 電子發燒友App
電子發燒友App


智猩猩與智東西將于4月18-19日在北京共同舉辦2024中國生成式AI大會,愛詩科技創始人兼CEO王長虎,Open-Sora開發團隊潞晨科技創始人尤洋,英偉達解決方案架構與工程總監王淼等50+位嘉賓已確認參會,其中,商湯科技大裝置事業群解決方案總監代繼,奕信通創始人張俠,趨動科技技術總監張增金等將在中國智算中心創新論壇帶來主題演講,歡迎報名。
 真正的差異化競爭力,源于系統性地、全面地掌握整個價值鏈中主導無法快速復制的關鍵環節。
真正的差異化競爭力,源于系統性地、全面地掌握整個價值鏈中主導無法快速復制的關鍵環節。
本文是華為2012實驗室網絡專家陸玉春博士去年12月在2012實驗室中央研究院網絡技術實驗室交流平臺【未來網絡前沿】分享的技術文章,在華為黃大年茶思屋線上發表。文章全面復盤與回顧了英偉達網絡技術,并對英偉達AI芯片路線圖的未來技術推演進行了深入的分析與解讀。
文章發布時間比北京時間3月19日發布的英偉達Blackwell系列GPU早3個多月,因此對B100的預測與實際發布新品不完全貼合。但這無礙陸玉春博士基于相關技術的分析推演與總結思考所提供的參考價值。以下是《NVIDIA AI芯片演進解讀與推演》文章全文:
在2023年10月的投資者會議上,NVIDIA(英偉達)展示了其全新的GPU發展藍圖 [1]。
與以往兩年一次的更新節奏不同,這次的路線圖將演進周期縮短至一年。預計在2024年,NVIDIA將推出H200和B100 GPU;到2025年,X100 GPU也將面世。
其AI芯片規劃的戰略核心是“One Architecture”統一架構,支持在任何地方進行模型訓練和部署,無論是數據中心還是邊緣設備,無論是x86架構還是Arm架構。其解決方案適用于超大規模數據中心的訓練任務,也可以滿足企業級用戶的邊緣計算需求。
AI芯片從兩年一次的更新周期轉變為一年一次的更新周期,反映了其產品開發速度的加快和對市場變化的快速響應。其AI芯片布局涵蓋了訓練和推理兩個人工智能關鍵應用,訓練推理融合,并側重推理。同時支持x86和Arm兩種不同硬件生態。在市場定位方面,同時面向超大規模云計算和企業級用戶,以滿足不同需求。
NVIDIA旨在通過統一的架構、廣泛的硬件支持、快速的產品更新周期以及面向不同市場提供全面的差異化的AI解決方案,從而在人工智能領域保持技術和市場的領先地位。
NVIDIA是一個同時擁有 GPU、CPU和DPU的計算芯片和系統公司,通過NVLink、NVSwitch和NVLink C2C技術將CPU、GPU進行靈活連接組合形成統一的硬件架構,并于CUDA一起形成完整的軟硬件生態。
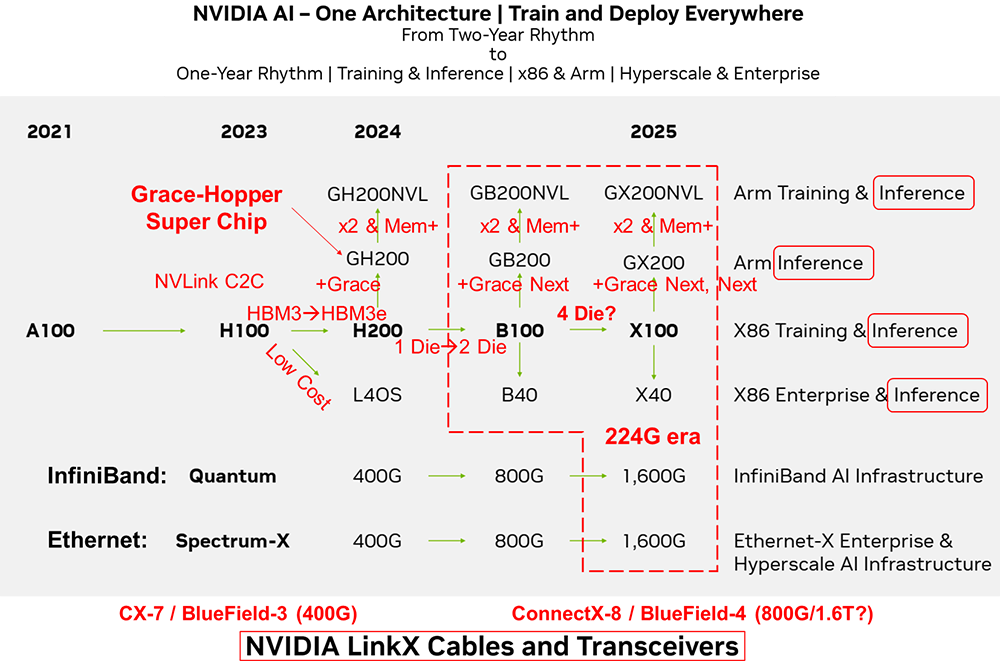
在AI計算芯片架構方面,注重訓練和推理功能的整合,側重推理。圍繞GPU打造Arm和x86兩條技術路線。在NVIDIA的AI路線圖中,并沒有顯示提及Grace CPU的技術路線,而是將其納入Grace+GPU的SuperChip超級芯片路標中。
NVIDIA Grace CPU會跟隨GPU的演進節奏并與其組合成新一代超級芯片;而其自身也可能根據市場競爭的需求組合成CPU超級芯片,實現“二打一”的差異化競爭力。
從需求角度來看,CPU的技術演進速度并不像GPU那樣緊迫,并且CPU對于成本更加敏感。CPU只需按照“摩爾”或“系統摩爾”,以每兩年性能翻倍的速度進行演進即可。而GPU算力需要不到一年就要實現性能翻倍,保持每年大約2.5倍的速率增長。這種差異催生了超級芯片和超節點的出現。
NVIDIA將延用SuperChip超級芯片架構,NVLink-C2C和NVLink互聯技術在NVIDIA未來的AI芯片架構中將持續發揮關鍵作用。
其利用NVLink-C2C互聯技術構建GH200、GB200和GX200超級芯片。更進一步,通過NVLink互聯技術,兩顆GH200、GB200和GX200可以背靠背連接,形成GH200NVL、GB200NVL和GX200NVL模組。NVIDIA可以通過NVLink網絡組成超節點,通過InfiniBand或Ethernet網絡組成更大規模的AI集群。
在交換芯片方面,仍然堅持InfiniBand和Ethernet兩條開放路線,瞄準不同市場,前者瞄準AI Factory,后者瞄準AIGC Cloud。但其并未給出NVLink和NVSwitch自有生態的明確計劃。224G代際的速度提升,可能率先NVLink和NVSwitch上落地。
以InfiniBand為基礎的Quantum系列和以Ethernet基礎的Spectrum-X系列持續升級。預計到2024年,將商用基于100G SerDes的800G接口的交換芯片;而到2025年,將迎來基于200G SerDes的1.6T接口的交換芯片。
其中800G對應51.2T交換容量的Spectrum-4芯片,而1.6T則對應下一代Spectrum-5,其交換容量可能高達102.4T。
從演進速度上看,224G代際略有提速,但從長時間周期上看,其仍然遵循著SerDes速率大約3到4年翻倍、交換芯片容量大約2年翻倍的規律。雖然有提到2024年Quantum將會升級到800G,但目前我們只能看到2021年發布的基于7nm工藝,400G接口的25.6T Quantum-2交換芯片。
路線圖中并未包含NVSwitch 4.0和NVLink 5.0的相關計劃。有預測指出NVIDIA可能會首先在NVSwitch和NVLink中應用224G SerDes技術。NVLink和NVSwitch作為NVIDIA自有生態,不會受到標準生態的掣肘,在推出時間和技術路線選擇上更靈活,從而實現差異化競爭力。
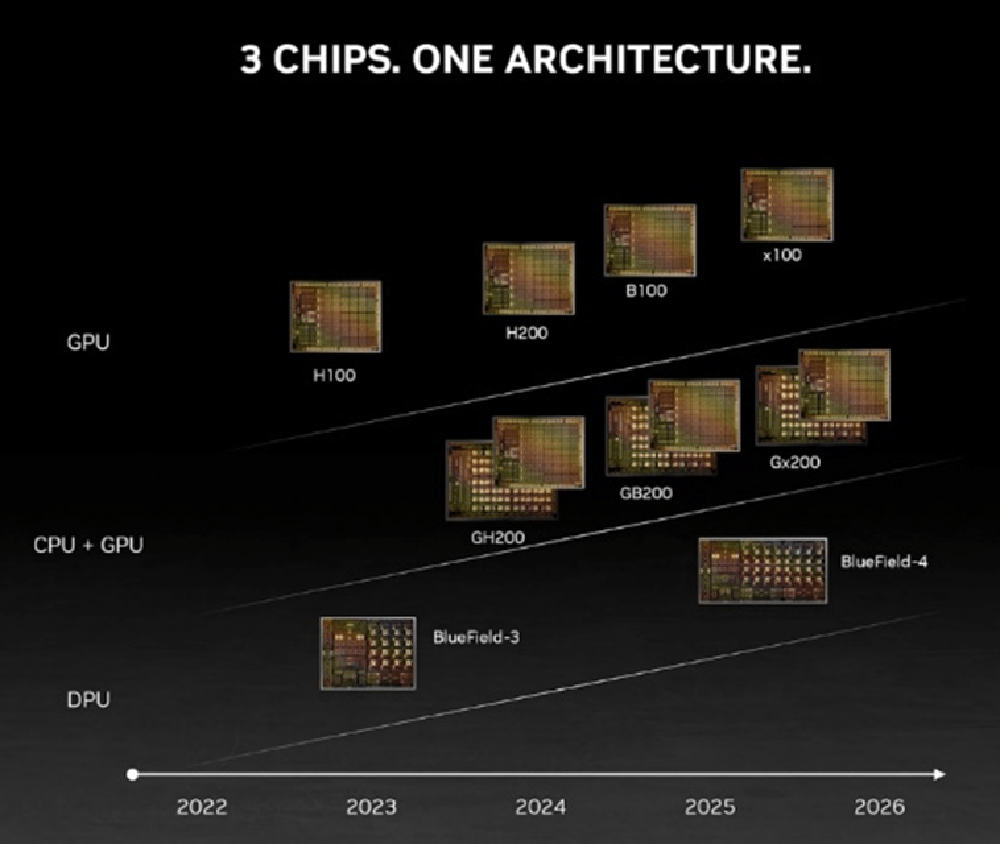
SmartNIC智能網卡/DPU數據處理引擎的下一跳ConnectX-8/BlueField-4目標速率為800G,與1.6T Quantum和Spectrum-X配套的SmartNIC和DPU的路標仍不明晰,NVLink5.0和NVSwitch4.0可能提前發力。
NVIDIA ConnectX系列SmartNIC智能網卡與InfiniBand技術相結合,可以在基于NVLink網絡的超節點基礎上構建更大規模的AI集群。而BlueField DPU則主要面向云數據中心場景,與Ethernet技術結合,提供更強大的網絡基礎設施能力。
