 電子發(fā)燒友App
電子發(fā)燒友App


前言
如今的大模型被應(yīng)用在各個場景,其中有些場景則需要模型能夠支持處理較長文本的能力(比如8k甚至更長),其中已經(jīng)有很多開源或者閉源模型具備該能力比如GPT4、Baichuan2-192K等等。
那關(guān)于LLM的長文本能力,目前業(yè)界通常都是怎么做的?有哪些技術(shù)點或者方向?今天我們就來總結(jié)一波,供大家快速全面了解。
當(dāng)然也有一些關(guān)于LLM長文本的綜述,感興趣的小伙伴可以看看,比如:
《Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey》:https://arxiv.org/pdf/2311.12351.pdf
今天我們會從如下幾個層面進行介紹::數(shù)據(jù)層面、模型層面、評估層面。每個層面挑幾個還不錯的工作淺淺學(xué)一下業(yè)界都是怎么做的。
全文涉及較多工作,建議收藏,方便后續(xù)查詢細(xì)讀或者下載數(shù)據(jù)。
數(shù)據(jù)層面
LongAlpaca-12k
鏈接:https://huggingface.co/datasets/Yukang/LongAlpaca-12k
其是LongAlpaca-12k的一個工作,共收集了9k條長文本問答語料對,包含針對名著、論文、深度報道甚至財務(wù)報表的各類問答。
同時為了兼顧短文本能力,還從原有的Alpaca數(shù)據(jù)集中挑選了3k左右的短問答語料即最終構(gòu)建了12k。
LongQLoRA
鏈接:https://huggingface.co/datasets/YeungNLP/LongQLoRA-Dataset
其是LongQLoRA的一個工作,其開源了兩部分?jǐn)?shù)據(jù)一部分是54k的預(yù)訓(xùn)練數(shù)據(jù),一部分是39k的sft數(shù)據(jù)。
Ziya-Reader
鏈接:https://arxiv.org/abs/2311.09198
本篇paper主要貢獻是如何構(gòu)建長文本問答訓(xùn)練數(shù)據(jù),專注用于多文檔或單文檔問答,雖然訓(xùn)練數(shù)據(jù)沒有開源,但是做數(shù)據(jù)的方法我們可以學(xué)習(xí)一下
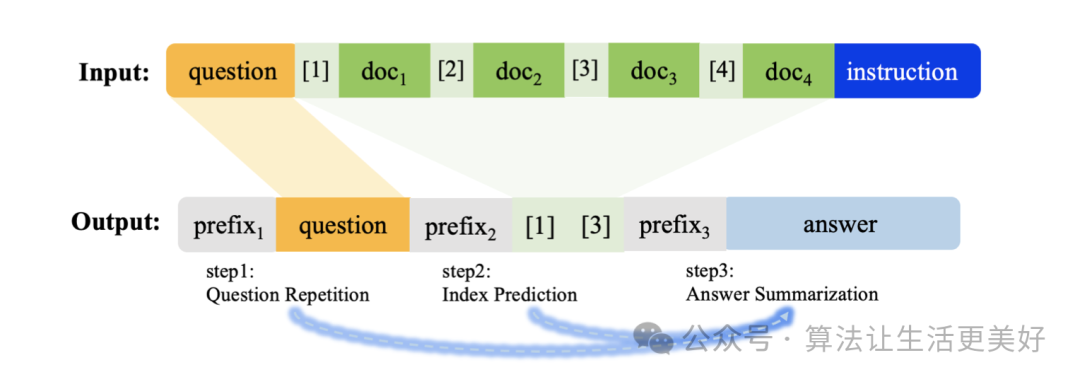
其主要借鑒cot的思路,在長文本問答領(lǐng)域也采用類cot,具體來說是:
(1)讓模型先對問題進行復(fù)述,這使得模型在看了一段非常長的上下文信息后,也不會因為距離衰減的原因忘記原始的提問,因而在生成回復(fù)時,更加能夠關(guān)注到問題。
