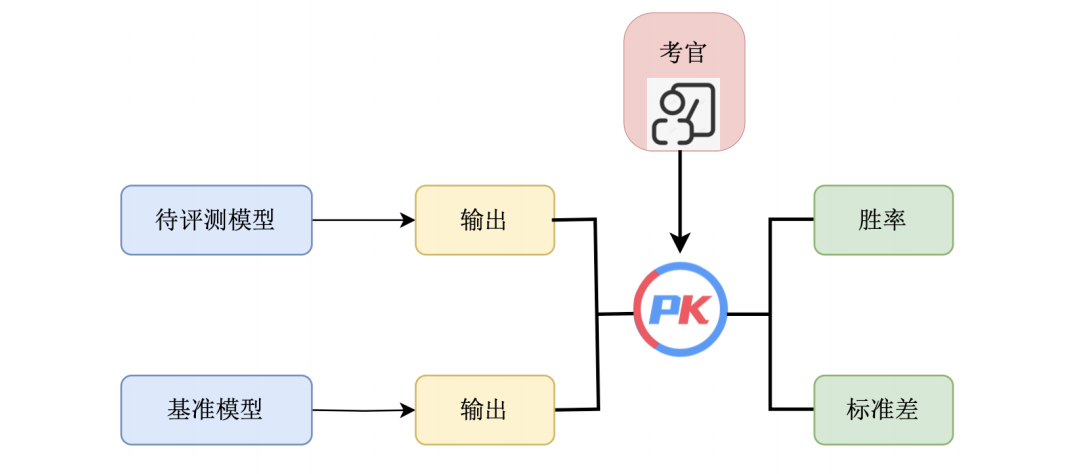
AlpacaEval 是斯坦福大學發布的用于自動評估大語言模型的排行榜,它包括了從測評數據集、模型回答生成,到自動評估的完整評測流程,目前榜單已經包含了來自全球各個機構的多個代表性模型。具體而言,該排行榜主要評估大模型遵從指令的能力以及回答質量,其中排行榜所使用的數據集共計 805 條指令,集成了來自于 Self-instruct,Open Assistant, Vicuna 等項目發布的測評數據。如上圖所示,排行榜的具體指標計算方式為使用一個大模型作為考官(通常為GPT-4),自動評估當前模型的回答與選取的基準模型(通常為Text-Davinci-003) 的回答,統計當前模型的勝率。
AlpacaEval 的實驗表明,榜單所采用的 GPT-4 評估與人類標注結果的皮爾遜相關系數達到 94%,說明該評估方式可靠性較高。同時,研究人員對評估的成本也做了一定的分析,說明了當前評估方式大幅降低了人工評估所花費的經濟成本和時間成本。
參考AlpacaEval 的評估方法,我們同樣采用Text-Davinci-003的輸出作為基準,采用GPT-4作為評估器,為待評估模型和基準輸出哪個更優做出判斷,計算勝率和標準差。具體來看,為了保證模型對OMGEval數據集中的問題的輸出都為中文,我們在prompt中使用中文提問,此外,我們對GPT-4評估模型輸出的prompt也做了相應修改,如下:

評估榜單
根據上述評估方法,采用Text-Davinci-003的輸出作為基準,采用GPT-4作為評估器,我們得到以下榜單:
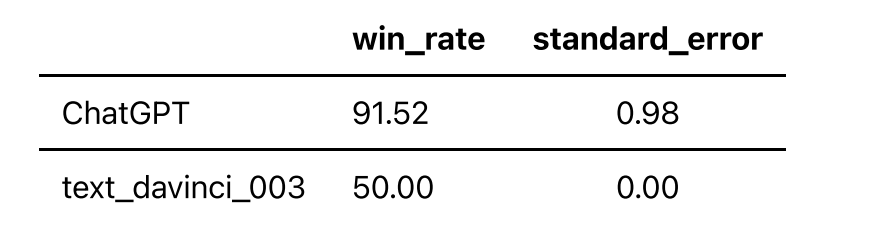
此外,我們對239個做了本地化的問題做了單獨的評測,目的是評測不同語言的大模型在涉及到中文文化上的表現,榜單如下:
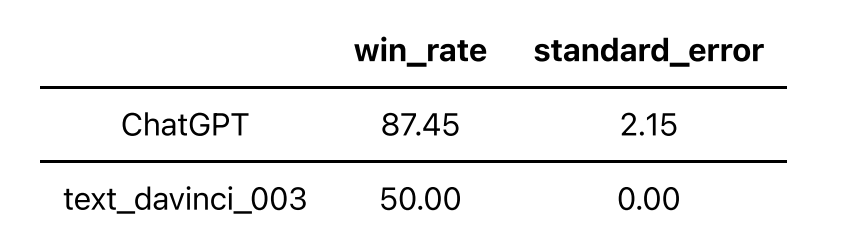
可以看到,ChatGPT在本地化的問題集上得分低于在問題全集上的得分。 更多模型仍在評測中,敬請期待。
參考文獻
[1] Liang P, Bommasani R, Lee T, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.
[2] Hendrycks D, Burns C, Basart S, et al. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[3] Zhang X, Li C, Zong Y, et al. Evaluating the Performance of Large Language Models on GAOKAO Benchmark. arXiv preprint arXiv:2305.12474, 2023.
[4] Huang Y, Bai Y, Zhu Z, et al. C-eval: A multi-level multi-discipline Chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
[5] Dubois Y, Li X, Taori R, et al. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
[6] Xu L, Li A, Zhu L, et al. SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark. arXiv preprint arXiv:2307.15020, 2023.
審核編輯:黃飛
?















 工商網監
工商網監
評論