相較于NVLink總線域網絡,InfiniBand和Ethernet屬于傳統網絡技術,兩種網絡帶寬比例大約為1:9。例如,H00 GPU用于連接SmartNIC和DPU的PCIe帶寬為128GB/s,考慮到PCIe到Ethernet的轉換,其最大可以支持400G InfiniBand或者Ethernet接口,而NVLink雙向帶寬為900GB/s或者3.6Tbps,因此傳統網絡和總線域網絡的帶寬比為1比9。
雖然SmartNIC和DPU的速率增長需求沒有總線域網絡的增速快,但它們與大容量交換芯片需要保持同步的演進速度。它們也受到由IBTA(InfiniBand)和IEEE802.3(Ethernet)定義互通標準的產業生態成熟度的制約。
互聯技術在未來的計算系統的擴展中起到至關重要的作用。NVIDIA同步布局的還有LinkX系列光電互聯技術。包括傳統帶oDSP引擎的可插拔光互聯(Pluggable Optics),線性直驅光互聯LPO(Linear Pluggable Optics),傳統DAC電纜、重驅動電纜(Redrived Active Copper Cable)、芯片出光(Co-Packaged Optics)等一系列光電互聯技術。隨著超節點和集群網絡的規模不斷擴大,互聯技術將在未來的AI計算系統中發揮至關重要的作用,需要解決帶寬、時延、功耗、可靠性、成本等一系列難題。
對NVIDIA而言,來自Google、Meta、AMD、Microsoft和Amazon等公司的競爭壓力正在加大。這些公司在軟件和硬件方面都在積極發展,試圖挑戰NVIDIA在該領域的主導地位,這或許是NVIDIA提出相對激進技術路線圖的原因。
NVIDIA為了保持其市場地位和利潤率,采取了一種大膽且風險重重的多管齊下的策略。他們的目標是超越傳統的競爭對手如Intel和AMD,成為科技巨頭,與Google、Microsoft、Amazon、Meta和Apple等公司并駕齊驅。
NVIDIA的計劃包括推出H200、B100和“X100”GPU,以及進行每年度更新的AI GPU。此外,他們還計劃推出HBM3E高速存儲器、PCIe 6.0和PCIe 7.0、以及NVLink、224G SerDes、1.6T接口等先進技術,如果計劃成功,NVIDIA將超越所有潛在的競爭對手 [2]。
盡管硬件和芯片領域的創新不斷突破,但其發展仍然受到第一性原理的限制,存在天然物理邊界的約束。通過深入了解工藝制程、先進封裝、內存和互聯等多個技術路線,可以推斷出未來NVIDIA可能采用的技術路徑。
盡管基于第一性原理的推演成功率高,但仍需考慮非技術因素的影響。例如,通過供應鏈控制,在一定時間內壟斷核心部件或技術的產能,如HBM、TSMC CoWoS先進封裝工藝等,可以影響技術演進的節奏。
根據NVIDIA 2023年Q4財報,該公司季度收入達到76.4億美元,同比增長53%,創下歷史新高。全年收入更是增長61%,達到269.1億美元的紀錄。數據中心業務在第四季度貢獻了32.6億美元的收入,同比增長71%,環比增長11%。財年全年數據中心收入增長58%,達到創紀錄的106.1億美元 [3]。
因此NVIDIA擁有足夠大的現金流可以在短時間內對供應鏈,甚至產業鏈施加影響。另外,也存在一些黑天鵝事件也可能產生影響,比如以色列和哈馬斯的戰爭就導致了NVIDIA取消了原定于10月15日和16日舉行的AI SUMMIT [4]。業界原本預期,NVIDIA將于峰會中展示下一代B100 GPU芯片 [5]。值得注意的是,NVIDIA的網絡部門前身Mellanox正位于以色列。
為了避免陷入不可知論,本文的分析主要基于物理規律的第一性原理,而不考慮經濟手段(例如控制供應鏈)和其他可能出現的黑天鵝事件(例如戰爭)等不確定性因素。
當然,這些因素有可能在技術鏈條的某個環節產生重大影響,導致技術或者產品演進節奏的放緩,或者導致整個技術體系進行一定的微調,但不會對整個技術演進趨勢產生顛覆式的影響。
考慮到這些潛在的變化,本文的分析將盡量采取一種客觀且全面的方式來評估這些可能的技術路徑。我們將以“如果A那么X;如果B那么Y;…”的形式進行思考和分析,旨在涵蓋所有可能影響技術發展的因素,以便提供更準確、更全面的分析結果。
此外,本文分析是基于兩到三年各個關鍵技術的路標假設,即2025年之前。當相應的前提條件變化,相應的結論也應該作適當的調整,但是整體的分析思路是普適的。
01. NVIDIA的AI布局
NVIDIA在人工智能領域的布局堪稱全面,其以系統和網絡、硬件和軟件為三大支柱,構建起了深厚的技術護城河 [6]。
有分析稱NVIDIA的H100顯卡有高達90%的毛利率。NVIDIA通過扶持像Coreweave這樣的GPU云服務商,利用供貨合同讓他們從銀行獲取資金,然后購買更多的H100顯卡,鎖定未來的顯卡需求量。
這種模式已經超出傳統硬件公司的商業模式,套用馬克思在資本論中所述“金銀天然不是貨幣,貨幣天然是金銀。”,有人提出了“貨幣天然不是H100,但H100天然是貨幣”的說法 [7]。這一切的背后在于對于對未來奇點臨近的預期 [8],在于旺盛的需求,同時更在于其深厚的技術護城河。
NVIDIA 2019年3月發起對Mellanox的收購 [9],并且于2020年4月完成收購 [10],經過這次收購NVIDIA獲取了InfiniBand、Ethernet、SmartNIC、DPU及LinkX互聯的能力。面向GPU互聯,自研NVLink互聯和NVLink網絡來實現GPU算力Scale Up擴展,相比于基于InfiniBand網絡和基于Ethernet的RoCE網絡形成差異化競爭力。
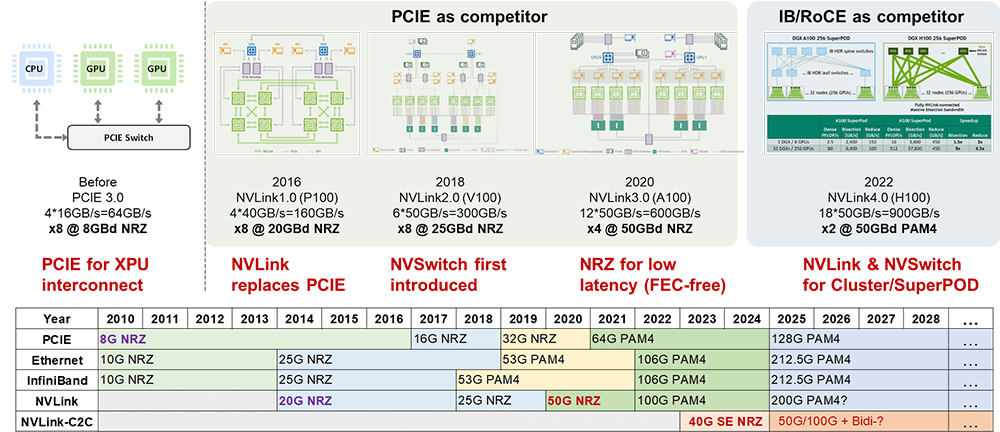
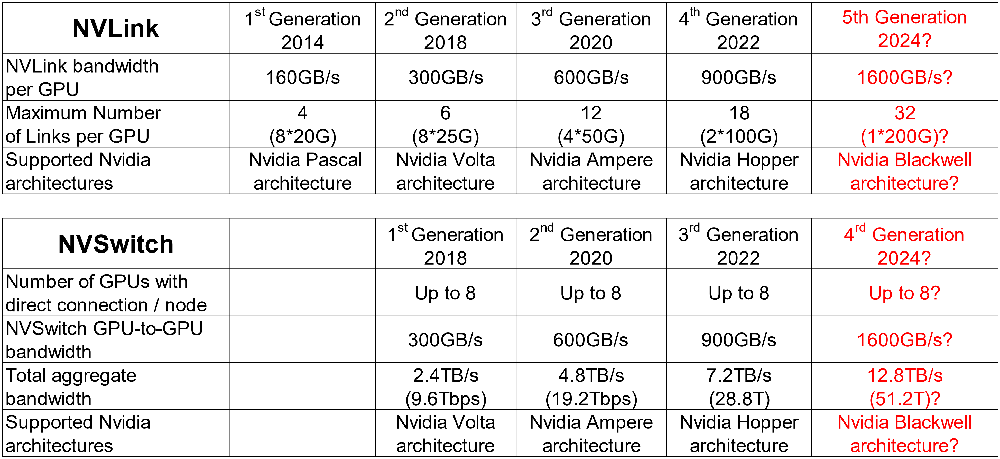
NVLink自2014年推出以來,已經歷了四個代際的演進,從最初的2014年20G NVLink 1.0,2018年25G NVLink 2.0,2020年50G NVLink 3.0 到2022年的100G NVLink 4.0,預計到2024年,NVLink將進一步發展至200G NVLink 5.0。在應用場景上,NVLink 1.0至3.0主要針對PCIe板內和機框內互聯的需求,通過SerDes提速在與PCIe互聯的競爭中獲取顯著的帶寬優勢。
值得注意的是,除了NVLink 1.0采用了20G特殊速率點以外,NVLink 2.0~4.0皆采用了與Ethernet相同或者相近的頻點,這樣做的好處是可以復用成熟的Ethernet互聯生態,也為未來實現連接盒子或機框組成超節點埋下伏筆。