(2)讓模型預(yù)測正確上下文段落的索引下標(biāo),通過這樣的方式可以讓模型更加關(guān)注正確的上下文段落。
(3)預(yù)測最終答案
可以看到(1)(2)就是作者采用的cot
除此之外之外,還構(gòu)建了一些負(fù)樣本,比如沒有正確上下文等等來增強模型的泛化性。
LongAlign
鏈接:https://huggingface.co/datasets/THUDM/LongAlign-10k
這篇工作主要聚焦做長文本的sft數(shù)據(jù),具體來說作者從9個不同的來源收集長篇文章后使用Claude 2.1根據(jù)給定的長篇背景生成任務(wù)和答案。
模型層面
模型層面主要是探索外推性,即如何確保在模型推理階段可以支持遠(yuǎn)遠(yuǎn)超過預(yù)訓(xùn)練的長度,其中限制外推的根本原因有兩個即在inference階段面對更長文本的時候,會出現(xiàn)更長的新位置編碼(相比訓(xùn)練)以及歷史上下文kv緩存過大這兩個根本難題。
為此目前的探索主要發(fā)力解決這兩個難題:(1)設(shè)計位置編碼;(2)動態(tài)設(shè)計局部注意力機制。下面我們逐個詳細(xì)看看~
(1)設(shè)計位置編碼
關(guān)于這部分推薦一篇博客:https://mp.weixin.qq.com/s/RtI95hu-ZLxGkdGuNIkERQ
大模型的位置編碼發(fā)展史: 絕對位置編碼 -> 相對位置編碼 -> 旋轉(zhuǎn)位置編碼。
其中絕對編碼的一個缺點是模型無法顯式的感知兩個token之間的相對位置,而后續(xù)的比如Sinusoidal相對位置編碼則通過正余弦函數(shù)實現(xiàn)了相對位置編碼,而旋轉(zhuǎn)位置編碼則實現(xiàn)了通過簡單的周期性旋轉(zhuǎn)將位置信息編入了進去。
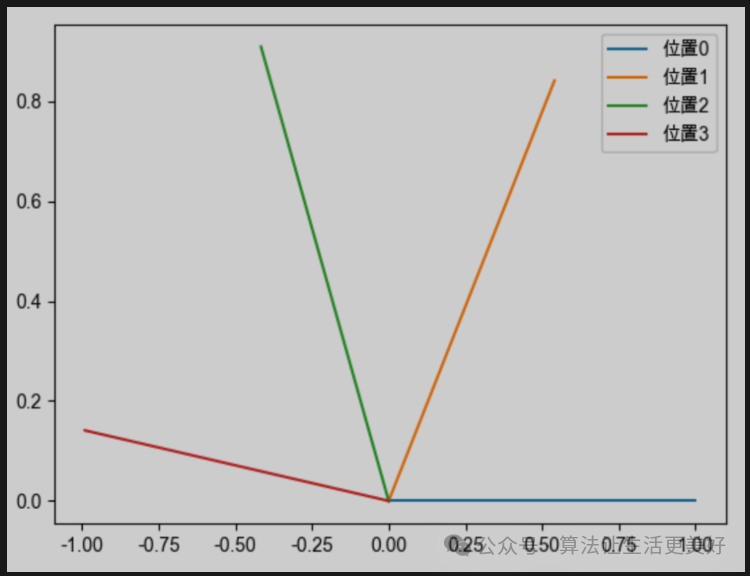
其中一個向量維度是d,越靠后的分組,它的旋轉(zhuǎn)速度越慢,正弦函數(shù)的周期越大、頻率越低。
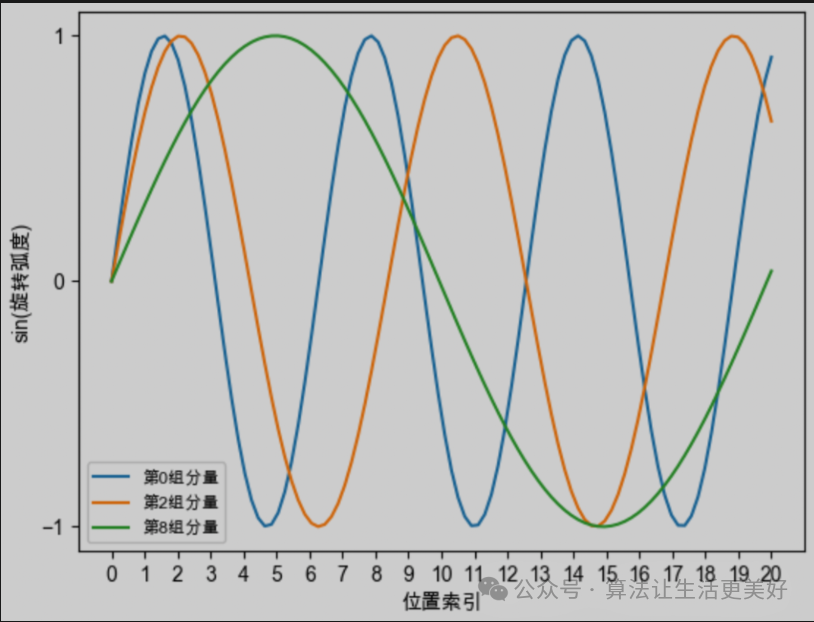
所以我們簡單總結(jié)一下旋轉(zhuǎn)位置編碼直觀的性質(zhì),他的核心是通過旋轉(zhuǎn)向量來將位置信息植入進來(非常巧妙,不需要其他什么復(fù)雜的改變,只需要旋轉(zhuǎn)向量就可以),具體的旋轉(zhuǎn)過程是:假設(shè)當(dāng)前向量是d維,那么就分為d/2個組,每個組進行各自的周期旋轉(zhuǎn),越靠后的分組,它的旋轉(zhuǎn)速度越慢,正弦函數(shù)的周期越大、頻率越低。
