 電子發(fā)燒友App
電子發(fā)燒友App


摘要:Transformers已成為大型語言模型(LLM)的支柱。然而,由于需要在內(nèi)存中存儲過去標(biāo)記的鍵值表示緩存,其大小與輸入序列長度和批量大小成線性比例,因此生成效率仍然很低。作為解決方案,我們提出了動態(tài)內(nèi)存壓縮(DMC),這是一種在推理時在線壓縮鍵值緩存的方法。最重要的是,該模型可以學(xué)習(xí)在不同的頭和層中應(yīng)用不同的壓縮率。我們將預(yù)訓(xùn)練的 LLM(如 Llama 2(7B、13B 和 70B))改裝成 DMC Transformers,在英偉達 H100 GPU 上實現(xiàn)了高達 ~3.7 倍的自動回歸推理吞吐量提升。DMC 通過持續(xù)預(yù)訓(xùn)練應(yīng)用于可忽略不計的原始數(shù)據(jù)百分比,而不添加任何額外參數(shù)。我們發(fā)現(xiàn),DMC 保持了原有的下游性能,緩存壓縮率高達 4 倍,優(yōu)于向上訓(xùn)練的分組查詢注意(GQA)。GQA 和 DMC 甚至可以結(jié)合使用,以獲得復(fù)合增益。因此,在任何給定的內(nèi)存預(yù)算內(nèi),DMC 都能適應(yīng)更長的上下文和更大的批次。
Q1: 這篇論文試圖解決什么問題?
A:這篇論文提出了一種名為動態(tài)內(nèi)存壓縮(Dynamic Memory Compression,簡稱DMC)的方法,旨在解決大型語言模型(Large Language Models,簡稱LLMs)在推理(inference)階段的內(nèi)存效率和生成效率問題。具體來說,論文關(guān)注的問題包括:
內(nèi)存消耗:在自回歸生成過程中,Transformer模型需要在內(nèi)存中存儲過去token的鍵值(key-value)表示,這些表示的內(nèi)存消耗與輸入序列長度和批量大小線性相關(guān),導(dǎo)致內(nèi)存負載隨序列長度增加而迅速增長。
生成效率:由于上述的內(nèi)存消耗問題,使用Transformer模型進行長序列生成(如對話和故事生成)或同時服務(wù)大量用戶查詢時,會變得非常低效,因為內(nèi)存限制了批量大小和序列長度。
現(xiàn)有解決方案的局限性:雖然已有一些方法(如Grouped Query Attention,GQA)通過減少內(nèi)存中的token數(shù)量來提高Transformer模型的內(nèi)存效率,但這些方法往往會犧牲下游任務(wù)的性能。
為了解決這些問題,論文提出了DMC方法,它允許模型在推理時動態(tài)地壓縮鍵值緩存,并且能夠?qū)W習(xí)在不同頭(heads)和層(layers)中應(yīng)用不同的壓縮率。這種方法旨在在不增加額外參數(shù)的前提下,通過少量的繼續(xù)預(yù)訓(xùn)練(continued pre-training)來實現(xiàn),從而在保持原有下游性能的同時,顯著提高模型的內(nèi)存效率和生成速度。
Q2: 有哪些相關(guān)研究?
