 電子發(fā)燒友App
電子發(fā)燒友App


導(dǎo)讀
本文總結(jié)了一些秋招面試中會(huì)遇到的問(wèn)題和一些重要的知識(shí)點(diǎn),適合面試前突擊和鞏固基礎(chǔ)知識(shí)。
前言
最近這段時(shí)間正臨秋招,這篇文章是老潘在那會(huì)找工作過(guò)程中整理的一些重要知識(shí)點(diǎn),內(nèi)容比較雜碎,部分采集于網(wǎng)絡(luò),簡(jiǎn)單整理下發(fā)出來(lái),適合面試前突擊,當(dāng)然也適合鞏固基礎(chǔ)知識(shí)。另外推薦大家一本叫做《百面機(jī)器學(xué)習(xí)》的新書(shū),2018年8月份出版的,其中包括了很多機(jī)器學(xué)習(xí)、深度學(xué)習(xí)面試過(guò)程中會(huì)遇到的問(wèn)題,比較適合需要準(zhǔn)備面試的機(jī)器學(xué)習(xí)、深度學(xué)習(xí)方面的算法工程師,當(dāng)然也同樣適合鞏固基礎(chǔ)~有時(shí)間一定要需要看的書(shū)籍:
程序員的數(shù)學(xué)系列,適合重溫知識(shí),回顧一些基礎(chǔ)的線性代數(shù)、概率論。
深度學(xué)習(xí)花書(shū),總結(jié)類(lèi)書(shū),有基礎(chǔ)知識(shí)的講解,比較全面。
統(tǒng)計(jì)學(xué)習(xí)方法,總結(jié)類(lèi)書(shū),篇幅不長(zhǎng),都是核心。
Pattern Recognition and Machine Learning,條理清晰,用貝葉斯的方式來(lái)講解機(jī)器學(xué)習(xí)。
機(jī)器學(xué)習(xí)西瓜書(shū),適合當(dāng)教材,內(nèi)容較廣但是不深。
?
百翻不爛的百面機(jī)器學(xué)習(xí)
常見(jiàn)的常識(shí)題
L1正則可以使少數(shù)權(quán)值較大,多數(shù)權(quán)值為0,得到稀疏的權(quán)值;L2正則會(huì)使權(quán)值都趨近于0但非零,得到平滑的權(quán)值;
在AdaBoost算法中,被錯(cuò)分的樣本的權(quán)重更新比例的公式相同;
Boosting和Bagging都是組合多個(gè)分類(lèi)器投票的方法,但Boosting是根據(jù)單個(gè)分類(lèi)器的正確率決定其權(quán)重,Bagging是可簡(jiǎn)單地設(shè)置所有分類(lèi)器權(quán)重相同;
EM算法不能保證找到全局最優(yōu)值;
SVR中核函數(shù)寬度小欠擬合,寬度大容易過(guò)擬合
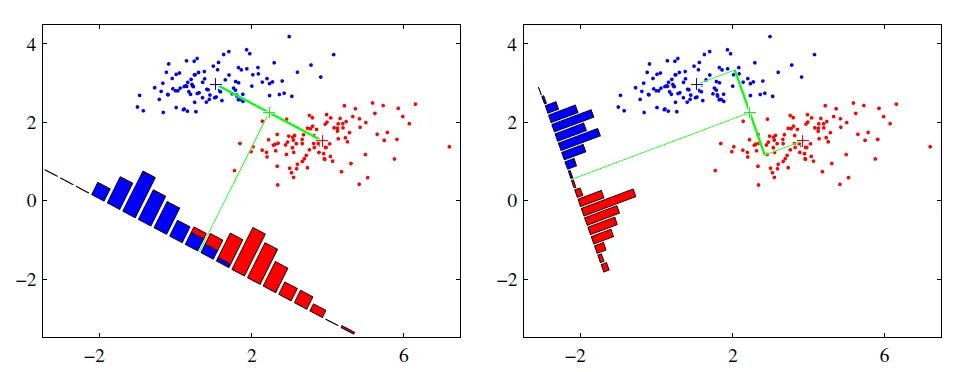
PCA和LDA都是經(jīng)典的降維算法。PCA是無(wú)監(jiān)督的,也就是訓(xùn)練樣本不需要標(biāo)簽;LDA是有監(jiān)督的,也就是訓(xùn)練樣本需要標(biāo)簽。PCA是去除掉原始數(shù)據(jù)中冗余的維度,而LDA是尋找一個(gè)維度,使得原始數(shù)據(jù)在該維度上投影后不同類(lèi)別的數(shù)據(jù)盡可能分離開(kāi)來(lái)。
PCA是一種正交投影,它的思想是使得原始數(shù)據(jù)在投影子空間的各個(gè)維度的方差最大。假設(shè)我們要將N維的數(shù)據(jù)投影到M維的空間上(M
PCA和LDA
參考鏈接:PCA和LDA的對(duì)比
KNN K近鄰
關(guān)于K近鄰算法的知識(shí)有很多,比如算法執(zhí)行的步驟、應(yīng)用領(lǐng)域以及注意事項(xiàng),不過(guò)相信很多人對(duì)K近鄰算法的使用注意事項(xiàng)不是很清楚。在這篇文章中我們針對(duì)這個(gè)問(wèn)題進(jìn)行解答,帶大家來(lái)好好了解一下k近鄰算法的注意事項(xiàng)以及K近鄰算法的優(yōu)點(diǎn)與缺點(diǎn)。
K近鄰算法的注意事項(xiàng)
K近鄰算法的使用注意事項(xiàng)具體就是使用距離作為度量時(shí),要保證所有特征在數(shù)值上是一個(gè)數(shù)量級(jí)上,以免距離的計(jì)算被數(shù)量級(jí)大的特征所主導(dǎo)。在數(shù)據(jù)標(biāo)準(zhǔn)化這件事上,還要注意一點(diǎn),訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集一定要使用同一標(biāo)準(zhǔn)的標(biāo)準(zhǔn)化。其中的原因總的來(lái)說(shuō)就有兩點(diǎn)內(nèi)容,第一就是標(biāo)準(zhǔn)化其實(shí)可以視為算法的一部分,既然數(shù)據(jù)集都減去了一個(gè)數(shù),然后除以一個(gè)數(shù),這兩個(gè)數(shù)對(duì)于所有的數(shù)據(jù)來(lái)說(shuō),就要一視同仁。第二就是訓(xùn)練數(shù)據(jù)集其實(shí)很少,在預(yù)測(cè)新樣本的時(shí)候,新樣本就更少得可憐,如果新樣本就一個(gè)數(shù)據(jù),它的均值就是它自己,標(biāo)準(zhǔn)差是0,這根本就不合理。
K近鄰算法的優(yōu)點(diǎn)是什么呢?
K近鄰算法的優(yōu)點(diǎn)具體體現(xiàn)在四方面。第一就就是k近鄰算法是一種在線技術(shù),新數(shù)據(jù)可以直接加入數(shù)據(jù)集而不必進(jìn)行重新訓(xùn)練,第二就是k近鄰算法理論簡(jiǎn)單,容易實(shí)現(xiàn)。第三就是準(zhǔn)確性高,對(duì)異常值和噪聲有較高的容忍度。第四就是k近鄰算法天生就支持多分類(lèi),區(qū)別與感知機(jī)、邏輯回歸、SVM。
K近鄰算法的缺點(diǎn)是什么呢?
K近鄰算法的缺點(diǎn),基本的 k近鄰算法每預(yù)測(cè)一個(gè)“點(diǎn)”的分類(lèi)都會(huì)重新進(jìn)行一次全局運(yùn)算,對(duì)于樣本容量大的數(shù)據(jù)集計(jì)算量比較大。而且K近鄰算法容易導(dǎo)致維度災(zāi)難,在高維空間中計(jì)算距離的時(shí)候,就會(huì)變得非常遠(yuǎn);樣本不平衡時(shí),預(yù)測(cè)偏差比較大,k值大小的選擇得依靠經(jīng)驗(yàn)或者交叉驗(yàn)證得到。k的選擇可以使用交叉驗(yàn)證,也可以使用網(wǎng)格搜索。k的值越大,模型的偏差越大,對(duì)噪聲數(shù)據(jù)越不敏感,當(dāng) k的值很大的時(shí)候,可能造成模型欠擬合。k的值越小,模型的方差就會(huì)越大,當(dāng) k的值很小的時(shí)候,就會(huì)造成模型的過(guò)擬合。
二維高斯核函數(shù)
如果讓你寫(xiě)一個(gè)高斯模糊的函數(shù),你該怎么寫(xiě)呢?
?
?
?
?
訓(xùn)練采樣方法
交叉驗(yàn)證
留一法
自助法(bootstrap):有放回的抽樣方法,可能會(huì)抽到重復(fù)的樣本
Kmean和GMM原理、區(qū)別、應(yīng)用場(chǎng)景
kmeans的收斂性?
