 電子發(fā)燒友App
電子發(fā)燒友App


01. 介紹
摘要:存內(nèi)計算(CiM)已成為一種極具吸引力的解決方案,用于緩解馮-諾依曼體系結(jié)構(gòu)中高昂的數(shù)據(jù)搬運成本。CiM 可以在內(nèi)存中執(zhí)行大規(guī)模并行通用矩陣乘法(GEMM)運算,這是機器學(xué)習(xí)(ML)推理中的主要計算。
然而,將存儲器重新用于計算提出了以下關(guān)鍵問題:1)使用哪種類型的 CiM:鑒于模擬和數(shù)字的 CiM 種類繁多,需要從系統(tǒng)角度確定它們的適用性。2) 何時使用 CiM:ML 推理包括具有各種內(nèi)存和計算要求的工作負載,因此很難確定 CiM 何時比標準處理內(nèi)核更有優(yōu)勢。3) 在哪里集成 CiM:。每個內(nèi)存級別具有不同的帶寬和容量,這會影響到集成CiM帶來的數(shù)據(jù)傳輸和局部性優(yōu)勢。
在本文中,我們將探討如何回答這些有關(guān) CiM 集成用于 ML 推理加速的問題。我們使用 Timeloop-Accelergy [1]、[2] 對 CiM 原型(包括模擬和數(shù)字基本運算單元)進行早期系統(tǒng)級評估。我們將 CiM 集成到類似 Nvidia A100 的基線架構(gòu)中的不同級別的高速緩沖存儲器,并為各種 ML 工作負載定制數(shù)據(jù)流。我們的實驗展示了CiM 體系架構(gòu)提高了能效,在 具有INT-8 精度的情況下,實現(xiàn)了能效比既定基線架構(gòu)低 0.12 倍,在具有權(quán)重交錯和重復(fù)的情況下,實現(xiàn)了高達 4 倍的性能提升。所提出的工作有助于深入了解應(yīng)使用哪種類型的 CiM,何時以及在緩存層次結(jié)構(gòu)中的哪個位置最優(yōu)地集成它以加速GEMM運算。
機器學(xué)習(xí)(ML)應(yīng)用已經(jīng)在汽車、醫(yī)療保健、金融和技術(shù)等各個領(lǐng)域變得無處不在。這導(dǎo)致對高性能、高能效 ML 硬件解決方案的需求不斷增加。
矩陣-向量乘法和通用矩陣-矩陣乘法(稱為 GEMM)是卷積網(wǎng)絡(luò)和transformers網(wǎng)絡(luò)等 ML 工作負載的核心[3]、[4]。
由于此類計算是數(shù)據(jù)密集型,它們會產(chǎn)生很高的能耗成本,尤其是在諸如中央處理器(CPU)和圖形處理器(GPU)等馮-諾依曼架構(gòu)的計算處理器。而造成這種高能耗成本的原因是,在此類架構(gòu)中,計算處理單元與存儲單元分離,導(dǎo)致處理單元與存儲器之間的存儲器訪問和數(shù)據(jù)移動成本高昂,這就是通常所說的 “存儲墻 ”或 “馮-諾依曼瓶頸”。
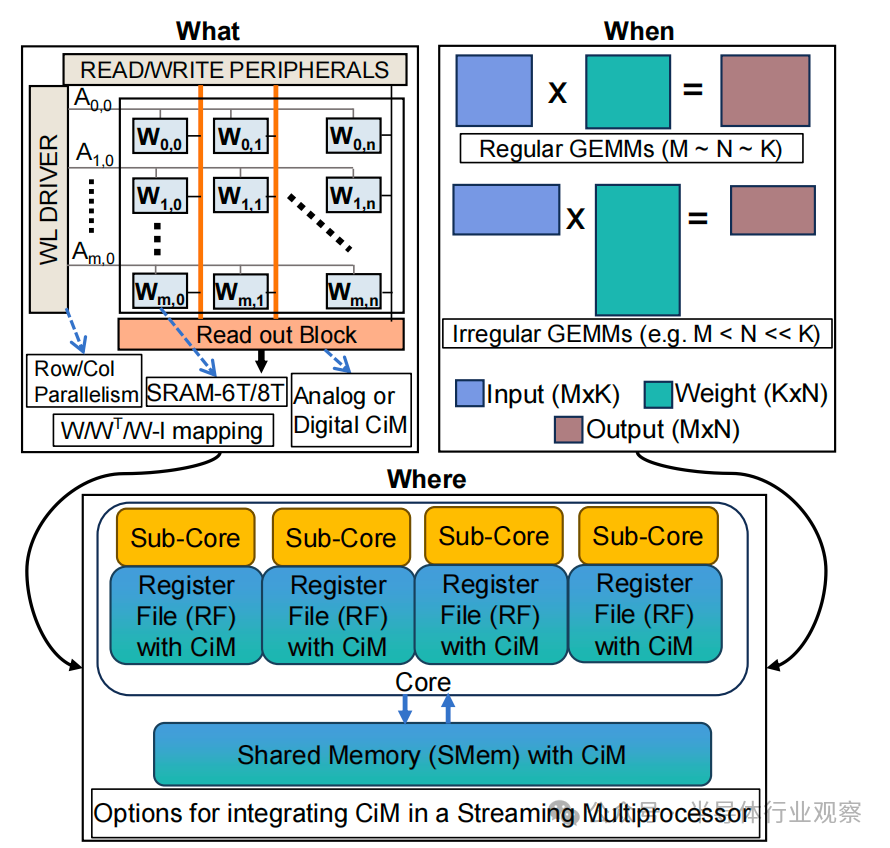 圖 1. 概覽圖顯示,要實現(xiàn)最佳的 ML 推理加速,需要了解各種 CiM 類型(What)、GEMM 形狀(When)和內(nèi)存級別(Where)的不同特性。
圖 1. 概覽圖顯示,要實現(xiàn)最佳的 ML 推理加速,需要了解各種 CiM 類型(What)、GEMM 形狀(When)和內(nèi)存級別(Where)的不同特性。
[5]。 為解決這一問題,人們提出了存內(nèi)計算(CiM)范式,通過在內(nèi)存中直接執(zhí)行計算,以降低昂貴的數(shù)據(jù)移動成本,并提供高能效比解決方案[6], [7]。
將 CiM 集成到跨存儲器層級的方法有很多:從 CMOS 片上高速緩沖存儲器到 DRAM 或閃存 [8]-[10]。在這項工作中,我們重點關(guān)注在片上存儲子系統(tǒng)中添加 CiM,因為這不需要激進極端的技術(shù)變革。雖然將 CiM 集成到緩存中的研究已經(jīng)展開[11]-[13],但在系統(tǒng)層面對不同類型的 CiM 基元(或設(shè)計)的有效性,尤其是對 ML 推理的有效性進行全面評估的研究仍有待進行。我們的工作探索了在 GPU 的流式多處理器(SM)中將 CiM 集成到不同高速緩存級別、寄存器文件(RF)和共享內(nèi)存(SMem)的好處(圖 1)。GPU 由數(shù)百個 SM 組成,這些 SM 通過大型交叉條互連并通過L2級存儲連接到 DRAM [14]。為了在存儲器子系統(tǒng)中有效利用 CiM,需要確定 CiM 的最佳類型、何時使用以及在何處使用,以便進行 ML 推理。
什么類型的 CiM:根據(jù)計算類型,CiM 大致可分為模擬和數(shù)字計算兩種 [15]-[21]。模擬 CiM 在存儲器陣列內(nèi)的模擬/混合信號域中執(zhí)行乘法和累加(MAC)運算操作。為了實現(xiàn)不同 CiM 塊之間的通信,需要使用數(shù)模轉(zhuǎn)換器 (DAC) 和模數(shù)轉(zhuǎn)換器 (ADC) 之類的外圍電路,以減少模擬噪聲對計算的影響。ADC 通常具有較高的面積、延遲和能耗成本,從而增加了整體模擬 CiM 的開銷。相比之下,數(shù)字 CiM 通過執(zhí)行比特逐位與/異或以及乘法運算,在數(shù)字域中執(zhí)行所有計算。為了計算最終的 MAC 輸出,需要執(zhí)行多逐位操作,這可能會增加數(shù)字 CiM 的計算延遲。此外,存儲器單元的類型(SRAM-6T/8T)、一次啟用的字線或位線的數(shù)量以及存儲器陣列中權(quán)重的映射方案等設(shè)計選擇,也使得確定系統(tǒng)中最有效的 CiM 基本運算單元變得越來越具有挑戰(zhàn)性。