NVSwitch 1.0、2.0、3.0分別與NVLink 2.0、3.0、4.0配合,形成了NVLink總線域網絡的基礎。NVLink4.0配合NVSwitch3.0組成了超節點網絡的基礎,這一變化的外部特征是NVSwitch脫離計算單板而單獨成為網絡設備,而NVLink則從板級互聯技術升級成為設備間互聯技術。
在計算芯片領域,NVIDIA于2020年9月發起Arm收購,期望構建人工智能時代頂級的計算公司 [11],這一收購提案因為面臨重大監管挑戰阻礙了交易的進行,于2022年2月終止 [12]。但是,在同年3月其發布了基于Arm的Grace CPU Superchip超級芯片 [13]。成為同時擁有CPU、GPU和DPU的計算芯片和系統公司。
從業務視角看,NVIDIA在系統和網絡、硬件、軟件三個方面占據了主導地位 [6]。
系統和網絡、硬件、軟件這三個方面是人工智能價值鏈中許多大型參與者無法有效或快速復制的重要部分,這意味著NVIDIA在整個生態系統中占據著主導地位。
要擊敗NVIDIA就像攻擊一個多頭蛇怪。必須同時切斷所有三個頭才有可能有機會,因為它的每個“頭”都已經是各自領域的領導者,并且NVIDIA正在努力改進和擴大其護城河。
在一批人工智能硬件挑戰者的失敗中,可以看到,他們都提供了一種與NVIDIA GPU相當或略好的硬件,但未能提供支持該硬件的軟件生態和解決可擴展問題的方案。而NVIDIA成功地做到了這一切,并成功抵擋住了一次沖擊。這就是為什么NVIDIA的戰略像是一個三頭水蛇怪,后來者必須同時擊敗他們在系統和網絡、硬件以及軟件方面的技術和生態護城河。
目前,進入NVIDIA平臺似乎能夠占據先機。OpenAI、微軟和NVIDIA顯然處于領先地位。盡管Google和Amazon也在努力建立自己的生態系統,但NVIDIA提供了更完整的硬件、軟件和系統解決方案,使其成為最具吸引力的選擇。
要贏得先機,就必須進入其硬件、軟件和系統級業務生態。然而,這也意味著進一步被鎖定,未來更難撼動其地位。從Google和Amazon等公司的角度來看,如果不選擇接入NVIDIA的生態系統,可能會失去先機;而如果選擇接入,則可能意味著失去未來。
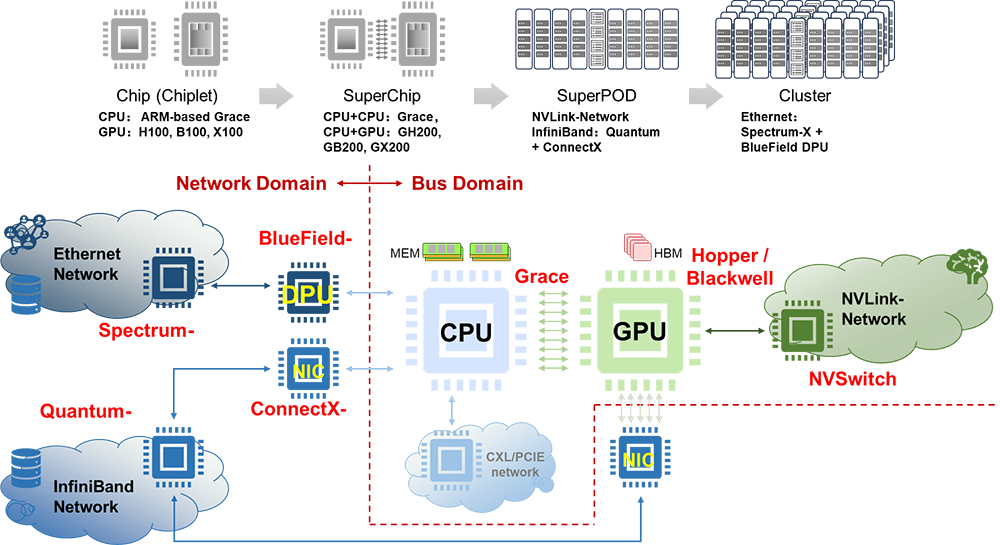
NVIDIA布局了兩種類型網絡,一種是傳統InfiniBand和Ethernet網絡,另一種是NVLink總線域網絡。
在傳統網絡中,Ethernet面向AIGC Cloud多AI訓練和推理等云服務,而InfiniBand面向AI Factory,滿足大模型訓練和推理的應用需求。在交換芯片布局方面,有基于開放Ethernet增強的Spectrum-X交換芯片和基于InfiniBand的封閉高性能的Quantum交換芯片。
當前Ultra Ethernet Consortium(UEC)正在嘗試定義基于Ethernet的開放、互操作、高性能的全棧架構,以滿足不斷增長的AI和HPC網絡需求 [14],旨在與NVIDIA的網絡技術相抗衡。
UEC的目標是構建一個類似于InfiniBand的開放協議生態,從技術層面可以理解為將Ethernet進行增強以達到InfiniBand網絡的性能,或者說是實現一種InfiniBand化的Ethernet。
從某種意義上說UEC在重走InfiniBand道路。總線域網絡NVLink的主要特征是要在超節點范圍內實現內存語義級通信和總線域網絡內部的內存共享,它本質上是一個Load-Store網絡,是傳統總線網絡規模擴大以后的自然演進。
從NVLink接口的演進歷程可以看出,其1.0~3.0版本明顯是對標PCIe的,而4.0版本實際上對標InfiniBand和Ethernet的應用場景,但其主要目標還是實現GPU的Scale Up擴展。
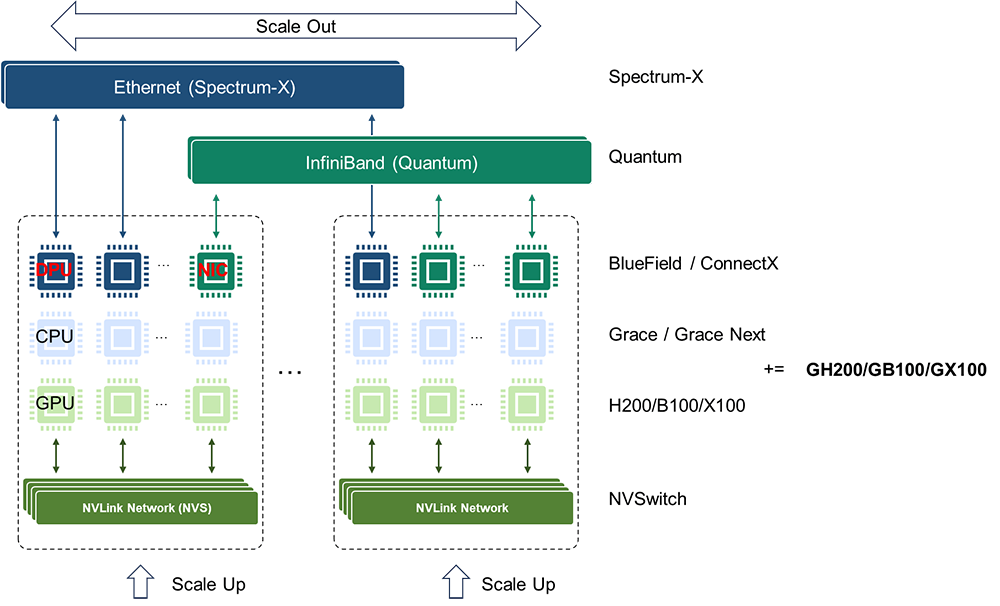
從原始需求的角度來看,NVLink網絡在演進過程中需要引入傳統網絡的一些基本能力,例如編址尋址、路由、均衡、調度、擁塞控制、管理控制和測量等。
同時,NVLink還需要保留總線網絡基本特征,如低時延、高可靠性、內存統一編址共享以及內存語義通信。這些特征是當前InfiniBand或Ethernet網絡所不具備的或者說欠缺的。
與InfiniBand和Ethernet傳統網絡相比,NVLink總線域網絡的功能定位和設計理念存在著本質上的區別。我們很難說NVLink網絡和傳統InfiniBand網絡或者增強Ethernet網絡最終會殊途同歸。
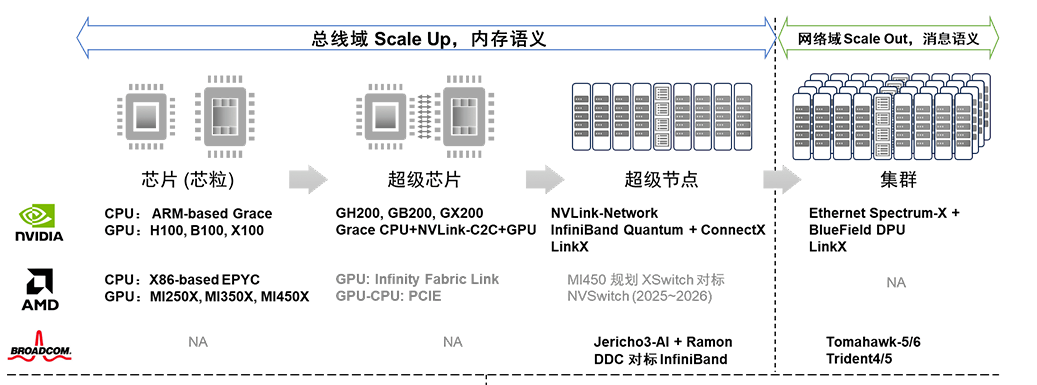
NVIDIA在AI集群競爭態勢中展現出了全面布局,涵蓋了計算(芯片、超級芯片)和網絡(超節點、集群)領域。
在計算芯片方面,NVIDIA擁有CPU、GPU、CPU-CPU/CPU-GPU SuperChip等全面的布局;在超節點網絡層面,Nvidia提供了NVLink和InfiniBand兩種定制化網絡選項;在集群網絡方面,NVIDIA有基于Ethernet的交換芯片和DPU芯片布局。
AMD緊隨其后,更專注于CPU和GPU計算芯片,并采用基于先進封裝的Chiplet芯粒技術。
與NVIDIA不同的是,AMD當前沒有超級芯片的概念,而是采用了先進封裝將CPU和GPU Die合封在一起。AMD使用私有的Infinity Fabric Link內存一致接口進行GPU、CPU、GPU和CPU間的互聯,而GPU和CPU之間的互聯仍然保留傳統的PCIe連接方式。
此外,AMD計劃推出XSwitch交換芯片,下一代MI450加速器將利用新的互連結構,其目的顯然是與NVIDIA的NVSwitch競爭 [15]。
BRCM則專注于網絡領域,在超節點網絡有對標InfiniBand的Jericho3-AI+Ramon的DDC方案;在集群網絡領域有基于Ethernet的Tomahawk系列和Trident系列交換芯片。
近期BRCM推出其新的軟件可編程交換Trident 5-X12集成了NetGNT神經網絡引擎實時識別網絡流量信息,并調用擁塞控制技術來避免網絡性能下降,提高網絡效率和性能 [16]。
Cerebras/Telsa Dojo則“劍走偏鋒”,走依賴“晶圓級先進封裝”的深度定制硬件路線。
02. 工程工藝洞察和推演假設
1、半導體工藝演進洞察
根據IRDS的樂觀預測,未來5年,邏輯器件的制造工藝仍將快速演進,2025年會初步實現Logic器件的3D集成。TSMC和Samsung將在2025年左右開始量產基于GAA(MBCFET)的2nm和3nm制程的產品 [17]。
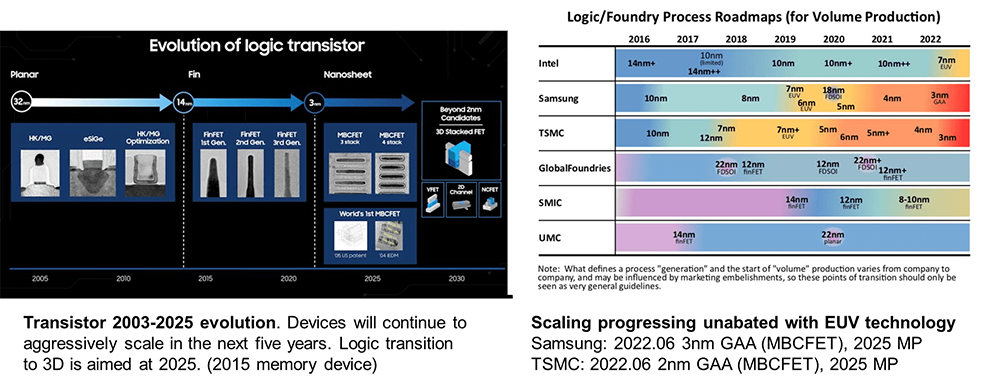
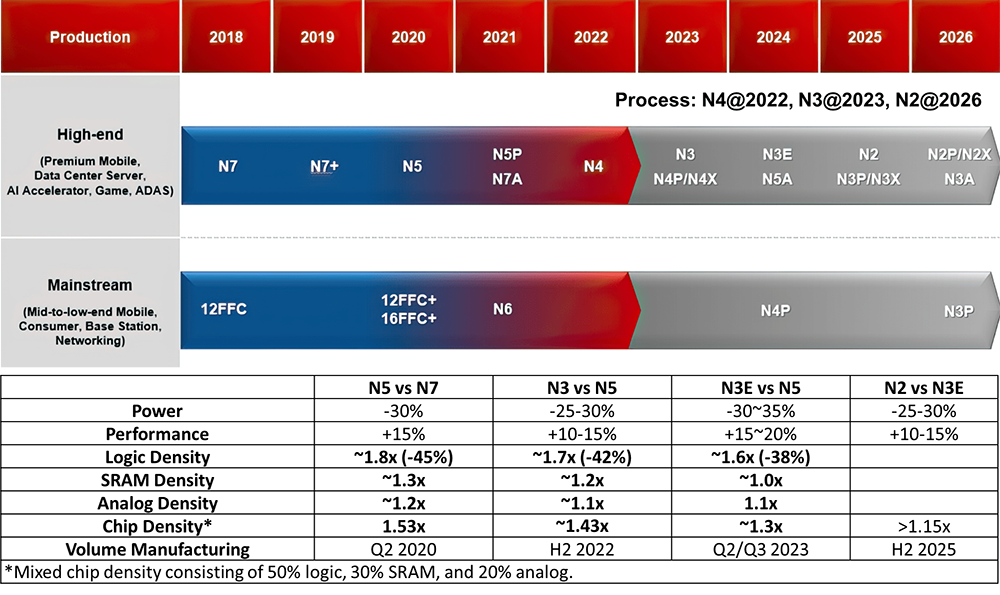
