 電子發燒友App
電子發燒友App


妙手、本手還是俗手?
昨夜,谷歌罕見地改變了去年堅持的“大模型閉源”策略,推出了“開源”大模型 Gemma。
Gemma 采用了與 Gemini 相同的技術,由谷歌 DeepMind 與谷歌其他團隊共同合作開發,在拉丁文中意為 “寶石”。
Gemma 包括兩種權重規模的模型:Gemma 2B 與 Gemma 7B,每種規模都有預訓練與指令微調版本。同時,谷歌還推出了一系列工具,旨在支持開發者創新,促進合作,并指導如何負責任地使用 Gemma 模型。
這樣一來,谷歌在大模型領域形成了雙線作戰——閉源領域對抗 OpenAI,開源領域對抗 Meta。
在人工智能領域,谷歌可以算是開源的鼻祖。今天幾乎所有的大語言模型,都基于谷歌在 2017 年發布的 Transformer 論文;谷歌的發布的 BERT、T5,都是最早的一批開源 AI 模型。
然而,自從 OpenAI 在 2022 年底發布閉源的 ChatGPT,谷歌也開始轉向閉源策略。此后,開源大模型被 Meta 的Llama 主導,后來被稱為“歐洲版 OpenAI”的法國開源大模型公司 Mistral AI 走紅,其 MoE 模型也被眾多 AI 公司追捧。
無論在閉源還是開源領域,有世界上最前沿技術儲備與人才儲備的谷歌,都沒能確立絕對的領先地位。
如今,閉源與開源雙線作戰,這是谷歌的妙手、本手還是俗手?
1.谷歌被迫開源?
?
谷歌開源大模型的發布時間,比 Meta 的 Llama 晚了整整一年。
對此,出門問問創始人李志飛表示:“相比于去年上半年就開源,現在可能要花數倍的努力進行模型的差異化以及推廣的投入、才有可能在眾多開源模型中脫穎而出。”
同時,李志飛認為谷歌的開源力度也不夠,還是被動防御和扭扭捏捏的應對之策,不是進攻。“比如說,開個7B的模型實在是太小兒科了,一點殺傷力都沒有。應該直接開源一個超越市場上所有開源的至少 100B 的模型、1M 的超長上下文、完善的推理 infra 方案、外加送一定的 cloud credit。是的,再不歇斯底里 Google 真的就晚了。面對 OpenAI 的強力競爭,只有殺敵一千、自損一千五。”
李志飛感覺,谷歌覺得自己還是 AI 王者,放不下高貴的頭顱,很多發布都有點不痛不癢,還是沿著過去研發驅動的老路而不是產品和競爭驅動,比如說不停發論文、取新名字(多模態相關模型過去半年就發了 Palme、rt-2、Gemini、VideoPoet、W.A.L.T 等等)、發布的模型又完整度不夠,感覺就沒有一個絕對能打的產品。谷歌可能要意識到在公眾眼中,他在 AI 領域已經是廉頗老矣潰不成軍,經常起大早趕晚集(比如說這次 Sora 借鑒的 ViT、ViViT、NaVit、MAGVit 等核心組件技術都是它家寫的論文)。
但作為前谷歌總部科學家,李志飛也希望谷歌希望亡羊補牢未為晚。他表示:“Google 作為一個僵化的大公司,動作慢一點可以理解,但是如果再不努力是不是就是 PC 互聯網的 IBM、移動互聯網的 Microsoft ? 作為 Google 的鐵粉,還是希望他能打起精神一戰,AI 產業需要強力的競爭才能不停往前發展,也需要他在前沿研究和系統的開源才能幫助一大眾貧窮的 AI 創業公司。”
另一位 AI 專家——微博新技術研發負責人張俊林認為,谷歌重返開源賽場,這是個大好事,但很明顯是被迫的。
張俊林表示:“去年 Google 貌似已經下定決心要閉源了,這可能源于低估了追趕 OpenAI 的技術難度,Bard 推出令人大失所望使得谷歌不得不面對現實,去年下半年進入很尷尬的局面,閉源要追上 OpenAI 估計還要不少時間,而開源方面 Meta 已下決心,還有 Mistral 這種新秀冒頭,逐漸主導了開源市場。這導致無論開源閉源,谷歌都處于被兩面夾擊,進退為難的境地。”
很明顯,Gemma 代表谷歌大模型策略的轉變:兼顧開源和閉源,開源主打性能最強大的小規模模型,希望腳踢 Meta 和 Mistral;閉源主打規模大的效果最好的大模型,希望盡快追上 OpenAI。
大模型到底要做開源還是閉源?
張俊林的判斷是,如果是做當前最強大的大模型,目前看還是要拼模型規模,這方面開源模型相對閉源模型處于明顯劣勢,短期內難以追上 GPT-4 或 GPT-4V。而且這種類型的大模型,即使是開源,也只能仰仗谷歌或者 Meta 這種財大氣粗的大公司,主要是太消耗資源了,一般人玩不起。國內這方面阿里千問系列做得比較好,肯把比較大規模的模型開源出來,當然肯定不是最好的,不過這也很難得了。
而在開源領域,張俊林的判斷是應該把主要精力放在開發并開源出性能足夠強的“小規模大模型”上(SLLM,Small Large Language Model),因此谷歌的開源策略是非常合理的。
目前看,作出強大的 SLLM 并沒有太多技巧,主要是把模型壓小的基礎上,大量增加訓練數據的規模,數據質量方面則是增加數學、代碼等數據來提升模型的推理能力。比如 Gemma 7B 用 6 萬億 Token 數據,外界猜測 Mistral 7B 使用了 7 萬億 Token 數據,兩者也應該大量采用了增強推理能力的訓練數據。
所以 SLLM 模型的性能天花板目前也沒有到頭,只要有更多更高質量的數據,就能持續提升 SLLM 模型的效果,仍然有很大空間。
而且 SLLM 相對 GPT-4 這種追求最強效果的模型比,訓練成本低得多,而因為模型規模小,推理成本也極低,只要持續優化效果,從應用層面,大家肯定會比較積極地部署 SLLM 用來實戰的,市場潛力巨大。也就是說,SLLM 應該是沒有太多資源,但是還是有一些資源的大模型公司必爭之地。
張俊林相信,2024 年開源 SLLM 會有黑馬出現。
2.大模型打壓鏈
?