何時使用 CiM:ML 模型由各種 GEMM 的形狀和大小組成。GEMM (M × N × K) 計算可視為將大小為 M × K 的輸入矩陣與大小為 K × N 的權(quán)重矩陣相乘,得到大小為 M × N 的輸出矩陣[22]。通過計算算術(shù)運算(浮點運算或 FLOPs)與內(nèi)存訪問(字節(jié)數(shù))的比率,算術(shù)強度或數(shù)據(jù)復(fù)用可以了解 GEMM 計算對內(nèi)存的依賴程度。圖 2 顯示了 GEMM 性能與算術(shù)運算強度之間的屋頂線表示。該圖表明 并非所有的 GEMM 都需要 GPU 的全部功能,從而導(dǎo)致 SM 利用率不足。當采用 CiM 進行 GEMM 計算時,它有可能保持與標準計算范式相當?shù)男阅堋?) GEMM 對計算和內(nèi)存的要求范圍很廣。因此,目前還不清楚 CiM 在能耗和性能方面的優(yōu)勢何時會高于基線。
在何處集成CiM:由于 GEMM 具有規(guī)則的數(shù)據(jù)訪問模式,并提供較高的時間局部性和空間局部性,因此矩陣以塊或更小的tile為單位從主存儲器獲取到高速緩存中[23]。通常情況下,GPU 會優(yōu)化其內(nèi)存層次結(jié)構(gòu),以高效地重復(fù)使用tile數(shù)據(jù),并在 SM 的子核中的數(shù)百個張量核上并行執(zhí)行 GEMM 操作。基于 CiM 的硬件設(shè)計也能通過在內(nèi)存陣列內(nèi)啟用多列和多行以及利用多個內(nèi)存陣列的并行性來執(zhí)行并行矩陣乘法。然而,每個內(nèi)存層級在帶寬和存儲容量方面都有所不同(表五),這影響了數(shù)據(jù)復(fù)用機會以及重新利用 CiM 功能時的計算并行性。因此,找到一個能很好地利用局部性并提供最高 CIM 效益的內(nèi)存級至關(guān)重要。
我們的方法為了充分利用和評估 CiM 相對于通用處理器的優(yōu)勢,我們考慮了一系列工作負載規(guī)格、內(nèi)存級別和 CiM 特性。隨后,針對給定規(guī)格選擇最優(yōu)數(shù)據(jù)流對于實現(xiàn)盡可能高的性能和能效非常重要。最優(yōu)數(shù)據(jù)流通過在給定硬件資源上高效調(diào)度和分配 GEMM,減少內(nèi)存訪問次數(shù),從而影響數(shù)據(jù)復(fù)用。GEMM 的算法數(shù)據(jù)復(fù)用可以用 MAC 運算次數(shù)除以矩陣總大小來計算。但需要注意的是,觀察到的數(shù)據(jù)復(fù)用是由數(shù)據(jù)流決定的,因為它取決于存儲器訪問的實際次數(shù)。
在類似 Nvidia-A100 的基線架構(gòu)中,分析評估基于 SRAM 的RF和 SMem 級模擬和數(shù)字 CiM 基元。
通過為給定的 CiM 架構(gòu)和 GEMM 形狀找到最優(yōu)數(shù)據(jù)流,優(yōu)化 CiM 帶來的性能和能效提升。
從能耗/性能的角度詳細解答各種 GEMM 形狀的 CiM 的類型、時間和位置的選擇。
本文其余部分安排如下:第二節(jié)將我們的工作與過去的其他研究區(qū)分開來。
下一節(jié)(III)介紹了這項工作的相關(guān)背景。第四節(jié)詳細介紹了用于實驗的 CiM 基本計算單元集。
下一節(jié)(V)重點介紹了主要收獲、結(jié)果和討論,最后一節(jié)是結(jié)論。
02. 相關(guān)工作
雖然已有研究考慮了 CPU 中的緩存內(nèi)計算,但還沒有研究將 GPU 內(nèi)存重新用于計算。例如,Duality 高速緩存[11]架構(gòu)重新利用了服務(wù)器級至強處理器的末級高速緩存來加速數(shù)據(jù)并行應(yīng)用。他們還擴展了系統(tǒng)堆棧,開發(fā)了類似于 CUDA 的單指令多線程(SIMT)編程模型,用于在緩存中執(zhí)行浮點和整數(shù)算術(shù)運算。MLIMP [12] 通過為多層內(nèi)存處理系統(tǒng)開發(fā)并發(fā)任務(wù)調(diào)度程序,擴展了圖形神經(jīng)網(wǎng)絡(luò)的 二元緩存(Duality Cache) 概念。他們提出了基于內(nèi)存類型(位串行存儲 SRAM/憶阻器ReRAM/動態(tài)存儲器 DRAM)的任務(wù)調(diào)度和內(nèi)存分配算法。另一方面,這項工作的重點是分析將 GPU 不同層次的內(nèi)存重新用于 ML 推理的好處。我們之所以考慮 GPU,是因為 GPU 在加速 GEMM(推理任務(wù)的核心計算)方面具有廣泛的優(yōu)勢。此外,GPU 是可編程加速器,同樣的編程模型有可能重新用于集成 CiM 的 GPU。
Livia [13] 還研究了修改 CPU 中的高速緩沖存儲器,以盡量減少不規(guī)則數(shù)據(jù)訪問的整體數(shù)據(jù)搬運。它提出了一種系統(tǒng)架構(gòu),可在存儲器層次結(jié)構(gòu)的不同位置動態(tài)調(diào)度任務(wù)和數(shù)據(jù)。相比之下,我們的重點是關(guān)注高度規(guī)則的工作負載(GEMM),并確定 CiM 基本計算單元提供的并行性是否能與高速緩存層次結(jié)構(gòu)提供的局部性優(yōu)勢相匹配。
To-Pim-or-Not[25]是第一個提出如何以及何時在不同應(yīng)用中使用存內(nèi)處理(PIM)問題的工作。它側(cè)重于開發(fā)一個軟件框架,以確定何時以及如何有效地將計算卸載到 PIM,同時分析性能優(yōu)勢和卸載成本之間的權(quán)衡。然而,這項工作的范圍僅限于新興的通用 DDR 存儲系統(tǒng),從而造成了對基于 SRAM 的 CIM 基本計算單元的理解上的空白。我們的工作通過考慮在GPGPU 的高速緩存層次結(jié)構(gòu)中的運用 CiM基本計算單元,從而填補了這一空白。最近另一項關(guān)于內(nèi)存中模擬與數(shù)字計算基準測試的工作 [26],基于固定的模擬 CiM 和數(shù)字 CiM 設(shè)計(稱為模板),開發(fā)了一種量化能耗模型。然而,CiMMacros基本運算單元在外圍電路方面差異很大,使用模板限制了 CiM Macro基本運算單元的設(shè)計選擇。此外,它也未提及在具有可配置數(shù)據(jù)流選項的系統(tǒng)中的 CiM 延遲或性能評估。我們利用 Timeloop 模型 [1] 方法對不同 CiM 基本運算單元的系統(tǒng)進行分析評估。Timeloop 考慮了具有算術(shù)單元和內(nèi)存層次結(jié)構(gòu)的通用架構(gòu)模板。