按照TSMC給出的工藝演進路標,2023~2025年基本以3nm工藝為主,2nm工藝在2025年以后才會發布。3nm技術已經進入量產階段,N3工藝和N3E版本已經于2023年推出。2024年下半年開始生產N3P版本,該版本將提供比N3E更高的速度、更低的功耗和更高的芯片密度。此外,N3X版本將專注于高性能計算應用,提供更高的時鐘頻率和性能,預計將于2025年開始量產 [18]。工藝演進的收益對于邏輯器件的收益小于50%,因此,未來單芯片算力提升將更依賴于先進封裝技術。
2、先進封裝演進洞察
TSMC的CoWoS先進封裝工藝封裝基板的尺寸在2023年為4倍Reticle面積,2025年將達到6倍Reticle面積 [19]。當前NVIDIA H100 GPU的封裝基板尺寸小于2倍Reticle面積,AMD的MI300系列GPU的封裝基板尺寸大約為3.5倍Reticle面積,逼近當前TSMC CoWoS-L工藝的極限。
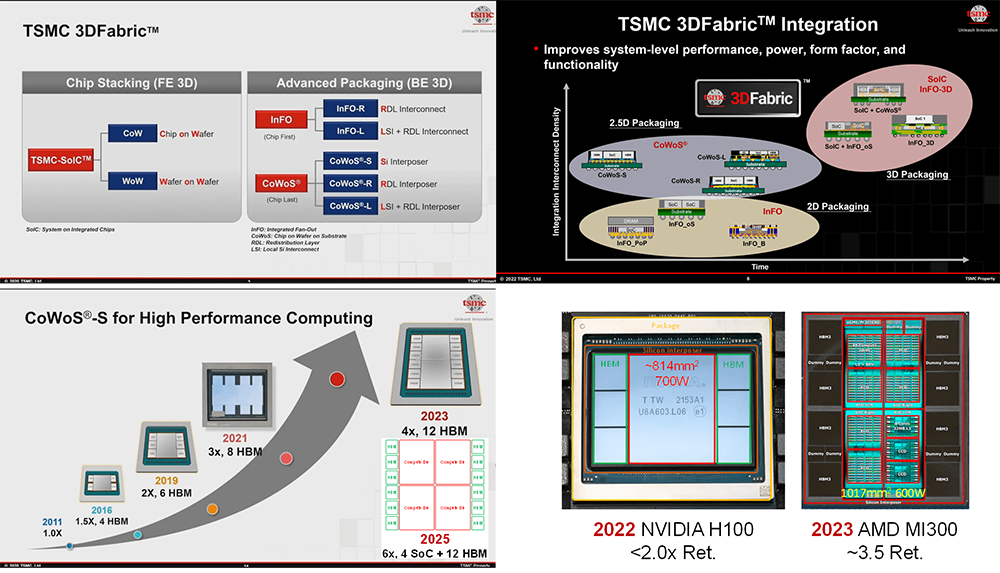
3、HBM內存演進洞察
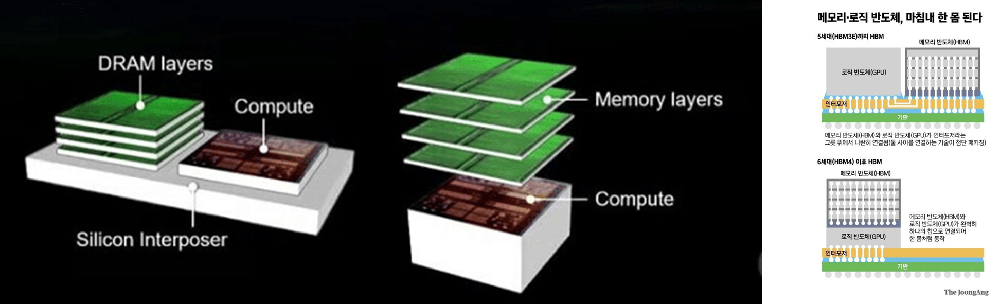
HBM內存的容量預計將在2024年達到24GB,并在2025年進一步增長至36GB [20]。HBM4預計將帶來兩個重要的變化:首先,HBM接口位寬將從1024擴展到2048;其次,業界正在嘗試將HBM內存Die直接堆疊在邏輯Die的上方 [21][22]。這兩個變化意味著HBM內存的帶寬和單個封裝內能容納的容量都將持續增長。

據報道,SK海力士已經開始招聘CPU和GPU等邏輯半導體的設計人員。該公司顯然正在考慮將HBM4直接堆疊在處理器上,這不僅會改變邏輯和存儲器設備的傳統互連方式,還會改變它們的制造方式。事實上,如果SK海力士成功實現這一目標,這可能會徹底改變芯片代工行業 [21][22]。
4、推演假設
本文基于兩個前提假設來推演NVIDIA未來AI芯片的架構演進。首先,每一代AI芯片的存儲、計算和互聯比例保持大致一致,且比上一代提升1.5到2倍以上;其次,工程工藝演進是漸進且可預測的,不存在跳變,至少在2025年之前不會發生跳變。
到2025年,工藝將保持在3nm水平,但工藝演進給邏輯器件帶來的收益預計不會超過50%。同時,先進封裝技術預計將在2025年達到6倍Reticle面積的水平。此外,HBM內存容量也將繼續增長,預計在2024年將達到24GB,而在2025年將達到36GB。
03. NVIDIA AI芯片架構解讀
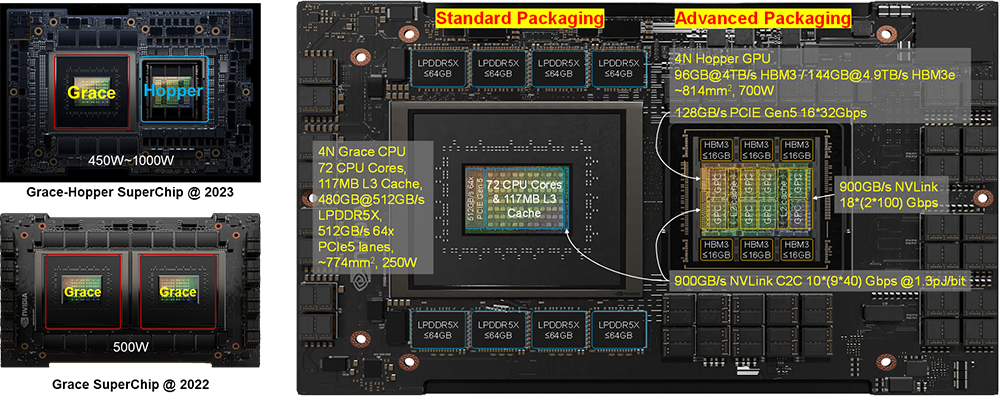
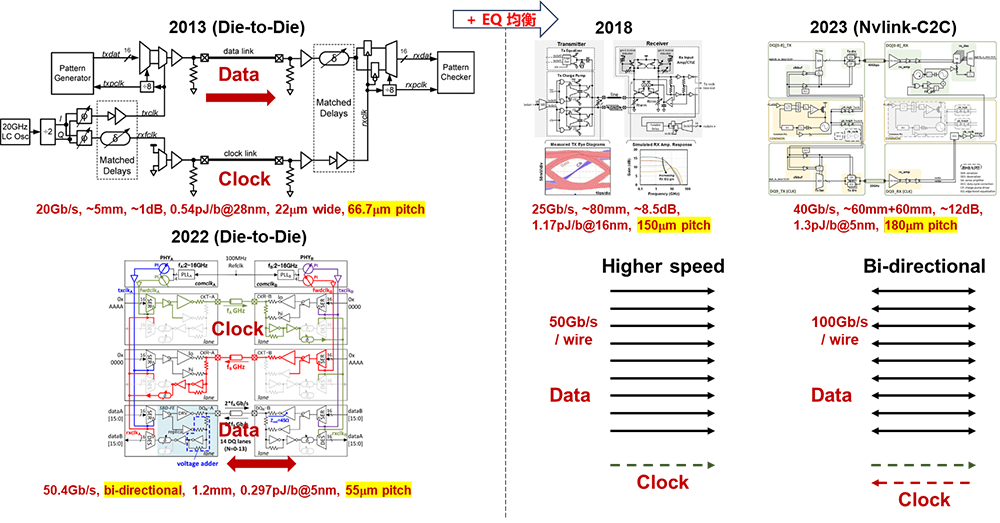
互聯技術在很大程度上決定了芯片和系統的物理架構。NVIDIA利用NVLink-C2C這種低時延、高密度、低成本的互聯技術來構建SuperChip超級芯片,旨在兼顧性能和成本打造差異化競爭力。與傳統的SerDes互聯相比,NVLink C2C采用了高密度單端架構和NRZ調制,使其在實現相同互聯帶寬時能夠在時延、功耗、面積等方面達到最佳平衡點;而與Chiplet Die-to-Die互聯相比,NVLink C2C具備更強的驅動能力,并支持獨立封裝芯片間的互聯,因此可以使用標準封裝,滿足某些芯片的低成本需求。
為了確保CPU和GPU之間的內存一致性操作(Cache-Coherency),對于NVLink C2C接口有極低時延的要求。
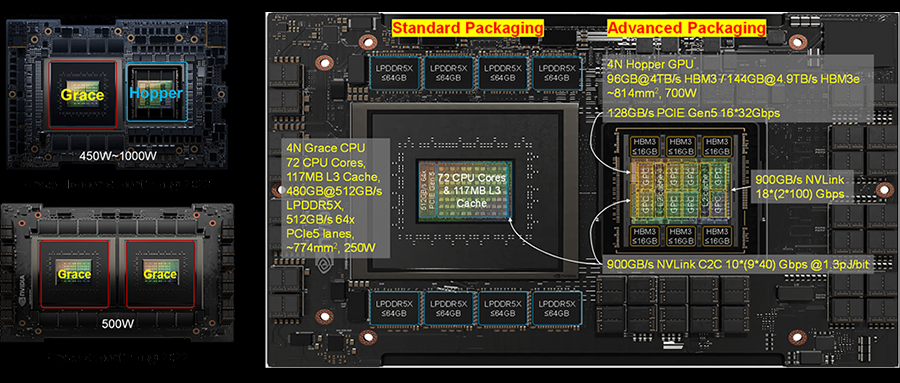
H100 GPU的左側需要同時支持NVLink C2C和PCIe接口,前者用于實現與NVIDIA自研Grace CPU組成Grace-Hopper SuperChip,后者用于實現與PCIe交換芯片、第三方CPU、DPU、SmartNIC對接。NVLink C2C的互聯帶寬為900GB/s,PCIe互聯帶寬為128GB/s。
而當Hopper GPU與Grace CPU組成SuperChip時,需要支持封裝級的互聯。值得注意的是,Grace CPU之間也可以通過NVLink C2C互聯組成Grace CPU SuperChip。考慮到成本因素,NVIDIA沒有選擇采用雙Die合封的方式組成Grace CPU,而是通過封裝間的C2C互聯組成SuperChip超級芯片。
從時延角度來看,NVLink C2C采用40Gbps NRZ調制,可以實現無誤碼運行(BER《1e-12),免除FEC,接口時延可以做到小于5ns。相比之下,112G DSP架構的SerDes本身時延可以高達20ns,因為采用了PAM4調制,因此還需要引入FEC,這會額外增加百納秒量級的時延。此外,NVLink C2C采用了獨立的時鐘線來傳遞時鐘信號,因此數據線上的信號不需要維持通信信號直流均衡的編碼或擾碼,可以進一步將時延降低到極致。
因此,引入NVLink C2C的主要動機是滿足芯片間低時延互聯需求。
從互聯密度來看,當前112G SerDes的邊密度可以達到12.8Tbps每邊長,遠遠大于當前H100的(900+128)GB/s * 8/2 = 4.112Tbps的邊密度需求。NVLink C2C的面密度是SerDes的3到4倍,(169Gbps/mm2 vs. 552Gbps/mm2)。而當前NVLink C2C的邊密度還略低于SerDes(281Gbps/mm vs. 304Gbps/mm)。更高的邊密度顯然不是NVLink C2C需要解決的主要矛盾。
從驅動能力來看,112G SerDes的驅動能力遠大于NVLink C2C。這在一定程度上會制約NVLink C2C的應用范圍,未來類似于NVLink C2C的單端傳輸線技術有可能進一步演進,拓展傳輸距離,尤其是在224G及以上SerDes時代,芯片間互聯更加依賴于電纜解決方案,這對與計算系統是不友好的,會帶來諸如芯片布局、散熱困難等一系列工程挑戰,同時也需要解決電纜方案成本過高的問題。
從功耗來看,112G SerDes的功耗效率為5.5pJ/bit,而NVLink C2C的功耗效率為1.3pJ/bit。在3.6Tbps互聯帶寬下,SerDes和NVLink C2C的功耗分別為19.8W和4.68W。雖然單獨考慮芯片間互聯時,功耗降低很多,但是H100 GPU芯片整體功耗大約為700W,因此互聯功耗在整個芯片功耗中所占比例較小。