從今天起,Gemma 在全球范圍內開放使用。該模型的關鍵細節如下:
發布了兩種權重規模的模型:Gemma 2B 和 Gemma 7B。每種規模都有預訓練和指令微調版本。
新的 Responsible Generative AI Toolkit 為使用 Gemma 創建更安全的 AI 應用程序提供指導和必備工具。
通過原生 Keras 3.0 為所有主要框架(JAX、PyTorch 和 TensorFlow)提供推理和監督微調(SFT)的工具鏈。 ?
上手即用 Colab 和 Kaggle notebooks,以及與 Hugging Face、MaxText 和 NVIDIA NeMo 等受歡迎的工具集成,讓開始使用 Gemma 變得簡單容易。
經過預訓練和指令微調的 Gemma 模型可以在筆記本電腦、工作站或 Google Cloud 上運行,并可輕松部署在 Vertex AI 和 Google Kubernetes Engine(GKE)上。
基于多個 AI 硬件平臺進行優化,其中包括 NVIDIA GPUs 和 Google Cloud TPUs。
使用條款允許所有組織(無論規模大小)負責任地進行商用和分發。
Gemma 是開源領域一股不可忽視的力量。根據谷歌給出的數據,性能超越 Llama 2。 ?
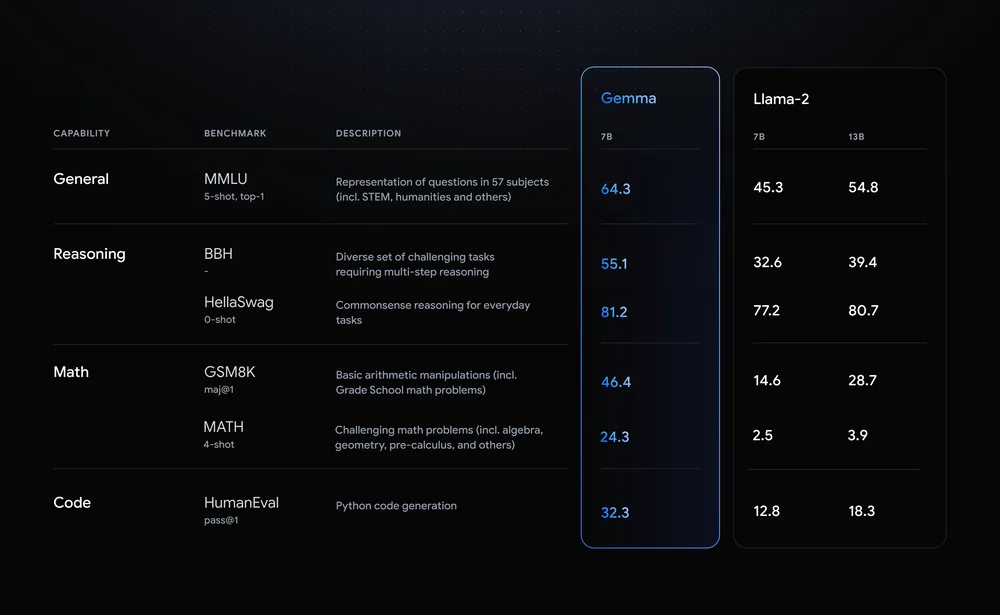
圖片來自谷歌
至此,大模型開源形成三巨頭局面:谷歌 Gemma、Meta LLama 和歐洲的 Mistral。 ? 張俊林認為,大模型巨頭混戰形成了打壓鏈局面:OpenAI 處于鏈條頂端,主要打壓對手是有潛力追上它的競爭對手:谷歌和 Anthropic,Mistral 估計也正在被列入 OpenAI 的打壓列表中。打壓鏈條為:OpenAI→Google &Anthropic & Mistral→ Meta→其它大模型公司。 ? 比如,谷歌上周發布的 Gemini 1.5 Pro 就是一個有代表性的案例,本身模型實例很強大,但在宣發策略上被 Sora 打到啞火;前年年底發布的 ChatGPT 也是臨時趕工出來打壓 Anthropic 的 Claude 模型的。 ?
張俊林對此判斷:“OpenAI 應該儲備了一個用于打壓對手的技術儲備庫,即使做得差不多了也隱而不發,專等競爭對手發布新產品的時候扔出來,以形成宣傳優勢。如果 OpenAI 判斷對手的產品對自己的威脅越強,就越可能把技術儲備庫里最強的扔出來,比如 ChatGPT 和 Sora,都是大殺器級別的,這也側面說明 OpenAI 比較認可 Gemini 1.5 和 Claude 的實力。而這種打壓策略很明顯還會繼續下去,以后我們仍然會經常看到類似的情景,不巧的是,可能其它公司比如谷歌也學會這招了,估計也很快會傳導到國內大模型公司范圍里。所以 2024 年會比較熱鬧,估計會有不少大戲上演。” ? 谷歌開源 Gemma 很明顯是針對 Meta 和 Mistral 而來。張俊林據此推測,Meta 的 LLama 3 很快就要發布了,或者Mistral 最近會有新品發布。
審核編輯:黃飛
?














 工商網監
工商網監
評論