轉(zhuǎn)化為數(shù)學(xué)一點為:向量q(維度為d)在位置m時, 它的第i組(總共d/2個組)分量的旋轉(zhuǎn)弧度為
當(dāng)訓(xùn)練長度為L時,模型訓(xùn)練的時候只見過即,當(dāng)推理長度大于L時,模型不能cover新的旋轉(zhuǎn)弧度也即無法插入新的位置信息了。
知道了卡點,下面我們來看幾個相關(guān)的改進工作。
Position Interpolation
該方法為位置插值,思路也比較好的理解,既然超過L后的旋轉(zhuǎn)模型因為沒有見過就不能理解,那么我們就不超過,但是位置m還想擴大(比如一倍),那就可以通過縮小每個位置的旋轉(zhuǎn)弧度(讓向量旋轉(zhuǎn)得慢一些),每個位置的旋轉(zhuǎn)弧度變?yōu)樵瓉淼模@樣的話長度就可以擴大幾倍。具體的為:,這樣的話即保證了沒有超過訓(xùn)練的旋轉(zhuǎn)范圍,又插入更長或者更多的位置。
NTK-Aware Interpolation
該方法也是通過縮放,具體方法為如下:具體的是引入了一個縮放因子。
從數(shù)學(xué)角度看的話,Position Interpolation是將縮放因子放到了外面,而NTK是放到了里面(帶有指數(shù))。從直觀的理論上看Position Interpolation方法是對向量的所有分組進行同等力度地縮小,而NTK對于較前的分組(高頻分量)縮小幅度小,對于較后的分組(低頻分量)縮小幅度大。
這樣做的目的是靠前的分組,在訓(xùn)練中模型已經(jīng)見過很多完整的旋轉(zhuǎn)周期(因為旋轉(zhuǎn)速度很快,這個性質(zhì)之前已經(jīng)介紹過了),位置信息得到了充分的訓(xùn)練,所以已經(jīng)具有較強的外推能力。而靠后的分組,由于旋轉(zhuǎn)的較慢,模型無法見到完整的旋轉(zhuǎn)周期,或者見到的旋轉(zhuǎn)周期很少,外推性能就很差,需要進行位置插值。
NTK-by-parts Interpolation
這個方法就更直接了,直接一刀切,對于高頻分量就不縮小了(一點也不)即不進行插值,因為已經(jīng)具備外推性,而對于低頻分量由于訓(xùn)練沒見過完整旋轉(zhuǎn)周期所以外推性差,那就進行插值。相比于NTK-Aware Interpolation方法,這個方法更硬一些。
Dynamic NTK Interpolatio
NTK插值在超過訓(xùn)練長度L時表現(xiàn)還不錯,但是在訓(xùn)練長度內(nèi)反而表現(xiàn)較差,為此本方法實現(xiàn)了動態(tài)插值即當(dāng)inference的長度l在訓(xùn)練長度L內(nèi)就不進行插值,超過訓(xùn)練長度L才進行NTK-Aware Interpolation。