A:這篇論文提到了與動態(tài)內(nèi)存壓縮(DMC)相關(guān)的幾個研究領(lǐng)域和具體工作,包括:
Transformer模型和大型語言模型(LLMs):Transformer作為LLMs的骨干網(wǎng)絡(luò)結(jié)構(gòu),是當(dāng)前生成式和對話式AI的最新進展。例如,Touvron et al. (2023) 和 Jiang et al. (2023) 等人的工作展示了LLMs在各種任務(wù)上的應(yīng)用。
內(nèi)存效率的Transformer變體:為了提高Transformer在推理階段的內(nèi)存效率,研究者們提出了多種方法,如Grouped Query Attention (GQA),它通過參數(shù)共享減少鍵值頭的數(shù)量。其他方法包括token合并和token剪枝,但這些方法往往會犧牲性能。
硬件/IO感知和子二次方算法:Dao et al. (2022) 和 Kwon et al. (2023) 等人的研究關(guān)注于如何使注意力機制更加高效,但這些方法并沒有直接減輕鍵值緩存的內(nèi)存負擔(dān)。
動態(tài)壓縮方法:Anagnostidis et al. (2023) 和 Kim & Cho (2020) 等人提出了動態(tài)壓縮方法,這些方法在推理時決定哪些token應(yīng)該從鍵值緩存中丟棄。與DMC不同,這些方法通過丟棄token來減少內(nèi)存消耗,而不是合并它們。
非學(xué)習(xí)型緩存驅(qū)逐策略:Zhang et al. (2023) 和 Sheng et al. (2023) 等人研究了基于啟發(fā)式的緩存驅(qū)逐策略,這些策略不依賴于額外的訓(xùn)練,但缺乏學(xué)習(xí)壓縮機制的能力。
動態(tài)令牌池:Nawrot et al. (2022) 提出了動態(tài)令牌池(Dynamic Token Pooling),這是一種在中間層對token表示進行合并的方法,DMC在這一基礎(chǔ)上進行了改進,將其應(yīng)用于KV緩存,并在訓(xùn)練期間引入了池化決策的連續(xù)放松。
這些相關(guān)研究為DMC的提出提供了背景和對比,DMC通過在保持原有模型性能的同時減少內(nèi)存消耗,為提高大型語言模型的推理效率提供了一種新的解決方案。
Q3: 論文如何解決這個問題?

 A:論文提出了一種名為動態(tài)內(nèi)存壓縮(Dynamic Memory Compression,DMC)的方法來解決大型語言模型(LLMs)在推理階段的內(nèi)存效率和生成效率問題。具體解決方案包括以下幾個關(guān)鍵步驟:
A:論文提出了一種名為動態(tài)內(nèi)存壓縮(Dynamic Memory Compression,DMC)的方法來解決大型語言模型(LLMs)在推理階段的內(nèi)存效率和生成效率問題。具體解決方案包括以下幾個關(guān)鍵步驟:
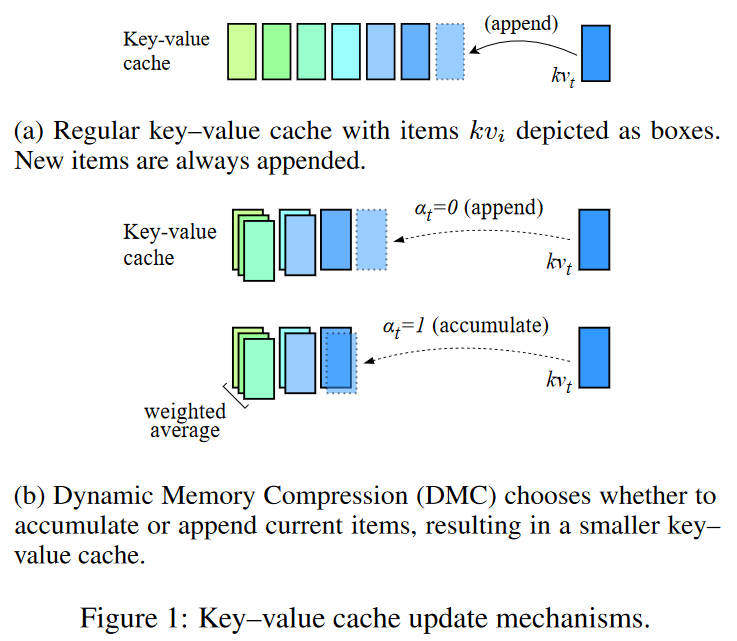
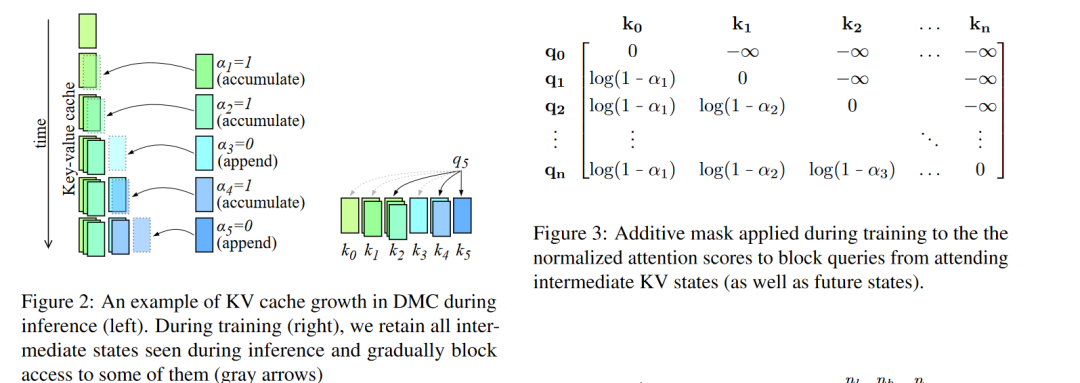
在線鍵值緩存壓縮:DMC在自回歸推理過程中動態(tài)地決定是否將當(dāng)前的鍵(key)和值(value)表示追加到緩存中,或者與緩存中的頂部元素進行加權(quán)平均。這種機制允許模型根據(jù)輸入序列的當(dāng)前部分來調(diào)整緩存的大小。
端到端學(xué)習(xí):DMC通過在繼續(xù)預(yù)訓(xùn)練(continued pre-training)過程中逐漸增加全局壓縮率(global Compression Ratio,CR),讓模型學(xué)習(xí)如何應(yīng)用不同的壓縮策略。這個過程不需要引入額外的參數(shù)。
分段機制:DMC通過一個決策變量(α)來有效地對輸入序列進行分段,每個段落可以獨立地決定是繼續(xù)追加還是進行累積。這允許模型在不同段落之間動態(tài)調(diào)整內(nèi)存使用。
重要性評分:DMC還引入了一個重要性變量(ω),用于在累積操作中計算當(dāng)前token與緩存頂部元素的加權(quán)平均,這樣模型可以學(xué)習(xí)保留更重要的信息。
訓(xùn)練策略:為了訓(xùn)練DMC模型,論文提出了一種隨機重參數(shù)化(stochastic reparametrization)的方法來處理離散的決策變量,以及一種中間壓縮步驟(intermediate compression steps)來處理連續(xù)的α值。此外,還設(shè)計了一個全局一邊損失(global one-sided loss)來激勵模型達到目標(biāo)壓縮率。
實際考慮:為了在不使用填充張量(padded tensors)的情況下實現(xiàn)變長緩存,論文提供了一個基于PyTorch的自定義注意力機制實現(xiàn),該實現(xiàn)允許不同的頭學(xué)習(xí)不同的壓縮率,同時避免了填充的需要。
通過這些方法,DMC能夠在保持原有LLMs性能的同時顯著提高內(nèi)存效率和推理速度,使得模型能夠適應(yīng)更長的上下文和更大的批量大小,同時減少內(nèi)存消耗。論文通過在不同規(guī)模的Llama 2模型上進行實驗,證明了DMC的有效性。
Q4: 論文做了哪些實驗?