03. 背景
A.GEMM 在 ML 工作負載中的重要性
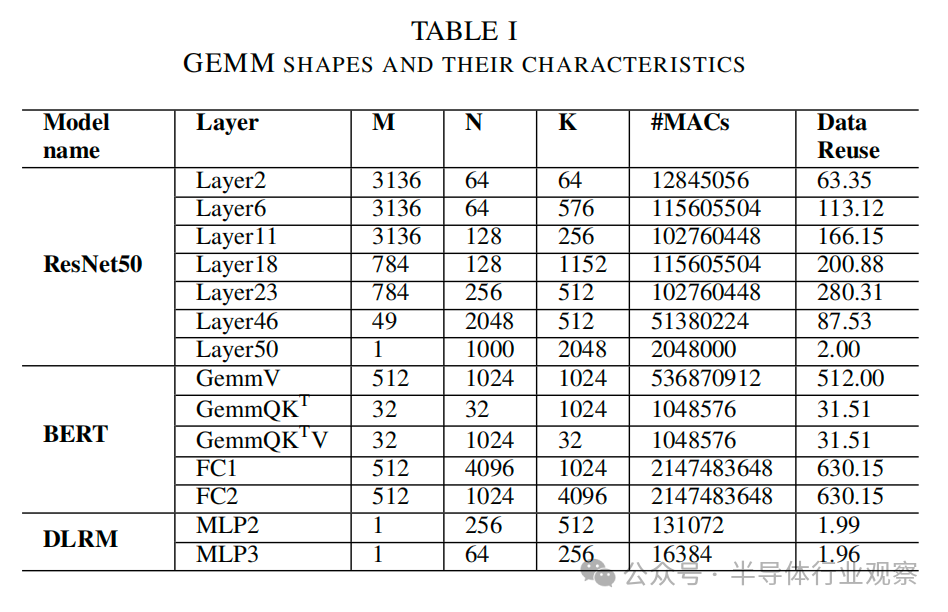
機器學(xué)習(xí)工作負載由各種神經(jīng)網(wǎng)絡(luò)組成,從卷積、全連接到Transformer和推薦模型。矩陣-向量乘法和矩陣-矩陣乘法是這些神經(jīng)網(wǎng)絡(luò)計算的核心[3], [4]。在本文中,我們將此類乘法統(tǒng)稱為通用矩陣-矩陣乘法或GEMM(M×N×K)。M、N 和 K 用來表示矩陣的維數(shù)(圖 1),其中 K 是約簡維數(shù)。
通過使用 im2col 將輸入和權(quán)重特征圖的卷積操作轉(zhuǎn)換為矩陣-矩陣乘法,可以將卷積神經(jīng)網(wǎng)絡(luò) (CNN) 作為 GEMMs來 實現(xiàn)[22]。im2col 或圖像-列轉(zhuǎn)換將三維卷積操作轉(zhuǎn)換為 GEMM (M,N,K),其中K代表輸入和權(quán)重之間 MAC 操作的約簡維度,M 代表此類約簡或卷積的總數(shù),N則根據(jù)輸出通道的數(shù)量決定。與其他層相比,CNN的初始層通常具有更大的輸入特征圖,適用于較大的數(shù)據(jù)集,如ImageNet。最后一層是分類器,本質(zhì)上是全連接(FC)層。它由矩陣向量乘法組成,可以看作是GEMM的一種特例。同樣,Transformer網(wǎng)絡(luò)模型根據(jù)初始層的輸入嵌入計算查詢矩陣(WQ)、鍵矩陣(WK)和值矩陣(WV),可視化為相同形狀的 GEMM。此外,Transformer網(wǎng)絡(luò)模型由其他 GEMMs 組成,如logit(QKT)、注意力(QKTV)和輸出(WO)計算,然后是FC層。另一方面,推薦模型采用多層感知器(MLP),從稠密特征池和用戶偏好中預(yù)測項目[27],基本上由 FC 層組成。表I列出了 GEMM 的形狀,代表了各種ML工作負載的形狀和大小。
B.基于 SRAM 的存內(nèi)計算基本計算單元
與邏輯運算相比,內(nèi)存訪問的成本較高[28],因此很多人提出在片上 SRAM 中執(zhí)行計算[29]。這些 CiM Macros的設(shè)計方式可以基于模擬或數(shù)字以各種方式設(shè)計。另一個關(guān)鍵因素是所使用的 SRAM 單元類型。這些單元的晶體管數(shù)量各不相同,常見的有 6T [20]、8T [17] 和 10T [30] 單元。此外,CiM Macros的輸入數(shù)據(jù)存儲或應(yīng)用于 CiM 計算的方式也各不相同。例如,輸入可以存儲在 CiM Macros本身,也可以從外部緩沖器應(yīng)用到 CiM Macros。
在數(shù)字CiM中,乘法和累加運算是通過位串行邏輯門在數(shù)字域中進行的。這種邏輯單元通常置于 CiM macro的外圍電路中 [15]、[18]、[19]。數(shù)字 CiM macro的計算并行程度通常取決于macro中添加的邏輯資源量。然而,在數(shù)字 CiM 設(shè)計中添加更多邏輯電路會導(dǎo)致顯著的晶圓面積開銷[18],從而影響性能/能耗-面積的權(quán)衡。另一方面, 模擬CiMmacro通過字線輸入比特來執(zhí)行 MAC 運算,同時將權(quán)重值存儲在CiM macro中 [16], [17]。輸出生成為位線上的模擬電壓或電流,其需要通過模數(shù)轉(zhuǎn)換器(ADC)將其轉(zhuǎn)換為數(shù)字信號,以實現(xiàn)macro之間的通信魯棒性。值得注意的是,模數(shù)轉(zhuǎn)換器是模擬CiMmacro的主要面積/延遲/能耗的瓶頸[31]。已有的技術(shù)試圖通過更窄的輸出精度或新穎的ADC電路設(shè)計來攤銷 ADC 的成本,以獲得更好的能效/性能 [16]、[17]。值得一提的是,數(shù)字 CiM 可與最先進的晶圓制造技術(shù)工藝節(jié)點相兼容匹配 [19],而模擬 CiM 則不可以,在這種先進的技術(shù)節(jié)點上,ADC會出現(xiàn)明顯的噪聲 [32]。
如前所述,CiMMacros包括各種 SRAM 單元類型。CiM Macros通常采用 8T(Transistor) 單元,因為它們具有解耦的讀寫端口,可將讀取干擾問題降至最低[15],且噪聲容限高于 6T 單元。基于 8T 的 CiM 可同時支持多條字線,從而實現(xiàn)更多并行 MAC 操作并提高能效。另一方面,6T 單元由于結(jié)構(gòu)緊湊面積小,已成為常規(guī)SRAM 設(shè)計的技術(shù)標準。。從而為了減少 8T 單元的面積開銷,人們提出了基于 6T 的 CiM設(shè)計。為了避免基于 6T 的 CiM macro的讀取干擾問題,目前提出了幾種電路技術(shù) [16]、[18]、[20]。例如,為了執(zhí)行基于 6T 的模擬 CiM,[16]、[20] 在共享相同位線的一組 6T 單元中添加了一個本地計算單元塊。在一列中有多個組,其中不同組中的兩個單元不共享同一位線。需要注意的是,在計算過程中,每個本地計算單元塊只激活一個 6T 單元,以避免讀取干擾。除了基于 6T 和 8T 的 CiM之外,一些報道過的macro還采用了其他單元類型(如 10T [30]),它們可以在單元內(nèi)執(zhí)行更復(fù)雜的計算(如脈沖神經(jīng)網(wǎng)絡(luò)的內(nèi)存內(nèi)加法和膜電位更新),但同時會導(dǎo)致更大的面積開銷。