具體的縮小因子也是個動態(tài)值為:,其中l(wèi)隨著不斷生成不斷累加,是個動態(tài)值。
(2)動態(tài)設(shè)計局部注意力機制
在生成每一個token的時候,其實核心都是在計算attention score,那么就需要查詢之前token的kv值,為了提高效率,一般來說會把歷史的kv值都緩沖起來,這樣后續(xù)就可以快速用了,但問題是當(dāng)隨著長度增加時,內(nèi)存必然OOM。
知道了卡點,下面我們來看幾個相關(guān)的改進工作。
EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
論文鏈接:https://arxiv.org/pdf/2309.17453.pdf
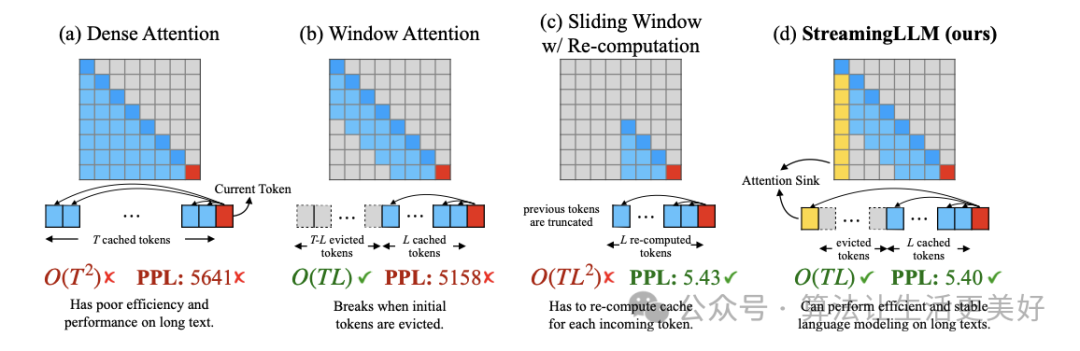
(a) 就是常規(guī)inference,可以看到不論是復(fù)雜度還是效果性能隨著長度增加,都會變得嚴(yán)峻。
(b) 就是常說的滑動窗口,核心方法就是每次只緩沖最近幾個token,這樣的話可以保證效率,但是當(dāng)文本變長后,性能會下降。
(c) 就是不緩沖,每次重新計算最近幾個token的,好處是保住了性能,但是效率也大大降低,因為每次都要重新計算
(d) 就是本文提出的方法,其通過觀察發(fā)現(xiàn)大量的注意力分?jǐn)?shù)被分配給初始token(即使這些token與語言建模任務(wù)沒有相關(guān)性),基于此作者沿用(b)的方法,只不過每次除了用緩沖的最近幾個token,額外再加上開頭的幾個token。
通過(d)方法最終實現(xiàn)了無限外推,該工作的代碼也已經(jīng)開源,star非常多,很受歡迎。
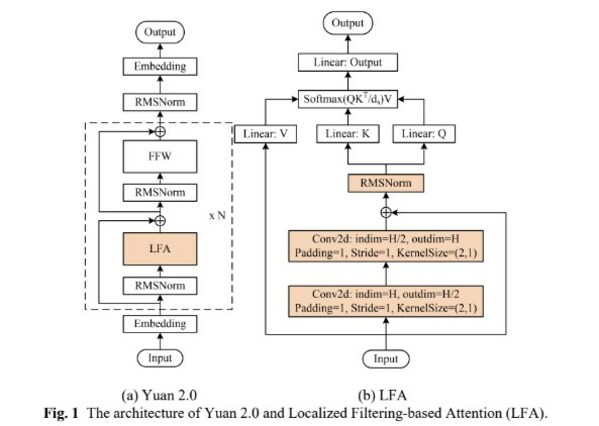
LONGLORA: EFFICIENT FINE-TUNING OF LONG- CONTEXT LARGE LANGUAGE MODELS
論文地址:https://browse.arxiv.org/pdf/2309.12307.pdf
本篇主要的貢獻在于開源了一個長文本訓(xùn)練數(shù)據(jù)(見上節(jié))以及提出了一個shift short attention
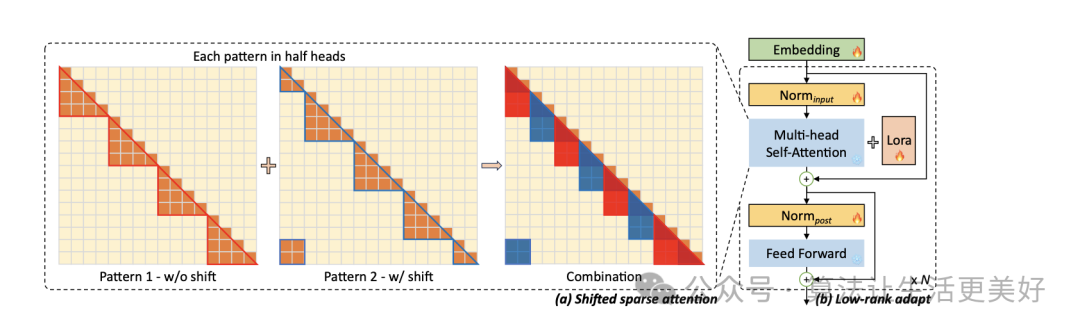
可以看到就是先分組(各個組內(nèi)進行self attention),只不過由于各個組由于之間沒有交互信息,導(dǎo)致效果變成,于是作者也采用滑窗口機制來緩解一下,即使用半組長度來滑,本質(zhì)上就是滑動窗口,只不過就是先分組再滑。
同時其支持lora訓(xùn)練,可快速訓(xùn)練適配部署自己的模型。