可以看這里 https://zhuanlan.zhihu.com/p/36331115
也可以看百面機(jī)器學(xué)習(xí)P93、P102
如何在多臺(tái)計(jì)算機(jī)上做kmeans
其實(shí)是這樣的,先分布到n臺(tái)機(jī)器上,要保證k個(gè)初始化相同,經(jīng)過(guò)一次迭代后,拿到k*n個(gè)新的mean,放到一臺(tái)新的機(jī)器上,因?yàn)槌跏蓟嗤詍ean的排列相同,然后對(duì)屬于每個(gè)類(lèi)的n個(gè)mean做加權(quán)平均,再放回每臺(tái)機(jī)器上做下一步迭代。
KNN算法以及流程
K值的選擇:
K值較小,則模型復(fù)雜度較高,容易發(fā)生過(guò)擬合,學(xué)習(xí)的估計(jì)誤差會(huì)增大,預(yù)測(cè)結(jié)果對(duì)近鄰的實(shí)例點(diǎn)非常敏感。
K值較大可以減少學(xué)習(xí)的估計(jì)誤差,但是學(xué)習(xí)的近似誤差會(huì)增大,與輸入實(shí)例較遠(yuǎn)的訓(xùn)練實(shí)例也會(huì)對(duì)預(yù)測(cè)起作用,使預(yù)測(cè)發(fā)生錯(cuò)誤,k值增大模型的復(fù)雜度會(huì)下降。
在應(yīng)用中,k值一般取一個(gè)比較小的值,通常采用交叉驗(yàn)證法來(lái)來(lái)選取最優(yōu)的K值。
KNN中的K值選取對(duì)分類(lèi)的結(jié)果影響至關(guān)重要,K值選取的太小,模型太復(fù)雜。K值選取的太大,導(dǎo)致分類(lèi)模糊。那么K值到底怎么選取呢?有人用Cross Validation,有人用貝葉斯,還有的用bootstrap。而距離度量又是另外一個(gè)問(wèn)題,比較常用的是選用歐式距離。可是這個(gè)距離真的具有普適性嗎?《模式分類(lèi)》中指出歐式距離對(duì)平移是敏感的,這點(diǎn)嚴(yán)重影響了判定的結(jié)果。在此必須選用一個(gè)對(duì)已知的變換(比如平移、旋轉(zhuǎn)、尺度變換等)不敏感的距離度量。書(shū)中提出了采用切空間距離(tangent distance)來(lái)替代傳統(tǒng)的歐氏距離。
無(wú)監(jiān)督學(xué)習(xí)和有監(jiān)督學(xué)習(xí)的區(qū)別
有監(jiān)督:
感知機(jī)
K近鄰法
樸素貝葉斯
決策樹(shù)
邏輯回歸
支持向量機(jī)
提升方法
隱馬爾科夫模型
條件隨機(jī)場(chǎng)
無(wú)監(jiān)督:
聚類(lèi)-kmeans
SVD奇異值分解
PCA主成分分析
生成式模型:LDA KNN 混合高斯 貝葉斯 馬爾科夫 深度信念 判別式模型:SVM NN LR CRF CART
邏輯回歸與SVM區(qū)別
邏輯回歸即LR。LR預(yù)測(cè)數(shù)據(jù)的時(shí)候,給出的是一個(gè)預(yù)測(cè)結(jié)果為正類(lèi)的概率,這個(gè)概率是通過(guò)sigmoid函數(shù)將wTx映射到[0,1]得到的,對(duì)于wTx正的很大時(shí)(可以認(rèn)為離決策邊界很遠(yuǎn)),得到為正類(lèi)的概率趨近于1;對(duì)于wTx負(fù)的很大時(shí)(可以認(rèn)為離決策邊界很遠(yuǎn)),得到為正類(lèi)的概率趨近于0。在LR中,跟“與決策邊界距離”扯得上關(guān)系的僅此而已。在參數(shù)w求解過(guò)程中完全沒(méi)有與決策邊界距離的影子,所有樣本都一視同仁。和感知機(jī)的不同之處在于,LR用到與決策邊界的距離,是用來(lái)給預(yù)測(cè)結(jié)果一個(gè)可以看得到的置信區(qū)間。感知機(jī)里面沒(méi)有這一考慮,只根據(jù)符號(hào)來(lái)判斷。而SVM更進(jìn)一步,在參數(shù)的求解過(guò)程中,便舍棄了距離決策邊界過(guò)遠(yuǎn)的點(diǎn)。LR和感知機(jī)都很容易過(guò)擬合,只有SVM加入了L2范數(shù)之后的結(jié)構(gòu)化風(fēng)險(xiǎn)最小化策略才解決了過(guò)擬合的問(wèn)題。總結(jié)之:
感知機(jī)前后都沒(méi)有引入與超平面“距離”的概念,它只關(guān)心是否在超平面的一側(cè);
LR引入了距離,但是在訓(xùn)練模型求其參數(shù)的時(shí)候沒(méi)有距離的概念,只是在最后預(yù)測(cè)階段引入距離以表征分類(lèi)的置信度;
SVM兩個(gè)地方有距離的概念:其一,在求超平面參數(shù)的時(shí)候有距離的概念,其表現(xiàn)為在與超平面一定距離內(nèi)的點(diǎn)著重關(guān)注,而其他的一切點(diǎn)都不再關(guān)注。被關(guān)注的點(diǎn)稱(chēng)之為“支撐向量”。其二,預(yù)測(cè)新樣本的時(shí)候,和LR一樣,距離代表置信度。
邏輯回歸只能解決二分類(lèi)問(wèn)題,多分類(lèi)用softmax。相關(guān)參考鏈接
https://blog.csdn.net/maymay_/article/details/80016175
https://blog.csdn.net/jfhdd/article/details/52319422
https://www.cnblogs.com/eilearn/p/9026851.html
bagging boosting 和 提升樹(shù)
bagging是通過(guò)結(jié)合幾個(gè)模型降低泛化誤差,分別訓(xùn)練幾個(gè)不同的模型,然后讓所有的模型表決測(cè)試樣例的輸出。模型平均奏效的原因是不同的模型通常不會(huì)在測(cè)試集上產(chǎn)生完全相同的誤差。從原始樣本集中抽取訓(xùn)練集.每輪從原始樣本集中使用Bootstraping的方法抽取n個(gè)訓(xùn)練樣本(在訓(xùn)練集中,有些樣本可能被多次抽取到,而有些樣本可能一次都沒(méi)有被抽中).共進(jìn)行k輪抽取,得到k個(gè)訓(xùn)練集.(k個(gè)訓(xùn)練集相互獨(dú)立)
Bagging是并行的學(xué)習(xí)算法,思想很簡(jiǎn)單,即每一次從原始數(shù)據(jù)中根據(jù)均勻概率分布有放回的抽取和原始數(shù)據(jù)集一樣大小的數(shù)據(jù)集合。樣本點(diǎn)可以出現(xiàn)重復(fù),然后對(duì)每一次產(chǎn)生的數(shù)據(jù)集構(gòu)造一個(gè)分類(lèi)器,再對(duì)分類(lèi)器進(jìn)行組合。對(duì)于分類(lèi)問(wèn)題,將上步得到的k個(gè)模型采用投票的方式得到分類(lèi)結(jié)果;對(duì)回歸問(wèn)題,計(jì)算上述模型的均值作為最后的結(jié)果.
Boosting是一族可將弱學(xué)習(xí)器提升為強(qiáng)學(xué)習(xí)器的算法.Boosting的每一次抽樣的樣本分布是不一樣的,每一次迭代,都是根據(jù)上一次迭代的結(jié)果,增加被錯(cuò)誤分類(lèi)的樣本的權(quán)重。使模型在之后的迭代中更加注重難以分類(lèi)的樣本。這是一個(gè)不斷學(xué)習(xí)的過(guò)程,也是一個(gè)不斷提升的過(guò)程,這就是Boosting思想的本質(zhì)所在。迭代之后,將每次迭代的基分類(lèi)器進(jìn)行集成,那么如何進(jìn)行樣本權(quán)重的調(diào)整和分類(lèi)器的集成是我們需要考慮的關(guān)鍵問(wèn)題。
Bagging和Boosting的區(qū)別:
1)樣本選擇上:Bagging:訓(xùn)練集是在原始集中有放回選取的,從原始集中選出的各輪訓(xùn)練集之間是獨(dú)立的. Boosting:每一輪的訓(xùn)練集不變,只是訓(xùn)練集中每個(gè)樣例在分類(lèi)器中的權(quán)重發(fā)生變化.而權(quán)值是根據(jù)上一輪的分類(lèi)結(jié)果進(jìn)行調(diào)整.
2)樣例權(quán)重:Bagging:使用均勻取樣,每個(gè)樣例的權(quán)重相等 Boosting:根據(jù)錯(cuò)誤率不斷調(diào)整樣例的權(quán)值,錯(cuò)誤率越大則權(quán)重越大.
3)預(yù)測(cè)函數(shù):Bagging:所有預(yù)測(cè)函數(shù)的權(quán)重相等. Boosting:每個(gè)弱分類(lèi)器都有相應(yīng)的權(quán)重,對(duì)于分類(lèi)誤差小的分類(lèi)器會(huì)有更大的權(quán)重.
4)并行計(jì)算:Bagging:各個(gè)預(yù)測(cè)函數(shù)可以并行生成 Boosting:各個(gè)預(yù)測(cè)函數(shù)只能順序生成,因?yàn)楹笠粋€(gè)模型參數(shù)需要前一輪模型的結(jié)果.