CiMmacro的輸入方式也各不相同。輸入數(shù)據(jù)可以在計算之前存儲在 CiM macro中[15],也可以在 CiM運行過程中從外部緩沖區(qū)流進macro[17]。輸入存儲/數(shù)據(jù)流會對相應(yīng)的 CiM macro產(chǎn)生不同的映射/數(shù)據(jù)流約束,從而導(dǎo)致不同的最優(yōu)數(shù)據(jù)變化。
此外,在這些研究中還出現(xiàn)了不同的輸入/輸出精度,這給比較帶來了挑戰(zhàn)。為了進行公平比較,我們在這項工作中將輸入/輸出精度固定為 8 位整數(shù)。值得一提的是,不同的CiMmacro由于其獨特的計算性質(zhì),可能會在macro級別上強加某些數(shù)據(jù)流 [15], [16]。
C.高速緩存層次結(jié)構(gòu)中的數(shù)據(jù)流優(yōu)化
GEMM 由于其規(guī)則的數(shù)據(jù)訪問模式而表現(xiàn)出很高的空間和時間局部性。為了利用這種局部性,GPU 通過分片(或分塊)輸出矩陣和并行執(zhí)行分片計算來實現(xiàn) GEMM [23]。對于給定的數(shù)據(jù)流,循環(huán)因子解釋了這種分片的大小,而循環(huán)順序(數(shù)據(jù)流循環(huán)表示中的 M、N、K 順序)決定了在給定存儲器級別上分片的復(fù)用。 算術(shù)強度或數(shù)據(jù)復(fù)用可以計算為運算次數(shù)除以從存儲器中提取的矩陣的總大小::
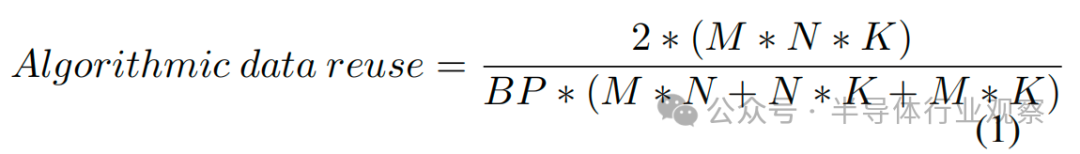
假設(shè)每個矩陣從主存儲器訪問一次,其中 BP 為位精度。
存儲器訪問的次數(shù)取決于矩陣如何被劃分成片以及不同矩陣維度的獲取順序,這稱為數(shù)據(jù)流。因此,觀察到的數(shù)據(jù)復(fù)用可能與算法上的數(shù)據(jù)復(fù)用不同。
GEMMs 的性能受到其算法運算強度和硬件資源的限制。算術(shù)強度低的 GEMM 受存儲器帶寬的限制,而算術(shù)強度高的 GEMM 則受峰值性能的限制。cuDNN 和 cuBLAS 等軟件庫可用于決定tile大小,以便在給定 GEMM 形狀下實現(xiàn)盡可能高的性能。tile越大,數(shù)據(jù)復(fù)用率越高。數(shù)據(jù)復(fù)用的增加可降低帶寬要求,提高效率。然而,選擇較大的tile可能會減少可并行運行tile的數(shù)量。這種減少有可能導(dǎo)致性能降低。
鑒于在 GPU 上優(yōu)化 GEMM 的實現(xiàn)是為了獲得最佳性能,因此為 CiM 集成架構(gòu)實現(xiàn)最優(yōu)數(shù)據(jù)流也很重要。在探索數(shù)據(jù)流搜索空間和選擇最優(yōu)數(shù)據(jù)流方面有多項研究。SCNN [33] 是最早為深度神經(jīng)網(wǎng)絡(luò)(DNN)引入數(shù)據(jù)流優(yōu)化的著作之一。他們提出了一種輸入固定數(shù)據(jù)流,即輸入激活保持靜態(tài),允許其乘以每個輸出通道所需的所有濾波器權(quán)重。此外,Timeloop [1] 提出了一種低成本映射器和模型,用于探索 DNN 和 GEMM 的數(shù)據(jù)流搜索空間。它將輸入問題的大小建模為嵌套循環(huán),從而可以評估數(shù)據(jù)復(fù)用的機會,并在不同架構(gòu)和工作負載之間進行高效映射。Maestro [34] 是另一種工具,它提出了一種分析成本模型,利用以數(shù)據(jù)為中心的方法評估數(shù)據(jù)流中的成本效益權(quán)衡。ZigZag [35]也通過將搜索范圍擴大到不均衡調(diào)度機會來探索 DNN 加速器的設(shè)計空間。
04. CiM 架構(gòu)構(gòu)建
為了估算不同 CiM 基本計算單元的能耗和性能,所有評估都使用 TimeloopAccelergy 框架 [1]。我們選擇 Timeloop/Accelergy 基礎(chǔ)架構(gòu)是因為:1.它是一種快速分析模型,在研究項目中廣泛用于早期設(shè)計估算;2.它提供了一種映射器,可為給定架構(gòu)選擇最佳數(shù)據(jù)流;3.它是一種靈活的工具,過去曾用于模擬 CiM 的建模[36]。
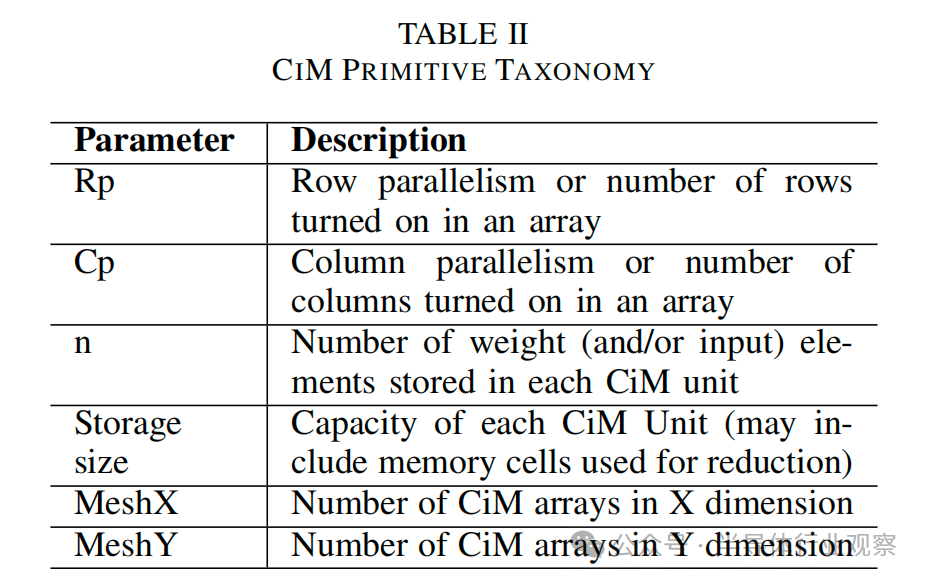
該框架將架構(gòu)、約束、映射配置和能耗表文件作為輸入。為了進行評估,我們創(chuàng)建了單獨的架構(gòu)模板文件,用于在RF和 SMem 層面集成 CiM(圖 1)。如圖 3 所示,這樣的架構(gòu)模板將運算單元塊在存儲器級別替換為 重新設(shè)計使用的CiM 的模塊。這種 CiM 集成存儲器級由多個 CiM 陣列(MeshX、MeshY)組成,取決于存儲器的大小和容量。每個 CiM 陣列是一個 CiM 單元網(wǎng)絡(luò),一次可計算一個 MAC。CiM 單元的數(shù)量取決于陣列中同時開啟的行數(shù)(Rp)和列數(shù)(Cp)。因此,所有 CiM 單元都可以并行執(zhí)行 MAC 運算。由于 CiM 陣列中的所有列/行通常不會同時打開,因此 CiM 陣列的這種順序性以時間循環(huán)因子 (n) 的形式體現(xiàn)(參見圖 6)。這種 “并行輸出-順序輸入 ”模板方法(圖 3)可同時捕捉模擬和數(shù)字信號。圖 3)同時捕捉了基于模擬和數(shù)字的 CiM 類型。表 II 詳細列出了 CiM 架構(gòu)模板中使用的參數(shù)。