從成本角度來看,NVLink C2C的面積和功耗優于SerDes互聯。因此,在提供相同互聯帶寬的情況下,它可以節省更多的芯片面積用于計算和緩存。然而,考慮到計算芯片并不是IO密集型芯片,因此這種成本節約的比例并不顯著。但是,如果將雙Chiplet芯粒拼裝成更大規模的芯片時,NVLink C2C可以在某些場景下可以避免先進封裝的使用,這對降低芯片成本有明顯的幫助,例如Grace CPU SuperChip超級芯片選擇標準封裝加上NVLink C2C互聯的方式進行擴展可以降低成本。在當前工藝水平下,先進封裝的成本遠高于邏輯Die本身。
C2C互聯技術的另一個潛在的應用場景是大容量交換芯片,當其容量突破200T時,傳統架構的SerDes面積和功耗占比過高,給芯片的設計和制造帶來困難。在這種情況下,可以利用出封裝的C2C互聯技術來實現IO的扇出,同時盡量避免使用先進的封裝技術,以降低成本。然而,目前的NVLink C2C技術并不適合這一應用場景,因為它無法與標準SerDes實現比特透明的轉換。因此,需要引入背靠背的協議轉換,這會增加時延和面積功耗。
Grace CPU具有上下翻轉對稱性,因此單個芯片設計可以支持同構Die組成SuperChip超級芯片。Hopper GPU不具備上下和左右翻轉對稱性,未來雙Die B100 GPU芯片可能由兩顆異構Die組成。
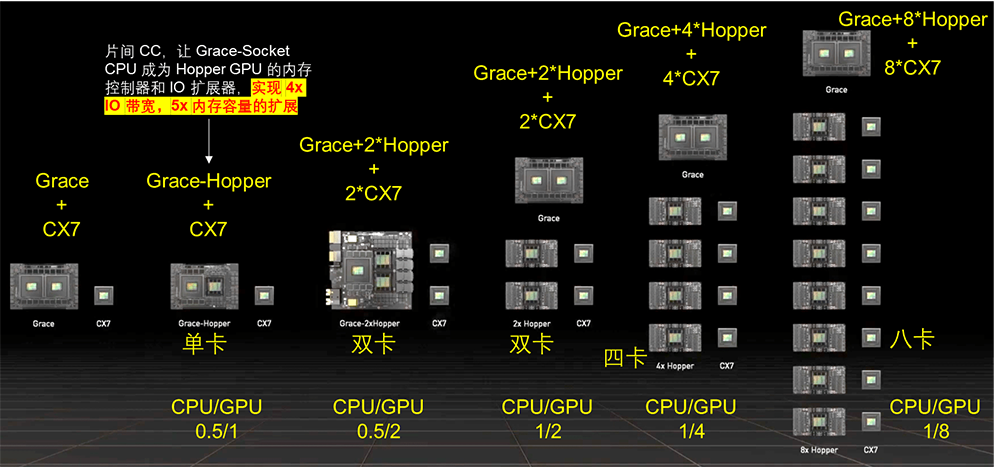
NVLink和NVLink C2C技術提供了更靈活設計,實現了CPU和GPU靈活配置,可以構建滿足不同應用需求的系統架構。NVLink C2C可以提供靈活的CPU、GPU算力配比,可組成 1/0,0.5/1,0.5/2,1/4,1/8等多種組合的硬件系統。
NVLink C2C支持Grace CPU和Hopper GPU芯片間內存一致性操作(Cache-Coherency),讓Grace CPU成為Hopper GPU的內存控制器和IO擴展器,實現了4倍IO帶寬和5倍內存容量的擴展。這種架構打破了HBM的瓶頸,實現了內存超發。對訓練影響是可以緩存更大模型,利用ZeRO等技術外存緩存模型,帶寬提升能減少Fetch Weight的IO開銷。對推理影響是可以緩存更大模型,按需加載模型切片推理,有可能在單CPU-GPU超級芯片內完成大模型推理 [23]。
有媒體測算NVIDIA的H100利潤率達到90%。同時也給出了估算的H100的成本構成,NVIDIA向臺積電下訂單,用N4工藝制造GPU芯片,平均每顆成本155美元。NVIDIA從SK海力士(未來可能有三星、美光)采購六顆 HBM3芯片,成本大概2000美元。臺積電生產出來的GPU和NVIDIA采購的HBM3芯片,一起送到臺積電CoWoS封裝產線,以性能折損最小的方式加工成H100,成本大約723美元 [24]。
先進封裝成本高,是邏輯芯片裸Die成本的3到4倍以上, GPU內存的成本占比超過60%。按照DDR: 5美金/GB,HBM: 15美金/GB以及參考文獻 [25][26] 中給出的GPU計算Die和先進封裝的成本測算,H100 GPU HBM成本占比為62.5%;GH200中HBM和LPDDR的成本占比為78.2%。

雖然不同來源的信息對各個部件的絕對成本估算略有不同,但可以得出明確的結論:內存在AI計算系統中的成本占比可高達60%到70%以上;先進封裝的成本是計算Die成本的3到4倍以上。在接近Reticle面積極限的大芯片良率達到80%的情況下,先進封裝無法有效地降低成本。因此,應該遵循非必要不使用的原則。
04. 與AMD和Intel GPU架構對比
AMD的GPU相對于NVIDIA更加依賴先進封裝技術。MI250系列GPU采用了基于EFB硅橋的晶圓級封裝技術,而MI300系列GPU則應用了AID晶圓級有源封裝基板技術。相比之下,NVIDIA并沒有用盡先進封裝的能力,一方面在當前代際的GPU中保持了相對較低的成本,另一方面也為下一代GPU保留了一部分工程工藝的價值發揮空間。
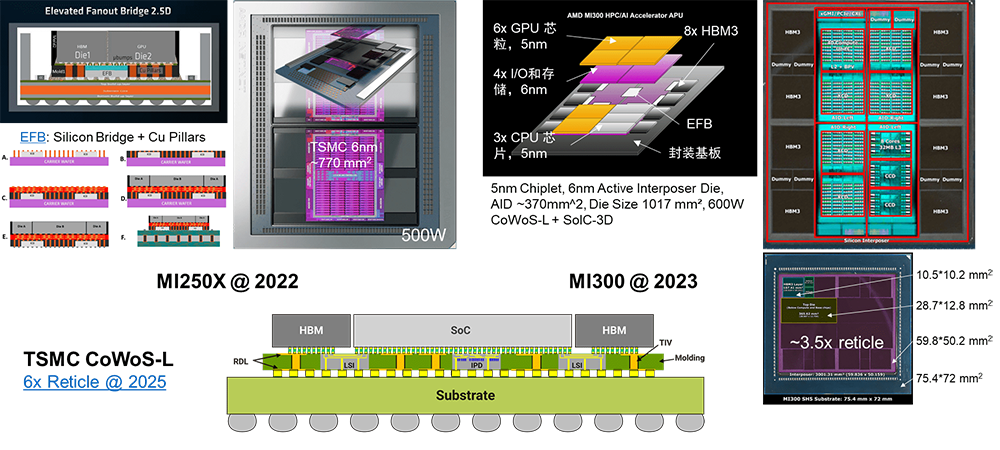
Intel Ponte Vecchio GPU將Chiplet和先進封裝技術推向了極致,它涉及5個工藝節點(包括TSMC和Intel兩家廠商的不同工藝),47個有源的Tile,并同時采用了EMIB 2.5D和Foveros 3D封裝技術。可以說,它更像是一個先進封裝技術的試驗場。
Intel的主力AI芯片是Gaudi系列AI加速芯片 [27][28][29]。值得注意的是,Gaudi系列AI芯片是由TSMC代工的,Gaudi 2采用的是TSMC 7nm工藝,Gaudi 3采用的是TSMC 5nm工藝。

05. NVIDIA未來AI芯片架構推演
1、NVLink和NVLink C2C演進推演
互聯技術在很大程度上塑造了芯片和系統的物理架構。從互聯技術的發展歷程出發,以芯片布局為線索,并考慮工程工藝的物理限制,可以對NVIDIA未來AI芯片架構進行預測。這種推演也有助于發掘對互聯技術的新需求。
互聯技術的演進是一個漸進的過程,其基本技術要素如帶寬、調制和編碼等都遵循著其內在的發展規律。這些物理規律相對穩定,通過將這些技術進行組合并結合當前工程工藝的發展趨勢以及需求,就可以大致描繪和預測出互聯技術的發展方向。在這里不深入探討晦澀難懂的互聯技術本身的發展,而是從宏觀技術邏輯和外在可觀察的指標兩個角度出發,探討NVLink和NVLink C2C的歷史演進,并對其未來發展進行預測。
從NVLink的演進看,當前其演進了四個代際,NVLink C2C當前只有一個代際,通過與當下不同協議的速率演進對比及NVLink宣傳材料,可以清晰的看到每個代際的NVLink技術的競爭對手和其要解決的痛點問題。
當前接口有兩大開放的互聯生態,PCIe互聯生態和Ethernet互聯生態,CXL協議依托于PCIe互聯生態,而InfiniBand則依托與Ethernet互聯生態。
NVLink的主要目標是解決GPU之間的互聯問題,而早期的GPU一定需要保留與CPU互聯的PCIe接口,用于GPU互聯是也天然的繼承了這一技術,因此NVLink早期的競爭對手是PCIe。從PCIe、Ethernet和NVLink的發展軌跡來看,NVLink的SerDes速率介于同時期PCIe和Ethernet SerDes速率之間。
這意味著NVLink利用了Ethernet生態成熟的互聯技術來對抗PCIe,實現接口速率超越PCIe。通過復用Ethernet生態的成熟互聯技術,NVLink在成本方面也具有優勢。
值得注意的是,NVLink并未完全遵循Ethernet的互聯技術規范。例如,在50G NVLink 3.0采用了NRZ調制,而不是Ethernet所采用的PAM4調制 [30]。