Bagging 是 Bootstrap Aggregating 的簡(jiǎn)稱(chēng),意思就是再取樣 (Bootstrap) 然后在每個(gè)樣本上訓(xùn)練出來(lái)的模型取平均,所以是降低模型的 variance. Bagging 比如 Random Forest 這種先天并行的算法都有這個(gè)效果。Boosting 則是迭代算法,每一次迭代都根據(jù)上一次迭代的預(yù)測(cè)結(jié)果對(duì)樣本進(jìn)行加權(quán),所以隨著迭代不斷進(jìn)行,誤差會(huì)越來(lái)越小,所以模型的 bias 會(huì)不斷降低High variance 是model過(guò)于復(fù)雜overfit,記住太多細(xì)節(jié)noise,受outlier影響很大;high bias是underfit,model過(guò)于簡(jiǎn)單,cost function不夠好。boosting是把許多弱的分類(lèi)器組合成一個(gè)強(qiáng)的分類(lèi)器。弱的分類(lèi)器bias高,而強(qiáng)的分類(lèi)器bias低,所以說(shuō)boosting起到了降低bias的作用。variance不是boosting的主要考慮因素。bagging是對(duì)許多強(qiáng)(甚至過(guò)強(qiáng))的分類(lèi)器求平均。在這里,每個(gè)單獨(dú)的分類(lèi)器的bias都是低的,平均之后bias依然低;而每個(gè)單獨(dú)的分類(lèi)器都強(qiáng)到可能產(chǎn)生overfitting的程度,也就是variance高,求平均的操作起到的作用就是降低這個(gè)variance。Bagging算法的代表:RandomForest隨機(jī)森林算法的注意點(diǎn):
在構(gòu)建決策樹(shù)的過(guò)程中是不需要剪枝的。
整個(gè)森林的樹(shù)的數(shù)量和每棵樹(shù)的特征需要人為進(jìn)行設(shè)定。
構(gòu)建決策樹(shù)的時(shí)候分裂節(jié)點(diǎn)的選擇是依據(jù)最小基尼系數(shù)的。
咱們機(jī)器學(xué)習(xí)升級(jí)版的隨機(jī)森林章節(jié),我用白板寫(xiě)了寫(xiě)這個(gè)公式:p = 1 - (1 - 1/N)^N,其意義是:一個(gè)樣本在一次決策樹(shù)生成過(guò)程中,被選中作為訓(xùn)練樣本的概率,當(dāng)N足夠大時(shí),約等于63.2%。簡(jiǎn)言之,即一個(gè)樣本被選中的概率是63.2%,根據(jù)二項(xiàng)分布的的期望,這意味著大約有63.2%的樣本被選中。即有63.2%的樣本是不重復(fù)的,有36.8%的樣本可能沒(méi)有在本次訓(xùn)練樣本集中。隨機(jī)森林是一個(gè)包含多個(gè)決策樹(shù)的分類(lèi)器,并且其輸出的類(lèi)別是由個(gè)別樹(shù)輸出的類(lèi)別的眾數(shù)而定。隨機(jī)森林的隨機(jī)性體現(xiàn)在每顆樹(shù)的訓(xùn)練樣本是隨機(jī)的,樹(shù)中每個(gè)節(jié)點(diǎn)的分裂屬性集合也是隨機(jī)選擇確定的。有了這2個(gè)隨機(jī)的保證,隨機(jī)森林就不會(huì)產(chǎn)生過(guò)擬合的現(xiàn)象了。隨機(jī)森林是用一種隨機(jī)的方式建立的一個(gè)森林,森林是由很多棵決策樹(shù)組成的,每棵樹(shù)所分配的訓(xùn)練樣本是隨機(jī)的,樹(shù)中每個(gè)節(jié)點(diǎn)的分裂屬性集合也是隨機(jī)選擇確定的。
SVM
相關(guān)的notebook除了cs231n也可以看這里。
https://momodel.cn/workspace/5d37bb9b1afd94458f84a521?type=module
凸集、凸函數(shù)、凸優(yōu)化
面試見(jiàn)得比較少,感興趣的可以看下:
https://blog.csdn.net/feilong_csdn/article/details/83476277
為什么深度學(xué)習(xí)中的圖像分割要先編碼后解碼
降采樣是手段不是目的:
降低顯存和計(jì)算量,圖小了顯存也小,計(jì)算量也小;
增大感受野,使用同樣3x3的卷積能在更大的圖像范圍上進(jìn)行特征提取。大感受野對(duì)分割很重要,小感受野做不了多分類(lèi)分割,而且分割出來(lái)很粗糙
多出幾條不同程度額下采樣分支,可以方便進(jìn)行多尺度特征的融合。多級(jí)語(yǔ)義融合會(huì)讓分類(lèi)更加準(zhǔn)確。
降采樣的理論意義,我簡(jiǎn)單朗讀一下,它可以增加對(duì)輸入圖像的一些小擾動(dòng)的魯棒性,比如圖像平移,旋轉(zhuǎn)等,減少過(guò)擬合的風(fēng)險(xiǎn),降低運(yùn)算量,和增加感受野的大小。相關(guān)鏈接:為什么深度學(xué)習(xí)中的圖像分割要先編碼再解碼?
(全局)平均池化average pooling和(全局)最大池化max pooling的區(qū)別
最大池化保留了紋理特征
平均池化保留整體的數(shù)據(jù)特征
全局平均池化有定位的作用(看知乎)
最大池化提取邊緣等“最重要”的特征,而平均池化提取的特征更加smoothly。對(duì)于圖像數(shù)據(jù),你可以看到差異。雖然兩者都是出于同樣的原因使用,但我認(rèn)為max pooling更適合提取極端功能。平均池有時(shí)不能提取好的特征,因?yàn)樗鼘⑷坑?jì)入并計(jì)算出平均值,這對(duì)于對(duì)象檢測(cè)類(lèi)型任務(wù)可能不好用但使用平均池化的一個(gè)動(dòng)機(jī)是每個(gè)空間位置具有用于期望特征的檢測(cè)器,并且通過(guò)平均每個(gè)空間位置,其行為類(lèi)似于平均輸入圖像的不同平移的預(yù)測(cè)(有點(diǎn)像數(shù)據(jù)增加)。Resnet不是采用傳統(tǒng)的完全連通層進(jìn)行CNN分類(lèi),而是直接從最后一個(gè)mlp轉(zhuǎn)換層輸出特征圖的空間平均值,作為通過(guò)全局平均合并層的類(lèi)別置信度,然后將得到的矢量輸入到 softmax層。相比之下,Global average更有意義且可解釋?zhuān)驗(yàn)樗鼜?qiáng)制實(shí)現(xiàn)了feature和類(lèi)別之間的對(duì)應(yīng)關(guān)系,這可以通過(guò)使用網(wǎng)絡(luò)的更強(qiáng)大的本地建模來(lái)實(shí)現(xiàn)。此外,完全連接的層易于過(guò)擬合并且嚴(yán)重依賴(lài)于 dropout 正則化,而全局平均池化本身就是起到了正則化作用,其本身防止整體結(jié)構(gòu)的過(guò)擬合。
https://zhuanlan.zhihu.com/p/42384808
https://www.zhihu.com/question/335595503/answer/778307744
https://www.zhihu.com/question/309713971/answer/578634764
全連接的作用,與1x1卷積層的關(guān)系
在實(shí)際使用中,全連接層可由卷積操作實(shí)現(xiàn):對(duì)前層是全連接的全連接層可以轉(zhuǎn)化為卷積核為1x1的卷積;而前層是卷積層的全連接層可以轉(zhuǎn)化為卷積核為hxw的全局卷積,h和w分別為前層卷積結(jié)果的高和寬使用 global average pooling 全局平均池化來(lái)代替卷積
全連接層(fully connected layers,F(xiàn)C)在整個(gè)卷積神經(jīng)網(wǎng)絡(luò)中起到“分類(lèi)器”的作用。如果說(shuō)卷積層、池化層和激活函數(shù)層等操作是將原始數(shù)據(jù)映射到隱層特征空間的話,全連接層則起到將學(xué)到的“分布式特征表示”映射到樣本標(biāo)記空間的作用。在實(shí)際使用中,全連接層可由卷積操作實(shí)現(xiàn):對(duì)前層是全連接的全連接層可以轉(zhuǎn)化為卷積核為1x1的卷積;而前層是卷積層的全連接層可以轉(zhuǎn)化為卷積核為hxw的全局卷積,h和w分別為前層卷積結(jié)果的高和寬
那么,1*1卷積的主要作用有以下幾點(diǎn):
降維( dimension reductionality )。比如,一張500x500且厚度depth為100的圖片在20個(gè)filter上做1*1的卷積,那么結(jié)果的大小為500*500*20。
加入非線性。卷積層之后經(jīng)過(guò)激勵(lì)層,1*1的卷積在前一層的學(xué)習(xí)表示上添加了非線性激勵(lì)( non-linear activation ),提升網(wǎng)絡(luò)的表達(dá)能力,但是也可以這樣說(shuō):使之由單純的線性變換,變?yōu)閺?fù)雜的feature map之間的線性組合,從而實(shí)現(xiàn)特征的高度抽象過(guò)程。這一過(guò)程視為由線性變換為非線性,提高抽象程度。而非加入激活函數(shù)的作用。
個(gè)人應(yīng)該是降維或者升維來(lái)減小參數(shù)個(gè)數(shù)和增加網(wǎng)絡(luò)深度,以及跨通道的特征聚合
可以代替全連接層
看這個(gè)問(wèn)題的回答?https://www.zhihu.com/question/56024942/answer/369745892?