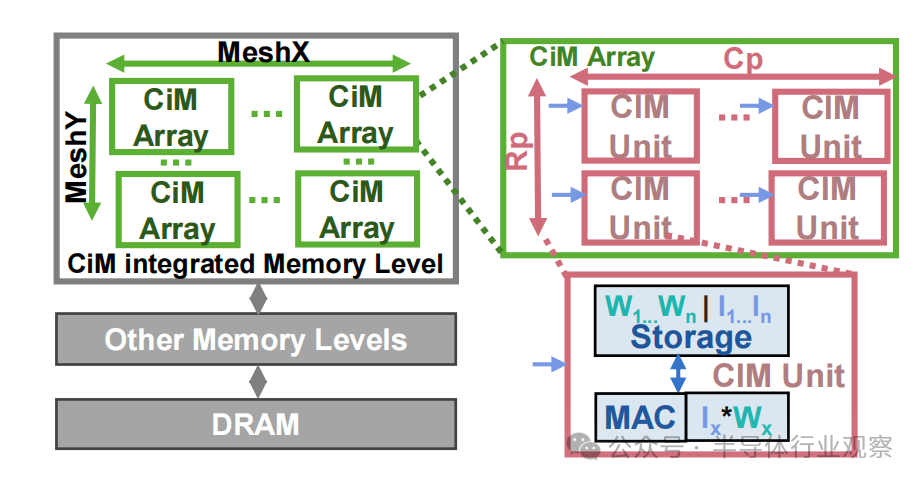 圖 3. 用于在 Timeloop 中表示 CiM 基本計算單元的架構(gòu)模板文件框圖。內(nèi)存級被重新組合為計算級,表現(xiàn)為多個 CiM 陣列的網(wǎng)絡(luò)。每個 CiM 陣列由可并行操作的單個 CiM 單元組成,每個 CiM 單元一次計算一個乘法累加 (MAC) 運算。CiM 單元的存儲空間可能只包含權(quán)重,也可能包含權(quán)重和輸入,具體取決于 CiM 基本計算單元的原始映射約束。
圖 3. 用于在 Timeloop 中表示 CiM 基本計算單元的架構(gòu)模板文件框圖。內(nèi)存級被重新組合為計算級,表現(xiàn)為多個 CiM 陣列的網(wǎng)絡(luò)。每個 CiM 陣列由可并行操作的單個 CiM 單元組成,每個 CiM 單元一次計算一個乘法累加 (MAC) 運算。CiM 單元的存儲空間可能只包含權(quán)重,也可能包含權(quán)重和輸入,具體取決于 CiM 基本計算單元的原始映射約束。
根據(jù)原始 CiM 硅原型測得的性能數(shù)據(jù),向 Accelergy 提供了 CiM 能耗表。由于原型在電源電壓和技術(shù)方面存在差異,因此根據(jù)已完成的縮放工作[37],對能耗數(shù)據(jù)進行了縮放,以匹配 1V 電源的 32nm 技術(shù)。在 Timeloop 架構(gòu)模板中假設(shè)頻率為 1GHz,通過計算周期的延遲來捕捉 CiM 基本計算單元工作頻率的差異。下一節(jié)將介紹如何調(diào)整約束配置,以獲得每個輸入規(guī)格的最優(yōu)數(shù)據(jù)流。
05. 演進
A.實驗設(shè)置
1) Cim 基本計算單元:我們?yōu)槟M/混合信號和數(shù)字CiM選擇了兩種最先進的基于 SRAM 的基元,如圖 4 所示。這些基本計算單元涵蓋了一系列不同的參數(shù),詳見表 III 和下文說明。
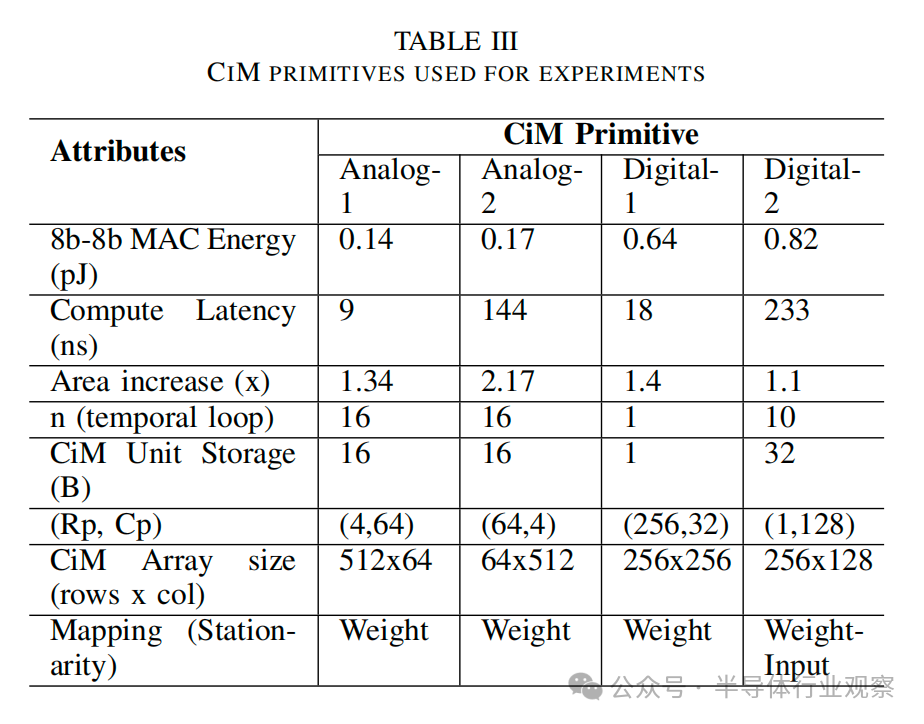
如圖4(a)所示,Analog-1 [16] CiM基本計算單元由4個存儲體組成,每個存儲體有4個128x64 SRAM6T單元塊。它采用轉(zhuǎn)置映射技術(shù),向多個列提供輸入。這種配置產(chǎn)生256個(4×64) CiM單元,每個單元有128b (16×8b)存儲空間。每個單元可以在9個周期內(nèi)執(zhí)行8b-8b MAC操作,同時處理2bit個輸入并激活8行權(quán)重位。然而,由于每個組共享的ADC數(shù)量有限,因此該基本計算單元的時間循環(huán)因子設(shè)置為16。
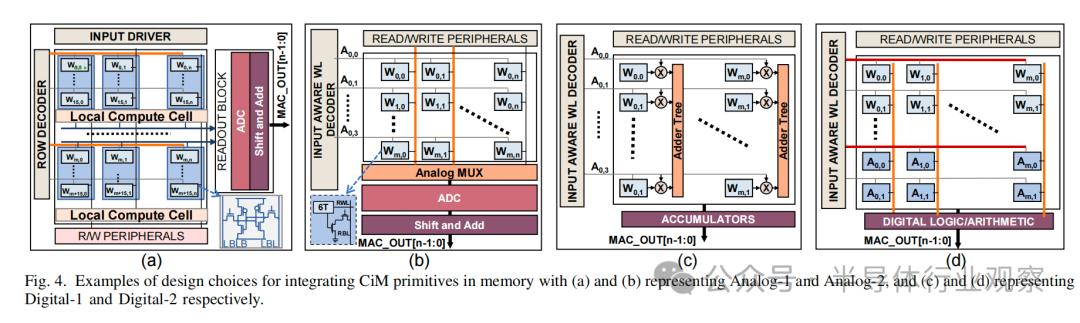
圖 4(b) 所示的模擬-2[17] 基本計算單元采用可重新配置的 ADC 設(shè)計,有 8 個陣列,每個陣列(64×64)存儲不同的權(quán)重位,每個計算周期有 4 個 ADC 輸出。這種設(shè)計產(chǎn)生了 256 (64×4)CiM 單元,每個單元能在144個周期內(nèi)執(zhí)行 8b-8b MAC,包括位串行延遲和從65納米到 32 納米的縮放調(diào)整。每個CiM單元包含 8×(64÷4) 個權(quán)重位,由于ADC的限制,這些權(quán)重位需要按順序依次計算。這種基元的單次計算能耗較低,但由于其可重新配置的特性,面積開銷較大。
圖 4(c)所示的 Digital-1 [18]采用全數(shù)字設(shè)計,將輸入輸送到每一行,并使用加法器樹在每一列執(zhí)行 MAC 運算。這里每個 CiM 單元通過組合存儲在 8 列中的權(quán)重比特來計算1個8b-8b MAC。加法器樹的減少產(chǎn)生了面積開銷,但導(dǎo)致 18 個周期的計算延遲。
圖4(d)中的Digital-2[15]基本計算單元顯示了輸入和權(quán)重都映射到同一列的設(shè)計。這種配置允許每個CiM單元(包括單列)執(zhí)行大約10個8b-8b MAC操作。然而,每個操作都需要233個周期,這歸因于過程中涉及的多個加法。盡管面積開銷很小,但由于在列中分配一些數(shù)組位以減少輸出,因此計算并行性受到限制。
2) GEMM形狀:我們從ResNet50[38]與ImageNet[39] 、序列長度等于1024的 BERT-medium[40]和DLRM[27] 等常用ML模型中提取了各種GEMM形狀。我們根據(jù)表 IV 所列的 GEMM 形狀的獨特屬性對其進行了剪枝,以涵蓋不同的權(quán)重大小、形狀和計算性質(zhì)。如圖 2 所示,計算密集型 GEMM 位于屋頂線表示的平頂下方。它們的數(shù)據(jù)復(fù)用率較高,這意味著每次內(nèi)存訪問的計算次數(shù)較多。另一方面,內(nèi)存密集型GEMM位于帶寬受限的屋頂線下方,以內(nèi)存訪問而非計算為主。表中計算密集度較低的GEMM技術(shù)上屬于計算密集型區(qū)域。不過,它們的數(shù)據(jù)復(fù)用程度中等,形狀偏斜。
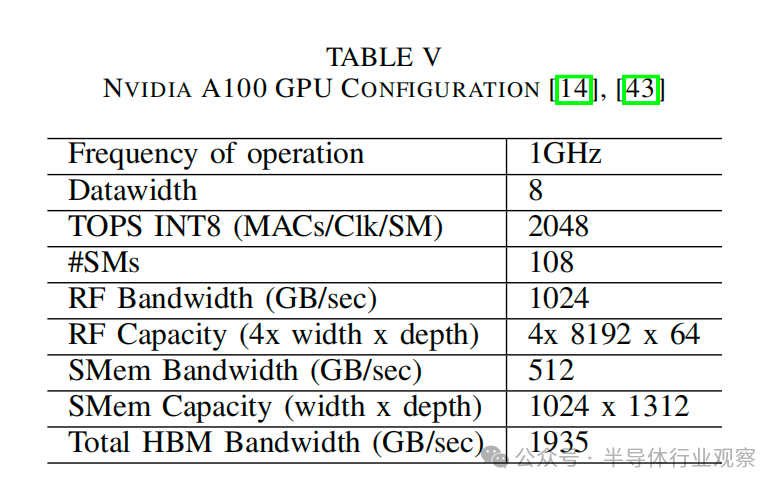
3) 基準:我們假設(shè)采用單個SM基準架構(gòu),與最新GPU(Nvidia A100)的規(guī)格一致,詳見表 V。所有實驗都是在INT-8精度、權(quán)重固定數(shù)據(jù)流和等面積約束下使用Timeloop/Accelergy 框架進行的。之所以選擇 INT-8,是因為它在 ML 推理任務(wù)中是可接受的精度[41]、[42]。等面積假定,通過調(diào)整容量,CiM 整合后的內(nèi)存級面積保持不變。 由于A100由108個SM組成,我們大約假設(shè)1個SM架構(gòu)的總HBM帶寬為10%。
B.數(shù)據(jù)流的影響