LONGQLORA: EFFICIENT AND EFFECTIVE METHOD TO EXTEND CONTEXT LENGTH OF LARGE LANGUAGE MODELS
論文地址:https://arxiv.org/pdf/2311.04879.pdf
其和上篇的LONGLORA大同小異,主要不同是替用qlora進行訓(xùn)練,更節(jié)省資源,同時另外一個貢獻就是開源了一個長文本數(shù)據(jù)集(見上節(jié))
Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon
論文地址:https://arxiv.org/pdf/2401.03462v1.pdf
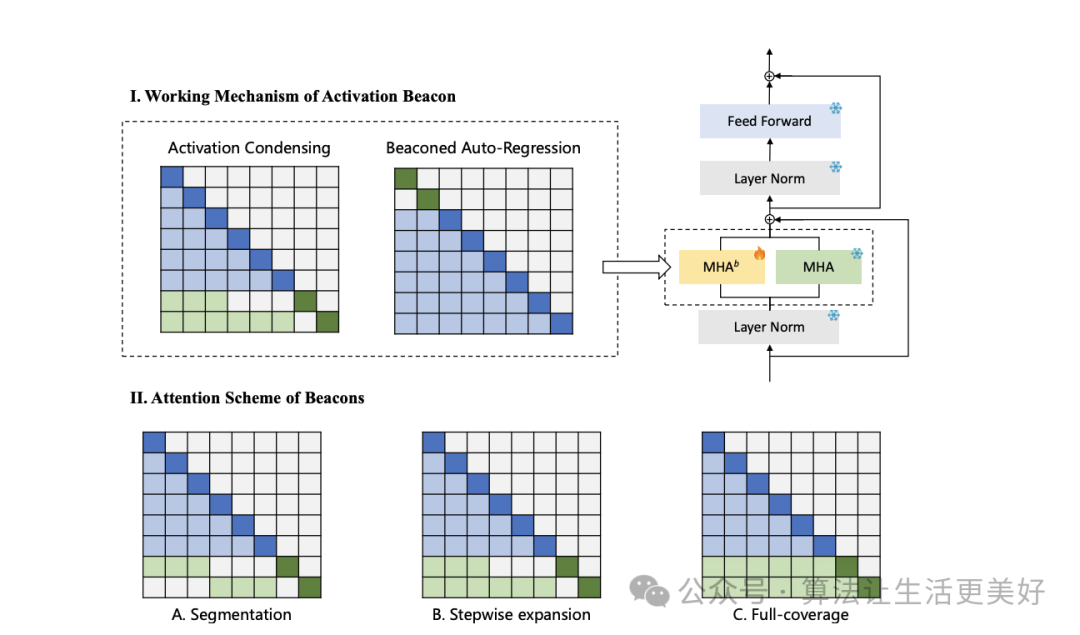
這篇論文的思路也很樸素:大的思路也是采用滑動窗口,只不過在怎么動態(tài)保存之前上下文的思路上采用的是壓縮思路,即前面信息既然太多,那就壓一壓。
具體的前面咱們介紹的EFFICIENT是通過每次滑的時候始終保留最前面幾個token,而本篇的思路就是把每個區(qū)間的信息(圖中藍色)壓縮成一個激活信標(biāo)(圖中綠色),而后面就用這些單個激活信標(biāo)來代表整個區(qū)間的信息。
那激活信標(biāo)怎么得到呢?作者也是采用了注意力機制,具體的探索了三種方法,一種是分段即每個信標(biāo)只用自己區(qū)間的信息(圖A),第二種是逐步分段即每個信標(biāo)可以關(guān)注比其前身多一個子區(qū)間(圖B),第三種是完全覆蓋,其中所有信標(biāo)都可以關(guān)注整個上下文(圖C)。這三種方法的計算成本相同。最后作者發(fā)現(xiàn)第二種最好。
有了信標(biāo)后,便可以將信標(biāo)和來自普通信息一起使用滑動窗口進行流式處理即每個滑動窗口由過去上下文區(qū)間的m個信標(biāo)和最新上下文區(qū)間的普通標(biāo)記組成。
評估層面
在迭代模型長文本能力的過程中,需要一個量化指標(biāo)來不斷指導(dǎo),目前業(yè)界已經(jīng)有一些評估,一起來看看吧~
ZeroSCROLLS
論文鏈接:https://arxiv.org/pdf/2305.14196.pdf
其由十個自然語言任務(wù)構(gòu)成,包括摘要、問答、聚合任務(wù)(給50條評論,讓模型預(yù)測正面評論的百分比)等等
longeval
論文鏈接:https://lmsys.org/blog/2023-06-29-longchat/
該工作通過設(shè)計topic和lines長文本記憶能力來測試模型的長文本能力。
L-Eval
論文鏈接:https://arxiv.org/pdf/2307.11088.pdf?