這意味著NVLink 3.0利用了100Gbps PAM4 SerDes代際的技術,并通過采用更低階NRZ調制來實現鏈路的無誤碼運行,免去FEC實現低時延。
同樣以低時延著稱的InfiniBand在50G這一代際則完全遵從了Ethernet的PAM4調制,這在一定程度上使其在50G這一代際喪失了低時延的技術優勢,市場不得不選擇長期停留在25G代際的InfiniBand網絡上。
當然,InfiniBand網絡也有其無奈之處,因為它需要復用Ethernet光模塊互聯生態,所以它必須完全遵循Ethernet的互聯電氣規范,而與之對應的NVLink 3.0則只需要解決盒子內或機框內互聯即可。
同樣的事情也會在100G代際的NVLink 4.0上發生,NVLink 4.0完全擺脫了盒子和框子的限制,實現了跨盒子、跨框的互聯,此時為了復用Ethernet的光模塊互聯生態,NVLink 4.0的頻點和調制格式也需要遵從Ethernet互聯的電氣規范。
以前InfiniBand遇到的問題,NVLink也同樣需要面對。在100G時代,可以觀察到Ethernet、InfiniBand和NVLink的SerDes速率在時間節奏上齊步走的情況。實際上,這三種互聯接口都采用了完全相同的SerDes互聯技術。同樣的情況在200G這一代際也會發生。
與InfiniBand和Ethernet不同的是,NVLink是一個完全私有的互聯生態,不存在跨速率代際兼容、同代際支持多種速率的接口和多廠商互通的問題。因此,在技術選擇上,NVLink可以完全按照具體應用場景下的需求來選擇設計甜點,在推出節奏上可以根據競爭情況自由把控,也更容易實現差異化競爭力和高品牌溢價。
NVLink的發展可以分為兩個階段。
NVLink 1.0~3.0主要在盒子內、機框內實現GPU高速互聯,對標PCIe。它利用了Ethernet SerDes演進更快的優勢,采用了更高速的SerDes,同時在NVLink2.0時代開始引入NVSwitch技術,在盒子內、機框內組成總線域網絡,在帶寬指標上對PCIE形成了碾壓式的競爭優勢。
NVLink 4.0以后NVLink走出盒子和機框,NVSwitch走出計算盒子和機框,獨立成為網絡設備,此時對標的是InfiniBand和Ethernet網絡。
雖然NVLink 4.0沒有公開的技術細節,但是從NVLink網絡的Load-Store網絡定位和滿足超節點內部內存共享的需求上看,一個合理的推測是,NVLink 4.0很可能采用了輕量FEC加鏈路級重傳的技術支持低時延和高可靠互聯。在時延和可靠性競爭力指標上對InfiniBand和Ethernet形成碾壓式的競爭力,這更有利于實現內存語義網絡,支持超節點內內存共享。提供傳統網絡所不能提供的關鍵特性,才是NVLink作為總線域網絡獨立存在的理由。
基于NVLink C2C的產品目前只有GH200這一代,但是從NVIDIA在該領域公開發表的論文中可以大致看出其技術發展的脈絡。從技術演進上看,它是封裝內Die間互聯的在均衡上的增強。從NVIDIA SuperChip超級芯片路標來看,它將在未來的AI芯片中繼續發揮重要作用。對于這類接口,仍需保持連接兩個獨立封裝芯片的能力和極低的時延和功耗。
當前的NVLink C2C采用9*40Gbps NRZ調制方式。
未來NVLink-C2C可能會向更高速率和雙向傳輸技術方向演進。而50G NRZ是C2C互聯場景下在功耗和時延方面的設計甜點。繼續維持NRZ調制,選擇合適工作頻率,走向雙向傳輸將是實現速率翻倍的重要技術手段。
雖然NVLink C2C針對芯片間互聯做了優化設計,但由于它與標準SerDes之間不存在速率對應關系,無法實現與標準SerDes之間比特透明的信號轉換,因此其應用場景受限。在與標準SerDes對接時需要多引入一層協議轉化會增加時延、面積和功耗開銷。 未來可能存在一種可
能性,即采用類似NVLink C2C這種高密單端傳輸技術,同時與標準SerDes實現多對一的速率匹配,這種技術一旦實現將極大地擴展C2C高密單端互聯技術的應用空間,也有可能開啟SerDes面向更高速率演進的新賽道。
從NVLink和NVSwitch的演進來看,每一代速率會是上一代的1.5到2倍。下一代NVLink 5.0大概率會采用200G每通道,每個GPU能夠出的NVLink接口數量從18個增加到32個,甚至更高。而NVSwitch 4.0在端口速率達到200G以外,交換芯片的端口數量可能在NVSwitch 3.0交換芯片64端口的基礎上翻2倍甚至4倍,總交換容量從12.8T到25.6T甚至51.2T [30]。
2、B100 GPU架構推演
以H100 GPU芯片布局為基礎,通過先進的封裝技術將兩顆類似H100大小的裸Die進行合封,可以推演B100 GPU架構。 B100 GPU有兩種“雙Die”推演架構:IO邊縫合和HBM邊縫合[31][32]。“HBM邊縫合”利用H100的HBM邊進行雙Die連接,這種方案的優點在于,它可以使得IO可用邊長翻倍,從而有利于擴展IO帶寬。然而,它的缺點在于HBM可用邊長并沒有改變,因此無法進一步擴展HBM容量。 “IO邊縫合”利用H100的IO邊進行雙Die連接,這種方案的優勢在于HBM可用邊長能夠翻倍,從而有利于擴展內存。然而,它的缺點在于IO可用邊長并未改變,因此需要進一步提升IO密度。考慮到每代芯片與上一代相比,在內存、算力、互聯三個層面需要實現兩倍以上的性能提升,采用“IO 邊縫合”方案的可能性更大。采用“IO 邊縫合”的方案需要提升IO的邊密度。

H100不具備旋轉對對稱性,而雙Die的B100仍需支持GH200 SuperChip超級芯片,因此B100可能由兩顆異構Die組成。按照不同的長寬比采用“IO邊縫合的方式”B100的面積達到3.3到3.9倍的Reticle面積,小于當前TSMC CoWoS先進封裝能夠提供的4倍Reticle面積的能力極限。計算Die之間互聯可以復用 NVLink C2C 互聯技術,既利用NVLink C2C出封裝的連接能力覆蓋Die間互聯的場景。
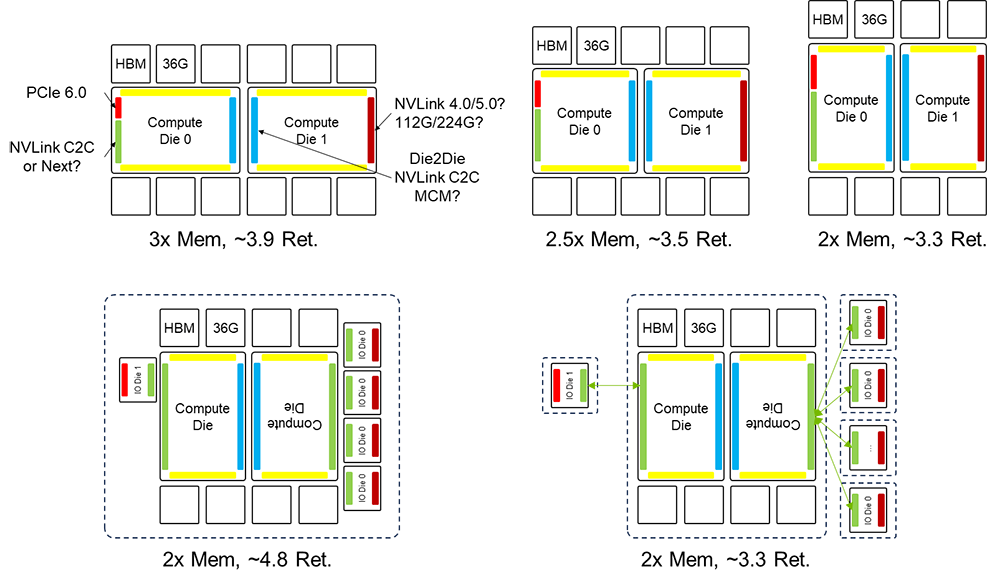
為了實現計算Die的歸一化,可以將IO從計算Die中分離出來,形成獨立的IO Die。這樣,計算Die的互聯接口就實現了歸一化,使計算Die具備了旋轉對稱性。 在這種情況下,仍然存在兩種架構:一種是同構計算Die與IO Die合封,另一種是計算Die與IO Die分別封裝并用C2C互聯將二者連接。計算Die的同構最大的優勢在于可以實現芯片的系列化。通過靈活組合計算Die和IO Die,可以實現不同規格的芯片以適應不同的應用場景的需求。