在本小節(jié)中,我們將簡要討論在寄存器文件RF中集成了CiM的兩種GEMM形狀,以強調(diào)不同的基本計算單元如何利用數(shù)據(jù)復(fù)用的機會。通過為每個基本計算單元設(shè)置約束文件,使用timelloop映射器找到最優(yōu)數(shù)據(jù)流。圖5顯示了CiM級別的樣本數(shù)據(jù)流,其中在約束文件中根據(jù)CiM類型設(shè)置了突出顯示的參數(shù)。為了最大限度地提高性能,我們設(shè)置了映射的約束,以便在CiM單元中并行完成最大的計算,即使用權(quán)重交錯。其他優(yōu)先級是最大化映射權(quán)重的輸入數(shù)據(jù)復(fù)用,并在有利的情況下允許權(quán)重重復(fù)。
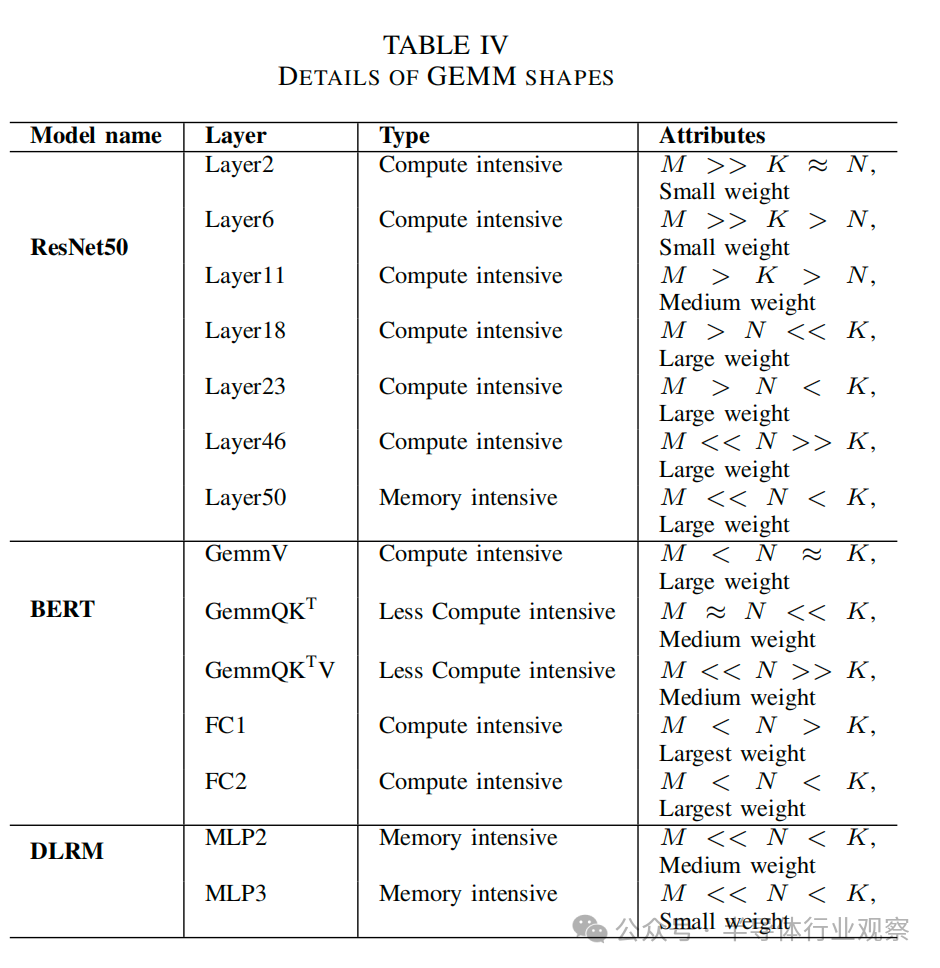
當權(quán)重(N × K)矩陣較小,且 M 明顯超過 N 和 K 時(圖 5(a)中為 Gemm-3136 × 64 × 64),權(quán)重可以與CiM 集成在寄存器文件 RF存儲器。這里,每個CiM基本計算單元由4096個CiM單元組成。基線已經(jīng)在DRAM上實現(xiàn)了最高的數(shù)據(jù)重用(≈63,見表I),并可以跨CiM基礎(chǔ)計算單元進行維護。然而,CiM 可以通過重復(fù)使用存儲在 SMem 中的整個輸入tile(M×K),更好地利用寄存器 RF及的輸入數(shù)據(jù)重復(fù)利用率(≈3112)。這就降低了 CiM 的內(nèi)存訪問次數(shù),從而將總能耗降低了 0.50 倍-0.67 倍。就吞吐量而言,CiM 的吞吐量受到了嚴重的影響,僅為基線吞吐量的 1%-22%。高計算周期 CiM 基本計算單元的計算周期比基線高 1 個周期,這直接影響了最終吞吐量,即使使用權(quán)重交錯映射也是如此。因此,在等容量限制條件下, 由于并行性有限,不可能達到基線吞吐量。
如圖 5(b) Gemm-3136x64x64 所示,在等面積限制下,CiM 的吞吐量損失可以部分抵消。這些限制允許在每個基本計算單元的面積開銷允許的范圍內(nèi)擁有盡可能多的 CiM 單元,從而擴展到 4096 個 CiM 單元以上。尤其是Digital-1 基本計算單元,通過復(fù)制權(quán)重,其吞吐量達到了基線吞吐量的 77%。由于寫入 SRAM 單元比訪問 DRAM 消耗更少的能量,因此權(quán)重復(fù)制能以最小的能量成本提高吞吐量[6]。需要注意的是,重復(fù)的次數(shù)受 CiM 單元數(shù)量和向 CiM 單元廣播輸入的上層存儲器容量的限制。
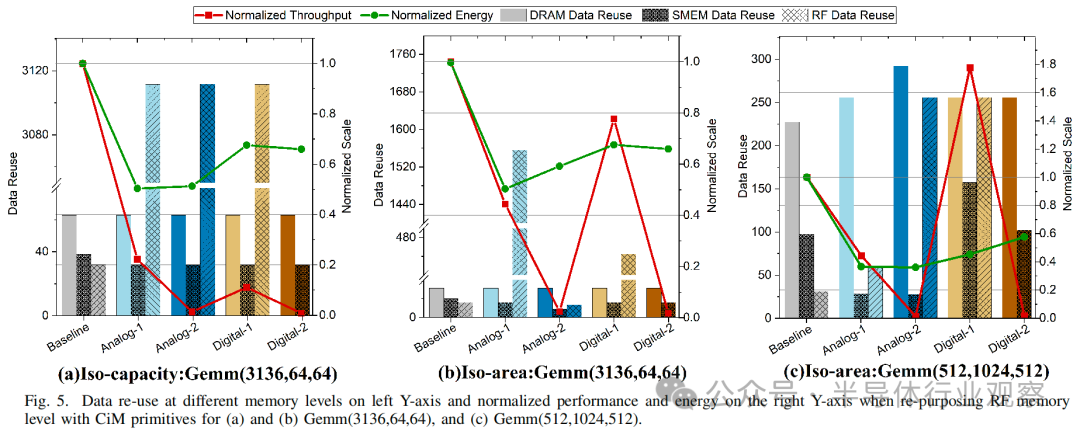
當權(quán)重矩陣過大而無法放入內(nèi)存(圖 5(c)Gemm-512x1024x512)且 M ≈ K 時,與基線相比,CiM 基元可利用 DRAM 中更高的數(shù)據(jù)復(fù)用率。這就減少了最后一級訪問,節(jié)省了更多能耗(是基線的 0.36-0.57 倍)。在吞吐量方面,較小的輸入矩陣(M×K)減少了對共享內(nèi)存容量的限制。這意味著所有 M 個維度都可以存儲在 SMem 中,用于映射 K 個維度,因此,如果有足夠的 CiM 單元,就可以進行更多的權(quán)重復(fù)制。Digital-1 利用這一機會 實現(xiàn)高于基線的吞吐量。Analog-2 和Digital-2 的吞吐量最低,因為它們的性能受到高計算延遲的限制。此外,面積開銷和映射限制也限制了它們的吞吐量。Analog-2 的面積開銷較大,限制了同一面積內(nèi)可容納的 CiM 單元數(shù)量。Digital-2 有一個固有的面積開銷,這是由于在同一列中映射輸入和部分輸出位的限制造成的,這進一步限制了可以并行操作的 CiM 單元的數(shù)量。
基于同樣的思路,我們確保所有工作負載都以最佳方式映射,并在接下來的小節(jié)中討論不同 GEMM 形狀、CiM 類型和存儲器級別的結(jié)果,以深入了解 “什么”、“何時 ”和 “何地 ”的問題。
C.性能結(jié)果
圖 7(a)和圖 7(c)分別比較了在寄存器文件 RF和 SMem 級集成 CiM 時觀察到的性能。
What:比較不同的CiM基本計算單元,Analog-1具有較小的計算延遲(9個周期)的其顯示的性能范圍為基線吞吐量的22%到100%。另一方面,Digital-1(計算延遲為 18 個周期)的吞吐量可高達基線吞吐量的 450%,總體上接近基線吞吐量,但某些 GEMM 除外(在 “何時 ”一節(jié)中討論)。這意味著,在 CiM 設(shè)計中,對于吞吐量而言,利用全行和全列并行性的能力比實現(xiàn)盡可能低的延遲更為重要。不過,也不能完全忽視延遲,正如Analog-2 和Digital-2 基本計算單元的較低性能所描述的,計算延遲分別高達 144 和 233 個周期。
When: 與其他 GEMM 形狀相比,具有較大權(quán)重矩陣的計算約束/密集層(Layer6、Layer18、Layer46、GemmV、FC1 和 FC2)在使用 CiM 基本計算單元時性能最高(在寄存器文件RF級重新使用時,最低為基線的 78%)。少數(shù)受計算約束/密集的 GEMM,特別是 K 值較小的 Layer2 和 QKTV,在所有 CiM 基元中的性能都不理想,分別只達到基線吞吐量的 39% 和 47%。這種較低的性能可歸因于 Digital-1 的較低性能,這源于對 K 維度的映射限制。CiM 架構(gòu)有權(quán)重 (N×K) 映射,以減少 K 維度上的多個部分和,從而限制了小 K 維度的并行性。基線則不存在此類限制,因此在此類 GEMM 中可獲得更高的性能。同樣重要的是,由于數(shù)據(jù)復(fù)用有限,CiM 基元的最高性能不會超過存儲約束層(Layer50、MLP2、MLP3)的基線。