該工作從公開數(shù)據(jù)集收集數(shù)據(jù),然后手動過濾和校正,重新標(biāo)注得到。
LongBench
論文鏈接:https://arxiv.org/abs/2308.14508
該工作也是設(shè)計了單文檔問答、多文檔問答、摘要任務(wù)、Few-shot任務(wù)、合成任務(wù)、代碼補全等等
LooGLE
論文鏈接:https://arxiv.org/pdf/2311.04939.pdf
該工作從科學(xué)論文、維基百科文章、電影和電視中收集樣本,然后也是設(shè)計摘要等任務(wù)。
FinLongEval
論文鏈接:https://github.com/valuesimplex/FinLongEval
主要聚焦金融領(lǐng)域的長文本評測
總結(jié)
可以看到,在助力LLM長文本能力的道路上目前有兩個大的方向在發(fā)力:
(1)從數(shù)據(jù)入手即構(gòu)建做高質(zhì)量長文本數(shù)據(jù),這非常重要,因為有了數(shù)據(jù)才能訓(xùn)練,其中長文本預(yù)訓(xùn)練數(shù)據(jù)相對來說比較好找,但是sft數(shù)據(jù)就比較難了,并不是說強行cat起來就是有效長文本,比如把多個單輪文本cat到8k,但是這是一個偽多輪,對模型學(xué)習(xí)全局信息幫助很小;關(guān)于怎么構(gòu)建高質(zhì)量的長文本數(shù)據(jù)尤其是中文領(lǐng)域的數(shù)據(jù)還需要更多的探索,可以借鑒長文本評測任務(wù)來汲取靈感進行構(gòu)建訓(xùn)練數(shù)據(jù)。
(2)從模型層面入手進行外推,目前一個是探索位置編碼,另外一個就是探索怎么緩解kv緩沖也即兩個核心問題:第一就是尋找或設(shè)計合適的位置編碼;第二是設(shè)計局部注意力機制。其中第一個大的方向都是縮放即通過縮放將旋轉(zhuǎn)范圍依然縮放到和訓(xùn)練一致但實現(xiàn)了插入了更多的或者更長的位置,第二個大的方向基本都是探索怎么把之前的信息進行動態(tài)壓縮,更進一步這里的動態(tài)其實就是滑動,只不過在滑動上進行各種不同的邏輯。將兩個技術(shù)點(本來就是解決不同問題的)合理的結(jié)合也是很重要的。
總的來說,首先盡可能的收集準(zhǔn)備好高質(zhì)量的長文本訓(xùn)練數(shù)據(jù),然后在當(dāng)前資源下訓(xùn)練到最大長度,最后在推理時可以借助各種外推手段進行拓展。
審核編輯:黃飛
?























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論