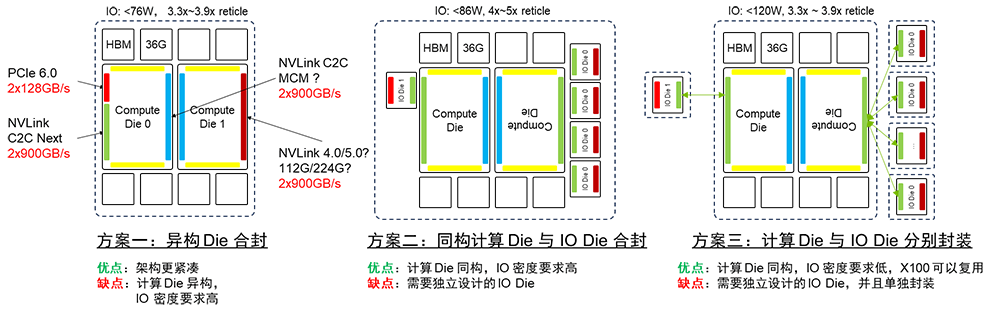
NVIDIA B100有“異構Die合封”,“計算Die與IO Die分離,同構計算Die與IO Die合封”,“計算Die與IO Die分離并分別封裝,并用C2C互聯將二者連接”三種架構選項。 NVIDIA B100如果采用單封裝雙Die架構,封裝基板面積達到3.3~3.9倍Reticle面積,功耗可能超過1kW。計算Die之間互聯可以復用NVLinkC2C互聯技術。 將計算Die和IO Die分離可以實現計算Die的同構化,降低成本。利用NVLink C2C出封裝互聯的能力,可以將IO扇出,降低IO邊密度壓力。需要注意的是,當前NVLink C2C速率與PCIe & NVLink的SerDes無法匹配,因此需要IO Die上作協議轉換,無法做到協議無關。 如果C2C互聯和SerDes速率能夠進行多對一的匹配實現比特透明的CDR,這樣可以消除協議轉換的開銷。考慮到B100 2024年推出的節奏,方案一、三匹配當前先進封裝能力,但方案三需要引入額外的協議轉換;方案二超出當前先進封裝能力。
注:其中關于Blackwell架構的謎底已經在美國圣何塞當地時間3月18日舉行的NVIDIA GTC大會上揭曉,詳情可參見《詳解最強AI芯片架構:英偉達Blackwell GPU究竟牛在哪?》。對于采用兩個GPU Die+1個CPU的GH200架構,陸玉春博士補充復盤道:“同一封裝大概率沒有IO Die,所以當時猜測的是異構Die。用同一個Socket的B100封裝內采用同構Die 180度旋轉這塊也有一些偏差,回頭刷一下對這個架構的洞察。如果GB200采用雙Socket的話其實這個問題就好猜了,兩個B100的連接實際上是依賴兩個邊上的NVLink C2C互聯的,這個時候是否遵循旋轉對稱性問題不大。有點兒超乎想象的是GB200的2 Socket 4 Die和文中的X100的對上了。未來GX200怎么搞就值得期待了。Nvidia的策略還是更激進的。這個預測和推演還是偏保守了。”
3、X100 GPU架構推演
NVIDIA X100如果采用單Socket封裝四Die架構,封裝基板面積將超過6倍Reticle面積,這將超出2025年的先進封裝路標的目標。而如果采用雙Socket封裝架構,則需要使用10~15cm的C2C互聯技術來實現跨封裝的計算 Die間的互聯,這可能需要對當前NVLink C2C的驅動能力進一步增強。 NVIDIA X100 GPU如果采用四Die架構,如果要控制封裝基板面積在6倍Reticle面積以下,匹配2025年先進封裝路標,則需要在計算Die上通過3D堆疊的方式集成HBM [21][22]。因此X100如果不采用SuperChip超級芯片的架構而是延續單封裝架構,要想在2025年推出,技術挑戰非常大。一方面需要先進封裝基板達到6倍Reticle面積,另一方面需要實現在計算Die上堆疊HBM,同時要解決HBM和計算Die堆疊帶來的芯片散熱問題。
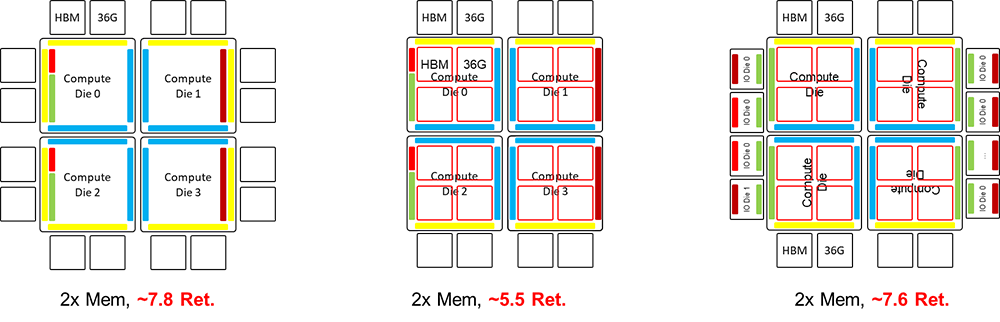
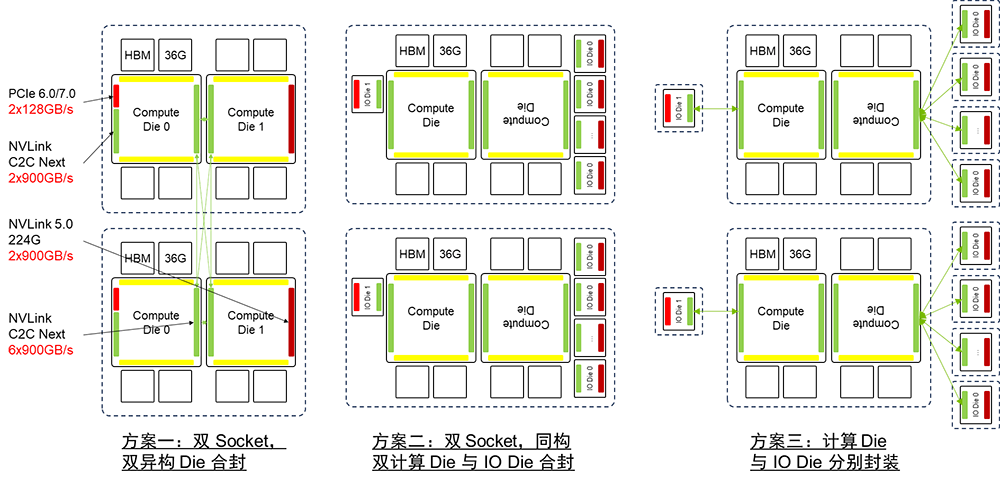
在滿足2025年的工程約束的前提下,X100也可以采用SuperChip超級芯片架構在B100雙Die架構的基礎上進行平面擴展。在這種情況下,NVIDIA X100也有“異構Die合封”,“同構計算Die與IO Die合封”,“計算Die與IO Die分別封裝”三種架構選項。如果采用封裝間互聯的超級芯片的擴展方式,先進封裝的基板面積約束將不再會是瓶頸,此時只需要增強NVLink C2C的驅動能力。
06. H100/H200,B100,X100
GPU架構演進總結
基于以下兩個前提:每一代AI芯片的存儲、計算和互聯比例保持大致一致,且比上一代提升1.5到2倍以上;工程工藝演進是漸進且可預測的,不存在跳變,至少在2025年之前不會發生跳變。因此,可以對2023年的H100、2024年的B100和2025年的X100的架構進行推演總結。 對于工程工藝的基本假設如下:到2025年,工藝將保持在3nm水平,但工藝演進給邏輯器件帶來的收益預計不會超過50%。同時,先進封裝技術預計將在2025年達到6倍 Reticle面積的水平。此外,HBM內存容量也將繼續增長,預計在2024年將達到24GB,而在2025年將達到36GB。 在上述前提假設條件下,針對H100/H200, B100, X100 GPU可以得到如下推演結論:
1. H200是基于H100的基礎上從HBM3升級到HBM3e,提升了內存的容量和帶寬。
2. B100將采用雙Die架構。如果采用異構Die合封方式,封裝基板面積將小于當前先進封裝4倍Reticle面積的約束。而如果采用計算Die和IO Die分離,同構計算Die和IO Die合封的方式,封裝基板面積將超出當前先進封裝4倍Reticle面積的約束。如果采用計算Die和IO Die分離,同構計算Die和IO Die分開封裝的方式,則可以滿足當前的工程工藝約束。考慮到B100 2024年推出的節奏,以及計算Die在整個GPU芯片中的成本占比并不高,因此用異構Die合封方式的可能性較大。 3. 如果X100采用單Socket封裝,四個異構Die合封裝的方式,需要在計算Die上堆疊HBM,同時需要先進封裝的基板達到6倍Reticle面積。但是,如果采用SuperChip超級芯片的方式組成雙Socket封裝模組,可以避免計算Die上堆疊HBM,并放松對先進封裝基板面積的要求,此時需要對NVLink C2C的驅動能力做增強。
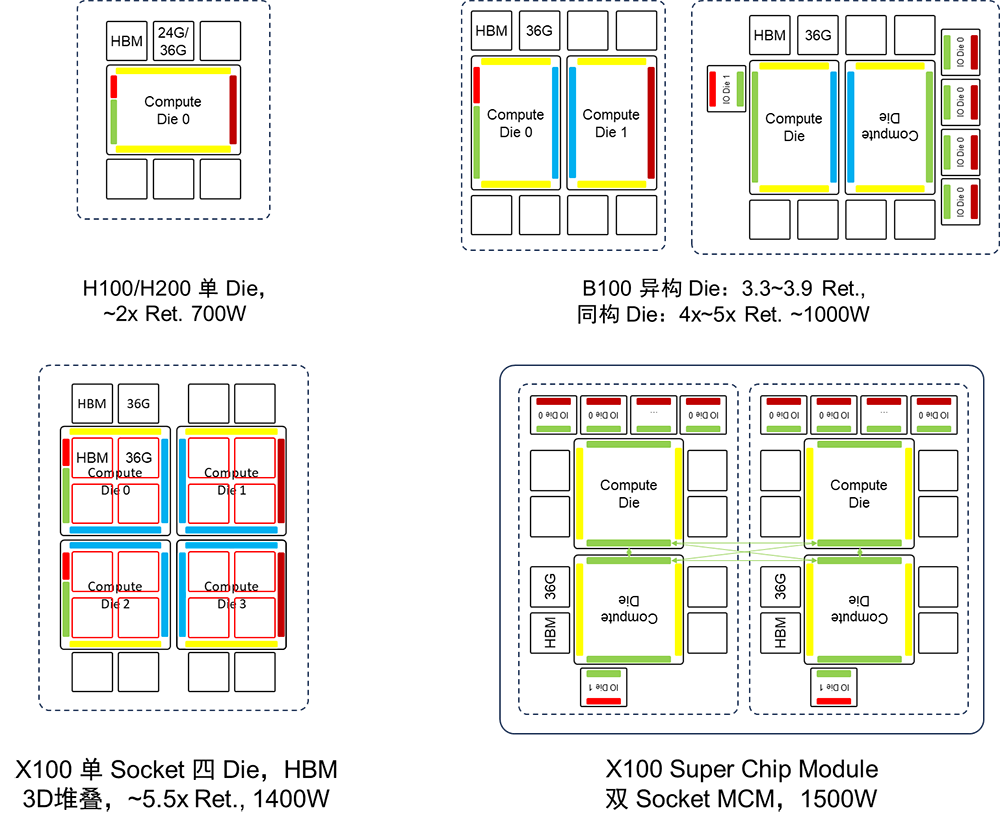
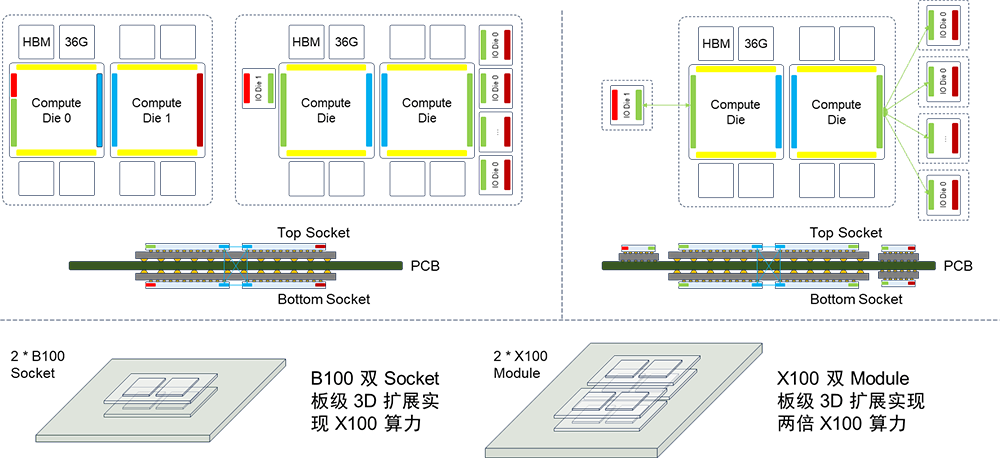
基于B100雙Die架構,采用雙Socket板級3D擴展可以實現與X100同等的算力。類似的方法也可以應用到X100中進一步擴展算力。板級擴展可以降低對工程工藝的要求,以較低的成本實現算力擴展。 雖然基于人們對于先進封裝的Chiplet芯粒架構充滿了期待,但是其演進速度顯然無法滿足AI計算系統“三年三個數量級”的增長需求 [33]。在AI計算領域基于先進封裝Die間互聯Chiplet芯粒架構,很可能因為無法滿足AI計算領域快速增長的需求而面臨“二世而亡”的窘境,業界需要重新尋找旨在提升AI算力的新技術路徑,比如SuperChip超級芯片和SuperPOD超節點。 因此,類似于NVLink C2C的低時延、高可靠、高密度的芯片間互聯技術在未來AI計算芯片的Scale Up算力擴展中將起到至關重要的作用;面向AI集群Scale Out算力擴展的互聯技術也同等重要。這兩中互聯技術,前者是AI計算芯片算力擴展的基礎,而后者是AI計算集群算力擴展的基礎。