Where: 考慮到所有 CiM 基本計算單元的最高性能,在寄存器文件RF級觀察到的最大吞吐量(≈400%)明顯高于在 SMem 級觀察到的吞吐量(≈170%)。這可歸因于 SMem 的面積(164KB)小于單個內(nèi)核中的 4 個 RF 實例(256KB),這使得相同面積中的 CiM 單元更少,從而限制了可實現(xiàn)的最大吞吐量。這種行為的一個反常現(xiàn)象是,由于內(nèi)存寬度和高度限制的不同,映射器在 SMem 而不是RF上找到了利用率更高的更好映射。例如,盡管在SMem層級計算時存在帶寬節(jié)流,但 MLP3 在 SMem 和 Analog-1 上的性能比在RF上高出≈50%。
D.能耗結(jié)果
根據(jù)圖 8(b) 和圖 8(d) 所示的能耗,我們可以得出以下結(jié)論:
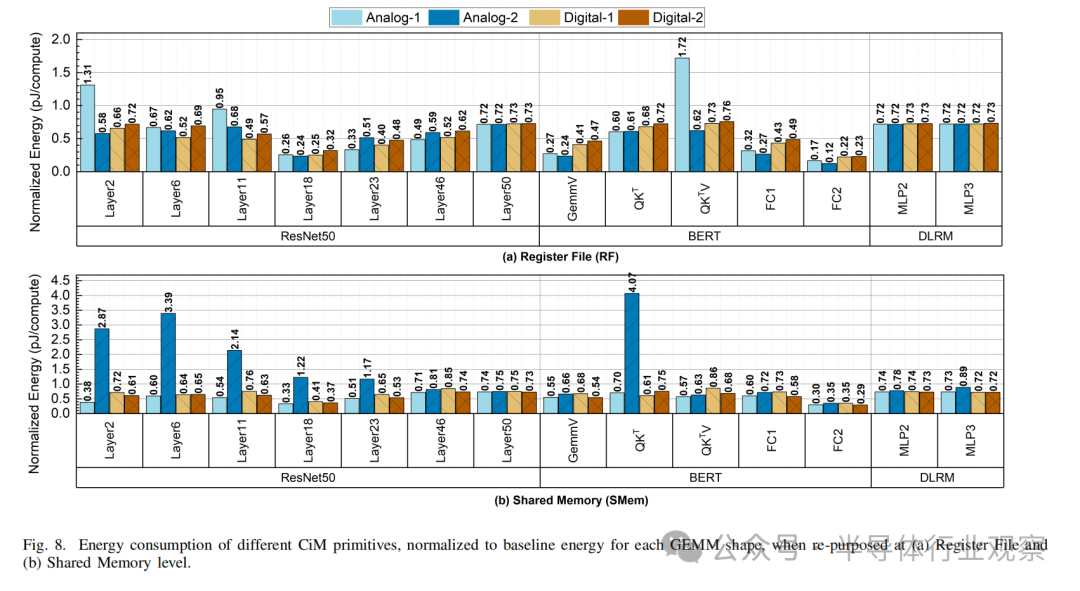
What:在能效方面,CiM 基本計算單元沒有明顯的優(yōu)勝者。雖然 Analog-1 和 Analog-2 顯示出最佳的能效,F(xiàn)C2 層的能效分別是基線能效的 0.16 倍和 0.12 倍,但 QKTV 層和 QKT 層的能效也分別高達基線能效的 1.7 倍和 4 倍。另一方面,Digital-1 和 Digital-2 基元的能耗始終呈下降趨勢,分別為基線能耗的 0.22 倍至 0.86 倍和 0.23 倍至 0.75 倍。這表明,如果考慮到主內(nèi)存,TOPS/W 最高的基本計算單元(本例中為 Analog-1)不一定是最節(jié)能的。對于無法映射所有權(quán)重(高 K 或高 N)的基本計算單元(取決于基元類型和內(nèi)存級別),由于輸出值的時間還原次數(shù)增加,總能耗會大于基線。舉例來說,Analog-2 在 K 較大時表現(xiàn)較差,尤其是在 SMem 時,因為設(shè)計將 N 維并行化,并將 K 限制在 64。當權(quán)重矩陣較小時(例如,模擬-2-SMem 的 QKTV,其中 N 》》 K),效果會很明顯,因為基線可以有效地減少部分和,并且不需要對主存儲器級進行大量訪問。SMem 的 Digital-2 也擁有較少的 CiM 單元,但與模擬系統(tǒng)不同的是,它允許將 K 維映射到同一陣列中的不同列。
When:我們觀察到第 18 層、第 23 層、GemmV、FC1 和 FC2 的能耗降低幅度最大,分別為基線能量的 0.24 倍、0.33 倍、0.24 倍、0.27 倍和 0.12 倍,尤其是在寄存器文件RF層重新使用時。所有這些層的 K 值都很高,這說明當部分的求和降維的數(shù)量較多時,CiM 基元的能量效益最大。對于存儲約束層(Layer50、MLP2 和 MLP3),所有 CiM 基元都表現(xiàn)出類似的優(yōu)勢,能耗降低了 30%,因為總能耗主要來自 DRAM 訪問。
Where:由于更大的面積和更多的實例,寄存器文件 RF比SMEM具有更多的CiM單元,這通常導(dǎo)致更低的存儲器訪問或能耗。例如,對于 QKT 層,與 SMem 相比,Analog-2 從 RF 計算中獲益最多。在 SMem 和 RF 中添加 CiM 后,總能耗分別從基準能耗的 4 倍降至 0.6 倍。同樣,對于 GemmV、FC1 和 FC2 層,與 SMem 相比,RF 的Analog-1、Digital-1 和Digital-2 能耗分別約為 0.5 倍、0.6 倍和 0.8 倍。不過,從不同 GEMM 形狀的平均值來看,根據(jù)基本計算單元設(shè)計和 GEMM 形狀的不同,一種 CiM 基元可能更適合特定的存儲器層。例如,Analog-2 基元的面積開銷較大,在寄存器文件 RF層集成時的能耗總是低于 SMem。對于其他基元,SMem 的能耗可能低于 RF 的能耗,如 Layer2(M》》N≈K)。另一個例子是,與寄存器文件 RF相比,Digital-2 在 SMem 下的平均能效更高。
E.討論與未來工作
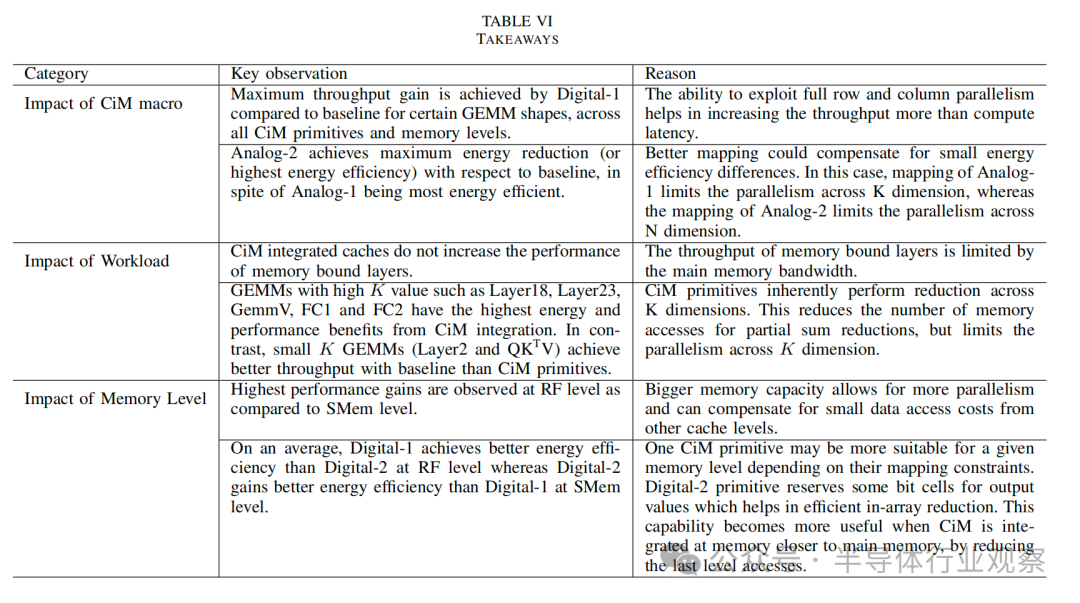
啟示: 隨著 ML 模型的增大和存儲器層次結(jié)構(gòu)的發(fā)展,性能和能效增益的絕對數(shù)字可能會發(fā)生變化。不過,我們預(yù)計在等面積限制下,這些啟示(表 VI)將保持不變。這些啟示取決于分析評估,考慮到:1)性能收益由計算延遲和計算并行性決定;2)能效收益取決于內(nèi)存訪問和計算成本。對于 CiM 基元,并行性反過來取決于 CiM 基元的映射約束、存儲器容量和面積開銷。例如,Digital-1 CiM 基元的面積開銷與 Analog-1 大致相同,而計算延遲幾乎是后者的兩倍。不過,由于映射約束更靈活,允許全行/列并行,Digital-1 實現(xiàn)了更高的并行性。另一方面,CiM 在能耗方面的優(yōu)勢取決于內(nèi)存訪問次數(shù)的減少和 CiM 單元固有的更高能效。數(shù)據(jù)流在減少內(nèi)存訪問方面發(fā)揮著重要作用,因此也能最大限度地提高 CiM 的效益,這一點在分析中也得到了考慮。
假設(shè):我們的評估以 Timeloop 中使用的分析模型為基礎(chǔ),假定架構(gòu)簡化,內(nèi)存子系統(tǒng)完全流水線化。在這種架構(gòu)中,如果沒有帶寬限制,一個內(nèi)存級訪問的延遲會被其他內(nèi)存級訪問所掩蓋。帶寬限制取決于內(nèi)存訪問的總次數(shù)和該內(nèi)存級的帶寬。它假定所有訪問都是合并的,并且不考慮諸如內(nèi)存庫沖突、有限的未命中處理緩沖區(qū)容量以及內(nèi)存中的其他架構(gòu)優(yōu)化等影響。但它仍能捕捉到不同 CiM 基本計算單元的大致性能,有助于了解它們在系統(tǒng)級的影響。
將 CiM 集成到內(nèi)存子系統(tǒng)的方法有多種。等容量集成 CiM 可以提供更高的并行性,但代價是增加晶圓面積。將 CiM 集成到等容量內(nèi)存中會影響高速緩沖存儲器的容量。這可能會進一步影響 SM 的基線吞吐量。不過,我們的工作設(shè)想了一種具有異構(gòu)內(nèi)核的架構(gòu),系統(tǒng)架構(gòu)中既有 CiM SM,也有非 CiM SM。此外,我們在所有方案中都假設(shè)了權(quán)重固定的數(shù)據(jù)流,因為它是最常用的數(shù)據(jù)流。