A:論文中進行了一系列實驗來驗證動態(tài)內(nèi)存壓縮(DMC)方法的有效性和效率。以下是實驗的主要內(nèi)容:
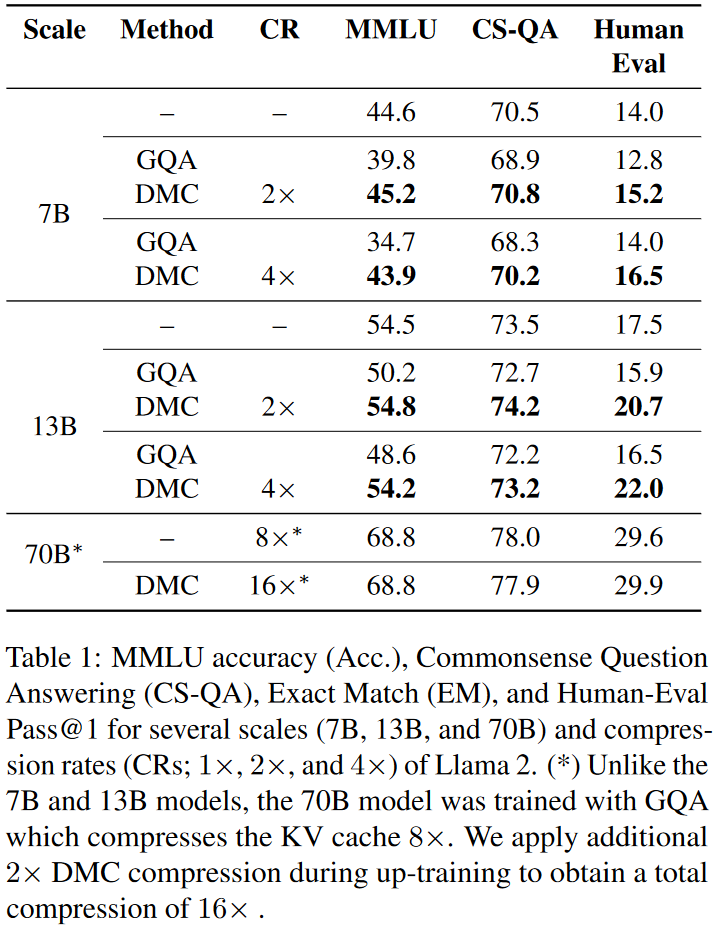
基線模型:選擇了不同規(guī)模的Llama 2模型(7B、13B和70B)作為基線模型,并與原始模型進行了比較。
壓縮率(CR)目標(biāo):針對不同的壓縮率(2×、3×和4×)訓(xùn)練DMC模型,并通過繼續(xù)預(yù)訓(xùn)練(continued pre-training)逐步增加壓縮率。
性能評估:在多個下游任務(wù)上評估DMC模型的性能,包括MMLU(用于事實性)、QA數(shù)據(jù)集(用于常識推理)和HumanEval(用于代碼生成)。
與GQA的比較:將DMC與Grouped Query Attention(GQA)進行比較,GQA是一種廣泛使用的減少KV緩存大小的方法。
樣本效率:比較DMC和GQA在不同壓縮率下的樣本效率,即在達到相同性能時所需的訓(xùn)練步驟數(shù)量。
吞吐量和延遲測量:使用NVIDIA Megatron-LM框架在NVIDIA A100和H100 GPU上測量DMC模型的推理吞吐量和延遲,以評估其在實際硬件上的性能提升。
每層和每頭的壓縮率分析:分析DMC模型在不同層和頭中學(xué)習(xí)到的壓縮率分布,以了解模型如何動態(tài)調(diào)整壓縮策略。
訓(xùn)練策略的消融研究:研究不同的訓(xùn)練策略(如不同的目標(biāo)CR調(diào)度和訓(xùn)練步驟數(shù))對DMC模型性能的影響。
DMC變體的評估:評估DMC的一個變體(DMC-C),它強制在同一層中的頭保持相似的壓縮率,以減少填充并比較其與標(biāo)準(zhǔn)DMC的性能差異。
這些實驗結(jié)果表明,DMC模型能夠在保持或甚至提高原始模型下游任務(wù)性能的同時,顯著提高推理效率,減少內(nèi)存消耗,并允許更大的批量大小和更長的序列處理。此外,DMC模型還能夠與GQA結(jié)合使用,以獲得更高的壓縮率和進一步的性能提升。
Q5: 有什么可以進一步探索的點?