看這個(gè)問(wèn)題的回答?https://www.zhihu.com/question/41037974/answer/150522307
concat與add(sum)的區(qū)別
對(duì)于兩路輸入來(lái)說(shuō),如果是通道數(shù)相同且后面帶卷積的話,add等價(jià)于concat之后對(duì)應(yīng)通道共享同一個(gè)卷積核。下面具體用式子解釋一下。由于每個(gè)輸出通道的卷積核是獨(dú)立的,我們可以只看單個(gè)通道的輸出。假設(shè)兩路輸入的通道分別為X1, X2, ..., Xc和Y1, Y2, ..., Yc。那么concat的單個(gè)輸出通道為(*表示卷積):
而add的單個(gè)輸出通道為:
因此add相當(dāng)于加了一種prior,當(dāng)兩路輸入可以具有“對(duì)應(yīng)通道的特征圖語(yǔ)義類(lèi)似”(可能不太嚴(yán)謹(jǐn))的性質(zhì)的時(shí)候,可以用add來(lái)替代concat,這樣更節(jié)省參數(shù)和計(jì)算量(concat是add的2倍)。FPN[1]里的金字塔,是希望把分辨率最小但語(yǔ)義最強(qiáng)的特征圖增加分辨率,從性質(zhì)上是可以用add的。如果用concat,因?yàn)榉直媛市〉奶卣魍ǖ罃?shù)更多,計(jì)算量是一筆不少的開(kāi)銷(xiāo)。https://www.zhihu.com/question/306213462/answer/562776112
concat改成sum確實(shí)會(huì)好很多,這兩個(gè)都是特征融合,到底有什么本質(zhì)區(qū)別呢?我用的時(shí)候也沒(méi)什么原則就是兩個(gè)都試一下(其實(shí)更喜歡用sum,畢竟更省顯存)。
我之前做過(guò)類(lèi)似ASP的實(shí)驗(yàn),金字塔型空洞卷積融合,最后實(shí)驗(yàn)結(jié)果sum比concat要好一些,但是原因不知道怎么解釋
我看過(guò)一些論文是concat比sum好的,可能這跟數(shù)據(jù)集等具體情況有關(guān)吧
不同的特征 sum 了,有什么意義呢,這些特征又損失了吧;如果直接 concat,讓后面的網(wǎng)絡(luò)學(xué)習(xí),應(yīng)該更好啊,用到的特征更多了
SSD怎么改動(dòng)變成FasterRCNN
SSD是直接分類(lèi),而FasterRcnn是先判斷是否為背景再進(jìn)行分類(lèi)。一個(gè)是直接細(xì)分類(lèi),一個(gè)是先粗分類(lèi)再細(xì)分類(lèi)。
反向傳播的原理
反向傳播原理看CS231n中的BP過(guò)程,以及Jacobian的傳播。
GD、SGD、mini batch GD的區(qū)別
在百面深度學(xué)習(xí)中有相應(yīng)的章節(jié)。
偏差、方差
有一篇文章比較好的介紹了,還有在那本電子版CNNbook中也有。
http://scott.fortmann-roe.com/docs/BiasVariance.html
泛化誤差可以分解成偏差的平方+方差+噪聲
偏差度量了學(xué)習(xí)算法的期望預(yù)測(cè)和真實(shí)結(jié)果的偏離程度,刻畫(huà)了學(xué)習(xí)算法本身的擬合能力
方差度量了同樣大小的訓(xùn)練集的變動(dòng)所導(dǎo)致的學(xué)習(xí)性能的變化,刻畫(huà)了數(shù)據(jù) 擾動(dòng)所造成的干擾
噪聲表達(dá)了當(dāng)前任務(wù)上學(xué)習(xí)任何算法所能達(dá)到的期望泛化誤差下界,刻畫(huà)了問(wèn)題本身的難度。
偏差和方差一般稱(chēng)為bias和variance,一般訓(xùn)練誤差越強(qiáng),偏差越小,方差越大,泛化誤差在中間會(huì)有一個(gè)最小值。
如果偏差較大,方差較小,此時(shí)為欠擬合,而偏差較小,方差較大為過(guò)擬合。
為什么會(huì)梯度爆炸,如何防止
多層神經(jīng)網(wǎng)絡(luò)通常存在像懸崖一樣的結(jié)構(gòu),這是由于幾個(gè)較大的權(quán)重相乘導(dǎo)致的。遇到斜率很大的懸崖結(jié)構(gòu),梯度更新會(huì)很大程序地改變參數(shù)值,通常會(huì)完全跳過(guò)這類(lèi)懸崖的結(jié)構(gòu)。花書(shū)P177.
分布式訓(xùn)練,多卡訓(xùn)練
http://ai.51cto.com/art/201710/555389.htm?
https://blog.csdn.net/xs11222211/article/details/82931120#commentBox
精確率和召回率以及PR曲線
這個(gè)講的比較好(TP與FP和ROC曲線):
https://segmentfault.com/a/1190000014829322
精確率是指分類(lèi)正確的正樣本個(gè)數(shù)占分類(lèi)器判定為正樣本的樣本個(gè)數(shù)的比例。召回率是指分類(lèi)正確的正樣本個(gè)數(shù)占真正的正樣本個(gè)數(shù)的比例。Precision值和Recall值是既矛盾又統(tǒng)一的兩個(gè)指標(biāo),為了提高Precision值,分類(lèi)器需要盡量在“更有把握”時(shí)才把樣本預(yù)測(cè)為正樣本,但此時(shí)往往會(huì)因?yàn)檫^(guò)于保守而漏掉很多“沒(méi)有把握”的正樣本,導(dǎo)致Recall值很低。如何權(quán)衡這兩個(gè)值,所以出現(xiàn)了PR曲線、ROC曲線以及F1 score等更多的標(biāo)準(zhǔn)來(lái)進(jìn)行判斷。https://www.cnblogs.com/xuexuefirst/p/8858274.html
Yolov2相比Yolov1因?yàn)椴捎昧讼闰?yàn)框(Anchor Boxes),模型的召回率大幅提升,同時(shí)map輕微下降了0.2。
https://segmentfault.com/a/1190000014829322?
https://www.cnblogs.com/eilearn/p/9071440.html?
https://blog.csdn.net/zdh2010xyz/article/details/54293298
空洞卷積
空洞卷積一般都伴有padding,如果dilation=6,那么padding也等于6。通過(guò)空洞卷積后的卷積特征圖的大小不變,但是這個(gè)卷積的感受野比普通同等大小的卷積大。不過(guò)通道數(shù)是可以改變的。
在DeepLabv3+中,最后的ASPP層,通過(guò)一個(gè)1x1卷積和3個(gè)3x3的空洞卷積,再concat上一個(gè)經(jīng)過(guò)全局平均池化后雙線性采樣到同等維度的特征圖。
但是要注意,由于空洞卷積本身不會(huì)增大運(yùn)算量,但是后續(xù)的分辨率沒(méi)有減小,后面的計(jì)算量就間接變大了。https://zhuanlan.zhihu.com/p/52476083
數(shù)據(jù)不好怎么辦,數(shù)據(jù)不均衡怎么處理、只有少量帶標(biāo)簽怎么處理
具體問(wèn)題具體分析。
訓(xùn)練過(guò)程中需要過(guò)擬合情況怎么辦
深度學(xué)習(xí)-通用模型調(diào)試技巧
如何根據(jù)訓(xùn)練/驗(yàn)證損失曲線診斷我們的CNN
關(guān)于訓(xùn)練神經(jīng)網(wǎng)路的諸多技巧Tricks(完全總結(jié)版)
深度學(xué)習(xí)中數(shù)據(jù)集很小是一種什么樣的體驗(yàn)
如果模型的實(shí)際容量比較大,那么可以說(shuō)模型可以完全學(xué)習(xí)到整個(gè)數(shù)據(jù)集,會(huì)發(fā)生過(guò)擬合。這時(shí)候再添加新的數(shù)據(jù)進(jìn)去,模型的性能會(huì)進(jìn)一步提升,說(shuō)明模型還沒(méi)有被撐死。期望風(fēng)險(xiǎn)是模型關(guān)于聯(lián)合分布的期望損失,經(jīng)驗(yàn)風(fēng)險(xiǎn)是模型關(guān)于訓(xùn)練數(shù)據(jù)集的平均損失。根據(jù)大樹(shù)定律,當(dāng)樣本容量N趨于無(wú)窮時(shí),經(jīng)驗(yàn)風(fēng)險(xiǎn)趨于期望風(fēng)險(xiǎn)。但是當(dāng)樣本的容量比較小的的時(shí)候,經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化學(xué)習(xí)的效果未必就會(huì)很好,會(huì)產(chǎn)生“過(guò)擬合”的現(xiàn)象。結(jié)構(gòu)風(fēng)險(xiǎn)最小化是為了防止過(guò)擬合而提出的策略。
https://lilianweng.github.io/lil-log/2019/03/14/are-deep-neural-networks-dramatically-overfitted.html?
https://www.jianshu.com/p/97aafe479fa1?(重要)
正則化
在Pytorch中只能在optim中設(shè)置weight_decay,目前只支持L2正則,而且這個(gè)正則是針對(duì)模型中所有的參數(shù),不論是w還是b,也包括BN中的W和b。
BN層和L2正則化一起有什么后果
就是因?yàn)?batch norm 過(guò)后, weight 影響沒(méi)那么重了,所以 l2 weight decay 的效果就不明顯了。證明了L2正則化與歸一化相結(jié)合時(shí)沒(méi)有正則化效應(yīng)。相反,正則化會(huì)影響權(quán)重的范圍,從而影響有效學(xué)習(xí)率。
https://www.cnblogs.com/makefile/p/batch-norm.html?utm_source=debugrun&utm_medium=referral
ROIPooling和ROIAlign的區(qū)別
空間金字塔池化(SSP)可以使不同尺寸的圖像產(chǎn)生固定的輸出維度。借題也問(wèn)個(gè)問(wèn)題,為什么fast rcnn的roi pooling是一個(gè)max pooling呢?roi pooling后面也是做單個(gè)roi的classification,為啥不和classification的pooling不同?我直覺(jué)是看feature map中的一個(gè)channel,提取全局特征(如,做classification)用average pooling,提取提取全局信息;提取局部特征(如,roi pooling)應(yīng)該用max pooling,提取局部最明顯的特征,成為7×7的grid后交給后面的fc來(lái)做classification。相關(guān)介紹:
SPPNet-引入空間金字塔池化改進(jìn)RCNN
自己實(shí)現(xiàn)圖像增強(qiáng)算法
https://zhuanlan.zhihu.com/p/71231560
圖像分類(lèi)的tricks
亞馬遜:用CNN進(jìn)行圖像分類(lèi)的Tricks(https://mp.weixin.qq.com/s/e4m_LhtqoUiGJMQfEZHcRA)
消融實(shí)驗(yàn)(Ablation experiment)
因?yàn)樽髡咛岢隽艘环N方案,同時(shí)改變了多個(gè)條件/參數(shù),他在接下去的消融實(shí)驗(yàn)中,會(huì)一一控制一個(gè)條件/參數(shù)不變,來(lái)看看結(jié)果,到底是哪個(gè)條件/參數(shù)對(duì)結(jié)果的影響更大。下面這段話摘自知乎,@人民藝術(shù)家:你朋友說(shuō)你今天的樣子很帥,你想知道發(fā)型、上衣和褲子分別起了多大的作用,于是你換了幾個(gè)發(fā)型,你朋友說(shuō)還是挺帥的,你又換了件上衣,你朋友說(shuō)不帥了,看來(lái)這件衣服還挺重要的。
手?jǐn)]NMS與soft-NMS
https://oldpan.me/archives/write-hard-nms-c
邏輯回歸和線性回歸
線性回歸:通過(guò)均方誤差來(lái)尋找最優(yōu)的參數(shù),然后通過(guò)最小二乘法來(lái)或者梯度下降法估計(jì):
而邏輯回歸的原型:對(duì)數(shù)幾率回歸:邏輯回歸和對(duì)數(shù)幾率回歸是一樣的,通過(guò)變形就可以得到,另外邏輯回歸使用極大似然概率進(jìn)行估計(jì)。簡(jiǎn)單總結(jié):
線性回歸和邏輯回歸都是廣義線性回歸模型的特例
線性回歸只能用于回歸問(wèn)題,邏輯回歸用于分類(lèi)問(wèn)題(可由二分類(lèi)推廣至多分類(lèi))
線性回歸無(wú)聯(lián)系函數(shù)或不起作用,邏輯回歸的聯(lián)系函數(shù)是對(duì)數(shù)幾率函數(shù),屬于Sigmoid函數(shù)
線性回歸使用最小二乘法作為參數(shù)估計(jì)方法,邏輯回歸使用極大似然法作為參數(shù)估計(jì)方法
兩者都可以使用梯度下降法
注意:
線性回歸的梯度下降法其實(shí)和我們訓(xùn)練神經(jīng)網(wǎng)絡(luò)一直,首先需要對(duì)參數(shù)進(jìn)行初始化,然后使用隨機(jī)梯度下降的方式對(duì)參數(shù)進(jìn)行更新//zhuanlan.zhihu.com/p/33992985
線性回歸與最小二乘法:https://zhuanlan.zhihu.com/p/36910496
最大似然?https://zhuanlan.zhihu.com/p/33349381
來(lái)源文章:
https://segmentfault.com/a/1190000014807779
https://zhuanlan.zhihu.com/p/39363869
https://blog.csdn.net/hahaha_2017/article/details/81066673
對(duì)于凸函數(shù)來(lái)說(shuō),局部最優(yōu)就是全局最優(yōu),相關(guān)鏈接:http://sofasofa.io/forum_main_post.php?postid=1000329?