在 CiM 數(shù)據(jù)流中增加更多靈活性可能會帶來更大的設(shè)計空間,這仍然是一個有待探索的開放式搜索空間。此外,最近的研究[44]、[45]已經(jīng)展示了浮點 CiM 加速器,擴大了內(nèi)存中的計算范圍。不過,這項工作中的所有實驗都假定了 INT-8 精度,包括基線中的 INT-8 精度,以使其包含各種 CiM 基本計算單元。此外,我們僅評估了 ML 工作負載中的單個 GEMM 操作,以估算可能的最大性能和能效收益。對于端到端分析,一種方法是擴展 Timeloop,使其包括層融合等功能以及非 GEMM 操作的成本開銷。層間評估還要求Timeloop考慮前一層的輸入、權(quán)重和輸出在內(nèi)存層次結(jié)構(gòu)中的位置,而當前版本不支持這一功能。需要注意的是,CiM 集成架構(gòu)還會產(chǎn)生編程成本開銷,在最終確定設(shè)計方案時應(yīng)考慮到這一點。
未來的可能性:為了克服 ADC 模塊影響模擬基本計算單元計算并行性的面積和延遲瓶頸,可以考慮采用無 ADC 模塊的模擬基本計算元[46]。無ADC 模擬基元只采用讀出放大器作為外圍電路,將部分和從陣列轉(zhuǎn)換為 1 位輸出。這樣的低面積開銷基本計算單元可以在相同的內(nèi)存區(qū)域內(nèi)實現(xiàn)更多的 CIM 單元。這將進一步有助于通過更高的并行性實現(xiàn)更高的性能,同時大幅改善能耗。模擬基本計算單元的一個注意事項是計算精度的損失。無模數(shù)轉(zhuǎn)換器 ADC的設(shè)計可能會因激進的硬件量化而導(dǎo)致較大的精度損失。不過,研究[47]表明,利用量化感知訓(xùn)練技術(shù) QAT 可以將精度降低到最低程度。
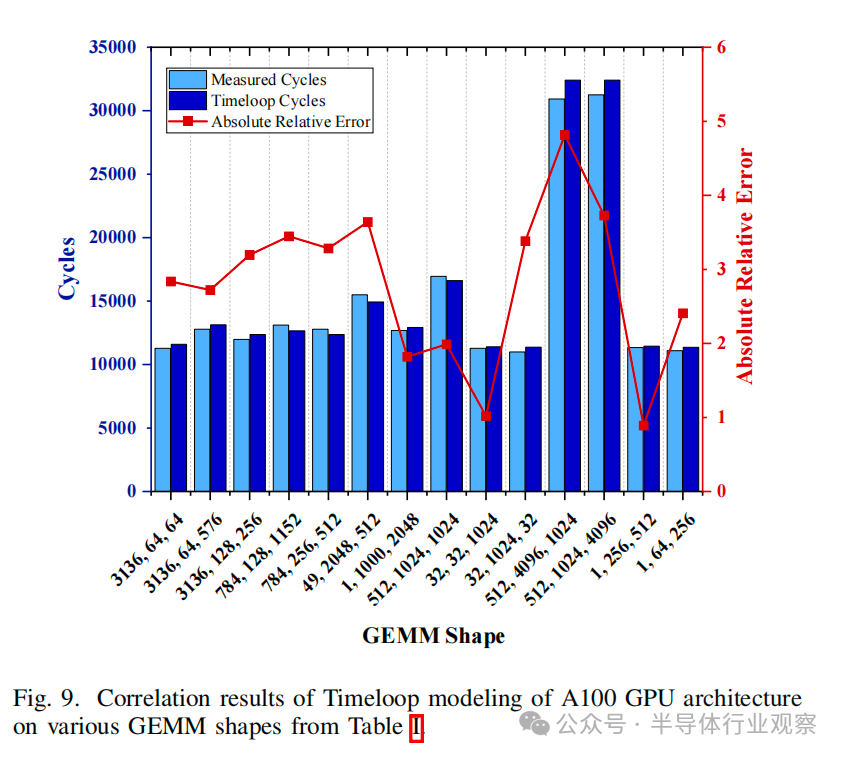
將 CiM 集成到內(nèi)存子系統(tǒng)中的另一種方法是增加存儲器級別或改變存儲器技術(shù)以包括新興的器件設(shè)備。此類研究不在本文研究范圍之內(nèi)。不過,我們的方法可以針對此類分析和新的 CiM 基本計算單元進行擴展。該分析還可以擴展到一個以上的 SM 架構(gòu),以包括 SM 間通信或網(wǎng)絡(luò)成本。完整的類 A100 GPU 模型將有 108 個 SMs,可用于映射更大的模型。圖 9 顯示了 Timeloop 中 GPU 完整模型版本與表 V 中規(guī)格的性能相關(guān)性,圖中使用 CUTLASS 3.2 [48]在 A100-80GB 上運行了測得的 GEMM 內(nèi)核。然而,全 GPU 模型的設(shè)計空間會爆炸,數(shù)據(jù)流搜索時間也會成倍增加。評估全 GPU 類模型將需要進行優(yōu)化或采用新方法,才能在如此大的設(shè)計空間中有效找到最優(yōu)映射。
06. 結(jié)論
我們在 GPU 架構(gòu)的片上高速緩沖存儲器中集成了存內(nèi)計算(CiM)。我們的實驗全面分析了 CiM 在加速基于機器學(xué)習(xí)(ML)推理任務(wù)的通用矩陣乘法(GEMM)工作負載方面的優(yōu)勢。特別是,基于等效面積的分析評估得出了以下結(jié)論:
相比之下,雖然模擬基本計算單元達不到 Digital-1 的高性能水平,但它們在能效方面表現(xiàn)出色,能耗僅為基線能耗的 0.12 倍;數(shù)字基本計算單元緊隨其后,最佳節(jié)能效果為基線能耗的 0.22 倍。CiM 在能效和性能之間的這種權(quán)衡可以使 GPU 受益,尤其是當 GPU 以較低頻率運行以管理功耗時[49]。
When:調(diào)查表明,數(shù)據(jù)復(fù)用率高、K(》 M)值大的計算約束/密集層在性能和能效方面從 CiM 中獲益最大。例如,BERT 模型中的全連接層(FC1、FC2)。相反,數(shù)據(jù)復(fù)用率低、K 值(《《 M)較小的計算綁定 GEMM 在使用基線時通常能獲得更高的吞吐量,但在使用 CiM 時則顯示出能耗優(yōu)勢。在我們的分析中,使用 Image net 數(shù)據(jù)集的 ResNet50 的初始層(如第 2 層和第 11 層)就是這樣的結(jié)果。同樣,偏斜 GEMM 在 K 》》 N 的情況下,能耗降低,吞吐量相當,但當 K 《《n 《=“” span=“”》時,性能下降。受內(nèi)存限制的 GEMM(如 ResNet50 和 DLRM 中的全連接層)僅在 CiM 中顯示出能耗優(yōu)勢,而吞吐量卻沒有提高。
Where:此外,研究結(jié)果表明,在集成 CiM 時,存儲器容量比存儲器層次結(jié)構(gòu)中的層數(shù)更重要。存儲器容量越大,權(quán)重重復(fù)的性能就越高。然而,映射約束和計算延遲等 CiM 特性仍會限制高內(nèi)存容量帶來的性能和能耗效益。
總之,這項工作對整個片上存儲器層次結(jié)構(gòu)中 CiM 基本計算單元的能耗、面積和性能之間的權(quán)衡進行了全面評估。我們相信,我們的工作為了解基于 SRAM 的 CIM 在實現(xiàn)可比性能的同時緩解能耗問題的潛力提供了重要見解。反過來,我們的方法也有助于優(yōu)化基于 CiM 的 ML 推理架構(gòu)。
致謝作者感謝 2021 年提供的北美 Qualcomn 創(chuàng)新獎學(xué)金為本項目提供資金,并感謝 Ramesh Chauhan 在項目初始階段提供的投入。部分研究還得到了由 DARPA 和 SRC 資助的 7 個 JUMP 中心之一 CoCoSys 的資助。作者還要感謝 Aayush Ankit 的頭腦風暴和討論會議。
審核編輯:黃飛














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論