07. 結語:總結與思考
本文嘗試從第一性原理出發,對NVIDIA的AI芯片發展路線進行了深入分析和解讀,并對未來的B100和X100芯片架構進行了推演預測。并且,希望通過這種推演提取出未來AI計算系統對互聯技術的新需求。 本文以互聯技術為主線展開推演分析,同時考慮了芯片代際演進的性能提升需求和工程工藝約束。最終得出的結論是:在AI計算領域,基于先進封裝Die間互聯的Chiplet芯粒架構無法滿足AI計算領域快速增長的需求,可能面臨“二世而亡”的窘境。低時延、高可靠、高密度的芯片間互聯技術在未來AI計算芯片的Scale Up算力擴展中將起到至關重要的作用;雖然未展開討論,同樣的結論也適用于面向AI集群Scale Out算力擴展的互聯技術。
224G及以上代際中,面向計算集群的互聯技術也存在非常大的挑戰。 需要明確指出的是,互聯技術并不是簡單地將芯片、盒子、機框連接起來的問題,它并不是一根連線而已,它需要在需求、技術、產業生態等各個方面進行綜合考慮,需要極具系統性的創新以及長時間的、堅持不懈的投入和努力。 除了互聯技術以外,通過對NVIDIA相關技術布局的分析也引發了如下思考:
1. 真正的差異化競爭力源于系統性地、全面地掌握整個價值鏈中主導無法快速復制的關鍵環節。NVIDIA在系統和網絡、硬件、軟件這三個方面占據了主導地位,而這三個方面恰恰是人工智能價值鏈中許多大型參與者無法有效或快速復制的重要部分。然而,要在這三個方面中的任何一方面建立領導地位都離不開長時間堅持不懈的投入和努力帶來的技術沉淀和積累。指望在一個技術單點形成突破,期望形成技術壁壘或者技術護城河的可能性為零。“重要且無法快速復制”是核心特征,其中“重要”更容易被理解,而“無法快速復制”則意味著“長時間堅持不懈的投入和努力”帶來的沉淀和積累,這是人們往往忽視的因素。
2. 開放的產業生態并不等同于技術先進性和競爭力。只有深入洞察特定領域的需求,進行技術深耕,做出差異化競爭力,才能給客戶帶來高價值,給自身帶來高利潤。NVIDIA基于NVLink C2C的SuperChip超級芯片以及基于NVLink網絡的SuperPOD超節點就是很好的例子。真正構筑核心競爭力的技術是不會開放的,至少在有高溢價的早期不會開放,比如NVIDIA的NVLink和NVLink C2C技術,比如Intel的QPI和UPI。開放生態只是后來者用來追趕強者的借口(比如UEC),同時也是強者用來鞏固自己地位的工具(比如PCIe)。然而,真正的強者并不會僅僅滿足于開放生態所帶來的優勢,而是會通過細分領域和構筑特定領域的封閉生態,實現差異化競爭力來保持領先地位。
3. 構筑特定領域的差異化競爭力與復用開放的產業生態并不矛盾。其關鍵在于要在開放的產業生態中找到真正的結合點,并能夠果斷地做出取舍,勇敢地拋棄不必要的負擔,只選擇開放產業生態中的精華部分,構建全新的技術體系。為了構筑特定領域的差異化競爭力,更應該積極擁抱開放的產業生態,主動引導其發展以實現這種差異化。比如,InfiniBand與Ethernet在低時延方面的差異化并不是天生的,而是人為構造出來的。兩者在基礎技術上是相同的。InfiniBand在25G NRZ代際以前抓住了低時延這一核心特征,摒棄跨速率代際兼容的需求,卸掉了技術包袱,并且在HPC領域找到了合適的戰場,因此在低時延指標上一直碾壓Ethernet,成功實現了高品牌溢價。而InfiniBand在56G PAM4這一代際承襲了Ethernet的互聯規范,因此這種低時延上的競爭力就逐漸喪失了。人為制造差異化競爭力的典型例子還有:同時兼容支持InfiniBand和Ethernet的CX系列網卡和BlueField系列DPU;內置在NVSwitch和InfiniBand交換機中的SHARP在網計算協議和技術;NVIDIA基于NVLink C2C構筑SuperChip超級芯片以及基于NVLink網絡構筑SuperPOD超節點。
4. “天下沒有免費的午餐”,這是恒古不變的真理和底層的商業邏輯。商業模式中的“羊毛出在狗身上,由豬買單”其實就是變相的轉移支付,羊毛終將是出在羊身上,只是更加隱蔽罷了。這一規律同樣適用于對復雜系統中的技術價值的判斷上。自媒體分析H100的BOM物料成本除以售價得到90%的毛利率是片面的,因為高價值部分是H100背后的系統競爭力,而不僅僅是那顆眼鏡片大小的硅片。這里包含了H100背后的海量的研發投入和技術積累。而隱藏在這背后的實際上是人才。如何對中長期賽道上耕耘的人提供既緊張又輕松的研究環境,使研究人員能安心與具有長期深遠影響的技術研究,是研究團隊面臨的挑戰和需要長期思考的課題。從公開發表的D2D和C2C相關文獻中可以看到,NVIDIA在這一領域的研究投入超過十年,針對C2C互聯這一場景的研究工作也超過五年。在五到十年的維度上長期進行迭代研究,需要相當強的戰略定力,同時也需要非常寬松的研究環境和持續的研究投入。
5. 在人工智能時代,通過信息不對稱來獲取差異化競爭力或獲得收益的可能性越來越低。這是因為制造信息不對稱的難度和代價不斷飆升,而其所帶來的收益卻逐漸減少。在不久的未來,制造信息不對稱的代價將會遠遠超過收益。妄圖通過壟斷信息而達到差異化的競爭力,浪費的是時間,而失去的是機會。隨著大模型的進一步演進發展,普通人可以通過人工智能技術輕松地獲取并加工海量的信息且不會被淹沒。未來的核心競爭力是如何駕馭包括人工智能在內的工具,對未來技術走向給出正確的判斷。
6. NVIDIA并非不可戰勝,在激進的技術路標背后也隱藏著巨大的風險。如何向資本證明其在AI計算領域的能夠長期維持統治地位,保持長期的盈利能力,以維持其高股價、實現持續高速增長,極具挑戰性。一旦2025年發布的X100及其配套關鍵技術不及預期,這將直接影響投資者的信心。這是NVIDIA必須面臨的資本世界的考驗,在這一點上它并沒有制度優勢。在一些基礎技術層面,業界面臨的挑戰是一樣的。以互聯技術為例,用于AI計算芯片Scale Up算力擴展的C2C互聯技術,以及面向AI集群Scale Out算力擴展的光電互聯技術都存在非常大的挑戰。誰能在未來互聯技術演進的探索中,快速試錯,最快地找到最佳路徑,少犯錯誤,誰就抓住了先機。在未來的競爭中有可能實現超越。
審核編輯:黃飛
































 工商網監
工商網監
評論