http://sofasofa.io/forum_main_post.php?postid=1000322Logistic classification with cross-entropy
什么是attention,有哪幾種
https://zhuanlan.zhihu.com/p/61440116?
https://www.zhihu.com/question/65044831/answer/227262160
深度學(xué)習(xí)的線性和非線性
卷積是線性的
激活函數(shù)是非線性的
梯度消失和梯度爆炸的問(wèn)題
Batch-norm層的作用
不看必進(jìn)坑~不論是訓(xùn)練還是部署都會(huì)讓你踩坑的Batch Normalization
Batch size過(guò)小會(huì)使Loss曲線振蕩的比較大,大小一般按照2的次冪規(guī)律選擇,至于為什么?沒(méi)有答出來(lái),面試官后面解釋是為了硬件計(jì)算效率考慮的,海哥后來(lái)也說(shuō)GPU訓(xùn)練的時(shí)候開(kāi)的線程是2的次冪個(gè)神經(jīng)網(wǎng)絡(luò)的本質(zhì)是學(xué)習(xí)數(shù)據(jù)的分布,如果訓(xùn)練數(shù)據(jù)與測(cè)試數(shù)據(jù)的分布不同則會(huì)大大降低網(wǎng)絡(luò)的泛化能力。隨著網(wǎng)絡(luò)訓(xùn)練的進(jìn)行,每個(gè)隱層的變化使得后一層的輸入發(fā)生變化,從而每一批訓(xùn)練的數(shù)據(jù)的分布也會(huì)變化,致使網(wǎng)絡(luò)在每次迭代過(guò)程中都需要擬合不同的數(shù)據(jù)分布,增加數(shù)據(jù)訓(xùn)練的復(fù)雜度和過(guò)擬合的風(fēng)險(xiǎn)。
對(duì)數(shù)據(jù)的劇烈變化有抵抗能力。
要注意BN在卷積網(wǎng)絡(luò)層中,因?yàn)閰?shù)的共享機(jī)制,每一個(gè)卷積核的參數(shù)在不同位置的神經(jīng)元當(dāng)中是共享的,因此也應(yīng)該被歸一化。(具體看一下實(shí)現(xiàn)過(guò)程)https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/batch_norm_layer.html但是在訓(xùn)練過(guò)程中如果batch-size不大的話,可以不使用BN(MaskRcnn這樣說(shuō)的)。至此,關(guān)于Batch Normalization的理論與實(shí)戰(zhàn)部分就介紹道這里。總的來(lái)說(shuō),BN通過(guò)將每一層網(wǎng)絡(luò)的輸入進(jìn)行normalization,保證輸入分布的均值與方差固定在一定范圍內(nèi),減少了網(wǎng)絡(luò)中的Internal Covariate Shift問(wèn)題,并在一定程度上緩解了梯度消失,加速了模型收斂;并且BN使得網(wǎng)絡(luò)對(duì)參數(shù)、激活函數(shù)更加具有魯棒性,降低了神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練和調(diào)參的復(fù)雜度;最后BN訓(xùn)練過(guò)程中由于使用mini-batch的mean/variance作為總體樣本統(tǒng)計(jì)量估計(jì),引入了隨機(jī)噪聲,在一定程度上對(duì)模型起到了正則化的效果。
https://zhuanlan.zhihu.com/p/34879333
BN與貝葉斯的關(guān)系:
從Bayesian角度淺析Batch Normalization
BN跨卡訓(xùn)練怎么保證相同的mean和var
在實(shí)踐中,我發(fā)現(xiàn),跨卡同步的BN對(duì)于performance相當(dāng)有用。尤其是對(duì)于detection,segmentation任務(wù),本來(lái)Batch size較小。如果Batch Norm能跨卡同步的話,就相當(dāng)于增大了Batch Norm的batch size 這樣能估計(jì)更加準(zhǔn)確的mean和variance,所以這個(gè)操作能提升performance。
如何實(shí)現(xiàn)SyncBN
跨卡同步BN的關(guān)鍵是在前向運(yùn)算的時(shí)候拿到全局的均值和方差,在后向運(yùn)算時(shí)候得到相應(yīng)的全局梯度。最簡(jiǎn)單的實(shí)現(xiàn)方法是先同步求均值,再發(fā)回各卡然后同步求方差,但是這樣就同步了兩次。實(shí)際上只需要同步一次就可以,我們使用了一個(gè)非常簡(jiǎn)單的技巧,改變方差的公式(公式是圖片,具體大家自己網(wǎng)上搜一下SyncBN)。這樣在前向運(yùn)算的時(shí)候,我們只需要在各卡上算出與,再跨卡求出全局的和即可得到正確的均值和方差, 同理我們?cè)诤笙蜻\(yùn)算的時(shí)候只需同步一次,求出相應(yīng)的梯度與。我們?cè)谧罱恼撐腃ontext Encoding for Semantic Segmentation 里面也分享了這種同步一次的方法。有了跨卡BN我們就不用擔(dān)心模型過(guò)大用多卡影響收斂效果了,因?yàn)椴还苡枚嗌購(gòu)埧ㄖ灰值呐看笮∫粯樱紩?huì)得到相同的效果。
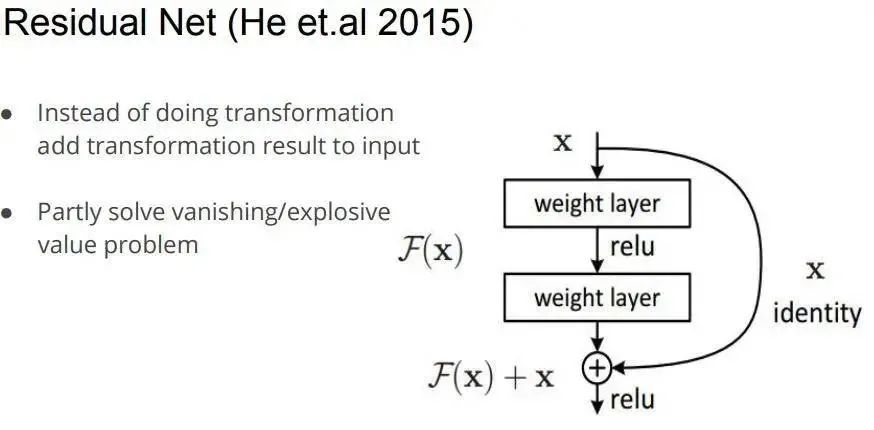
ResNet為什么好用
出現(xiàn)因素:
隨著網(wǎng)絡(luò)的加深,優(yōu)化函數(shù)越來(lái)越陷入局部最優(yōu)解
隨著網(wǎng)絡(luò)層數(shù)的增加,梯度消失的問(wèn)題更加嚴(yán)重,因?yàn)樘荻仍诜聪騻鞑サ臅r(shí)候會(huì)逐漸衰減
原因,誤差傳播公式可以寫(xiě)成參數(shù)W和導(dǎo)數(shù)F連乘的形式,當(dāng)誤差由第L層傳播到輸入以外的第一個(gè)隱含層的時(shí)候,會(huì)涉及到很多很多的參數(shù)和導(dǎo)數(shù)的連乘,這時(shí)誤差很容易產(chǎn)生消失或者膨脹,導(dǎo)致不容易學(xué)習(xí),擬合能力和泛化能力較差。殘差層中的F層只需要擬合輸入x與目標(biāo)輸出H的殘差H-x即可,如果某一層的輸出已經(jīng)較好地?cái)M合了期望結(jié)果,那么多一層也不回使得模型變得更差,因?yàn)樵搶拥妮敵鲋苯颖欢探拥絻蓪又螅喈?dāng)于直接學(xué)習(xí)了一個(gè)恒等映射,而跳過(guò)的兩層只需要擬合上層輸出和目標(biāo)之間的殘差即可。
https://zhuanlan.zhihu.com/p/42706477
https://zhuanlan.zhihu.com/p/31852747
Resnet的缺點(diǎn)
resnet其實(shí)無(wú)法真正的實(shí)現(xiàn)梯度消失,這里面有很強(qiáng)的先驗(yàn)假設(shè),并且resnet真正起作用的層只在中間,深層作用比較小(到了深層就是恒等映射了),feature存在利用不足的現(xiàn)象,add的方式阻礙了梯度和信息的流通。
L1范數(shù)和L2范數(shù) 應(yīng)用場(chǎng)景
L1正則可以使少數(shù)權(quán)值較大,多數(shù)權(quán)值為0,得到稀疏的權(quán)值;L2正則會(huì)使權(quán)值都趨近于0但非零,得到平滑的權(quán)值;https://zhuanlan.zhihu.com/p/35356992
網(wǎng)絡(luò)初始化有哪些方式,他們的公式初始化過(guò)程
目前的權(quán)重初始化分為三類(lèi):
全置為0 - 幾乎不會(huì)使用
隨機(jī)初始化(均勻隨機(jī)、正態(tài)分布)
Xavier 作者 Glorot 認(rèn)為,優(yōu)秀的初始化應(yīng)該使得各層的激活值和狀態(tài)梯度的方差在傳播過(guò)程中保持一致。適合sigmoid,但是不適合Relu。
He初始化適用于Relu。
初始化,說(shuō)白了就是構(gòu)建一個(gè)平滑的局部幾何空間從而使得優(yōu)化更簡(jiǎn)單xavier分布解析:
https://prateekvjoshi.com/2016/03/29/understanding-xavier-initialization-in-deep-neural-networks/
假設(shè)使用的是sigmoid函數(shù)。當(dāng)權(quán)重值(值指的是絕對(duì)值)過(guò)小,輸入值每經(jīng)過(guò)網(wǎng)絡(luò)層,方差都會(huì)減少,每一層的加權(quán)和很小,在sigmoid函數(shù)0附件的區(qū)域相當(dāng)于線性函數(shù),失去了DNN的非線性性。當(dāng)權(quán)重的值過(guò)大,輸入值經(jīng)過(guò)每一層后方差會(huì)迅速上升,每層的輸出值將會(huì)很大,此時(shí)每層的梯度將會(huì)趨近于0. xavier初始化可以使得輸入值x 方差經(jīng)過(guò)網(wǎng)絡(luò)層后的輸出值y方差不變。
https://blog.csdn.net/winycg/article/details/86649832
https://zhuanlan.zhihu.com/p/57454669
在pytorch中默認(rèn)的權(quán)重初始化方式是何凱明的那個(gè),舉個(gè)例子:
resnet中權(quán)重的初始化
?