A:盡管論文提出了一種有效的動態(tài)內(nèi)存壓縮(DMC)方法并進行了廣泛的實驗驗證,但仍有一些潛在的研究方向和可以進一步探索的點:
不同模型架構(gòu)的適用性:研究DMC方法在不同類型的Transformer模型或其他序列處理模型中的應(yīng)用,例如BERT、GPT、T5等。
從頭開始訓(xùn)練的模型:探索在模型預(yù)訓(xùn)練階段直接集成DMC機制的可能性,而不是僅在預(yù)訓(xùn)練模型上進行改造。
更深層次的解釋性分析:對DMC模型學(xué)習(xí)到的壓縮模式進行更深入的分析,以理解模型如何根據(jù)輸入序列的不同特征進行壓縮。
壓縮策略的優(yōu)化:研究是否可以進一步優(yōu)化壓縮策略,以提高內(nèi)存效率和推理速度,同時保持或提高模型性能。
長序列和復(fù)雜任務(wù)的性能:在更長的序列和更復(fù)雜的任務(wù)上評估DMC模型的性能,以測試其在實際應(yīng)用中的有效性。
不同硬件配置下的性能:在不同的硬件配置上測試DMC模型,包括CPU、不同的GPU型號以及其他加速器,以評估其通用性和可擴展性。
實時或在線生成場景:研究DMC在實時或在線生成場景中的應(yīng)用,例如聊天機器人、語音識別和翻譯系統(tǒng)。
環(huán)境影響和能效:評估DMC在減少計算資源消耗和降低環(huán)境影響方面的潛力,特別是在大規(guī)模AI模型訓(xùn)練和部署中。
與其他技術(shù)的結(jié)合:探索將DMC與其他模型壓縮和效率提升技術(shù)(如量化、剪枝、知識蒸餾等)結(jié)合使用的可能性。
開源實現(xiàn)和社區(qū)貢獻:鼓勵開源DMC的實現(xiàn),并與研究社區(qū)合作,以促進方法的改進和應(yīng)用。
這些潛在的研究方向可以幫助進一步提升DMC方法的性能和實用性,同時為大型語言模型的高效推理提供新的思路。
Q6: 總結(jié)一下論文的主要內(nèi)容?
A:這篇論文的主要內(nèi)容可以總結(jié)如下:
背景: 大型語言模型(LLMs)如Transformer在生成任務(wù)中表現(xiàn)出色,但在推理階段存在內(nèi)存消耗大和生成效率低的問題,因為需要存儲過去token的鍵值(key-value)表示。
問題: 隨著輸入序列長度的增加,鍵值緩存的大小線性增長,導(dǎo)致內(nèi)存消耗和生成延遲增加,限制了模型在長序列生成和高并發(fā)查詢場景中的應(yīng)用。
方法: 提出了動態(tài)內(nèi)存壓縮(DMC),一種在推理時在線壓縮鍵值緩存的方法。DMC允許模型根據(jù)輸入序列動態(tài)決定是追加新的鍵值表示到緩存中,還是與緩存中的頂部元素進行加權(quán)平均。
實現(xiàn): 通過在原有預(yù)訓(xùn)練模型上進行少量的繼續(xù)預(yù)訓(xùn)練,DMC能夠在不增加額外參數(shù)的情況下學(xué)習(xí)不同的壓縮策略,實現(xiàn)高達4倍的緩存壓縮。
實驗: 在不同規(guī)模的Llama 2模型上進行實驗,包括7B、13B和70B版本,評估了DMC在多個下游任務(wù)上的性能,如MMLU、QA數(shù)據(jù)集和HumanEval。
結(jié)果: DMC在保持或提高原始模型性能的同時,顯著提高了推理速度和內(nèi)存效率。與Grouped Query Attention(GQA)相比,DMC展現(xiàn)了更高的性能和樣本效率。
結(jié)論: DMC是一種有效的技術(shù),可以加速大型語言模型的推理過程,減少內(nèi)存消耗,并允許模型處理更長的上下文和更大的批量大小。此外,DMC的壓縮策略可以與GQA結(jié)合,實現(xiàn)進一步的性能提升。
未來工作: 論文提出了一些潛在的研究方向,包括將DMC應(yīng)用于不同的模型架構(gòu)、在預(yù)訓(xùn)練階段集成DMC、以及在不同硬件配置下測試DMC的性能。
審核編輯:黃飛
?














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論