?
?
?
求解模型參數(shù)量
?
?
?
?
卷積計(jì)算量
差不多這幾個(gè)懂了就OK。
普通卷積
可分離卷積
全連接
點(diǎn)卷積
可以看老潘的這篇文章:
你的模型能跑多快???
多標(biāo)簽和多分類(lèi)
那么,如何用softmax和sigmoid來(lái)做多類(lèi)分類(lèi)和多標(biāo)簽分類(lèi)呢?
1、如何用softmax做多分類(lèi)和多標(biāo)簽分類(lèi) 現(xiàn)假設(shè),神經(jīng)網(wǎng)絡(luò)模型最后的輸出是這樣一個(gè)向量logits=[1,2,3,4], 就是神經(jīng)網(wǎng)絡(luò)最終的全連接的輸出。這里假設(shè)總共有4個(gè)分類(lèi)。用softmax做多分類(lèi)的方法:?tf.argmax(tf.softmax(logits))首先用softmax將logits轉(zhuǎn)換成一個(gè)概率分布,然后取概率值最大的作為樣本的分類(lèi),這樣看似乎,tf.argmax(logits)同樣可以取得最大的值,也能得到正確的樣本分類(lèi),這樣的話softmax似乎作用不大.那么softmax的主要作用其實(shí)是在計(jì)算交叉熵上,首先樣本集中y是一個(gè)one-hot向量,如果直接將模型輸出logits和y來(lái)計(jì)算交叉熵,因?yàn)閘ogits=[1,2,3,4],計(jì)算出來(lái)的交叉熵肯定很大,這種計(jì)算方式不對(duì),而應(yīng)該將logits轉(zhuǎn)換成一個(gè)概率分布后再來(lái)計(jì)算,就是用tf.softmax(logits)和y來(lái)計(jì)算交叉熵,當(dāng)然我們也可以直接用tensorflow提供的方法sofmax_cross_entropy_with_logits來(lái)計(jì)算 這個(gè)方法傳入的參數(shù)可以直接是logits,因?yàn)檫@個(gè)根據(jù)方法的名字可以看到,方法內(nèi)部會(huì)將參數(shù)用softmax進(jìn)行處理,現(xiàn)在我們?nèi)〉母怕史植贾凶畲蟮淖鳛樽罱K的分類(lèi)結(jié)果,這是多分類(lèi)。我們也可以取概率的top幾個(gè),作為最終的多個(gè)標(biāo)簽,或者設(shè)置一個(gè)閾值,并取大于概率閾值的。這就用softmax實(shí)現(xiàn)了多標(biāo)簽分類(lèi)。
2、如何用sigmoid做多標(biāo)簽分類(lèi) sigmoid一般不用來(lái)做多類(lèi)分類(lèi),而是用來(lái)做二分類(lèi)的,它是將一個(gè)標(biāo)量數(shù)字轉(zhuǎn)換到[0,1]之間,如果大于一個(gè)概率閾值(一般是0.5),則認(rèn)為屬于某個(gè)類(lèi)別,否則不屬于某個(gè)類(lèi)別。那么如何用sigmoid來(lái)做多標(biāo)簽分類(lèi)呢?其實(shí)就是針對(duì)logits中每個(gè)分類(lèi)計(jì)算的結(jié)果分別作用一個(gè)sigmoid分類(lèi)器,分別判定樣本是否屬于某個(gè)類(lèi)別。同樣假設(shè),神經(jīng)網(wǎng)絡(luò)模型最后的輸出是這樣一個(gè)向量logits=[1,2,3,4], 就是神經(jīng)網(wǎng)絡(luò)最終的全連接的輸出。這里假設(shè)總共有4個(gè)分類(lèi)。tf.sigmoid(logits)sigmoid應(yīng)該會(huì)將logits中每個(gè)數(shù)字都變成[0,1]之間的概率值,假設(shè)結(jié)果為[0.01, 0.05, 0.4, 0.6],然后設(shè)置一個(gè)概率閾值,比如0.3,如果概率值大于0.3,則判定類(lèi)別符合,那這里,樣本會(huì)被判定為類(lèi)別3和類(lèi)別4都符合。
數(shù)據(jù)的輸入為什么要?dú)w一化
為了消除數(shù)據(jù)特征之間的量綱影響在實(shí)際應(yīng)用中,通過(guò)梯度下降法求解的模型通常是需要數(shù)據(jù)歸一化的,包括線性回歸、邏輯回歸、支持向量機(jī)、神經(jīng)網(wǎng)絡(luò)等,但是決策模型不是很適用。
為什么說(shuō)樸素貝葉斯是高偏差低方差?
首先,假設(shè)你知道訓(xùn)練集和測(cè)試集的關(guān)系。簡(jiǎn)單來(lái)講是我們要在訓(xùn)練集上學(xué)習(xí)一個(gè)模型,然后拿到測(cè)試集去用,效果好不好要根據(jù)測(cè)試集的錯(cuò)誤率來(lái)衡量。但很多時(shí)候,我們只能假設(shè)測(cè)試集和訓(xùn)練集的是符合同一個(gè)數(shù)據(jù)分布的,但卻拿不到真正的測(cè)試數(shù)據(jù)。這時(shí)候怎么在只看到訓(xùn)練錯(cuò)誤率的情況下,去衡量測(cè)試錯(cuò)誤率呢?
由于訓(xùn)練樣本很少(至少不足夠多),所以通過(guò)訓(xùn)練集得到的模型,總不是真正正確的。(就算在訓(xùn)練集上正確率100%,也不能說(shuō)明它刻畫(huà)了真實(shí)的數(shù)據(jù)分布,要知道刻畫(huà)真實(shí)的數(shù)據(jù)分布才是我們的目的,而不是只刻畫(huà)訓(xùn)練集的有限的數(shù)據(jù)點(diǎn))。而且,實(shí)際中,訓(xùn)練樣本往往還有一定的噪音誤差,所以如果太追求在訓(xùn)練集上的完美而采用一個(gè)很復(fù)雜的模型,會(huì)使得模型把訓(xùn)練集里面的誤差都當(dāng)成了真實(shí)的數(shù)據(jù)分布特征,從而得到錯(cuò)誤的數(shù)據(jù)分布估計(jì)。這樣的話,到了真正的測(cè)試集上就錯(cuò)的一塌糊涂了(這種現(xiàn)象叫過(guò)擬合)。但是也不能用太簡(jiǎn)單的模型,否則在數(shù)據(jù)分布比較復(fù)雜的時(shí)候,模型就不足以刻畫(huà)數(shù)據(jù)分布了(體現(xiàn)為連在訓(xùn)練集上的錯(cuò)誤率都很高,這種現(xiàn)象較欠擬合)。過(guò)擬合表明采用的模型比真實(shí)的數(shù)據(jù)分布更復(fù)雜,而欠擬合表示采用的模型比真實(shí)的數(shù)據(jù)分布要簡(jiǎn)單。
在統(tǒng)計(jì)學(xué)習(xí)框架下,大家刻畫(huà)模型復(fù)雜度的時(shí)候,有這么個(gè)觀點(diǎn),認(rèn)為Error = Bias + Variance。這里的Error大概可以理解為模型的預(yù)測(cè)錯(cuò)誤率,是有兩部分組成的,一部分是由于模型太簡(jiǎn)單而帶來(lái)的估計(jì)不準(zhǔn)確的部分(Bias),另一部分是由于模型太復(fù)雜而帶來(lái)的更大的變化空間和不確定性(Variance)。
所以,這樣就容易分析樸素貝葉斯了。它簡(jiǎn)單的假設(shè)了各個(gè)數(shù)據(jù)之間是無(wú)關(guān)的,是一個(gè)被嚴(yán)重簡(jiǎn)化了的模型。所以,對(duì)于這樣一個(gè)簡(jiǎn)單模型,大部分場(chǎng)合都會(huì)Bias部分大于Variance部分,也就是說(shuō)高偏差而低方差。
在實(shí)際中,為了讓Error盡量小,我們?cè)谶x擇模型的時(shí)候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
Canny邊緣檢測(cè),邊界檢測(cè)算法有哪些
https://zhuanlan.zhihu.com/p/42122107?
https://zhuanlan.zhihu.com/p/59640437
傳統(tǒng)的目標(biāo)檢測(cè)
傳統(tǒng)的目標(biāo)檢測(cè)一般分為以下幾個(gè)步驟:
區(qū)域選擇:一幅圖像通過(guò)selective search的方法,首先對(duì)原圖進(jìn)行分割(聚類(lèi)),然后通過(guò)計(jì)算相鄰區(qū)域的相似度,最終找到2000個(gè)框,同樣要與GT進(jìn)行正例和負(fù)例的判斷。
特征提取:通過(guò)SIFT或者其他的特征提取方法,將2000個(gè)轉(zhuǎn)化為特征向量
分類(lèi)器分類(lèi):將特征向量放入SVM中進(jìn)行分類(lèi)訓(xùn)練,同時(shí)將父類(lèi)也放入分類(lèi)器中進(jìn)行訓(xùn)練。
經(jīng)典的結(jié)構(gòu):
HoG + SVM
傳統(tǒng)方法的缺點(diǎn):
基于滑窗的區(qū)域選擇策略沒(méi)有針對(duì)性,時(shí)間復(fù)雜度高,窗口冗余
手工設(shè)計(jì)的特征對(duì)環(huán)境多樣性的變化并沒(méi)有很好的魯棒性
腐蝕膨脹、開(kāi)運(yùn)算閉運(yùn)算
可以看學(xué)習(xí)OpenCV第三版中的相關(guān)內(nèi)容,搜索erode、dilation
一些濾波器
https://blog.csdn.net/qq_22904277/article/details/53316415
https://www.jianshu.com/p/fbe8c24af108
https://blog.csdn.net/qq_22904277/article/details/53316415
https://blog.csdn.net/nima1994/article/details/79776802
https://blog.csdn.net/jiang_ming_/article/details/82594261
圖像中的高頻、低頻信息以及高通濾波器、低通濾波器
在圖像中,邊緣信息等比較明顯的變化比較劇烈的像素點(diǎn)就是圖像中的高頻信息。而除了邊緣部分,比較平緩的像素點(diǎn)變化不是很劇烈的內(nèi)容信息就是低頻信息。
高通濾波器就是突出變化劇烈(邊緣),去除低頻部分,也就是當(dāng)做邊緣提取器。而低通濾波器主要是平滑該像素的亮度。主要用于去噪和模糊化,高斯模糊是最常用的模糊濾波器(平滑濾波器)之一,它是一個(gè)削弱高頻信號(hào)強(qiáng)度的低通濾波器。
Resize雙線性插值
在網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行特征融合的時(shí)候,雙線性插值的方式比轉(zhuǎn)置卷積要好一點(diǎn)。因?yàn)檗D(zhuǎn)置卷積有一個(gè)比較大的問(wèn)題就是如果參數(shù)配置不當(dāng),很容易出現(xiàn)輸出feature map中帶有明顯棋盤(pán)狀的現(xiàn)象。
需要注意的,最近鄰插值的效果是最不好的。
雙線性插值也分為兩類(lèi):
align_corners=True
align_corners=False
一般來(lái)說(shuō),使用align_corners=True可以保證邊緣對(duì)齊,而使用align_corners=False則會(huì)導(dǎo)致邊緣突出的情況。這個(gè)講的非常好:
https://blog.csdn.net/qq_37577735/article/details/80041586
代碼實(shí)現(xiàn)的講解:
https://blog.csdn.net/love_image_xie/article/details/87969405
https://www.zhihu.com/question/328891283/answer/717113611?看這里的圖像展示:https://discuss.pytorch.org/t/what-we-should-use-align-corners-false/22663
gradient clipping 梯度裁剪
為了避免梯度爆炸而做出的改進(jìn),注意要和提前終止區(qū)別開(kāi)來(lái)。(提前終止是一種正則化方法,因?yàn)楫?dāng)訓(xùn)練有足夠能力表示甚至?xí)^(guò)擬合的大模型時(shí),訓(xùn)練誤差會(huì)隨著時(shí)間的推移逐漸降低但驗(yàn)證集的誤差會(huì)再次上升。這意味著只要我們返回使驗(yàn)證集誤差最低的參數(shù)設(shè)置即可)第一種做法很容易理解,就是先設(shè)定一個(gè) gradient 的范圍如 (-1, 1), 小于 -1 的 gradient 設(shè)為 -1, 大于這個(gè) 1 的 gradient 設(shè)為 1.
https://wulc.me/2018/05/01/%E6%A2%AF%E5%BA%A6%E8%A3%81%E5%89%AA%E5%8F%8A%E5%85%B6%E4%BD%9C%E7%94%A8/
實(shí)現(xiàn)一個(gè)簡(jiǎn)單的卷積
實(shí)現(xiàn)卷積一般用的是im2col的形式,但是面試中我們簡(jiǎn)單實(shí)現(xiàn)一個(gè)滑窗法就行了。比如:用3x3的卷積核(濾波盒)實(shí)現(xiàn)卷積操作。NCNN中在PC端卷積的源碼也是這樣的。
?
?
?
?
參考:
https://www.cnblogs.com/hejunlin1992/p/8686838.html
卷積的過(guò)程
看看Pytorch的源碼與caffe的源碼,都是將卷積計(jì)算轉(zhuǎn)化為矩陣運(yùn)算,im2col,然后gemm。https://blog.csdn.net/mrhiuser/article/details/52672824
轉(zhuǎn)置卷積的計(jì)算過(guò)程
https://cloud.tencent.com/developer/article/1363619
1*1的卷積核有什么用,3*3的卷積核和一個(gè)1*3加一個(gè)3*1的有什么區(qū)別
1x1卷積可以改變上一層網(wǎng)絡(luò)的通道數(shù)目。卷積核大于1x1,意味著提特征需要鄰域信息。
若提取橫向紋理,則橫向鄰域信息密度比縱向信息密度高。
核扁橫著最科學(xué)。若提縱向紋理,同理,瘦高豎著最好。
若你想提取的紋理種類(lèi)豐富,那橫向鄰域信息密度的期望~=縱向信息密度期望
所以對(duì)懶人來(lái)說(shuō),最優(yōu)核的尺寸的期望是正方形。至于1*n和n*1,它們一般是搭配使用的,從而實(shí)現(xiàn)n*n卷積核的感受野,可以在減少參數(shù)的同時(shí)增加層數(shù),在CNN的較高層中使用可以帶來(lái)一定的優(yōu)勢(shì)。卷積核并非都是正方形的,還可以是矩形,比如3*5,在文本檢測(cè)和車(chē)牌檢測(cè)當(dāng)中就有應(yīng)用,這種設(shè)計(jì)主要針對(duì)文本行或者車(chē)牌的形狀,能更好的學(xué)習(xí)特征。其實(shí)我覺(jué)得方形矩形影響不大,網(wǎng)絡(luò)的學(xué)習(xí)能力是非常強(qiáng)的。當(dāng)然我們也可以學(xué)習(xí)卷積的形狀,類(lèi)似于deformable convolution,老潘后續(xù)會(huì)講下。
ResNet中bottlenet與mobilenetv2的inverted結(jié)構(gòu)對(duì)比
注意,resnet中是先降維再升維,而mobilenetv2中是先升維后降維(所以稱(chēng)之為inversed)。
https://zhuanlan.zhihu.com/p/67872001
https://zhuanlan.zhihu.com/p/32913695
卷積特征圖大小的計(jì)算
很簡(jiǎn)單但是也很容易錯(cuò)的問(wèn)題:
Conv2D
動(dòng)態(tài)圖和靜態(tài)圖的區(qū)別
靜態(tài)圖是建立一次,然后不斷復(fù)用;靜態(tài)圖可以在磁盤(pán)中序列化,可以保存整個(gè)網(wǎng)絡(luò)的結(jié)構(gòu),可以重載,在部署中很實(shí)用,在tensorflow靜態(tài)圖中條件和循環(huán)需要特定的語(yǔ)法,pytorch只用python的語(yǔ)法就可以實(shí)現(xiàn)
而動(dòng)態(tài)圖是每次使用的時(shí)候建立,不容易優(yōu)化,需要重復(fù)之前的代碼,但是動(dòng)態(tài)圖比靜態(tài)圖代碼更簡(jiǎn)潔
依據(jù)采用動(dòng)態(tài)計(jì)算或是靜態(tài)計(jì)算的不同,可以將這些眾多的深度學(xué)習(xí)框架劃分成兩大陣營(yíng),當(dāng)然也有些框架同時(shí)具有動(dòng)態(tài)計(jì)算和靜態(tài)計(jì)算兩種機(jī)制(比如 MxNet 和最新的 TensorFlow)。動(dòng)態(tài)計(jì)算意味著程序?qū)凑瘴覀兙帉?xiě)命令的順序進(jìn)行執(zhí)行。這種機(jī)制將使得調(diào)試更加容易,并且也使得我們將大腦中的想法轉(zhuǎn)化為實(shí)際代碼變得更加容易。而靜態(tài)計(jì)算則意味著程序在編譯執(zhí)行時(shí)將先生成神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),然后再執(zhí)行相應(yīng)操作。從理論上講,靜態(tài)計(jì)算這樣的機(jī)制允許編譯器進(jìn)行更大程度的優(yōu)化,但是這也意味著你所期望的程序與編譯器實(shí)際執(zhí)行之間存在著更多的代溝。這也意味著,代碼中的錯(cuò)誤將更加難以發(fā)現(xiàn)(比如,如果計(jì)算圖的結(jié)構(gòu)出現(xiàn)問(wèn)題,你可能只有在代碼執(zhí)行到相應(yīng)操作的時(shí)候才能發(fā)現(xiàn)它)。盡管理論上而言,靜態(tài)計(jì)算圖比動(dòng)態(tài)計(jì)算圖具有更好的性能,但是在實(shí)踐中我們經(jīng)常發(fā)現(xiàn)并不是這樣的。
歷年來(lái)所有的網(wǎng)絡(luò)
這個(gè)可以看CS231n中的第九課以及
https://ucbrise.github.io/cs294-ai-sys-sp19/assets/lectures/lec02/classic_neural_architectures.pdf
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
正式總結(jié)下:
LeNet-5:第一個(gè)卷積,用來(lái)識(shí)別手寫(xiě)數(shù)組,使用的卷積大小為5x5,s=1,就是普通的卷積核池化層結(jié)合起來(lái),最后加上全連接層。
AlexNet:在第一個(gè)卷積中使用了11x11卷積,第一次使用Relu,使用了NormLayer但不是我們經(jīng)常說(shuō)的BN。使用了dropout,在兩個(gè)GPU上進(jìn)行了訓(xùn)練,使用的訓(xùn)練方式是模型并行、
ZFNet:AlexNet的加強(qiáng)版,將11x11卷積改成了7x7,也在AlexNet的基礎(chǔ)上將卷積的通道深度加深。所以在分類(lèi)比賽中比之前的效果好了些。
VGGNet:只使用了小卷積3x3(s=1)以及常規(guī)的池化層,不過(guò)深度比上一個(gè)深了一些,最后幾層也都是全連接層接一個(gè)softmax。為什么使用3x3卷積,是因?yàn)槿齻€(gè)3x3卷積的有效感受野和7x7的感受野一致,而且更深、更加非線性,而且卷積層的參數(shù)也更加地少,所以速度更快也可以適當(dāng)加深層數(shù)。
GoogleNet:沒(méi)有使用FC層,參數(shù)量相比之前的大大減少,提出了Inception module結(jié)構(gòu),也就是NIN結(jié)構(gòu)(network within a network)。但是原始的Inception module計(jì)算量非常大,所以在每一個(gè)分支加了1x1 conv "bottleneck"結(jié)構(gòu)(具體細(xì)節(jié)看圖)。googlenet網(wǎng)絡(luò)結(jié)構(gòu)中為了避免梯度消失,在中間的兩個(gè)位置加了兩個(gè)softmax損失,所以會(huì)有三個(gè)loss,整個(gè)網(wǎng)絡(luò)的loss是通過(guò)三個(gè)loss乘上權(quán)重相加后得到 相關(guān)文章:https://zhuanlan.zhihu.com/p/42704781 inception結(jié)構(gòu)的特點(diǎn):1、增加了網(wǎng)絡(luò)的寬度,同時(shí)也提高了對(duì)于不同尺度的適應(yīng)程度。2、使用 1x1 卷積核對(duì)輸入的特征圖進(jìn)行降維處理,這樣就會(huì)極大地減少參數(shù)量,從而減少計(jì)算量。3、在V3中使用了多個(gè)小卷積核代替大卷積核的方法,除了規(guī)整的的正方形,我們還有分解版本的 3x3 = 3x1 + 1x3,這個(gè)效果在深度較深的情況下比規(guī)整的卷積核更好。4、發(fā)明了Bottleneck 的核心思想還是利用多個(gè)小卷積核替代一個(gè)大卷積核,利用 1x1 卷積核替代大的卷積核的一部分工作。也就是先1x1降低通道然后普通3x3然后再1x1回去。
Xception:改進(jìn)了inception,提出的?depthwise Separable Conv?讓人眼前一亮。https://www.jianshu.com/p/4708a09c4352
ResNet:越深的網(wǎng)絡(luò)越難進(jìn)行優(yōu)化,有一個(gè)特點(diǎn)需要搞明白,越深的層最起碼表現(xiàn)應(yīng)該和淺層的一樣,不能比淺層的還差。對(duì)于更深的Resnet(50+),這里采用bottleneck層(也就是兩個(gè)1x1分別降維和升維)去提升網(wǎng)絡(luò)的效率。更詳細(xì)的描述可以看百面機(jī)器學(xué)習(xí)和ppt。相關(guān)講解:https://zhuanlan.zhihu.com/p/42706477
DenseNet 不能簡(jiǎn)單說(shuō)densenet更好,二者比較,ResNet是更一般的模型,DenseNet是更特化的模型。DenseNet用于圖像處理可能比ResNet表現(xiàn)更好,本質(zhì)是DenseNet更能和圖像的信息分布特點(diǎn)匹配,是使用了多尺度的Kernel。但是也有缺點(diǎn)最直接的計(jì)算就是一次推斷中所產(chǎn)生的所有feature map數(shù)目。有些框架會(huì)有優(yōu)化,自動(dòng)把比較靠前的層的feature map釋放掉,所以顯存就會(huì)減少,或者inplace操作通過(guò)重新計(jì)算的方法減少一部分顯存,但是densenet因?yàn)樾枰貜?fù)利用比較靠前的feature map,所以無(wú)法釋放,導(dǎo)致顯存占用過(guò)大。正是這種_concat_造成densenet能更密集的連接。
SeNet:全稱(chēng)為Squeeze-and-Excitation Networks。屬于注意力特征提取的范疇,加了GP(Global pooling)和兩個(gè)FC再加上sigmoid和scale。也就是生成注意力掩膜,去乘以輸入的x得到新的x。核心思想就是去學(xué)習(xí)每個(gè)特征通道的重要程度,然后根據(jù)這個(gè)重要程度去提升有用的特征并抑制對(duì)當(dāng)前任務(wù)用處不大的特征。這個(gè)給每一個(gè)特征層通道去乘以通過(guò)sigmoid得到的重要系數(shù),其實(shí)和用bn層去觀察哪個(gè)系數(shù)重要一樣。缺點(diǎn):由于在主干上存在 0~1 的 scale 操作,在網(wǎng)絡(luò)較深 BP 優(yōu)化時(shí)就會(huì)在靠近輸入層容易出現(xiàn)梯度消散的情況,導(dǎo)致模型難以?xún)?yōu)化。http://www.sohu.com/a/161633191_465975
Wide Residual Networks
ResNeXt:是resnet和inception的結(jié)合體,旁邊的residual connection就是公式中的x直接連過(guò)來(lái),然后剩下的是32組獨(dú)立的同樣結(jié)構(gòu)的變換,最后再進(jìn)行融合,符合split-transform-merge的模式。雖然分了32組,都是先點(diǎn)卷積降維,然后3x3普通卷積,然后1x1卷積升維(與Mobilenetv2中的相反) 相關(guān)介紹:https://zhuanlan.zhihu.com/p/51075096
Densely Connected Convolutional Networks:有利于減輕梯度消失的情況,增強(qiáng)了特征的流動(dòng)。
shufflenet:https://blog.csdn.net/u011974639/article/details/79200559
一些統(tǒng)計(jì)知識(shí)
正太分布:https://blog.csdn.net/yaningli/article/details/78051361
關(guān)于如何訓(xùn)練(訓(xùn)練過(guò)程中的一些問(wèn)題)
MaxPool導(dǎo)致的訓(xùn)練震蕩(通過(guò)在MaxPool之后加上L2Norm)//mp.weixin.qq.com/s/QR-KzLxOBazSbEFYoP334Q
全連接層的好伴侶:空間金字塔池化(SPP)
https://zhuanlan.zhihu.com/p/64510297
感受野計(jì)算
感受野計(jì)算有兩個(gè)公式,一個(gè)普通公式一個(gè)通項(xiàng)公式:
需要注意,卷積和池化都可以增加感受野。
審核編輯:黃飛
?
`def gaussian_2d_kernel(kernel_size = 3,sigma = 0):
kernel = np.zeros([kernel_size,kernel_size])
center = kernel_size // 2
if sigma == 0:
sigma = ((kernel_size-1)*0.5 - 1)*0.3 + 0.8
s = 2*(sigma**2)
sum_val = 0
for i in range(0,kernel_size):
for j in range(0,kernel_size):
x = i-center
y = j-center
kernel[i,j] = np.exp(-(x**2+y**2) / s)
sum_val += kernel[i,j]
#/(np.pi * s)
sum_val = 1/sum_val
return kernel*sum_val
`




for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def model_info(model): # Plots a line-by-line description of a PyTorch model
n_p = sum(x.numel() for x in model.parameters()) # number parameters
n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
print('
%5s %50s %9s %12s %20s %12s %12s' % ('layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma'))
for i, (name, p) in enumerate(model.named_parameters()):
name = name.replace('module_list.', '')
print('%5g %50s %9s %12g %20s %12.3g %12.3g' % (
i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
print('Model Summary: %d layers, %d parameters, %d gradients' % (i + 1, n_p, n_g))
????print('Model?Size:?%f?MB?parameters,?%f?MB?gradients
'?%?(n_p*4/1e6,?n_g*4/1e6))

`/*
輸入:imput[IC][IH][IW]
IC = input.channels
IH = input.height
IW = input.width
卷積核: kernel[KC1][KC2][KH][KW]
KC1 = OC
KC2 = IC
KH = kernel.height
KW = kernel.width
輸出:output[OC][OH][OW]
OC = output.channels
OH = output.height
OW = output.width
其中,padding = VALID,stride=1,
OH = IH - KH + 1
OW = IW - KW + 1
也就是先提前把Oh和Ow算出來(lái),然后將卷積核和輸入數(shù)據(jù)一一對(duì)應(yīng)即可
*/
for(int ch=0;ch










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論